Книга «Python для data science»
 Привет, Хаброжители!
Привет, Хаброжители!
Python — идеальный выбор для манипулирования и извлечения информации из данных всех видов. «Python для data science» познакомит программистов с питоническим миром анализа данных. Вы научитесь писать код на Python, применяя самые современные методы, для получения, преобразования и анализа данных в управлении бизнесом, маркетинге и поддержке принятия решений.
Познакомьтесь с богатым набором встроенных структур данных Python для выполнения основных операций, а также о надежной экосистемы библиотек с открытым исходным кодом для data science, включая NumPy, pandas, scikit-learn, matplotlib и другие. Научитесь загружать данные в различных форматах, упорядочивать, группировать и агрегировать датасеты, а также создавать графики, карты и другие визуализации. На подробных примерах стройте реальные приложения, в том числе: службу такси, использующую геолокацию, анализ корзины для определения товаров, которые обычно покупаются вместе, а также модель машинного обучения для прогнозирования цен на акции.
Или, может быть, вы хотите создать собственное приложение на основе данных или просто расширить знания о применении Python в области data science.
Книга предполагает, что у вас уже есть базовый опыт работы с Python и для вас не составит труда следовать таким инструкциям, как установка базы данных или получение ключа API. Тем не менее концепции data science объясняются с нуля на практических, тщательно разобранных примерах. Поэтому опыт работы с данными не требуется.
Получение инсайтов из данных
Ежедневно компании генерируют огромное количество данных в виде необработанных фактов, показателей и событий, но о чем вся эта информация говорит на самом деле? Чтобы извлечь ценные сведения и инсайты из данных, их необходимо преобразовать, проанализировать и представить в наглядной форме. Другими словами, нужно превратить необработанные данные в значимую информацию, которую можно использовать для принятия решений, ответов на вопросы и выполнения поставленных задач.
Рассмотрим сценарий с супермаркетом, который собирает большие объемы данных о покупках клиентов. Эти данные представляют интерес для аналитиков супермаркета, поскольку с их помощью можно получить представление о предпочтениях покупателей. В частности, для этого служит анализ потребительской корзины (market basket analysis) — метод интеллектуального анализа данных, который исследует совершенные транзакции и выявляет товары, которые обычно приобретаются вместе. Вооружившись этими знаниями, супермаркет сможет принимать более обоснованные бизнес-решения, например, о выкладке товаров в магазине или о том, как объединять товары в группы со скидками.
В этой главе мы подробно рассмотрим, как получить инсайты из данных о транзакциях с помощью анализа потребительской корзины на Python. Мы расскажем, как использовать библиотеку mlxtend и алгоритм Apriori для определения товаров, которые обычно приобретаются вместе, и как применять эти знания для принятия обоснованных бизнес-решений.
Хотя в центре внимания данной главы будет выявление предпочтений покупателей, анализ потребительской корзины можно применять не только с этой целью. Та же техника используется в таких областях, как телекоммуникации, анализ использования веб-ресурсов (web usage mining), банковское дело и здравоохранение. Например, при исследовании использования веб-ресурсов с помощью анализа потребительской корзины можно определить, на какую страницу пользователь, скорее всего, перейдет дальше, и создать ассоциации часто посещаемых страниц.
Ассоциативные правила
Анализ потребительской корзины — это измерение степени взаимосвязи между объектами на основе вероятности их совместного присутствия в одних и тех же транзакциях. Взаимосвязи между объектами представлены в виде ассоциативных правил, которые обозначаются следующим образом:
X->Y
X и Y, называемые антецедентом (antecedent) и консеквентом (consequent) правила соответственно, представляют собой отдельные наборы товаров, или группы из одного либо нескольких товаров, полученных из данных о транзакции. Например, ассоциативное правило, описывающее связь между товарами творог и сметана, будет таким:
творог -> сметана
В данном случае творог является антецедентом, а сметана — консеквентом. Правило утверждает, что люди, покупающие творог, скорее всего, купят и сметану.
