[Перевод] Объяснение легковесных потоков в 200 строк на Rust
Легковесные потоки (ligthweight threads, coroutines, корутины, green threads) являются очень мощным механизмом в современных языках программирования. В этой статье Carl Fredrik Samson попытался реализовать рантайм для легковесных потоков на Раст, попутно объясняя, как они устроены «под капотом».
Так же следует учесть, что статья не суперсвежая, так что для того, чтобы примеры заработали в современной ночной версии компилятора Раст, скорее всего понадобятся изменения, найти которые можно в репозитории кода для этой статьи.
Переводил для себя большей частью. Обо всех замечаниях пишите — оперативно исправлю. Старался переводить близко текста, но в некоторых местах переформулировал, чтобы читалось легче и было понятнее.
Green Threads
Грин треды решают общую проблему в программировании — вам не хочется, чтобы ваш код блокировал процессор, растрачивая ресурсы. Решается это использованием многозадачности, которая позволяет приостановить выполнение одного участка кода, запуская на выполнение другой, переключаясь между «контекстами».
Легко спутать с параллелизмом, но не делайте этого — это две совершенно разные вещи. Параллелизм — это как забрасывание проблемы вычислительными ресурсами. Грин треды позволяют работать умнее и эффективнее, эффективнее расходовать ресурсы.
Два способа реализовать их:
- вытесняющая многозадачность
- невытесняющая (кооперативная) многозадачность
Вытесняющая многозадачность
Некоторый внешний планировщик останавливает задачу и запускает другую перед тем, как переключиться обратно. В этом случае задача никак не может повлиять на ситуацию — решение принимается «чем-то» ещё (часто каким-либо планировщиком). Ядра используют это в операционных системах, например, позволяя в однопоточных системах вам использовать UI (User Interface — интерфейс пользователя) в то время, когда ЦПУ выполняет вычисления. Не будем останавливаться на этом типе многозадачности, но предполагаю, что поняв одну парадигму, вы без проблеме поймёте и вторую.
Невытесняющая многозадачность
О ней и поговорим сегодня. Задача сама решает, что процессору лучше бы заняться чем-то ещё вместо того, чтобы ждать, когда в текущей задаче что-то случится. Обычно это выполняется с помощью передачи контроля (yielding control) планировщику. Нормальным юз-кейсом является передача контроля, когда что-то блокирует выполнение кода. Например, это могут быть операции ввода/вывода. Когда контроль уступили центральному планировщику напрямую, процессор возобновляет выполнение другой задачи, которая готова делать что-то ещё, кроме как блокировать.
Предварительная информация
Это самая техническая часть статьи, но если вы на самом деле хотите понимать происходящее, то просто обязаны пробраться сквозь её дебри. Обещаю сделать это быстро и по делу, как только возможно. Достаточно быстро перейдём к коду.
Перво-наперво, мы будем взаимодействовать и управлять процессором напрямую. Это не очень переносимо, т.к. видов процессоров целая прорва. Идея всё та же самая, но мелкие детали реализации отличаются.
Сосредоточимся на одной из самых широко используемых архитектур — x86–64. В этой архитектуре процессор снабжён набором из 16 регистров:
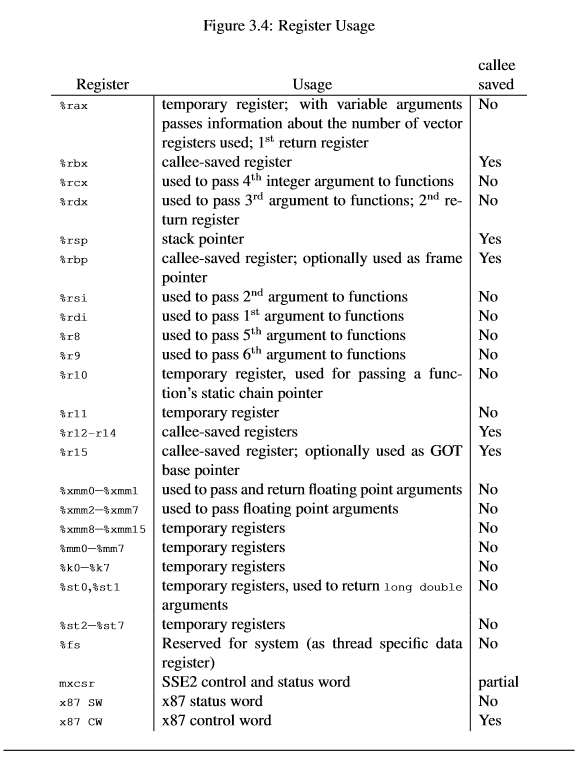
Если интересно, остальную часть спецификации можно найти здесь
Вне нашего интереса прямо сейчас регистры, помеченные как «callee saved». Это регистры, которые хранят контекст — следующую инструкцию для выполнения, указатель на базу, указатель на верхушку стека и т.д. Рассмотрим их чуть позже подробнее.
