Справочная: “Архив Интернета” — история создания, миссия и дочерние проекты

Вероятно, на Хабре не так много пользователей, кто никогда не слышал об «Архиве Интернета» (Internet Archive), сервисе, который занимается поиском и сохранением важных для всего человечества цифровых данных, будь то интернет-странички, книги, видео или информация иного типа.
Кто управляет Интернет-архивом, когда он появился и какова его миссия? Об этом читайте в сегодняшней «Справочной».
Зачем вообще нужен «Архив»?
Это далеко не только развлечение. Миссия организации — всеобщий доступ ко всей информации. «Интернет-архив» стремится бороться с монополией на предоставление информации со стороны как телекоммуникационных компаний (Google, Facebook и т.п.), так и государств.
При этом «Архив» является законопослушной организацией. Если по закону США какую-то информацию необходимо удалить, организация это делает.
«Архив Интернета» также служит инструментом работы ученых, спецслужб, историков (например, археографов) и представителей многих других сфер, не говоря уже об отдельных пользователях.
Когда появился «Интернет-архив»?
Создатель «Архива» — американец Брюстер Кейл, который создал компанию Alexa Internet. Оба его сервиса стали чрезвычайно популярными, оба они процветают и сейчас.
«Интернет-архив» начал архивировать информацию с сайтов и хранить копии веб-страниц, начиная с 1996 года. Штаб-квартира этой некоммерческой организации располагается в Сан-Франциско, США.
Правда, в течение пяти лет данные были недоступны для общего доступа — данные хранились на серверах «Архива», и это все, просмотреть старые копии сайтов могла лишь администрация сервиса. С 2001 года администрация сервиса решила предоставить доступ к сохраненным данным всем желающим.
В самом начале «Интернет-архив» был лишь веб-архивом, но затем организация начала сохранять книги, аудио, движущиеся изображения, ПО. Сейчас «Интернет-архив» выступает хранилищем для фотографий и других изображений НАСА, текстов Open Library и т.п.
На что существует организация?
«Архив» существует на добровольные пожертвования — как организаций, так и частных лиц. Можно предоставить поддержку и в биткоинах, кошелек 1Archive1n2C579dMsAu3iC6tWzuQJz8dN. Этот кошелек, кстати, за все время существования получил 357.47245492 BTC, это примерно $2,25 миллиона по текущему курсу.
Как работает «Архив»?
Большинство сотрудников заняты в центрах по сканированию книг, выполняя рутинную, но достаточно трудоемкая работа. У организации три дата-центра, расположенных в Калифорнии, США. Один — в Сан-Франциско, второй — Редвуд Сити, третий — Ричмонде. Для того, чтобы избежать опасности потери данных в случае природной катастрофы или других катаклизмов, у «Архива» есть запасные мощности в Египте и Амстердаме.
«Миллионы людей потратили массу времени и усилий, чтобы разделить с другими то, что мы знаем в виде интернета. Мы хотим создать библиотеку для этой новой платформы для публикаций», — заявил основатель Архива интернета Брюстер Кале (Brewster Kahle)
Насколько велик сейчас «Архив»?
У «Интернет-архива» есть несколько подразделений, и у того, которое занимается сбором информации с сайтов, есть собственное название — Wayback Machine. На момент написания «Справочной» в архиве хранилось 339 миллиардов сохраненных веб-страниц. В 2017 году в «Архиве» хранилось 30 петабайт информации, это примерно 300 млрд веб-страниц, 12 млрд книг, 4 млн аудиозаписей, 3,3 млн видеороликов, 1,5 млн фотографий и 170 тыс. различных дистрибутивов ПО. Всего за год сервис заметно «прибавил в весе», теперь «Архив» хранит 339 млрд веб-страниц, 19 млн книг, 4,5 млн видеофайлов, 4,7 млн аудиофайлов, 3,2 млн изображений разного рода, 381 тыс. дистрибутивов ПО.
Как организовано хранение данных?
Информация хранится на жестких дисках в так называемых «дата-нодах». Это серверы, каждый из которых содержит 36 жестких дисков (плюс два диска с операционными системами). Дата-ноды группируются в массивы по 10 машин и представляют собой кластерное хранилище. В 2016 году «Архив» использовал 8-терабайтными HDD, сейчас ситуация примерно такая же. Получается, что одна нода вмещает около 288 терабайт данных. В целом, еще используются жесткие диски и других размеров: 2, 3 и 4 ТБ.
