Как мы придумали свою диаграмму Ганта
В управлении проектами часто возникает вопрос: как лучше спланировать последовательность работ разных отделов, убедиться в отсутствии оверкапа по капасити, да и вообще понять критический путь будущего релиза? Желательно еще и визуализировать все эти планы. Ко всему этому, часто бывает, что нужно внезапно и быстро переработать утвержденное ранее.
К нашему счастью, эту проблему решили за нас еще в конце XIX века, придумав диаграмму Ганта. Затем придумали компьютеры, а после — Интернет. И, казалось бы, какие тут еще могут остаться проблемы, но не всё так просто — ведь нельзя просто создать универсальный инструмент, который удовлетворял бы нуждам всех.
Сегодня я расскажу о том, как мы перебрали множество вариантов диаграммы Ганта, но по итогу пришли к тому, чтобы разработать собственный.
Что такое диаграмма Ганта
Если вы не до конца понимаете, что такое диаграмма Ганта, лучше всего это объяснит картинка ниже:
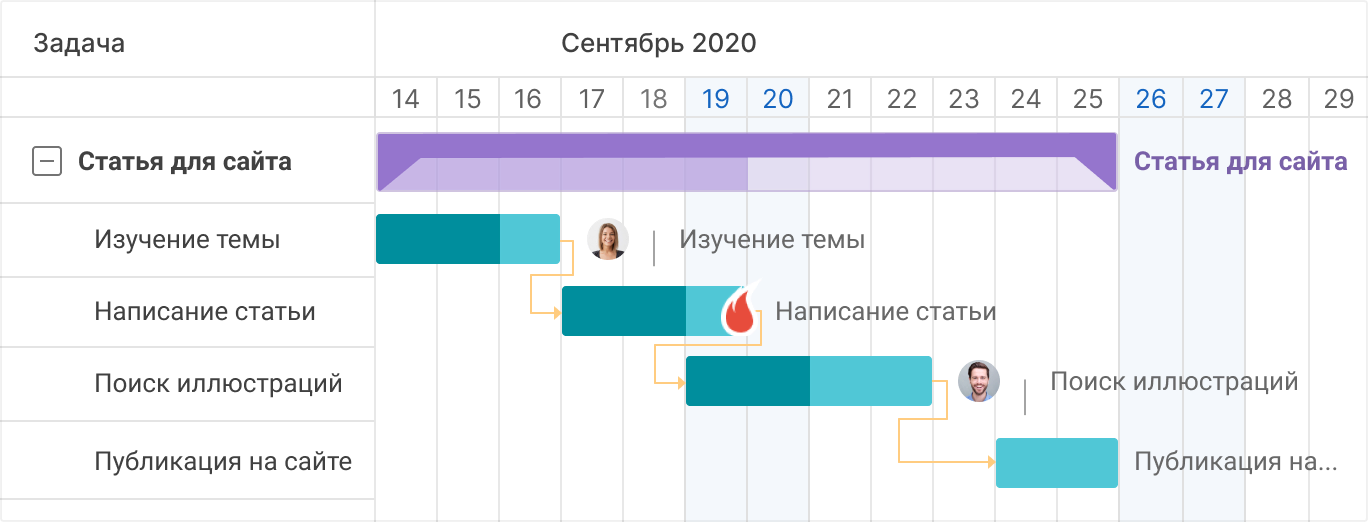
В двух словах, Гант — это визуальное отображение последовательности задач на горизонтальной шкале времени (таймлайне). Такая диаграмма нужна для упрощения понимания планов работ по проекту.
Наши требования к диаграмме
Тулзу мы выбирали исходя из простого набора критериев:
Наглядное отображение планов для команды и руководства;
Участники команды должны всегда иметь доступ к диаграмме;
Возможность быстрого перепланирования;
Поддержка связей для задач;
Возможность обнаружить оверхед по капасити;
Безопасность хранения данных;
В дополнение: не хотелось выходить за рамки сервисов, имеющихся в компании.
Связи задач, быстрое перепланирование и отображение оверкапа по капасити сигнализируют о том, что диаграмма должна быть с хорошей автоматизацией. Наглядное отображение и доступ команды к просмотру намекают на какой-нибудь web-интерфейс.
С этим набором требований я и вышел в Интернет в поисках решения.
Существующие диаграммы и что с ними не так (в нашем случае)
На рынке существует миллион решений с диаграммой Ганта. Еще со времен работы в инди-студиях я пытался найти бесплатный и универсальный инструмент для отображения диаграммы Ганта и демонстрации простого роадмап. На тот момент я был более-менее знаком с решением OpenProj. Но помимо того, что он по КД крашится, он и нашим критериям не удовлетворяет. Также с этим решением у команды нет доступа к диаграмме в любой момент времени. Кстати, по этой же причине отпадает платный MS Project или плагины для MS Excel.
У нас была опция найти платный сервис и купить подписку на N участников команды. Но свой ресерч я начал с уже купленных инструментов. Поэтому на первой итерации отпали все онлайн-сервисы типа monday.com, teamgantt.com или любая другая из первых ссылок запроса в Google.
Почему не используем готовые решения
Как и многие другие студии, мы пользуемся классическим набором инструментов: Atlassian Jira/Confluence и, в дополнение к ним, у нас есть плагин Structure для Jira. Каждый сервис из этого набора предлагает свой вариант диаграммы Ганта.
Почему не Confluence
У «Конфлы» есть пара плагинов, один из них — Roadmap Planner. Он достаточно прост в использовании и нагляден. Однако он больше подходит для демонстрации роадмапов «широкими мазками», когда используешь не более чем 2–3 линий. Так как добавлять и перетаскивать блоки в этой диаграмме — боль еще та, не говоря уже о перепланировке и отсутствии связи между блоками, мы решили отказаться от диаграммы в Confluence. Второй плагин тоже не совсем подходил для построения серьезной диаграммы.
Почему не Jira/Structure
Видел на Хабре очень неплохую статью про удачный кейс использования плагина Structure в качестве диаграммы Ганта. Решение хорошо подходило для кейсов, описанных в той статье. Казалось, бы все хорошо, и наши критерии учтены:
внутренний и уже купленный инструмент — чек,
безопасность — чек,
наглядность и доступ для команды — чек,
связи и автоматизация — чек,
возможность быстро все перепланировать — чек.
Так чем же диаграмма от плагина нас не устроила?
Чтобы ответить на этот вопрос, нужно немного погрузиться в специфику нашей работы.
Разные отделы, разный скоуп задач, и не все из этого отражено в Jira. Существуют работы, которые не имеет смысла переносить в Jira в виде тикетов, например — регресс-тесты перед релизом. В данном кейсе единственное, что важно для планирования знать, — сколько людей будет задействовано и какая ожидается продолжительность работ. Конечно, это можно занести в Jira как тикет, но непонятно, зачем это нужно команде.
Если заносить все действия, необходимые для планирования в Jira, рождается много микроменеджмента. Как минимум, у всех тикетов должны быть даты начала и конца работы. Тикетов при этом может быть очень много, а работа не всегда идет в той последовательности, которая изначально была запланирована.
Также необходимость перепланировать или прикинуть совсем альтернативный вижен плана может ввести в заблуждение команду: внезапно даты у задач поменяются, и появятся новые непонятные задачи. Такие действия вызывают вопросы и волнение у команды.
Бывает, что для упрощения планирования требуется объединить несколько задач в одну, например — «работа клиент-программистов». Чтобы отобразить такое в Structure, придется создавать новую сущность, чего тоже совсем не хочется.
Все вышеперечисленное — это только часть проблем, с которыми придется столкнуться, ведя Гант только на базе задач в Jira. Так что наш последний шанс — Google Sheets.
Решение на базе Google-таблиц
Google-таблицы обладают широкими возможностями в плане визуализации и работы с данными. К тому же, в них есть поддержка скриптов на случай, если захочется чего-то совсем универсального (слышал, что на Google-таблицах даже делают простые игры). В общем, если покопаться в формулах и Интернете, то можно найти все необходимые составляющие для реализации диаграммы Ганта на базе Google-таблиц.
В итоге, немного поработав с формулами, правилами форматирования и совместив пару интересных задумок из разных существующих диаграмм на Google-таблицах, получилось сделать очень функциональную диаграмму с поддержкой связей, хорошей визуализацией и возможностью быстро вносить изменения — и, что самое главное, сразу видеть результат. Это решение закрыло практически все минусы рассматриваемых мной до этого сервисов.
Мы назвали эту диаграмму sGantt — сокращенно от smart Gantt. Дальше расскажу вам, чем такая таблица нам помогла, как мы с ней работаем, а затем разберем логику работы формул и правил форматирования.
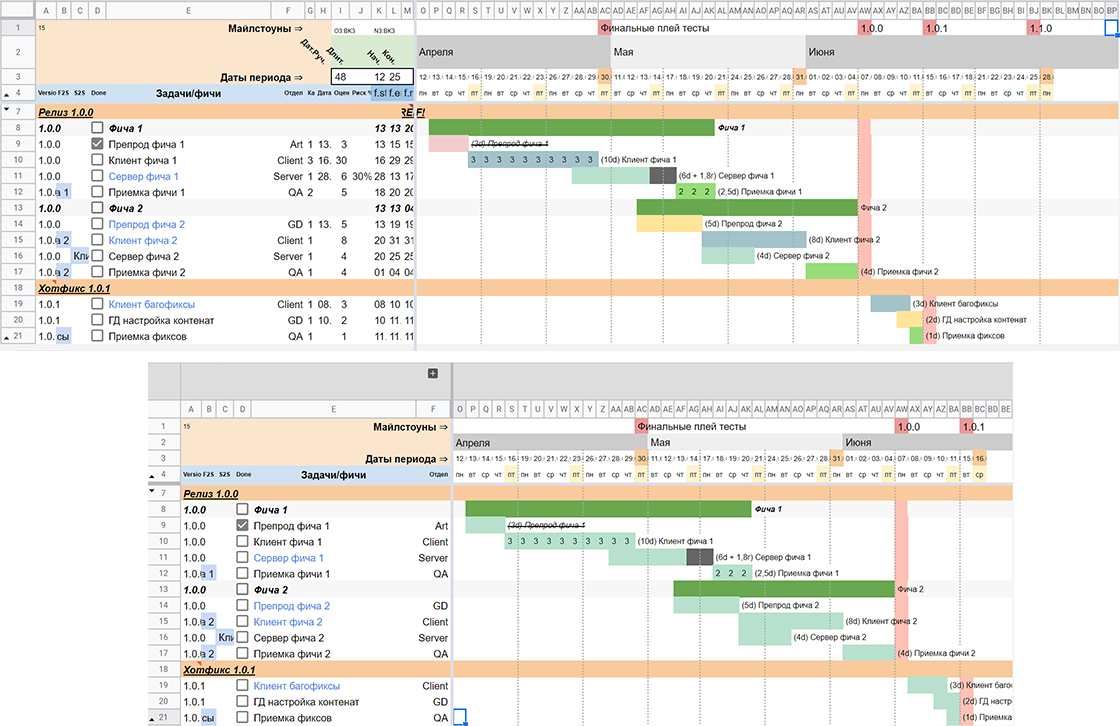 Пример финального вида sGantt с разным форматированием
Пример финального вида sGantt с разным форматированием Примеры разных вариантов реализации диаграммы на базе sGantt
Примеры разных вариантов реализации диаграммы на базе sGantt
Плюсы и минусы
К сожалению, нельзя сделать универсальный инструмент, особенно при наличии ограничений самой платформы. Поэтому немного заострю внимание на минусах — хотя для нас эти недостатки были незначительны по сравнению с плюсами.
