Скорость с доставкой до пользователя

Анатолий Орлов (anatolix), Денис Нагорнов (Яндекс)
Анатолий Орлов: Всем привет! Меня зовут Анатолий. Я последние 10 лет работал в Яндексе. В Яндексе я занимался разными вещами, но, так получилось, что на HighLoad я всегда доклады делаю про скорость разного вида. У меня есть содокладчик — Денис Нагорнов, он и сейчас работает в Яндексе и занимается, помимо всего прочего, не поверите, тоже скоростью.
Доклад называется «Скорость с доставкой до пользователя». Как вы знаете, огромное количество компаний пытаются оптимизировать загрузку своих страничек. Некоторые компании так гордятся достигнутыми результатами, что они эти результаты пишут на своих страничках, причем даже не внизу, а вверху.
Например, скриншот с сайта Google: 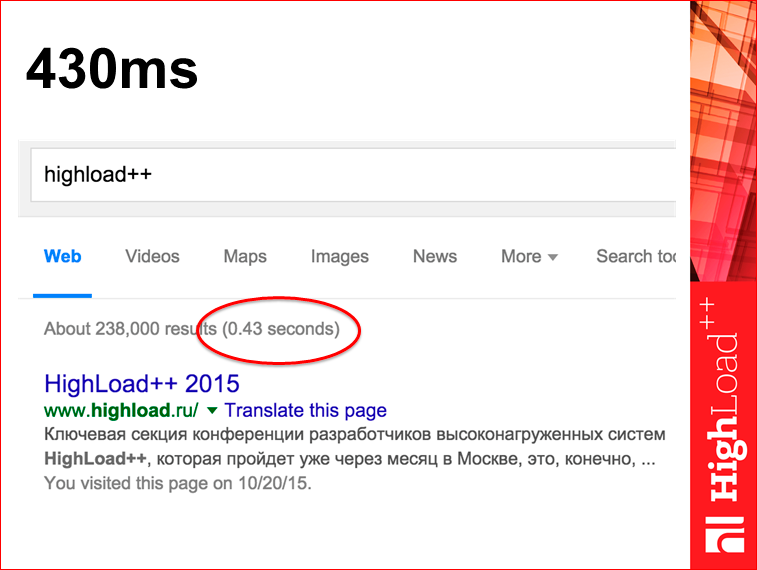
Если вы эту же самую страничку посмотрите в Developer Tools в браузере, вы увидите, что число будет маленечко отличаться, будет не 430 мс, а 625.
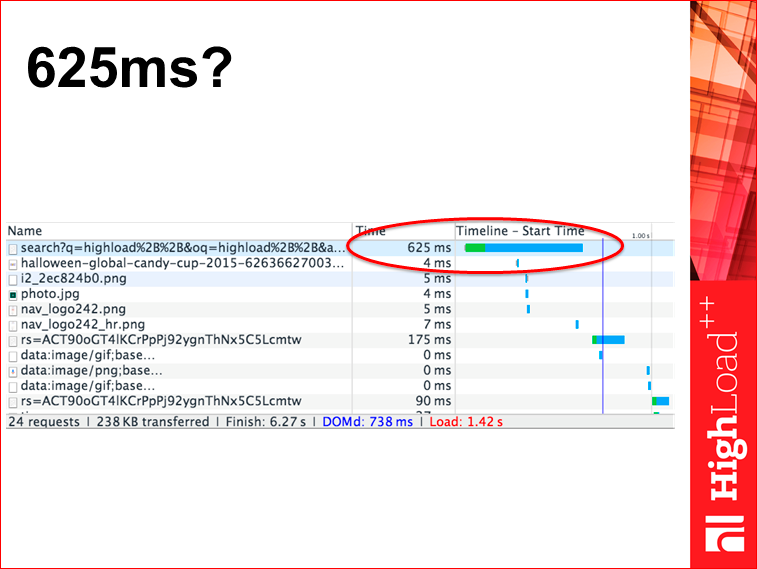
Интуитивно всем более-менее понятно, что 430 — это где-то на сервере Google, а 625 — это тут у вас в браузере. Вопрос: какая циферка больше подходит для того, чтобы являться метрикой скорости? Мне кажется, что циферка, которая у вас в браузере, более полезна, потому что циферкой на сервере можно гордиться, но пользы от нее больше никакой нет. А циферка в браузере реально ускоряет экспириенс пользователя.

Мы хотим сделать некую метрику скорости на клиенте. Здесь сразу возникает вопрос — что измерять и как измерять?
Как измерять — вопрос простой. А что измерять — это не очень тривиально, потому что загрузка страницы — это некий комплексный процесс, про это целые доклады делают. Но, представьте себе, вы загружаете файл с «Войной и миром» с lib.ru и там вы его читать можете практически сразу, а загрузится он через несколько минут, возможно. Это пример, что непонятно какую точку выбрать за время загрузки.
Есть огромное количество сайтов, у которых, например, моментально работает, когда вы переходите со странички на страничку — у вас моментально открывается навигация, потому что она вся кэшированная, но некоторое время занимает загрузка результатов.
Ответа на вопрос, что нужно измерять для всех сайтов во всем мире, не существует. Для вашего определенного сайта такой ответ можно придумать. Для поисковой системы, наверное, загрузка первого результата выдачи — это ровно та отметка, которую стоит измерять.
Есть такая фраза: если у вас из инструментов только молоток, то все ваши проблемы выглядят как гвозди. В этой области молотков вот столько:

Т.е. есть два API более-менее стандартных и два свойства, из которых одно резонно в Chrome, а другое — в IE. И поэтому измерить можно не все. Вы не знаете, когда у вас прорисовался, например, первый результат выдачи.
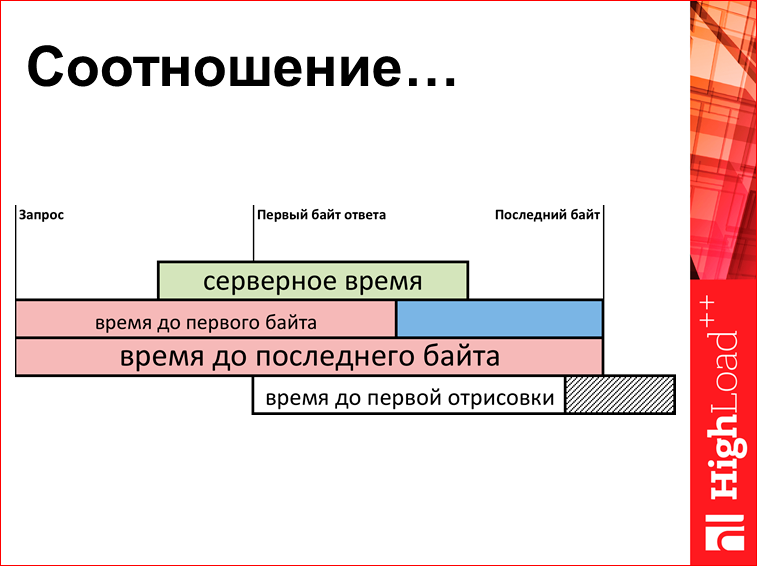
Что можно измерять? Есть некая очень упрощенная схема (реально она раз в 5 больше) того, что происходит у вас в браузере:
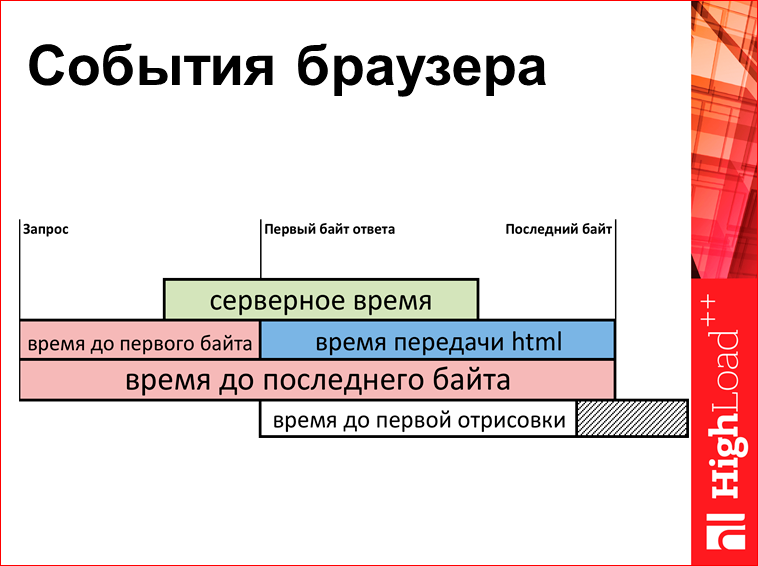
Есть какой-то момент времени, когда браузер задал запрос на сервер. Потом сервер начинает выдавать HTML. Сначала приходит первый байт, потом потихонечку остальные байтики, потом последний байт. И здесь у нас получается некий набор метрик. Можно померить время до первого байта, можно померить время передачи, можно померить время до последнего байта, и это все вытащить Java Script«ом, загрузить на сервер и на сервере построить графиков.
Для сравнения. Это некий первый байт быстрого сервера, сервер находится где-то не очень далеко от Москвы. Как он выглядит в разных городах России:
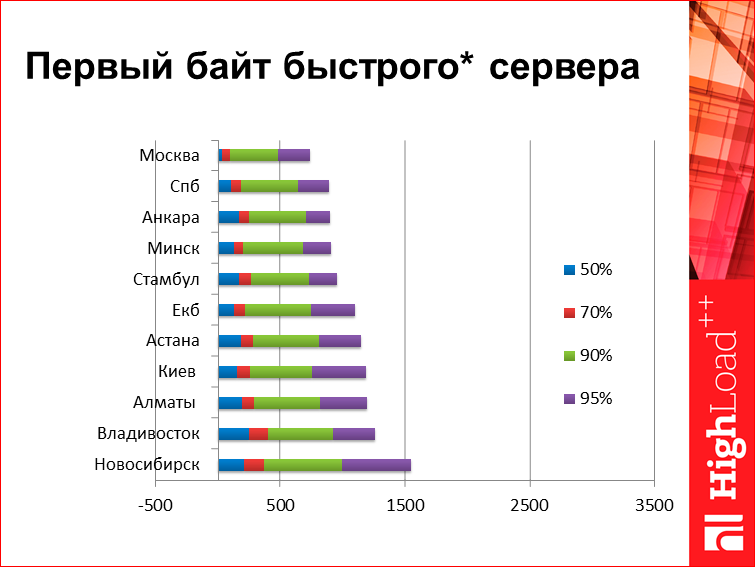
Здесь в каждой строчке есть несколько значений, это т.н. перцентили. Для тех, кто не знает, 50-ая перцентиль означает, что 50% ответов пользователей быстрее, чем данное значение, 50% — больше. Ну, 95% — то же самое. Что мы видим на этом графике? Здесь сервер, который отвечает условно за 0, т.е. с сервера первый байтик улетает сразу же. Размер странички для первого байта значения не имеет, потому что это первый байт — он как пришел, так пришел. Из интересных данных здесь, например, посмотрим на Владивосток — он почему-то на высоких перцентилях уверенно «делает» Новосибирск, потом, если посмотреть низкие перцентили. Низкие перцентили условно определяются скоростью света, а высокие перцентили, определяются непонятно чем. Мне, здесь из этого графика кажется, что в Новосибирске есть какая-то проблема со связанностью.
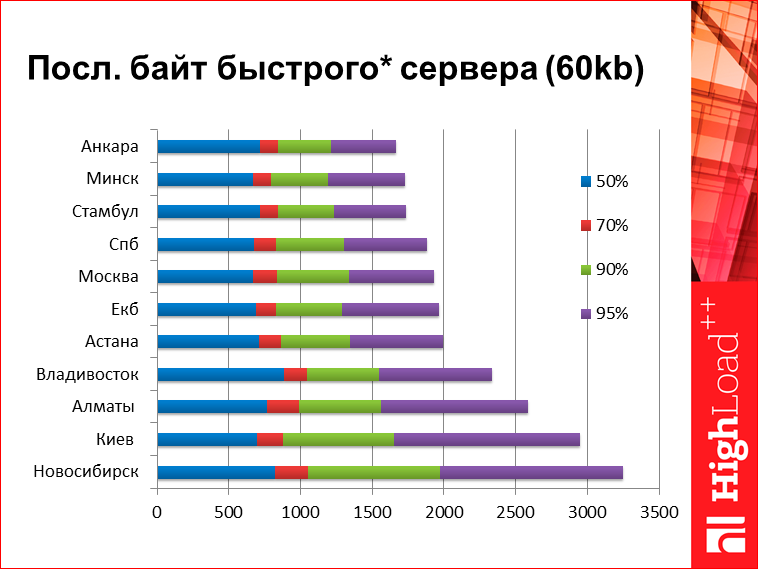
Последний байт быстрого сервера. На самом деле, это некая статическая метрика здесь у меня нарисована. Т.е. здесь я взял время выдачи поиска, но, поскольку здесь серверное время сильно нулевое, я его просто вычел из результатов. Т.е., грубо говоря, это сколько бы занимал ответ поиска, если бы время работы сервера была равно нулю. Здесь мы видим числа достаточно большие. Из интересного — здесь опять же Новосибирск вырывается в какие-то анти-лидеры, Владивосток выступает неожиданно круто, он «делает» Алматы и Киев. Примерно вот такие цифры. Я цифры дал, чтобы вы поняли порядок. Там на нижней циферке, 95-ой перцентили, 3 секунды с копейками. Т.е., грубо говоря, если вы оптимизируете ваш сервер на 100 мс, вы понимаете, что вы оптимизируете какое-то время не совсем то.

На предыдущих двух слайдах была статистика. Есть такая поговорка, что бывает ложь, наглая ложь и статистика. Это статистика.
Когда мы говорим про статистику, то нужно говорить про ограничения. Во-первых, эти API поддерживаются не всеми браузерами. Т.е. на десктопе все с этим неплохо, но на мобильниках, эти API умеют только Chrome на Android«е. Во-вторых, надо понимать, что браузеры выдают разные цифры. Т.е. разные названия свойств в Chome based браузерах и в IE, говорят, что меряем что-то разное.
Потом, если по Chrome можно понять, что эта циферка обозначает, потому что есть исходники, то что циферка обозначает в IE, на самом деле, понять нельзя. Поэтому чисто формально сравнивать их не очень корректно, но с другой стороны, если вы не автор браузера, и не пытаетесь обогнать IE, вам на самом деле все равно, потому что у вас примерно одинаковое распределение браузеров на сайте, сравнивайте с тем, что было, и нормально. И различные статистические выводы подвержены разным когнитивным ошибкам.
Давайте посмотрим на что-нибудь более интересное. У нас здесь разбиение времени до первого байта в разрезе по разным браузерам:
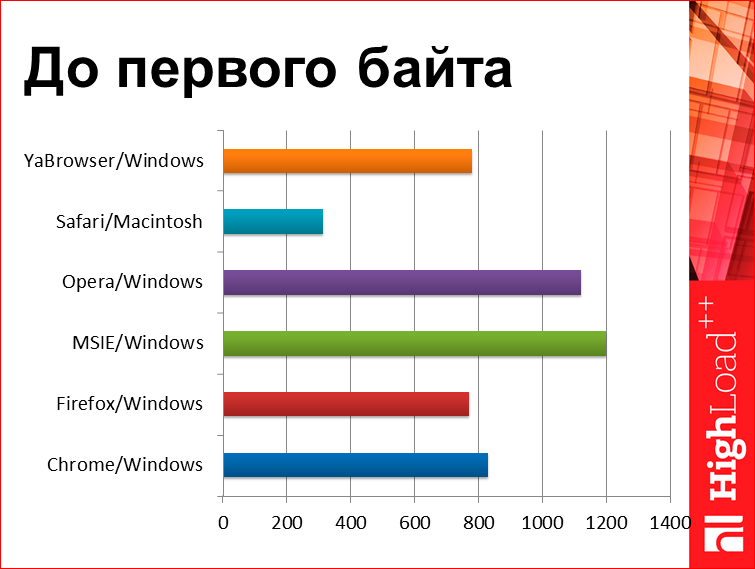
Что мы здесь видим? Мы видим, что Chrome быстрее, чем IE, Opera неожиданно выступает плохо. А тут у нас есть супербраузер, называется Safari, который работает в 2.5 раза быстрее, чем все остальные браузеры. Это классический пример, который называется bias. Ситуация очень простая — если вы вокруг посмотрите, то Маcintosh у каждого второго, условно говоря. Значит, если вы куда-нибудь за озеро Байкал уедете в лес, там Маcintosh будет только ваш, других картинок нет, поэтому да, это правда, что у всех людей в Safari очень быстро открываются странички, но это не потому что Safari хороший, а потому что у них обычно хороший Интернет. Они в Москве, они IT-специалисты и все такое. Нет ничего удивительного, что такая картинка есть. Это к тому, что когда вы видите какие-то гипотезы, их надо как-то обдумано проверять и понимать.

