OOX 2.0: Out of Order eXecution made easy
As Intel Threading Building Blocks (TBB) is being refreshed using new C++ standard, deprecating tbb: task interface, the need for high-level tasking interface becomes more obvious. In this article, I«m proposing yet another way of defining what a high-level parallel task programming model can look like in modern C++. I created it in 2014 and it was my last contribution to TBB project as its core developer after 9 wonderful years of working there. However, this proposal has not been used in production yet, so a new discussion might help it to be finally adopted.
Motivation
According to the customer feedback, the nested blocking programming model used in TBB can cause deadlocks if a program uses parallel algorithms with locks in user functions. It can be worked-around using tbb: task_arena by preventing work mixing but it is not an efficient approach. And there is no good way to solve the latency problem: one outermost task can stuck until another outermost task of a high-level algorithm completes. It can be approached in different ways, e.g. using stack-switching (co-routines) or just replacing a blocked thread by a new one, or preventing the task stealing using tbb: this_task_arena: isolate (). This article explores a purely semantical way out of these issues avoiding the burden of additional restrictions, complexity, or resources in the scheduler since on the low-level, it is all still possible via now deprecated tbb: task interface.
Design forces
Main idea
A solution for the nested blocking issue requires to interrupt current execution scope either by switching to new stack/thread (scheduler way) or by terminating and splitting the scope into parts running as a sequence of continuations (semantical way). The latter leads to additional complexity of dealing with variables which go out of scope, e.g. consider this example with blocking style:
int result = parallel_reduce(...);
post_process(result);If we want parallel_reduce not to block, we need to split this into two tasks (by lines) with separate scopes. But how to deal with the `result` then? The concept of `future` seems to be the closest approach to this and C++11 provides std: async (), which returns std: future as a result of the user’s functor:
future result = std::async(parallel_reduce, ...);
std::async(post_process, result); Now, how to connect the tasks into as a sequence? std: future is blocking. However, this example demonstrates that the most native way to express dependencies is to follow the function arguments: second task waits for the result of the first one. We just need to extend ideas of std: future and std: async to cover our needs.
Meanwhile, let’s consider the weakness of C++11 async constructs using the following example:
future Fib(int n) {
// error: no implicit conversion
if(n < 2) return n;
// error: no conversion from 'std::future >' to 'std::future’
future &&left = async(Fib, n-1);
future &&right = async(Fib, n-2);
return async([](future &&l, future &&r) -> int {
return l.get() + r.get(); // it blocks
}, std::move(left), std::move(right));
} In order to support recursions like this for continuation-style tasking, we need:
— direct initialization of a 'future' variable by a value (optionally)
— collapse template recursion of a 'future' variables
— build task dependencies based on 'future' arguments instead of blocking
— unpack 'future' types into plain types before calling user functor
The result can be as beautiful and concise as the following:
oox_var Fib(int n) {
if(n < 2) return n;
return oox_run(std::plus(), oox_run(Fib, n-1), oox_run(Fib, n-2) );
} Where:
oox_var
oox_var
All these requires tasking with multi-continuations and dynamic dependencies just as in the initial OOX (Out of Order eXecution) proposal by Arch Robison. Thus the `oox_` prefix and the second version.