Минусы
Основной минус, на мой взгляд, — это невозможность редактировать границу отрезка задачи прямо в таймлайне, как в других решениях, в которых вы просто тянете край отрезка задачи в нужную сторону. Его можно обойти, но тогда теряется львиная доля информации о блоке на таймлайне.
Еще одной иногда возникающей проблемой является отсутствие двойных связей на одну задачу. Иными словами, нельзя решить запрос «начать задачу А, когда самая поздняя из задач Б или В завершится».
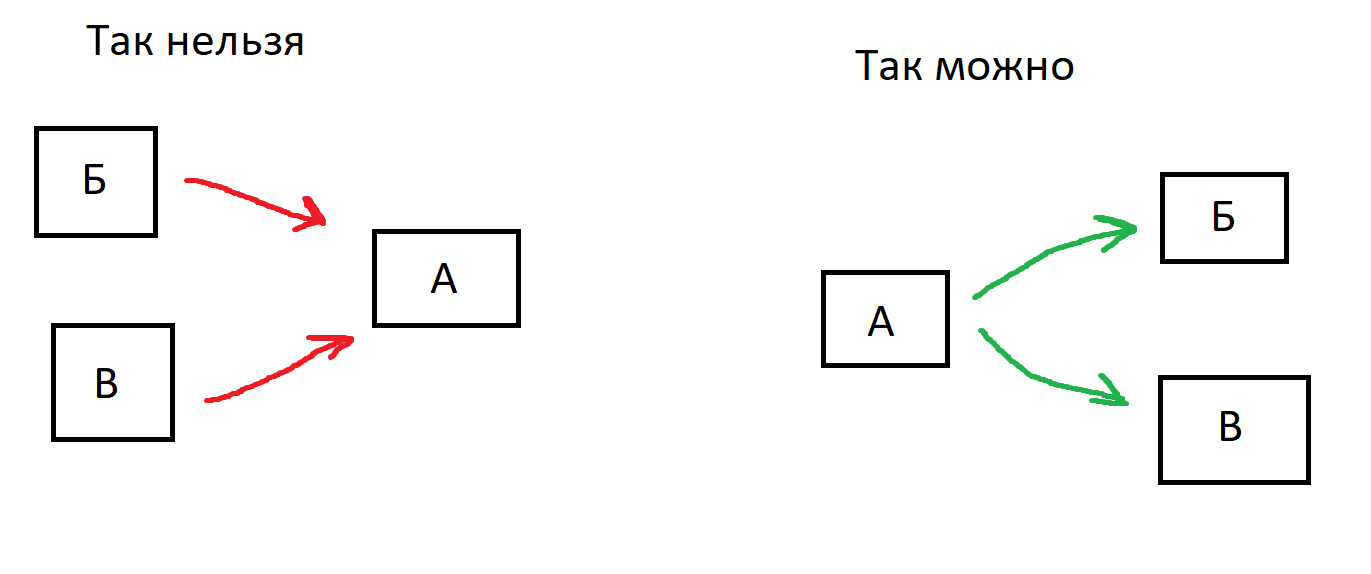 Иллюстрация ограничений связей
Иллюстрация ограничений связей
При именовании задач нужно использовать уникальные названия. К сожалению, поиск для связей тут основан на названии задачи. Да, можно попробовать улучшить решение, добавив генератор уникальных ID, но руки до этого у меня так и не дошли. К тому же, за все время использования каких-то особых проблем с созданием уникальными имен не возникло.
Также при создании новой строки в нее нужно скопировать формулу расчета дат. Этот минус обходится созданием достаточного количества строк заранее и копированием в них нужной формулы.
И последний, минорный минус: если сделать ОЧЕНЬ объемную диаграмму — более 400 строк — и растянуть план по времени на год вперед (при отображении каждого дня), обновление связей может занять некоторое время (от 30 секунд до минуты). Очень сомневаюсь, что в оперировании нужны такие огромные таблицы (по крайней мере, нам такое не требовалось). Но в случае, если нужен архив планирования, всегда можно завести отдельную таблицу архива и скопировать туда старые планы.
Плюсы
Высокая степень автоматизации, что позволяет избегать ошибок по глупости или из-за невнимательности;
Простота внесения и изменения данных;
Поддержка учета выходных, праздничных и нерабочих дней, что позволяет строить более точные планы;
Высокая скорость отображения внесенных изменений;
Поддержка связей между задачами (start-to-start и finish-to-start);
Возможность обозначения вех и вложенных работ;
Поддержка расчета рисков;
Гибкая настройка визуализации;
На основе базовых формул можно сделать разные таблицы — например, таблицу отпусков со статусами approved/not approved/finished или отобразить план-факт по задачам;
Базовые плюсы от платформы:
возможность одновременно редактировать таблицу нескольким людям;
возможность применять фильтры;
постоянный доступ команды к диаграмме;
возможность встроить таблицу в Confluence, Miro и прочее. Причем из Confluence диаграмму можно редактировать, не переходя в саму таблицу;
безопасность хранения данных.
Чем нам помогла такая таблица
До sGantt некоторые команды пользовались диаграммой Ганта с «ручным» закрашиванием ячеек в таблице. И первое, что стоит упомянуть при переходе на sGantt, — это значительное сокращение «ручной» работы с планированием релизов. Теперь при изменении планов можно поменять всего пару ячеек, а все остальное пересчитывается автоматически. Помимо этого, серьезно сократилось количество ошибок по невнимательности, таких как пересечение работ или оверхэд по капасити отделов.
Таблица поддерживает учет нерабочих и праздничных дней. Благодаря этому мы заранее стали обращать внимание на будущие сокращенные недели, что увеличило точность долгосрочного планирования.
Хорошая визуализация помогла команде проще понимать планы по проекту и его релизам. Команда своевременно узнавала о будущих передачах фич от одного отдела к другому.
Визуально стало проще осознавать отрезки времени. С диаграммой невольно понимаешь, что две абстрактные недели — это на самом всего деле 10 ячеек в таблице. Осознаешь, что объемную фичу с препродом, разработкой и приемкой сложно уложить в эти ячейки. Также стало проще показывать руководству, почему сроки именно такие, какие есть, и из чего они складываются, так как мы в диаграмме расписывали все необходимые виды работ.
При этом, когда нам нужно было быстро проверять теории оптимизации очередности фичей, мы просто копировали актуальную таблицу и из копии делали черновик. В нем мы работали, просчитывая все возможные маневры. Такие эксперименты проходили без ущерба текущей, актуальной диаграмме и не вызывали беспокойства команды.
Однозначным достижением таблицы я считаю тот факт, что однажды я смог значительно переделать планы по релизу только с помощью телефона и мобильного интернета, находясь при этом в метро. Более того, этот необычный опыт не вызвал у меня какого-то дискомфорта и не отнял много времени.
Помимо очевидной сферы применения диаграммы (планирования работ), мы также закрыли некоторые смежные задачи:
расчет и проверка капасити команды и отделов;
отображение последовательности работ для каждого отдела;
наглядное отражение планов по отпускам.
 Пример таблицы отпусков
Пример таблицы отпусков
Как мы работаем с таблицей
А теперь давайте познакомимся с принципом работы в таблице на примере добавления третьей фичи в план (две уже есть — см. рисунок ниже). Начнем с уже настроенной таблицы, а затем посмотрим, как работать с «голой таблицей».
Для удобства чтения текущей главы рекомендую открыть на соседней вкладке шаблон диаграммы (ссылка на шаблон) и проделывать все действия параллельно с чтением пунктов.
 Пример таблицы с двумя фичами
Пример таблицы с двумя фичами
Чтобы отобразить работу на таймлайне, нужно совершить шесть простых действий:
Добавить новую строку;
Скопировать в нее формулы из любой заполненной строки (ячейки K, L и M);
Дать строке название — это будет название задачи;
Указывать ответственный отдел (или вид работ — зависит от настроек);
Отметить, сколько работа займет человеко-дней;
Выбрать дату начала работы.
Выглядит достаточно просто, учитывая, что первые два действия можно сделать в начале работы с таблицей, добавив сразу около 100 строк и скопировав в них необходимые формулы.
Теперь давайте более подробно рассмотрим каждое из этих действий, а затем укажем связи в задачах и, наконец, обозначим вехи для скоупов работ и релизов.
Добавление задач
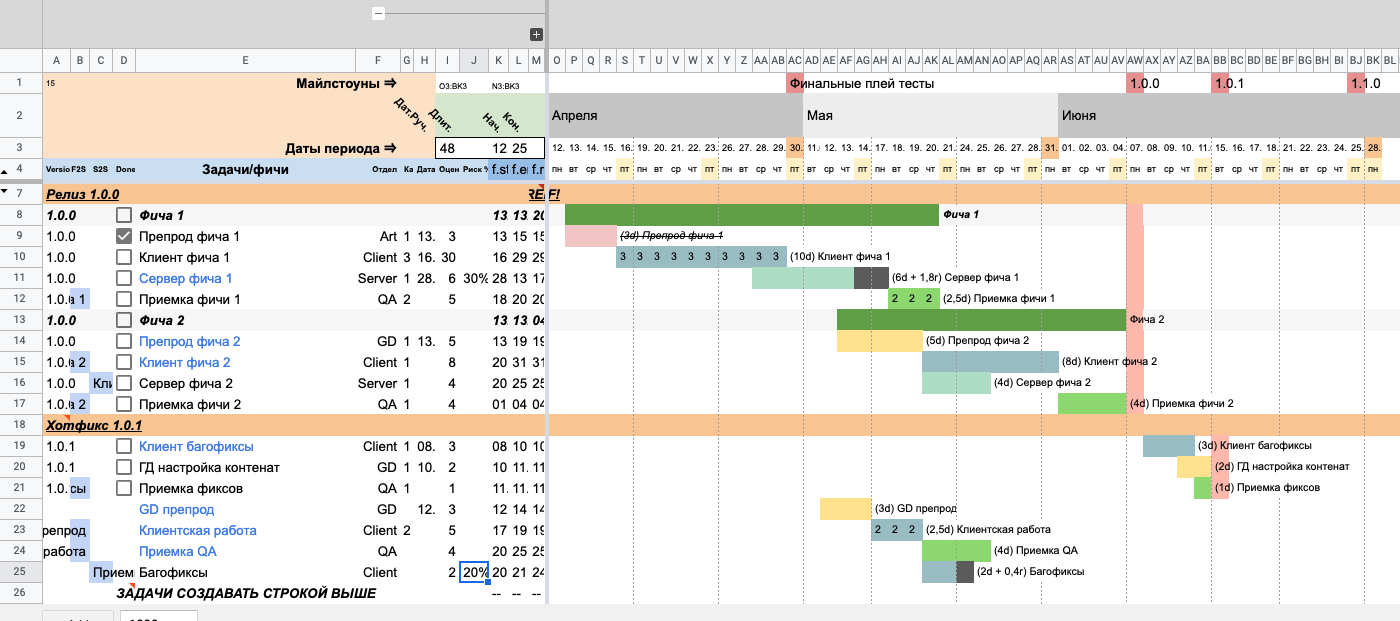
Продолжим разбирать пример из иллюстрации выше. Предположим, что нам нужна абстрактная «Фича 3». В нее будут входить три типа работ: «GD препрод», «Клиентская работа» и «Приемка QA».
Добавляем несколько новых строк сразу под задачей «Приемка фиксов». Часть ячеек справа подсветилась желтым. Это значит, что в них нет формул, так что давайте это исправим.