Есть такой волшебный протокол, он называется HTTPS. Мы его все любим, на него все переходят. Что мы про него знаем? Вообще, протокол должен быть медленней. Все понимают, что там вычисления открытых ключей всяких, всякого разного вида handshake, там лишний roundtrip. В общем, все знают, что HTTPS медленней, такое вот общее понимание.
Если мы посмотрим на эти графики, то первый байт в HTTPS приходит быстрее. Я не буду вам показывать график, это здесь не самое важное. Я считаю, что это некий выбор статистики, т.е. скорее всего браузер первый байт handshake считает первым байтом HTML, поэтому говорят, что чуть быстрее. Но здесь еще такой странный вывод, что вообще становится в сумме быстрее. Вот реально, HTTPS быстрее. И этот вывод для нас в какой-то момент оказался сильно парадоксальным, мы стали копать, в чем там проблема.
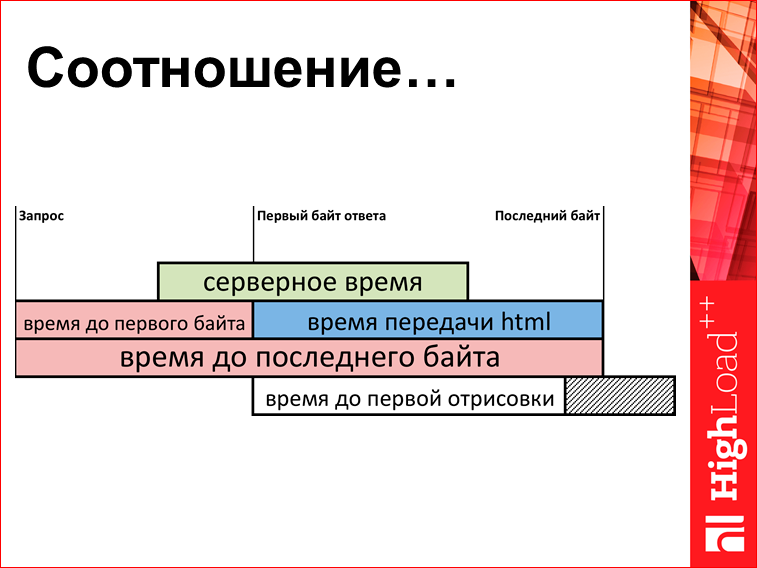
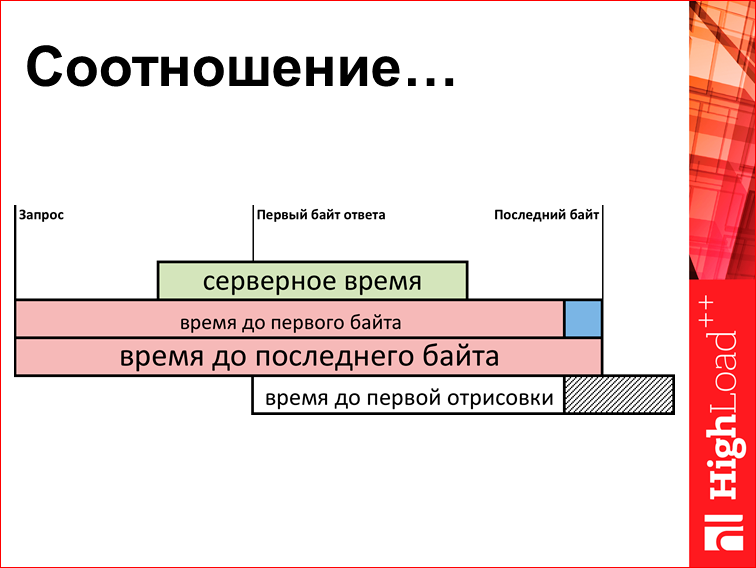
Это я уже показывал. Но поскольку все уже забыли, я покажу еще раз. Смотрим на параметры «время до 1-го байта» и «время передачи html». Здесь бывает разность отношения этой шутки. Так:
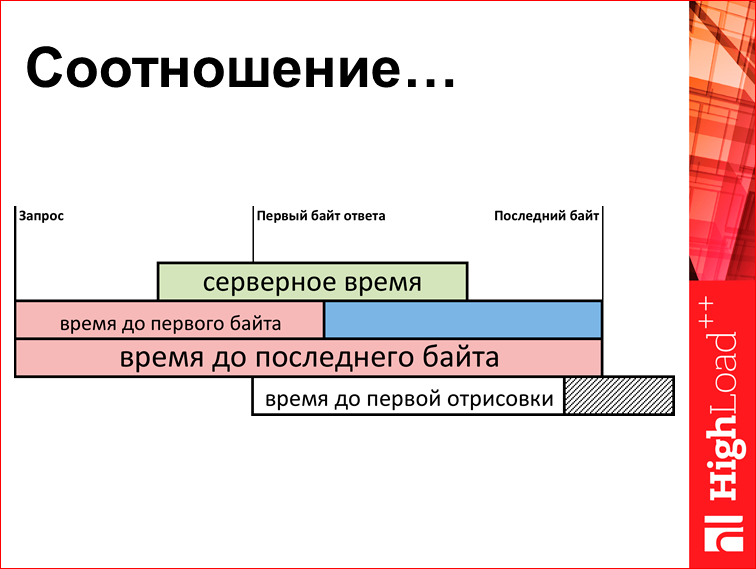
Так:
Так:

Или так:
Короче, есть некий график, который… Это на самом деле, первый график в презентации, над которым стоит подумать, чтобы понять, что на нем нарисовано:
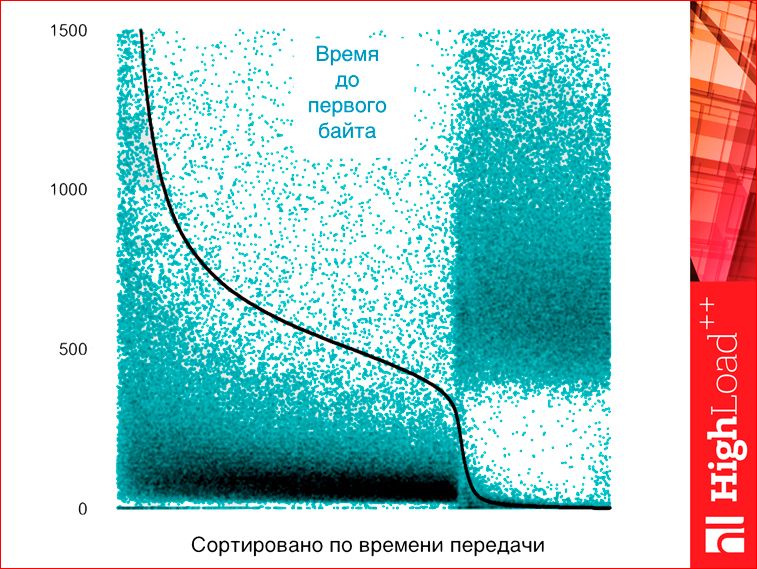
Смотрите, что мы делаем. По оси Х просто номер запроса. Но запросы отсортированы по времени передачи html. А по оси Y отложены зеленой точкой — время до первого байта, а черной точкой — время до передачи html. Поскольку по времени передачи html у нас все отсортировано, то все точки черные выстроились в одну непрерывную линию, что как бы более-менее логично. А поскольку время до первого байта не сортировано, то они не выстроились, но там видно, что есть какая-то корреляция, т.е. там чем больше время загрузки первого байта, тем больше время передачи. Но здесь на графике мы видим два явно разных кластера. Первые кластера ведут себя более-менее нормально, там время передачи коррелирует, и он примерно 70%, а правый край 30% — это время странных запросов, у которых время загрузки, условно, примерно 0, а время первого байта — не нулевое. Т.е., грубо говоря, страничка долго-долго тупила, а потом моментально отдалась целиком. Вопрос: что это такое? Вы не поверите, это на самом деле антивирусы.
Как работает антивирус? Антивирус очень-очень боится, что вы сейчас загрузите себе на страничку какой-нибудь страшный вирус или картинку с эксплоитом, или что-нибудь еще. Поэтому когда вы что-нибудь грузите по http, антивирус все буферизует, ждет последнего байтика, быстренько проверяет и потом все вам выплевывает. Поскольку страничка уже у вас на компьютере, то получается, что страничка долго тормозила, потом быстро пришла.
Вопрос: что произойдет, если мы в этом месте переключимся на HTTPS? Сразу же все антивирусы потеряют возможность свое волшебное добро творить, и странички начинают загружаться после этого быстрее. Это эффект, собственно, про то, почему HTTPS, несмотря на все интуитивные суждения, работает быстрее, чем HTTP. И это причина, почему все сайты типа Google и Facebook переходят на HTTPS — он просто тупо быстрее. Я понимаю, что это некое сильно революционное заявление, поэтому я приложу proofpic.
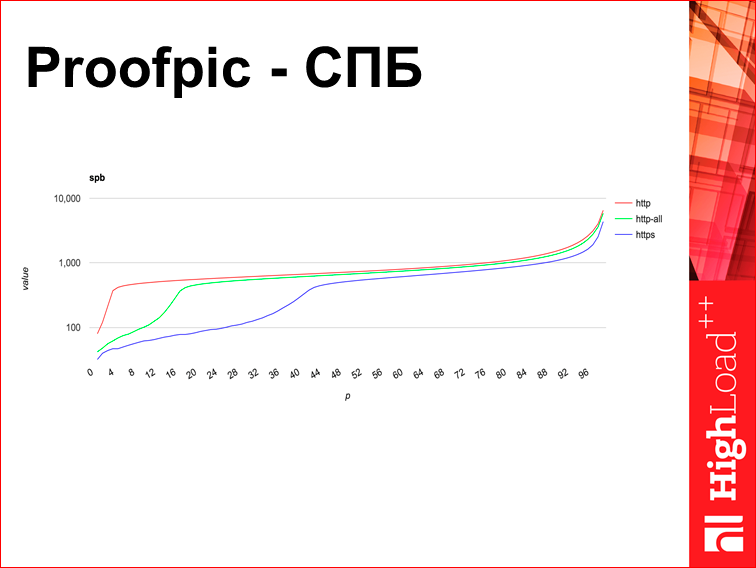
Proofpic — что это такое? Это картинка из некоего внутреннего интерфейса Яндекса. Я предыдущие графики перерисовывал в Excel, но если бы я этот график в Excel перерисовал, это был бы не Proofpic, я бы мог его подделать. Поэтому он с тонкими линиями, не очень удобный. Это время загрузки некой странички Яндекса в HTTPS и не в HTTPS в городе Санкт-Петербург. По оси Х отложена перцентиль, по оси Y отложено время загрузки, при том, что оно логарифмическое, т.е. шкала 100 тыс., 10 тыс., а не 100, 200, 300. И здесь мы видим, что HTTPS на всех перцентилях быстрее.
Это то же самое во Владивостоке:
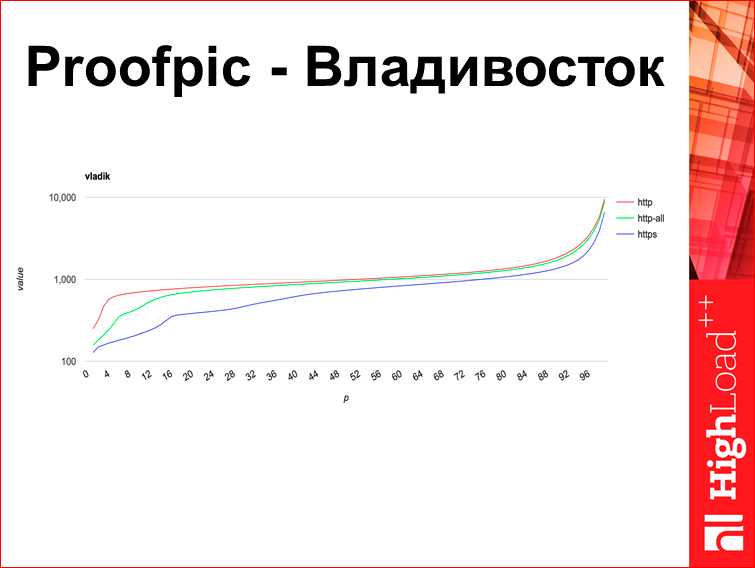
Компания Яндекс, когда боролась с антивирусами (у нас хорошие отношения с антивирусными компаниями), мы попросили их всех в конечном итоге засунуть нас в «белые листы». Тот график, который я зелеными точками строил, он очень старый, это до этого момента. Но этот эффект не исчез, это новые графики, буквально за сентябрь. Мне казалось, что эти графики дают разные DPI системы, которые у нас банят сайты, чтобы не дай бог, что-нибудь там плохое не посмотрели в Интернете. Вроде же есть такая штука.
Этот график из Киева:
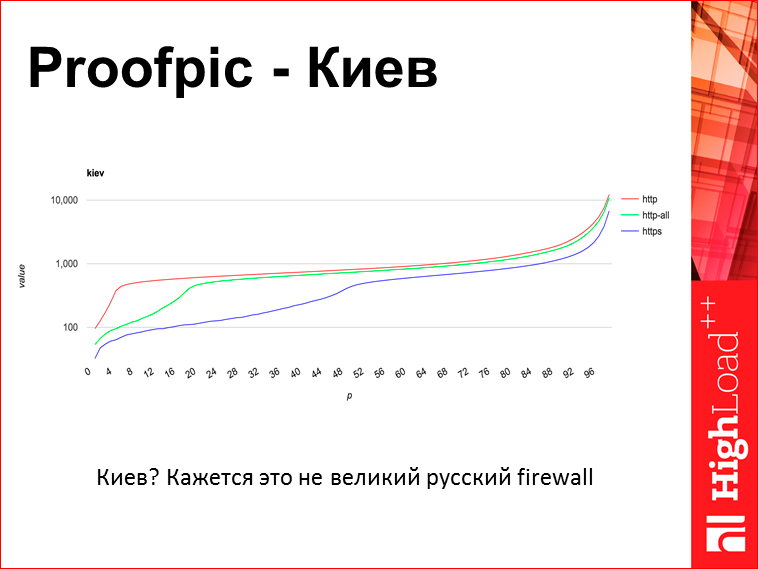
И здесь ровно такая же ситуация, что говорит, что возможно великий русский DPI не совсем при чем, хотя он там как-нибудь участвует.
А этот график из Стамбула:
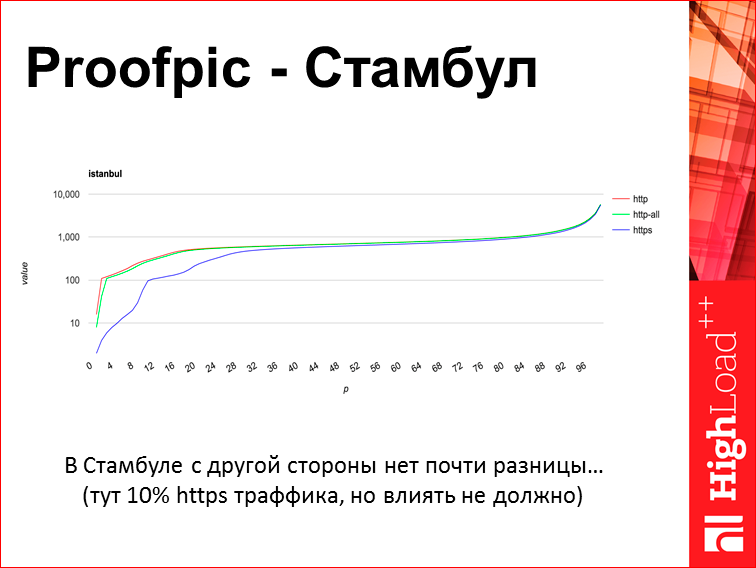
В Стамбуле, как вы видите, HTTPS и HTTP практически не различаются, там какая-то другая ситуация, но почему, не знаю.
Вывод, который я делаю, примерно такой, что есть какое-то огромное количество разного вида систем, которые себя считают шибко умными, им очень интересно, что у вас там в HTTP, и они из-за этого тормозят. Поэтому я вас призываю пользоваться HTTPS почти во всех случаях.

