Упадок RNN и LSTM сетей
Автор: Eugenio Culurciello, оригинальное название: The fall of RNN / LSTM
Перевод: Давыдов А.Н.
Ссылка на оригинал
Мы полюбили RNN (рекуррентные нейронные сети), LSTM (Long-short term memory), и все их варианты. А теперь пора от них отказаться!
В 2014 году LSTM и RNN, были воскрешены. Но мы были молоды и неопытны. В течении нескольких лет они был способом решения таких задач как: последовательное обучение, перевод последовательностей (seq2seq). Так же они позволили добиться потрясающих результатов в понимании речи и переводе ее в текст. Эти сети поспособствовали восхождению таких голосовых помощников как Сири, Кортана, Гугл и Алекса. Не забудем и машинный перевод, который позволил нам переводить документы на разные языки. Или нейросетевой машинный перевод, позволяющий переводить изображения в текст, текст в изображения, делать субтитры для видео и т.д.
Затем, в последующие годы (2015–16) появились ResNet и Attention («Внимание»). Тогда начало приходить понимание, что LSTM — была умной техникой обойти, а не решить задачу. Так же Attention показал, что MLP сеть (Multi-Layer Perceptron Neural Networks -многослойные персептроны) может быть заменена усредняющими сетями, управляемыми вектором контекста. (более подробно об этом дальше).
Прошло всего 2 года, и сегодня мы можем однозначно сказать:
«Завязывайте с RNN и LSTM, они не так хороши!»
Можете не принимать наши слова на веру, просто посмотрите, что сети на основе Attention используют такие компании как Гугл, Фэйсбук, Сэйлфорс и это только некоторые из них. Все эти компании заменили RNN сети и их варианты на сети основанные на Attention и это только начало. Дни RNN сочтены во всех приложениях, так как они требуют больше ресурсов для обучения и работы, чем модели основанные на Attention.
Но почему?
Вспомним, что RNN, LSTM и их производные используют в основном последовательную обработку во времени. Обратите внимание на горизонтальную стрелку на диаграмме ниже:
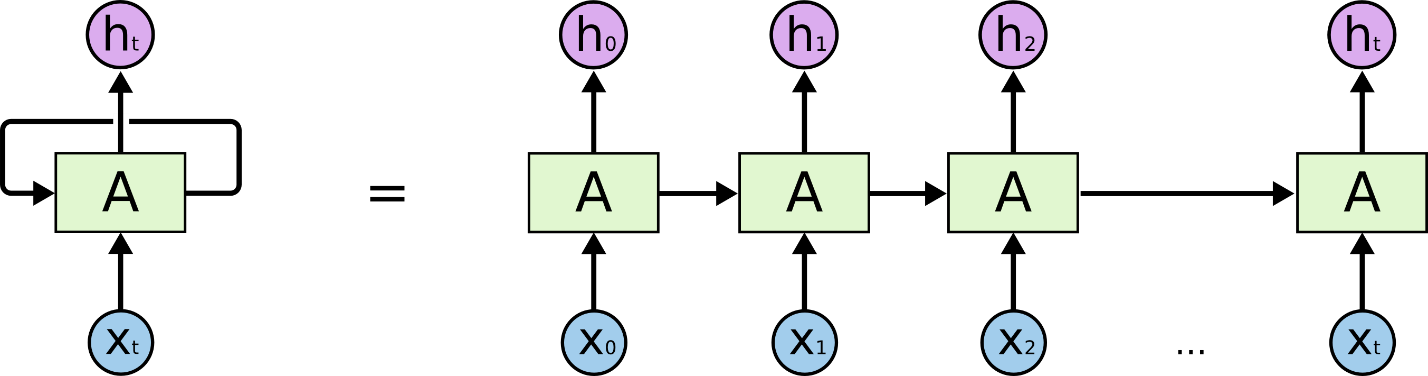 Рис. 1 Последовательность процессов в RNN сетях
Рис. 1 Последовательность процессов в RNN сетяхОна означает, что долгосрочная информация должна последовательно пройти через все ячейки, прежде чем попасть в текущую обрабатываемую ячейку. Это означает, что ее можно легко повредить, многократно умножая на малые числа близкие к 0, что является причиной исчезновения градиента.
