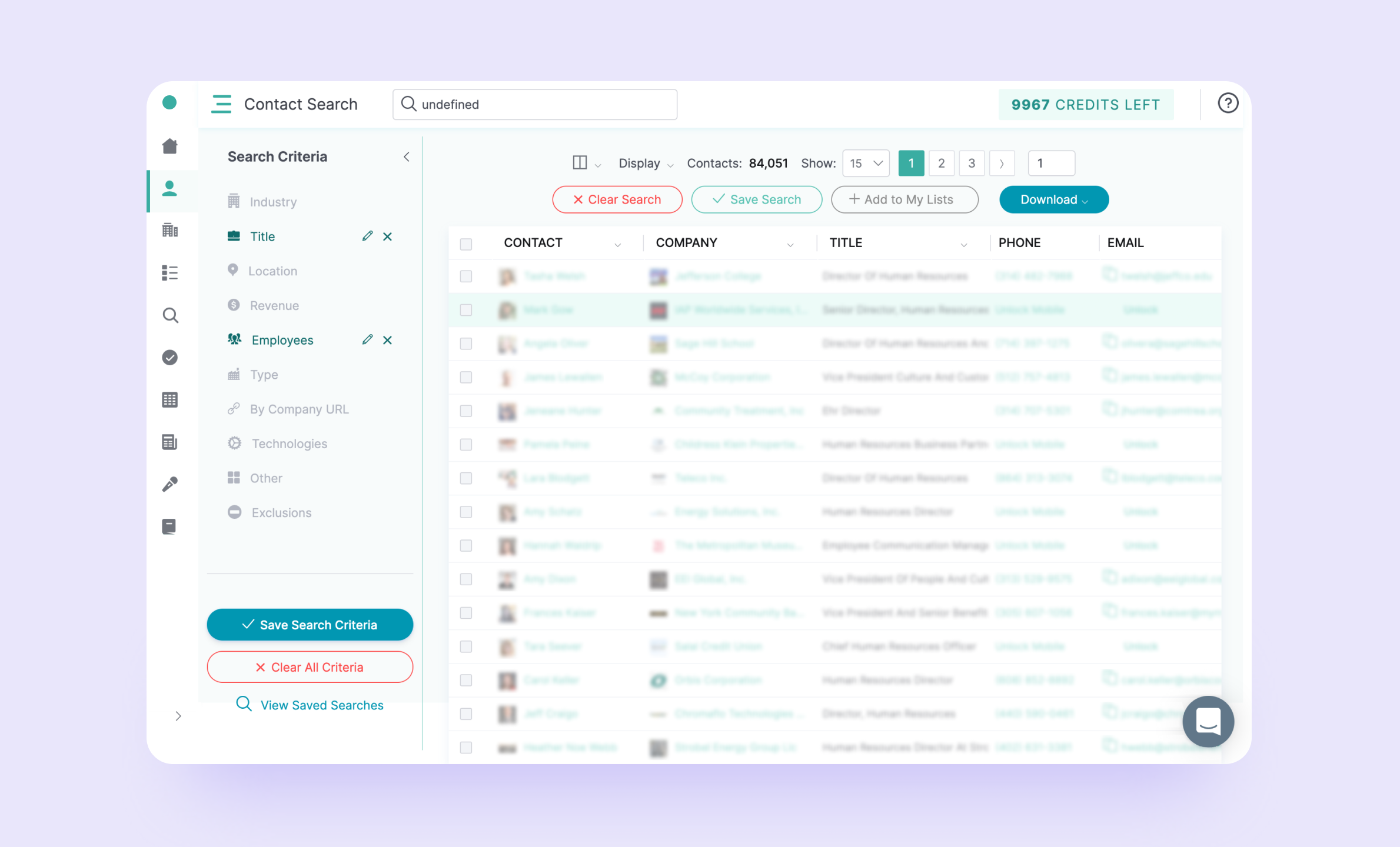
Кейс: разработка массивного сервиса для хранения и поиска данных о лидах
ЗаказчикМаксимально скрытный заказчик-конспиролог, настоящее имя которого мы узнали только спустя три года работы с ним.ЗадачаРазработать массивный сервис для просмотра, поиска и фильтрации базы из 60 млн. записей.