Это некий промежуточный итог, конец первой части.
Мы поняли, что серверное время — это не все. И мы поняли, как измерять клиентское. Что нам тут непонятно, это как так получается, что во Владивостоке, докуда ping явно меньше 200 мс, время загрузки странички в 95-ой перцентили может быть 3 секунды, и вопрос: где эти пакеты шлялись все это время? И здесь же становится понятным недостаток тех API браузеров, про которые я говорил, потому что оно вам возвращает циферку, и вы сами понятия не имеете, из чего эта циферка сложилась, не знаете, что там происходит.
Есть такой волшебный tool, называется tcpdump:

Все админы знают и когда-нибудь им пользовались. Что tool делает? Вы можете снять у себя трафик, и там будет все, потому что, когда сервер посылает пакетик пользователю, от пользователя приходит пакетик, что «чувак, я получил твой пакет», и тем самым можно засечь время доставки. Проблема в том, что эта штука трудоемкая, а во-вторых, она точечно применяется, вы можете посмотреть одну сессию, вы можете посмотреть 10 сессий, но вы не можете в tcpdump посмотреть 1 млн. сессий. Как бы работа на самом деле тупая, вопрос: можно ли это автоматизировать? Выясняется, что можно.
Есть такой opensource tool. Я его написал.

Я понял, что я забыл открыть проект на GitHub, но это сделаю сразу же после доклада. Он будет лежать по второй ссылке, а на первую ссылку его потом переложат.
Что это такое? Это некоторый tool, который парсит tcpdump«ы. Он парсит tcpdump в текстовый файлик, который можно загрузить в Excel и понять, что там происходит. Я могу сразу сказать, что это не конечный продукт, это hardcore tool. Не стесняйтесь ко мне обращаться, я вам скажу, как им пользоваться, если что.
Сейчас я попробую выдать результат, который может, собственно, tool. Давайте рассмотрим сначала такой стенд:
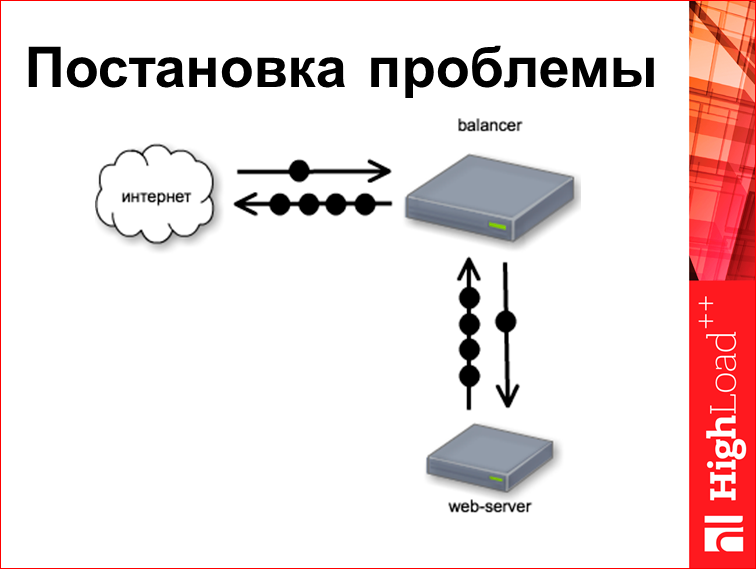
Это некий классический стенд. У нас есть веб-сервер, над ним есть какой-то балансер, допустим, это nginx. Из Интернета поступает запросик. Попробуем понять, какие здесь есть тайминги этих запросов.
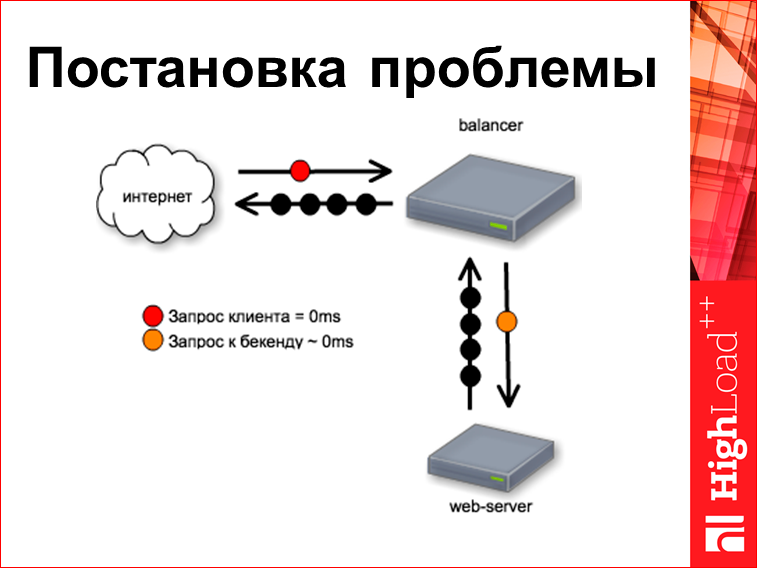
Запрос клиента у нас всегда тождественно приходит в нулевую миллисекунду, потому что мы от него начинаем отсчитывать время. Балансер у нас очень-очень быстрый и хорошо написанный, поэтому этот запрос идет к бэкенду прямо в ту же самую нулевую миллисекунду, т.е. пришел пакетик, и его кинули сразу же.
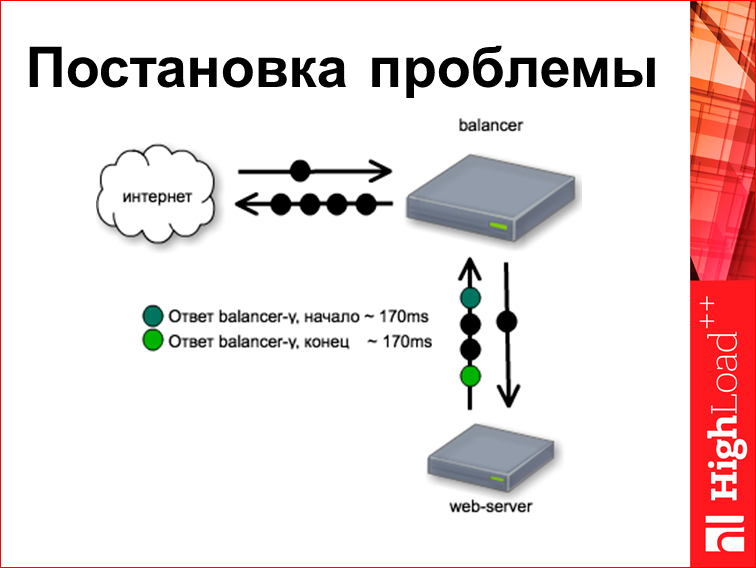
Следующее. Время работы с веб-сервером. Этот конкретный веб-сервер устроен так. Он про что-то думает 170 мс, а потом целиком отдает готовую страничку. И стоит заметить, что, если запрос — это обычно один пакетик, то ответ — это несколько пакетиков, мы из них берем первый и последний, но поскольку она у нас вся родилась и вся плюется целиком, они опять же идут в одно и то же время. А потом балансер начинает раздавать эту страничку пользователю, для чего, собственно, написан nginx.
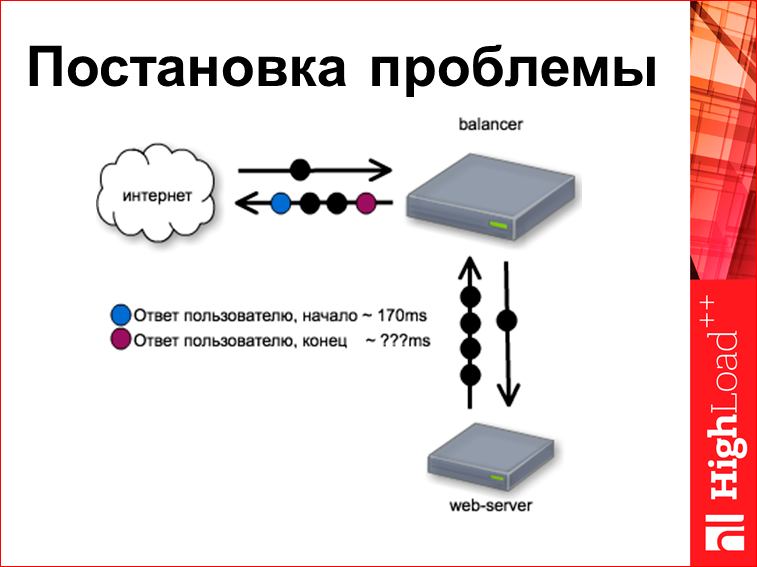
