Kafka: что нужно знать тестировщику? Часть 1
Всем привет!
В этой серии из нескольких статей мы разберемся, что делать тестировщику на проекте с кафкой (как впервые, так и имея какой-то опыт). Здесь я не буду говорить о брокерах и zookeeper-ах, о том, как развернуть кафку. Но мы разберемся, как её настроить и как с её помощью тестировать ваши микросервисы.
Начнём с «базы» (точнее, теории).
Apache Kafka — распределённый программный брокер сообщений с открытым исходным кодом, разрабатываемый в рамках фонда Apache на языках Java и Scala.

Что такое кафка?
Кафку можно представить как большую трубу, внутри которой много трубочек поменьше.

А если проще?
Представим, что есть 2 микросервиса: один должен писать данные, а второй — читать. И между ними поместили кафку, как трубу, через которую данные должны двигаться от одного сервиса к другому.
Простыми словами, у нас есть микросервис, который что-то пишет, а второй его читает.

Если эту схему расширить, получается, что писать и читать одну и ту же кафку могут разные микросервисы в направлениях «туда» и «обратно».
Представим себе новостной портал, состоящий из нескольких микросервисов. Один микросервис получил по API какие-то данные, например, что в веб-версии какого-то приложения пользователь прочитал новость. Он это обработал, может, даже что-то себе в БД записал и передал через кафку другому. Другой микросервис также это прочитал и записал к себе в БД, например, для истории, когда пользователь читает новости — утром или вечером. Допустим, есть еще мобильное приложение, и тут проблема — пользователь в веб-версии новость уже прочитал, и в приложении она не должна у него светиться как непрочитанная. Мы снова кидаем сообщение в кафку, чтобы отобразить в приложении актуальный статус.
Можно сказать, что это обмен данными в реальном времени.

Уже должно быть больше похоже на первую схему вверху статьи.
Микросервис, который пишет, — это продюсер, а тот, который читает, — консьюмер.

Уровни доступа — что запомнить
1. На схеме выше есть слова producer и consumer, так и разделяются микросервисы по ролям относительно кафки (producer — пишет, consumer — читает).
2. Права могут регулироваться сертификатами SSL, либо юзер+пароль. Сертификаты умеют протухать.
3. Один сервис может и читать, и писать.
4. Вы, как тестировщик, тоже играете роль продюсера или консьюмера и используете те же креды для доступа (об этом будет подробнее во второй части).

Топики и партиции
Вернемся к трубам — это и есть кафка. У одного топика, в который пишут и который читают микросервисы, есть одна или более партиций. Это нужно для распределения нагрузки, чтобы не получать всю кучу данных.
Топик я себе представляю для аналогии как определённую тему — например, я хочу читать статьи на Хабре только из этого «топика».
Или как таблицу в БД — это не вся база, это определённая её часть.
С точки зрения хранения, партиции — это единицы хранения сообщений, а топики — что-то вроде контейнеров, в которых эти партиции находятся.

Разработчик при настройке Producer может указать, что данные нужно записывать в определенный топик, при этом партиции он не указывает. В таком случае Kafka сама распределит по партициям весь набор передаваемых сообщений:

Количество партиций зависит от проекта, а точнее — от ресурсов, которые потребуются.
Приоритет
Разработчик может настроить и наоборот, чтобы микросервис писал/читал только из конкретной партиции топика.
Напомню, что таких писателей и читателей у одного топика может быть много. Например, группа читателей так и называется — консьюмер-группа.
А еще разработчик может настроить задержку — например, чтобы в топике появлялась только 1 запись в секунду и распределялась нагрузка.