Если хотим указать управлять процессором напрямую, то нам нужно совсем немного кода на ассемблере. К счастью, для этого нужно знать совсем немного инструкций для нашего дела. Вот как перемещать значения из одного регистра в другой:
mov %rsp, %raxСупербыстрое введение в ассемблер
В первую очередь. Язык ассемблера не слишком переносимый. Каждый ЦПУ может иметь специальный набор инструкций, однако, некоторые (наборы инструкций) являются общими на большинстве десктопных машинах
Есть два популярных диалекта: AT&T и Интел.
Диалект AT&T является стандартным при использовании ассемблерных вставок на Rust. Но можно использовать и диалект от Интел, указав на это компилятору. По большей части Раст перекладывает работу с ассемблерными вставками на LLVM. Для LLVM он очень похож на синтаксис ассемблерных вставок Си, но не точно такой же.
В примерах будем использовать диалект AT&T.
Ассемблер имеет строгие гарантии обратной совместимости. Вот поэтому вы видите те же самые регистры, которые адресуют данные разными способами. Взглянем на регистр %rax, который мы использовали в примере выше:
%rax # 64 битный регистр (8 байт)
%eax # младшые 32 бита регистра "rax"
%ax # младшие 16 бит регистра "rax"
%ah # старшие 8 бит части "ax" регистра "rax"
%al # младшие 8 бит регистра "rax"+-----------------------------------------------------------------------+
|76543210 76543210 76543210 76543210 76543210 76543210 76543210 76543210|
+--------+--------+--------+--------+--------+--------+--------+--------+
| | | | | | | %ah | %al |
+--------+--------+--------+--------+--------+--------+--------+--------+
| | | | | | | %ax |
+--------+--------+--------+--------+--------+--------+-----------------+
| | | | | %eax |
+--------+--------+--------+--------+-----------------------------------+
| %rax |
+-----------------------------------------------------------------------+По сути, можно разглядеть историю эволюции процессоров. Так как большинство процессоров сейчас являются 64 битными, то будем использовать 64 битные регистры.
Указание размеров в «словах» в ассемблере обусловлено историческими причинами. Оно пошло из тех времён, когда у процессоров были шины данных в 16 бит, так что размер слова равен 16 битам. Это важно знать, т.к. в диалекте AT&T будете встречать множество инструкций с суффиксом q (quad-word — четверное слово) или l (long-word — длинное слово). Так что movq означает перемещение 4×16 бит = 64 бит.
Простая мнемоника mov будет использовать размер, заданный указанным регистром. Это стандартное поведение в диалекте AT&T.
Так же стоит обратить внимание на выравнивание стека по границе 16 байт в архитектуре x86–64. Просто стоит помнить об этом.
Пример, который мы будем собирать
В этом примере мы создадим свой собственный стек и заставим процессор вернуться из текущего контекста и перейти к использованию стеку, который мы создали.
Подготовка проекта
Начнём новый проект в каталоге с названием «green_threads». Запустите команду
cargo initИз-за того, что некоторые нужные нам возможности ещё не стабилизированы, будем использовать ночную версию Раст:
rustup override set nightlyВ файле main.rs начнём с установления флага, который позволит использовать макрос llvm_asm!:
#![feature(llvm_asm)]Установим небольшой размер стека, только 48 байт, так что можно будет лишь поглядеть на него да вывести перед переключением контекстов.
const SSIZE: isize = 48;Затем добавляем структуру, отражающую состояние процессора. Всё, что там сейчас нужно, так это лишь указатель на стек, так что сосредоточимся на регистре, который его хранит.
#[derive(Debug, Default)]
#[repr(C)]
struct ThreadContext {
rsp: u64,
}В дальнейших примерах мы будем использовать все регистры, помеченные как «callee saved» в документации, на которую ссылка была ранее. Эти регистры описаны в ABI x86–64. Но прямо сейчас обойдёмся лишь одним, заставив процессор перейти по нашему стеку.
Так же стоит заметить, что из-за обращения к данным из ассемблера, нужно указать #[repr(C)]. У Раста нет стабильного ABI, так что нет уверенности в том, что значение rsp будет занимать первые 8 байт. У Си же есть стабильный ABI, и именно его компилятор будет использовать при указании атрибута.
fn hello() -> ! {
println!("I LOVE WAKING UP ON A NEW STACK!");
loop {}
}Для очень простого примера определяем функцию, которые просто выводит сообщение, а потом запускает бесконечный цикл.
А следующим делом пишем ассемблерный код, который переключает нас на использование нашего собственного стека:
unsafe fn gt_switch(new: *const ThreadContext) {
llvm_asm!("
mov 0x00($0), %rsp
ret
"
:
: "r"(new)
:
: "alignstack" // пока работает без этого, но будет нужно позднее
);
}Здесь мы используем трюк. Мы пишем адрес функции, которую хотим запустить на нашем новом стеке. Затем мы передаём адрес первого байта, где мы сохранили этот адрес на регистр rsp (адрес в new.rsp будет указывать на адрес в нашем стеке, который ведёт к функции, указанной выше). Разобрались?
