Шерудим под капотом Stable Diffusion
Вероятно вы уже слышали про успехи нейросетей в генерации картинок по текстовому описанию.
Я решил разобраться, и заодно сделать небольшой туториал, по архитектуре Stable Diffusion. Сегодня мы не будем глубоко погружаться в математику и процесс тренировки. Вместо этого сфокусируемся на применении и устройстве основных компонент: UNet, VAE, CLIP.
 Процесс генерации картинки моделью Stable Diffusion по текстовому описанию
A grey sketch on paper of a Ferrari car, full car, pencil art
Процесс генерации картинки моделью Stable Diffusion по текстовому описанию
A grey sketch on paper of a Ferrari car, full car, pencil art
Под катом
DreamStudio для первых экспериментов
Пайплайн в библиотеке Diffusers от Hugging Face
Основная идея модели
Variational Autoencoder (VAE)
CLIP Text Encoder
UNet
Собираем свой пайплайн
Заключение
Ссылки
DreamStudio для первых экспериментов
Если вы еще никогда не пробовали генерировать картинки по текстовому описанию, то можете сделать это в DreamStudio с регистрацией, но без смс. Интерфейс простой — вводите текст в поле снизу. Нажимаете Dream. Профит.
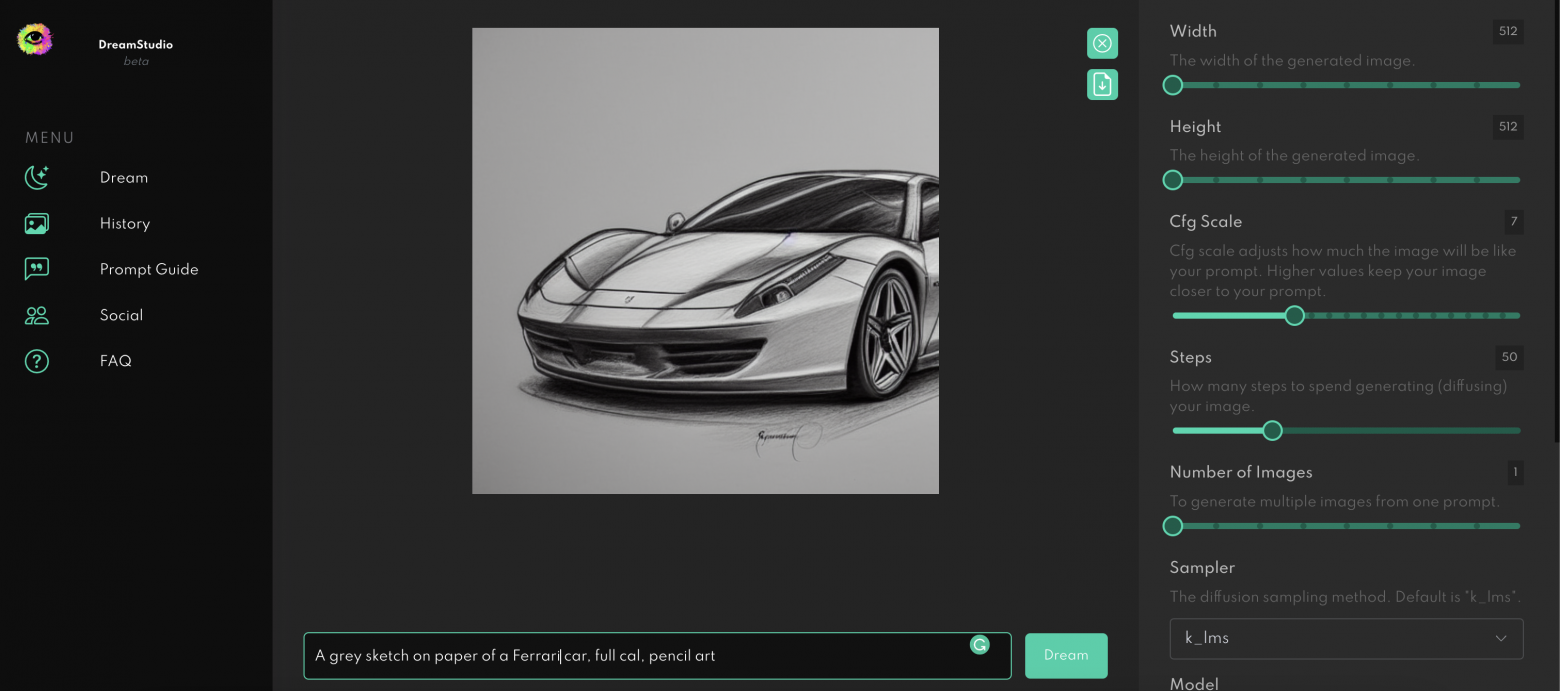 Пример генерации через интерфейс DreamStudio
Пример генерации через интерфейс DreamStudio
Пайплайн в библиотеке Diffusers от Hugging Face
Для начала вам потребуется GPU с достаточно большим объемом видеопамяти. Поэтому предлагаю воспользоваться подарком невиданной щедрости от Google — бесплатными GPU в Google Colab. Можете создать отдельный ноутбук, или воспользоваться шаблоном.