На помощь пришел модуль LSTM. Который сегодня можно рассматривать, как многошлюзовый переключатель, немного похожий на ResNet. Он может обходить блоки (модули) и таким образом помнить более длительные временные отрезки. Таким образом у LSTM есть способ устранить некоторые проблемы с исчезающим градиентом. Но не все.
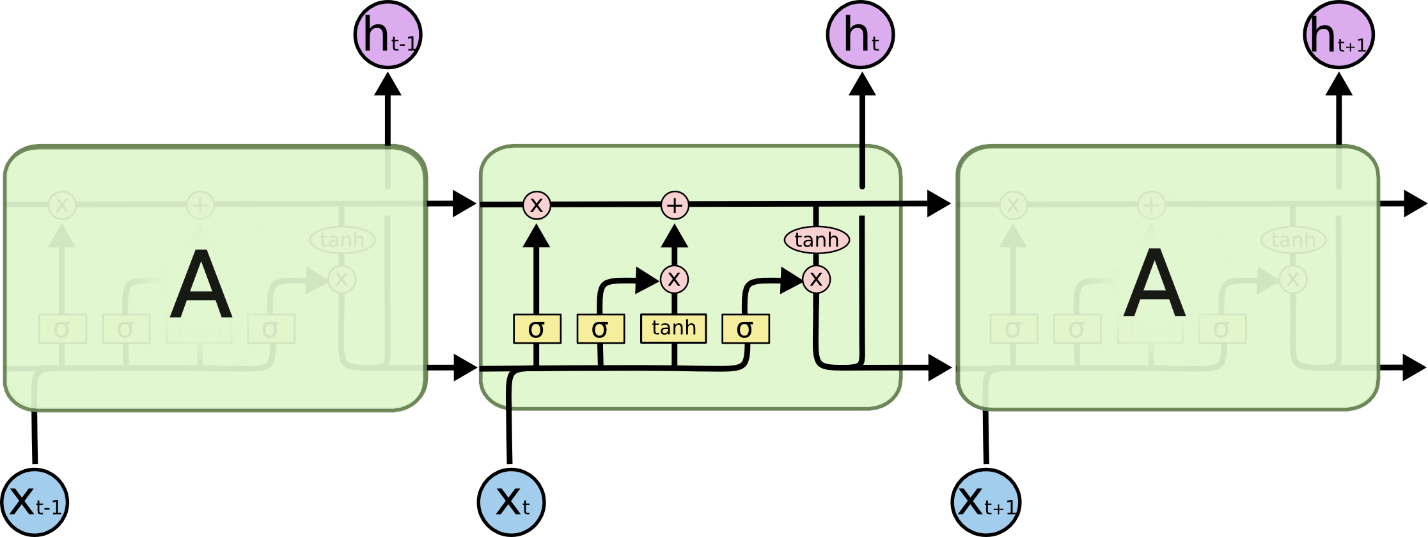 Рис. 2 Последовательность процессов в LSTM
Рис. 2 Последовательность процессов в LSTM У нас есть последовательный путь от старых ячеек к текущей. Фактически, путь теперь еще более сложен, так как оброс добавочными и забытыми ветвями. Несомненно, LSTM, GRU и их производные могут оперировать намного более долгосрочной информацией! Но они могут помнить последовательности из сотен (100), а не из тысяч или десятков тысяч.
И еще одна проблема RNN сетей заключается в том, что они очень требовательны к оборудованию. Требуют много ресурсов, как для обучения (это значит мы не можем обучить их быстро), так и для запуска. Для моделей основанных на RNN в облаке требуется много ресурсов. Учитывая, что потребность в преобразовании речи в текст быстро растет, а облако не масштабируется, нам потребуется производить обработку прямо на Amazon Echo!
Что нам делать?