Само по себе ассоциативное правило, подобное этому, на самом деле не очень информативно. Ключом к успешному анализу потребительской корзины является использование данных о транзакциях для оценки степени значимости ассоциативных правил на основе различных метрик. Возьмем простой пример. Предположим, у нас есть данные о 100 покупательских транзакциях, 25 из которых содержат творог и 30 — сметану. Среди 30 транзакций, содержащих сметану, 20 также содержат творог. В табл. 11.1 представлены эти показатели.
Учитывая эти данные, можно оценить значимость ассоциативного правила творог → сметана, используя такие метрики, как поддержка (support), доверие (confidence) и лифт (lift). Эти метрики помогут определить, действительно ли существует связь между творогом и сметаной.

Поддержка
Поддержка (support) — это отношение количества транзакций, включающих один или более товаров, к общему количеству транзакций. Например, показатель поддержки творога в наших данных о сделке может быть рассчитан следующим образом:
поддержка(творог) = творог / общее количество = 25 / 100 = 0.25
В контексте ассоциативного правила поддержка — это отношение количества транзакций, включающих и антецедент, и консеквент, к общему количеству транзакций. Таким образом, поддержка ассоциативного правила творог → сметана будет равна:
поддержка(творог -> сметана) = (творог & сметана) / общее количество =
20 / 100 = 0.2
Метрика поддержки имеет значение в диапазоне от 0 до 1 и говорит о том, в каком проценте случаев набор товаров появляется в транзакции вместе. В данном примере мы видим, что в 20% транзакций есть и творог, и сметана. Поддержка симметрична для любого ассоциативного правила, то есть поддержка для творог → сметана такая же, как для сметана → творог.
Доверие
Доверие (confidence) ассоциативного правила — это отношение транзакций, в которых есть и антецедент, и консеквент, к транзакциям, в которых присутствует только антецедент. Другими словами, доверие измеряет, какая доля транзакций, содержащих антецедент, также содержит консеквент. Доверие для ассоциативного правила творог → сметана можно рассчитать следующим образом:
доверие(творог -> сметана) = (творог & сметана) / творог = 20 / 25 = 0.8
Этот показатель можно интерпретировать так: если клиент купил творог, то вероятность того, что он также купит сметану, составляет 80%.
Как и поддержка, доверие находится в диапазоне от 0 до 1, но, в отличие от поддержки, оно не симметрично. Это означает, что метрика доверия для правила творог → сметана может отличаться от доверия для правила сметана → творог:
доверие(сметана -> творог) = (творог & сметана) / сметана = 20 / 30 = 0.66
В данном сценарии значение доверия будет меньше, если антецедент и консеквент ассоциативного правила поменяются местами. Это говорит о том, что вероятность того, что человек, покупающий сметану, купит и творог, меньше, чем вероятность того, что человек, покупающий творог, купит и сметану.
Лифт
Лифт (lift) оценивает значимость ассоциативного правила для случая, когда элементы правила оказываются в одной транзакции случайно. Лифт ассоциативного правила творог → сметана — это отношение наблюдаемой поддержки для творог → сметана к ожидаемой, если бы покупка творога и покупка сметаны были независимы друг от друга. Рассчитать лифт можно следующим образом:
лифт(сметана -> творог) = поддержка(творог & сметана) / (поддержка (творог) * поддержка(сметана)) = 0.2 / (0.25 * 0.3) = 2.66
Метрика лифта симметрична — если поменять местами антецедент и консеквент, значение метрики не изменится. Коэффициент лифта варьируется от 0 до бесконечности, и чем больше этот коэффициент, тем сильнее связь. В частности, коэффициент лифта, больший 1, указывает на то, что связь между антецедентом и консеквентом сильнее, чем можно было бы ожидать, если бы они были независимыми, то есть эти два товара часто покупают вместе. Коэффициент лифта, равный 1, указывает на отсутствие корреляции между антецедентом и консеквентом. Коэффициент лифта, меньший 1, говорит о наличии отрицательной корреляции между антецедентом и консеквентом. Это означает, что их вряд ли купят вместе. В данном случае коэффициент лифта 2.66 можно интерпретировать так: когда клиент покупает творог, ожидаемая вероятность того, что он также купит сметану, увеличивается на 166%.