Ключевое слово ret передаёт контроль программе по адресу возврата, находящегося на вершине стека. Загрузив в регистр %rsp наш адрес, мы заставляем процессор думать, что это адрес, на который нужно будет вернуться из выполняемой в данный момент функции. Так что передав инструкцию ret, мы заставили процессор вернуться к выполнению задач в нашем собственном стеке.
И первое, что делает процессор, читает адрес нашей функции и запускает её.
Краткое введение в макрос для ассемблерных вставок
Если до этого вы ещё не использовали ассемблерные вставки, то он может вам показаться чужеродным. Мы будем использовать его расширенную версию чуть позже для переключения контекста. Объясню, что тут и как строка за строкой:
unsafe — ключевое слово, которое сообщает компилятору не использовать гарантии безопасности в функции, которую мы пишем. Так как мы управляем процессором напрямую, то это по определению небезопасно.
gt_switch(new: *const ThreadContext) — принимаем указатель на экземпляр структуры ThreadContext, из которой мы будем читать только одно поле.
llvm_asm!(" — макрос из стандартной библиотеки Раста. Он проверяет синтаксис и предоставляет сообщения об ошибках, если встречает что-то непохожее на валидный ассемблер диалекта AT&T (по-умолчанию).
Первое, что макрос принимает в качестве входных данных — ассемблер с шаблоном — mov 0x00($0), %rsp. Это простая инструкция, которая копирует значение, хранящееся по смещению 0×00 (в шестнадцатеричной системе; в данном случае оно нулевое) от позиции $0 в памяти, в регистр rsp. Регистр rsp хранит указатель на следующее значение в стеке. Мы перезаписываем значение, указывающее на верхушку стеку, на предоставленный адрес.
В нормальном ассемблерном коде вы не встретите $0. Это часть ассемблерного шаблона и означает первый параметр. Параметры нумеруются, как 0, 1, 2 и т.д., начиная с параметров output и двигаясь к параметрам input. У нас только один входной параметр, который соответствует $0.
Если встретите символ $ в ассемблере, то, скорее всего, он означает непосредственное значение (целочисленную константу), но это не всегда так (да, символ доллара может означать разные вещи в зависимости от диалекта ассемблера и в зависимости от того, ассемблер это x86 или x86–64).
ret — служебное слово, которое заставляет процессор вытолкнуть значение, содержащее адрес в памяти, из стека и безусловно перейти по нему. В результате, мы перехватили управление процессором и заставили его вернуться к нашему стеку.
output
:Ассемблерные вставки немного отличаются от обычного ассемблера. В них четыре дополнительных параметра, которые мы передаём после ассемблерного шаблона. Первый из них называется output, и в нём передаются выходные параметры, которые используются для возвращения значений в нашей функции.
input
: "r"(new)Второй параметр — это параметр input. Литерал "r" — это то, что при написании ассемблерных вставок называется ограничением (constraint). Можно использовать эти ограничения для инструктирования компилятора о решении, где размещать ваши входные параметры (например, в одном из регистров или где-то в памяти). "r" означает, что нужно разместить значение в регистре общего назначения по выбору компилятора. Ограничения в ассемблерных вставках — довольно обширная тема сама по себе, но, к счастью, нам слишком много и не нужно.
clobber list
:Следующая опция — clobber list — список, в котором указываются регистры, которые компилятор не должен трогать, и который позволяет ему сообщить, что мы хотим управлять ими в своём ассемблерном коде. Если мы хотим вытолкнуть из стека значения, то тут нужно указать, в какие регистры, и сообщить компилятору, что он не сможет спокойно распоряжаться ими. Ну, а т.к. мы просто возвращаемся к новому стеку, то тут нам ничего и не требуется указывать.
options
: "alignstack"И последний параметр — это опции. Для Раста они уникальные и мы можем задать три: alignstack, volatile и intel. Я просто оставлю ссылку на документацию, где объясняется их назначение. Для работы под Windows нам требуется указать опцию alignstack.
Запуск примера
fn main() {
let mut ctx = ThreadContext::default();
let mut stack = vec![0_u8; SSIZE as usize];
unsafe {
let stack_bottom = stack.as_mut_ptr().offset(SSIZE);
let sb_aligned = (stack_bottom as usize & !15) as *mut u8;
std::ptr::write(sb_aligned.offset(-16) as *mut u64, hello as u64);
ctx.rsp = sb_aligned.offset(-16) as u64;
gt_switch(&mut ctx);
}
}Это пример создания нашего нового стека. hello уже является указателем (на функцию), так что мы просто кастуем значение напрямую в u64, потому что все указатели на 64хбитных системах имеют такую длину, а потом записываем этот указатель в наш новый стек.
Чуть позже поговорим про стек подробнее, но сейчас уже нужно знать одну вещь — стек растёт вниз (в сторону младших адресов). Если 48 байтный стек начинается с индекса 0 и заканчивается индексом 47, индекс 32 будет находиться по смещению 16 байт от начала/базы нашего стека.
|0 1 2 3 4 |4 5
|0123456789 012345|6789 0123456789 01|23456789 01234567|89 0123456789
| | |XXXXXXXX |
| | | stack bottom
|0th byte |16th byte |32nd byteЗаметьте, что мы записали указатель по смещению в 16 байт от базы нашего стека (помните, что я писал про выравнивание по границе 16 байт?)
