Как мы считали экономику продукта «Семья» через uplift CLTV
Всем привет! Меня зовут Владлен Севернов. Я работаю ML-инженером в команде CLTV билайна. В этой статье я поделюсь с вами моим опытом решения задачи uplift-моделирования для оценки экономики продукта «Семья» с точки зрения CLTV.
Что мы подразумеваем под CLTV
Подробнее про CLTV в билайне вы можете почитать в наших предыдущих статьях:
С использованием CLTV билайн может сосредоточиться на удержании наиболее ценных клиентов, повышении их удовлетворенности и лояльности, а также оценивать эффективность маркетинговых и рекламных кампаний.
Немного про продукт «Семья»
Семейные тарифы — это возможность создать общую группу (семью) с другими людьми и добавить в нее до пяти абонентов (в зависимости от тарифа). После объединения в семью платящим остается только один абонент, называемый «донором», а другие члены группы, которые пользуются общими пакетами минут, SMS и трафика и не платят, называются «реципиентами».
Почему для семейных тарифов необходимо считать именно CLTV?
Экономика продукта семья считается непросто — с одной стороны, растет выручка у донора, с другой — ожидаем каннибализацию выручки с потенциальных реципиентов. При продвижении продукта мы делаем ставку на 2 сценария:
Помогаем группе клиентов снизить суммарные расходы, ожидая более долгие отношения
Рассчитываем, что такая механика будут стимулировать приток реципиентов от конкурентов
Для исследования экономики продукта и повышения эффективности его продвижения идеально подходит такая метрика как CLTV.
Постановка задачи
Постановка задачи следующая: абоненты билайна могут объединяться в группы (семьи), где может быть один донор и несколько реципиентов (до 5 человек). До объединения в семью донор и реципиенты в большинстве случаев платили за услуги связи, но после объединения в семью платящим остается только донор, а реципиенты перестают платить (или платят только за какие-то дополнительные услуги) и, по сути, происходит каннибализация выручки. Семейным абонентом мы называем донора или реципиента, которые объединены в продукт «Семья». Стоит задача оценить CLTV абонентов после фактического объединения в семью и каким был бы CLTV таких абонентов, если бы они в семью не объединились.
Прежде чем погружаться в детали, введем некоторые обозначения:
H0 — абонент не объединился в семью;
H1 — абонент объединился в семью;
P (paid=1|H0, N) — вероятность нахождения абонента в платящей базе через N месяцев, если бы объединения в семью не произошло;
P (paid=1|H1, N) — вероятность нахождения абонента в платящей базе через N месяцев, после объединения в семью;
SM (H0, N) — сервисная маржа (маржа после вычета костов) абонента через N месяцев с учетом вероятности P (paid=1|H0, N), если бы объединения в семью не произошло;
SM (H1, N) — сервисная маржа абонента через N месяцев с учетом вероятности P (paid=1|H1, N) после объединения в семью;
delta CLTV (N) = SM (H1, N) — SM (H0, N).
По условию задачи необходимо разработать модель прогнозирования дельты CLTV семейного абонента в каждом отчетном периоде на заданный горизонт (на месяц вперед, на два месяца и т.д. до 12 месяцев). Дельтой CLTV абонента в данном случае называем разность SM (H1, N) — SM (H0, N). Дельта CLTV считается как для доноров, так и для реципиентов. Дельтой CLTV семьи мы называем суммарную дельта CLTV донора и его реципиентов.