Static Dependencies
OOX implementation enables automatic deduction for write-after-write («output»), write-after-read («anti»), and read-after-write («flow») dependencies. This new interface approach provides a way to enumerate all the prerequisites in arguments and identify theirs properties such as:
read-write — l-value reference &
final-write — r-value reference &&
read-only — const reference &, value
copy-only — value
Thus, each oox_run task knows which oox_var can be modified, which has only to be read, and which can be just copied thus unlocking more potential parallelism with write-after-read dependent tasks. It allows to build complete task dependency graph without additional specifications beside oox_run () arguments for the case of fixed number of tasks since the number of arguments is compile-time decision:
oox_var a, b, c;
oox_run( [](T&A) { A=f(); }, a);
oox_run( [](T&B) { B=g(); }, b);
oox_run( [](T&C) { C=h(); }, c);
oox_run( [](T&A, T B) { A+=B; }, a, b);
oox_run( [](T&B, T C) { B+=C; }, b, c);
oox_wait_for_all(b); // this thread joins computation 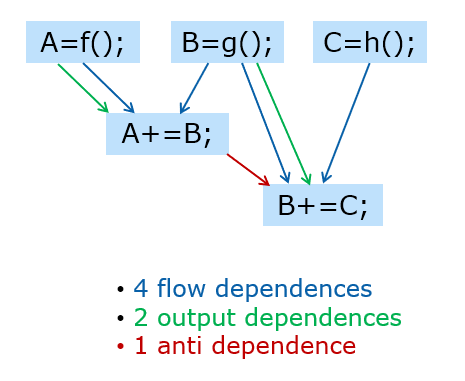
To sum up, there are two big design ideas behind OOX 2.0:
1. Abstract user functor from task dependencies
2. Reuse functor argument types for task dependency types specification
Users make their best effort to specify the minimally necessary access types and OOX extracts as much parallelism as possible in response.
Function and arguments types match
There are two options for the way of passing arguments to oox_run and receiving them in the user functor.
Match oox_run arguments to functor arguments. It means if the functor receives by lv-reference, it will be stored as a reference and it will be user responsibility for the lifetime of the referred object. However, if the functor receives const-reference, what to choose? copy the argument or keep as a reference? If it passed to oox_run as rv-reference, it surely has to be a copy.
The standard uses a different way. You can choose to pass reference and take responsibility for its object lifetime, but it has to be done explicitly via std: ref (), std: cref (), and std: reference_wrapper<>. Otherwise everything is passed by value.
Since semantics of oox_run arises from similarity with std: async and std: thread, it looks natural to assume the same rules for argument passing in case they are not oox_var, i.e. cplusplus.com says the following:
Their types shall be move-constructible. If Fn is a member pointer, the first argument shall be an object for which that member is defined (or a reference, or a pointer to it). The function uses decay copiesof these arguments. Fn and Args… are template parameters: if implicitly deduced, these are the proper lvalue or rvalue reference types of the arguments. Note though, that the function uses decay copiesof fn and args… (see std: ref for a wrapper class that makes references copyable).
Now, what to do with oox_var<> arguments? They differ from plain types because they guarantee lifetime and access synchronization. Following the same logic of unification and taking into account that access to oox_var<> content is synchronized by dependency graph build by oox_run (), we can claim that arguments referred as oox_var<> are always stored by reference. It does not make much sense to always store arguments by value, since it kills half of use cases where oox_var<> is used as a synchronization point when a writer waits for readers. On the other hand, when user functor takes an argument by value, it is not visible to user whether a task stores it by value or by reference to the oox_var storage. The former enables task graph optimization opportunity when the producer can copy the argument to the consumer task and proceed to the next write immediately, without depending upon finishing of the consumer task. See note //1 below.
But when an oox argument is stored and passed by lv-reference, a visible difference with a plain type can arise for oox_var<> passed by r-value reference: oox_run(f, move(my_var));It can prevent the optimization for functors f (T) and f (T&&) which works fine for non-oox types. Thus, arguments passed as oox_var&& have to be moved into the user functor instead of just passing as lv-reference as for other cases. See note //2 below.
