Теория вероятностей в машинном обучении. Часть 2: модель классификации
В предыдущей части мы рассматривали вероятностную постановку задачи машинного обучения, статистические модели, модель регрессии как частный случай и ее обучение методом максимизации правдоподобия.
В данной части рассмотрим метод максимизации правдоподобия в классификации: в чем роль кроссэнтропии, функций сигмоиды и softmax, как кроссэнтропия связана с «расстоянием» между распределениями вероятностей и почему модель регрессии тоже обучается через минимизацию кроссэнтропии. Данная часть содержит много отсылок к формулам и понятиям, введенным в первой части, поэтому рекомендуется читать их последовательно.
В третьей части (статья планируется) перейдем от метода максимизации правдоподобия к байесовскому выводу и его различным приближениям.
Содержание текущей части
В первом разделе мы рассмотрим модель классификации, кроссэнтропию и ее связь с методом максимизации правдоподобия, а также ряд несколько фактов про функции softmax и sigmoid.
Во втором разделе поговорим о связи минимизации кроссэнтропии с минимизацией расхождения Кульбака-Лейблера, и как минимизация расхождения Кульбака-Лейблера может помочь в более сложных случаях, чем обычная классификация и регрессия.
Звездочкой* отмечены дополнительные разделы, которые не повлияют на понимание дальнейшего материала.
1. Вероятностная модель классификации
1.1. Модель классификации и функция потерь
1.2. Функция softmax в классификации
1.3. Температура softmax и операция hardmax*
1.4. Функция sigmoid в классификации
2. Кроссэнтропия в вероятностных моделях
2.1. Разметка с неуверенностью
2.2. Кроссэнтропия и расхождение Кульбака-Лейблера
2.3. Кроссэнтропия как максимизация правдоподобия*
2.4. Кроссэнтропия в задаче регрессии*
2.5. Кроссэнтропия с точки зрения оптимизации*
1. Вероятностная модель классификации
1.1. Модель классификации и функция потерь
Чтобы задать вероятностную модель, нам нужно определить, в какой форме она будет предсказывать распределение  . Если задаче регрессии мы ограничивали распределения
. Если задаче регрессии мы ограничивали распределения  только нормальными распределениями, то в задаче классификации это будет не оптимальным решением, так как классы по сути представляют собой неупорядоченное множество (хотя на них есть порядок, но лишь технически, и он может быть выбран произвольно). В задаче классификации мы можем предсказывать вероятность для каждого класса, и тогда модель будет выдавать столько чисел, сколько есть классов в
только нормальными распределениями, то в задаче классификации это будет не оптимальным решением, так как классы по сути представляют собой неупорядоченное множество (хотя на них есть порядок, но лишь технически, и он может быть выбран произвольно). В задаче классификации мы можем предсказывать вероятность для каждого класса, и тогда модель будет выдавать столько чисел, сколько есть классов в  .
.
Пусть мы имеем датасет  и предполагаем, что все примеры независимы и взяты и одного и того же распределения (i.i.d., см. предыдущую часть, раздел 3.4). Для обучения модели снова применим метод максимизации правдоподобия, то есть будем искать такие параметры
и предполагаем, что все примеры независимы и взяты и одного и того же распределения (i.i.d., см. предыдущую часть, раздел 3.4). Для обучения модели снова применим метод максимизации правдоподобия, то есть будем искать такие параметры  , которые максимизируют
, которые максимизируют  . В разделе 2.3 мы уже расписывали эту формулу, которая получается в результате, но ввиду ее важности повторим ее еще раз. Первое равенство ниже следует из i.i.d.-гипотезы, второе по правилам математики:
. В разделе 2.3 мы уже расписывали эту формулу, которая получается в результате, но ввиду ее важности повторим ее еще раз. Первое равенство ниже следует из i.i.d.-гипотезы, второе по правилам математики:

Таким образом, для максимизации вероятности выборки данных нам нужно минимизировать сумму величин