Что делает строкаlet sb_aligned = (stack_bottom as usize & !15) as *mut u8;? Когда мы запрашиваем память при созданииVec, нет гарантии, что она будет выравнена по границе 16 байт. Эта строка просто округляет адрес до ближайшего меньшего, кратного 16 байтам. Если он уже кратен, то ничего не делает.
Мы кастуем указатель так, чтобы он указывал на тип u64 вместо u8. Мы хотим записать данные наше значение u64 на позиции 32–39, которые как раз и составляют 8 байт места под него. Без этого приведения типов мы будем пытаться записать наше u64-значение только в позицию 32, а это не то, что мы хотим сделать.
В регистр rsp (Stack Pointer — указатель на стек) мы кладём адрес индекса 32 в нашем стеке. Мы не передаём само u64-значение, которое там хранится, а только адрес на первый байт этого значения.
Когда мы выполняем команду cargo run, то получаем:
dau@dau-work-pc:~/Projects/rust-programming-book/green_threads/green_threads$ cargo run
Compiling green_threads v0.1.0 (/home/dau/Projects/rust-programming-book/green_threads/green_threads)
Finished dev [unoptimized + debuginfo] target(s) in 0.44s
Running `target/debug/green_threads`
I LOVE WAKING UP ON A NEW STACK!Так что же происходит? Мы не вызываем функцию hello ни в каком виде, но она всё равно запускается. Происходит следующее: мы заставляем процессор перейти на работу с нашим собственным стеком и выполнить код. Мы сделали первый шаг к реализации переключения контекста.
Стек
Это очень важно знать. У компьютера есть только память. Нет специальной «стековой» или «памяти для кучи» — это всё части одной и той же памяти.
Разница в том, как осуществляется доступ к этой памяти и как она используется. Стек поддерживает простые операции заталкивания и выталкивания (push/pop) в непрерывном участке памяти, что и делает его быстрым. Память в куче выделяется аллокатором по запросу и может быть разбросана.
Не будем погружаться в различия между стеком и кучей — есть множество статей, где это описано, включая главу в Rust Programming Language.
Как выглядит стек
Начнём с упрощённого представления стека. 64 битные процессоры читают по 8 байт за раз. В примере выше, даже представив стек в виде длинной строки из значений типаu8, передавая указатель, нам нужно быть уверенными, что он указывает на адрес 000, 0008 или 0016.
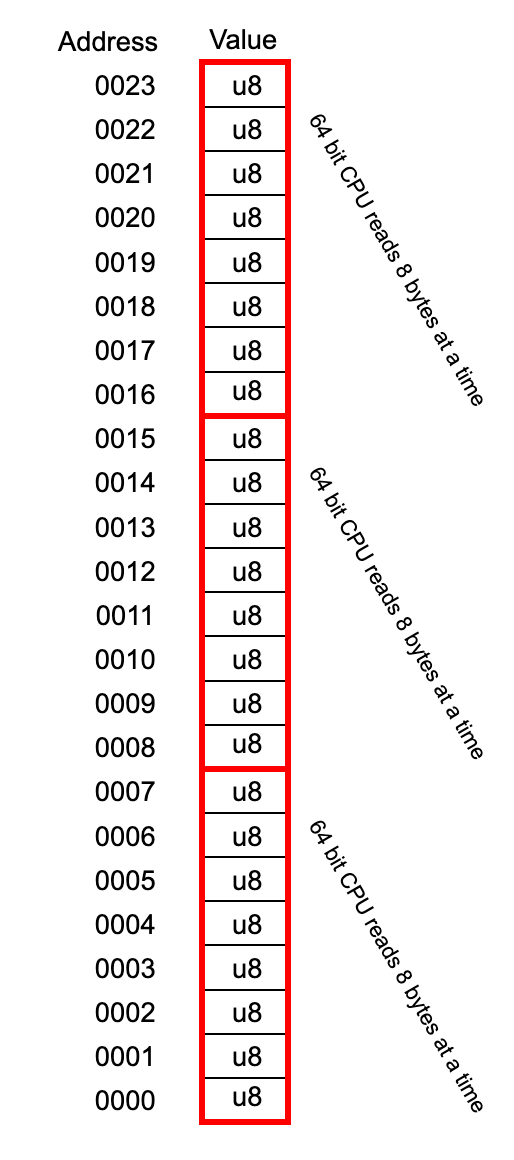
Стек растёт вниз, так что мы начинаем сверху и спускаемся ниже.
Когда мы помещаем в stack pointer указатель на стек, выровненный по границе 16 байт, мы нужно быть уверенными, что адрес, на который он указывает, кратен 16 (считая от начала стека — прим). В примере выше, единственным адресом, удовлетворяющим условию, является адрес 0008 (помните, что стек начинается сверху).