Алгоритм Apriori
Теперь вы знаете, что собой представляют ассоциативные правила и некоторые метрики оценки их значимости, но как создавать ассоциативные правила для анализа потребительской корзины? Один из способов — использовать алгоритм Apriori (Apriori algorithm), автоматизированный процесс анализа данных о транзакциях. В общих чертах этот алгоритм состоит из двух шагов:
1. Определение всех часто встречающихся наборов или группы из одного либо нескольких товаров, которые в рамках датасета присутствуют сразу во многих транзакциях. Алгоритм находит все товары или группы товаров, значение поддержки которых превышает определенный порог.
2. Генерирование ассоциативных правил для часто встречающихся наборов товаров путем рассмотрения всех возможных бинарных разбиений каждого набора товаров (то есть всех разбиений набора на группу антецедентов и группу консеквентов) и вычисления метрик ассоциативных правил для каждого разбиения.
После создания ассоциативных правил их значимость можно оценить с помощью метрик из предыдущего раздела.
Несколько сторонних библиотек Python поставляются с реализацией алгоритма Apriori. Одна из них — библиотека mlxtend (сокращение от machine learning extensions). Библиотека mlxtend включает инструменты для решения ряда общих задач в области data science. В этом разделе мы рассмотрим пример анализа потребительской корзины с помощью реализации алгоритма Apriori. Но сначала установим mlxtend с помощью pip:
$ pip install mlxtendПРИМЕЧАНИЕЧтобы узнать больше о mlxtend, обратитесь к документации библиотеки (1).
Создание датасета с транзакциями
Для проведения анализа потребительской корзины понадобятся данные о нескольких транзакциях. Для простоты можно использовать всего несколько транзакций, реализованных в виде списка списков, как показано ниже:
transactions = [
['curd', 'sour cream'], ['curd', 'orange', 'sour cream'],
['bread', 'cheese', 'butter'], ['bread', 'butter'], ['bread', 'milk'],
['apple', 'orange', 'pear'], ['bread', 'milk', 'eggs'], ['tea', 'lemon'],
['curd', 'sour cream', 'apple'], ['eggs', 'wheat flour', 'milk'],
['pasta', 'cheese'], ['bread', 'cheese'], ['pasta', 'olive oil', 'cheese'],
['curd', 'jam'], ['bread', 'cheese', 'butter'],
['bread', 'sour cream', 'butter'], ['strawberry', 'sour cream'],
['curd', 'sour cream'], ['bread', 'coffee'], ['onion', 'garlic']
]
Каждый внутренний список содержит набор товаров одной транзакции. Внешний список transactions содержит в общей сложности 20 транзакций. Для сохранения количественных пропорций, определенных в исходном примере творог/сметана, датасет содержит пять операций с творогом (curd), шесть операций со сметаной (sour cream) и четыре операции, содержащие и творог, и сметану.
Чтобы пропустить данные транзакций через алгоритм Apriori библиотеки mlxtend, необходимо преобразовать их в булев массив, созданный с помощью быстрого кодирования (OHE, one-hot encoding), то есть структуру, где каждый столбец представляет доступный товар, а строка — транзакцию. Значения массива могут быть равны либо True, либо False (True, если транзакция включала данный конкретный товар, и False — если нет). Во фрагменте кода ниже мы выполняем необходимое преобразование, используя объект mlxtend TransactionEncoder:
import pandas as pd
from mlxtend.preprocessing import TransactionEncoder
❶ encoder = TransactionEncoder()
❷ encoded_array = encoder.fit(transactions).transform(transactions)
❸ df_itemsets = pd.DataFrame(encoded_array, columns=encoder.columns_)
Мы создаем объект TransactionEncoder ❶ и используем его для преобразования списка списков transactions в булев OHE-массив с названием encoded_array ❷. Затем преобразуем массив в pandas DataFrame df_itemsets ❸, фрагмент которого приведен ниже:
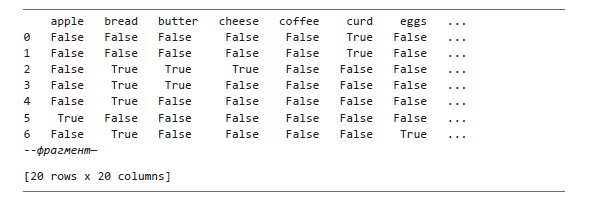
Датафрейм состоит из 20 строк и 20 столбцов. Строки представляют собой транзакции, а столбцы — товары. Чтобы проверить, что в исходном списке списков действительно было 20 транзакций, основанных на 20 доступных товарах, используйте следующий код:
print('Number of transactions: ', len(transactions))
print('Number of unique items: ', len(set(sum(transactions, []))))
В обоих случаях должно получиться 20.