В 2016 году жестких дисков было около 20 000. Дата-центры «Архива» оснащены климатическими установками для поддержания микроклимата с постоянными характеристиками. Одно кластерное хранилище из 10 нод потребляет около 5 кВт энергии.
Структура Internet Archive представляет собой виртуальную «библиотеку», которая поделена на такие секции, как книги, фильмы, музыка и т.п. Для каждого элемента есть описание, внесенное в каталог — обычно это название, имя автора и дополнительная информация. С технической точки зрения элементы структурированы и находятся в Linux-директориях.
Общий объем данных, хранимых «Архивом» составляет 22 ПБ, при этом сейчас есть место еще для 22 ПБ. «Потому, что мы параноики», — говорят представители сервиса.

Посмотрите на скриншот содержимого директории — там есть файл с названием, оканчивающимся на »_files.xml». Это каталог с информацией обо всех файлах директории.
Что будет с данными, если выйдет из строя один или несколько серверов?
Ничего страшного не произойдет — данные дублируются. Как только в библиотеке «Архива» появляется новый элемент, он тут же реплицируется и размещается на различных жестких дисках на разных серверах. Процесс «зеркалирования» контента помогает справиться с проблемами вроде отключения электричества и сбоях в файловой системе.
Если выходит из строя жесткий диск, его заменяют на новый. Благодаря зеркалируемой и редуплицируемой структуре данных новичок сразу же заполняется данными, которые находились на старом HDD, вышедшем из строя.
У «Архива» есть специализированная система, которая отслеживает состояние HDD. В день приходится заменять 6–7 вышедших из строя накопителей.
Что такое Wayback Machine?
Это лишь один из сервисов «Интернет-архива», который специализируется на сохранении веб-страниц. У сервиса есть собственный «паук», который регулярно обследует все доступные в сети сайты и сохраняет их на специализированных серверах. Чем популярнее веб-сайт, тем чаще робот копирует его содержимое. Если администратор ресурса не желает, чтобы информация сайта копировалась ботом, достаточно прописать запрет в файле robots.txt.
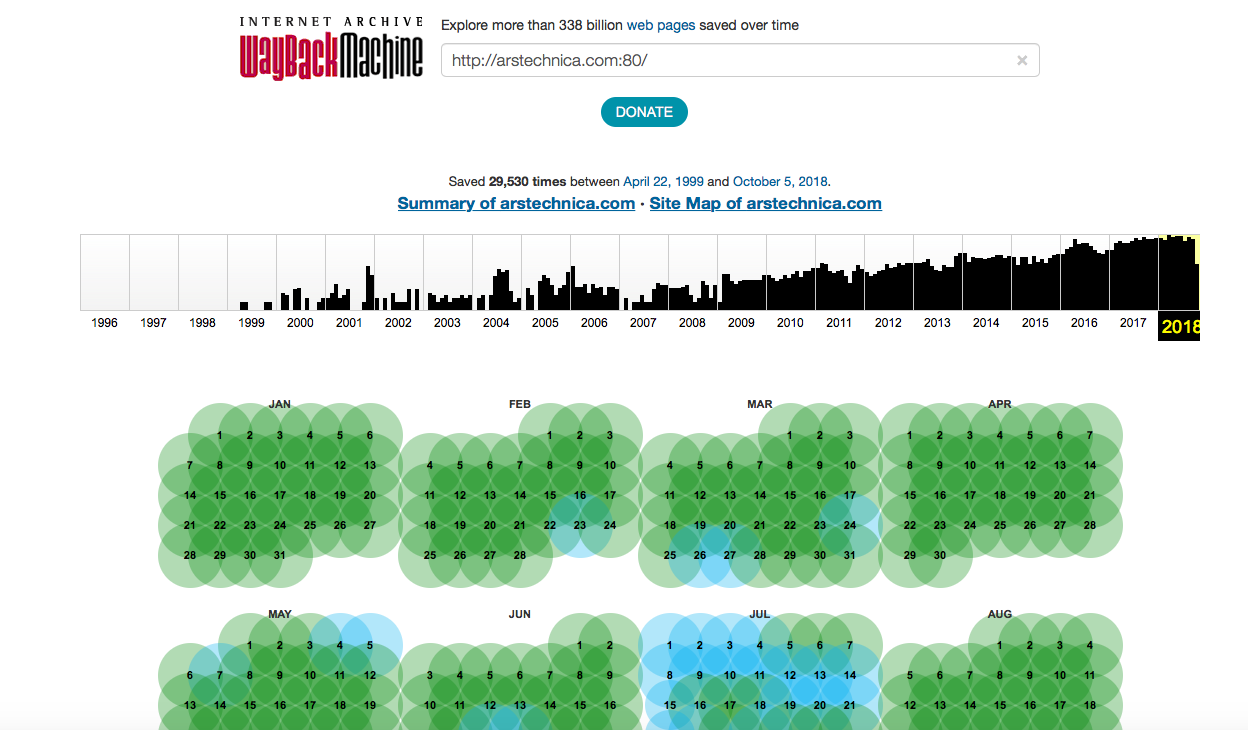
Популярные ресурсы копируются часто — практически ежедневно. Wayback Machine индексирует даже социальные сети, включая Twitter, Facebook
В 2017 году «Архив» запустил обновленный сервис Wayback Machine, пообещав более удобный доступ к сохраненным веб-страницам. Сервис был написан если не с нуля, то здорово переработан. Теперь он поддерживает ряд форматов файлов, которые ранее просто не сохранялись В том же 2017 году организация заявила, что каждую неделю ее сервера сохраняют около 1 млрд веб-страниц.
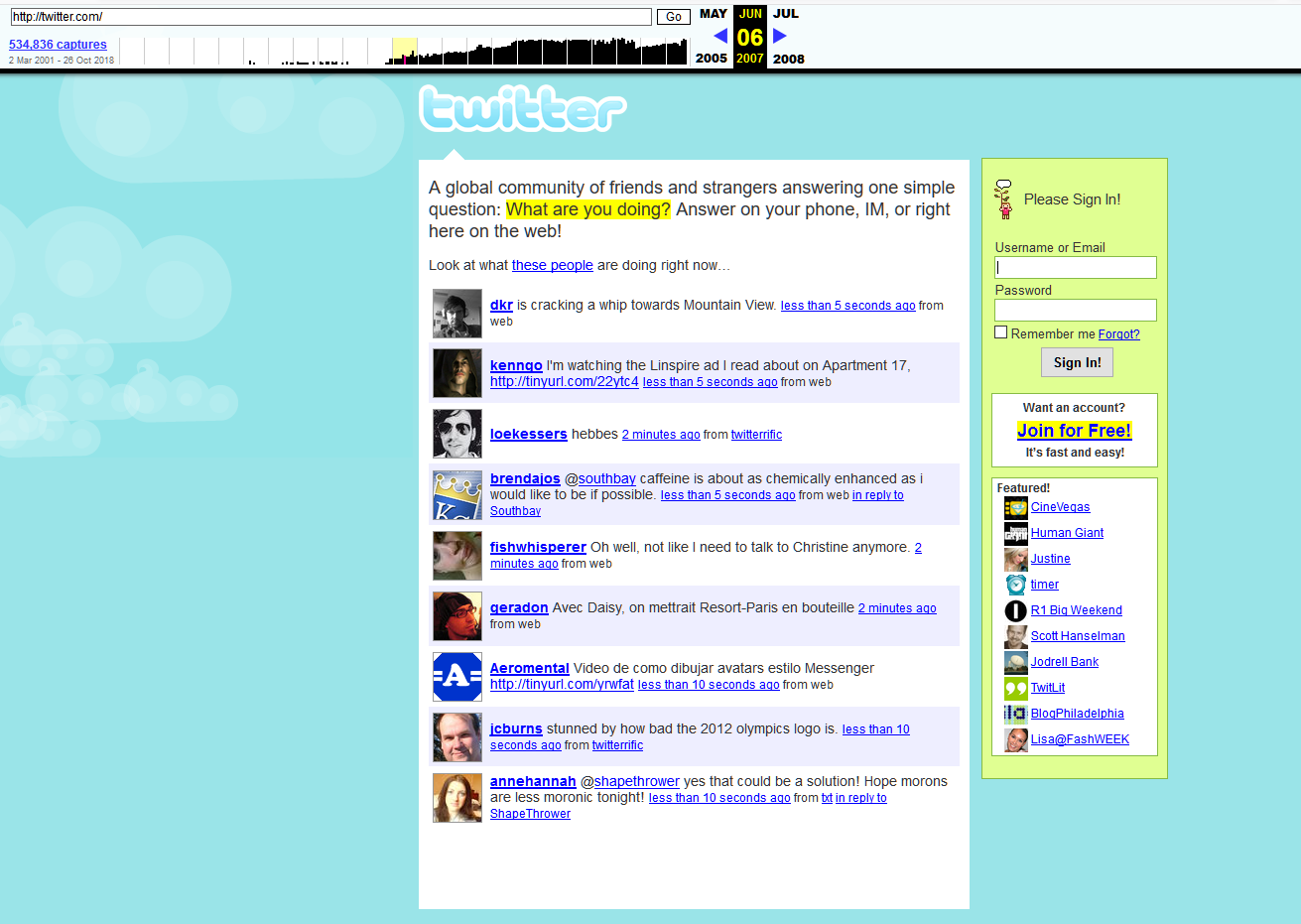
Так выглядел Twitter в 2007 году
Что еще можно найти в базе «Интернет-архива»?