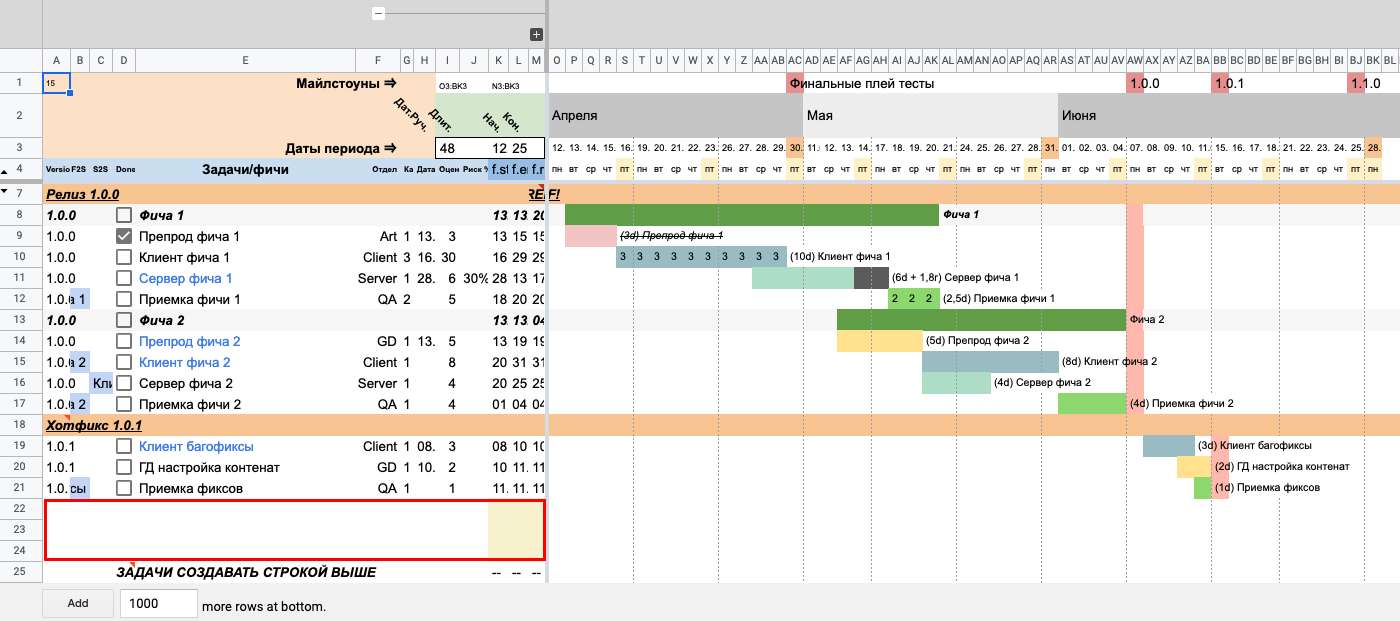
Копируем формулы из заполненной строки (K, L и M) и вставляем во все строки ниже. В ячейках появилась ошибка #REF!, но это нормально: она пропадет, когда мы заполним данные в строках. Почему так получается, разберемся позже.
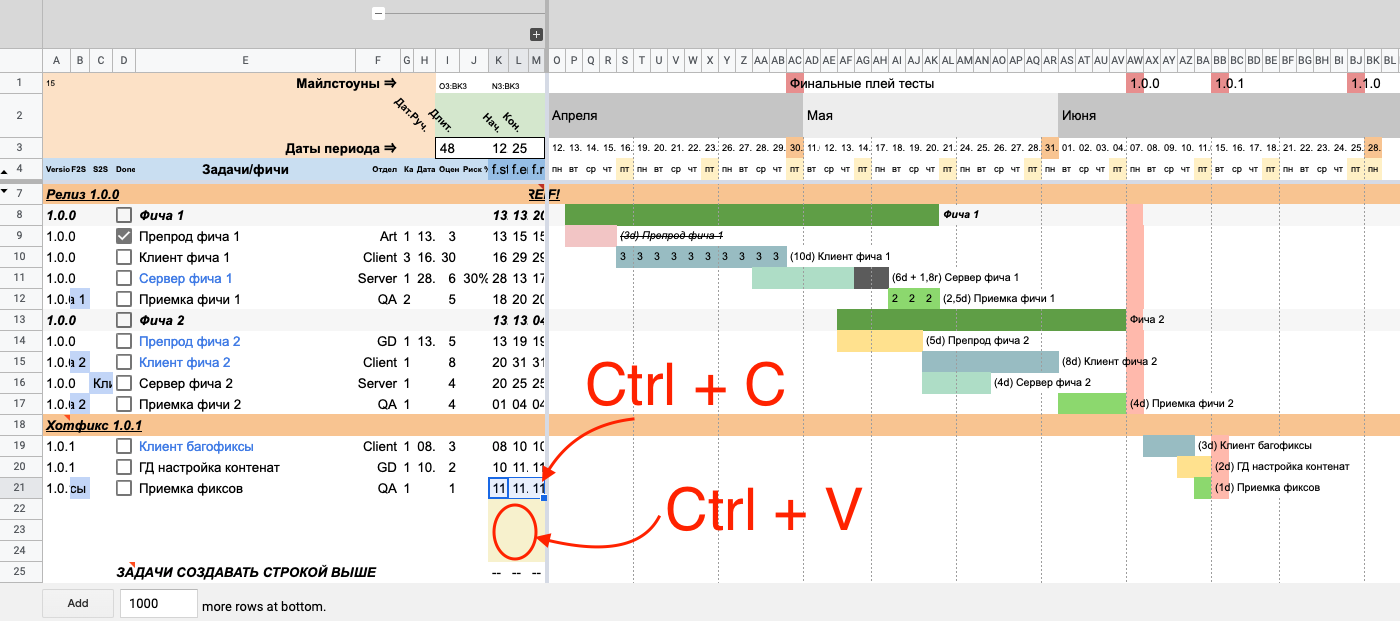 До копирования
До копирования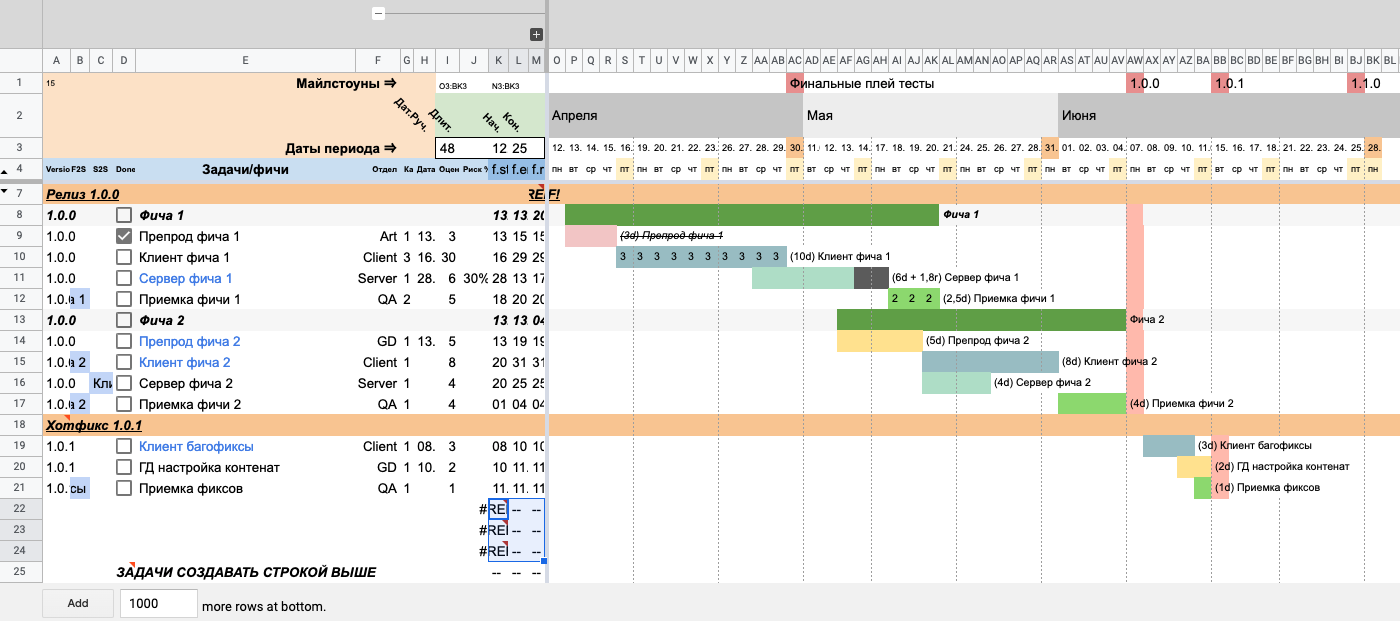 После копирования
После копированияНаполняем строки информацией о задаче. Добавим в них названия «GD препрод», «Клиентская работа» и «Приемка QA».
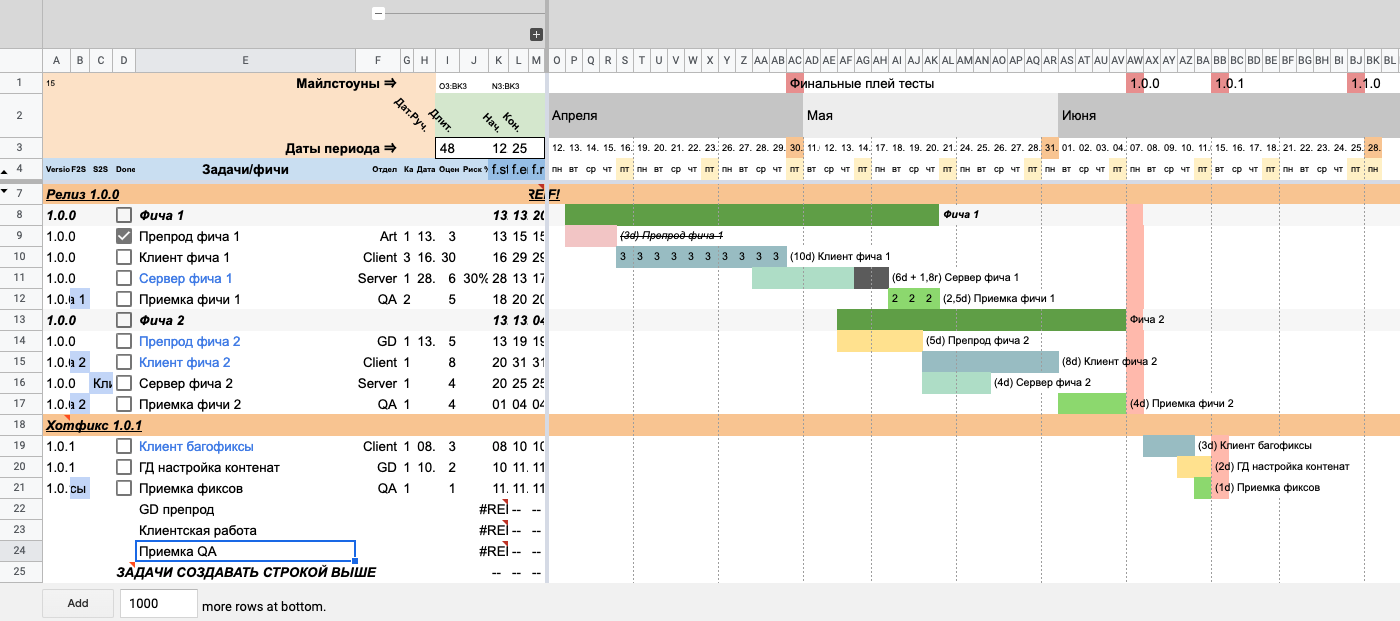 Добавляем названия задач в строках 22–24
Добавляем названия задач в строках 22–24Указываем соответствующие отделы для каждой строки. В будущем это подкрасит линию на таймлайне в заданный цвет отдела. Обратите внимание, что ошибка #REF! пропала.