И поскольку балансер у нас быстрый, он первый байтик пользователю дает на 170-ой миллисекунде. Вопрос: когда он отдаст последний байтик?
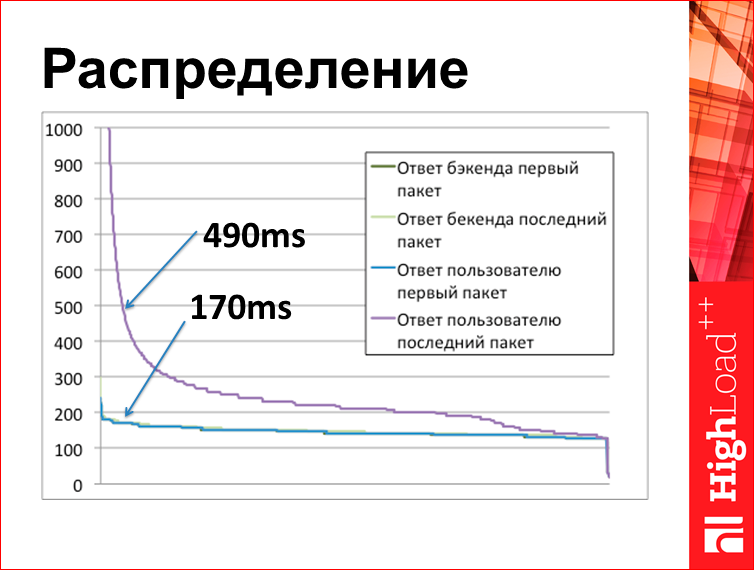
Этот график, построенный по результатам tcplanz. Что здесь на графике? По оси Х номер запроса, сортированный по времени. Здесь на самом деле 4 линии, но 3 линии внизу соединились условно в одну, потому что они прям про одно и то же, они все 170 мс, они друг на друге. А фиолетовая линия — это когда ушел последний байт ответа пользователю от нашего балансера. Что мы здесь видим? У нас веб-сервер сделал страничку за 170 мс, а потом, когда мы начали отдавать пользователю, мы последний байт отдали на 490 мс.

Т.е. вывод примерно такой: когда вы задаете вопрос: «а где шлялись пакеты все это время?», они на самом деле все это время лежали у вас на сервере, как ни странно. Когда во Владивостоке 95-ая перцентиль 3 секунды, у вас все это время пакеты не покидают ваш сервер. Это некий парадоксальный ответ. Сейчас я объясню, откуда он берется.
Для того чтобы получить ответ на этот вопрос, нужно знать, как работает TCP. Про TCP написано много книжек, прямо тома. Про TCP можно рассказать даже за отдельное выступление, но я попробую рассказать за один слайд. Хотя получится очень примитивно.

Здесь написаны три концепции TCP, которые надо осознать:
- первая — это т.н. round trip time — это время, когда пакетик доходит до нужного сервера и обратно. Когда вы применяете утилиту ping, та циферка, которую вы там видите, это и есть время round trip.
- потом есть такое понятие ACK — это подтверждение доставки. Вы кидаете пакет данных пользователю, а от пользователя приходит пакетик «чувак, я данные получил», и по этому пакету вы можете понять, когда данные дошли, потому что вы время разницы между пакетиком и ack делите пополам, и примерно в это время он был у пользователя. Стоит заметить, что ack приходит не на каждый пакет, потому что одним ack ack«ают несколько пакетов.
- третья концепция называется cwnd — это т.н. congestion window. Что это такое? Это некая циферка, которая означает, сколько можно отсылать пакетов без подтверждения, т.е. вы шлете сколько-то пакетов, а потом ждете подтверждения, пока он не придет.

Чем определяется скорость доставки. Правило очень простое: на каждые CWND пакетов, вам нужно rtt времени. Т.е. в Интернете типичный размер пакета 1450 байт или 1410, когда у вас cwnd=10, rtt=100, то у вас скорость потока будет 145 Кбайт в секунду. Когда у вас cwnd=100, rtt=50, скорость будет почти 3 метра в секунду. И cwnd — это не какой-то захардкорженный параметр, это параметр, которым регулируется скорость TCP-канала. Есть на самом деле много политик, которые можно применять, но правило очень простое: cwnd медленно растет, пока все хорошо, т.е. пока пакетики идут, и сильно падает, когда что-то плохое в канале происходит, когда пакет теряется. Типичная политика, которую можно применить — за каждый ack можно увеличивать на единицу, а когда пакет потерялся — резать вдвое. Это такая самая старая, сейчас новые, более модные всякие политики и т.д.

