[Перевод] Как машинное обучение и искусственный интеллект ускоряют поиск новых лекарств

The light inside me by Wilvarin-Liadon
Команда Mail.ru Cloud Solutions перевела в сокращенном варианте эссе Кевина Ву, который рассуждает о том, чего уже добилась фармацевтическая промышленность и здравоохранение с помощью искусственного интеллекта и машинного обучения, а также когда новые технологии помогут найти лекарства от всех болезней.
Почему может казаться, что прогресса нет
Некоторые высказывают разочарование жизнью примерно так: «Если это будущее, то где мой реактивный ранец?» На первый взгляд, такая тоска по ретро-будущему кажется странной в эпоху вездесущих вычислений, программируемых клеток и возрождающихся космических исследований. Но у некоторых такой ностальгический футуризм держится удивительно стойко. Они цепляются за предсказания, которые выглядят странно в ретроспективе, игнорируя поразительную реальность, которую никто не мог предсказать.
Кто мог подумать, что благодаря глубокому обучению мы сможем предсказывать свойства пока несуществующих лекарств? Это имеет огромное значение для фармацевтической промышленности.
Применительно к искусственному интеллекту жалобы могут звучать примерно так: «Прошло почти восемь лет после изобретения нейросети AlexNet [прим. переводчика: в 2012 году Алексей Крижевский опубликовал дизайн сверточной нейросети AlexNet, которая с большим отрывом победила в соревновании ImageNet ], ну и где мой беспилотный автомобиль?» Действительно, может показаться, что ожидания середины 2010-х годов остались неудовлетворенными. Среди пессимистов набирают обороты прогнозы о следующем застое в исследованиях искусственного интеллекта.
Цель этого эссе — обсудить значимый прогресс машинного обучения в реальной задаче открытия новых лекарств. Хочу напомнить другую старую пословицу, на этот раз от исследователей ИИ. Если слегка перефразировать, она звучит так: «ИИ называют ИИ, пока он не заработает, потом это просто софт».
То, что еще несколько лет назад считалось передовыми фундаментальными исследованиями в области машинного обучения, теперь часто называют «просто наукой о данных» (или даже аналитикой) — и она производит настоящую революцию в фармацевтической промышленности. Есть солидный шанс, что применение глубокого обучения для открытия лекарств серьезно изменит наши жизни к лучшему.
Компьютерное зрение и глубокое обучение в биомедицинской визуализации
Как только ученые получили доступ к компьютерам и появилась возможность загружать туда изображения, они сразу попытались их обработать. В основном, речь о биомедицинских изображениях: рентгенограммах, результатах УЗИ и МРТ. Во времена «старого доброго ИИ» обработка обычно означала выведение вручную логических утверждений на основе простых признаков, таких как контуры и яркость.
В 1980-х годах произошел сдвиг в сторону алгоритмов машинного обучения с учителем, но они по-прежнему опирались на признаки, установленные вручную. Простые модели обучения с учителем (например, линейная регрессия или полиномиальное приближение) обучаются на признаках, извлеченных такими алгоритмами, как SIFT (масштабно-инвариантная трансформация признаков) и HOG (гистограмма направленных градиентов). Не следует удивляться, что разработки, которые сегодня привели к практическому применению глубокого обучения, стартовали еще десятилетия назад.
Сверточные нейронные сети впервые применили для анализа биомедицинских изображений в 1995 году, когда Ло с коллегами представили модель для распознавания раковых опухолей в легких на флюорограммах. Их метод немного отличался от того, к чему мы привыкли сегодня, выведение результата занимало около 15 секунд, но концепция была по существу той же самой — с обучением через обратное распространение вплоть до сверточных ядер нейросети. Их модель предусматривала два скрытых слоя, тогда как у популярных сегодня архитектур глубинных сетей часто сто и более слоев.
Перенесемся в 2012 год. Сверточные нейросети произвели фурор с появлением системы AlexNet, что привело к скачку в производительности теперь уже знаменитого набора данных ImageNet. Успех AlexNet, сети с пятью сверточными и тремя плотно связанными слоями, обученными на игровых GPU, стал настолько известен в области машинного обучения, что люди теперь говорят о »моментах ImageNet» в разных нишах машинного обучения и ИИ.
