[Перевод] Я написал одну из самых быстрых библиотек датафреймов

❯ 1. Вступление
У меня в портфолио есть несколько готовых пет-проектов на Rust, и я заметил, что позиция «а у нас уже получилась DataFrame?» нисколько меня не устраивает. Поэтому я подумал, не сделать ли мне элементарный контейнер, который решал бы мою конкретную задачу. Но этот проект вышел из-под контроля.
Год спустя, написав немало кода, я создал одну из самых быстрых библиотек датафреймов, применимую в Rust и Python. Вот мой первый официальный «Hello World» на polars, размещённый у меня в блоге. Надеюсь, что с помощью этого поста я смогу пояснить читателю некоторые решения, которые мне довелось принять при проектировании, и вам станет понятнее, как Polars работает под капотом.
❯ 2. Достаточно смелое заявление
Я знаю, что это довольно смелое заявление, и я бы не стал делать его сгоряча. Существует инструмент для бенчмаркинга систем баз данных, который позволяет анализировать софт для обработки данных в оперативной памяти (in-memory) под управлением h2o.ai. Этот контрольный набор состоит из 10 тестов groupby на данные различной мощности (кардинальности) и запросов разной сложности, позволяющий дать всестороннее представление о производительности инструмента. Есть ещё 5 тестов на различные запросы join. На момент написания этого поста Polars является самой быстрой библиотекой датафреймов из всех протестированных, уступает лишь data.table из R, и Polars входит в топ-3 среди всех рассмотренных инструментов.
Ниже приведены результаты теста с набором данных 5 ГБ, а весь бенчмарк можно посмотреть здесь.
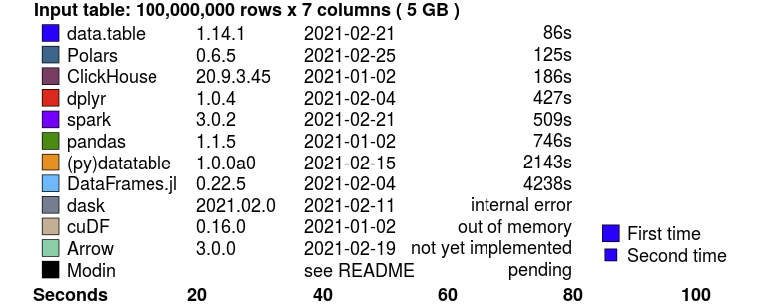
Краткое описание бенчмарка Join:
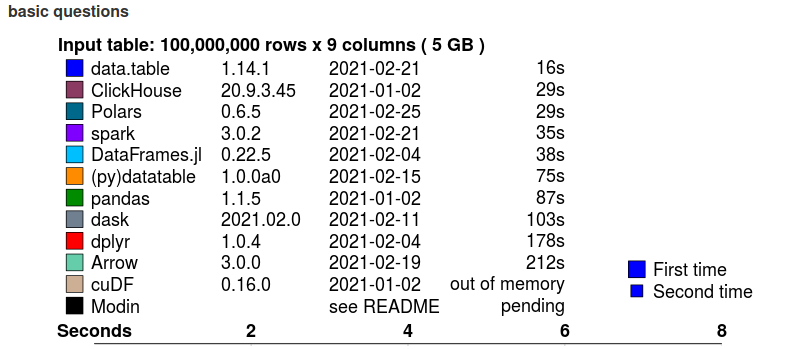
Краткое описание бенчмарка Groupby (базовые запросы):
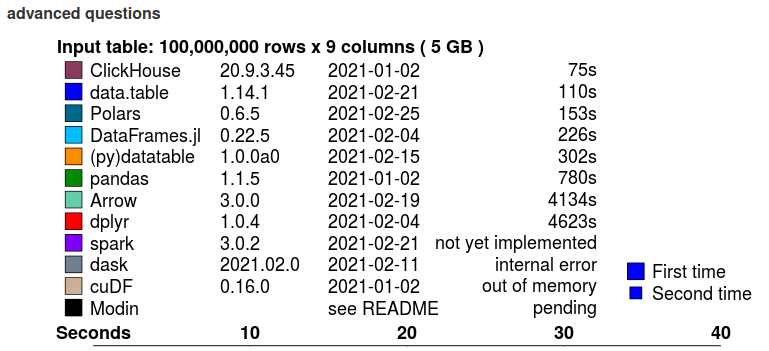
Краткое описание бенчмарка Groupby (сложные запросы):
❯ 3. Знайте свое оборудование
Если вы хотите добиться оптимальной производительности, то обязаны учитывать, на каком оборудовании работаете. Бывает, сто из-за сложности алгоритма не удаётся составить полного представления о реальной производительности из-за аппаратных проблем, таких как иерархия кэша и прогнозирование ветвлений. Например, до определенного порогового количества элементов (около 100, в зависимости от типа данных), поиск заданного элемента в массиве идёт быстрее, чем поиск такого же элемента в hashmap, в то время как временная сложность этих структур данных составляет O (n) и O (1) соответственно. Поэтому решение, принятое при проектировании, также получаются временным: узкое место, наблюдаемое в настоящее время, в будущем может не представлять проблем. Это хорошо видно