AI агенты — клоны сотрудников (часть 3)
Итак, я прошел длинный путь создания RAG с нуля, и начал делать AI агентов для нашей компании.
По технологиям испробовал:
Локальные embed модели (не заметил большой разницы между ними)
Локальные generation модели (то что влезало на MacBook M3 18Gb RAM)
Облачные embed модели (OpenAI)
Облачные generation модели (Gemini, Grok, OpenAI, Yandex, Gigachat)
VectorDB (ChromaDB)
NER aka Named Entity Recognition (spaCy)
GraphDB (neo4j)
Еще в списке на попробовать:
E2E фреймворк LangChain
Его граф БД (LangGrpaph)
Первый хороший вариант RAG получился на ChromaDB и Gemini-Flash 2.0.
ChromaDB работает очень быстро при нашем объеме документов в несколько тысяч (Wiki). Gemini срабатывает мгновенно; в основном я использовал top_k = 5, то есть выборку 5 самых схожих векторов с запросом. И temperature = 0, чтобы он давал только факты.
Все это прикручено к SlackBot.
Затем я попробовал NER и получил полный провал. Похоже, что в нашем случае spaCy не справляется с хорошим выявлением сущностей.
GraphDB требовал титанических усилий для построения графа из Википедии, в которой много устаревших документов и мало прямых релевантных связей.
Короче говоря, чтобы NER и GraphDB работали, данные должны быть предварительно размечены, например, хэштегами по темам, и между документами должны быть качественные множественные связи, чего у нас нет.
AI Агенты вместо RAG
И я перешел на OpenAI Assistants (AI Agents), даже несмотря на то, что его модели работают медленнее, чем Gemini Flash.

То есть теперь у меня нет RAG, а есть набор ассистентов OpenAI. Каждый ассистент имеет свой набор входных текстовых файлов и свою векторную базу данных, а именно VectorStore.