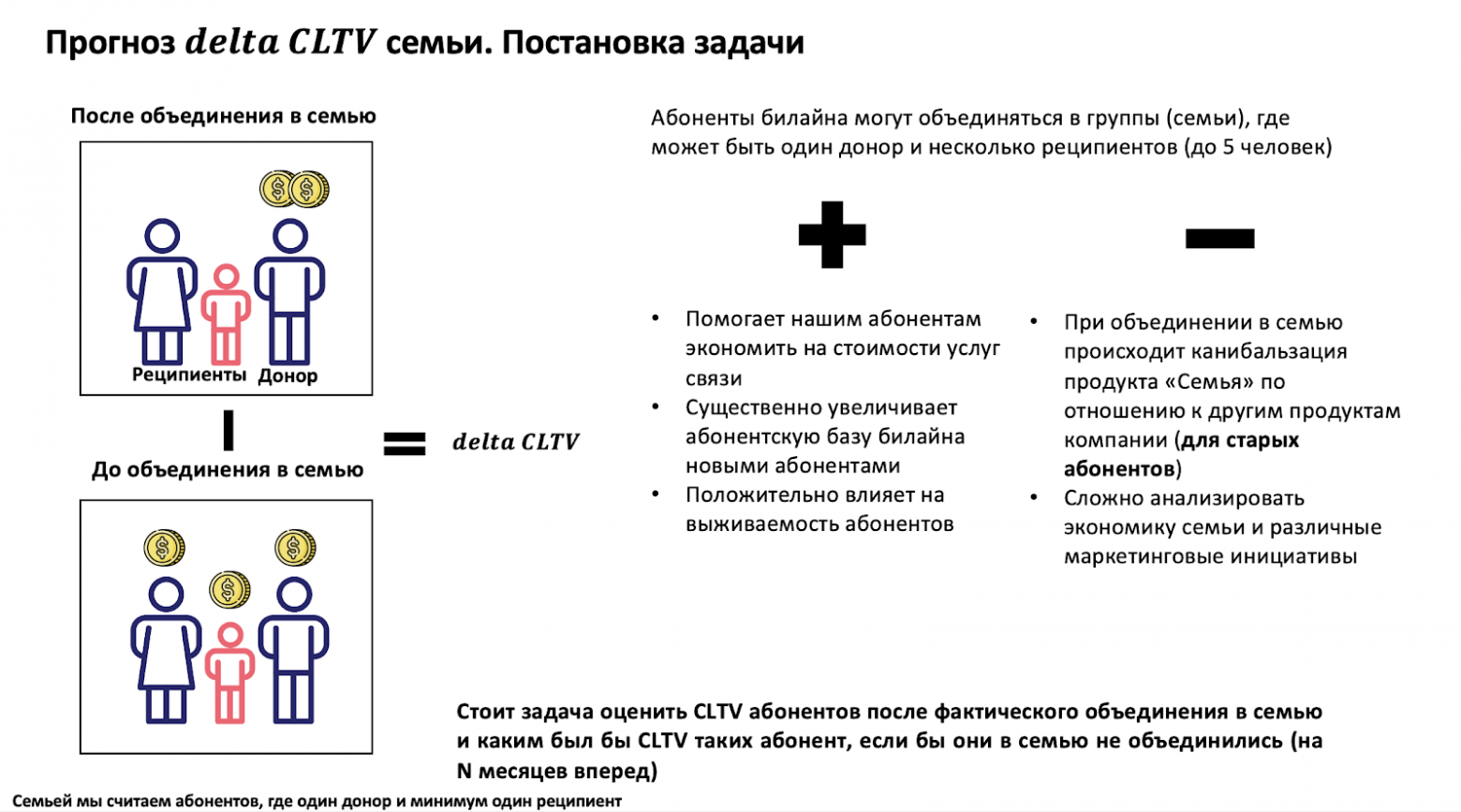
В идеале, чтобы семья была прибыльной, должны выполняться следующие неравенства:
P (paid=1|H1, N) > P (paid=1|H0, N) — выживаемость абонентов после объединения в семью должна быть больше, чем если бы абоненты в семью не объединились.
SM (H1, N)> SM (H0, N) — суммарная сервисная маржа абонентов в семье должна быть больше после объединения в семью, чем если бы абоненты в семью не объединились (в основном за счет абонентской платы донора).
В семью объединяются новые абоненты, которые приходят в билайн, чтобы объединиться в семью и экономить на связи
Если суммарная deltaCLTV по донору и реципиенту отрицательная, то считается, что объединение в семью было убыточным.
Абонентская база
Модель прогнозирования дельты CLTV нацелена на работу с новыми объединениями в семью. Новым объединением называется статус абонента, который в текущем месяце впервые за некоторое время объединился в семью (в нашем случае, если абонент не объединялся в семью хотя бы в течение одного месяца) и пробудет в ней определенное количество месяцев (в нашем случае хотя бы один месяц). Принцип выбора такого абонента завязан на таблице, содержащей ежедневную информацию по абонентам, объединившимся в семью по следующему правилу: берем только тех абонентов, которые не были в этой таблице в конце предыдущего месяца, но есть в ней в конце текущего месяца, при условии, что этот абонент пробудет в статусе семейного как минимум до конца следующего месяца и не поменяет свою роль в семье.
Модель дельта CLTV семьи
Для прогнозирования CLTV абонентов в случае H0 и H1 строится две отдельных Catboost-модели на данных контрольной и целевой групп соответственно. Принципы формирования контрольной и целевой группы объясняются ниже в статье.
Модель в случае H0 мы называем — несемейной, а в случае H1 — семейной.
Каждая из моделей состоит из модели прогнозирования выживаемости (вероятности оказаться в платящей базе) и модели прогнозирования сервисной маржи.

Семейная модель
Строится на данных целевой группы. В целевую группу попадают семейные абоненты, которых мы считаем новыми объединениями в семью.