на примере СУБД. Системы баз данных предыдущего поколения, такие как PostgreSQL или MySQL, представляют собой Volcano-модели на основе строк, и предусмотреть их при проектировании было очень грамотно в ту эпоху, когда диски были намного медленнее, а оперативная память была в дефиците. Сегодня, когда у нас есть быстрые SSD-диски и большие объемы доступной памяти, а также широкие SIMD-регистры, мы видим, что колоночные базы данных, в частности, CockroachDB, DuckDB, являются одними из самых производительных СУБД.
3.1 Иерархия кэша
Говоря проще, оперативная память бывает двух видов: большая и медленная или быстрая и маленькая. По этой причине кэши памяти выстраиваются иерархически. У вас есть основная память, которая является большой и медленной. А память, которую вы использовали совсем недавно, хранится в кэше L1, L2, L3 — чем больше номер, тем длительнее задержка. Приведённый ниже результат позволяет составить впечатление об относительной задержке на различных уровнях кэша.
Время доступа, выраженное в циклах процессора:
- Регистр процессора — 1 цикл
- Кэш L1 — ~1–3 цикла
- Кэш L2 — ~10 циклов
- L3 кэш — ~40 циклов
- Основная память — ~100–300 циклов
При последовательном обращении к данным мы хотим быть уверены, что данные будут как можно длительнее пребывать в кэше, иначе мы легко можем получить ~100-кратное снижение производительности. Кэш загружается и удаляется в кэш-линиях. Когда мы загружаем одну точку данных, мы получаем целую строку кэша, но мы и удаляем целую строку кэша. Они обычно имеют длину 64 или 128 байт и выравниваются по 64-байтовым адресам памяти.
3.2 Предвыборка и прогнозирование ветвлений
Ядра ЦП предвыбирают данные и инструкции, перенося их в локальный кэш. Так удаётся снизить нагрузку, приводящую к задержкам при работе с памятью. Если у вас тугой цикл без каких-либо ветвлений (структур if-else-then), то ЦП без труда различает, какие данные нужно предварительно выбрать — и поэтому может в полной мере использовать конвейеры инструкций.
Конвейеры инструкций скрывают задержку, так как распараллеливают работу. Каждая инструкция ЦП проходит цикл Fetch, Decode, Execute, Write-back (выбрать, декодировать, выполнить, записать обратно). Четыре этих инструкции можно не выполнять последовательно в единственном конвейере, а распределить эту работу на несколько конвейеров, которые уже предвыбирают (декодируют, выполняют, т.д.) следующие инструкции. Так повышается пропускная способность и скрывается задержка. Правда, если этот процесс прервать, то мы имеем пустые конвейеры и должны выдержать весь период задержки до следующей инструкции. Ниже проиллюстрировано, как выглядит конвейер инструкций.