Формат данных, которые можно передавать через кафку, напоминает API:

Таким образом, в топиках кафки накапливается очередь из таких сообщений.
Очередь
Выглядит примерно следующим образом:

У каждой записи есть партиция, в которую она попала, оффсет, уникальный ключ (по которому, кстати, можно искать сообщения при тестировании), тело сообщения, а также еще время, в которое оно было отправлено.
Оффсет — это указатель в очереди, который используется для отслеживания прогресса консьюмера при чтении данных. Можно сравнить это со страницей в книге. В какой-то момент вы приостановили чтение (микросервис упал, сертификат протух), потом поднялись и нужно продолжить читать с того же места. Или, наоборот, вы только подключились к топику (или что-то пошло совсем не так), и нужно прочитать всё заново. Для этого есть сброс оффсета.
Пример команды по сбросу оффсета:
./bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group [myConsumerGroup] --reset-offsets --to-earliest --topic [my_topic] –execute
Тогда консьюмер, к которому применили данную команду, будет вычитывать всю очередь заново.
Или, наоборот, оффсет можно сбросить, т.е. сдвинуть к конец.
./bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group [myConsumerGroup] --reset-offsets --to-latest --topic [my_topic] –execute
Это требуется, например, при подключении консьюмера, которому не нужны данные в реальном времени, т.е ему всё равно, что было до него (как подключиться к каналу/чату, например).
Можно также и сдвинуть к конкретному времени, с которого требуется начать читать:
./bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group [myConsumerGroup] --reset-offsets --to-datetime 2024–05–20T00:00:00.000 --topic [my_topic] –execute
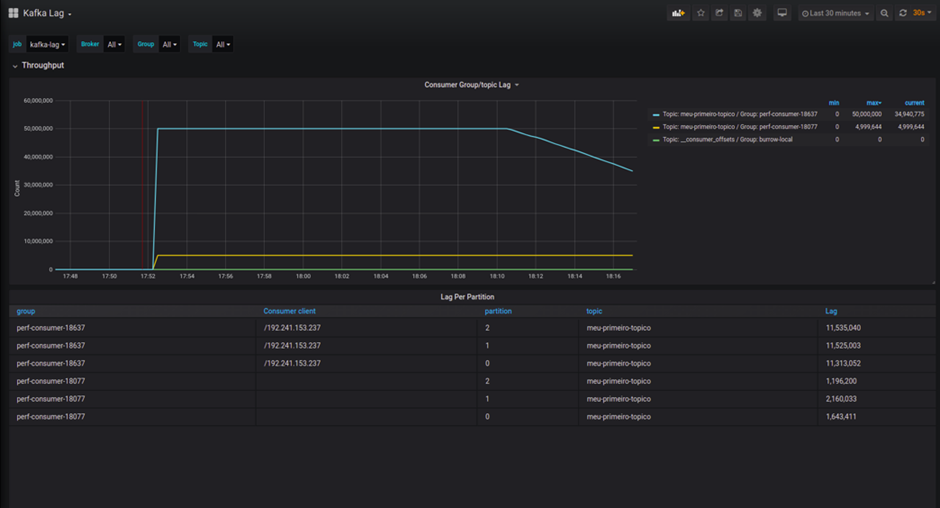
Оффсет ещё используется для вычисления так называемого Kafka Lag.
kafka lag = последний оффсет в топике — последний вычитанный консьюмером оффсет
Это количество показывает, сколько записей консьюмер «упустил». Например, в таблице выше это может быть так: всего записей 7 (от 0 до 6), а консьюмер вычитал последним второй оффсет. 6–2=4 записи у нас «лага».
Kafka lag иногда отображают в графике в Grafana.
В норме Kafka lag = 0, если происходит скачок, скорее всего, сервис упал, либо протух доступ к топику. Затем очередь «рассасывается», следовательно, проблема устранена.
А еще можно настроить сервис так, чтобы он читал не в реальном времени, а, например, раз в сутки — ночью.
Временное хранение
Пока микросервис-консьюмер упал или потерял доступ, кафка еще выступает временным хранилищем — как раз чтобы продолжить читать с оффсета, на котором остановились.
Время хранения может быть неделя-месяц, но также в целях разгрузки и безопасности может быть совсем коротким, на моей практике самое короткое время — полчаса.
К сожалению, это не очень удобно для тестирования. Пока первый раз проходишь последовательность или ведешь детективное расследование, на каком этапе что упало, — можно уже начинать заново.
По умолчанию время хранения — 7 дней.
Итак, на этом первую часть статьи я, пожалуй, завершу. Мы рассмотрели теоретические основы, принципы и особенности взаимодействи в рамках тестирования микросервисов. А вот во второй части мы перейдем к практике тестирования и обсудим методы поиска и исправления возможных ошибок. До скорого!