Определение часто встречающихся наборов
Теперь, когда данные транзакции представлены в удобном формате, можно использовать функцию mlxtend apriori () для определения всех часто встречающихся наборов товаров в данных о транзакциях, то есть всех товаров или групп товаров с достаточно высокой метрикой поддержки. Вот как это реализовать:
from mlxtend.frequent_patterns import apriori
frequent_itemsets = apriori(df_itemsets, min_support=0.1, use_colnames=True)
Из модуля mlxtend.frequent_patterns импортируем функцию apriori (). Затем вызываем ее, передавая датафрейм с данными о транзакциях в качестве первого параметра. Также устанавливаем для параметра min_support значение 0.1, чтобы возвращать наборы с поддержкой не менее 10% (помните, что метрика поддержки показывает, в каком проценте транзакций встречается товар или группа товаров). Для use_colnames мы устанавливаем значение True, чтобы определить столбцы, включаемые в каждый набор товаров, по их названию (например, curd или sour cream), а не по индексу. В результате apriori () возвращает следующий датафрейм:

Как уже отмечалось, набор товаров может состоять из одного или нескольких позиций, и действительно, apriori () вернул несколько наборов с одним товаром. В конечном итоге mlxtend не будет учитывать наборы с одним товаром при составлении ассоциативных правил; тем не менее ему понадобятся данные обо всех часто встречающихся наборах (включая те, которые содержат один товар). Ради интереса можете выбрать только те наборы товаров, которые содержат несколько позиций. Для этого добавьте колонку length к датафрейму frequent_itemsets:
frequent_itemsets['length'] = frequent_itemsets['itemsets'].apply(lambda itemset:
len(itemset))
Затем, используя синтаксис pandas, отфильтруйте датафрейм так, чтобы остались только те строки, значение поля length которых равно или больше 2:
print(frequent_itemsets[frequent_itemsets['length'] >= 2])
Вы получите датафрейм, который не содержит наборов с одним товаром:
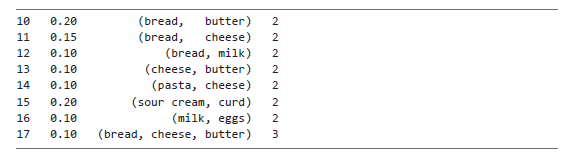
Повторимся, однако, что для генерации ассоциативных правил mlxtend требует информацию обо всех часто встречающихся наборах товаров. Поэтому убедитесь, что вы не удаляете ни одной строки из исходного датафрейма frequent_itemsets.
Генерирование ассоциативных правил
Мы определили все наборы товаров, которые соответствуют желаемому пороговому значению метрики поддержки. Второй шаг алгоритма Apriori заключается в генерации ассоциативных правил для этих наборов. Для этого используется функция association_rules () из модуля mlxtend frequent_patterns:
from mlxtend.frequent_patterns import association_rules
rules = association_rules(frequent_itemsets, metric="confidence",
min_threshold=0.5)
Во фрагменте кода выше мы вызываем функцию association_rules (), передавая в нее датафрейм frequent_itemsets в качестве первого параметра. Кроме того, выбираем метрику для оценки значимости правил и устанавливаем ее пороговое значение. В нашем конкретном случае мы указываем, что функция должна возвращать только те ассоциативные правила, метрика доверия которых равна или больше 0.5. Как отмечалось в предыдущем разделе, функция автоматически пропускает генерацию правил для наборов с одним товаром.