Четырёхэтапный конвейер инструкций:
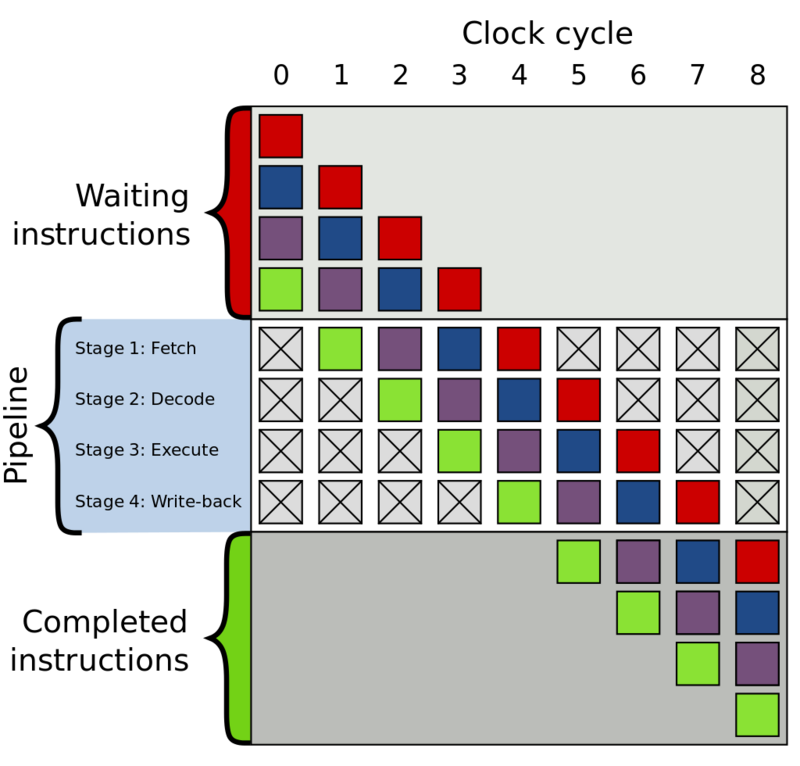
ЦП максимально пытается угадать, какой именно условный переход предпринят, и, в зависимости от прогноза выполняет конкретный код заранее (чтобы конвейеры не пустовали). Но, если прогноз оказался ошибочным, то уже сделанная работа должна быть отменена. Соответственно, придётся заплатить задержкой до тех пор, пока конвейеры не будут вновь заполнены.
3.3 SIMD-инструкции
Современные процессоры оснащены регистрами SIMD (Single Instruction Multiple Data), которые оперируют целыми векторами данных за каждый цикл процессора. Ширина полосы векторов варьируется от 128 бит до 512 бит, а ускорение зависит от ширины регистров и количества битов, необходимых для представления конкретного типа данных. Эти регистры значительно повышают производительность при выполнении простых операций, если удаётся заполнить их достаточно быстро (линейные данные). Поэтому колоночный формат памяти может полностью использовать SIMD-инструкции. Polars и его бекэнд Arrow для работы с памятью используют SIMD ради оптимальной производительности.
Сравнение SISD и SIMD:

❯ 4. Формат памяти Arrow
Библиотека Polars основана на нативной реализации Apache Arrow в Rust. Arrow можно рассматривать как промежуточное ПО для СУБД, движков запросов и библиотек датафреймов. Arrow обеспечивает структуры данных с высокой когерентностью кэша, а также учитывает при работе недостающие данные.
Давайте рассмотрим несколько примеров, чтобы понять, что это значит.
4.1 Числовой массив Arrow
Числовой массив Arrow состоит из буфера данных, содержащего некоторые типизированные данные, например, f32, u64, и т. д. Он показан на рисунке в виде оранжевого массива. Кроме данных значений, массив Arrow всегда имеет проверочный буфер (validity buffer). Этот буфер представляет собой битовый массив, в котором разряды обозначают недостающие данные. Поскольку недостающие данные представлены битами, затраты памяти минимальны.