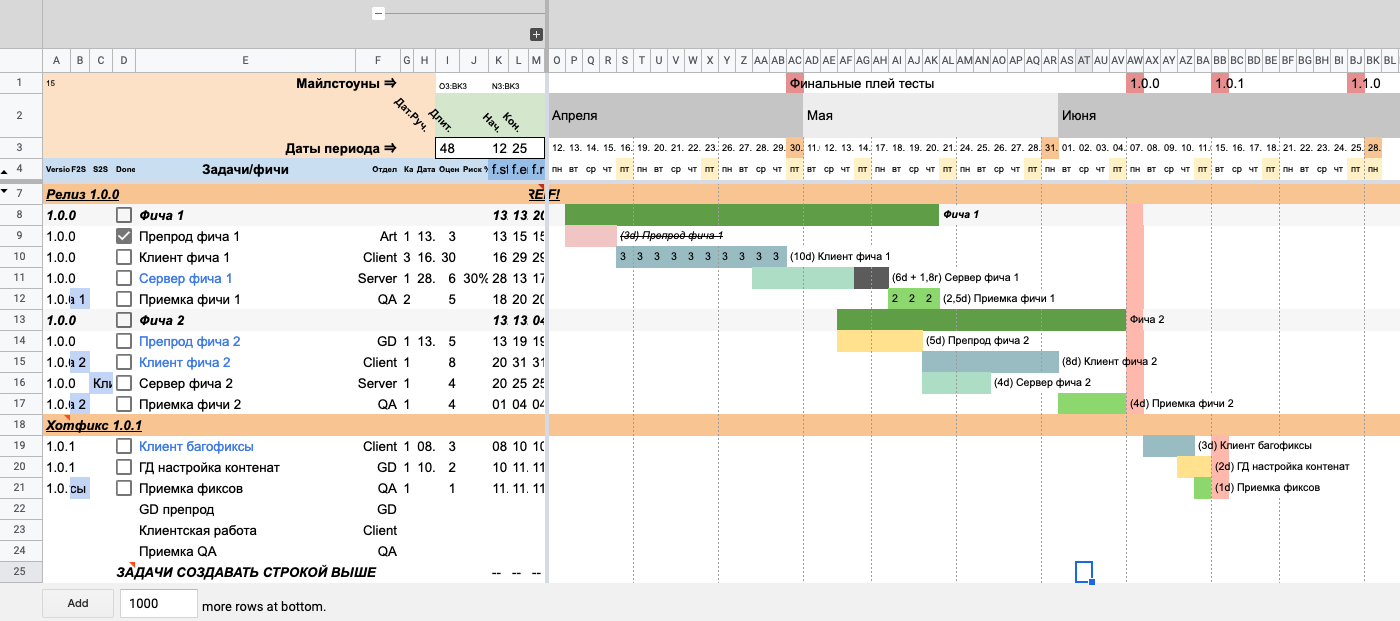 Здесь мы добавили отделы в строках 22–24
Здесь мы добавили отделы в строках 22–24Проставляем оценку задачи в человекоднях.
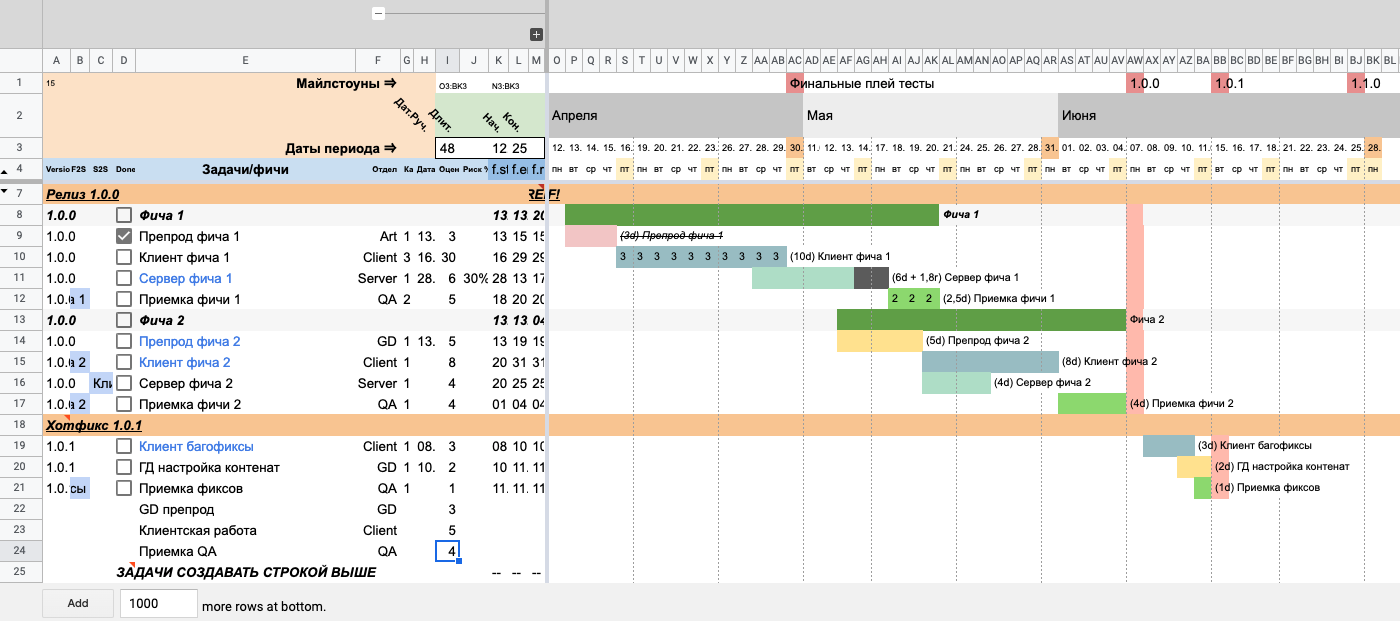
Указываем дату начала работы над «GD препродом». Дату можно как написать руками, так и выбрать из выпадающего списка, кликнув два раза на ячейку.
Сразу после выставления даты в ячейке на таймлайне появляется отрезок, обозначающий продолжительность работы над задачей. Так произошло, потому что мы заполнили все необходимые для этого поля. При этом отрезок имеет желтый цвет, так как в задаче указан отдел GD.
Мы можем аналогично заполнить оставшиеся строки, но лучше воспользуемся связями и посмотрим, для чего нужны незаполненные ячейки.
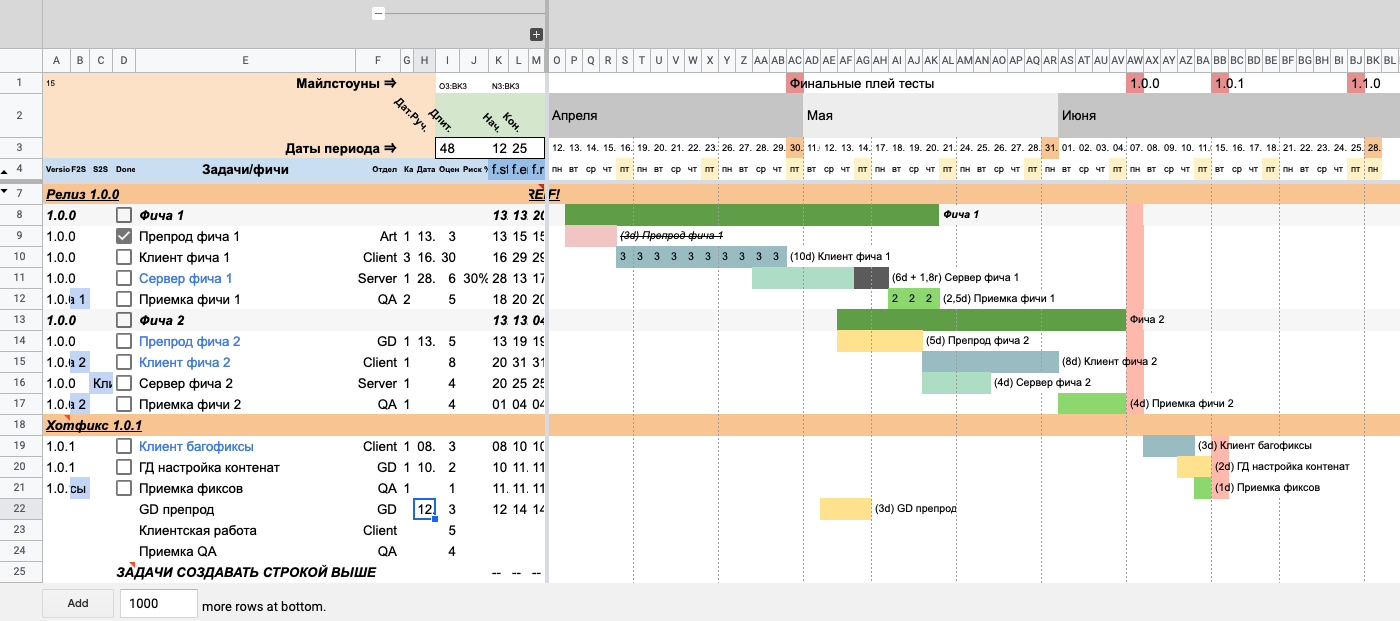 Иллюстрация с отрезком работы на шкале времени для GD препрода (строка 22)
Иллюстрация с отрезком работы на шкале времени для GD препрода (строка 22)
Связи
В качестве примера предположим, что «Работа клиента» начнется сразу после завершения работы над «GD Препродом», а «Приемка QA» начнется после завершения работы на клиенте. Таким образом, вырисовывается цепочка связей: «GD Препрод» → «Работа клиента» → «Приемка QA». В этом случае мы используем связь f2s (finish-2-start).
Приступим.
В поле f2s (колонка B) для задачи «Работа клиента» указываем название связанной (предшествующей) задачи. В данном случае это будет «GD Препрод».
Аналогичным образом указываем связь для «Приемки QA». Поэтому в соответствующем поле выбираем или пишем «Работа клиента».
В ячейках связей, так же как и поле с выбором даты начала задачи, предусмотрен выпадающий список, в котором перечислены все имеющиеся наименования задач.
После установки связей, задачи сразу появились на шкале времени. Это произошло, потому что при наличии связи данные о начале работы не требуются. При этом если указать дату начала работы, ничего не произойдет. Связь всегда важнее указанной даты.
Также можно увидеть, что названия «GD Препрод» и «Работа клиента» стали синими. Это означает, что на них ссылаются другие задачи.
