Введение в сетевую часть облачной инфраструктуры

Облачные вычисления все глубже и глубже проникают в нашу жизнь и уже наверно нет ни одного человека, который хотя бы раз не пользовался какими либо облачными сервисами. Однако что же такое облако и как оно работает в большинстве своем мало кто знает даже на уровне идеи. 5G становится уже реальностью и телеком инфраструктура начинает переходить от столбовых решений к облачным решениями, как когда переходила от полностью железных решений в виртуализированным «столбам».
Сегодня поговорим о внутреннем мире облачной инфраструктуре, в частности разберем основы сетевой части.
Что такое облако? Та же виртуализация — вид в профиль?
Более чем логичный вопрос. Нет — это не виртуализация, хотя без нее не обошлось. Рассмотрим два определения:
Облачные вычисления (далее Облако) — это модель предоставления удобного для пользователя доступа к распределенным вычислительным ресурсам, которые должны быть развернуты и запущены по запросу с минимально возможной задержкой и минимальными затратами со стороны сервис провайдера.
Виртуализация — это возможность разделить одну физическую сущность (например сервер) на несколько виртуальных, тем самым повысив утилизацию ресурсов (например у вас было 3 сервера, загруженных на 25–30 процентов, после виртуализации вы получаете 1 сервер, загруженный на 80–90 процентов). Естественно виртуализация отъедает часть ресурсов — вам надо прокормить гипервизор, однако, как показала практика, игра стоит свеч. Идеальный пример виртуализации — это VMWare, которая отлично готовит виртуальные машины, или например KVM, который мне больше по душе, но это уже дело вкуса.
Мы используем виртуализацию сами этого не понимая, да даже железные маршрутизаторы уже используют виртуализацию — например в последних версия JunOS операционная система ставится как виртуальная машина поверх real-time linux дистрибутива (Wind River 9). Но виртуализация — это не облако, однако облако не может существовать без виртуализации.
Виртуализация — это один из кирпичиков, на котором облако строится.
Сделать облако, просто собрав несколько гипервизоров в один L2 домен, добавив пару yaml плейбуков для автоматического прописывания вланов через какой нибудь ansible и нахлобучить на это все что то типа системы оркестрации для автоматического создания виртуальных машин — не получится. Точнее получится, но полученный Франкенштейн — не то облако которое нам нужно, хотя кому как, может быть для кого то это предел мечтаний. К тому же если взять тот же Openstack — по сути еще тот еще Франкенштейн, но да ладно не будем пока об этом.
Но я понимаю что из представленного выше определения не совсем понятно, что же на самом деле можно назвать облаком.
Поэтому в документе от NIST (National Institute of Standards and Technology) приведены 5 основных характеристик, которыми должна обладать облачная инфраструктура:
Предоставление сервиса по запросу. Пользователю должен быть предоставлен свободный доступ к выделенным ему компьютерным ресурсам (таким как сети, виртуальные диски, память, ядра процессоров и т д) причем эти ресурсы должны предоставляться автоматически — то есть без вмешательства со стороны сервис провайдера.
Широкая доступность сервиса. Доступ к ресурсам должен обеспечиваться стандартными механизмами для возможности использования как стандартных ПК, так и тонких клиентов и мобильных устройств.
Объединение ресурсов в пулы. Пулы ресурсов должны обеспечивать одновременное предоставление ресурсов нескольким клиентам, обеспечивая изоляцию клиентов и отсутствие взаимного влияния между ними и конкуренции за ресурсы. В пулы включаются и сети, что говорит о возможности использования пересекающейся адресации. Пулы должны поддерживать масштабирование по запросу. Использование пулов позволяет обеспечить необходимый уровень отказоустойчивости ресурсов и абстрагирование физических и виртуальных ресурсов — получателю сервиса просто предоставляется запрошенный им набор ресурсов (где эти ресурсы расположены физически, на скольких серверах и коммутаторах — клиенту не важно). Однако надо учитывать тот факт, что провайдер должен обеспечить прозрачное резервирование данных ресурсов.
Быстрая адаптация к различным условиям. Сервисы должны быть гибкими — быстрое предоставление ресурсов, их перераспределение, добавление или сокращение ресурсов по запросу клиента, причем со стороны клиента должно складываться ощущение, что ресурсы облака бесконечны. Для простоты понимания, например, вы же не видите предупреждение о том, что у вас в Apple iCloud пропала часть дискового пространства из за того, что на сервере сломался жесткий диск, а диски то ломаются. К тому же с вашей стороны возможности этого сервиса практически безграничны — нужно вам 2 Тб — не проблема, заплатили и получили. Аналогично можно привести пример с Google.Drive или Yandex.Disk.
Возможность измерения предоставляемого сервиса. Облачные системы должны автоматически контролировать и оптимизировать потребляемые ресурсы, при этом эти механизмы должны быть прозрачны как для пользователя так и для провайдера услуг. То есть вы всегда можете проверить, сколько ресурсов вы и ваши клиенты потребляют.
Стоит учесть тот факт, что данные требования в большинстве своем являются требованиями к публичному облаку, поэтому для приватного облака (то есть облака, запущенного для внутренних нужд компании) эти требования могут быть несколько скорректированы. Однако они все же должны выполняться, иначе мы не получим всех плюсов облачных вычислений.
Зачем нам облако?
Однако любая новая или уже существующая технология, любой новый протокол создается для чего-то (ну кроме RIP-ng естественно). Протокол ради протокола — никому не нужен (ну кроме RIP-ng естественно). Логично, что Облако создается чтобы предоставить какой то сервис пользователю/клиенту. Мы все знакомы хотя бы с парой облачных сервисов, например Dropbox или Google.Docs и я так полагаю большинство успешно ими пользуется — например данная статья написана с использованием облачного сервиса Google.Docs. Но известные нам облачные сервисы это только часть возможностей облака — точнее это только сервис типа SaaS. Предоставить облачный сервис мы можем тремя путями: в виде SaaS, PaaS или IaaS. Какой сервис нужен именно вам зависит от ваших желаний и возможностей.
Рассмотрим каждый по порядку:
Software as a Service (SaaS) — это модель предоставления полноценного сервиса клиенту, например почтовый сервис типа Yandex.Mail или Gmail. В такой модели предоставления сервиса вы, как клиент по факту не делаете ничего, кроме как пользуетесь сервисов — то есть вам не надо думать о настройке сервиса, его отказоустойчивости или резервировании. Главное не скомпрометировать свой пароль, все остальное за вас сделает провайдер данного сервиса. С точки зрения провайдера сервиса — он отвечает полностью за весь сервис — начиная с серверного оборудования и хостовых операционных систем, заканчивая настройками баз данных и программного обеспечения.