Функция association_rules () возвращает правила в виде датафрейма, где каждая строка представляет одно ассоциативное правило. В датафрейме несколько колонок: для антецедентов, консеквентов и различных метрик, включая поддержку, доверие и лифт. Выводим на экран выбранные столбцы:
print(rules.iloc[:,0:7])
Вот что мы получаем:
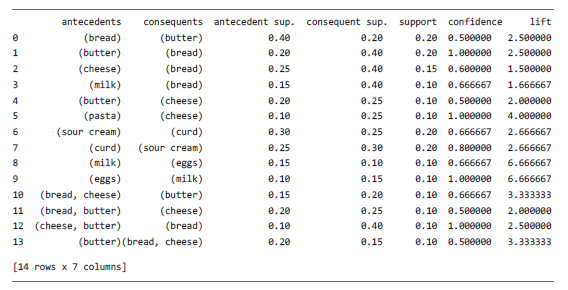
Некоторые из правил могут показаться излишними. Например, присутствует и правило bread → butter, и правило butter → bread. Аналогичным образом существует несколько правил, основанных на наборе элементов (bread, cheese, butter). Отчасти это связано с тем, что, как уже говорилось в этой главе, доверие несимметрично; если поменять местами антецедент и консеквент в правиле, значение метрики может измениться. Кроме того, для набора из трех товаров лифт может меняться в зависимости от того, какие элементы являются частью антецедента, а какие — частью консеквента. Таким образом, значение лифта для (bread, cheese) → butter отличается от (bread, butter) → cheese.
Визуализация ассоциативных правил
Как вы узнали из главы 8, визуализация — это простой, но мощный метод анализа данных. При анализе потребительской корзины визуализация — это удобный способ оценки значимости набора ассоциативных правил: можно просматривать метрики для различных пар антецедент/консеквент. В этом разделе мы будем использовать Matplotlib для визуализации ассоциативных правил, созданных в предыдущем разделе, в виде аннотированной тепловой карты (heatmap).
Тепловая карта — это график в виде сетки, где значения ячеек обозначаются цветом. В этом примере мы создадим тепловую карту метрики лифта различных ассоциативных правил. Мы расположим все антецеденты вдоль оси y, а консеквенты — вдоль оси x и заполним область их пересечения соответствующим цветом метрики лифта. Чем темнее цвет, тем выше значение лифта.
ПРИМЕЧАНИЕВ этом примере мы визуализируем метрику лифта, поскольку она часто используется для оценки значимости ассоциативных правил. Однако вы можете визуализировать и другую метрику, например доверие.
Перед построением графика создадим пустой датафрейм, в который скопируем столбцы antecedents, consequents и lift из созданного ранее датафрейма rules:
rules_plot = pd.DataFrame()
rules_plot['antecedents']= rules['antecedents'].apply(lambda x:
','.join(list(x)))
rules_plot['consequents']= rules['consequents'].apply(lambda x:
','.join(list(x)))
rules_plot['lift']= rules['lift'].apply(lambda x: round(x, 2))
Используем лямбда-функции для преобразования значений столбцов antecedents и consequents из датафрейма rules в строки, чтобы их было удобнее использовать в качестве меток графика. Изначально значения имели тип frozenset (неизменяемые множества Python). Для округления значений лифта до двух знаков после запятой применяем еще одну лямбда-функцию.
Далее необходимо преобразовать вновь созданный датафрейм rules_plot в матрицу, которая будет использоваться для создания тепловой карты с консеквентами, расположенными по горизонтали, и антецедентами — по вертикали. Для этого можно изменить форму rules_plot так, чтобы уникальные значения в столбце antecedents стали индексами, а уникальные значения в столбце consequents — новыми столбцами. Значения столбца lift будут использоваться для заполнения ячеек преобразованного датафрейма. Для этой цели применим метод pivot () датафрейма rules_plot:
pivot = rules_plot.pivot(index = 'antecedents', columns = 'consequents', values= 'lift')