На сентябрь 2018 г я бы настойчиво рекомендовал бы рассмотреть этот подход — Постоянное внимание (Pervasive Attention)
Это 2D свёрточная нейронная сеть, которая может превзойти как модели RNN/LSTM, так и модели на основе Attention, такие как Transformer
Метод Transformer был отличным решением с 2017 года до статьи, ссылка на которую дана выше. Как уже говорилось ранее, он дает большие преимущества по ряду параметров.
В качестве альтернативы: если последовательной обработки следует избегать, мы можем найти блоки данных, которые «смотрят вперед» или, лучше сказать «оглядываются назад», поскольку большую часть времени мы имеем дело с причинно-следственными данными в реальном времени (когда мы знаем прошлое и хотим повлиять на будущие решения) Другой случай, когда нам надо перевести предложение или проанализировать видео, у нас есть все данные и мы можем размышлять над ними больше времени. Такие блоки, смотрящие вперед/назад являются модулями нейронного внимания.
На помощь приходит «иерархический нейронный кодировщик внимания», объединяющий несколько модулей нейронного внимания, показанный на рисунке ниже:
 Рис. 3 Иерархический нейронный кодировщик внимани
Рис. 3 Иерархический нейронный кодировщик вниманиЛучший способ заглянуть в прошлое — использовать модули внимания, чтобы суммировать все прошлые закодированные вектора в контекстный вектор Ct
Обратите внимание, что здесь есть иерархия модулей внимания, очень похожая на иерархию нейронных сетей. Это также похоже на временную свёрточную сеть (TCN), описанную в примечании 3 ниже.
В иерархическом нейронном кодировщике множество слоев «Внимания» могут смотреть на небольшую часть недавнего прошлого, скажем 100 векторов, в то время как слои выше могут смотреть на эти 100 модулей «внимания» смотрящие на эти 100 векторов. Эффективно интегрируя информацию 100×100 векторов. Это расширяет возможности иерархического кодировщика нейронного внимания до 10 000 прошлых векторов.
Это способ заглянуть глубже в прошлое, чтобы эффективнее влиять на будущее.
Но что еще более важно, взгляните на длину пути, необходимого на распространение вектора данных, поданного на вход сети: в иерархических сетях, он пропорционален логарифму N (log (N)), где N — количество уровней иерархии. Это контрастирует с шагами Т, которые должна выполнить RNN, где Т — максимальная длина запоминаемой последовательности. Как мы видимо T многократно больше N (T>>N)
Последовательности легче запомнить, если данные проходят через 3–4 слоя нежели чем через 100!
Эта архитектура похожа на нейронную машину Тьюринга, но позволяет нейронной сети решать, какую информацию считывать из памяти посредством «внимания». Это означает, что реальная нейронная сеть будет решать, какие вектора из прошлого важны для будущих решений.
Но как на счет объема памяти? Вышеупомянутая архитектура сохраняет все предыдущие данные в памяти, в отличии от нейронной машины Тьюринга. Это, кажется, не очень эффективным: представьте, что мы будем хранить данные о каждом кадре в видео — в большинстве случаев вектор данных не меняется от кадра к кадру, поэтому мы будем хранить слишком много данных об одном и том же. Что мы можем сделать, так это добавить еще один модуль, чтобы предотвратить сохранение коррелированных данных. Например, не запоминать вектора слишком похожие на ранее запомненные. Но это реально геморрой, лучше всего позволить нейросети самой решить, какие вектора запоминать, а какие нет.
В итоге — забудьте о RNN и вариантах. Используйте Attention. Внимание, — действительно всё, что вам нужно!