Книги. Коллекция организации огромна, она включает оцифрованные книги, как распространенные, так и очень редкие издания. Книги сохраняются не только англоязычные, но и на многих других языках. У «Архива» есть специализированные центры по сканированию книг, всего таких центров 33, расположены они в пяти странах по всему миру.
В день сотрудники центров сканируют около 1000 книг. В базе сервиса содержатся миллионы изданий, работа по их оцифровке финансируется как обычными людьми, так и различными организациями, включая библиотеки и фонды.
С 2007 года «Интернет-архив» сохраняет в своей базе общедоступные книги из Google Book Search. После запуска, база книг быстро разрослась — в 2013 году насчитывалось уже более 900 тысяч книг, сохраненных из сервиса Google.
Один из сервисов «Архива» также предоставляет доступ к книгам, которые полностью открыты, таковых насчитывается уже более миллиона. Называется этот сервис Open Library.
Видео. Сервис хранит 4,5 млн роликов. Они разбиты по тематикам и имеют самую разную направленность. На серверах «Архива» хранятся фильмы, документальные фильмы, записи спортивных соревнований, ТВ-шоу и многие другие материалы.
В 2015 году «Архив» дал начало масштабному проекту — оцифровке видеокассет. Сначала речь шла о 40 тысячах кассет из архива Мэрион Стоукс, женщины, которая в течение многих десятилетий записывала на кассеты новости. Затем добавились и другие видеокассеты, которые присылали «Архиву» поклонники идеи оцифровки данных, важных для человечества.
Аудио. Аналогично видео, «Архив» хранит и аудиофайлы, которые также разбиты по тематикам. В прошлом году «Архив» начал реализовывать свой новый проект — расшифровку шеллачных пластинок, старейшего формата аудиозаписей. Звук сохранялся на пластинках из шеллака — природной смолы, которую выделяют самками червецов. Всего в архиве Great 78 Project несколько сотен тысяч пластинок.
Программное обеспечение. Конечно, хранить все созданное человечеством ПО просто невозможно, даже для «Архива». На серверах хранится винтаж — например, программы для Macintosh, ПО под DOS и прочий софт. В 2016 году сотрудники «Архива» выложили 1500+ программ под Windows 3.1, работать можно прямо в браузере. В 2017 Internet Archive выпустил архив софта для первых Macintosh.
Игры. Да, «Архив» предоставляет доступ к огромному количеству игр. В некоторые из них можно поиграть в среде браузерного эмулятора. Игры хранятся самые разные, в том числе, и с портативных аналогово-цифровых приставок. Есть игры под MS-DOS и консольные игры для Atari и ColecoVision.

Впервые архив старых игр организация выложила еще в 2013 году. Речь идет о тайтлах 30–40 летней давности, в которые можно было играть прямо в браузере. Это игры для приставок Atari 2600 (1977 года выпуска), Atari 7800 (1986 г.), ColecoVision (1982 г.), Philips Videopac G7000 (1978 г.) и Astrocade (1983 г.). Самое интересное, что Internet Archive добился того, что играть можно вполне легально. Сейчас коллекция насчитывает уже более 3400 игр и продолжает пополняться.