Выбираем столбцы antecedents и consequents для формирования осей итогового датафрейма pivot, а из столбца lift берем значения. Если вывести pivot на экран, получим:
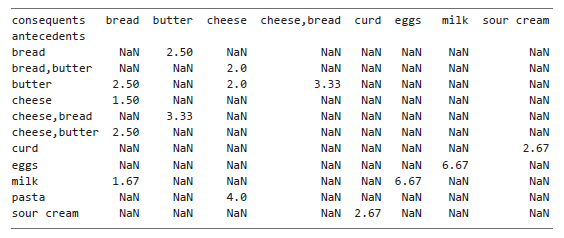
Этот датафрейм содержит все необходимое для построения тепловой карты: значения индекса (antecedents) станут метками оси y, названия столбцов (consequents) — метками оси x, а сетка чисел и NaN — значениями для графика (в данном контексте NaN означает, что для данной пары антецедент/консеквент отсутствует ассоциативное правило). Извлекаем эти компоненты в отдельные переменные:
antecedents = list(pivot.index.values)
consequents = list(pivot.columns)
import numpy as np
pivot = pivot.to_numpy()
Теперь у нас есть метки оси y в списке antecedents, метки оси x в списке consequents, а также значения для графика в NumPy-массиве pivot. В скрипте ниже мы используем все эти компоненты для построения тепловой карты с помощью Matplotlib:
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
fig, ax = plt.subplots()
❶ im = ax.imshow(pivot, cmap = 'Reds')
ax.set_xticks(np.arange(len(consequents)))
ax.set_yticks(np.arange(len(antecedents)))
ax.set_xticklabels(consequents)
ax.set_yticklabels(antecedents)
❷ plt.setp(ax.get_xticklabels(), rotation=45, ha="right",
rotation_mode="anchor")
❸ for i in range(len(antecedents)):
for j in range(len(consequents)):
❹ if not np.isnan(pivot[i, j]):
❺ text = ax.text(j, i, pivot[i, j], ha="center", va="center")
ax.set_title("Lift metric for frequent itemsets")
fig.tight_layout()
plt.show()
Основные моменты построения графиков с помощью Matplotlib были рассмотрены в главе 8. Сейчас мы разберем только специфичные для данного конкретного примера строки кода. Метод imshow () преобразует данные из массива pivot в двумерное изображение (image) с цветовой кодировкой ❶. С помощью параметра метода cmap указываем, каким цветам соответствуют числовые значения массива. В Matplotlib есть ряд встроенных цветовых палитр, из которых можно выбрать любую, в том числе Reds, используемую в нашем примере.
После создания меток осей используем метод setp () для поворота меток оси x на 45 градусов ❷. Это позволит уместить все метки в пространстве, отведенном для маркировки горизонтальной оси. Затем проходим по массиву pivot ❸ и создаем текстовые аннотации для каждого квадрата тепловой карты с помощью метода text () ❺. Первые два параметра, j и i, являются x- и y-координатами метки. Следующий параметр, pivot[i, j], — текст метки, остальные параметры задают другие настройки. Перед вызовом метода text () используется оператор if для отсеивания пар антецедент/консеквент, для которых отсутствует значение лифта ❹. В противном случае в каждом пустом квадрате тепловой карты появится метка NaN.
На рис. 11.1 показан полученный график.
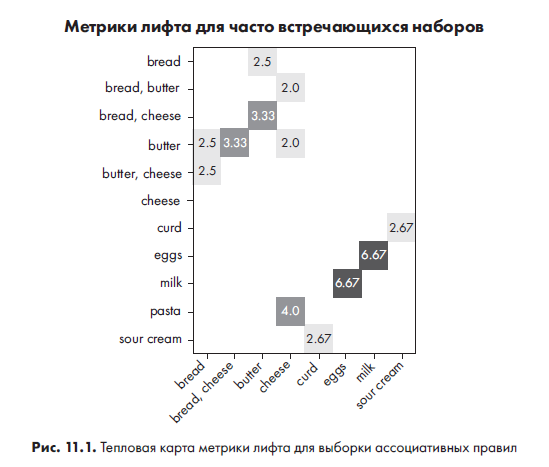
Тепловая карта наглядно демонстрирует, для каких ассоциативных правил значения лифта самые высокие (чем темнее цвет ячейки, тем выше значение). Глядя на эту визуализацию, можно с высокой степенью уверенности утверждать, что покупатель, который приобретает молоко, скорее всего, купит и яйца. Точно так же можно быть вполне уверенными, что покупатель, приобретающий макароны, купит и сыр. Есть и другие ассоциативные пары, например масло и сыр, но как видим, они не так сильно подкреплены метрикой лифта.
Тепловая карта также иллюстрирует, что метрика симметрична. Посмотрите, например, на значения правил bread → butterо и butter → bread. Они одинаковы.
