История эволюции веб-сервиса: от примера из доки до космолета
Введение
Привет, на связи команда платформы A/B экспериментов Okko, и сегодня мы расскажем вам об эволюции нашего сервиса для сплитования трафика.

Уже было написано несколько статей о нашей платформе. Мы улучшали сервис в целом и процессы проведения A/B экспериментов, ускоряли его работу (первая, вторая, третья). Данная статья — продолжение истории создания собственной платформы для A/B экспериментов в Okko.
В этот раз предлагаю взглянуть на процесс развития веб-сервиса для сплитования трафика с точки зрения эволюции его архитектуры. Начнем с примера из документации к популярному фреймворку и постепенно дойдем до того как мы справились с функциональными и техническими требованиями.
Этап первый: тех. задача
Развитие компании потребовало создания собственной платформы для A/B-тестирования, которая бы позволила пользователям легко запускать новые эксперименты, отслеживать их статус и анализировать результаты.
Одним из её ключевых компонентов стал сервис для сплитования трафика. Через него проходит весь трафик пользователей, и для каждого запроса рассчитывается, в какие эксперименты пользователь включен. После этого запрос пользователя направляется в целевые сервисы. Например, в систему рекомендаций. Там ему выдается контент в зависимости от тестовой группы, в которую он попал.
Поскольку через сервис сплитования проходит весь трафик Okko, к нему предъявляются серьезные технические требования: он должен обрабатывать нагрузку в 5 тысяч запросов в секунду (RPS), обеспечивать время ответа не более 5 миллисекунд и поддерживать одновременное проведение 100 экспериментов.
Расчет экспериментальных групп для пользователей является чисто математической задачей, требующей значительных вычислительных ресурсов. Подробности были описаны в предыдущих статьях, а в данном контексте нас интересует только логика обработки запросов:
с каждым запросом поступает информация о пользователе;
запущенные эксперименты загружаются из базы данных;
вычисляются экспериментальные группы;
результаты передаются в ответе.
Решение из доки
Для решения этой задачи мы выбрали CPython версии 3.11. У нас в отделе большая экспертиза в этом языке, и мы решили использовать ее в полной мере. В качестве веб-фреймворка остановились на популярном и простом Flask, а в качестве WSGI-сервиса — на Gunicorn.
А так как у нас в Okko принято покрывать сервис мониторингами и деплоится в Kubernetes, то к выбранным технологиям добавились: OpenTelemetry для сбора трейсинга и Prometheus client для сбора метрик.
Телеметрия отправлялась по push модели, то есть клиент сам отправлял пакеты в агент, развернутый в поде как sidecar. А пробы и метрики собиралась по pull модели, то есть специализированные решения сами ходили в сервис в конкретные endpoint-ы.
Старт разработки, конечно, начался с копирования примеров из документаций и попыткой связать все технологии в одном сервисе.
Архитектура получилось следующей:
мастер процесс слушает порт и передает данные из запроса в воркеры;
в воркере основной тред обрабатывает служебные, такие как выдача метрик и пробы, и запросы от других сервисов;
второстепенный в воркере тред отправляет собранные трейсы.


Минусы конфигураций из док
Опыт подсказывал нам, что примеры из документации — это только примеры, а не «prod-ready» решение.
Пробы, проверяющие внешние зависимости, блокируют воркеры, а большой объем метрик отнимает время и у воркера, и у мастер-процесса.
Чтобы нивелировать влияние служебных запросов на полезную работу, мы решили вынести пробы и метрики в отдельный веб-сервис, который будет работать на другом порту в мастер-процессе в отдельном треде. Тред запускается с флагом daemon=True, чтобы, когда умирает Main-тред, убивался тред отдающий пробы, и Kubernetes перезапускал под.