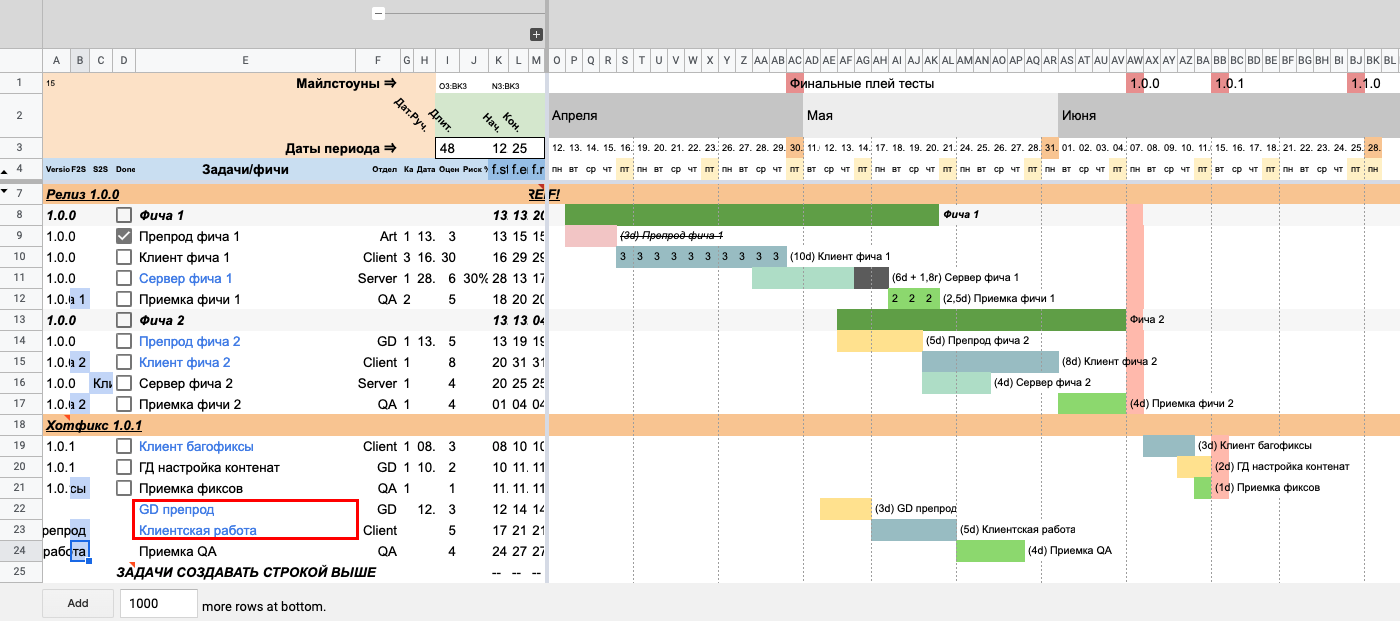
Чтобы продемонстрировать работу связи s2s (start-to-start) добавим еще одну задачу — «Багофиксы». Предположим, что команда будет фиксить проект параллельно с приемкой QA.
Для этого указываем в поле s2s (колонка C) название задачи, вместе с которой должны стартовать «Багофиксы». В данном случае это «Приемка QA».
Обратим внимание, что если не указывать продолжительность работы над задачей, на таймлайне все равно появится данная задача. Однако такое работает только для связей.
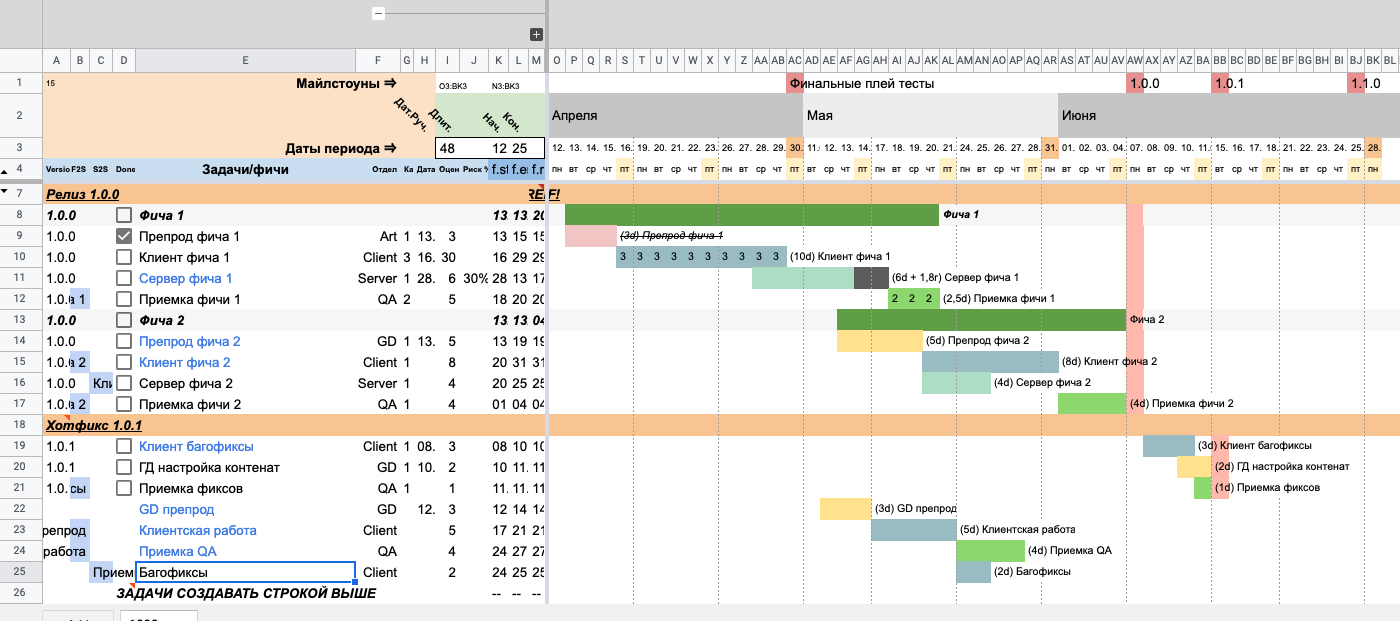 Таблица со связанными задачами s2s
Таблица со связанными задачами s2s
Капасити и риски
У нас остались два незаполненных поля: капасити и риски. Капасити позволяет указать, сколько сотрудников работает над задачей. Риски, в свою очередь, указываются в процентах и добавляют определенное количество человеко-дней к уже заданной оценке.
Добавим к задаче капасити. Предположим, что клиентскую работу будут выполнять два программиста.
В соответствующей ячейке (колонка G) ставим цифру 2 (количество исполнителей).
Отрезок с задачей на таймлайне изменился. Мы указали оценку в 5 человеко-дней, но на диаграмме видим 3 дня и рядом в уточнении — 2,5 дня. Это логично, так как задачей занимаются 2 исполнителя, и указанные 5 человеко-дней превращаются в 2,5 рабочих дня. Но для отрезка на диаграмме дни округляются в большую сторону, поэтому на таймлайне закрашено 3 рабочих дня.
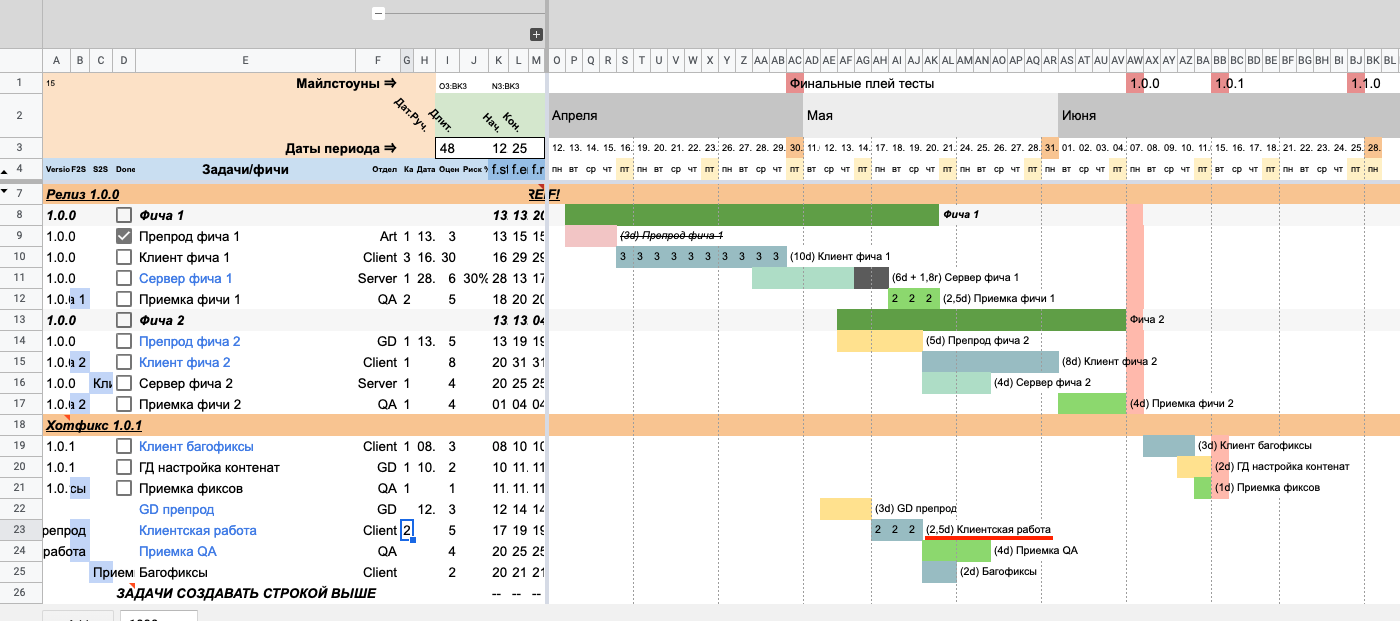 Обращаем внимание на подчеркивание 2,5 дней таймлайне
Обращаем внимание на подчеркивание 2,5 дней таймлайнеОбратите внимание, что количество человек показывается на линии на шкале времени. Сделано это для упрощения просмотра количества исполнителей. Числа на отрезке появляются, если исполнителей больше одного человека. Если капасити не указывать, будет считаться, что над задачей работает 0 человек.
На листе «Capacity overview» можно посмотреть, нет ли оверкапа по капасити, и в целом оценить загруженность отдела. Единственное: нужно убедиться, что в каждой ячейке этого листа есть формула.
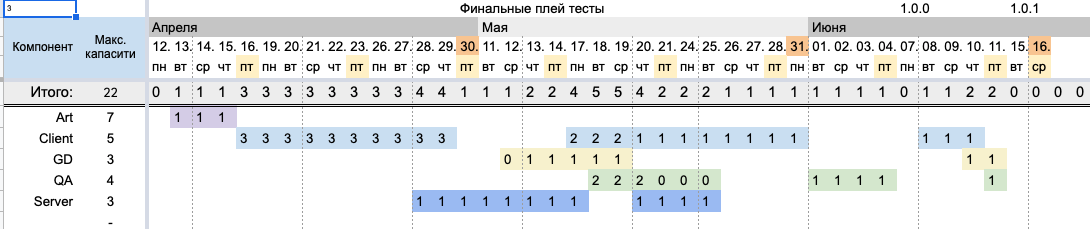 Лист капасити
Лист капаситиТеперь добавим риски. Самое реалистичное в рассматриваемом примере — это добавить риск к задаче «Багофиксы», так как обычно сложно заранее предугадать, какое время займет решение того или иного бага.
Указываем риски в процентах. На строке с задачей «Багофиксы» в соответствующем поле (колонка J) вписываем нужное нам значение — например, 20%.
Риски сразу отображаются на таймлайне черным цветом как продолжение отрезка соответствующей задачи.
 Риски
Риски
Вехи — блоки работ (скоупы)
Мы уже знаем достаточно, чтобы добавлять задачи, связывать их и составлять какие-то планы. Однако для комфортной работы можно добавить и еще пару визуальных улучшений. Речь идет про вехи, они же майлстоуны.
Давайте объединим наши задачи в один блок (скоуп работ) и назовем его «Фича 3».