Например, «обработка естественного языка, возможно, пережила свой момент ImageNet с разработкой больших трансформеров в 2018 году» или «обучение с подкреплением всё еще ждет своего момента ImageNet».
Прошло почти десять лет после AlexNet. Модели компьютерного зрения и глубокого обучения постепенно совершенствуются. Приложения вышли за пределы классификации. Сегодня они научились сегментировать изображения, оценивать глубину и автоматически реконструировать 3D-сцены по нескольким 2D-изображениям. И это далеко не полный список их возможностей.
Глубокое обучение для анализа биомедицинских изображений стало горячей областью исследований. Побочный эффект — неизбежное увеличение шума. В 2019 году опубликовано примерно 17 000 научных статей о глубоком обучении. Конечно, не все из них достойны прочтения. Вероятно, многие исследователи слишком переобучают модели на своих скромных наборах данных.
Большинство из них не внесло никакого вклада ни в фундаментальную науку, ни в машинное обучение. Страсть к глубокому обучению охватила академических исследователей, которые ранее не проявляли к нему никакого интереса, и это неспроста. Оно может делать то же, что и классические алгоритмы компьютерного зрения (см. универсальную теорему аппроксимации Цыбенко и Хорника), и часто делает это быстрее и лучше, избавляя инженеров от утомительного проектирования каждого нового приложения вручную.
Редкая возможность бороться с «забытыми» болезнями
Это подводит нас к сегодняшней теме открытия новых лекарств — отрасли, которую ожидает хорошая встряска. Фармацевтические компании и их подрядчики любят повторять об огромных затратах на вывод нового препарата на рынок. Эти затраты в значительной степени обусловлены тем, что многие лекарственные препараты долго изучаются и тестируются, прежде чем пойти в расход.
Затраты на разработку нового лекарственного препарата могут достигать $2,5 млрд или более. Иногда из-за высокой стоимости и относительно низкой рентабельности на задний план отодвигаются ряд работ над некоторыми классами лекарств.
Это также ведет к всплеску заболеваемости в метко названной категории «забытых болезней», включая непропорционально большое число тропических болезней, которыми страдают жители беднейших стран и которые считаются невыгодными для лечения, а также редких болезней с низкими показателями заболеваемости. Каждым из них страдает относительно немного человек, но общее число людей со всеми редкими заболеваниями довольно велико. По оценкам, около 300 миллионов человек. И даже это число может оказаться заниженным из-за мрачной оценки экспертов: около 30% страдающих редким заболеванием не доживают до пяти лет.
«Длинный хвост» редких заболеваний — это существенный потенциал для улучшения жизни огромного количества людей, и здесь на помощь приходят машинное обучение и обработка больших данных. Слепое пятно в отношении редких (орфанных) заболеваний, у которых нет официально одобренного лечения, открывает возможность для инноваций со стороны небольших команд биологов и разработчиков машинного обучения.
Один такой стартап в Солт-Лейк-Сити, штат Юта, пытается сделать именно это. Основатели Recursion Pharmaceuticals расценивают отсутствие лекарств для лечения редких заболеваний как пробел в фармацевтической промышленности. Они получают огромные объемы данных, анализируя результаты микроскопии и лабораторных анализов. С помощью нейронных сетей можно выявлять особенности заболеваний и искать методы лечения.
К концу 2019 года компания провела тысячи экспериментов и собрала более 4 петабайт информации. Небольшое подмножество этих данных (46 ГБ) они выложили для конкурса NeurIps 2019, можете скачать их с сайта RxRx и поиграться самостоятельно.
Описанный в этой статье рабочий процесс в значительной степени основан на информации из официальных документов [pdf] компании Recursion Pharmaceuticals, но этот подход вполне может послужить источником вдохновения для других областей.
Среди других стартапов в этой области можно назвать Bioage Labs (болезни, связанные со старением), Notable Labs (онкология) и TwoXAR (различные заболевания, для которых отсутствуют варианты лечения). Как правило, молодые стартапы занимаются инновационными методами обработки данных и применяют разнообразные методы машинного обучения в дополнение или вместо глубокого обучения с компьютерным зрением.