Новые функциональные требования
В процессе разработки, как это часто бывает, окружение изменилось, и появилось новое функциональное требование. Результат расчета экспериментальных групп стало нужно не только отдавать в запросе, но и сохранять в DWH.
У нас в Okko хорошо настроен процесс сбора данных для записи в DWH, для этого достаточно писать в Kafka. Поэтому задача оказалась тривиальной. Мы всего лишь добавили популярный инструмент kafka-python, где уже настроена работа с несколькими партициями и отправка данных батчами в фоне.В результате в каждом воркер-процессе стал появляться еще один тред, который занимается отправкой данных в Kafka.
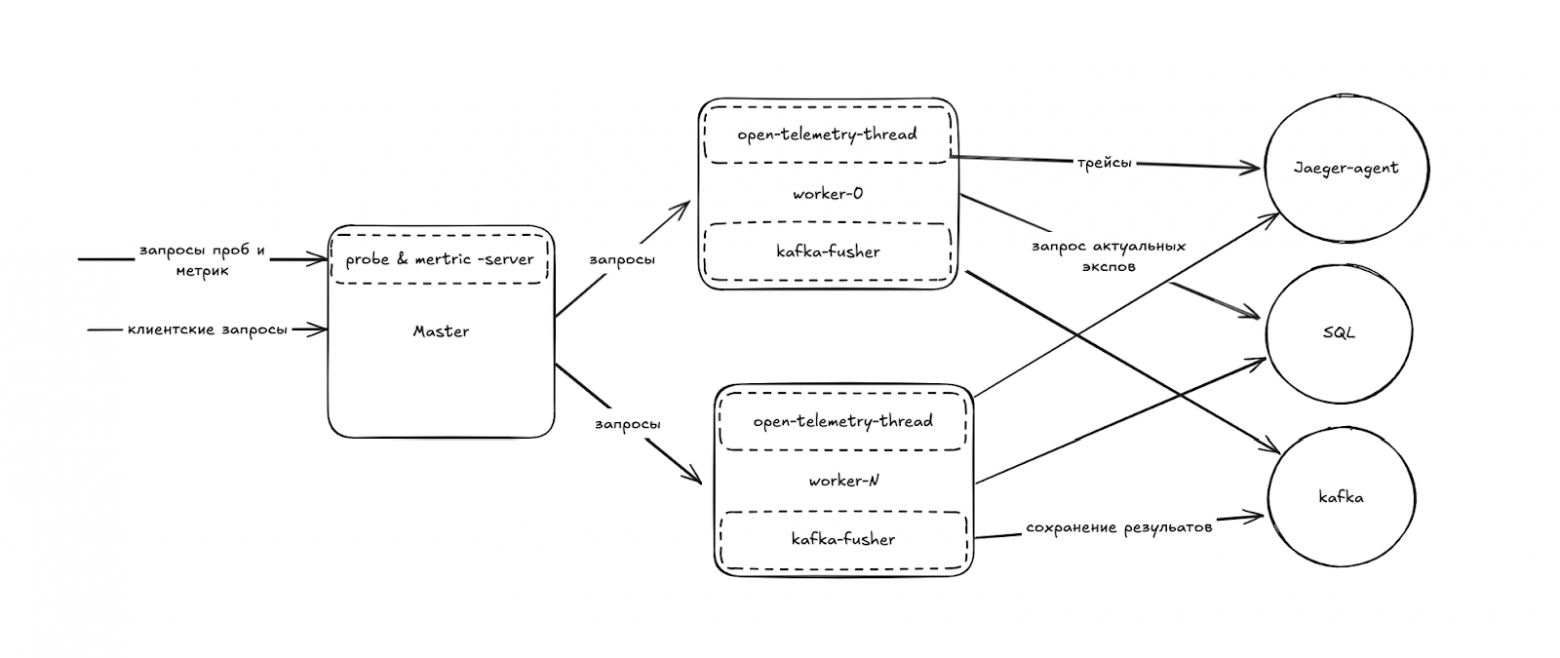
Первая реализация
Итак! Первая реализация готова.
Мы отнесли образ на нагрузочное тестирование и увидели, что наши воркеры не держат нужный RPS и время ответа значительно больше желаемого.
Начали искать «узкое место». Отладка многопроцессных программ — задача не из простых, но мы выяснили, что проблема недостаточной производительности кроется в Gunicorn. Одна из причин — неумение держать коннекты (у нас sync-worker, так как задача cpu-bound). На каждый запрос происходит TCP handshake, что тоже отнимает время. И это не единственный минус Gunicorn в этой задаче: между мастер-процессом и воркерами есть очередь. Она не заявлена как очередь, а представляет собой сокет для быстрой передачи данных между процессами, который также служит для функционала Health Checks воркеров.
Так собственно в чем проблема, спросит внимательный читатель?
Проблема проявляется под нагрузкой. Когда нагрузка превышает возможности воркеров, очередь запросов в Gunicorn начинает расти. Это прекрасный инструмент, чтобы сгладить неравномерность трафика. Но когда очередь занимает всю выделенную память, запись новых запросов в сокеты становится блокирующей. Это приводит к заметной деградации мастер-процесса как при приеме новых запросов, так и при выдаче ответов на уже обработанные.
Мы решили эту проблему, заменив Gunicorn на Bjoern. В Bjoern порты слушают сами воркеры, а мастер-процесс больше не участвует в обработке трафика. Это устранило проблему с очередью и деградацией мастер-процесса. А бонусом мы получили поддержку Keep-alive соединений. Однако, так как код остался синхронным, каждый воркер может держать только одно соединение. В Gunicorn, чтобы запросы корректно распределялись между воркерами , мастер-процесс сам выбирал какому воркеру достанется новый запрос. Теперь это осуществляет ingress, который и так работал все это время.
Нам нужен кеш
В начале статьи мы говорили, что данные о пользователе приходили с запросов, а за запущенными экспериментами необходимо сходить в БД. При этом, от запроса к запросу в сервис эксперименты не сильно менялись, поэтому результат SQL-запроса для получения всех актуальных экспериментов всегда был одинаковым.
Очевидным решением стало добавление кеша. А так как объём необходимых данных был небольшим (за все время работы едва больше 1MB) — решили делать его in-memory. Добавили декоратор на нужную функцию из популярной библиотеки и в сервис раз в N запросов делался запрос в БД, чтобы собрать актуальные данные. В остальных случаях использовался результат предыдущего запроса в базу.
Однако, мы быстро поняли, что даже самый оптимизированный запрос к БД не будет выполняться за считанные миллисекунды, разве что при использовании Redis. Но отказываться от in-memory кеша в пользу Redis мы не стали, так как это увеличило бы время обработки запроса. Вместо этого мы решили оставить in-memory кеш, но добавить в каждый воркер тред, который бы обновлял его раз в минуту.