Есть шанс, что из коробки у вас только CPU. Чтобы это исправить, в верхнем меню выбираем
Среда выполнения → Сменить среду выполнения.
Устанавливаем значение
Аппаратный ускоритель: GPU.
Устанавливаем зависимости.
!pip install diffusers transformers scipy ftfy "ipywidgets>=7,<8"Импортируем зависимости.
import os
import requests
import torch
import google.colab.output
from torch import autocast
from torch.nn import functional as F
from torchvision import transforms
from diffusers import (
StableDiffusionPipeline, AutoencoderKL,
UNet2DConditionModel, PNDMScheduler, LMSDiscreteScheduler
)
from diffusers.schedulers.scheduling_ddim import DDIMScheduler
from transformers import CLIPTextModel, CLIPTokenizer, CLIPProcessor, CLIPModel
from tqdm.auto import tqdm
from huggingface_hub import notebook_login
from PIL import Image, ImageDraw
device = 'cuda'
google.colab.output.enable_custom_widget_manager()
notebook_login()И видим челебоса, который просит токен.

Для получения токена:
Логинимся на сайте Hugging Face https://huggingface.co/login
Принимаем лицензию модели https://huggingface.co/CompVis/stable-diffusion-v1–4
Генерируем токен https://huggingface.co/settings/tokens
Вставляем в Colab.
 В случае успеха
В случае успеха
Настало время написать 3 строчки кода на Python — поступок не мальчика, но мужа!
Скачиваем веса сети и загружаем их в видеопамять.
pipe = StableDiffusionPipeline.from_pretrained(
'CompVis/stable-diffusion-v1-4',
revision='fp16',
tourch_dtype=torch.float16,
use_auth_token=True
)
pipe = pipe.to(device)Задаем prompt и генерируем картинку.
prompt = 'A grey sketch on paper of a Ferrari car, full car, pencil art'
with autocast(device):
image = pipe(prompt)['images'][0]
imageНаслаждаемся результатом.
Также есть возможность генерировать сразу несколько картинок.
def image_grid(images, rows, cols):
assert len(images) == rows * cols
w, h = images[0].size
grid = Image.new('RGB', size=(cols * w, rows * h))
grid_w, grid_h = grid.size
for i, img in enumerate(images):
grid.paste(img, box=(i % cols * w, i // cols * h))
return gridnrows, ncols = 1, 3
prompts = [
'A grey sketch on paper of a Ferrari car, full car, pencil art'
] * nrows * ncols
with autocast(device):
images = pipe(prompts)['sample']
image_grid(images, rows=nrows, cols=ncols)Вращаем барабан. Получаем суперприз — автомобиль в количестве трех штук.