The following table summarizes the observations above and couples it with dependency arcs types formed for the task graph as explained below (and please note that this complexity is rather implementation writer’s headache, not users'):
Stage | oox arg \ functor arg: | f (T) | f (T&) | f (const T&) | f (T&&) |
pack | var &a | A s (*a.p) //1 | A& r (*a.p) | A& r (*a.p) | A s (*a.p) //2 |
arc | var &a | copy-only //1 | read-write | read-only | copy-only //2 |
use | var &a | f (move (s)) //1 | f® | f ((constA&)r) | f (move (s)) //2 |
pack | const var &a | A s (*a.p) //1 | #Error | A& r (*a.p) | A s (*a.p) //2 |
arc | const var &a | copy-only //1 | #Error | read-only | copy-only //2 |
use | const var &a | f (move (s)) //1 | #Error | f ((constA&)r) | f (move (s)) //2 |
pack | var &&a | A& r (*a.p) | #Error | A& r (*a.p) | A& r (*a.p) |
arc | var &&a | final-write | #Error | final-write | final-write |
use | var &&a | f (move®) //3 | #Error | f (move®) //3 | f (move®) //3 |
1. True for an copy-optimized implementation, in a read-only version, it is just the same as for const ref.
2. True for an copy-optimized implementation, in a read-only version, it is f (A (*a.p)).
3. The lifetime of oox_var is over and its stored value can be moved in order to repeat plain type behavior.
read-write — the value is exclusively owned by a single producer task which can modify it. It unlocks all the pending shared consumers to be scheduled for execution.
final-write — there is no consumers or next producers for this read-write task — useful for optimizations.
read-only — the value can be simultaneously shared between concurrent tasks which start after the producer task finishes and which prevent the next producer from being executed until all consumers finish.
copy-only — producer copies the value to this consumer and does not depend upon its completion.
Consistency
One of the basic design principle for oox_var is that its usage should be implicit/transparent for the user functor perhaps following std: reference_wrapper<> notion. It is also motivated by recursive algorithms where oox_run for the same functor can take oox_var to build dependency graph or direct parameter on the leaf nodes. It is seamless for a functor taking by value (T) or by rv-reference (T&&):
// setup
void f(int by_value, string && by_rv_reference);
// for plain types
int i = 0; const int &j = i; string s = "plain";
oox_run(f, 1, string("temporary"));
oox_run(f, i, s); oox_run(f, j, move(s));
// for oox variables
oox_var oi = 0; oox_var os = string("managed");
oox_run(f, oi, move(os)); As for const-reference (const T& and lv-reference (T&), the std::reference_wrapper<>has to be used for plain types, and oox_var<> looks like a similar concept. This similarity also asks for std: ref-like function, which makes oox_var<> for the given variable. Unlike std::refwhere a user assumes the lifetime responsibility, 'oox_ref' has to either copy or move the content. The idea is to take a variable by its name (without a type) and detach it from current scope prolonging its lifetime. E.g.:
// setup
void f(int & by_ref, const string & by_cref);
int i = 0; const int &j = i; string s = "plain";
// for plain types
auto ri = std::ref(i); auto crs = std::cref(s);
oox_run(f, ri, crs);
// for oox_vars
auto oi = oox_make_copy(i); auto os = oox_make_move(s);
oox_run(f, oi, os);Stored types
Following the same rules described above (oox tasks store plain types by value and oox_var usage has to be indifferent from plain type), it is easy to come to the following type storage rule:
1. oox_run () return oox_var<> for decay type of functor return type, copy- or move-initialized.
2. oox_var<> doesn’t store references. Use reference_wrapper or pointer types instead.
3. Although, oox_var
4. Don’t compile oox_varif not is_same
Dynamic Dependencies
The simplest approach to dynamic number of tasks is to build a chain of small tasks, which are also dependent upon bigger parallel tasks:
oox_var disk_usage(INode& node) {
if (node.is_file())
return node.size();
oox_var sum = 0;
for (auto &subnode : node)
oox_run([](size_t &sm, // serialized on write operation
size_t sz) {
sm += sz;
}, sum,
oox_run(disk_usage, std::ref(subnode))); // parallel recursive leaves
return sum;
} It also enables linearization and deterministic reduction.