Platform as a Service (PaaS) — при использовании данной модели поставщик услуг предоставляет клиенту заготовку под сервис, например возьмем Web сервер. Поставщик услуг предоставил клиенту виртуальный сервер (по факту набор ресурсов, таких как RAM/CPU/Storage/Nets и т д), и даже установил на данный сервер ОС и необходимое ПО, однако настройку всего этого добра производит сам клиент и за работоспособность сервиса уже отвечает клиент. Поставщик услуг, как и в прошлом случае отвечает за работоспособность физического оборудования, гипервизоров, самой виртуальной машины, ее сетевую доступность и т д, но сам сервис уже вне его зоны ответственности.
Infrastructure as a Service (IaaS) — данный подход уже интереснее, по факту поставщик услуг предоставляет клиенту полную виртуализированную инфраструктуру — то есть какой то набор (пул) ресурсов, таких как CPU Cores, RAM, Networks и т д. Все остальное — дело клиента — что клиент хочет сделать с этими ресурсами в рамках выделенного ему пула (квоты) — поставщику не особо важно. Хочет клиент создать свой собственный vEPC или вообще сделать мини оператора и предоставлять услуги связи — не вопрос — делай. В таком сценарии поставщик услуг отвечает за предоставление ресурсов, их отказоустойчивость и доступность, а также за ОС, позволяющую объединить данные ресурсы в пулы и предоставить их клиенту с возможность в любой момент провести увеличение или уменьшение ресурсов по запросу клиента. Все виртуальные машины и прочую мишуру клиент настраивает сам через портал самообслуживания и консоли, включая и прописание сетей (кроме внешних сетей).
Что такое OpenStack?
Во всех трех вариантах поставщику услуг нужна ОС, которая позволит создать облачную инфраструктуру. Фактически же при SaaS за весь стек данный стек технологий отвечает не одно подразделение — есть подразделение, которое отвечает за инфраструктуру — то есть предоставляет IaaS другому подразделению, это подразделение предоставляет клиенту SaaS. OpenStack является одной из облачных ОС, которая позволяет собрать кучу коммутаторов, серверов и систем хранения в единый ресурсный пул, разбивать этот общий пул на подпулы (тенанты) и предоставлять эти ресурсы клиентам через сеть.
OpenStack — это облачная операционная система которая позволяет контролировать большие пулы вычислительных ресурсов, хранилищ данных и сетевых ресурсов, провижининг и управление которыми производится через API с использованием стандартных механизмов аутентификации.
Другими словами, это комплекс проектов свободного программного обеспечения который предназначен для создания облачных сервисов, (как публичных, так и частных) — то есть набор инструментов, которые позволяют объединить серверное и коммутационное оборудование в единый пул ресурсов, управлять этими ресурсами, обеспечивая необходимый уровень отказоустойчивости.
На момент написания данного материала структура OpenStack выглядит так: 
Картинка взята с openstack.org
Каждая из компонент, входящих в состав OpenStack которых выполняет какую либо определенную функцию. Такая распределенная архитектура позволяет включать в состав решения тот набор функциональных компонент, которые вам необходимы. Однако часть компонент являются корневыми компонентами и их удаление приведет к полной или частичной неработоспособности решения в целом. К таким компонентам принято относить:
- Dashboard — GUI на базе web для управления OpenStack сервисами
- Keystone — централизованный сервис идентификации, который предоставляет функциональность аутентификации и авторизации для других сервисов, а также управлять учетными данными пользователей и их ролями.
- Neutron — сетевая служба, обеспечивающая связность между интерфейсами различных служб OpenStack (включая и связность между VM и доступ их во внешний мир)
- Cinder — предоставляет доступ к блочному хранилищу для виртуальных машин
- Nova — управление жизненным циклом виртуальных машин
- Glance — репозиторий образов виртуальных машин и снапшотов
- Swift — предоставляет доступ к объектому хранилищу
- Ceilometer — служба, предоставляющая возможность сбора телеметрии и замера имеющихся и поребляющих ресурсов
- Heat — оркестрация на базе темплейтов для автоматического создания и провижининга ресурсов
Полный список всех проектов и их назначение можно посмотреть тут.
Каждая из компонент OpenStack — это служба, отвечающая за определенную функцию и обеспечивающая API для управления этой функцией и взаимодействия этой службы с другими службами облачной операционной системы в целях создания единой инфраструктуры. Например, Nova обеспечивает управления вычислительными ресурсами и API для доступа к конфигурированию данных ресурсов, Glance — управления образами и API для управления ими, Cinder — блочное хранилище и API для управления им и тд. Все функции взаимоувязаны между собой очень тесным образом.
Однако если посудить, то все сервисы, запущенные в OpenStack представляет из себя в конечном счете какую либо виртуальную машину (или контейнер), подключенную к сети. Встает вопрос —, а зачем нам столько элементов?
Давайте пробежимся по алгоритму создания виртуальной машины и подключения ее к сети и постоянному хранилищу в Openstack.
- Когда вы создаете запрос на создание машины, будь то запрос через Horizon (Dashboard) или же запрос через CLI, первое что происходит — это авторизация вашего запроса на Keystone — можете ли вы создавать машину, имеет или право использовать данную сеть, хватает ли у вашего проекта квоты и т д.
- Keystone производит аутентификацию вашего запроса и генерирует в ответном сообщении auth-токен, который будет использован далее. Получив ответ от Keystone запрос отправляется в сторону Nova (nova api).
- Nova-api проверяет валидность вашего запроса, обращаясь в Keystone, используя ранее сгенерированный auth-токен
- Keystone производит аутентификацию и предоставляет на основании данного auth-токена информацию по разрешениям и ограничениям.
- Nova-api создает в nova-database запись о новой VM и передает запрос на создание машины в nova-scheduler.
- Nova-scheduler производит выбор хоста (компьют ноды), на которой VM будет развернута на основании заданных параметров, весов и зон. Запись об этом и идентификатор VM записываются в nova-database.
- Далее nova-scheduler обращается к nova-compute с запросом об развертывании инстанса. Nova-compute обращается в nova-conductor для получения информации о параметрах машины (nova-conductor является элементом nova, выполняющим роль прокси сервера между nova-database и nova-compute, ограничивая количество запросов в сторону nova-database во избежании проблем с консистентность базы данных сокращения загрузки).
- Nova-conductor получает из nova-database запрошенную информацию и передает ее nova-compute.
- Далее nova-compute обращается к glance для получения ID образа. Glace проводит валидацию запроса в Keystone и возвращает запрошенную информацию.
- Nova-compute обращается к neutron для получения информации о параметрах сети. Аналогично glance, neutron проводит валидацию запроса в Keystone, после чего создает запись в database (идентификатор порта и т д), создает запрос на создание порта и возвращает запрошенную информацию в nova-compute.