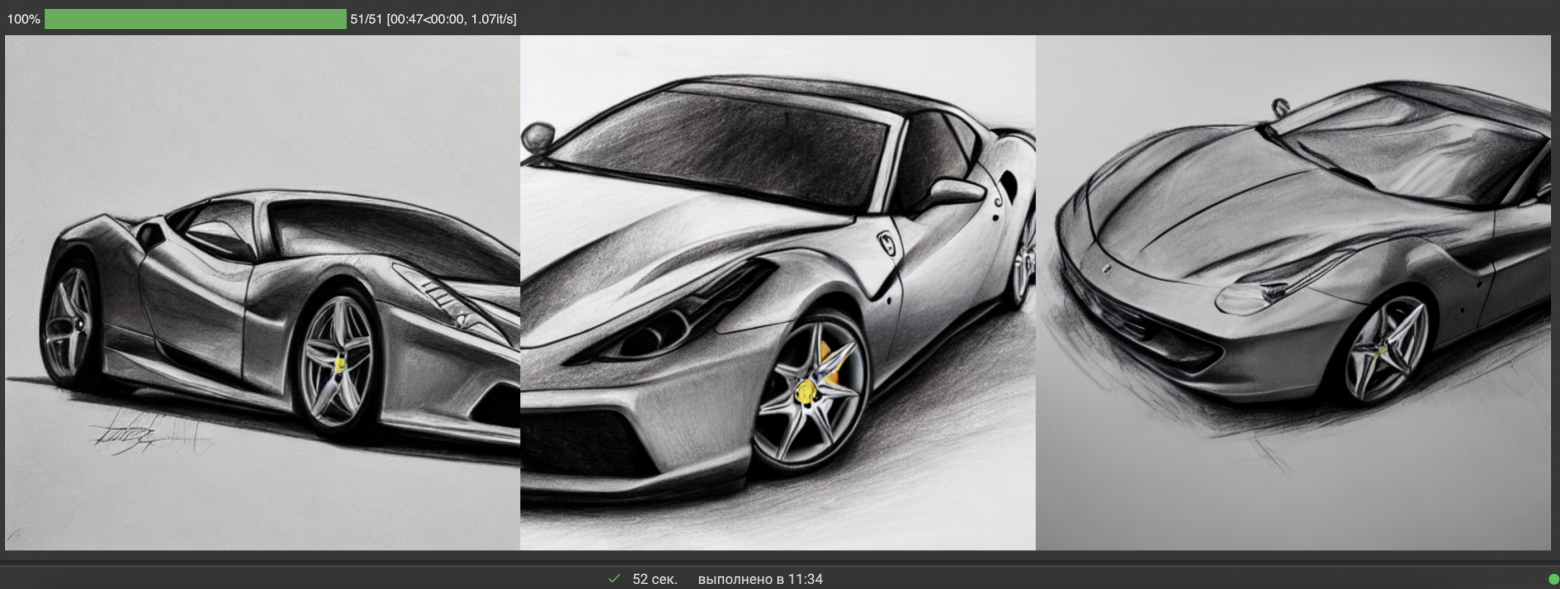 Пример генерации сразу нескольких картинок
Пример генерации сразу нескольких картинок
Если переборщить с числом одновременно генерируемых картинок, то вылетит ошибка.
RuntimeError: CUDA out of memory.Если посмотреть на потребление видеопамяти с помощью команды
!nvidia-smiУвидим, что в моем случае (попробовал nrows=2, ncols=3) занято 15 из 16 Gb.
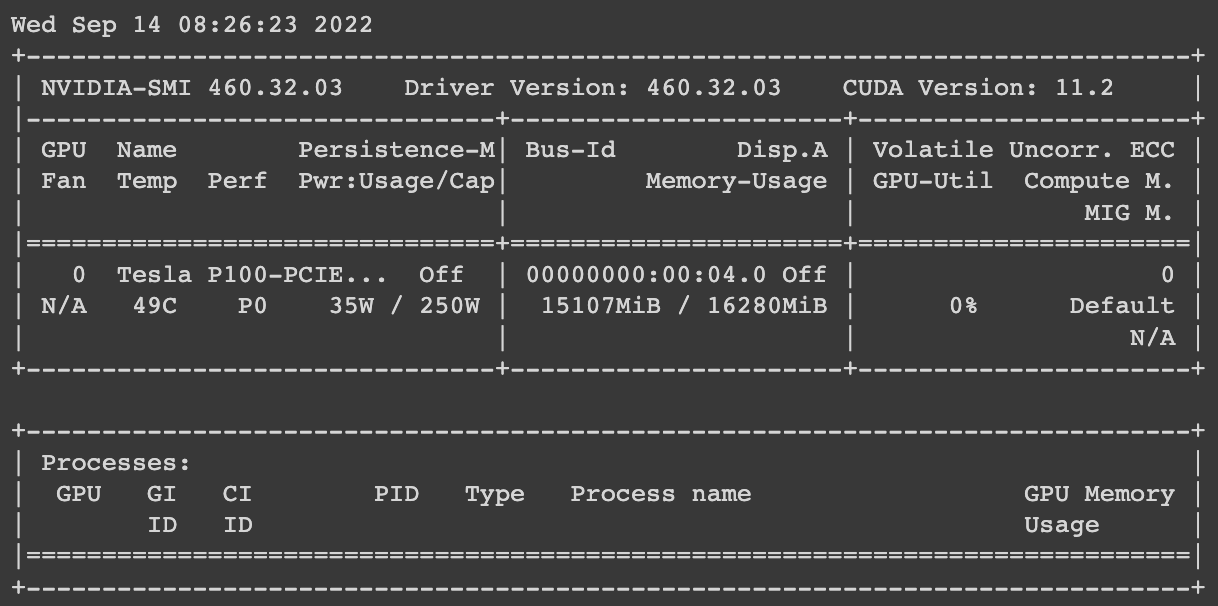 ! nvidia-smi
Пример, когда 15 из 16 Gb видеопамяти заняты и вылетает ошибка CUDA out of memory.