Далее я опишу процесс анализа изображений и то, как глубокое обучение вписывается в рабочий процесс открытия лекарств для редких заболеваний. Мы рассмотрим процесс на высоком уровне, который применим к целому ряду других областей поиска новых лекарств.
Например, его легко использовать для скрининга лекарств от рака по их влиянию на морфологию опухолевых клеток. Возможно, даже для анализа реакции клеток конкретных пациентов на разные варианты лекарств. Этот подход использует понятия из нелинейного метода главных компонент, семантического хэширования [pdf] и старой доброй классификации изображений сверточной нейросетью.
Классификация в морфологическом шуме
Биология — это бардак. Поэтому высокопроизводительная многопараметрическая микроскопия — источник постоянного разочарования для клеточных биологов. Полученные изображения сильно отличаются от одного эксперимента к другому. Колебания температуры, времени воздействия, количества реагентов и другие приводят к изменениям, не связанным с изучаемым фенотипом или действием лекарства, а значит, к ошибкам в полученных результатах.
Может быть, климат-контроль в лаборатории по-разному работает летом и зимой? Может, кто-то пообедал рядом с препаратами, прежде чем вставить их в микроскоп? Может, сменился поставщик одного из ингредиентов питательной среды? Или поставщик сменил собственного поставщика? На результат эксперимента влияет огромное число переменных. Отслеживание и выделение непреднамеренного шума — одна из основных задач в области поиска новых лекарств, основанного на анализе данных.
Изображения под микроскопом могут сильно отличаться в одинаковых экспериментах. Яркость изображения, форма клеток, форма органелл и многие другие характеристики изменяются из-за соответствующих физиологических эффектов или случайных погрешностей.
Так, изображения на рисунке ниже получены из одного и того же общедоступного набора микрографов метастатических раковых клеток, собранного Скоттом Уилкинсоном и Адамом Маркусом. Вариации насыщенности и морфологии должны отражать погрешность экспериментальных данных. Они создаются путем введения искажений в процесс обработки. Это своего рода аналог аугментации, которую исследователи применяют для регуляризации глубокой нейронной сети в задачах классификации. Поэтому неудивительно, что способность к обобщению больших моделей на больших наборах данных — логичный выбор для поиска физиологически значимых признаков в море шума.
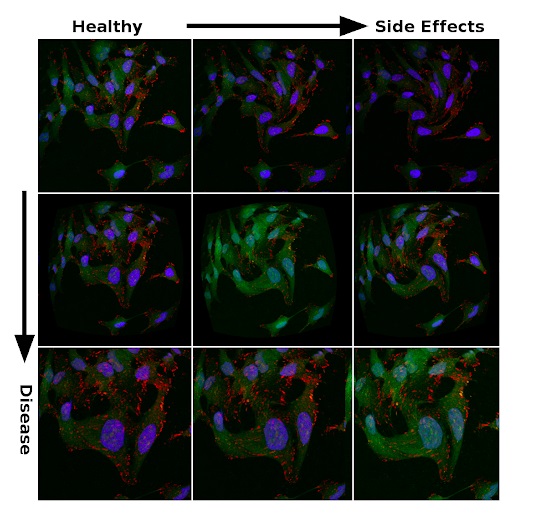
Признаки эффективности лечения и побочных эффектов среди зашумленных данных
Основной причиной редких заболеваний обычно является генетическая мутация. Чтобы построить модели для поиска лечения этих заболеваний, нужно понять эффекты большого диапазона мутаций и их взаимосвязи с разными фенотипами. Чтобы эффективно сравнивать возможные методы лечения конкретного редкого заболевания, проводится обучение нейросетей на базе из тысяч различных мутаций.
Эти мутации можно имитировать, подавляя экспрессию генов с помощью малых интерферирующих РНК (siRNA). Это немного похоже на то, как малыши хватают вас за лодыжки: даже если вы умеете быстро бегать, ваша скорость сильно снизится с племянницей или племянником, висящими на каждой ноге. siRNA действует примерно также: небольшая последовательность интерферирующих РНК прилипает к соответствующим частям матричной РНК конкретных генов, не допуская их полной экспрессии.