- Nova-compute обращается к cinder с запросом выделения виртуальной машине volume. Аналогично glance, cider проводит валидацию запроса в Keystone, создает запрос на создание volume и возвращает запрошенную информацию.
- Nova-compute обращается к libvirt с запросом разворачивания виртуальной машины с заданными параметрами.
По факту вроде бы простая операция по созданию простой виртуальной машины превращается в такой водоворот api коллов между элементами облачной платформы. Причем, как вы видите, даже ранее обозначенные службы — тоже состоят из более мелких компонент, между которыми происходит взаимодействие. Создание машины — это лишь малая часть того, что дает сделать облачная платформа — есть служба, отвечающая за балансировку трафика, служба, отвечающая за блочное хранилище, служба, отвечающая за DNS, служба, отвечающая за провижининг bare metal серверов и т д. Облако позволяет вам относиться к вашим виртуальным машинам как к стаду баранов (в отличии от виртуализации). Если в виртуальной среде у вас что то произошло с машиной — вы ее восстанавливаете из бекапов и т д, облачные же приложения построены таким образом, что бы виртуальная машины не играла такую важную роль — виртуальная машина «умерла» — не беда — просто создается новая машина на основании темплейта и, как говорится, отряд не заметил потери бойца. Естественно это предусматривает наличие механизмов оркестрации — используя Heat темплейты вы без особых проблем можете развернуть сложную фунцию, состоящую из десятков сетей и виртуальных машин.
Стоит всегда держать в уме то, что облачной инфраструктуры без сети не бывает — каждый элемент так или иначе взаимодействует с другими элементами через сеть. Кроме того облако имеет абсолютно не статичную сеть. Естественно underlay сеть еще более-менее статична — не каждый день добавляются новые ноды и коммутаторы, однако overlay составляющая может и неизбежно будет постоянно менять — будут добавляться или удаляться новые сети, появляться новые виртуальные машины и умирать старые. И как вы помните из определения облака, данного в самом начале статьи — ресурсы должны выделять пользователю автоматически и с наименьшим (а лучше без) вмешательством со стороны сервис провайдера. То есть тот тип предоставления ресурсов сети, который есть сейчас в виде фронтенда в виде вашего личного кабинета доступного по http/https и дежурного сетевого инженера Василия в качестве бэкэнда — это не облако, даже при наличии у Василия восьми рук.
Neutron, являясь сетевой службой, обеспечивает API для управления сетевой частью облачной инфраструктуры. Служба обеспечивает работоспособность и управление сетевой части Openstack обеспечивая уровень абстракции, называемый Network-as-a-Service (NaaS). То есть сеть является такой же виртуальной измеримой единицей, как например виртуальные ядра CPU или объем RAM.
Но перед тем как переходить к архитектуре сетевой части OpenStack, рассмотрим как в OpenStack эта сеть работает и почему сеть является важной и неотъемлемой частью облака.
Итак, у нас есть две виртуальные машины клиента RED и две виртуальные машины клиента GREEN. Предположим, что эти машины расположенные на двух гипервизорах таким образом:
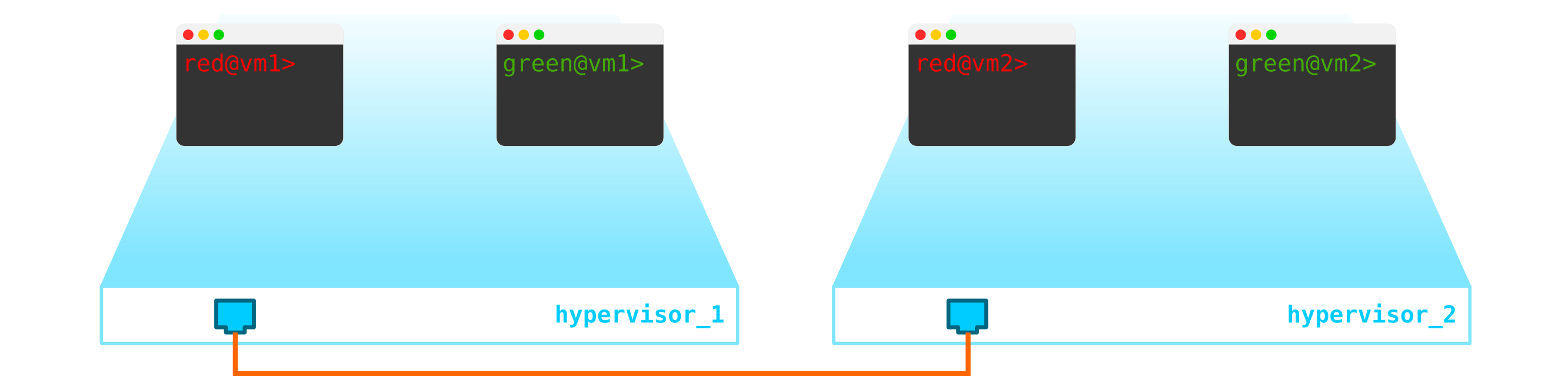
В данный момент это просто виртуализация 4-х серверов и не более того, так как пока что все что мы сделали — виртуализировали 4 сервера, раположив их на двух физических серверах. Причем пока что они даже не подключены к сети.
Чтобы получилось облако нам надо добавить несколько компонент. Во первых виртуализируем сетевую часть — нам надо эти 4 машины попарно соединить, причем клиенты хотят именно L2 соединение. Можно использовать кончено коммутатор и настроить в его сторону транк и разрулить все с помощью linux bridge ну или для более продвинутых юзеров openvswitch (к нему мы еще вернемся). Но сетей может быть очень много, да и постоянно пропихивать L2 через свич — не самая лучшая идея — так разные подразделения, сервис-деск, месяцы ожидания выполнения заявки, недели траблшутинга — в современно мире такой подход уже не работает. И чем раньше компания это понимает — тем легче ей двигаться вперед. Поэтому между гипервизорами выделим L3 сеть через которую будут общаться наши виртуальные машины, а уже поверх данной L3 сети построим виртуальные наложенные L2 (overlay) сети, где будет бегать трафик наших виртуальных машин. Как инкапсуляцию можно использовать GRE, Geneve или VxLAN. Пока остановимся на последнем, хотя это не особо важно.