! nvidia-smi
Пример, когда 15 из 16 Gb видеопамяти заняты и вылетает ошибка CUDA out of memory.
Чтобы справиться с ошибкой, можно перезапустить среду выполнения в верхнем меню. При этом зависимости заново устанавливать не потребуется, они кэшируются на время сеанса.
Основная идея модели
Давайте научим нейросеть рисовать картинки из ничего. А для вдохновения заглянем к физикам.
Помните, что будет, если в воду капнуть чернил? Жидкости смешаются, вода почернеет. В физике этот процесс называется диффузией.
Stable Diffusion принадлежит к классу диффузионных моделей. Идея в том, чтобы смешать картинку и гауссовский шум. А далее обучить нейросеть из зашумленных изображений восстанавливать оригиналы.
 Постепенное зашумление изображения
Постепенное зашумление изображения
Если подать такой нейросети на вход чистый шум, то постепенно она превратит его в симпатичную картинку. В Stable Diffusion этим занимается UNet.
Нюанс в том, что картинка с разрешением 512×512 состоит из 262 144 пикселей. Если применять диффузионный процесс к ней напрямую, то на вычисления будет уходить много времени и памяти, что усложняет процесс тренировки и инференса. Мы же хотим генерировать картинки быстро и на относительно небольших видеокартах. Поэтому изображения отображаются в пространство меньшей размерности (latent space), там производятся вычисления, а результат обратно разжимается с помощью Variational Autoencoder (VAE).
Мало сгенерировать случайную картинку из шума. Мы хотим заставить модель обращать внимание на текстовое описание, которое ей подаем. Для этого используется Text Encoder из модели CLIP.
Управляет процессом Scheduler — некоторый алгоритм, которые не содержит в себе обучаемых параметров. Он отвечает за то, как именно мы зашумляем изображения.
Variational Autoencoder (VAE)
В библиотеке Diffusers используется реализация VAE из статьи Auto-Encoding Variational Bayes by Diederik P. Kingma and Max Welling.
Модель состоит из энкодера и декодера.
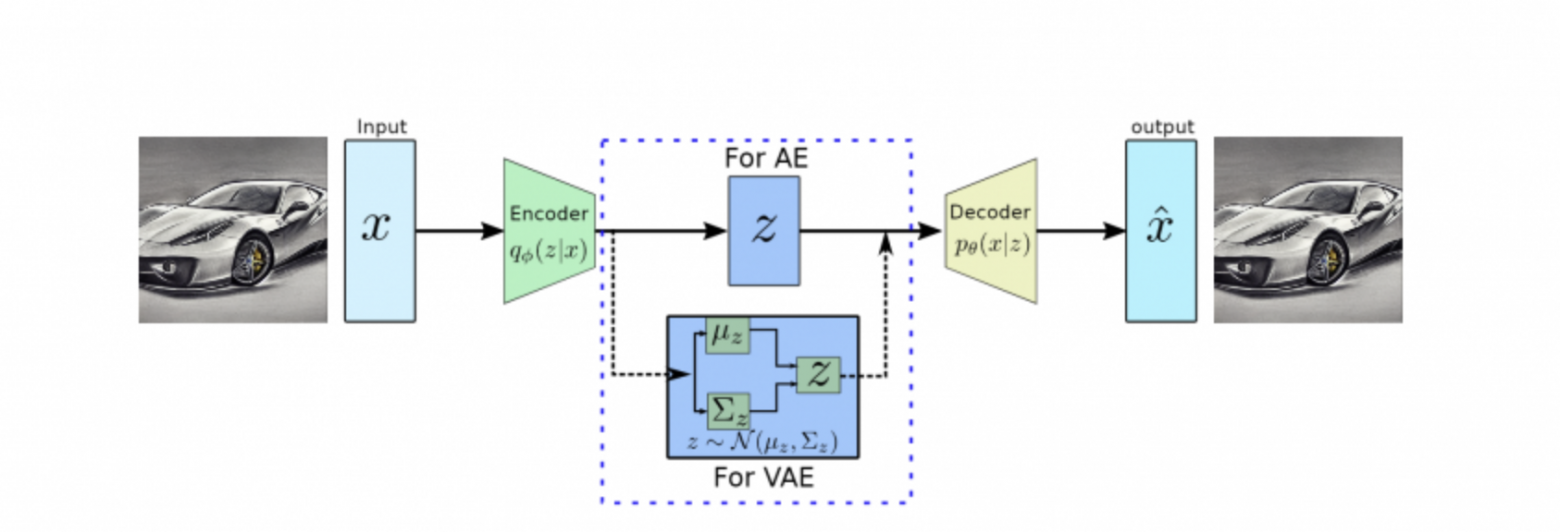 Архитектура VAE
Архитектура VAE
Энкодер принимает на вход картинку в виде тензора (1, 3, 512, 512), где 1 — размер батча, 3 — RGB-кодировка. Возвращает латентное (сжатое) представление — тензор размерности (1, 4, 64, 64).