Если мы добавим следующие строки в код нашего примера перед переключением (перед вызовом gt_switch), мы увидим содержимое нашего стека.
Прим: код изменён — добавлен вывод адреса функции hello, значения в ячейках выводятся в шестнадцатеричной системе, добавлен вывод пустых строк для группировки и удобочитаемости.
print!(
"hello func address: 0x{addr:016X} ({addr})\n\n",
addr = hello as usize
);
for i in (0..SSIZE).rev() {
print!(
"mem: {}, value: 0x{:02X}\n{}",
stack.as_ptr().offset(i as isize) as usize,
*stack.as_ptr().offset(i as isize),
if i % 8 == 0 { "\n" } else { "" }
);
}Вот примерно такой вывод будет:
hello func address: 0x0000560CD80B50B0 (94613164216496)
mem: 94613168839439, value: 0x00
mem: 94613168839438, value: 0x00
mem: 94613168839437, value: 0x00
mem: 94613168839436, value: 0x00
mem: 94613168839435, value: 0x00
mem: 94613168839434, value: 0x00
mem: 94613168839433, value: 0x00
mem: 94613168839432, value: 0x00
mem: 94613168839431, value: 0x00
mem: 94613168839430, value: 0x00
mem: 94613168839429, value: 0x56
mem: 94613168839428, value: 0x0C
mem: 94613168839427, value: 0xD8
mem: 94613168839426, value: 0x0B
mem: 94613168839425, value: 0x50
mem: 94613168839424, value: 0xB0
mem: 94613168839423, value: 0x00
mem: 94613168839422, value: 0x00
mem: 94613168839421, value: 0x00
mem: 94613168839420, value: 0x00
mem: 94613168839419, value: 0x00
mem: 94613168839418, value: 0x00
mem: 94613168839417, value: 0x00
mem: 94613168839416, value: 0x00
mem: 94613168839415, value: 0x00
mem: 94613168839414, value: 0x00
mem: 94613168839413, value: 0x00
mem: 94613168839412, value: 0x00
mem: 94613168839411, value: 0x00
mem: 94613168839410, value: 0x00
mem: 94613168839409, value: 0x00
mem: 94613168839408, value: 0x00
mem: 94613168839407, value: 0x00
mem: 94613168839406, value: 0x00
mem: 94613168839405, value: 0x00
mem: 94613168839404, value: 0x00
mem: 94613168839403, value: 0x00
mem: 94613168839402, value: 0x00
mem: 94613168839401, value: 0x00
mem: 94613168839400, value: 0x00
mem: 94613168839399, value: 0x00
mem: 94613168839398, value: 0x00
mem: 94613168839397, value: 0x00
mem: 94613168839396, value: 0x00
mem: 94613168839395, value: 0x00
mem: 94613168839394, value: 0x00
mem: 94613168839393, value: 0x00
mem: 94613168839392, value: 0x00
I LOVE WAKING UP ON A NEW STACK!Я вывел адреса в памяти в виде значений u64, чтобы было легче в них разобраться, если вы не очень знакомы с шестнадцатеричной системой исчисления (что вряд ли — прим.).
Первое, что заметно, так это то, что это непрерывный участок памяти, который начинается с адреса 94613168839392 и заканчивается адресом 94613168839439.
Адреса с 94613168839424 по 94613168839431 включительно представляют для нас особый интерес. Первый адрес — это первый адрес нашего stack pointer, значения, которое мы записываем в регистр %rsp%. Диапазон представляет собой значения, которые мы пишем в стек перед переключением. (прим — коряво и сомнительно!!!)
Ну, а сами значения 0xB0, 0x50, 0x0B, 0xD8, 0x0C, 0x56, 0x00, 0x00 — это указатель (адрес в памяти) на функцию hello(), записанный в виде значений u8.
По мере того, как мы будем писать более сложные функции, нашего крайне скудного 48 байтного стека скоро перестанет хватать, вы увидите, как функции запускаются, а код инструктирует процессор заталкивать и выталкивать значения из нашего стека при выполнении программы.
Размеры стека
Когда вы запускаете процесс в большинстве современных операционных системах, стандартный размер стека обычно составляет 8 Мб, но может быть сконфигурирован и другой размер. Этого хватает для большинства программ, но на плечах программиста убедиться, что не используется больше, чем есть. Это и есть причина пресловутого «переполнения стека» (stack overflow), с которым многие из нас сталкивались.
Однако, когда мы сами управляем стеками, мы можем выбирать для них размер. 8 Мб для каждого контекста определённо больше, чем нам требуется при выполнении простых функций, например, в веб-сервере. Таким образом, уменьшив размер стека мы сможем держать миллионы легковесных потоков запущенными на машине, в то время, как при использовании стеков, предоставляемых операционной системой, мы очень скоро столкнёмся с нехваткой памяти.
