После RSS
В свободное время я занимаюсь разработкой сервиса «Awakari», идея которого — фильтрация интересных событий из неограниченного числа различных источников. В этой статье я расскажу о способах извлечения публично доступной информации в интернете за пределами RSS-лент и телеграм-каналов.
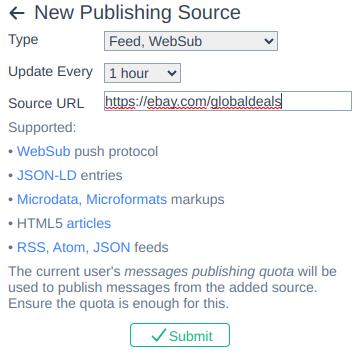
Добавление источника типа «лента обновлений» в Awakari
Первый и самый очевидный тип источников Awakari — это ленты RSS. Сервис избавляет пользователя от необходимости посещать снова и снова все возможные ленты, каналы и сайты в поиске того, что ему интересно. Вместо этого сервис выполняет обратный поиск и присылает релевантные сообщения (например, в Телеграм). Однако, огромное количество полезной информации в интернете при этом остается недоступной.
С одной стороны, различным сервисам выгоднее, чтобы пользователи получали контент только в их приложениях и платформах. Это также является одной из причин, почему поддержка RSS только падает последние лет 10–20. Кроме того, многие сервисы целенаправленно препятствуют автоматизированному сбору метаданных. Это уже давно не секрет.
Микроразметка
С другой стороны, есть прямо противоположное направление:
Schema.org — совместная инициатива по разработке единой схемы для семантической разметки в HTML5. Инициатива была запущена второго июня 2011 года создателями крупнейших поисковых систем — компаниями Google[1], Yahoo![2] и Microsoft[3] , а первого ноября 2011 года к ней присоединилась российская компания Яндекс[4][5][6]. Основной целью schema.org является помощь веб-разработчикам в создании качественных метаданных, что, в свою очередь, позволяет улучшать качество поиска. Метаданные на сайтах, использующие схемы, описанные на schema.org, могут быть напрямую проанализированы поисковыми роботами, помогая последним лучше «понимать» содержимое веб-ресурсов. Например, при помощи микроразметки веб-мастера могут разметить страницу товара, указав стоимость, общий рейтинг товара и прочие данные, которые Google выведет в результатах поисковой выдачи.

В широком распространении микроразметки нет ничего удивительного. Сервисы всё равно будут предоставлять машиночитаемые и структурированные данные хотя бы для того, чтобы быть выше в результатах поиска у гугла. Детальная статистика использования различных вариантов микроразметки также доступна.
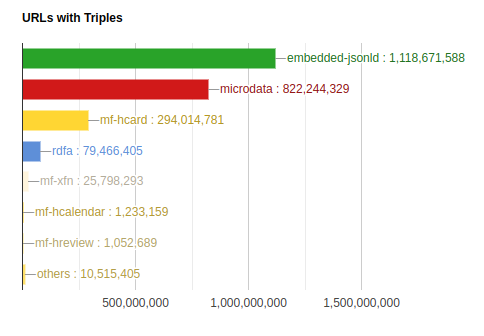
Как видно, на текущий момент в интернете лидируют два варианта — JSON-LD и Microdata. Оба формата описывают структуры определённого типа. Наиболее часто встречающиеся типы:
Как это выглядит на практике:

Есть также и другие способы семантической разметки данных, например:
HTML5 тэг «article», как правило содержит также заголовок, дату, изображение и т.п.
Microformats
Все эти варианты источников теперь поддерживаются сервисом Awakari. Для этого потребовалось также решить, каким образом конвертировать эти данные в уникальные сообщения. Допустим, источник обновляется раз в 1 час. Нужно понять, что уже было отправлено в обработку, а что является новой информацией. Для этого каждая исходная структура (кусок JSON-LD, элемент в ленте RSS или содержимое тэга «article») должна однозначным способом конвертироваться в сообщение. После этого можно считать хэш сумму значимых атрибутов сообщения и решать, встречалось ли оно ранее.
Таким образом, в «ленту новостей» теперь можно превратить всё, что шевелится куда больше источников, таких как блоги, магазины, доски объявлений и прочее.
Как это работает
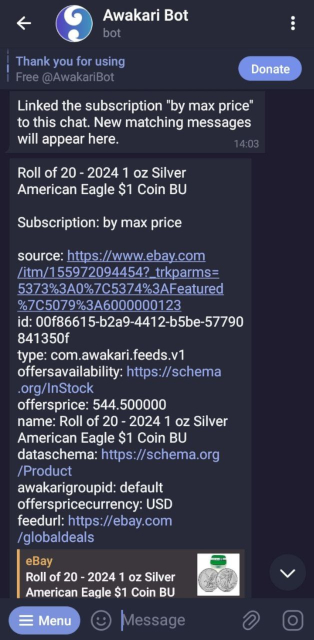
Чтобы воспользоваться новыми возможностями в Awakari, можно создать подписку с указанием, например, цены товара:

Для простоты примера наименование товара и валюта указаны. Для реальных случаев лучше использовать группу условий, включающую также необходимое наименование товара, например «iPhone». По такой подписке будет приходить всё подряд из онлайн магазинов, что дешевле 1000 попугаев. Но всегда можно уточнять условия подписки по атрибутам получаемых сообщений:
WebSub
WebSub является протоколом, а не форматом передачи данных. Изначально он также был задуман для улучшения работы с RSS/Atom. Вся суть заключается в том, что клиенту не требуется периодически выкачивать содержимое ленты, а достаточно сообщить хабу адрес вебхука для получения обновлений, когда они появятся. Это позволяет минимизировать задержку получения новостей с одной стороны и избавиться от «холостых» запросов с другой. Awakari теперь также распознает автоматически, если источник поддерживает WebSub протокол и подписывается на обновления. Пример такого источника:
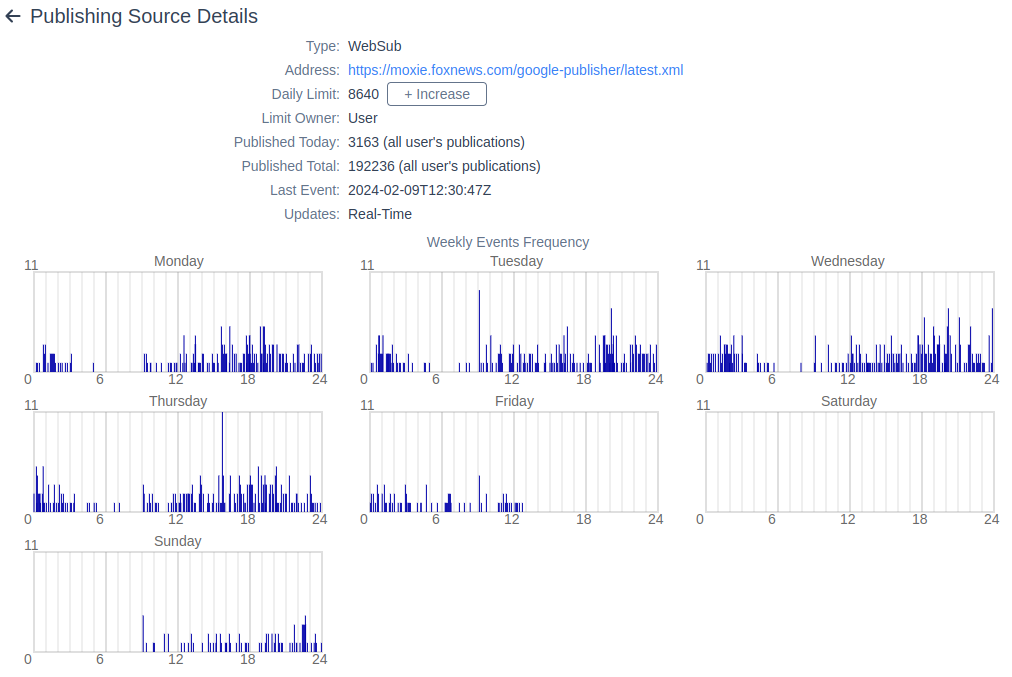
На скриншоте выше также есть графики, которые показывают частоту получаемых из данного источника сообщений на каждую минуту недели. В дальнейшем я планирую использовать эту статистику для автоматической адаптации периода обновления для тех источников, которые обновляются поллингом (то есть те, что не поддерживают WebSub). Кроме того, есть идея интеграции с ActivityPub, что ещё больше расширит набор поддерживаемых источников данных.