для всех обучающих примеров  .
.
В модели регрессии эта величина была сведена к квадрату разности предсказания и верного ответа (часть 1, формула 7). Но в задаче классификации на данном этапе считать больше ничего не нужно. Нашей задачей было задать вероятностную модель, определить с ее помощью функцию потерь и таким образом свести обучение к задаче оптимизации, то есть минимизации функции потерь, и мы это уже сделали. Функция потерь (2) называется кроссэнтропией (также перекрестной энтропией, или logloss). Она равна минус логарифму предсказанной вероятности для верного класса  .
.
Категориальная кроссэнтропия
Возьмем произвольный пример и выданные моделью вероятности обозначим за ![p_{pred}[1], \dots, p_{pred}[K]](https://habrastorage.org/getpro/habr/upload_files/e63/c9f/df9/e63c9fdf964b5305282a8f0ea1c9311f.svg) , где
, где  — количество классов. К метке класса (эталонному ответу) применим one-hot кодирование, получив вектор
— количество классов. К метке класса (эталонному ответу) применим one-hot кодирование, получив вектор ![p_{true}[1], \dots, p_{true}[K]](https://habrastorage.org/getpro/habr/upload_files/17e/f32/435/17ef32435ab4071cdd673e3c77cf185f.svg) , в котором лишь один элемент равен единице, а остальные равны нулю. Тогда выражение (2) можно рассчитать таким образом:
, в котором лишь один элемент равен единице, а остальные равны нулю. Тогда выражение (2) можно рассчитать таким образом:
![\text{CrossEntropy}(p_{true}, p_{pred}) = \sum\limits_{i=1}^K p_{true}[i] * \ln (p_{pred}[i]) \tag{3}](https://habrastorage.org/getpro/habr/upload_files/6c9/73c/a0c/6c973ca0cec545b37d32b35e6e71b8ac.svg)
Лишь один элемент суммы будет не равен нулю — тот, который соответствует верному классу. Для него первый множитель будет равен единице, а второй будет логарифмом предсказанной вероятности для верного класса, что соответствует выражению (2).
Примечание. На самом деле формула (3) является определением кроссэнтропии, а формула (2) ее частным случаем, когда  вырождено и назначает вероятность 1 классу с индексом
вырождено и назначает вероятность 1 классу с индексом  . О случае, когда это не так, подробнее поговорим во втором разделе.
. О случае, когда это не так, подробнее поговорим во втором разделе.
Бинарная кроссэнтропия
Если класса всего два, то как правило делают следующим образом: модель выдает лишь одно число  от 0 до 1, оно рассматривается как вероятность второго класса, а
от 0 до 1, оно рассматривается как вероятность второго класса, а  рассматривается как вероятность первого класса. Пусть
рассматривается как вероятность первого класса. Пусть  равно единице, если первый класс верен, иначе равно нулю. Тогда выражение (3) технически можно вычислить следующим образом:
равно единице, если первый класс верен, иначе равно нулю. Тогда выражение (3) технически можно вычислить следующим образом:

Снова лишь одно слагаемое будет ненулевым, и таким образом мы посчитаем логарифм предсказанной вероятности для верного класса. Формулы (18) и (19) называются категориальной кроссэнтропией (они эквивалентны если  для одного из классов), формула (18) называется бинарной кроссэнтропией.
для одного из классов), формула (18) называется бинарной кроссэнтропией.
В этом разделе мы рассмотрели обучение модели классификации. Часто в классификации упоминают о функции softmax, но почему-то мы о ней ничего не говорили. Складывается ощущение, что мы что-то упустили. В следующем разделе мы поговорим о роли функции softmax в классификации.
1.2. Функция softmax в классификации
В предыдущем разделе мы определили, что модель классификации должна выдавать вероятности для всех классов. Но модель — это не только формат входных и выходных данных, а еще и внутренняя архитектура. Она может быть совершенно разной: для классификации применяются либо нейронные сети, либо решающие деревья, либо машины опорных векторов и так далее.
Рассмотрим для примера нейронную сеть. Пусть мы имеем  классов, и выходной слой нейронной сети выдает
классов, и выходной слой нейронной сети выдает  чисел от
чисел от  до
до  . Чтобы вектор из
. Чтобы вектор из  чисел являлся распределением вероятностей, он должен удовлетворять двум ограничениям:
чисел являлся распределением вероятностей, он должен удовлетворять двум ограничениям:
Вероятность каждого класса не может быть ниже нуля
Сумма вероятностей должна быть равна единице
Для удовлетворения первого ограничения лучше чтобы модель выдавала не вероятности, а их логарифмы: если логарифм некой величины меняется от  до
до  , то сама величина меняется от
, то сама величина меняется от  до
до  . Чтобы удовлетворялось второе ограничение, каждую предсказанную вероятность мы можем делить на сумму всех предсказанных вероятностей. Такая операция называется
. Чтобы удовлетворялось второе ограничение, каждую предсказанную вероятность мы можем делить на сумму всех предсказанных вероятностей. Такая операция называется  -нормализацией вектора вероятностей.
-нормализацией вектора вероятностей.
Отсюда мы можем вывести формулу для операции softmax. Эта операция принимает на вход набор из  чисел от
чисел от  до
до  (они называются логитами, англ. logits)
(они называются логитами, англ. logits)  и возвращает распределение вероятностей из
и возвращает распределение вероятностей из  чисел
чисел  . Softmax является последовательностью двух операций: взятия экспоненты и
. Softmax является последовательностью двух операций: взятия экспоненты и  -нормализации:
-нормализации:

Таким образом, softmax — это векторная операция, принимающая вектор из произвольных чисел (логитов) и возвращающая вектор вероятностей, удовлетворяющий свойствам 1 и 2. Она применяется как завершающая операция во многих моделях классификации — таким образом мы можем быть уверены, что выданные моделью числа будут именно распределением вероятностей (т. е. удовлетворять свойствам 1 и 2). Существуют и различные альтернативы функции softmax, например sparsemax (Martins and Astudillo, 2016).
Модель, предсказывающая  логитов, к которым применяется операция softmax, будет обладать только одним ограничением: она не может предсказывать строго нулевые или строго единичные вероятности. Зато такую модель можно обучать градиентным спуском, так как функция softmax дифференцируема.
логитов, к которым применяется операция softmax, будет обладать только одним ограничением: она не может предсказывать строго нулевые или строго единичные вероятности. Зато такую модель можно обучать градиентным спуском, так как функция softmax дифференцируема.
Технически иногда функция softmax рассматривается как часть модели, иногда как часть функции потерь. Например, в библиотеке Keras мы можем добавить функцию активации 'softmax' в последний слой сети и использовать функцию потерь CategoricalCrossentropy(), а можем наоборот не добавлять функцию активации в последний слой и использовать функцию потерь CategoricalCrossentropy (from_logits=True), которая включает в себя расчет softmax (и ее производной при обратном проходе). С математической точки зрения разницы между этими двумя способами не будет, но погрешность расчета функции потерь и производной во втором случае будет меньше. В PyTorch мы можем применить LogSoftmax вместе с NLLLoss (negative log-likelihood), а можем вместо этого применить torch.nn.functional.cross_entropy, который включает в себя расчет LogSoftmax.
1.3. Температура softmax и операция hardmax*
У функции softmax (5) есть важное свойство: если ко всем логитам  прибавить одну и ту же константу
прибавить одну и ту же константу  , то вероятности
, то вероятности  никак не изменятся, так как после применения экспоненты константа из слагаемого превратится в множитель, и множители в числителе и знаменателе сократятся. Однако если все логиты
никак не изменятся, так как после применения экспоненты константа из слагаемого превратится в множитель, и множители в числителе и знаменателе сократятся. Однако если все логиты  умножить на некую константу
умножить на некую константу  , то тогда вероятности
, то тогда вероятности  изменятся: если
изменятся: если  , то вероятности
, то вероятности  станут ближе друг к другу, что означает меньшую уверенность в предсказании, если же
станут ближе друг к другу, что означает меньшую уверенность в предсказании, если же  тот класс, логит которого был наибольшим, получит вероятность 1, остальные классы — вероятность 0, такую операцию по аналогии часто называют hardmax. Иногда ее упоминают как argmax, потому что hardmax можно считать one-hot кодированием индекса, который возвращает операция argmax.
тот класс, логит которого был наибольшим, получит вероятность 1, остальные классы — вероятность 0, такую операцию по аналогии часто называют hardmax. Иногда ее упоминают как argmax, потому что hardmax можно считать one-hot кодированием индекса, который возвращает операция argmax.