Нам надо где то расположить VTEP (надеюсь все знакомы с терминологией VxLAN). Так как с серверов у нас выходит сразу L3 сеть, то нам ничего не мешает расположить VTEP на самих серверах, причем OVS (OpenvSwitch) это отлично умеет делать. В итоге мы получили вот такую конструкцию:
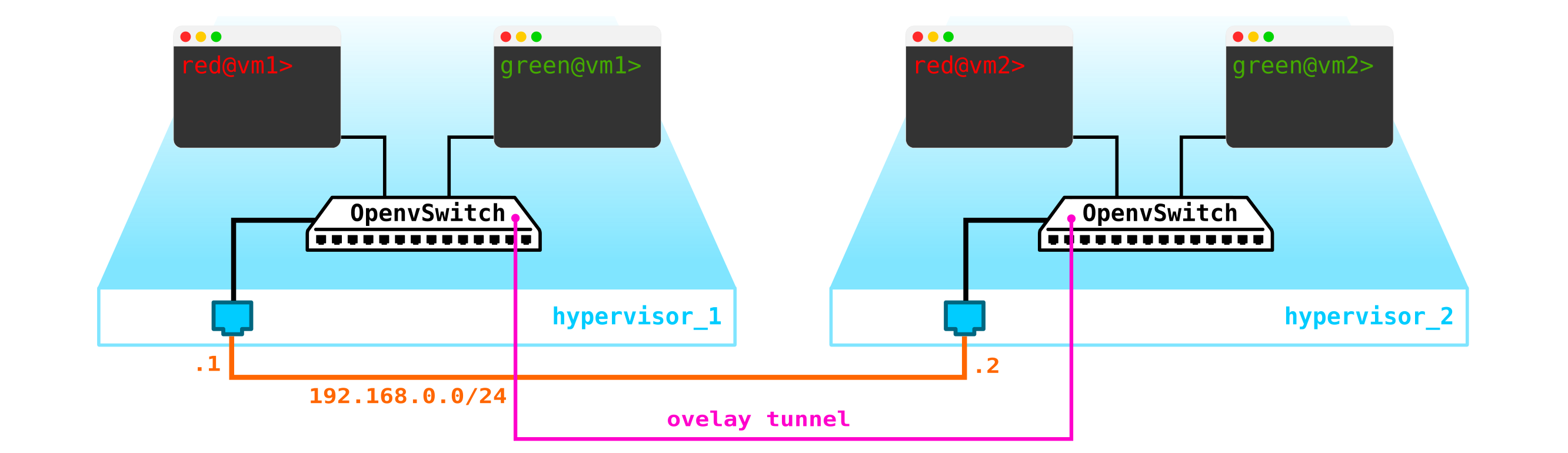
Так как трафик между VM должен быть разделен, то порты в сторону виртуальных машин будут иметь разные номера вланов. Номер тега играет роль только в пределах одного виртуального коммутатора, так как при инкапсулировании в VxLAN мы его можем беспроблемно снять, так как у нас будет VNI.

Теперь мы можем плодить наши машины и виртуальные сети для них без каких либо проблем.
Однако что если у клиента будет еще одна машина, но находится в другой сети? Нам нужен рутинг между сетями. Мы разберем простой вариант, когда используется централизованный рутинг — то есть трафик маршрутизируется через специальные выделенные network ноды (ну как правило они совмещены с control нодами, поэтому у нас будет тоже самое).
Вроде бы ничего сложного — делаем бридж интерфейс на контрольной ноде, гоним на нее трафик и оттуда маршрутизируем его куда нам надо. Но проблема в том, что клиент RED хочет использовать сеть 10.0.0.0/24, и клиент GREEN хочет использовать сеть 10.0.0.0/24. То есть у нас начинается пересечение адресных пространств. Кроме того клиенты не хотят, чтобы другие клиенты могли маршрутизироваться в их внутренние сети, что логично. Чтобы разделить сети и трафик данных клиентов мы для каждого из них выделим отдельный namespace. Namespace — это по факту копия сетевого стека Linux, то есть клиенты в namespace RED полностью изолированы от клиентов из namespace GREEN (ну либо маршрутизация между данными сетями клиентов разрешена через default namespace либо уже на вышестоящем транспортном оборудовании).
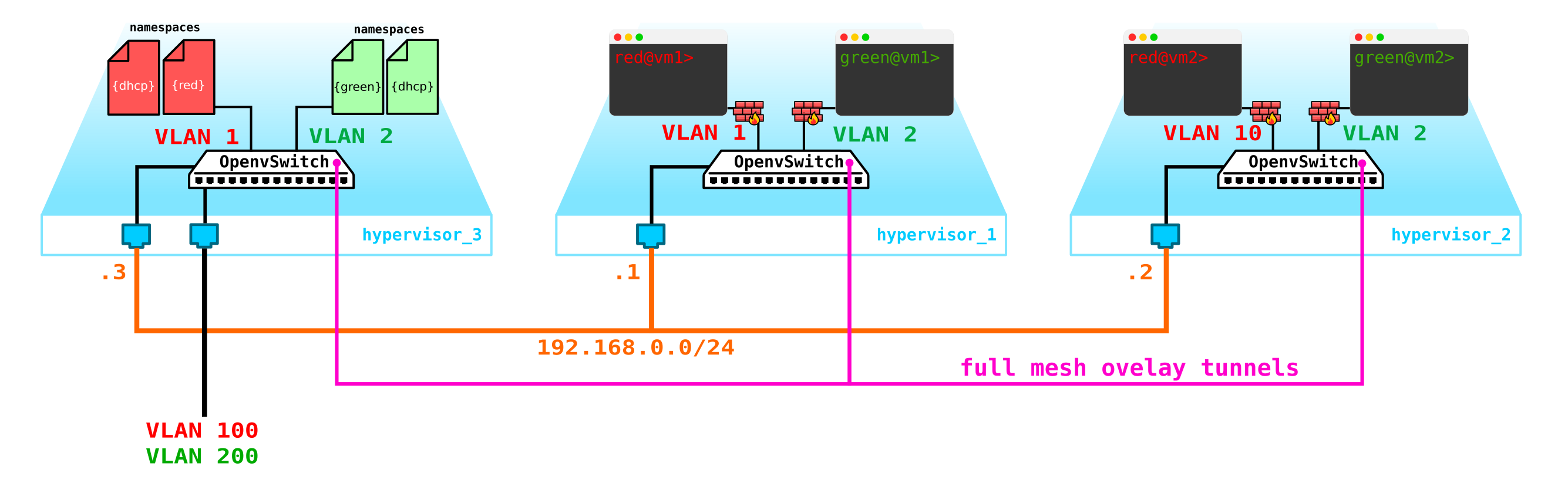
То есть получаем такую схему:
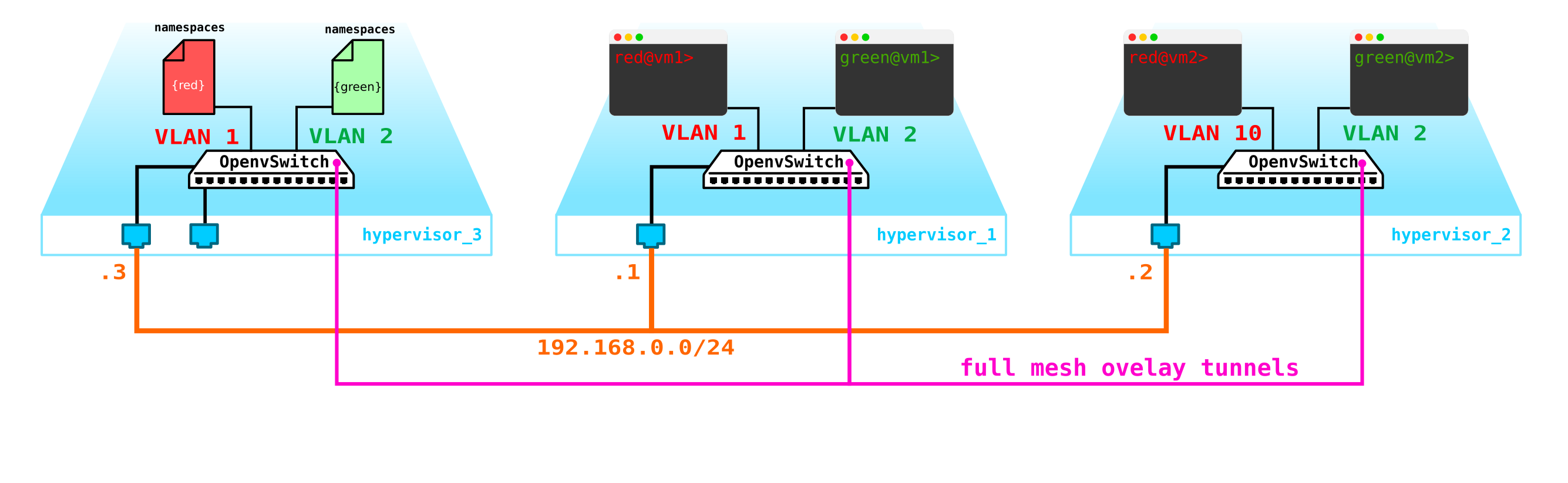
L2 тоннели сходятся со всех вычислительных нод на контрольную. ноду, где расположен L3 интерфейс для данных сетей, каждый в выделенном namespace для изоляции.