Что делать разработчику, когда ему приносят запрос на сервис с базой на 60 млн контактов? Брать и делать, конечно же! Даже, если до этого у него не было опыта работы с большими массивами данных. Меня зовут Сергей Никоненко, я операционный директор Purrweb. Расскажу, как мы меняли базу данных и поисковую систему буквально на лету и какая тайна нам открылась на третий год работы с заказчиком.

Темной-темной ночью пришел темный-темный заказчик
Это почти мистическая история: в 2017 году к нам обратился заказчик-конспиролог с идеей мегасервиса лидогенерации, который позволял бы компаниям находить реальные лиды (контактные данные организаций) в B2B. Это должен был быть универсальный инструмент лидогенерации для любого более менее крупного отдела продаж, которому приходится работать с холодными базами.
При этом заказчик пришел не с пустыми руками: у него уже была база данных с 60 млн записей (не спрашивайте откуда, сами не знаем, да и NDA никто не отменял). В базе было то, что поможет отделу продаж искать лиды для работы:
| ? е-мейл; | ? описание NAICS; |
| ? название организации; | ? название отрасли в LinkedIn; |
| ? адрес (город, штат, страна); | ? биржевой тикер; |
| ? сайт; | ? валовый доход; |
| ? телефонный номер; | ? кол-во сотрудников; |
| ? код SIC; | ? год основания; |
| ? отрасль; | ? рейтинг Alexa; |
| ? код NAICS; | ? ФИО контактного лица. |
С помощью сервиса пользователь должен был фильтровать интересующих людей или компании, и получать их актуальные контакты: email и телефон.
Мы назвали заказчика конспирологом, потому что он не полагался даже на NDA — его настоящее имя мы узнали только на третий год работы. Впрочем, нам это никак не помешало, мы сработались и это уже не единственный совместный проект.
Требование невозможного
На переговорах мы оценивали проект в $15 тыс. Заказчик очень легко и воздушно описывал, чего хочет, а мы были молоды, зелены и воодушевлены. Ударили по рукам, думая, что всего-то нужно подрубить базу данных, подключить интерфейс и доделать мелочи.
Уже на первом этапе разработки проект превзошел ожидания и по времени, и по деньгам. Заказчик постоянно добавлял новые вводные, а я переживал, что ничего не получится, еще должны останемся.
Говорят, делай, что должен, и будь, что будет. В какой-то момент мы нашли общий язык. Я перестал переживать и паниковать, и нам удалось приоритезировать внедрение новых фич. И работа встала на нормальные рельсы.
А позже мы узнали, что заказчик вообще ничего от нас не ожидал — до конца не верил, что мы сделаем. До этого сервис пыталась сделать другая компания — получилась ерунда. Кроме того, заказчик понимал, что такой проектище за такие небольшие деньги не сделать.
Фронт работ и технологии
Такой сервис — не единственный на рынке. Основные конкуренты — Zoominfo, Clearbit и D&B Hoovers. Они все проигрывают нашему проекту в точности контактных данных и в точности информации о компании. Это заслуга базы данных, которую предоставил заказчик.
В этом проекте мы сразу же попробовали несколько разных технологий:
- Фронт писали на React, бэк — на Ruby on Rails. Ruby взяли из-за большого выбора готовых решений «из коробки», которые на том же Node.js, например, пришлось бы делать руками.
- Для управления базами данных взяли сначала MongoDB, но в процессе перешли на PostgreSQL, потому что с последней лучше работать со структурированными базами данных — она умеет в связи между данными.
- Для поиска по базам данных взяли поисковую систему Elasticsearch, которую потом сменили на Apache Solr.
- Для верификации email — ZeroBounce.
- Для работы с платежками — BrainTree.
- …и другие инфраструктурные сервисы.