На этом примере видно то, как употребляются понятия soft и hard в машинном обучении: hard-операции (hardmax, argmax, hard attention, hard labeling, sign) связаны с выбором некоего элемента в множестве, а soft-операции (softmax, soft attention, soft labeling, soft sign) являются их дифференцируемыми аналогами. Например, в softmax можно рассчитать производную каждого выходного элемента по каждому входному. В hardmax или argmax это не имеет смысла: производные всегда будут равны нулю.
Это можно понять даже не прибегая к расчетам, поскольку у дифференцируемости есть очень простая наглядная интерпретация: операция  дифференцируема если плавное изменение
дифференцируема если плавное изменение  приводит к плавному изменению
приводит к плавному изменению  . Это верно для операции softmax, и благодаря этому мы можем применять градиентный спуск или градиентный бустинг. Но в операции hardmax плавное изменение логитов приводит к тому, что выходные вероятности либо остаются такими же, либо меняются скачкообразно, поэтому (без дополнительных ухищрений) градиентный спуск и градиентный бустинг оказываются неприменимы.
. Это верно для операции softmax, и благодаря этому мы можем применять градиентный спуск или градиентный бустинг. Но в операции hardmax плавное изменение логитов приводит к тому, что выходные вероятности либо остаются такими же, либо меняются скачкообразно, поэтому (без дополнительных ухищрений) градиентный спуск и градиентный бустинг оказываются неприменимы.
1.4. Функция sigmoid в классификации
Рассмотрим случай бинарной классификации. Представим, что у нас есть 2 класса, и модель выдает 2 логита  , из которых с помощью softmax получаем вероятности
, из которых с помощью softmax получаем вероятности  , сумма которых равна единице. Но прибавление одной и той же константы к
, сумма которых равна единице. Но прибавление одной и той же константы к  не меняет вероятности, поэтому иметь две «степени свободы» излишне, и имеет смысл зафиксировать
не меняет вероятности, поэтому иметь две «степени свободы» излишне, и имеет смысл зафиксировать  в значении 0. Теперь меняя
в значении 0. Теперь меняя  модель будет менять вероятности классов
модель будет менять вероятности классов  . Значения
. Значения  и
и  , согласно (21), будут связаны следующим образом:
, согласно (21), будут связаны следующим образом:

Такая функция носит название сигмоиды:

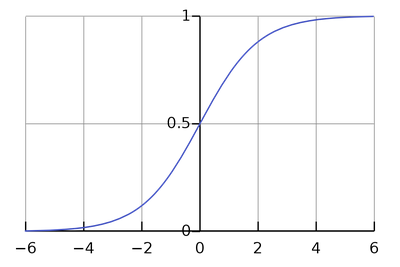
Примечание. В более широком смысле, сигмоидами называют и другие функции одной переменной, график которых выглядит похожим образом. Для преобразования логита в вероятность вместо  можно использовать любую и этих функций, разница между ними не принципиальна. Также сигмоида иногда используется в промежуточных слоях нейронных сетей.
можно использовать любую и этих функций, разница между ними не принципиальна. Также сигмоида иногда используется в промежуточных слоях нейронных сетей.
К чему мы в итоге пришли? К тому, что если класса всего два, то иметь два логита в модели не обязательно, достаточно всего одного, к которому применяется сигмоида вместо softmax. Функция потерь при этом становится бинарной кроссэнтропией (4). На самом деле то же рассуждение можно применить и к мультиклассовой классификации: если классов  , то достаточно иметь
, то достаточно иметь  логитов, но так обычно не делают.
логитов, но так обычно не делают.
Теперь запишем функцию, обратную сигмоиде. Эта функция преобразует вероятность обратно в логит и называется logit function:

Если  — это вероятность второго класса, а
— это вероятность второго класса, а  — вероятность первого класса, то выражение
— вероятность первого класса, то выражение  означает то, во сколько раз второй класс вероятнее первого. Это выражение называется odds ratio. Логит является его логарифмом и называется log odds ratio.
означает то, во сколько раз второй класс вероятнее первого. Это выражение называется odds ratio. Логит является его логарифмом и называется log odds ratio.
Если мы используем в обучении сигмоиду, то модель непосредственно предсказывает логит  , то есть логарифм того, во сколько раз второй класс вероятнее первого.
, то есть логарифм того, во сколько раз второй класс вероятнее первого.
2. Кроссэнтропия в вероятностных моделях
2.1. Разметка с неуверенностью
В выражениях для функции потерь в классификации (2) и регрессии (часть 1, формула 7) мы предполагали наличие для каждого примера  эталонного ответа
эталонного ответа  , к которому модель должна стремиться. Но в более общем случае эталонный ответ
, к которому модель должна стремиться. Но в более общем случае эталонный ответ  может быть не конкретным значением, а распределением вероятностей на множестве
может быть не конкретным значением, а распределением вероятностей на множестве  , так же как и предсказание модели. То есть в разметке датасета значения
, так же как и предсказание модели. То есть в разметке датасета значения  указаны с определенной степенью неуверенности: если это классификация, то могут быть указаны вероятности для всех классов, если регрессия — то может быть указана погрешность.
указаны с определенной степенью неуверенности: если это классификация, то могут быть указаны вероятности для всех классов, если регрессия — то может быть указана погрешность.
Ситуация, когда разметка датасета содержит некую степень неуверенности, не такая уж редкая. Например, в пусть в задаче классификации эмоций по видеозаписи датасет размечен сразу несколькими людьми-аннотаторами, которые иногда дают разные ответы. Например, одно из видео в датасете может быть размечено как «happiness» 11 аннотаторами и как «sadness» 9 аннотаторами. Оставив только «happiness» мы потеряем часть информации. Вместо этого мы можем оставить обе эмоции, считать их распределением вероятностей:  ,
,  и обучать модель выдавать для данного примера такое же распределение вероятностей.
и обучать модель выдавать для данного примера такое же распределение вероятностей.
Благодаря разметке с неуверенностью сохраняется больше информации: есть явно выраженные эмоции, а есть сложно определяемые.
Но с другой стороны для каждого видео есть какая-то истинная эмоция: либо «happiness», либо «sadness» — человек не может испытывать обе эти эмоции одновременно. В теории модель могла бы обучиться определять эмоции точнее, чем человек, и разметка с неуверенностью может помешать модели выучиться точнее человека: если человек дает 50% вероятности обоим классам, и мы используем это как эталонный ответ, то модель будет стремиться к нему, даже если она способна определить эмоцию точнее.
2.2. Кроссэнтропия и расхождение Кульбака-Лейблера
Пусть мы имеем датасет из пар  , в котором эталонный ответ
, в котором эталонный ответ  является не конкретным значением признака
является не конкретным значением признака  , а распределением вероятностей на множестве
, а распределением вероятностей на множестве  . Нам каким-то образом нужно «подогнать» предсказанное распределение
. Нам каким-то образом нужно «подогнать» предсказанное распределение  под эталонное распределение
под эталонное распределение  .
.
Пример 1. Если в задаче классификации в эталонном распределении вероятности классов равны 0.7 и 0.3, то мы хотели бы, чтобы в предсказании  они тоже были бы равны 0.7 и 0.3.
они тоже были бы равны 0.7 и 0.3.
Пример 2. Если в задаче регрессии эталонное распределение имеет две моды в значениях 0.5 и 1.5, то нам хотелось бы, чтобы предсказанное распределение вероятностей  тоже имело моды в этих точках. Но если мы моделируем
тоже имело моды в этих точках. Но если мы моделируем  нормальным распределением (как в разделе 2.3 первой части), тогда в нем в любом случае будет только одна мода, и чтобы хоть как-то приблизить предсказание к эталонному ответу, можно расположить моду посередине между точками 0.5 и 1.5 — тогда мат. ожидание ошибки предсказания будет наименьшим.
нормальным распределением (как в разделе 2.3 первой части), тогда в нем в любом случае будет только одна мода, и чтобы хоть как-то приблизить предсказание к эталонному ответу, можно расположить моду посередине между точками 0.5 и 1.5 — тогда мат. ожидание ошибки предсказания будет наименьшим.
Как видим, второй пример получился сложнее первого. Если множество  непрерывно, то задача приближения предсказанного распределения к эталонному означает задачу сближения функций плотности вероятности.
непрерывно, то задача приближения предсказанного распределения к эталонному означает задачу сближения функций плотности вероятности.
Такая постановка задачи неоднозначна: сблизить функции можно по-разному, так как «расстояние» между функциями можно определять по-разному. Чаще всего для этого используют расхождение Кульбака-Лейблера (относительную энтропию)  — несимметричную метрику сходства между двумя распределениями вероятностей
— несимметричную метрику сходства между двумя распределениями вероятностей  и
и  . Расхождение Кульбака-Лейблера можно расписать как сумму в дискретном случае и как интеграл в непрерывном случае.
. Расхождение Кульбака-Лейблера можно расписать как сумму в дискретном случае и как интеграл в непрерывном случае.
Дискретный случай ( ,
,  — функции вероятности):
— функции вероятности):