Однако можно заметить, что для некоторых пар антецедент/консеквент на графике значение лифта несимметрично. Например, лифт для правила cheese → bread равен 1.5, однако значения лифта для bread → cheese на графике нет. Это связано с тем, что когда мы изначально создавали ассоциативные правила с помощью функции mlxtend association_rules (), мы установили 50-процентный порог доверия. Это решение исключило многие потенциальные ассоциативные правила, включая bread → cheese с показателем доверия 37.5% против 60-процентого доверия пары cheese → bread. Таким образом, данные правила bread → cheese не учитывались при построении графика.
Получение полезных инсайтов из ассоциативных правил
Используя алгоритм Apriori, мы определили часто встречающиеся наборы товаров в выборке данных о транзакциях и на их основе создали ассоциативные правила. По сути, эти правила показывают вероятность того, что покупатель приобретет какой-то продукт, если он уже купил другой, а визуализация значений лифта на тепловой карте позволяет определить самые четкие закономерности. Следующий логичный вопрос — как эта информация может быть полезна бизнесу?
В этом разделе мы рассмотрим два способа, с помощью которых компания может получить полезные инсайты из набора ассоциативных правил. Мы исследуем, как генерировать рекомендации на основе товаров, которые покупатель уже приобрел, и как эффективно планировать скидки на основе часто встречающихся наборов товаров. Обе эти техники помогают увеличить доход компании и одновременно обеспечить лучшее качество клиентского сервиса.
Генерирование рекомендаций
После того как покупатель положил какой-то товар в корзину, какой следующий товар он, скорее всего, добавит? Конечно, это нельзя определить наверняка, однако можно сделать прогноз на основе ассоциативных правил, полученных из данных о транзакциях. Результаты такого прогнозирования могут стать основой для формирования набора рекомендаций тех товаров, которые часто приобретают вместе с товаром, который уже находится в корзине. Ритейлеры обычно используют такие рекомендации, чтобы показать покупателям другие товары, которые им потенциально понадобятся.
Вероятно, самый естественный способ создания рекомендаций такого типа — рассмотрение всех ассоциативных правил, в которых товар, находящийся в корзине, выступает в качестве антецедента. Затем определяются самые значимые правила — например, три правила с самым высоким значением доверия — и извлекаются их консеквенты. Ниже показано, как выполнить этот алгоритм для товара butter (масло). Начинаем с поиска правил, в которых butter является антецедентом, используя возможности фильтрации библиотеки pandas:
butter_antecedent = rules[rules['antecedents'] == {'butter'}]
[['consequents','confidence']]
.sort_values('confidence', ascending = False)
В коде выше мы сортируем правила по столбцу confidence так, чтобы правила с наивысшим рейтингом доверия оказались в начале датафрейма butter_antecedent. Далее используем списковое включение для извлечения трех основных консеквентов:
butter_consequents = [list(item) for item in butter_antecedent.iloc[0:3:,] ['consequents']]
В этом списковом включении мы проходим по столбцу consequents датафрейма butter_antecedent, выбирая первые три значения. Для списка butter_consequents можно сгенирировать рекомендации:
item = 'butter'
print('Items frequently bought together with', item, 'are:', butter_consequents)
Вот как они выглядят:
Items frequently bought together with butter are: [['bread'], ['cheese'],
['cheese', 'bread']]
Это указывает на то, что покупатели масла в дополнение к нему часто покупают либо хлеб или сыр, либо и то и другое.
Планирование скидок на основе ассоциативных правил
Ассоциативные правила, созданные для часто встречающихся наборов товаров, также применяются для выбора продуктов, на которые можно назначить скидки. В идеале продукт со скидкой должен быть в каждой значимой группе товаров, чтобы удовлетворить как можно больше покупателей. Другими словами, необходимо выбрать один товар для назначения скидки в каждом часто встречающемся наборе.
Для этого, прежде всего, такие наборы нужно найти. К сожалению, в датафрейме rules, созданном ранее функцией association_rules (), содержатся колонки с антецедентами и консеквентами, а не с наборами товаров целиком. Поэтому необходимо создать колонку itemsets, объединив столбцы antecedents и consequents, как показано ниже:
from functools import reduce
rules['itemsets'] = rules[['antecedents', 'consequents']].apply(lambda x:
reduce(frozenset.union, x), axis=1)
Мы используем функцию reduce () из модуля functools Python для применения метода frozenset.union () к значениям колонок antecedents и consequents. При этом отдельные неизменяемые множества (frozenset) из этих колонок объединяются в одно.