Дополнительная информация
О тренировке RNN\LSTM: RNN и LSTM сложно обучить, потому что они требуют вычислений с ограничением полосы пропускания памяти, что является худшим кошмаром для разработчика оборудования и в конечном итоге ограничивает применимость решений на основе таких нейронных сетей. Короче говоря, LSTM требует 4 линейных слоя (слой MLP) на ячейку для работы на каждом временном шаге последовательности. Для вычисления линейных слоев требуется большая пропускная способность памяти, фактически они не могут часто использовать много вычислительных единиц, потому что системе не хватает пропускной способности памяти для питания вычислительных единиц. И легко добавить больше вычислительных блоков, но сложно добавить больше пропускной способности памяти (обратите внимание на достаточное количество строк на микросхеме, длинные провода от процессора к памяти и т. Д.). В результате RNN / LSTM и их варианты не подходят для аппаратного ускорения, и мы говорили об этой проблеме раньше здесь и здесь. Решение будет вычисляться в устройствах памяти, подобных тем, над которыми мы работаем в FWDNXT.
Примечание
1: Иерархическое нейронное внимание похоже на идеи в WaveNet. Но вместо свёрточной нейронной сети мы используем иерархические модули внимания. Также: иерархическое нейронное внимание может быть двунаправленным.
2: RNN и LSTM — это проблемы с ограниченной пропускной способностью памяти (подробности см. Здесь). Блоку (ам) обработки требуется столько пропускной способности памяти, сколько операций / с они могут обеспечить, что делает невозможным их полное использование! Внешней пропускной способности никогда не будет достаточно, и способ немного решить проблему — использовать внутренние быстрые кеши с высокой пропускной способностью. Наилучший способ — использовать методы, которые не требуют перемещения большого количества параметров из памяти взад и вперед или которые могут быть повторно использованы для многократных вычислений на каждый передаваемый байт (высокая арифметическая интенсивность).
3: вот статья, в которой CNN сравнивается с RNN. Временная сверточная сеть (TCN) «превосходит канонические рекуррентные сети, такие как LSTM, в разнообразном диапазоне задач и наборов данных, демонстрируя при этом более эффективную память».
4: С этой темой связан тот факт, что мы мало знаем о том, как наш человеческий мозг учится и запоминает последовательности. «Мы часто изучаем и запоминаем длинные последовательности в более мелких сегментах, например, телефонный номер 858 534 22 30, запоминаемый в виде четырех сегментов. Поведенческие эксперименты предполагают, что люди и некоторые животные используют эту стратегию разбиения когнитивных или поведенческих последовательностей на фрагменты для решения широкого круга задач »- эти фрагменты напоминают мне небольшие свёрточные сети или сети, подобные «Вниманию» (Attention), на более мелких последовательностях, которые затем иерархически связаны друг с другом, как в иерархическом кодировщике нейронного внимания и временной сверточной сети (TCN). Дополнительные исследования заставляют меня думать, что рабочая память похожа на сети RNN, которые используют рекуррентные реальные нейронные сети, и их емкость очень мала. С другой стороны, кора и гиппокамп дают нам возможность запоминать действительно длинные последовательности шагов (например, где я припарковал свою машину в аэропорту 5 дней назад), предполагая, что может быть задействовано больше параллельных путей для запоминания длинных последовательностей, где механизм внимания блокирует важные фрагменты и форсирует прыжки в частях последовательности, которые не имеют отношения к конечной цели или задаче.
5: Приведенные выше свидетельства показывают, что мы не читаем последовательно, фактически мы интерпретируем символы, слова и предложения как группу. Основанный на «внимании» или свёрточный модуль воспринимает последовательность и проецирует представление в нашем сознании. Мы не ошиблись бы в этом, если бы обрабатывали эту информацию последовательно! Остановимся и заметим нестыковки!
6: Недавняя статья показывающая обучение без использования методов Attention или Transformer, показала удивительную эффективность в обучении без учителя. VGG или NLP? Эта работа также является продолжением новаторской работы Джереми и Себастьяна, где LSTM со специальными процедурами обучения смог научиться без учителя предсказывать следующее слово в последовательности текста, а затем также мог передавать эти знания новым задачам. Здесь приводится сравнение эффективности LSTM и Transformer (на основе внимания), которое показывает, что внимание обычно побеждает, и что «обычный LSTM превосходит Transformer на наборе данных — MRPC »
7: Здесь вы можете найти отличное объяснение архитектуры Transformer и потока данных!