Налицо явное преимущество такого решения, например, перед Pandas, где нет четкого различия между NaN с плавающей точкой и отсутствующими данными — притом, что по сути это действительно разные вещи.
Числовой массив Arrow:

4.1 Строковый массив Arrow
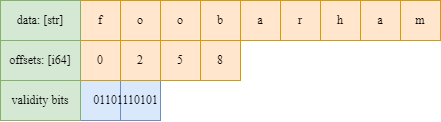
На следующем рисунке показана схема памяти массива Arrow LargeString Этот рисунок описывает следующий массив ["foo", "bar", "ham"]. Массив Arrow состоит из буфера данных, где все байты строк объединяются в один последовательный буфер (способствует когерентности кэша!). Для определения начальной и конечной позиции строкового значения есть отдельный массив смещений, и, наконец, есть буфер нулевых битов для указания недостающих значений.
Массив Arrow large-utf8:
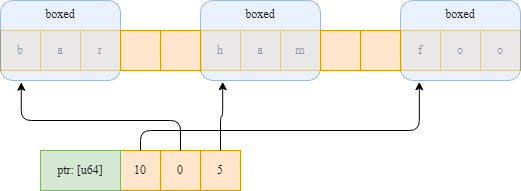
Давайте сравним эту структуру со строковым массивом pandas. Строки Pandas на самом деле являются объектами Python, поэтому имеют ячеистую структуру (что означает, что также есть затраты памяти на кодирование типа вместе с данными). Последовательный доступ к строкам в pandas приводит к промахам кэша, потому что каждое значение строки может указывать на совершенно разные участки памяти.
Строковый массив Pandas:
Представление Arrow явно лучше других обеспечивает согласованность кэша. Однако за это приходится платить. Если мы захотим отфильтровать этот массив или принимать значения, взятые из некоторого индексного массива, нам нужно будет скопировать гораздо больше данных. Строковый массив pandas хранит только указатели на данные и может недорого создать новый массив с указателями. Строковые массивы Arrow должны копировать все строковые данные, и, особенно, если мы имеем дело с большими строковыми значениями, это может приводить к очень серьёзным издержкам. Также сложнее оценить размер буфера строковых данных, поскольку он включает длину всех строковых значений.
В Polars также есть тип Categorical, который помогает смягчить эту проблему. В Arrow также есть решение этой проблемы — так называемый тип Dictionary, который похож на тип Categorical в Polars.
4.2 Подсчёт ссылок
Буферы Arrow считаются по ссылкам и являются неизменяемыми. Это означает, что копирование DataFrame, Series, Array практически невозможно, и поэтому с ними очень просто писать чисто функциональный код. То же самое относится и к операциям сегментирования, для которых требуется простой инкремент количества ссылок и изменение смещения.
4.3 Производительность: недостающие данные и ветвления
Как мы уже видели, недостающие данные кодируются в отдельном буфере. Это означает, что мы можем легко написать неразветвленный код, просто игнорируя нулевой буфер во время операции. По завершении операции буфер нулевых битов просто копируется в новый массив. Когда пропуск ответвления будет более затратен, чем выполнение операции — считайте, мы в выигрыше. Такой приём используется во многих операциях с Arrow в Polars.
4.4. Производительность: фильтр-трик
В СУБД часто приходится выполнять фильтрацию. На основе некоторого предиката (логической маски) мы фильтруем строки. Нулевой битовый буфер Arrows позволяет делать это очень быстро фильтровать с помощью так называемого фильтр-трюка (я сам придумал этот термин). Честь за изобретение фильтр-трюка причитается авторам реализации Apache Arrow. Обратите внимание, что этот фильтр-трюк часто позволяет создавать более быстрые фильтры, но не всегда. Если ваш предикат состоит из чередующихся булевых значений, например,
[true, false, true, false, …, true, false], то этот трюк сопряжён с небольшими издержками.