Однако мы забыли самое главное. Виртуальная машина должна предоставлять сервис клиенту, то есть она должна иметь хотя бы один внешний интерфейс, через который к ней можно достучаться. То есть нам нужно выйти во внешний мир. Тут есть разные варианты. Сделаем самый просто вариант. Добавим клиентам по одной сети, которые будут валидны в сети провайдера и не будут пересекаться с другими сетями. Сети могу быть тоже пересекающимися и смотреть в разные VRF на стороне провайдерской сети. Данные сети также будут жить в namespace каждого из клиентов. Однако выходить во внешний мир они все равно будут через один физический (или бонд, что логичнее) интерфейс. Чтобы разделить трафик клиентов трафик, выходящий наружу будет производиться тегирование VLAN тегом, выделенным клиенту.
В итоге мы получили вот такую схему:

Резонный вопрос — почему не сделать шлюзы на самих compute нодах? Большой проблемы в этом нет, более того, при включении распределенного маршрутизатора (DVR) это так и будет работать. В данном сценарии мы рассматриваем самый простой вариант с централизованным gateway, который в Openstack используется по умолчанию. Для высоконагруженных функций будут использовать как распределенный маршрутизатор, так и технологии ускорения типа SR-IOV и Passthrough, но как говорится, это уже совсем другая история. Для начала разберемся с базовой частью, а потом уйдем в детали.
Собственно наша схема уже работоспособна, однако есть пара нюансов:
- Нам надо как то защитить наши машины, то есть повесить на интерфейс свича в сторону клиента фильтр.
- Сделать возможность автоматического получения ip адреса виртуальной машиной, чтобы не пришлось каждый раз заходить в нее через консоль и прописывать адрес.
Начнем с защиты машин. Для этого можно использовать банальные iptables, почему бы и нет.
То есть теперь наша топология уже немного усложнилась:
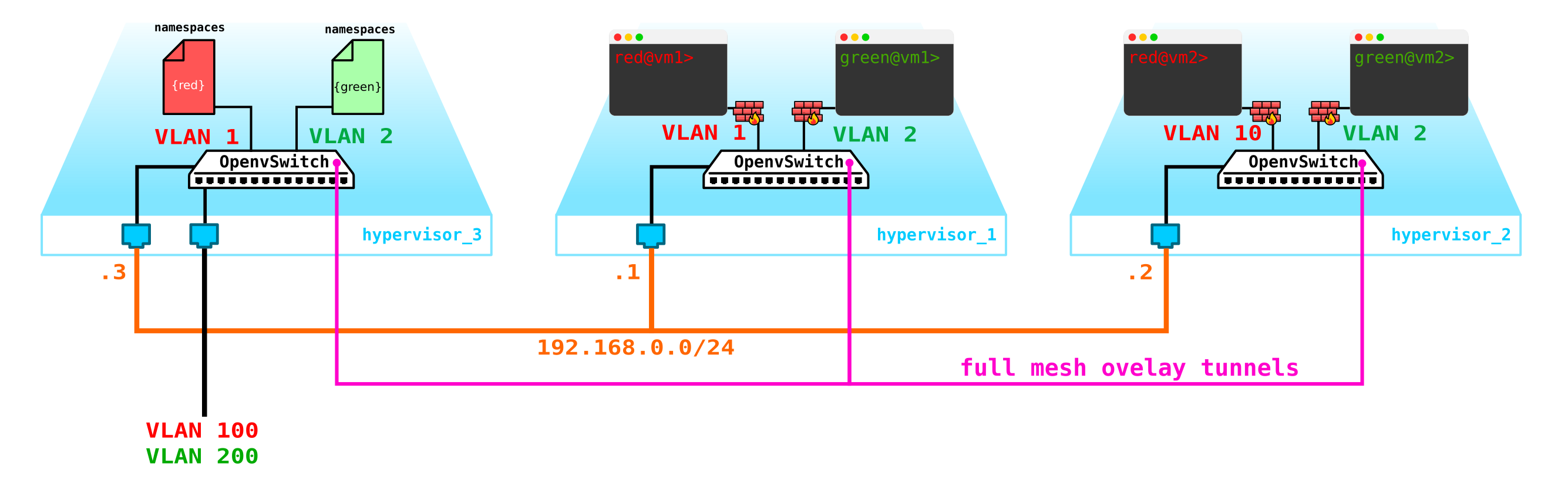
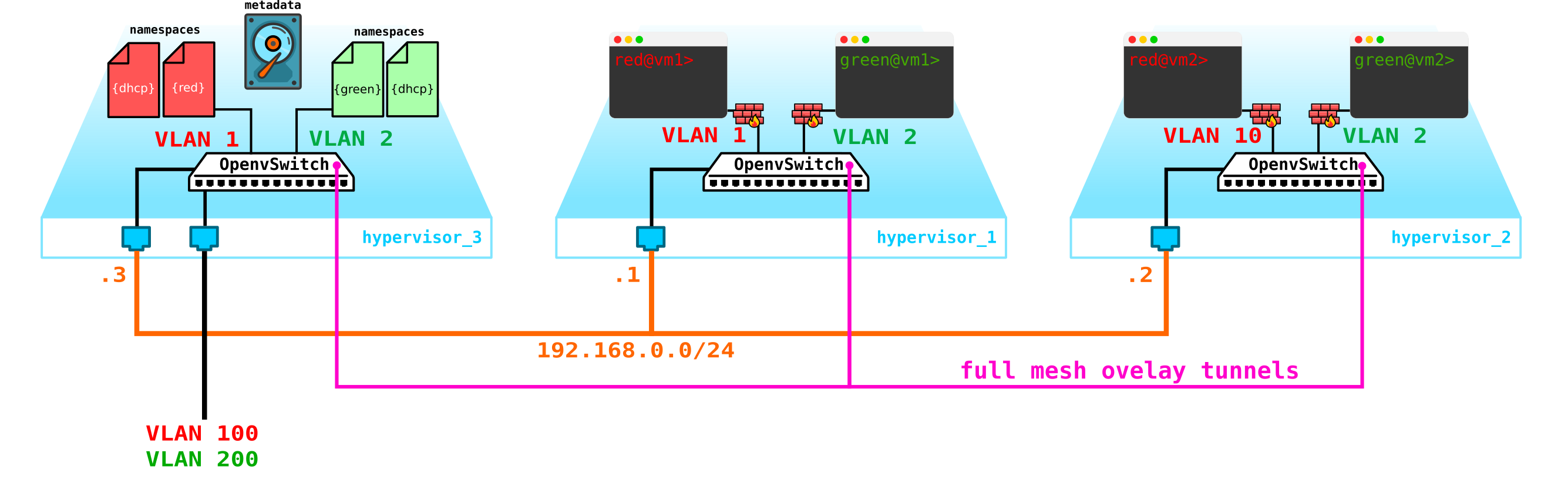
Пойдем далее. Нам надо добавить DHCP сервер. Самым идеальным местом для расположения DHCP серверов для каждого из клиентов будет уже упомянутая выше контрольная нода, где расположены namespaces:
Однако, есть небольшая проблема. То если все перезагрузится и вся информация по аренде адресов на DHCP пропадет. Логично, что машинам будут выданы новые адреса, что не очень удобно. Выхода тут два — либо использовать доменные имена и добавить DNS сервер для каждого клиента, тогда нам адрес будет не особо важен (по аналогии с сетевой часть в k8s) —, но тут есть проблема с внешними сетями, так как в них адреса также могу быть выданы по DHCP — нужна синхронизация с DNS серверов в облачной платформе и внешним DNS сервером, что на мой взгляд не очень гибко, однако вполне возможно. Либо второй вариант — использовать метаданные — то есть сохранять информацию о выданной машине адресе чтобы DHCP сервер знал, какой адрес машине выдать, если машина уже получала адрес. Второй вариант проще и гибче, так как позволяет сохранить доп информацию о машине. Теперь на схему добавим metadata агента:
Еще один вопрос который также стоит освятить — это возможность использовать одну внешнюю сеть всеми клиентами, так как внешние сети, если они должны быть валидны во всей сети, то будет сложность — надо постоянно выделять и контролировать выделение этих сетей. Возможность использования единой для всех клиентов внешней предконфигурированной сети будет очень кстати при создании публичного облака. Это упростит развертывание машин, так как нам не надо сверяться с базой данных адресов и выбирать уникальное адресное пространство для внешней сети каждого клиента. К тому же мы можем прописать внешнюю сеть заранее и в момент развертывания нам надо будет всего лишь ассоциировать внешние адреса с клиентскими машинами.
И тут на помощь нам приходит NAT — просто сделаем возможность клиентов выходить во внешний мир через default namespace с использованием NAT трансляции. Ну и тут небольшая проблема. Это хорошо, если клиентский сервер работает как клиент, а не как сервер — то есть инициирует, а не принимает подключения. Но у нас то будет наоборот. В там случае нам надо сделать destination NAT, чтобы при получении трафика контрольная нода понимала, что данный трафик предназначен виртуальной машине А клиента А, а значит надо сделать NAT трансляцию из внешнего адреса, например 100.1.1.1 во внутренний адрес 10.0.0.1. В таком случае, хотя все клиенты будут использовать одну и ту же сеть, внутренняя изоляция полностью сохраняется. То есть нам надо на контрольной ноде сделать dNAT и sNAT. Использовать единую сеть с выделением плавающих адресов или внешние сети или же и то и то сразу — обуславливается тем, что вы хотите в облако затянуть. Мы не будем наносить на схему еще и плавающие адреса, а оставим уже добавленные ранее внешние сети — у каждого клиента есть своя внешняя сеть (на схеме обозначены как влан 100 и 200 на внешнем интерфейсе).
В итоге мы получили интересное и в то же время продуманное решение, обладающее определенной гибкость, но пока что не обладающее механизмами отказоустойчивости.
Во первых у нас всего одна контрольная нода — выход ее из строя приведет к краху все системы. Для устранения данной проблемы необходимо сделать как минимум кворум из 3-х нод. Добавим это на схему:
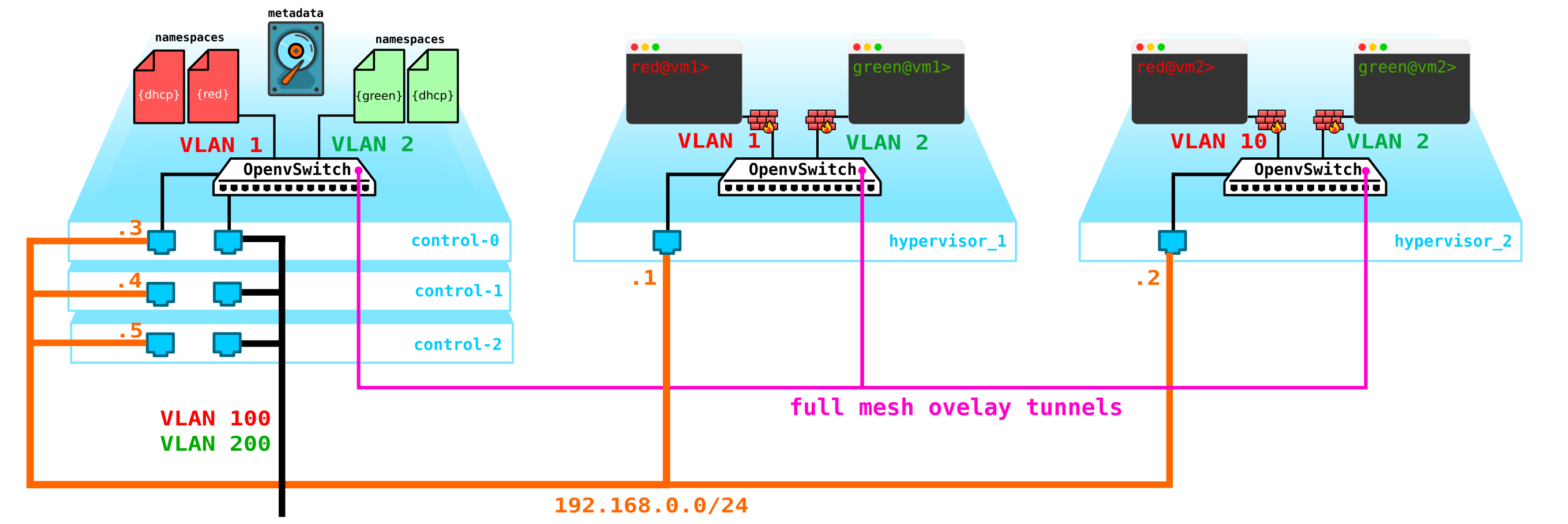
Естественно все ноды синхронизируются и при выходе активной ноды ее обязанности на себя возьмет другая нода.