Так как абоненты могут объединяться в семьи в любой день месяца, то для построения семейноймодели необходимо выжидать как минимум один месяц после подключения семьи и обучать модель на признаках, включающих следующий месяц после объединения. Это необходимо для накопления большего количества полезной информации по абоненту после объединения в семью и улучшения качества прогноза.
Прогноз делается на 12 периодов (на 1 месяц вперед, на 2 месяца вперед и т.д.) до года и на 5 лет. Прогноз на 5 лет представляет из себя прогноз суммарной сервисной маржи, полученной от абонента в течение 5 лет, и делается с использованием пятилетнего коэффициента продления, вычисленного по прогнозам SM на 12 периодов.

Несемейная модель
Строится на данных контрольной группы. В контрольную группу попадают абоненты, которые не стали семейными на всем диапазоне моделирования. Для построения несемейной модели, используются признаки на момент объединения в семью в целевой группе. Так же, как и для семейной модели, прогноз делается на 12 периодов (на 1 месяц вперед, на 2 месяца вперед и т.д.) до года и на 5 лет.

Целевая прогнозируемая переменная
Для семейной и несемейной моделей целевая переменная в случае прогноза сервисной маржи представляет собой среднедневное значение сервисной маржи в каждом календарном месяце (месячная сервисная маржа, деленная на количество дней в месяце) с горизонтом 12 месяцев для целевой и контрольной группы соответственно. При скоринге предсказания среднедневной сервисной маржи умножаются на количество дней в предсказываемом месяце.
Целевая переменная в случае прогноза вероятности оказаться в платящей базе представляет собой флаг наличия в платящей базе (1 — в платящей базе, 0 — не в платящей базе) с горизонтом 12 месяцев.
Балансировка целевой и контрольной группы
Так как абоненты билайна сами решают, стоит ли им объединяться в семью или нет, то мы не можем случайным образом разбить выборку на две группы и одних объединить в семью, а других нет. Поэтому было принято решение в качестве контрольной группы использовать абонентов, которые не объединились в семью на всем горизонте моделирования. Но если просто случайным образом выбрать для контрольной группы таких абонентов, то ничего хорошего не выйдет, так как данные на предпериоде целевой и контрольной группы будут несбалансированными, а результаты, полученные на несбалансированных данных в случае решения задачи uplift-моделирования будут некорректными. Чтобы результат был «честным», перед обучением моделей проводилась балансировка целевой и контрольной группы. Балансировка проводилась с использованием метода propensity score matching.
Propensity score (оценка склонности) — это числовая оценка вероятности принадлежности человека к определенной группе, основанная на наборе известных признаков (факторов, влияющих на исход). В статистике propensity score используется для устранения смещения в оценке эффекта воздействия в наблюдательных исследованиях (например, когда невозможно провести контролируемый эксперимент). Путем сопоставления участников, которые имеют похожие propensity scores, но отличаются только в том, что одни получили воздействие, а другие нет, можно получить оценку эффекта воздействия. Propensity score используется в таких методах, как propensity score matching, propensity score weighting, и propensity score stratification.
Мы в CLTV в качестве базовой модели для propensity score используем Catboost, а в качестве признаков для балансировки (ковариатов) — признаки на предпериоде. Важно, чтобы в качестве фичей для балансировки не попали признаки, которые как-то косвенно учитывают наше воздействие. Например, нет смысла брать сервисную маржу донора или реципиента в месяц подключения семьи и по ней балансировать, так как у доноров и у реципиентов становится специфичная для объединённых в семью сервисная маржа, а именно достаточно большая у доноров, но почти нулевая у реципиентов. Хорошей практикой является балансировка с жестким фиксированием подгрупп, например, балансировать внутри определенной даты и региона, так как в нашем бизнесе необходимо учитывать сезонность и характеристики абонентов из разных регионов, которые могут отличаться в зависимости от региона.

Uplift-модель (T-learner)
В основе прогнозирования дельта CLTV семьи лежит uplift-модель, которая реализована следующим образом:
1) Строится семейная модель
2) Строится несемейная модель
3) Скорим семейной и несемейной моделью абонентов, которых считаем новыми объединением в семью. Для скоринга по семейной модели необходимо подтягивать фичи к дате через месяц после подключения, а для несемейной модели подтягиваем фичи на предпериоде к дате подключения семьи. Затем вычисляем разность между прогнозами семейной и несемейной модели — это и есть дельта CLTV. Дельта CLTV семьи равно сумме дельта CLTV донора и реципиентов в момент подключения семьи.