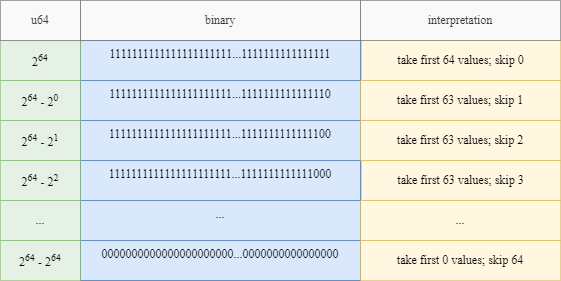
Основная идея фильтр-трюка заключается в том, что мы можем загрузить битовый массив из памяти как любой нужный нам целочисленный тип. Допустим, мы загружаем битовый массив как беззнаковое целое u64, тогда мы знаем, что максимальное закодированное значение равно 264264 (64 последовательных единичных значения в двоичном формате), а минимальное закодированное значение равно 0 (64 последовательных значения 0 в двоичном формате). Мы можем составить таблицу из 64 записей, которые представляют, сколько последовательных значений мы можем отфильтровать и пропустить. Если это целое число есть в этой таблице, мы знаем, что у нас есть много значений для фильтрации за очень малое количество тактов процессора, мы можем применить memcpy для эффективного копирования данных. Если целое число отсутствует в таблице, нам придется перебирать биты один за другим и надеяться, что оно попадёт в следующие 64 бита, которые мы загрузим.
Фильтр-трюк:
Этот фильтр-трюк используется, конечно, в любой операции, включающей маску предиката, такой как filter, set и zip.
❯ 5. Распараллеливание
С достижением предела тактовой частоты процессора и окончанием закона Мура халява закончилась. Однопоточная производительность почти достигла предела. Чтобы смягчить эту проблему, почти все современные ЦП делаются многоядерными. У меня на ноутбуке 12 логических ядер, поэтому существует огромный потенциал для распараллеливание задач. Polars написана так, чтобы использовать параллелизм как можно активнее.
5.1 Чрезвычайная параллельность
Конечно, распараллеливание лучше всего идёт в задачах, где нет необходимости в обмене данными и нет зависимостей между данными. Polars использует этот вид параллелизма настолько активно, насколько это возможно.
Например, если мы выполняем агрегацию столбцов в датафрейме. Все столбцы можно агрегировать параллельно.
Еще один чрезвычайно параллельный алгоритм применяется в Polars в фазе apply в операции groupby.
Чрезвычайная параллельность на практике:
5.2 Параллельное хеширование
На хешировании основаны многие операции в библиотеке датафреймов: операция groupby создает хеш-таблицу с проиндексированными группами, а при операции объединения (join) хеш-таблица требуется для поиска кортежей, сопоставляющих строки левого и правого датафреймов.
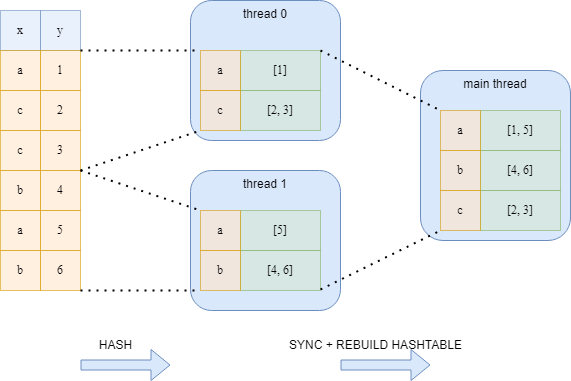
5.2.1 Дорогостоящая синхронизация
В обеих операциях мы не можем просто разделить данные между потоками. Нет никакой гарантии, что все одинаковые ключи окажутся в одной и той же хеш-таблице в одном и том же потоке. Поэтому нам потребуется дополнительная фаза синхронизации, на которой мы создадим новую хеш-таблицу. Этот принцип показан на следующем рисунке для двух потоков.
Дорогостоящая синхронизация:
5.2.2 Дорогостоящая блокировка
Другой вариант, который считается слишком затратным — хеширование данных в отдельных потоках и единая хеш-таблица в мьютексе. Как вы уже представляете, в этом алгоритме очень высок уровень зацикливания потоков, и параллелизм не приносит никакой пользы.