Для этого создаем новую строку над первой задачей в нашей фиче — «GD препродом»;
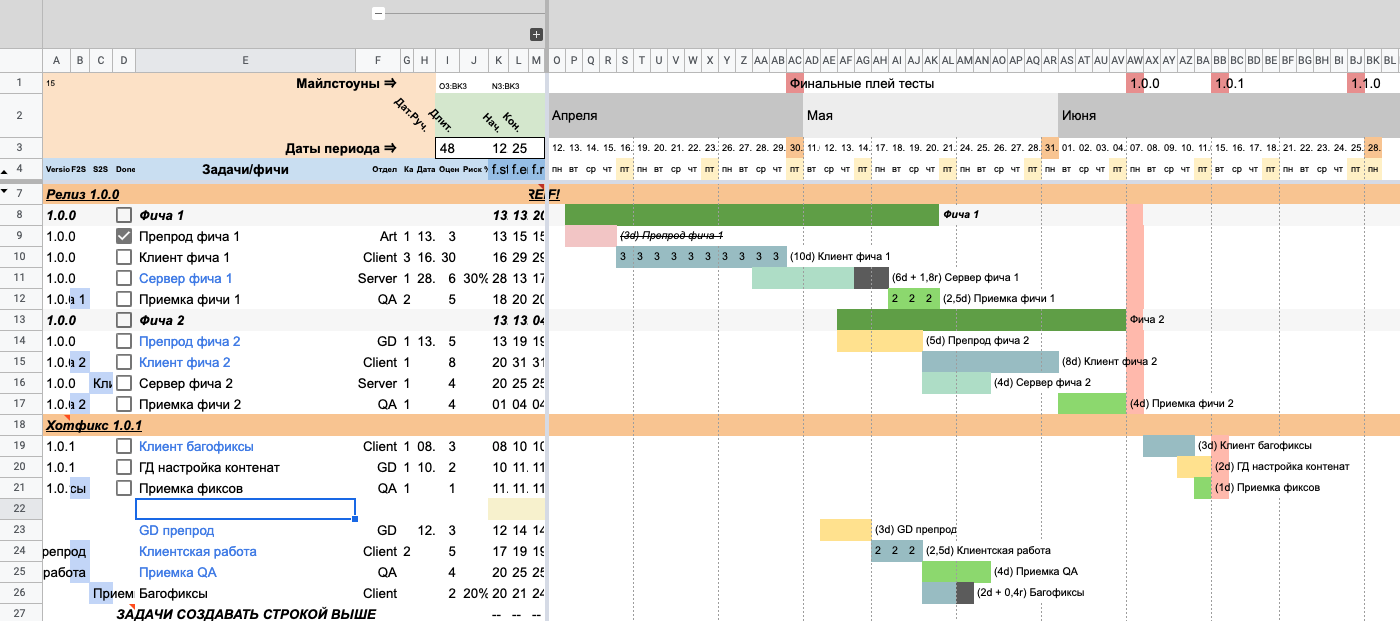 Обратите внимание на пустую строку над «GD препродом»
Обратите внимание на пустую строку над «GD препродом»Добавляем название «Фича 3»;
Копируем формулы из любой строки (выше или ниже) и вставляем их в строку нашего скоупа — «Фича 3».
Обращаем внимание, что на шкале времени сразу появился зеленый отрезок с названием «Фича 3», который начинается в день старта «GD препрода» и заканчивается в день «Приемки QA». Это и есть блок работ или скоуп.
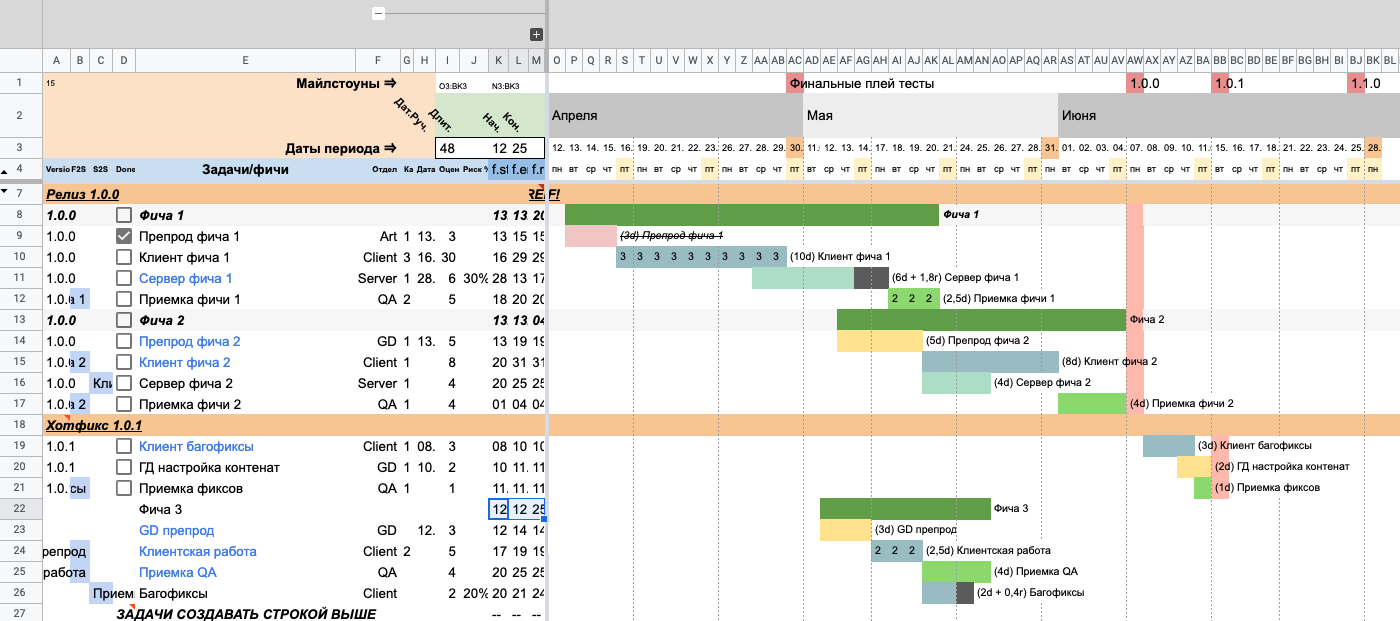 Иллюстрация с отрезком «Фичи 3»
Иллюстрация с отрезком «Фичи 3»Этот скоуп определяется по простой логике: если в строке указано только название и при этом отсутствует отдел, то эта строка — блок работ, а не задача.
Если в строке указывается скоуп работ, то формула для определения дат (колонки K, L и M) ищет следующую строку с блоком работ, то есть — без указанного отдела. Когда формула находит такую строку, все задачи до следующего блока будут принадлежать текущему. Отсюда следует, что все задачи всегда должны иметь указанный отдел, иначе эта строка будет считаться блоком работ.
По этой причине и возникала ошибка #REF! в пустой таблице: таблица считала, что все строки — это блоки работ, но без задач внутри, и каждый блок не мог найти свои даты начала и конца.
Чтобы лучше выделить блок работ на таймлайне, мы можем оформить его в виде сепаратора. Для этого в самой первой ячейке пишем или выбираем номер релиза. В нашем случае присваиваем релиз 1.1.0.
Можно заметить, как после этого вся линия покрасилась сероватым цветом, а шрифт стал жирным. Теперь скоуп работ выглядит как сепаратор.
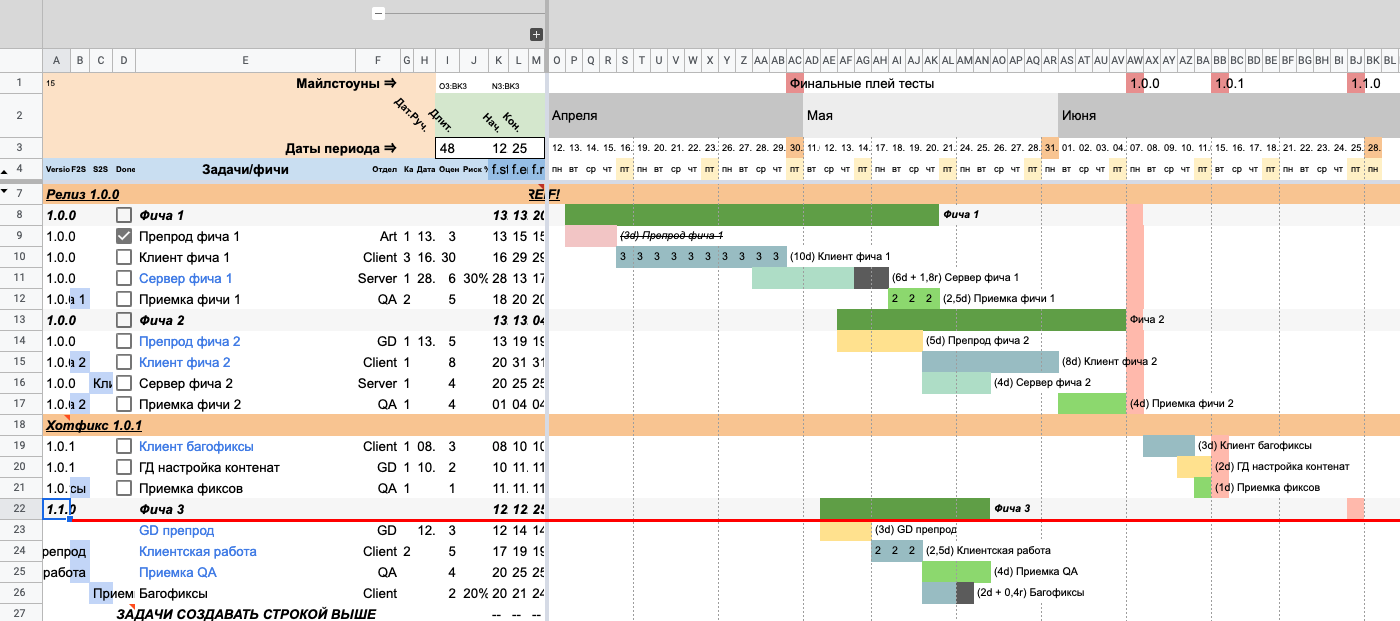 Иллюстрация фичи-сепаратора
Иллюстрация фичи-сепаратора
Вехи — релизы
Наконец, вишенкой на торте будет отделение нашей новой фичи в другой релиз.
Как и раньше, добавляем новую строку над «Фича 3».
Указываем название релиза, но уже в поле «Version» (колонка A). Назовем его «Новый релиз 1.1.0».
Вся линия сразу покрасилась в рыжий цвет, а название релиза стало жирным подчеркнутым. Больше никаких дополнительных полей заполнять не нужно. Релизом считается строчка, в которой заполнено только первое поле «Version» и больше ничего.