Чтобы посмотреть, что получилось в результате, можно вывести на экран только что созданный столбец itemsets вместе с колонками antecedents и consequents:
print(rules[['antecedents','consequents','itemsets']])
Вывод:
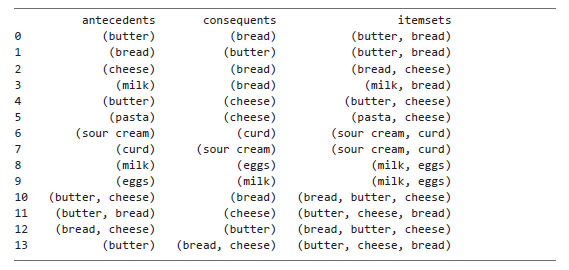
Обратите внимание, что в новом столбце itemsets есть несколько дубликатов. Как уже говорилось, один и тот же набор товаров может образовывать более одного ассоциативного правила, поскольку порядок товаров влияет на некоторые метрики. Порядок товаров в наборе не имеет значения для текущей задачи, поэтому можно безопасно удалить дубли наборов, как показано ниже:
rules.drop_duplicates(subset=['itemsets'], keep='first', inplace=True)
Для этого используется метод датафрейма drop_duplicates (), осуществляющий поиск повторяющихся значений в столбце itemsets. Мы сохраняем первую строку множества дублирующихся строк и, задавая значение True для параметра inplace, удаляем дубликаты из существующего датафрейма вместо создания нового.
Выведем на экран колонку itemsets:
print(rules['itemsets'])
И получим:

Затем из каждого набора выбираем по одному товару, который будет уценен:
discounted = []
others = []
❶ for itemset in rules['itemsets']:
❷ for i, item in enumerate(itemset):
❸ if item not in others:
❹ discounted.append(item)
itemset = set(itemset)
itemset.discard(item)
❺ others.extend(itemset)
break
❻ if i == len(itemset)-1:
discounted.append(item)
itemset = set(itemset)
itemset.discard(item)
others.extend(itemset)
print(discounted)
Сначала создается список discounted для сохранения товаров, выбранных для скидки, и список others для получения товаров из набора, на которых скидки не будет. Затем мы проходим по каждому набору товаров ❶ и по каждому товару внутри набора ❷. Мы ищем элемент, которого еще нет в списке others, поскольку такого элемента либо нет ни в одном из предыдущих наборов, либо он уже был выбран ранее в качестве уцененного товара для какого-то другого набора. Рационально выбрать его в качестве товара со скидкой и для текущего набора ❸. Мы отправляем выбранный товар в список discounted ❹, а остальные товары набора — в список others ❺. Если мы перебрали все товары набора и не нашли элемент, которого еще нет в списке others, то выбираем последний элемент набора и отправляем его в список discounted ❻.
Итоговый список discounted будет отличаться, поскольку множества frozenset, представляющие наборы товаров, не упорядочены. Вот как он будет выглядеть:
['bread', 'bread', 'bread', 'cheese', 'pasta', 'curd', 'eggs', 'bread']
Если сопоставить список с созданным ранее столбцом itemsets, можно заметить, что в каждом наборе есть один уцененный товар. Более того, благодаря тому, что мы грамотно распределили скидки, фактически уцененных товаров получилось значительно меньше, чем наборов. Это можно проверить, удалив дубликаты из списка discounted:
print(list(set(discounted)))
Как видно из результата, несмотря на то что у нас восемь наборов, сделать скидку пришлось лишь на пять товаров:
['cheese', 'eggs', 'bread', 'pasta', 'curd']
Таким образом, нам удалось уценить хотя бы один товар в каждом наборе (существенная выгода для многих покупателей) и не пришлось делать скидку на большее количество продуктов (существенная выгода для бизнеса).
Более подробно с книгой можно ознакомиться на сайте издательства:
» Оглавление
» Отрывок
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.
Для Хаброжителей скидка 25% по купону — Python