Вспомогательный тред мешает воркеру
Знаете это чувство, когда кажется, что вот-вот и всё заработает так как надо?
У нас было такое, когда мы отдавали последнюю версию сервиса на нагрузочное тестирование. Но чувство не соответствовало реальности: сервис все еще не соответствовал требованиям. Поэтому мы взяли сэмплирующий профилировщик и начали исследовать, куда тратится время. py-spy раз в N миллисекунд сохраняет стек, который сейчас активен в интерпретаторе и считает как часто каждая строчка кода оказывается в стеке. Затем оценивает сколько процессорного времени тратится на ту или иную функцию.
У нас получилась примерно такая картинка:

Флеймграф наглядно показал, что стек разделился. Это означает, что параллельно работают два треда, один из который отправляет данные в Kafka, и оба потребляют значительные ресурсы. Из этого стало очевидно, что тред Kafka занимает GIL настолько долго, что это существенно влияет на обработку трафика
Мы стали искать, как избавиться от GIL, и нашли решение — использовать не треды, а процессы:
воркер занимается только обработкой трафика, а затем отправляет результат в другой процесс через pipe для сохранения данных;
новый процесс «flusher» принимает данные из pipe по одному объект и передает в библиотеку Kafka, где они аккумулируются по партициям и батчам.
Новая схема получается вот такой:

Мешает кеш
Занимаясь оптимизацией программы при работе с GIL, мы начали находить удивительные закономерности. С тредом обновления кеша получилось также. Главная проблема что он тред, а значит тоже перетягивает на себя GIL. Это не так заметно, но переключение тредов случается по-умолчанию каждые 5 мс, а значит каждый запрос может нарваться на лишнее ожидание. Зачастую это просто переключение треда туда и обратно, без полезной работы. Но когда надо сходить в БД и сформировать новый контекст — это приводит к более существенным задержкам.
Быстрого и простого решения этой проблемы мы не нашли, а продакт-менеджеры очень ждали возможности запускать A/B-эксперименты. Чтобы удовлетворить их потребности, но не переписывать все на GO, мы пришли к следующему сценарию. Кеш формируется при старте и больше никогда не проверяется и не обновляется. А чтобы изменения доходили до продакшена, мы договорились о перезапуске подов каждый час.
Владелец продукта заверил, что пользователям платформы A/B экспериментов этого часа хватит.

Проблема всех языков с GC: он мешается
Убрав работу с GIL из воркеров, мы были уверены, что пропадет шум на графике времени ответа. Он, конечно, уменьшился, но не исчез. А размеры спайков вообще не изменились.
Средства трассировки не находили новых внешних событий, создающих остановки. Процессов в поде было выделено с запасом, тротлинг отсутствовал, GIL убрали, а остальным процессам в поде еще и уменьшили приоритет инструментом nice.
Помощь пришла команды рекомендаций, которая столкнулась с аналогичными аномалиями. Их исследования привели нас к популярной теме сборки мусора (GC). В своей статье Татьяна подробно описан путь исследования и подбора порогов для GC. Мы в команде, перенимая ее опыт, пришли к выводу, что любая работа GC для нас чревата потерей запросов пользователей. С другой стороны большие пороговые значения заставляют GC вести себя так, как будто он выключен. Пока однажды он не дойдет до порога, что может привести к задержкам в сотни секунд. Поэтому мы просто отключили сборку мусора :)
Многие сочтут это опасным ходом. Так как без сборки мусора есть риск роста памяти, и, как следствие, смерть процессов и подов. Однако в CPython реализован еще один способ удаления неиспользуемых объектов через счетчик ссылок. Именно из-за него память не росла.
Спайки исчезли, а график времени ответа стал практически ровным.
Большой time-to-market изменений
Казалось бы, мы всего добились: latency стабильный, RPS держим, эксперименты проводятся. Но изменения в БД поступали в сервис сплитования раз в час при рестарте, а это недостаточно часто. Поэтому нам требовалось решение для бесшовной подгрузки контекста в работающий сервис.