Итого, что мы знаем про TCP? Вообще, это новейший протокол, сделан в 70-ом году, сейчас маленечко устарел. В протоколе никто не обещал, что будет быстро, в 70-ом году такого понятия не было. Протокол обещал, что если вы делите один и тот же канал с каким-то другим TСP-потоком, то у вас канал поделят примерно поровну, или по-честному, я не знаю.
Вообще, протокол сделан для проводов, т.е. когда его дизайнили, не было никакого wi-fi, ни сотовой связи, ничего не было. И очень важная ubsumbtion протокола, который сейчас нарушен, выглядит так: потеря означает congestion. Что это такое? Это означает, что когда у вас связь идет по проводам, у вас не бывает такого, что пакетик взял и потерялся сам по себе, пакетик там теряется в одном конкретном случае — это когда вы пытаетесь с двух 100-Мбитных каналов трафик засунуть в один 100-Мбитный канал, вы не можете, он не пролезает, и когда очередной пакет не лезет, вы его просто дропаете. И в этот момент TCP понимает, что вы превысили канал, надо бы слать меньше, и из этого получается это правило, что когда у вас теряется пакет, нужно уменьшать скорость передачи. К сожалению, прямо сейчас эта штука нарушена. Почему? Потому что пакеты больше не передаются по проводам, они передаются, например, по wi-fi, а в wi-fi пакет может пропасть просто так, не потому что скорость превышена, а потому что не повезло.
Многие люди не понимают, как работает wi-fi. Они считают, что это какое-то радио, которое сквозь стену бьет. Вот пример распространения wi-fi волны в квартире:

Очевидно, что wi-fi заворачивает за стены, тут написано в какую стену он попадает. Wi-fi сам на себя интерферирует, волны пересекаются сами с собой, с другими девайсами и т.д. Вы понимаете, что в wi-fi просто теряется пакетик и все, это просто такое ограничение. У wi-fi есть длина волны 12.5 см, если очень-очень точно к стене поставить wi-fi роутер, т.е. не на 12.5 см от стены, а на 12.5 см от железной части стены, то можно получить т.н. стоячую волну, когда у нас роутер вообще перестанет работать. Чтоб вы поняли, там все странно. И поэтому в wi-fi совершенно нормально, что там пакеты теряются. Но TCP, когда он видит теряющиеся wi-fi пакеты, он начинает снижать скорость, что непонятно, зачем нужно.
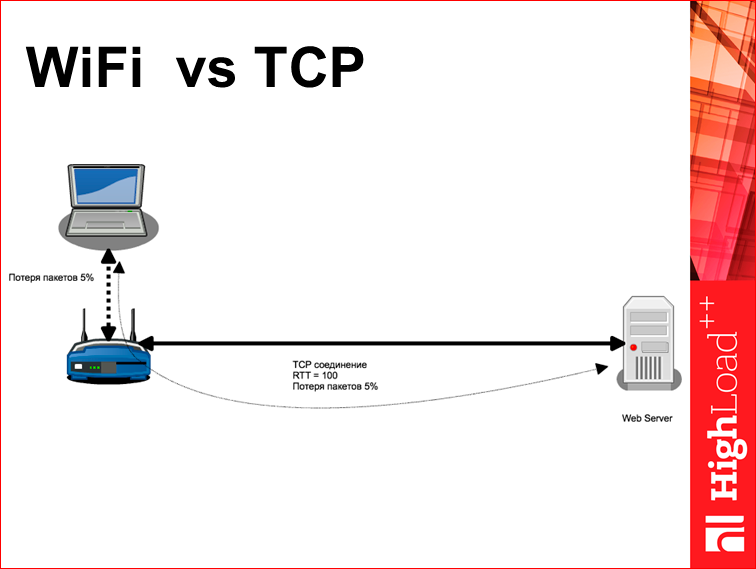
Вот типичная битва двух ёкодзун — wi-fi vs TCP. Предположим, у нас есть веб-сервер и от него до клиента расстояние 2000 км и rtt=100. На этом расстоянии 2000 км пакетики идут по проводам, и они обычно там не теряются. Они могут там потеряться, если какой-то магистральный роутер перегружен, но обычно провайдеры за этим следят. Дальше у вас все это дело упирается в wi-fi роутер, а от него еще расстояние 20 м до вашего лэптопа. И получается странно, что у вас на последних 20 м в основном теряются все пакеты. Т.е. уровень потери пакетов в 5% для wi-fi — это большой уровень потери, медленный wi-fi. Но не запредельный, сейчас, наверное, 80% где-то в зале теряется. И получается странная ситуация, у вас получается логический TCP-канал, который делает следующее: rtt=100 и потеря пакетов 5%. Вы понимаете, что в этом канале не может быть никакой большой скорости. Поэтому не надо жаловаться, что у вас странички сайта загружаются медленно, так все устроено.
Что же делать? Ответ на это от Капитана Очевидности — уменьшайте размер странички.

Во-первых, все знают этот ответ, поэтому он неинтересный, во-вторых, это скучно, хочется что-то другое поделать. Я вынужден сказать, что здесь какой-то серебряной пули нет, т.е. я не могу сейчас сказать, как улучшить весь Интернет. Но давайте попробуем что-нибудь сделать на эту тему.
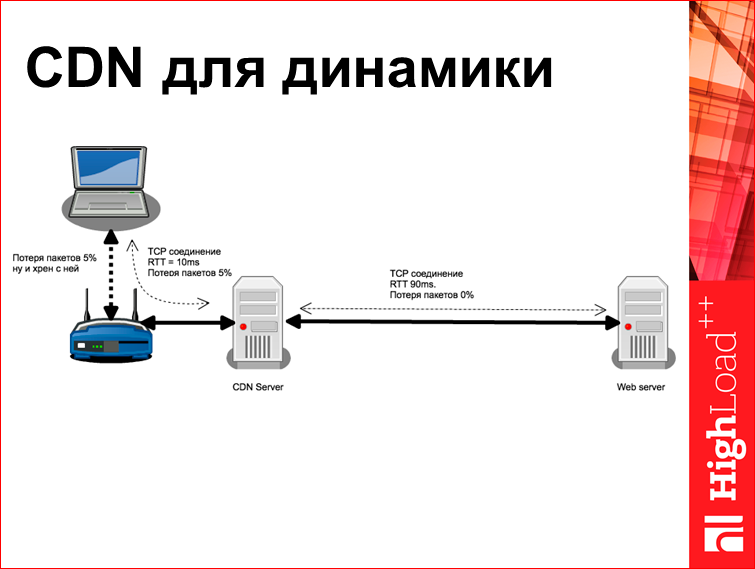
Все знают, что такое CDN, но большинство людей считают, что CDN нужен для какой-то статики, большие картинки положить, видео, чего-нибудь еще. На самом деле, это неправда. Потому что, даже если вы сделаете CDN для динамического контента, у вас станет все резко-резко лучше, потому что вы разорвете тот волшебный loop, что у вас получается TCP-соединение с потерей пакетов в 5% и rtt=100. Здесь у вас будет два разных TCP-соединения, в одном из них будет потеря 0% и rtt=90, но из-за того, что там потеря 0% и если там типа лайф-соединения, у вас этот параметр CWND разгонится до какой-то космической величины, и у вас любая страничка будет туда просто улетать сразу. Тут от CDN-сервера до юзера будут все те же 5% пакетов, но грубо говоря, ничего в этом страшного нет, потому что rtt будет 10 мс.