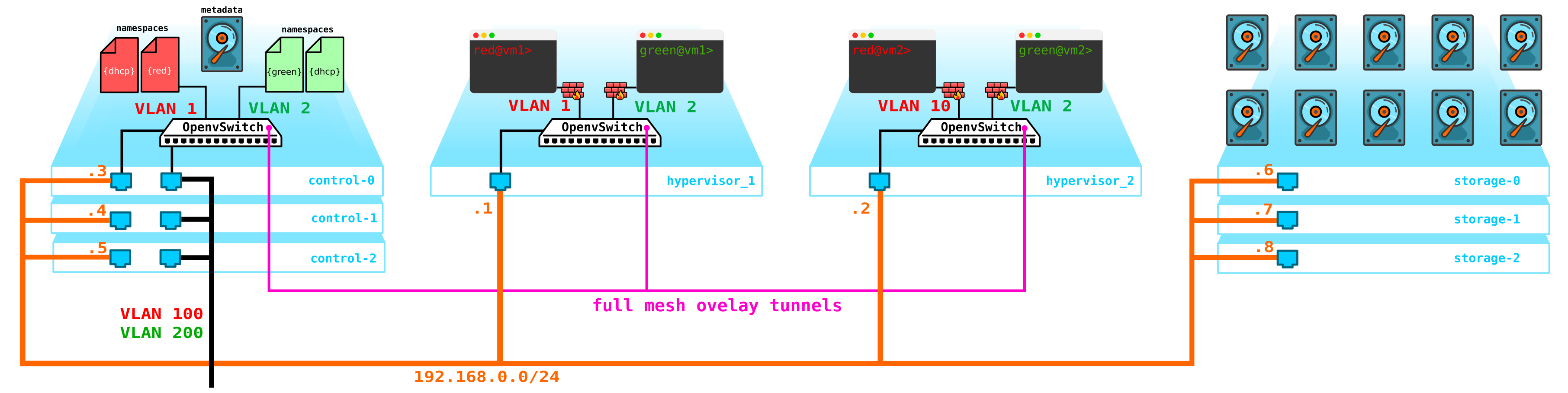
Следующая проблема — диски виртуальных машин. В данный момент они хранятся на самих гипервизорах и в случае проблем с гипервизором мы теряем все данные — и наличие рейда тут никак не поможет если мы потеряем не диск, а весь сервер целиком. Для этого нам нужно сделать службу, которая будет выступать фронтэндом для какого либо хранилища. Какое это будет хранилище нам особо не важно, но оно должно защитить наши данные от выхода из строя и диска и ноды, а возможно и целого шкафа. Вариантов тут несколько — есть конечно SAN сети с Fiber Channel, но скажем честно — FC это уже пережиток прошлого — аналог E1 в транспорте — да согласен, он еще используется, но только там, где без него ну никак нельзя. Поэтому добровольно разворачивать FC сеть в 2020 году я бы не стал, зная о наличии других более более интересных альтернатив. Хотя каждому свое и возможно найдутся те, кто считает, что FC со всеми его ограничениями — все что нам надо — не буду спорить, у каждого свое мнение. Однако наиболее интересным решением на мой взгляд является использование SDS, например Ceph.
Ceph позволяет построить выскодоступное решение для хранения данных с кучей возможных вариантов резервирования, начиная с кодов с проверкой четности (аналог рейд 5 или 6) заканчивая полной репликацией данных на разные диски с учетом расположения дисков в серверах, и серверов в шкафах и т д.
Для сборки Ceph нужно еще 3 ноды. Взаимодействие с хранилищем будет производиться также через сеть с использованием служб блочного, объектного и файлового хранилищ. Добавим в схему хранилище:
Всем этим добром надо как то управлять — нужно что то, через что мы можем создать машину, сеть, виртуальный маршрутизатор и т д. Для этого на контрольную ноду добавим службу, которая будет выполнять роль dashboard — клиент сможет подключиться к данному порталу через http/https и сделать все, что ему надо (ну почти).
В итоге теперь мы имеем отказоустойчивую систему. Всеми элементами данной инфраструктуры надо как то управлять. Ранее было описано, что Openstack — это набор проектов, каждый их которых обеспечивает какую то определенную функцию. Как мы видим элементов, которые надо конфигурировать и контролировать более чем достаточно. Сегодня мы поговорим о сетевой части.
Архитектура Neutron.
В OpenStack именно Neutron отвечает за подключение портов виртуальных машин к общей L2 сети, обеспечение маршрутизации трафика между VM, находящимися в разных L2 сетях, а также маршрутизацию наружу, предоставление таких сервисов как NAT, Floating IP, DHCP и т д.
Высокоуровнево работу сетевой службы (базовая часть) можно описать так.
При запуске VM сетевая служба
- Создает порт для данной VM (или порты) и оповещает об этом DHCP сервис;
- Создается новый виртуальный сетевой девайс (через libvirt);
- VM подключается к созданному на 1 шаге порту (портам);
Как ни странно, но в основе работы Neutron лежат стандартные механизмы, знакомые всем, что когда либо погружался в Linux — это namespaces, iptables, linux bridges, openvswitch, conntrack и т д.
Следует сразу уточнить, что Neutron не является SDN контроллером.