История с GIL научила нас, что запускать параллельные треды нельзя. С другой стороны, для параллельных процессов GIL не требуется, а значит можно запустить процесс, который будет с интервалом в пару минут искать изменения в БД, и при их появлении, формировать новый контекст.
План был огонь, но при реализации возникали вопросы:
Как каждый воркер будет понимать, что ему пора обновить свой контекст?
Как передать контекст из сотни экспериментов и сегментов в другие процессы максимально быстро (за микросекунды)?
У нас уже был готовый инструмент в проекте для работы с pipe, чтобы отправлять данные на сохранение. Однако, процессов-воркеров несколько, и нужно либо придумать как открывать N pipe«ов, либо как каждому воркеру читать из пайпа новый контекст только один раз и не прочитать случайно чужой. Помог нюанс CPython в передаче объектов между процессами. Для этого используется pickle, который не умеет работать с лямбда-функциями и замыканиями. А мы как раз использовали оптимизации похожие на JIT, чтобы быстрее вычислять эксперименты.
Команде пришлось потратить немало сил, но в результате мы пришли к такому решению:
В мастер-процессе запускается тред splitter-loader, который ищет обновления для контекста сплитования.
При появлении обновлений splitter-loader формирует новый контекст и маршализует его с помощью dill (в отличие от pickle он умеет работать с лямбда-функциями).
Полученный контекст в виде последовательности байт записывается в SharedMemory, а у межпроцессной переменной (Synchronized) выставляется текущее время.
Процессы-воркеры раз в N секунд проверяют, обновилось ли время в межпроцессорной переменной.
Если время изменилось, значит пришли апдейты, и воркер читает и распаковывает новый контекст из SharedMemory.
Важно отметить, что скорость распаковки и обращения к SharedMemory и Synchronized была тщательно проверена, и даже в худшем сценарии накладные расходы не превышали 0.5 миллисекунды
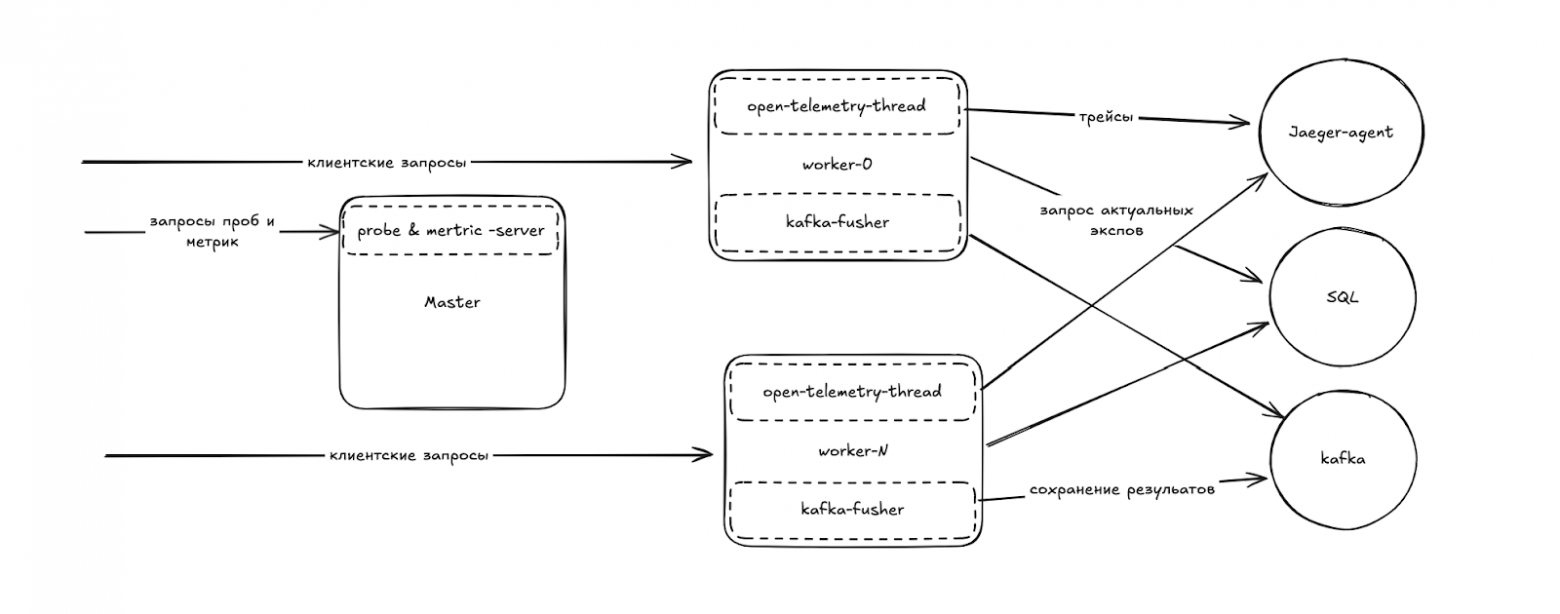
Финальная версия
Задача выполнена! Финальная архитектура выглядит вот так:

Сравните ее с самой первой схемой, которая иллюстрирует пример из документации.

Итог:
Построенный космолет — ЕСТЬ
Довольный менеджер — ЕСТЬ
Минимальный bus-factor — ЕСТЬ
Рефлексируя о проделанной работе, невольно задаешься модным сегодня вопросом:, а почему не Go?
И лично мое ощущение, что писать космолет на Python, зная его узкие места, и писать на Go, мало что зная о нем, скорее всего будет сопоставимо по времени.