If such a serialization is not an option, anti-dependence trick can be used:
oox_var disk_usage(INode& node) {
if (node.is_file())
return node.size();
typedef tbb::concurrent_vector cv_t;
typedef cv_t *cv_ptr_t;
oox_var resv = new cv_t;
for (auto &subnode : node)
oox_run([](const cv_ptr_t &v, // make it read-only (not copyable) and thus parallel
size_t s){ v->push_back(s); },
resv, oox_run(disk_usage, std::ref(subnode)));
return oox_run([](cv_ptr_t &v) { // make it read-write to induce anti-dependence
// from the above read-only tasks
size_t res = std::accumulate(v->begin(), v->end(), 0);
delete v; v = nullptr; // release memory, reset the pointer
return res;
}, resv);
} This might be enough for a minimal set of OOX features. Though, additional extensions might be useful to improve usability of this case:
oox_var_ptroox_varbut disables copy-and-release optimization
oox_node — base of oox_var or same as oox_var
ox_node oox_join (oox_node… begin)
oox_node oox_join (Iter
oox_var<> oox_run (oox_node, Func, args…) — same as simple oox_run(Func, args...)but additionally flow-dependent upon the oox_node.
Integration with parallel algorithms
Now, when the problem of passing results between continuation tasks is solved, let’s return to the nested blocking issue. This is how to avoid it:
tbb::parallel_for(0, N, [](int i)->auto {
mutex.lock();
oox_node dep = parallel_for(0, M, Body);
return oox_run(dep, []{ // runs possibly on
mutex.unlock(); // different thread
});
});And this is how to avoid the performance implication issues:
tbb::parallel_for(0, N, [](int i)->auto {
oox_node dep = parallel_for(0, M, Body1);
return oox_run(dep, []()->oox_node {
return parallel_for(0, M, Body2);
});
});This is enabled by the following rules and constructs:
sync_var
— wait_for_all () in destructor:-(
— operator T (): implicitly waits for the value
private constructors: not user-manageable.
oox_var
sync_var
sync_var
Note that it is impossible to implement `oox_run (parallel_for, 0, M, Body)` form because overload resolution cannot be used for functor type deduction.
Storage Considerations
Since oox_var<> is passed between tasks and can go out of scope before a task finishes working with its value, it needs a separate storage. I.e. oox_var<> is always a pointer. And there are two ways to implement it:
separate storage
It’s straightforward but it requires additional allocation in oox_run () returning an oox_var. Besides, it becomes too close to notion of shared_ptr and probably should be better integrated with it.
embed into writing task
each writing task moves the var inside itself from the previous location before modification and keeps it while someone references it. This reduces the number of allocations for oox_run () with a return value but
requires a move or copy constructor for the user type and gives no guarantee of the same location for stored variable.
embed into initiating task
a task executing oox_run functor contains a storage for its return value. But it keeps the whole task object, which has produced this value, allocated.
There are more tricks and variations for how to optimize storage and execution of oox tasks, e.g. use NRVO+TLS trick to pass hidden execution context, introduce async_var for building more optimized graph of tasks thanks to deferred parallelism, etc. but this article is long enough already, so, let’s stop here.
Instead of conclusion
There is a Proof of Concept implementation proving these ideas feasible. However unfortunately, nobody is brave and unoccupied enough to move these ideas into production (it can be any project, not necessary TBB for which it was initially designed). However, if more and more people are interested in this type of user interface and giving feedback, there will be a greater chance of seeing it eventually working for people. Please write me if you are interested.