Расширяемые стеки
Некоторые реализации используют расширяемые (growable — способные расти) стеки. При этом выделяется небольшой объём памяти, достаточный для большинства задач. Но при его перерасходе, вместо переполнения стека, происходит выделение памяти большего объёма под новый стек, в который переносится всё из старого, после чего выполнение программы возобновляется.
Примером такой стратегии является реализация в языке Go. Работа начинается со стека размера в 8 Кб, и когда в нём заканчивается место, выделяется стек побольше. Как и в любом аспекте программирования, в данном поведении есть компромиссы, все имеющиеся указатели должны быть правильно обновлены, а это не очень простая задача. Если вас заинтересовало то, как GO управляет стеком (что является хорошим примером использования и компромиссной реализации растущего стека), то отправляю вас к этой статье.
Ещё одна вещь, что будет важна позже: мы использовали обычный вектор (Vec) из стандартной библиотеки. Он очень удобен, но с ним есть проблемы. Среди прочего, нет гарантии, что он останется на прежнем месте в памяти.
Как вы можете понять, если стек будет перемещён в памяти, то программа аварийно завершится из-за того, что все наши указатели станут недействительными. Что-нибудь такое простое, как вызовpush()для нашего стека (имеется в виду вектор — прим.) может вызвать его расширение. А когда вектор расширяется, то запрашивается новый кусок памяти большего размера, в который потом перемещаются значения.
Только что мы прошли основы того, как стек выглядит и работает, и готовы переходить к реализации наших грин тредов. Вы уже проделали много сложной работы, так что обещаю больше кода.
Как настроить стек
Windows x86–64 организует стек чуть иначе, чем регламентируется соглашением вызовов x86–64 psABI. Я уделю чуть больше времени стеку Windows в приложении, но важно знать, что различия не такие большие, когда вы настраиваете стек под простые функции, которые не принимают параметры, что мы и делаем.
Организация стека в psABI выглядит следующим образом:
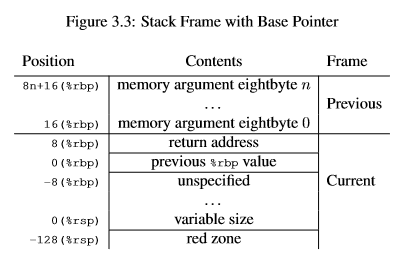
Как вы уже знаете, %rsp — это наш указатель на стек. Теперь, как вы видите, нужно положить указатель на стек в позицию от base pointer, кратную 16. Адрес возврата располагается в соседних 8 байтах, и, как вы видите, выше ещё есть место для аргументов. Нужно держать всё это в уме, когда хотим сделать что-нибудь более сложное.
Вы заметите, что мы регулярно записываем адрес на нашу функцию по адресу stack_ptr + SSIZE - 16 без объяснения, почему именно так. По-любому SSIZE — это размер стека в байтах.
Думайте об этом следующим образом. Мы знаем, что размер указателя (в нашем случае — указателя на функцию) равен 8 байтам. Мы знаем, что rsp должен быть записан на границе 16 байт, чтобы соответствовать ABI.
У нас на самом деле и выбора-то нет, кроме как писать по адресу stack_ptr + SSIZE - 16. Записывая байты по адресам от младшего к старшему:
- Мы не можем записать их по адреса, начиная с
stack_ptr + SSIZE(является границей 16 байт), т.к. мы выйдем за границы выделенного участка памяти, что запрещено. - Мы не можем записать их по адресам, начиная с
stack_ptr + SSIZE - 8, которые находятся внутри валидного адресного пространства, но не выровнены по границе 16 байт.
Остаётся только stack_ptr + SSIZE - 16 в качестве первой подходящей позиции. На практике мы пишем 8 байт в позиции -16, -15, -14, ..., -9 от старшего адреса нашего стека (который, запутывая, часто зовётся bottom of stack, т.к. растёт в сторону младших адресов (прим — если адреса записать в колонку по порядку, вверху будут младшие адреса, а внизу — старшие, то дно стека как раз будет внизу)).
Бонусный материал
Если вы достаточно любознательны, вы можете заинтересоваться тем, что происходит со стеком после того, как мы переключаемся на него.
Ответ заключается в том, как написанный нами код на Расте компилируется в инструкции для процессора, которые затем переходит к нашему стеку и используют его, как и любой другой стек.
К сожалению, чтобы показать это, пришлось увеличить размер стека до 1024 байт, чтобы в нём оказалось достаточно места для того, чтобы наш код смог распечатать его содержимое. Так что тут вывод не будет приводиться.
Взглянем на стек
Однако, я написал альтернативную версию нашего примера, который вы можете запустить. Он создаст два текстовых файла: BEFORE.txt (содержимое стека перед переключением на него) и AFTER.txt (содержимое стека после переключения). Вы можете своими глазами посмотреть, как живёт стек и используется нашим кодом.
Если вы видете что-то незнакомое в этом коде, то расслабьтесь — позже мы подробно рассмотрим детали.