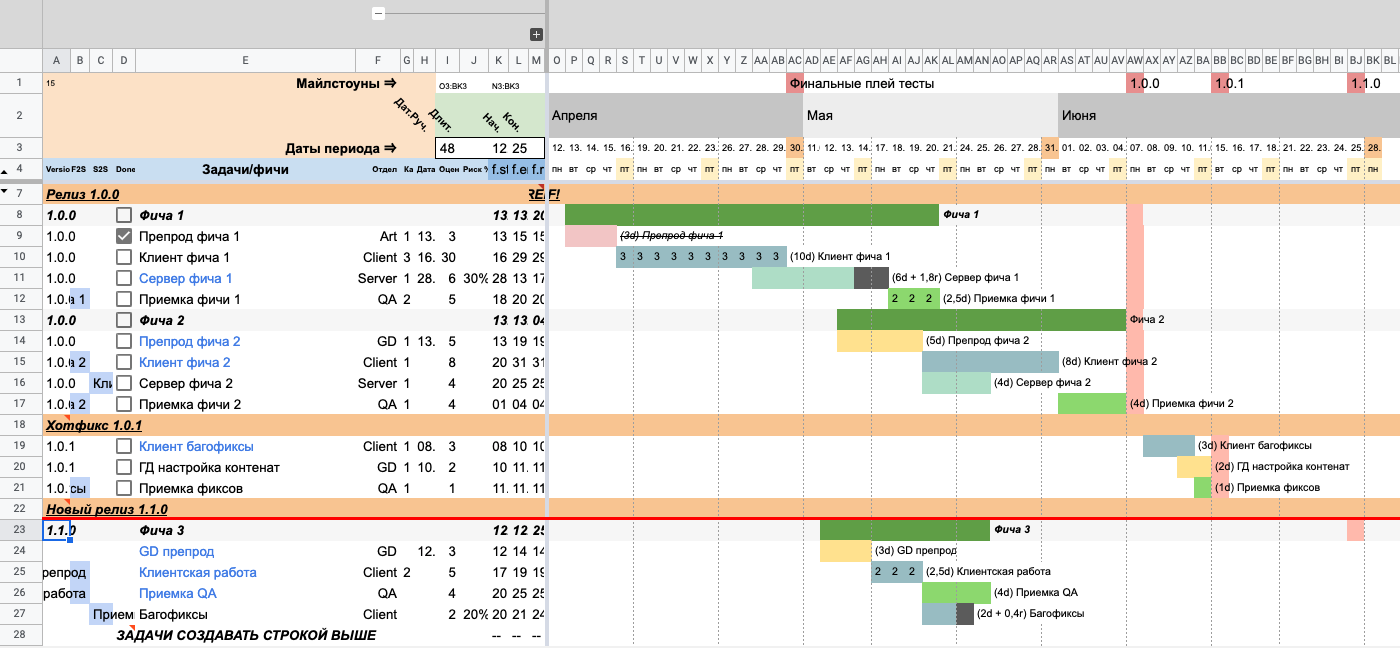 Иллюстрация сепаратора релиза
Иллюстрация сепаратора релизаТеперь будет удобно присвоить задачам номер релиза, чтобы на шкале времени можно было увидеть дедлайн по срокам. Для этого выставляем нужный нам номер релиза в первой ячейке для каждой интересующей нас строки.
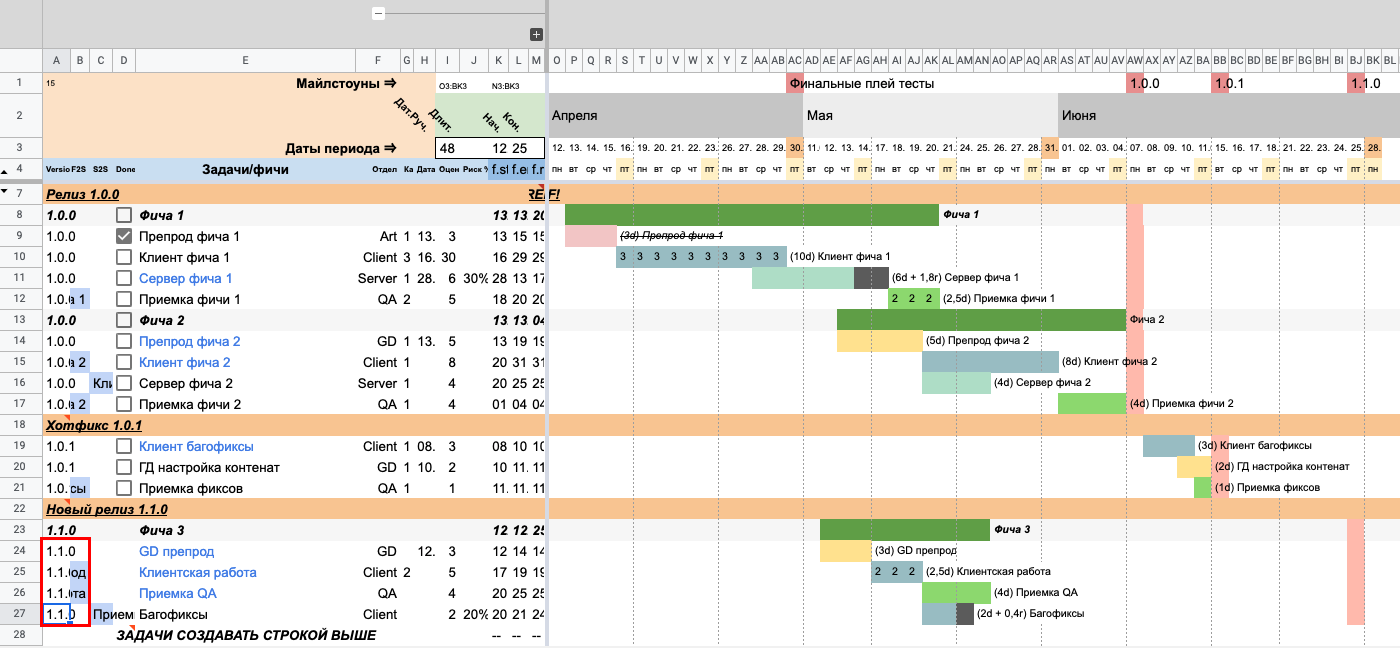 Проставляем релиз
Проставляем релизНа таймлайне появилась граница в виде красной отметки напротив каждой задачи, для которой мы указали номер релиза. Этот номер и привязанная к нему дата задаются в настройках таблицы, о которых мы поговорим чуть позже.
Чтобы сделать диаграмму максимально удобной, можно объединить все задачи под скоупами в группы (стандартной функцией таблиц) и скопировать чекбоксы со строк выше (это позволит отметить факт выполнения задачи).
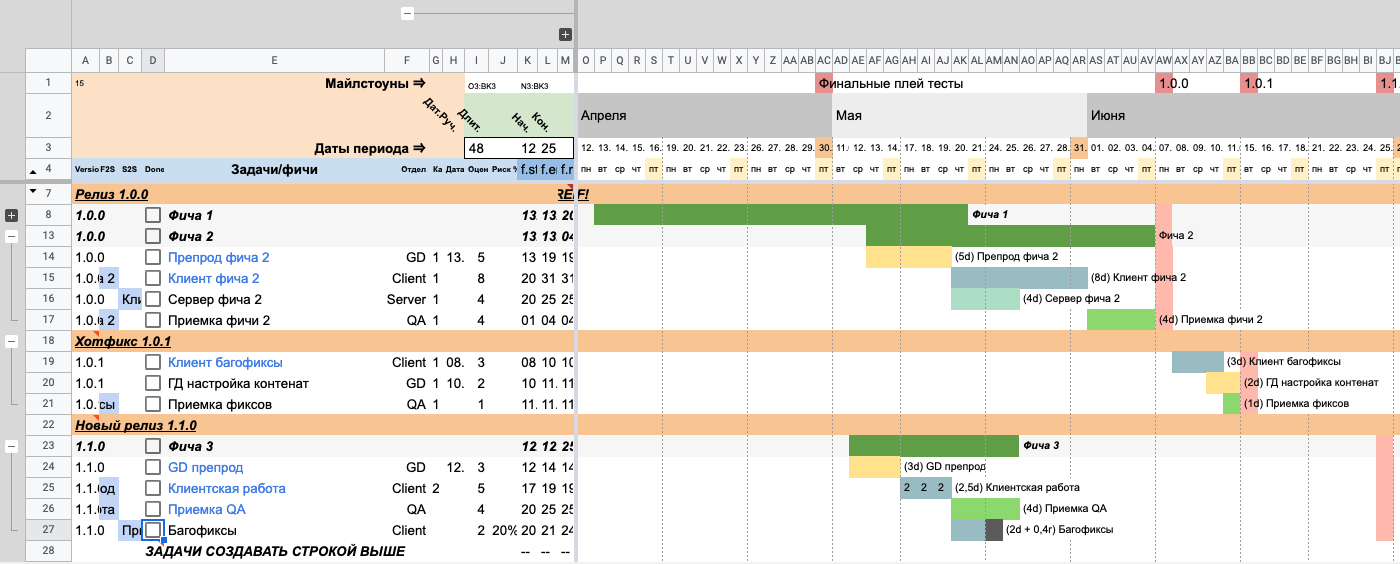 Картинка с объединенными группами
Картинка с объединенными группами
Промежуточный итог
Теперь вы знаете почти все необходимое, чтобы свободно добавлять задачи в таблицу и строить планы, разбивая их на релизы и скоупы. Мы успели узнать, как добавлять задачи, связывать их, делать вехи и указывать релизы. Поняли, что в зависимости от заполненных ячеек строка может быть релизом, блоком работ или задачей (см. таблицу ниже).
Тип | Обязательно заполнить поля |
Релиз | Текст в первой ячейке (остальное можно удалить). |
Блок (скоуп) работ | Майлстоун в первой ячейке (для окрашивания). Название блока работ (колонка E). Формулы. |
Задача | Название задачи (колонка E). Отдел. Формулы. |
Для полного комфорта нам осталось разобраться в том, как указать свой отрезок времени проекта и как настраивать таблицу.
Работа с пустой таблицей
Прежде, чем говорить о настройках, закроем последний вопрос, связанный с работой в основной диаграмме, — выбор дат для проекта.
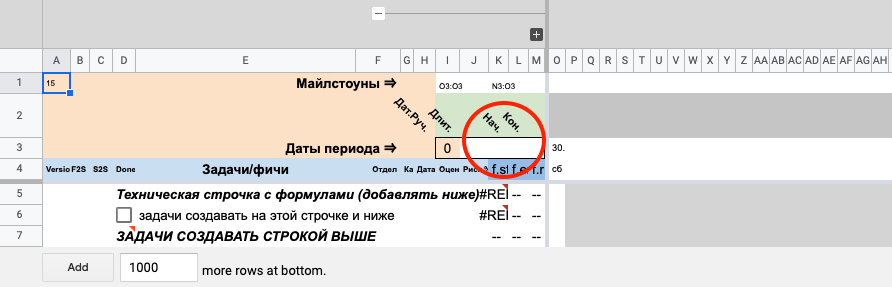
Так выглядит незаполненная таблица. Выберем в ней временной отрезок, скроем лишние поля и добавим пару строк для подготовки к заполнению. Первое, что мы делаем — указываем даты проекта.
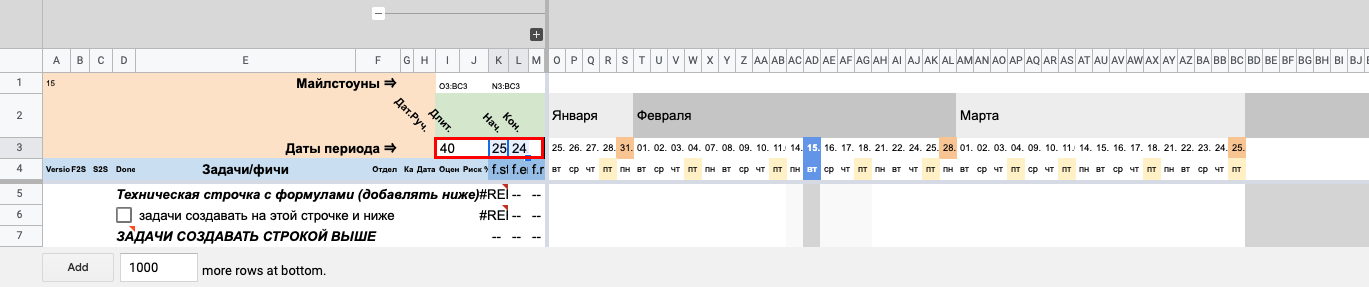 Здесь показано, куда вставлять числа, и сразу картинка с результатом
Здесь показано, куда вставлять числа, и сразу картинка с результатом
В ячейках K3 и L3 двойным кликом вызываем виджет календаря и выбираем интересующие нас даты начала и конца интересующего нас отрезка. Видим, что в правой части таблицы появились даты, названия месяцев и дни недели.