Instead of P.S.: more examples
MergeSort
template
oox_node mergesort(RAIter begin_it, RAIter end_it)
{
size_t const base_case_bound = 50;
if (end_it - begin_it < 2)
return;
if (end_it - begin_it < base_case_bound) {
for (RAIter it = begin_it + 1; it < end_it; ++it)
for (RAIter mentor = it; mentor > begin_it && *mentor < *(mentor - 1); --mentor)
std::iter_swap(mentor, mentor - 1);
return oox_node();
}
RAIter middle_it = begin_it + (end_it - begin_it) / 2;
auto left = oox_run(mergesort, begin_it, middle_it);
auto right= oox_run(mergesort, middle_it, end_it);
return oox_run( oox_join(left, right), [=] { std::inplace_merge(begin_it, middle_it, end_it) });
} Quicksort
template
oox_node quicksort(RAIter begin_it, RAIter end_it)
{
size_t const base_case_bound = 350;
if (end_it - begin_it < base_case_bound) {
for (RAIter it = begin_it + 1; it < end_it; ++it)
for (RAIter mentor = it; mentor > begin_it && *mentor < *(mentor - 1); --mentor)
std::iter_swap(mentor, mentor - 1);
return oox_node();
}
typedef typename std::iterator_traits::value_type Value;
std::iter_swap(begin_it, begin_it + (end_it - begin_it) / 2);
Value const &pivot = *begin_it;
RAIter greater_or_equal_begin = std::partition(begin_it + 1, end_it, [&pivot](Value const &value) { return value < pivot; });
RAIter less_end = greater_or_equal_begin - 1;
std::iter_swap(begin_it, less_end);
return oox_join( oox_run(quicksort, begin_it, less_end), oox_run(quicksort, greater_or_equal_begin, end_it) );
} NBody
template class T>
oox_node nbody(T const &triangle, std::vector &forces, divconq_range2d const &range)
{
size_t const base_case_bound = 180;
if (range.rows().end() <= range.cols().begin()) {
return;
}
if (range.rows().end() - range.rows().begin() < base_case_bound) {
for (size_t i = range.rows().begin(); i < range.rows().end(); ++i)
for (size_t j = range.cols().begin(); j < std::min(range.cols().end(), i); ++j) {
A const &term = triangle.at(i - 1, j);
forces[i] += term;
forces[j] -= term;
}
return oox_node();
}
auto self = static_cast const &, std::vector &, divconq_range2d const &)>(&nbody);
auto subtask = std::bind(self, std::ref(triangle), std::ref(forces), std::placeholders::_1);
auto d=oox_join( oox_run(subtask, range.a11()), oox_run(subtask, range.a22()) );
return oox_join( oox_run(d, subtask, range.a12()), oox_run(v, subtask, range.a21()) );
} Wavefront
void Serial_LCS( const char* x, size_t xlen, const char* y, size_t ylen )
{
int F[MAX_LEN+1][MAX_LEN+1];
for( size_t i=1; i<=xlen; ++i )
for( size_t j=1; j<=ylen; ++j )
F[i][j] = x[i-1]==y[j-1] ? F[i-1][j-1]+1 : max(F[i][j-1],F[i-1][j]);
}
void Straight_LCS( const char* x, size_t xlen, const char* y, size_t ylen )
{
oox_var F[MAX_LEN+1][MAX_LEN+1];
auto f = [x,y,xlen,ylen](int F11, int F01, int F10) {
return x[i-1]==y[j-1] ? F11+1 : max(F01, F10);
};
for( size_t i=1; i<=xlen; ++i )
for( size_t j=1; j<=ylen; ++j )
F[i][j] = oox_run(f, i+j==0?0:F[i-1][j-1], j==0?0:F[i][j-1], i==0?0:F[i-1][j]);
int res = oox_get_and_wait(F[MAX_LEN][MAX_LEN]);
}
void RecursiveLCS( const char* x, size_t xlen, const char* y, size_t ylen ) {
struct RecursionBody {
int (*F)[MAX_LEN+1];
const char *X, *Y;
RecursionBody(int f[][MAX_LEN+1], const char* x, const char* y) : F(f), X(x), Y(y) {}
oox_node operator()(Range2D r) {
if( !r.is_divisible4() ) {
for( size_t i=r.rows().begin(), ie=r.rows().end(); i 