Neutron состоит из нескольких взаимоувязанных между собой компонент: 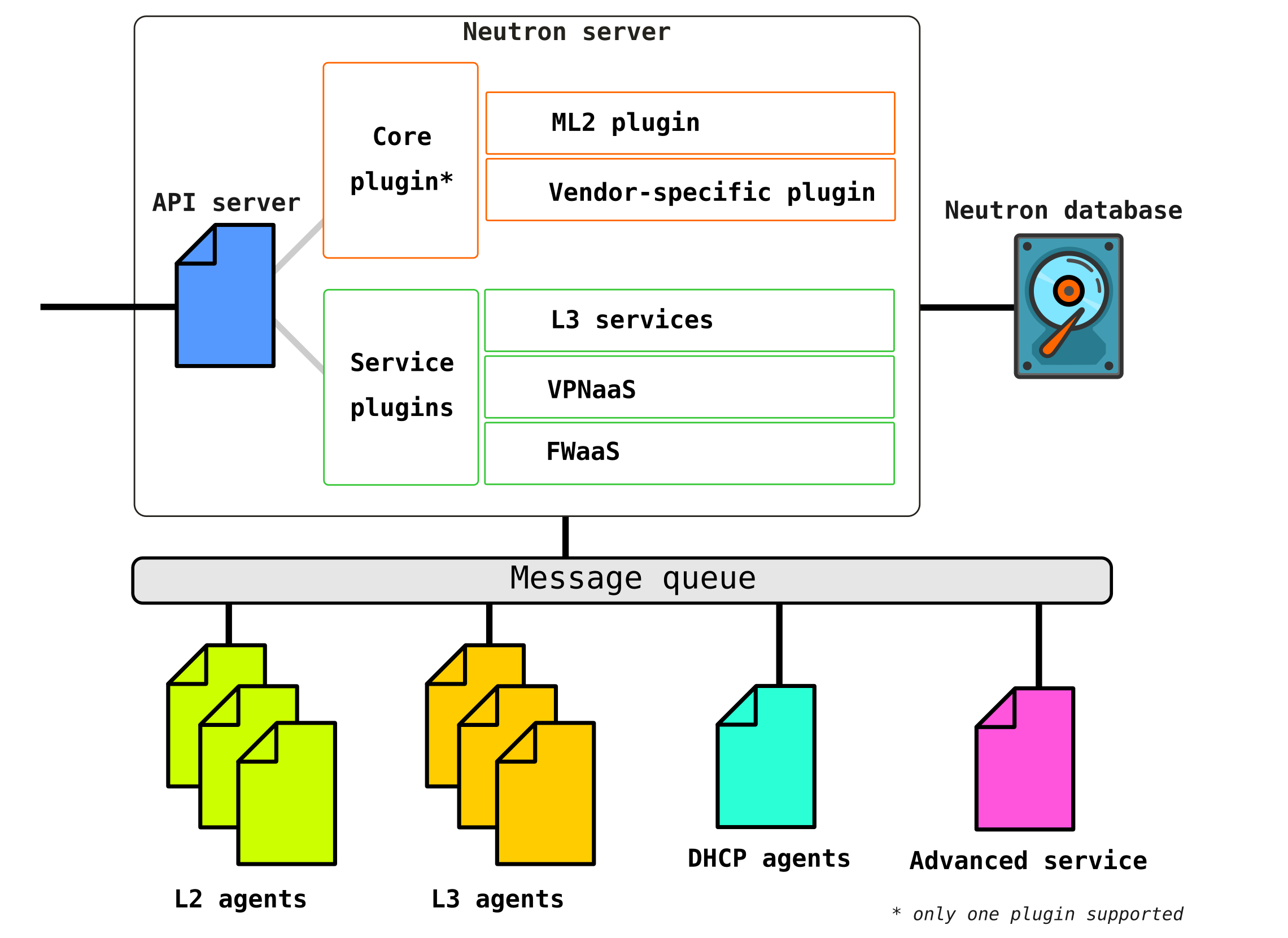
Openstack-neutron-server — это демон, который через API работает с пользовательскими запросами. Данный демон не занимается прописыванием каких либо сетевых связностей, а дает необходимую для этого информацию своим плагинам, которые далее настраивают нужный элемент сети. Neutron-агенты на узлах OpenStack регистрируются на сервере Neutron.
Neutron-server это фактически приложение, написанное на python, состоящее из двух частей:
REST service
Neutron Plugin (core/service)
REST сервис предназначен для приема API вызовов от остальных компонент (например запрос на предоставление какой либо информации и т д)
Плагины это подключаемые программные компоненты/модули которые вызываются при API запросах — то есть приписывание какого то сервиса происходит через них. Плагины делятся на два вида — сервисный и корневой. Как правило коневой плагин отвечает в основном за управление адресным пространством и L2 соединения между VM, а сервисные плагины уже обеспечивают дополнительный функционал например VPN или FW.
Список доступных на сегодня плагинов можно посмотреть например тут
Сервисных плагинов может быть несколько, однако коневой плагин может быть только один.
Openstack-neutron-ml2 — это стандартный корневой плагин Openstack. Данный плагин имеет модульную архитектуру (в отличии от своего предшественника) и через подключаемые к нему драйверы производит конфигурирование сетевого сервиса. Сам плагин рассмотрим чуть позже, так как фактически он дает ту гибкость, которой обладает OpenStack в сетевой части. Корневой плагин может быть заменен (например Contrail Networking делает такую замену).
RPC service (rabbitmq-server) — сервис, обеспечивающий управлением очередями и взаимодействие с другими службами OpenStack, а также взаимодействие между агентами сетевой службы.
Network agents — агенты, которые расположены в каждой ноде, через которые и производится конфигурирование сетевых сервисов.
Агенты бывают нескольких видов.
Основной агент — это L2 agent. Эти агенты запускаются на каждом из гипервизоров включая и контрольные ноды (точнее сказать на всех узлах, которые предоставляют какой либо сервис для тенантов) и их основная функция — подключение виртуальных машин к общей L2 сети, а также генерировать оповещения при возникновении каких либо событий (например отключения/включения порта).
Следующим, не менее важным агентом является L3 agent. По умолчанию этот агент запускается исключительно на network ноде (часто network node совмещается с control node) и обеспечивает маршрутизацию между сетями тенантов (как между его сетями и сетями других тенатов, так и доступен во внешний мир, обеспечивая NAT, а также DHCP сервис). Однако при использовании DVR (распределенный маршрутизатор) необходимость в L3 плагине появляется и на compute нодах.
L3 агент использует Linux namespaces для предоставления каждому тенанту набора собственных изолированных сетей и функционал виртуальных маршрутизаторов, которые маршрутизируют трафик и предоставляют услуги шлюза для Layer 2 сетей.
Database — база данных идентификаторов сетей, подсетей, портов, пулов и т д.
Фактически Neutron принимает API запросы от на создание каких либо сетевых сущностей аутентифицирует запрос, и через RPC (если обращается к какому то плагину или агенту) или REST API (если общается в SDN) передает агент