OpenAI автоматически эмбедит файлы в свой VectorStore. И сам потом их выбирает; там можно конфигурировать до 50 top_k, то есть выбирать до 50 наиболее релевантных векторов при каждом запросе.
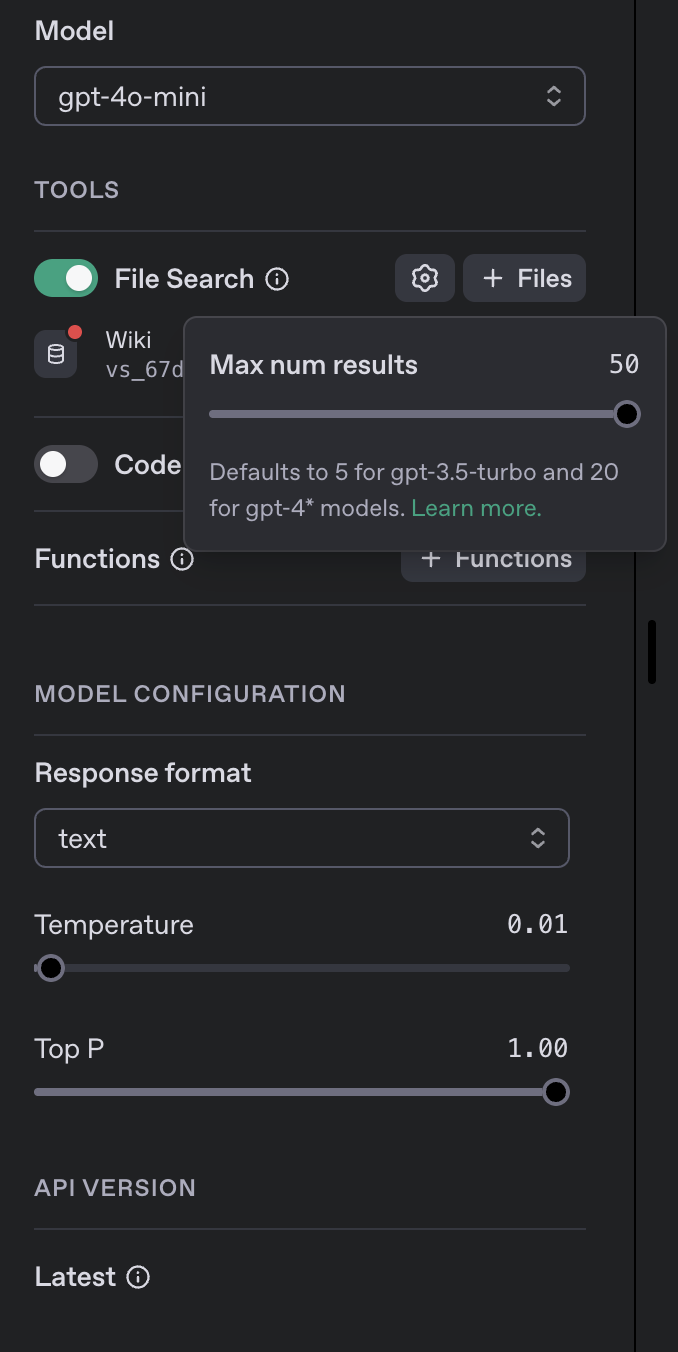
Модель можно выбрать индивидуально для каждого ассистента, а также настроить другие параметры.
Например, для WikiBot я выбрал модель gp4–4o-mini, потому что она быстрая, а цена у нее ниже, и она хорошо справляется с задачей. Температура установлена около 0, чтобы максимально использовать факты из VectorStore, а не фантазии. Top P = 1.0, то есть использовать 100% выбранных векторов из VectorStore. Выбирать 50 топ-векторов.
В чем преимущество над RAG?
Нативная сематическая embed модель от OpenAI
Внутри каждого Vectorstore можно настраивать chunking (определять как бьется текст на куски), мне пока подошла default модель (4096 bytes с перекрытием чанков 400 bytes).
Можно прикрутить Function calling, то есть можно сделать реального AI агента. Например для WikiBot это может быть вызов Wiki API для апдейта документов на основании общения с пользователями.
Треды OpenAI хранят всю историю общения в течение сессии и используют её для формирования контекста. Каждый агент в рамках каждого треда будет дообучаться при общении.
Самым большим плюсом OpenAI threads является то, что это бесплатно и экономит множество токенов. Если я захочу реализовать подобную функциональность на LangChain, то мне придется хранить весь контекст для всех сессий самостоятельно и каждый раз передавать его заново в модель при каждом запросе.
В чем минусы:
Я не могу использовать GraphDB, только семантическую векторую БД от OpenAI
Я не могу, или почти не могу использовать NER
На самом деле минусы спорные, потому что когда я оценил объем работы по чистке, разметке и добавлению правильных связей для нашей небольшой Вики (~2000–3000 страниц), то я отказался от использования NER и GraphDB. По сути, мне пришлось бы вместо использования всей мощи модели применять ручное структурирование наших документов. Для меня это подрывает саму идею использования больших языковых моделей (LLM). Единственное, на что я готов согласиться, — это внедрить правила создания новых документов на Вики в формате Markdown, так как модели лучше обрабатывают такой формат.
При этом я всё ещё планирую провести эксперимент по воссозданию всей инфраструктуры, которая есть в OpenAI, с помощью LangChain. Напишу об этом отдельную статью, когда всё будет готово.
Что создано?
WikiBot, отлично отвечает на все то что явно есть в Wiki, ниже скрины его ответов. BuggerBot, хорошо классифицирует баги от customers.
Осталось прикрутить JIRA API через OpenAI Function Calling, чтобы он заводил как баги то что прошло проверку.
EmployeeClone bots. Вот это удивило. Я просто взял все slack сообщения за много лет по каждому сотруднику и вкинул их в отдельный VectorStore, и создал отдельный AI Assistant для каждого сотрудника со следующим prompt:

И я был поражен, когда мой клон начал отвечать точно так же, как я бы ответил на вопросы, которые были в его истории. Он сохраняет как фактуру, так и манеру каждого сотрудника.
Как это применять? Например, если сотрудник заболел, находится в отпуске или даже уволился, и нужно быстро узнать, что он делал по конкретным вопросам или его мнение по определенной теме. И клон отлично справляется с этой задачей, особенно учитывая, что поиск в Slack ужасен. А бот за 2 секунды он выдает точный ответ от имени конкретного сотрудника.
Выводы
Любая система RAG сильно зависит от входных данных. При большом объеме входных данных результат получается плохим.
Лучше создавать микро-агенты под конкретные задачи с ограниченным набором данных.
Лучше использовать последовательные данные, которые согласованы между собой (например, все разговоры сотрудника за несколько лет оказались намного более последовательными, чем наборы документов на Википедии, написанные разными сотрудниками в разное время). В результате ответы также намного более точные
Что дальше?
План — создать множество микро-агентов для конкретных задач и разработать Chief Agent или агент-оркестратор, к которому можно обратиться для выявления нужного агента.
Этот оркестратор может организовать взаимодействие между агентами. Например, если WikiBot не имеет достаточно информации из Википедии и нужна помощь сотрудников, оркестратор запрашивает эту помощь у всех агентов-клонов сотрудников.
Те, кто не в теме, ответят «не знаю», а те, кто в теме, предоставят дополнительную информацию, которая будет передана обратно в WikiBot для ответа на запрос пользователя.
Также планирую очистить код и выложить его на GitHub.
Примеры ответов WikiBot