#![feature(llvm_asm)]
#![feature(naked_functions)]
use std::io::Write;
const SSIZE: isize = 1024;
static mut S_PTR: *const u8 = 0 as *const u8;
#[derive(Debug, Default)]
#[repr(C)]
struct ThreadContext {
rsp: u64,
r15: u64,
r14: u64,
r13: u64,
r12: u64,
rbx: u64,
rbp: u64,
}
fn print_stack(filename: &str) {
let mut f = std::fs::File::create(filename).unwrap();
unsafe {
for i in (0..SSIZE).rev() {
writeln!(
f,
"mem: {}, val: {}",
S_PTR.offset(i as isize) as usize,
*S_PTR.offset( i as isize)
)
.expect("Error writing to file.");
}
}
}
fn hello() {
println!("I LOVE WAKING UP ON A NEW STACK!");
print_stack("AFTER.txt");
loop {}
}
unsafe fn gt_switch(new: *const ThreadContext) {
llvm_asm!("
mov 0x00($0), %rsp
ret
"
:
: "r"(new)
:
: "alignstack"
);
}
fn main() {
let mut ctx = ThreadContext::default();
let mut stack = vec![0_u8; SSIZE as usize];
let stack_ptr = stack.as_mut_ptr();
unsafe {
S_PTR = stack_ptr;
std::ptr::write(stack_ptr.offset(SSIZE - 16) as *mut u64, hello as u64);
print_stack("BEFORE.txt");
ctx.rsp = stack_ptr.offset(SSIZE - 16) as u64;
gt_switch(&mut ctx);
}
}Реализация грин тредов
Прежде, чем начать, замечу, что код, который мы напишем, не совсем безопасный, а так же не соответствует «лучшим практикам» (best practicies) в Расте. Я хочу попытаться сделать его, как можно безопаснее без привнесения множества ненужной сложности, так что если вы видите, что что-то можно сделать ещё безопаснее без сверхусложнения кода, то призываю тебя, дорогой читатель, предложить соответствующий PR в репозиторий.
Приступим
Первое, что сделаем — удалим наш предыдущий пример в файле main.rs, начав всё с нуля, и добавим следующее:
#![feature(llvm_asm)]
#![feature(naked_functions)]
use std::ptr;
const DEFAULT_STACK_SIZE: usize = 1024 * 1024 * 2;
const MAX_THREADS: usize = 4;
static mut RUNTIME: usize = 0;Мы задействовали две фичи: ранее рассмотренную asm и фичу naked_functions, которую требуется в разъяснении.
naked_functions
Когда Раст компилирует функцию, он добавляет к ней небольшие «пролог» и «эпилог», которые вызывают некоторые проблемы из-за того, что при переключении контекстов стек оказывается невыровненным. Хотя в нашем простом примере всё работает нормально, но когда нам нужно переключаться обратно на тот же самый стек, то возникают трудности. Атрибут #[naked] убирает генерацию пролога и эпилога для функции. Главным образом этот атрибут используется в связке с ассемблерными вставками.
Если интересно, то проnaked_functionsможно почитать в RFC #1201.Naked-функции не совсем функции. Когда вызывается обычная функция, то сохраняются регистры, в стек заталкивается адрес возврата, стек выравнивается и т.п. При вызове naked-функций ничего из этого не происходит. Если слепо вызвать
retв naked-функции (без предварительных манипуляций как в прологе и эпилоге, описанных в ABI), то попадёте на территорию неопределённого поведения. В лучшем случае закончите в вызывающем коде с мусором в регистрах.
Размер стека DEFAULT_STACK_SIZE задан в 2 МБ, чего более, чем достаточно для наших нужд. Так же задаём количество тредов (MAX_THREADS) равным 4, т.к. для примера больше не нужно.
Последняя строка — константа RUNTIME — указатель на структуру, содержащую информацию о системе времени исполнения (да, я знаю, что использовать мутабельную глобальную переменную для этого не очень красиво, она нам нужна дальше, а задаём для неё значение только во время инициализации).
Для представления наших данных допишем кое-что свежее:
pub struct Runtime {
threads: Vec,
current: usize,
}
#[derive(Debug, Eq, PartialEq)]
enum State {
Available,
Running,
Ready,
}
struct Thread {
id: usize,
stack: Vec,
ctx: ThreadContext,
state: State,
}
#[derive(Debug, Default)]
#[repr(C)]
struct ThreadContext {
rps: u64,
r15: u64,
r14, u64,
r13: u64,
r12: u64,
rbx: u64,
rbp: u64,
} Главной точкой входа будет структура Runtime. Мы создадим очень маленький, простой рантайм для планирования выполнения потоков и переключения между ними. Структура содержит в себе вектор структур Thread и поле current, которое указывает на поток, который выполняется в данный момент.
Структура Thread содержит данные для потока. Для того, чтобы отличать потоки друг от друга, они имеют уникальный id. Поле stack такое же, какое мы видели в примерах ранее. Поле ctx содержит данные для процессора, которые нужны для продолжения работы потока с того места, где он покинул стек. Поле state — это состояние потока.