Работу поделили на пять крупных блоков:
- Архитектура для фронтенда и бэкенда.
- Работа с базой данных в MongoDB и PostgreSQL.
- Основная разработка.
- Тестирование.
- Поддержка.
Сейчас расскажу подробнее.
Первая замена в игре: Elasticsearch больше не справляется
Работу с поиском по базе данных начали с поисковой системы Elasticsearch, потому что она была довольно простой в работе. Правда, со временем функциональности системы стало не хватать:
- У Elasticsearch не работает пагинация — деление поисковой выдачи на страницы. Например, пользователь видит контакты всех сотрудников сразу, поиск не может их сгруппировать по компаниям.
- Нет возможности сделать живой поиск — выдавать предварительные результаты по мере ввода запроса.
Нам пришлось искать альтернативу (и это, как вы помните, не первая замена технологии по ходу проекта). Решили перейти на Apache Solr. Было не очень больно, потому что и Elasticsearch и Apache Solr в принципе похожи — у них в основе одна технология.
В итоге поиск стал удобнее и быстрее.
Вторая замена в игре: PostgreSQL вместо MongoDB
У нас не было большого опыта работы с базами данных, когда мы начинали работу над проектом. Для управления базой данных мы выбрали MongoDB — наиболее популярный инструмент, хоть и не самый удобный. В него можно было свалить все в кучу и потом разгребать. Когда мы разобрались, как все структурировать, пришло время поменять систему управления базой данных.
Причин сменить СУБД было две:
- Мы использовали хостинг AWS, на котором не было выделенного облачного сервиса для MongoDB, но был для PostgreSQL. Нам приходилось самим поднимать и настраивать масштабирование, репликацию, бекапы.
- PostgreSQL — это реляционная база данных, она предназначена для работы со связанными данными. Например, в ней есть транзакции, они гарантируют целостность данных, если произойдет какой-то сбой. В MongoDB такого механизма нет.