Непрерывный случай ( ,
,  — функции плотности вероятности):
— функции плотности вероятности):

Пользуясь тем, что  , мы можем расписать расхождение Кульбака-Лейблера как разность двух величин. Для дискретного случая:
, мы можем расписать расхождение Кульбака-Лейблера как разность двух величин. Для дискретного случая:

Первое слагаемое со знаком минус называется энтропией распределения  (или дифференциальной энтропией в непрерывном случае) и обозначается как
(или дифференциальной энтропией в непрерывном случае) и обозначается как  , а второе слагаемое (включая минус) называется кроссэнтропией
, а второе слагаемое (включая минус) называется кроссэнтропией  между распределениями
между распределениями  и
и  . Эти величины можно расписать через мат. ожидание:
. Эти величины можно расписать через мат. ожидание:



В машинном обучении первым аргументом в  обычно ставят эталонное распределение, вторым аргументом — предсказанное. Как видно из формулы (9), первое слагаемое не зависит от
обычно ставят эталонное распределение, вторым аргументом — предсказанное. Как видно из формулы (9), первое слагаемое не зависит от  , поэтому минимизация
, поэтому минимизация  по
по  равносильно минимизации кроссэнтропии между
равносильно минимизации кроссэнтропии между  и
и  .
.
Резюме. Если значения целевого признака в датасете даны как распределения вероятностей, то для обучения модели мы можем минимизировать кроссэнтропию между предсказанными и эталонными распределениями. Мы так уже делали в модели классификации, но там эталонное распределение было вырожденным назначало вероятность 1 одному из классов, поэтому в формуле (3) лишь одно слагаемое было ненулевым. В этом разделе мы рассмотрели более общий случай, когда эталонное распределение невырождено и в (3) может быть много ненулевых слагаемых.
2.3. Кроссэнтропия как максимизация правдоподобия*
Является ли «подгонка» предсказанного распределения  под эталонное распределение
под эталонное распределение  применением метода максимизации правдоподобия? Для ответа на этот вопрос нужно понять что такое «правдоподобие» в том случае, когда вместо эталонного ответа мы имеем распределение.
применением метода максимизации правдоподобия? Для ответа на этот вопрос нужно понять что такое «правдоподобие» в том случае, когда вместо эталонного ответа мы имеем распределение.
Мы можем сделать таким образом. Пусть для  -го примера мы имеем значение
-го примера мы имеем значение  и распределение
и распределение  . Мысленно сгенерируем из этого примера очень большое (стремящееся к бесконечности) количество примеров (обозначим его
. Мысленно сгенерируем из этого примера очень большое (стремящееся к бесконечности) количество примеров (обозначим его  ), в которых исходные признаки равны
), в которых исходные признаки равны  , а целевой признак взят из распределения
, а целевой признак взят из распределения  :
:

Объединение  нельзя рассматривать как i.i.d.-выборку, потому что при бесконечном количестве примеров мы имеем лишь
нельзя рассматривать как i.i.d.-выборку, потому что при бесконечном количестве примеров мы имеем лишь  уникальных значений
уникальных значений  . Но поскольку мы не моделируем распределение
. Но поскольку мы не моделируем распределение  , это не является проблемой. Поскольку все
, это не является проблемой. Поскольку все  независимы:
независимы:


В итоге при  минус логарифм правдоподобия
минус логарифм правдоподобия  оказался равен кроссэнтропии между эталонным распределением
оказался равен кроссэнтропии между эталонным распределением  и предсказанным моделью распределением
и предсказанным моделью распределением  . Отсюда получается, что минимизация кроссэнтропии (или, что эквивалентно, минимизация расхождения Кульбака-Лейблера) максимизирует правдоподобие.
. Отсюда получается, что минимизация кроссэнтропии (или, что эквивалентно, минимизация расхождения Кульбака-Лейблера) максимизирует правдоподобие.
2.4. Кроссэнтропия в задаче регрессии*
Вернемся к случаю регрессии. Если для обучающей пары  точно известен ответ
точно известен ответ  , то его можно представить как распределение вероятностей на
, то его можно представить как распределение вероятностей на  , имеющее лишь одно возможное значение
, имеющее лишь одно возможное значение  с вероятностью 1 (такое распределение называют вырожденным, в данном случае его еще называют «эмпирическим»).
с вероятностью 1 (такое распределение называют вырожденным, в данном случае его еще называют «эмпирическим»).
Для таких случаев математики придумали специальную функцию, называемую дельта-функцией Дирака  . Она равна нулю во всех точках кроме нуля, в нуле равна бесконечности, а ее интеграл равен единице. Например, если мы возьмем функцию плотности вероятности нормального распределения (часть 1, формула 4) с
. Она равна нулю во всех точках кроме нуля, в нуле равна бесконечности, а ее интеграл равен единице. Например, если мы возьмем функцию плотности вероятности нормального распределения (часть 1, формула 4) с  и устремим
и устремим  к нулю, то в пределе получим дельта-функцию.
к нулю, то в пределе получим дельта-функцию.
В случае регрессии эмпирическое распределение можно записать как  . Попробуем, по аналогии с классификацией, минимизировать кроссэнтропию между эталонным и предсказанным распределениями. Пусть модель выдает для
. Попробуем, по аналогии с классификацией, минимизировать кроссэнтропию между эталонным и предсказанным распределениями. Пусть модель выдает для  нормальное распределение
нормальное распределение  . Распишем кроссэнтропию между эмпирическим и предсказанным распределением:
. Распишем кроссэнтропию между эмпирическим и предсказанным распределением:

Обратите внимание, что оба аргумента  являются не числами, а функциями от
являются не числами, а функциями от  , и подынтегральное выражение не равно нулю только в одной точке
, и подынтегральное выражение не равно нулю только в одной точке  . С помощью формулы (10) мы пришли к тому, что минимизация кроссэнтропии означает минимизацию
. С помощью формулы (10) мы пришли к тому, что минимизация кроссэнтропии означает минимизацию  , что эквивалентно максимизации
, что эквивалентно максимизации  . Именно это мы и делали в разделе 2. Получается, что модель регрессии тоже обучается с помощью кроссэнтропии, которая по формуле (10) превращается в минимизацию
. Именно это мы и делали в разделе 2. Получается, что модель регрессии тоже обучается с помощью кроссэнтропии, которая по формуле (10) превращается в минимизацию  и далее в минимизацию среднеквадратичного отклонения (часть1, формула 7), если
и далее в минимизацию среднеквадратичного отклонения (часть1, формула 7), если  моделируется нормальным распределением.
моделируется нормальным распределением.
Как видим, мы получаем максимально унифицированный и при этом гибкий подход, который можно применять для задания функции потерь в сложных случаях.
Кроссэнтропия с точки зрения оптимизации*
В задаче регрессии мы рассматривали два подхода к выбору функции потерь: первый подход опирается на здравый смысл, наши представления о метрике сходства на множестве  и легкость оптимизации. Второй подход опирается на теорию вероятностей и наши представления об условном распределении
и легкость оптимизации. Второй подход опирается на теорию вероятностей и наши представления об условном распределении  , из которого следует формула для функции потерь (статья 1, формулы 5–7).
, из которого следует формула для функции потерь (статья 1, формулы 5–7).
Теперь вернемся к задаче классификации. Есть ли здесь аналогичные два подхода? Вероятностный подход, который приводит к кроссэнтропии, мы уже рассматривали. Но хороша ли кроссэнтропия с точки зрения оптимизации, или есть более удобная функция потерь? Например, вместо кроссэнтропии мы могли бы минимизировать среднеквадратичную ошибку между предсказанным распределением вероятностей ![p_{pred}[1], \dots, p_{pred}[K]](https://habrastorage.org/getpro/habr/upload_files/1a7/3cf/cc7/1a73cfcc7fe04507b5903bfc37641dbd.svg) и эталонным распределением вероятностей
и эталонным распределением вероятностей ![p_{true}[1], \dots, p_{true}[K]](https://habrastorage.org/getpro/habr/upload_files/012/308/3ff/0123083ffccb94662905c18f94ffc342.svg) , в котором вероятность 1 назначается верному классу:
, в котором вероятность 1 назначается верному классу:
![loss(p_{true}, p_{pred}) = \sum\limits_{i=1}^K (p_{true}[i] - p_{pred}[i])^2](https://habrastorage.org/getpro/habr/upload_files/bcf/6ab/506/bcf6ab5064b964dd0a237a2053666109.svg)
Смысл такого выражения с точки зрения теории вероятностей не совсем ясен, но видно, что чем ближе предсказание к истине, тем меньше будет функция потерь. А это и есть то свойство, которое требуется от функции потерь.
Что же лучше: кроссэнтропия или среднеквадратичная ошибка? Чтобы понять, какая из функций потерь лучше подходит для оптимизации градиентным спуском, давайте рассчитаем градиенты этих функций потерь по логитам (то есть тем значениям, которые выдаются до операции softmax или sigmoid). Пусть классификация является бинарной, верный ответом является второй класс, и модель выдала значение логита, равное  . Отсюда вероятность второго класса равна
. Отсюда вероятность второго класса равна  , где
, где  — операция сигмоиды (6). Рассчитаем производную функции потерь по логиту
— операция сигмоиды (6). Рассчитаем производную функции потерь по логиту  .
.
В случае бинарной кроссэнтропии:

В случае среднеквадратичной ошибки:

При © Habrahabr.ru