Потом можно попробовать покрутить параметры TCP. Есть такая штука, называется Initial CWND, это стартовая CWND, с которым стартует TCP-соединение. Эта Initial CWND=10. Число »10» подозрительно совпадает с числом пальцев на руках человека, вы понимаете, что это число просто какой-то человек взял и написал.
Я могу рассказать вам историю этого параметра. Сначала был оригинальный (?), и там было написано, что этот параметр должен быть равен 1 или 2. Потом какой-то умный человек написал новый (?), и там написано, что этот параметр должен быть от 2 до 4. А потом еще другие люди из компании Google всех спасли и написали, что там должно быть сразу 10. Правда же, что никто не верит, что число 10 — самое лучшее число для всех каналов всего мира, всех скоростей, всех годов развития Интернета? Это число 10 означает примерно следующее, что если вы в первый раз заходите на сайт, то первая страничка у вас загружается за 3–4 rtt, потому что у вас за 10 пакетов загрузится примерно 14 Кбайт. Потом оно медленно там вырастет, и все равно у вас будет и получится либо 3, либо 4 rtt, как повезет. Это при том, что у вас идеальный канал, т.е. никаких потерь, ничего нет.
Этот параметр можно подкрутить.
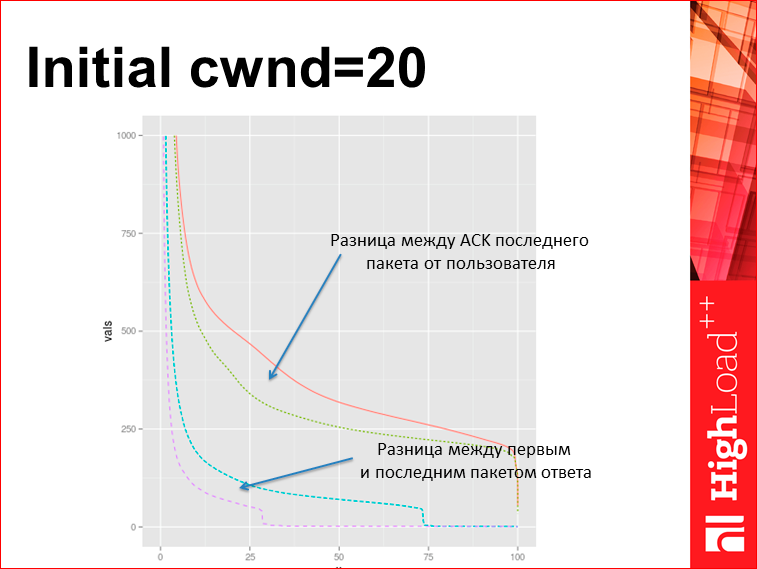
Например, эксперимент в Яндексе. Это турецкий балансер, в нем взяли и поставили initial cwnd=20. Заметим, что это один sysctl в unix«е. Что получилось? Здесь 4 графика. Они попарно — это было, это стало. На нижнем графике отражена задержка между первым и последним пакетом ответа по tcpdump. Т.е. мы видим, что раньше уходило треть страниц сразу, без ожидания, сейчас стало уходить 2/3. А на верху — это время до получения ack пользователя, что страничка дошла. Для tcpdump это то же самое значение, что время до последнего байта в браузере, которое было. Т.е. мы просто покрутили sysctl и на пустом месте улучшили загрузку странички. Это пример, как можно креативно с TCP поступать.
Ради справедливости нужно сказать, что это была типа морда, мы такую же штуку пытались сделать с результатами поиска, они просто больше, и там получилось, скорее странно — некоторые классы запросов усилились, а некоторые ухудшились. Там видимо нужно этот параметр уметь крутить отдельно для разных клиентов, что ядро сейчас не позволяет сделать.
Здесь есть такой безумный пример:

Почему безумный? Потому что я сам так не делал и не призываю вас так делать. Но он хорошо иллюстрирует, что можно сделать в TCP. Представьте, что вы вообще CWND игнорируете. Т.е. страничка, она там типа 60 Кб — 40 пакетов, ее всю просто кидаете в канал. Чтобы там клиент не офигел от того, что много пакетов идет сразу, давайте между пакетиками сделаем 1 мс паузы между двумя соседними. У нас за 40 мс уйдет вся страничка. Выясняется, что если просто так кинуть страничку рандомному клиенту, то скорее всего, она вся дойдет, с вероятностью 70%. В какие-то медленные каналы — в мобильники, к людям, у которых сейчас работают торренты, она возможно не пролезет, но реально это будет работать. Поэтому, чтобы было более-менее надежно, мы подождем, пока от этой странички придет selective ack (информация, что «я все получил, но 3, 10, 17-ый пакеты у меня не дошли», и ты посылаешь обратно 3, 10, 17-ый пакеты). Т.о. получается следующее: страничка на хорошем канале придет к пользователю за 1–2 rtt. Т.е. это быстрее, это не 3 секунды. Это хороший пример, как можно испортить TCP так, что станет быстрее.
Проблема в том, что сейчас такое сделать нельзя, потому что TCP крутится где-то в ядре, а ручек снаружи никаких нет, а еще крутить его надо в первый конекшн. Т.е. если вы смотрите user agent у клиента, если он там типа mobile safari какой-нибудь, то надо быть осторожным с трафиком, если там на декстопе какой-нибудь клиент быстрый, то надо просто ему кинуть и все.
Но есть подход, называется QUIC. Это гугловый протокол для веба, он UDР-based. Прямо сейчас в этом протоколе ничего такого супер интересного меняющегося нет, он примерно такой, как TCP, только на UDP. Но там что очень важно сделано — там клиент может сам управлять всей политикой перепосылки и посылки пакетов, потому что это все вытащено в user space. И в нем вы легко можете сделать разные политики в зависимости от user agent и т.д. Тем не менее, даже если у вас есть QUIC, делать так, как здесь написано, вам не надо. Почему? Потому что если вы сделаете так, у вас станет лучше, но если так сделают все в Интернете, то Интернет сломается.
Сделать нельзя. Тут стоит звездочка, она расшифровывается примерно так: если вы посмотрите на ваш CDN, то, что написано — это ровно то, что внутри происходит. Там даже без паузы в 1 мс. Там компьютеры, которые доверяют друг другу, что они способны принять большой объем данных, каналы, на которых ничего не теряется, congestion«ов почти нет, и любая страничка, которую вы внутри CDN кидаете, она вся уходит туда, поскольку CWND офигенный, разогнанный. И примерно так сейчас работают CDN у большого-большого количества компаний.
На этом месте я хочу подвести некие итоги.

Надо понимать, что те 3 секунды сервера, которые есть, они происходят не потому, что пакет в Интернетах где-то шляется, пакет в это время лежит на вашей машине, и ваша собственная машина из-за ограничения протокола его задерживает.
Серебряной пули здесь нет, но здесь можно что-то пооптимизировать. Потом, если вы работаете с браузерами, у вас не очень большой простор для оптимизации, но если вы пишите мобильное приложение, то вы QUIC можете сделать прямо сейчас.
И третье — когда вы делаете оптимизацию, пожалуйста, следите, что получается. Tools«ы есть, Timing API в браузерах, есть tcpdump, в которых можно понять вообще все, что происходит. Просто берете и смотрите.
Контакты
» anatolix@yandex.ru
» den@yandex-team.ru
» Блог компании Яндекс
Такие доклады мы любим больше всего — реальные исследования, которые могут быть полезны и экономят слушателям (а теперь и читателям) кучу времени.Этот доклад — расшифровка одного из лучших выступлений на конференции разработчиков высоконагруженных систем HighLoad++.
Также некоторые из этих материалов используются нами в обучающем онлайн-курсе по разработке высоконагруженных систем HighLoad.Guide — это цепочка специально подобранных писем, статей, материалов, видео. Уже сейчас в нашем учебнике более 30 уникальных материалов. Подключайтесь!
Ну и главная новость — мы начали подготовку весеннего фестиваля «Российские интернет-технологии», в который входит восемь конференций, включая HighLoad++ Junior. Junior — это не для детей! Junior это про то, как работать с высокими нагрузками, не имея сотен серверов, мегарасшардированной базы данных и Игоря Сысоева в консультантах. Хайлоад в реальных жизненных условиях