Переезжали постепенно: сначала перенесли все сущности, кроме контактов. Какое-то время мы работали с двумя базами одновременно. Постепенно адаптировали код для работы с PostgreSQL, затем забрали данные из MongoDB и с ними окончательно ушли в PostgreSQL.
Верифицируй и обогащай
Итак, у вас есть 60 млн емейлов. Как будем верифицировать: отметать мертвые и сломанные? Сначала выбрали BriteVerify, но позже перешли на Zerobounce, с которым легко сконнектились. У BriteVerify точность верификации была выше, но этот инструмент для лидогенерации стоил сильно дороже. Выбрали Zerobounce как оптимальный вариант.
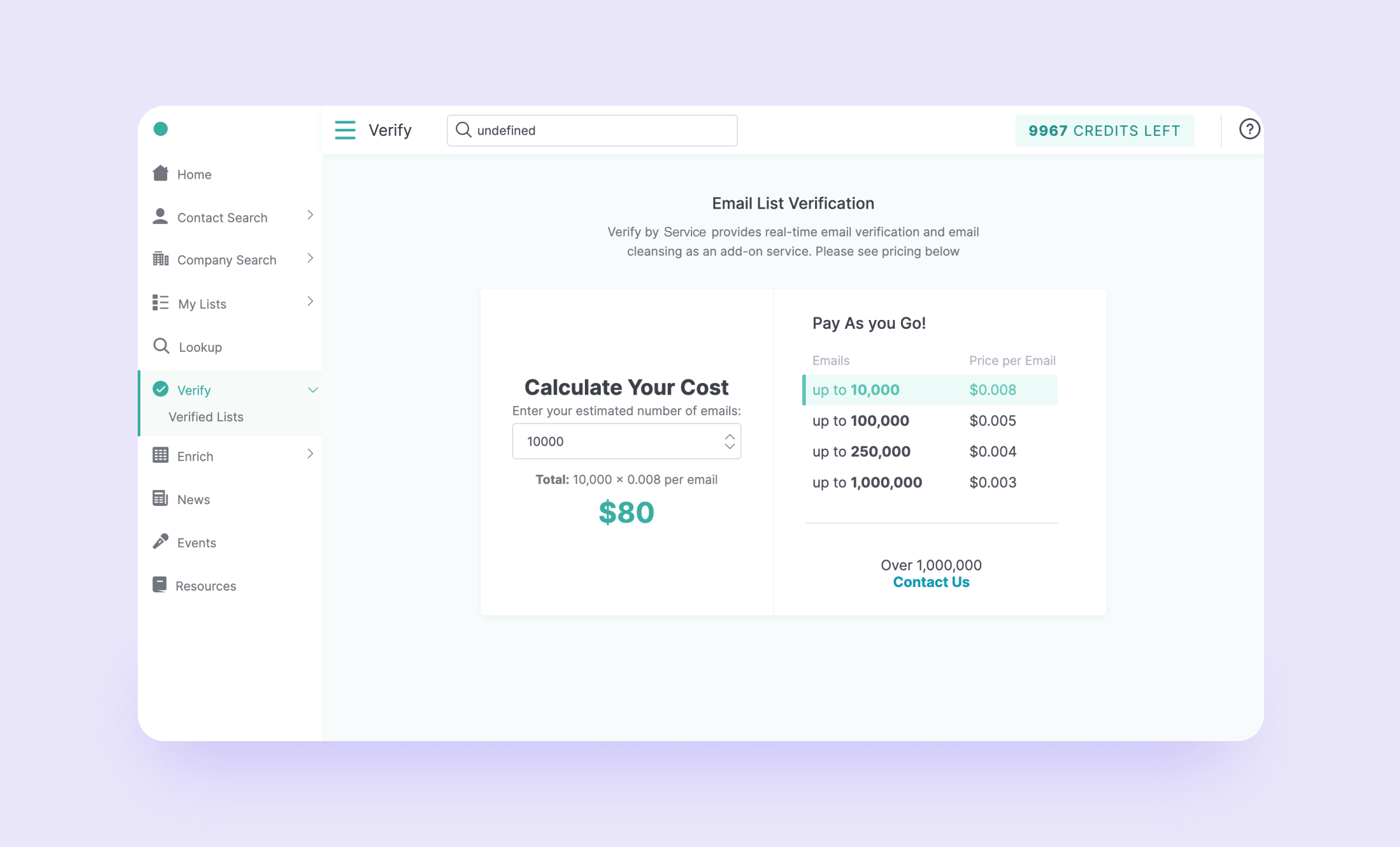
Все работает так: отправляем сервису почту, он говорит о состоянии имейла. Запросы на валидацию почты для пользователя платные, но это недорого.
Вообще у емейлов в системе может быть аж 10 статусов, но в рамках юзерфрендли-разработки мы объединили их в три основные группы: валидный — письма можно слать (скорее всего ответят), accept all — промежуточное состояние (можно, конечно, затеять переписку, но есть риск, что почтовый сервер отклонит запрос) и невалидный — писать бесполезно.
На этом профит от Zerobounce не заканчивается: пользователь может загрузить в наш сервис свою CSV«шку с емейлами и провалидировать их.
Незаканчивающиеся обновления
Если у отдела продаж уже завелась своя CRM, он ее никому не отдаст постарается построить вокруг нее экосистему и будет до последнего отказываться переходить на другую.
 Чтобы сделать сервис лидогенерации конкурентоспособным, было необходимо подключить как можно больше CRMок
Чтобы сделать сервис лидогенерации конкурентоспособным, было необходимо подключить как можно больше CRMок
Мы выбрали 15 наиболее популярных CRM и попытались интегрировать их со своим сервисом. По каждой мы прочитали всю документацию и интегрировались вручную, потому что автоматизировать это невозможно. Попадались простые CRM с режимом песочницы и понятной документацией: прочитал и перепроверил себя, что все ок. Были CRM посложнее, в которых пришлось ковыряться.