State — это перечисление состояний потока, которое может принимать значения:
Available— поток доступен и готов быть назначенным для выполнения задачи, если нужно.Running— поток выполняетсяReady— поток готов продолжать и возобновить выполнение.
ThreadContext содержит данные регистров, которые нужны процессору для возобновления исполнения на стеке.
Если запамятовали, то вернитесь к части «Предварительные сведения» для того, чтобы почитать о регистрах. В спецификации архитектуры x86–64 Эти регистры помечены как «callee saved».
Продолжаем:
impl Thread {
fn new(id: usize) -> Self {
Thread {
id,
stack: vec![0_u8; DEFAULT_STACK_SIZE],
ctx: ThreadContext::default(),
state: State::Available,
}
}
}Тут всё довольно просто. Новый поток стартует в состоянии Available, которое означает, что он готов принять задачу для исполнения.
Нужно отметить, что здесь мы выделяем стек. Это не слишком необходимое и оптимальное решение с точки зрения использования ресурсов, т.к. память можно выделить при первом использовании структуры. Но это позволяет снизить сложность в некоторых частях кода на которых можно сфокусировать внимание, вместо того, чтобы выделять память для стека.
Важно заметить, что после того, как стек выделен, он не должен перемещаться. Никаких вызовов методаpush()и других, которые могут спровоцировать перевыделение памяти. Лучше было бы использовать свой собственный тип данных, который предоставляет только безопасные с этой точки зрения методы.Так же упомянем, что у
Vecесть методinto_boxed_slice(), который возвращаетBox<[T]>— срез, выделенный в куче. Срезы не могут быть расширены, так что мы можем использовать их для решения проблемы перевыделения памяти.
Реализация рантайма
Весь код этой части находится внутри блока impl Runtime, реализуя методы для одноимённой структуры.
impl Runtime {
pub fn new() -> Self {
let base_thread = Thread {
id: 0,
stack: vec![0_u8; DEFAULT_STACK_SIZE],
ctx: ThreadContext::default(),
state: State::Running,
};
let mut threads = vec![base_thread];
let mut available_threads: Vec = (1..MAX_THREADS).map(|i| Thread::new(i)).collect();
threads.append(&mut available_threads);
Runtime {
threads,
current: 0,
}
}
// code of other methods is here
// ...
} При инстанцировании структуры Runtime создаётся базовый поток в состоянии Running. Он держит среду исполнения запущенной пока все задачи не будут завершены. Потом создаются остальные потоки, а текущим назначается поток с номером 0, который является базовым.
// Читерство, но нам нужен указатель на структуру Runtime
// сохранённый таким образом, чтобы мы могли вызывать метод yield
// без прямого обращения к этой структуре по ссылке.
// по сути мы дублируем указатель втихомолку от компилятора
pub fn init(&self) {
unsafe {
let r_ptr: *const Runtime = self;
RUNTIME = r_ptr as usize;
}
}Сейчас нам это нужно. Как я упоминал, когда расписывал константы, нам нужна глобальная переменная для того, чтобы вызывать метод yield позже. Не очень симпатично, но мы знаем, что наш рантайм должен жить, пока есть потоки.
pub fn run(&mut self) -> ! {
while self.t_yield() {};
std::process::exit(0);
}А это то место, где мы запускаем наш рантайм. Он беспрестанно вызывает метод t_yield(), пока тот не вернёт значение false, что означает, задач больше нет, и мы можем завершить процесс.
fn t_return(&mut self) {
if self.current != 0 {
std.threads[self.current].state = State::Available;
self.t_yield();
}
}Когда процесс завершается, то вызываем эту функцию. Мы назвали её t_return, т.к. слово return входит в список зарезервированных. Заметьте, что пользователь наших потоков не вызывает эту функцию — мы организуем стек таким образом, что эта функцию вызывается, когда задача завершается.
Если вызывающий поток является базовым, то ничего не делаем. Наш рантайм вызывает метод yield для базового потока. Если же вызов приходит из порождённого (spawned) потока, мы узнаём, что он завершился, т.к. у всех потоков на вершине их стека находится функция guard (её объясню позже). Так что единственное место, откуда t_return может быть вызвана — это как раз функция guard.
Мы назначаем потоку состояние Available, сообщая рантайму, что готовы принять новую задачу (task), а затем немедленно вызываем t_yield, который дёргает планировщик для запуска нового потока.
Далее рассмотрим функцию yield:
fn t_yield(&mut self) -> bool {
let mut post = self.current;
while self.threads[pos].state != State::Ready {
pos += 1;
if pos == self.threads.len() {
pos = 0;
}
if pos == self.current {
return false;
}
}
if self.threads[self.current].state != State::Available {
self.threads[self.current].state = State::Ready;
}
self.threads[pos].state = State::Running;
let old_pos = self.current;
self.current = pos;
unsafe {
let old: *mut ThreadContext = &mut self.threads[old_pos].ctx;
let new: *const ThreadContext = &self.threads[pos].ctx;
llvm_asm!(
"
mov $0, %rdi
mov $1, %rsi
call switch
"
:
: "r"(old), "r"(new)