Оптимизация семейных кампаний с использованием дельты CLTV
Разработанная модель deltaCLTV позволяет анализировать только экономику уже существующих семей. Но хотелось бы научиться оценивать экономику будущих семей на этапе предложения подключить семью тому или иному абоненту. Другими словами, предлагать подключить семью только тем абонентом, с которыми deltaCLTV будет положительной. Для этого мы разработали несколько подходов, представленных ниже.
Модель house hold + модель deltaCLTV для house hold
Модель house hold— модель, которая по графу звонков определяет, являются ли абоненты потенциальным домохозяйством.
Модель deltaCLTV для house hold отличается от рассмотренной ранее модели deltaCLTV только тем, что семейная модель в качестве семейных фичей использует только роль в семье, и мы не ждем один месяц для накопления семейной истории абонента.
Идея заключается в том, что семью было бы разумно продавать потенциальным домохозяйством, в которых мы бы сами выбирали потенциального донора, наилучшего с точки зрения deltaCLTV.
Принцип выбора донора по результатам работы модели deltaCLTV для house hold выглядит следующим образом:
Для каждого выбранного домохозяйства:
Для каждого абонента из домохозяйства, у которого на тарифе доступна семья и который не объединился в семью:
Считаем, каким был бы CLTV (1y|owner), если бы этот абонент стал донором
Считаем, каким был бы CLTV (1y|child), если бы этот абонент стал реципиентом
Считаем каким был бы CLTV (1y|H0), если бы этот абонент не объединился в семью
Предлагаем стать донором тому абоненту, с которым, если он станет донором deltaCLTV1y будет положительно.
deltaCLTV1y=CLTV (1y|owner)+1hhsize-1k=1hhsize-1CLTV (1y|child)k-CLTV (1y|H0, owner)-1hhsize-1k=1hhsize-1CLTV (1y|H0, child)k
где hhsize — размер домохозяйства
Чтобы проверить эффективность модели deltaCLTV для house hold, был запущен пилот по продвижению семьи. Дизайн пилота был следующий.
Разбиваем домохозяйства случайным образом на 3 группы, которые будем сравнивать между собой
Для первой группы предлагаем стать донором такому абоненту из домохозяйства, у которого средняя сервисная маржа за предыдущие три месяца была наибольшей
Для второй группы предлагаем стать донором случайному абоненту из домохозяйства
Для третьей группы предлагаем стать донором абоненту из домохозяйства, выбранного по модели deltaCLTV для house hold.
Сравниваем средний годовой CLTV семьи каждой из групп
Смотрим, какой из методов продвижения семьи оказался самым выгодным с точки зрения годового CLTV (спойлер: таким методом оказалась модель deltaCLTV для house hold)
Модель ранжирования доноров по deltaCLTV
Когда происходит коммуникация с потенциальным донором, мы заранее не знаем:
Кто будет у потенциального донора в качестве реципиентов, сколько их будет
Приведет ли этот донор новых абонентов в качестве реципиентов или старых
Дельта CLTV семьи зависит от нескольких факторов, в особенности от фактического времени сотрудничества с реципиентом и их количества. Когда люди приходят в компанию ради семьи, то это положительно влияет на дельту CLTV, так как в таком случае фактор каннибализации сводится к нулю. Было бы разумно научиться вычислять для потенциального донора вероятность того, что он приведет нового реципиента и использовать эту вероятность как дополнительный признак. Так как у нас есть исторические данные по образованным семьям, мы можем разработать модель прогнозирования вероятности подключения нового реципиента в семье при таком доноре и использовать эту вероятность как признак для обучения.
Можно оценивать deltaCLTV всей семьи только по фичам донора
В качестве целевой переменной используем прогнозное значение deltaCLTV для семьи (суммарный за год)
В качестве признаков используем признаки потенциального донора + вероятность того, что это донор приведет нового реципиента (для прогнозирования вероятности используется отдельная модель)
Строим модель регрессии для предсказания прогнозного значения deltaCLTV
Предлагаем стать донорами только тем, у кого прогноз больше некоторого порога
Для прогноза суммарно используем 3 ML модели (delta CLTV (балансировка + 4 ML модели) + Lifetime (1 ML модель) + Ranking (1 ML модель))
Что нам это все дало?
Модель оценки дельта CLTV продукта «Семья» дает нам возможность оценивать финансовые показатели каждой семьи в разрезе выживаемости и сервисной маржи. Используя представленный подход, можно также улучшать таргетинг в компаниях по продвижению семьи и предлагать стать донором только тем абонентам, с которыми семья будет выгоднее с точки зрения CLTV, чем если бы объединения в семью не произошло. В билайне на момент написания статьи дельта CLTV семьи используется для оценки эффективности компаний по продвижению продукта «Семья» и для максимизации эффективности таргетинга продукта.