Интеграции растянулись на несколько лет: процесс шел постепенно, а новые CRM для интеграции заказчик добавлял в бэклог, когда появлялась необходимость. Кроме того, у этой задачи нет срока годности: каждую интеграцию нужно поддерживать и обновлять.
Но это не единственная часть проекта, которую приходится апгрейдить. Даже 60 млн контактов однажды могут закончиться: базу обработают вдоль и поперек, и сервис больше не будет нужен. Поэтому контакты приходится обновлять.
Раз в 3–4 недели заказчик скидывает нам архив примерно на 1000 json-файлов. Разобрать апдейт и обновить базу нам удается в среднем за неделю:
- Собираем данные в один огромный json размером под 1 ТБ.
- Парсим файл, достаем из него нужную информацию и создаем csv-файл — на это уходит 2–3 дня.
- Заливаем csv в PostgreSQL — около 2 дней.
- Индексируем данные в Solr — еще 3 дня.
Триггер на триггере
Кроме работы с базами данных мы подтянули в приложение полезные прикладные фичи. Так в сервисе лидогенерации появились новости и сейлзтриггеры:
- Пользователь указывает, какую компанию отслеживать и тип новости.
- Когда новость появится, наш сервис пришлет уведомление.
Мы интегрировались с Contify, который шлет новости по компаниям из нашей базы данных. Пользователи могут выбрать, какие именно триггеры нужны: например, новости о банкротстве всех IT-корпораций и больше ничего.
Если, например, наш пользователь занимается разработкой, он может настроить триггеры на новости о стартапах и инвестициях. Узнали о том, что стартап получил деньги → написали стартапу и предложили свои услуги.
Офлайн мероприятия были, есть и будут самым мощным каналом нетворкинга, поэтому мы научили сервис лидогенерации подтягивать новости о предстоящих ивентах и конференциях. Сервис умеет не только информировать пользователей о предстоящих событиях, но и выдавать ссылки на регистрацию.
Подкручиваем платежку
Топовая система платежей для сервисов — Stripe. Но мы столкнулись с неожиданной проблемой: заказчику работу с этой системой не одобрили из-за специфики проекта. Мы начали искать альтернативу и подобрали BrainTree. Он не хуже Stripe, нюанс был только в том, что с этой платежкой мы работали впервые. А недавно проекту одобрили Stripe, поэтому теперь мы подключаем его как еще один вариант платежной системы в сервисе.
Что еще узнаем?
Сейчас проект уже выпущен в мир, но мы продолжаем его дорабатывать — у заказчика неиссякаемый поток идей. И если сначала это был средних размеров сервис лидогенерации с подпиской, то теперь это гигант со своим публичным API — компании могут подключаться к базам данных сервиса напрямую.
Как и планировалось, проект вышел на окупаемость и приносит больше 5 млн долларов в год. У сервиса примерно 10 тыс. активных пользователей в месяц (зарегистрировано 110 тыс.).
Идей по-прежнему много и никто не планирует останавливаться. Мы тоже. Ведь если на четвертый год мы узнали настоящее имя заказчика, кто знает, что еще хорошего может принести продолжение сотрудничества.
«В отличие от других разработчиков, с которыми я работал, ребята из Purrweb действительно думают о продукте и хотят привести его к успеху. Я считаю Purrweb своим партнёром — они вкладываются в наше сотрудничество и развитие продукта. И если сравнивать Purrweb с разработчиками, с которыми я работал до, они превзошли мои ожидания. Будь я эгоистом, предпочел бы, чтобы Purrweb работали только со мной. Ребята потрясающие, и я советую сотрудничество с ними всем, кто ищет команду для разработки веб-приложения. Каждый день платформой пользуются тысячи пользователей. Это успешный продукт, который помог моей компании вырасти», — отзывается заказчик.
| Менеджмент | Разработка | Тестирование | Контент |
| Анастасия Енина | Борис Шаталов | Татьяна Перина | Дарья Лобачёва |
Перейти на сайт
Полный текст статьи читайте на CMS Magazine