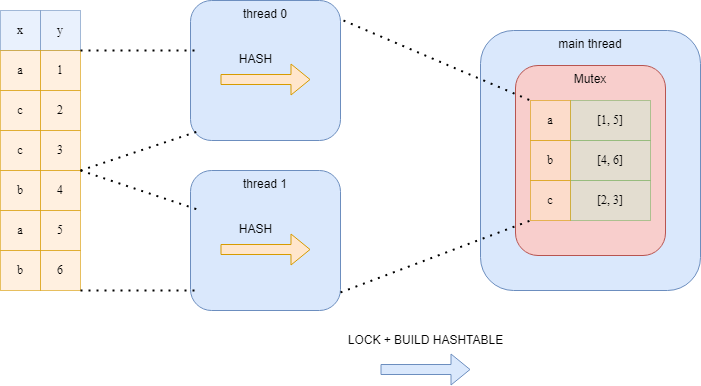
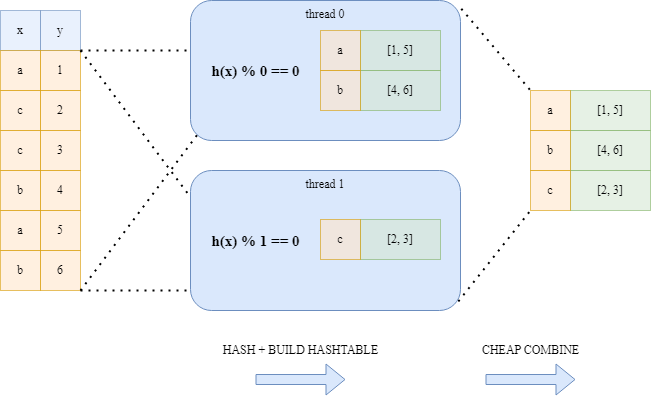
5.2.2 Неблокирующее хеширование
Вместо вышеупомянутых подходов Polars использует алгоритм хеширования без блокировки. Этот подход выполняет больше работы, чем предыдущий подход с дорогостоящей блокировкой, но эта работа выполняется параллельно, и все потоки гарантированно не должны ждать друг друга. Каждый поток вычисляет хеши ключей, но в зависимости от результата хеширования определяется, принадлежит ли этот ключ хеш-таблице данного потока. Это просто выяснить по hash value % thread number. Благодаря этому простому приему мы уверены, что каждая потоковая хеш-таблица имеет уникальные ключи, и мы можем просто объединить указатели хэш-таблиц в главном потоке.
Неблокирующее хеширование:
❯ 6. Оптимизация запросов: Меньше — значит больше
Максимальный прирост производительности достигается, если просто не делать никакой работы вообще. Polars включает два общедоступных API, один из которых ориентирован на жадное процедурное программирование, а другой — на ленивое декларативное программирование. Я бы рекомендовал как можно чаще использовать ленивый API при работе с критичным по производительности кодом.
Декларативный DSL позволяет Polars анализировать логический план вашего запроса и применять несколько оптимизаций/эвристик, чтобы ваш запрос мог быть выполнен за счет сокращения объема работы.
❯ 7. И многое другое
В этой статье были рассмотрены лишь некоторые из конструкций, связанных с производительностью, в библиотеке Polars and Arrow. Другие реализованные вещи — это, например:
Теперь «hello world» официально готов. Ещё посмотрите polars на github, и если у вас есть какие-либо замечания, пожелания по функциям и т. д., дайте мне знать!
Источники
[1] Graefe G… Volcano (1994) an extensible and parallel query evaluation system.IEEE Trans. Knowl. Data Eng.
[2] Herb Sutter (2005) The Free Lunch Is Over: A Fundamental Turn Toward Concurrency in Software Weblog [3] Angela Chang: CockroachDB (2019) 40x faster hash joiner with vectorized execution Weblog