Обучаясь на тысячах мутаций вместо сингулярной клеточной модели конкретного заболевания, нейронная сеть учится кодировать фенотипы в многомерном скрытом пространстве. Полученный код позволяет оценить лекарственные препараты по их способности приблизить фенотип заболевания к здоровому фенотипу, каждый из которых представлен многомерным набором координат. Точно так же побочные эффекты лекарств можно встроить в кодированное представление фенотипа, а лекарства оцениваются не только по исчезновению симптомов заболевания, но и по минимизации вредных побочных эффектов.

Диаграмма отражает влияние лечения на клеточную модель заболевания (представлена красной точкой). Лечение представляет собой перемещение закодированного фенотипа ближе к здоровому фенотипу (синяя точка). Это упрощенное трехмерное представление фенотипического кодирования в многомерном скрытом пространстве
Модели глубокого обучения, используемые для этого рабочего процесса, во многом похожи на другие задачи классификации с большим набором данных, хотя если вы привыкли работать с малым количеством категорий, как в наборах данных CIFAR-10 и CIFAR-100, то не сразу привыкнете к тысячам различных классификационных меток.
Кроме того, этот метод поиска лекарств на основе изображений хорошо работает с той же архитектурой на основе DenseNet или ResNet с сотней слоев, которая обеспечивает оптимальную производительность на наборах данных вроде ImageNet.
Значения активации слоев, закодированные в многомерном пространстве, отражают фенотип, патогенез заболевания, взаимосвязи между лечением, побочными эффектами и другими недугами. Поэтому все эти факторы можно анализировать путем смещения в кодируемом пространстве. Этот фенотипический код можно подвергнуть специальной регуляризации (например, путем минимизации ковариации между разными активациями слоев), чтобы уменьшить корреляции кодирования или для других целей.
На рисунке ниже показана упрощенная модель. Черные стрелки представляют операции свертки + подвыборки (pooling). Синие линии представляют плотные соединения. Для простоты количество слоев уменьшено и не показаны остаточные residual-соединения.
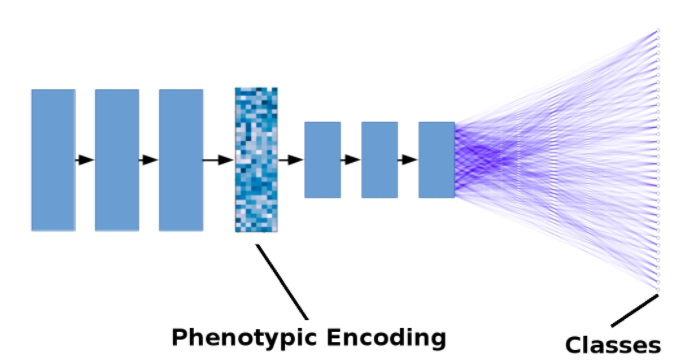
Упрощенная иллюстрация модели глубокого обучения для поиска лекарств
Будущее глубокого обучения в области поиска лекарств и фармацевтической промышленности
Высокая стоимость вывода на рынок новых препаратов привела к тому, что фармацевтические компании часто делают выбор в пользу рыночных «хитов» вместо исследования лекарств для серьезных заболеваний. Небольшие, команды дата-аналитиков в стартапах лучше подготовлены для инноваций в этой области, а забытые и редкие заболевания дают возможность выйти на рынок и продемонстрировать ценность машинного обучения.
Эффективность этого подхода доказана. Мы видим существенный прогресс в исследованиях, а несколько препаратов уже находятся на первом этапе клинических испытаний. Например, этого достигают команды всего из нескольких сотен ученых и инженеров в таких компаниях, как Recursion Pharmaceuticals. Другие стартапы совсем рядом: у TwoXAR несколько кандидатов на лекарства, которые проходят доклинические испытания в других категориях заболеваний.
Можно ожидать, что подход глубокого обучения и компьютерного зрения для разработки лекарственных средств окажет значительное влияние на крупные фармацевтические компании и здравоохранение в целом. Вскоре мы увидим, как это отразится на разработке новых методов лечения распространенных заболеваний (включая сердечно-сосудистые заболевания и диабет), а также редких недугов, которые до сегодняшнего дня оставались вне поля зрения.
Что еще почитать по теме:
- Форматы файлов в больших данных: краткий ликбез.
- Анализ больших данных в облаке: как компании стать дата-ориентированной.
- Наш Telegram-канал о цифровой трансформации.