Лишние незаполненные столбцы в правой части можно удалить, чтобы они не мешались и чтобы таблица быстрее рассчитывала условное форматирование (чем меньше ячеек, тем быстрее будет работать таблица). Если удалить лишние, таблица вернет их обратно сама.
Теперь добавим пару строк для работы с задачами. Под строкой с названием «задачи создавать на этой строчке и ниже» создаем нужное нам количество строк.
Копируем в них формулы, чтобы не делать это каждый раз при создании задачи
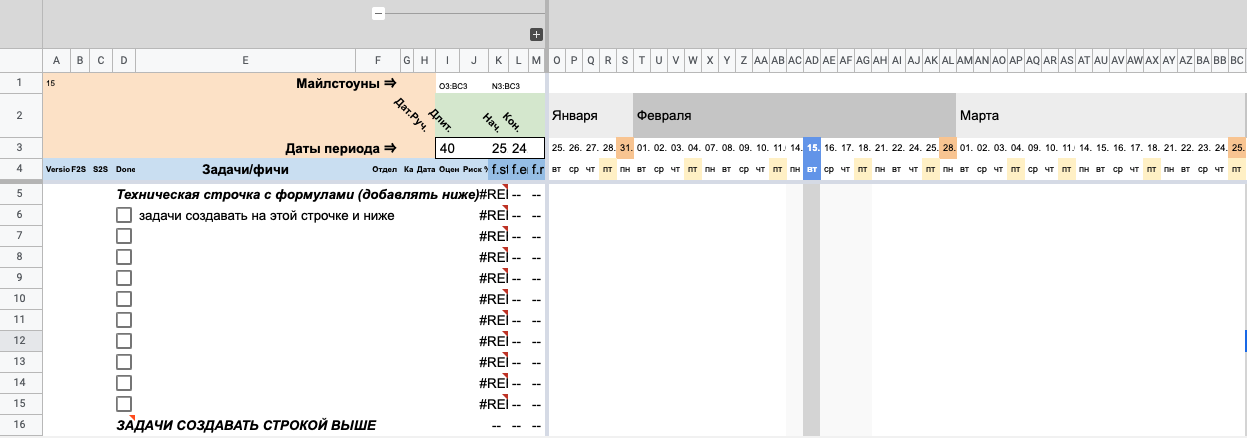
Для удобства скрываем техническую строку с названием «Техническая строчка с формулами (добавлять ниже)». Также по желанию можно скрыть последнюю строку «ЗАДАЧИ СОЗДАВАТЬ СТРОКОЙ ВЫШЕ». Скрыть строки можно, кликнув правой кнопкой по номеру строки и выбрав пункт меню «Скрыть строку».
Скрываем мы их, чтобы случайно не удалить или не переместить в другое место. Случайное перемещение может сломать диапазоны в формулах. В первой строке содержатся основные формулы с диапазонами, для которых важно, чтобы первая и последняя строки были именно первой и последней.
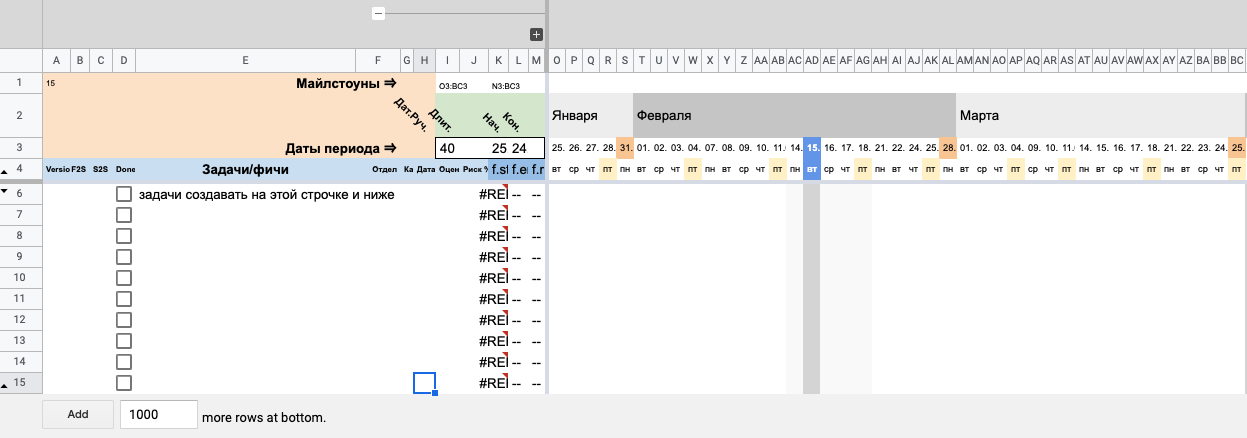 Здесь мы скрываем строку и результат
Здесь мы скрываем строку и результатТеперь было бы неплохо разделить недели вертикальными сепараторами. Если вы были внимательны, то могли заметить, что в строке меню у таблицы есть пункт «Scripts». В нем находится специальная функция, которая визуально разделяет таймлайн на недели.
Обращу внимание, что для работы скрипта в ячейке A1 обязательно должен быть номер колонки, с которой начинается таймлайн.

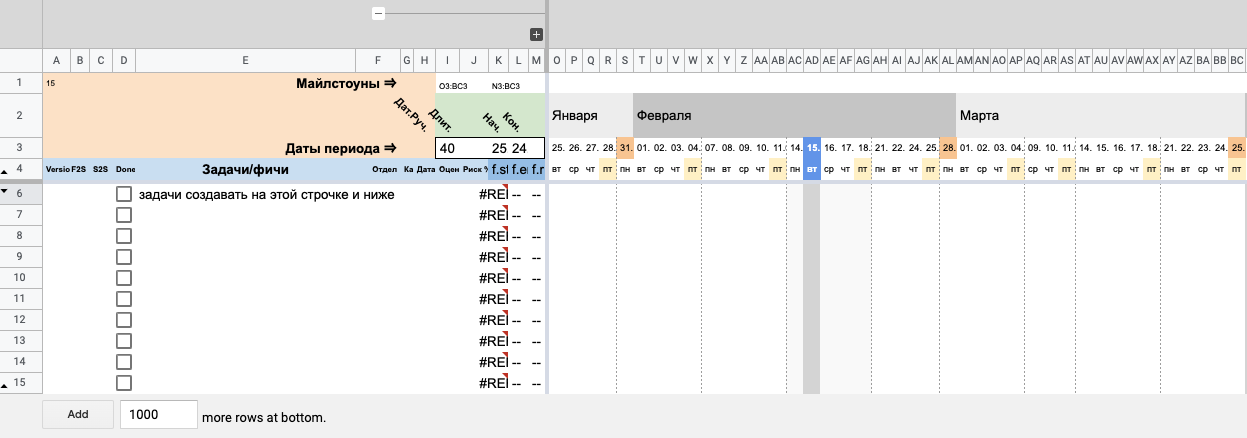
На этом все: наша таблица полностью готова к работе. Что делать дальше для заполнения диаграммы, вы уже знаете.
Теперь перейдем к теме настроек таблицы.
Настройка таблицы
В таблице есть лист с названием «Tech Lists». Это лист с настройкам диаграммы. Давайте посмотрим на него пристальнее и изучим, какие в нем есть параметры.
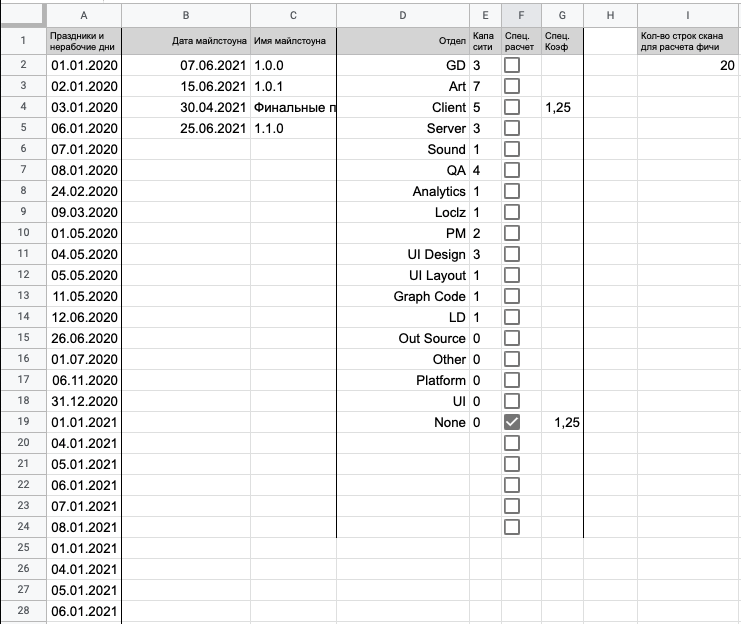
Раздел | Описание | Применение |
|---|---|---|
Праздники и нерабочие дни Колонка A | В колонке указываются все праздничные дни за интересующий нас промежуток времени. Выходные дни (сб и вс) указывать не нужно, так как они учитываются автоматически. | Указанные дни не будут отображаться на линии времени в диаграмме Ганта. |
Майлстоуны и релизы Колонки B и C | Раздел отвечает за отображение релизов и майлстоунов на шкале времени в диаграмме. В первой колонке указывается дата майлстоуна, во второй колонке — его название. | На диаграмме майлстоуны автоматически отображаются в верхней части шкалы времени, если на шкале есть дата, соответствующая майлстоуну. |
Отделы или виды работ Колонки D, E, F и G | В данном разделе можно отобразить отделы или виды работ (кому как удобнее). Рядом с отделом можно указать максимально доступное количество исполнителей (капасити). Также есть дополнительная опция для учета специального коэффициента при оценке. Этот коэффициент игнорируется, пока не будет установлена галочка напротив отдела (как в примере у отдела «None»). | Указанные отделы будут доступны для выбора в ячейке отдела по двойному клику при заполнении диаграммы. Капасити используется для проверки оверкапа по задачам в листе «Capacity overview». Специальный коэффициент нужен для учета фиксированных рисков при оценке в днях. Например, когда мы знаем, что 1 день — это 1,5 дня с учетом встреч и прочего. |
Вместимость скоупа работ Колонка I | В этой колонке указывается, сколько строчке вниз нужно смотреть формуле, чтобы найти следующий скоуп. | Можно сказать, что значение этого параметра — это сколько задач может вместить в себя блок работ. |
Итоги по работе с таблицей
Мы с вами изучили все аспекты работы с таблицей. Теперь вы можете скопировать себе шаблонную таблицу (ссылка на шаблон) из примера и полноценно в ней работать, настроив ее полностью под свои нужны.
Однако, чтобы вы могли настраивать ее максимально гибко, нужно понимать, как работают формулы и правила условного форматирования. Когда вы это осознаете, для вас не будет препятствий в кастомизации этой диаграммы. Вы сможете свободно удалять и добавлять нужные вам колонки и писать новые функции без страха что-то сломать.
Но о логике работы формул в таблице я расскажу подробнее в следующей статье.