Декодер принимает на вход тензор из латентного пространства и восстанавливает исходную картинку с некоторой точностью. В результате имеем сеть, которая умеет сжимать и разжимать картинки.
Загрузим модель.
vae = AutoencoderKL.from_pretrained(
'CompVis/stable-diffusion-v1-4', subfolder='vae', use_auth_token=True
)
vae = vae.to(device)
dict(vae.config)
> {
'in_channels': 3,
'out_channels': 3,
'down_block_types': ['DownEncoderBlock2D',
'DownEncoderBlock2D',
'DownEncoderBlock2D',
'DownEncoderBlock2D'],
'up_block_types': ['UpDecoderBlock2D',
'UpDecoderBlock2D',
'UpDecoderBlock2D',
'UpDecoderBlock2D'],
'block_out_channels': [128, 256, 512, 512],
'layers_per_block': 2,
'act_fn': 'silu',
'latent_channels': 4,
'sample_size': 512,
'_class_name': 'AutoencoderKL',
'_diffusers_version': '0.3.0',
'_name_or_path': 'CompVis/stable-diffusion-v1-4'
}Возьмем картинку.
content = requests.get('https://i.ibb.co/qmcCRQJ/ferrari.png', stream=True).raw
car_img = Image.open(content)
car_img = car_img.resize((512, 512))
car_img Вход на VAE Encoder
Вход на VAE Encoder
И отобразим ее в латентное пространство с помощью энкодера.
def preprocess(pil_image):
pil_image = pil_image.convert("RGB")
processing_pipe = transforms.Compose([
transforms.Resize((512, 512)),
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]),
])
tensor = processing_pipe(pil_image)
tensor = tensor.reshape(1, 3, 512, 512)
return tensor
def encode_vae(img):
img_tensor = preprocess(img)
with torch.no_grad():
diag_gaussian_distrib_obj = vae.encode(img_tensor.to(device), return_dict=False)
img_latent = diag_gaussian_distrib_obj[0].sample().detach().cpu()
img_latent *= 0.18215
return img_latent
car_latent = encode_vae(car_img)
car_latent.shape
> torch.Size([1, 4, 64, 64])Получили car_latent — сжатое представление нашей картинки с размерностью (1, 4, 64, 64).
Теперь подадим картинку на вход декодеру.
def decode_latents(latents):
latents = 1 / 0.18215 * latents
with torch.no_grad():
images = vae.decode(latents)['sample']
images = (images / 2 + 0.5).clamp(0, 1)
images = images.detach().cpu().permute(0, 2, 3, 1).numpy()
images = (images * 255).round().astype('uint8')
pil_images = [Image.fromarray(image) for image in images]
return pil_images
images = decode_latents(car_latent.to(device))
images[0] Результат VAE Decoder
Результат VAE Decoder
Получили нечто, очень похожее на входное изображение. Это и позволяет моделям типа Latent Diffusion показывать хорошие результаты, используя меньшие вычислительные ресурсы, за счет оперирования в latent space.
CLIP
CLIP — модель от OpenAI, которая обучалась на изображениях и их описаниях из интернета. Основная прелесть в том, что она отображает картинки и тексты в единое векторное пространство. Это позволяет измерять близость между картинками и текстами.
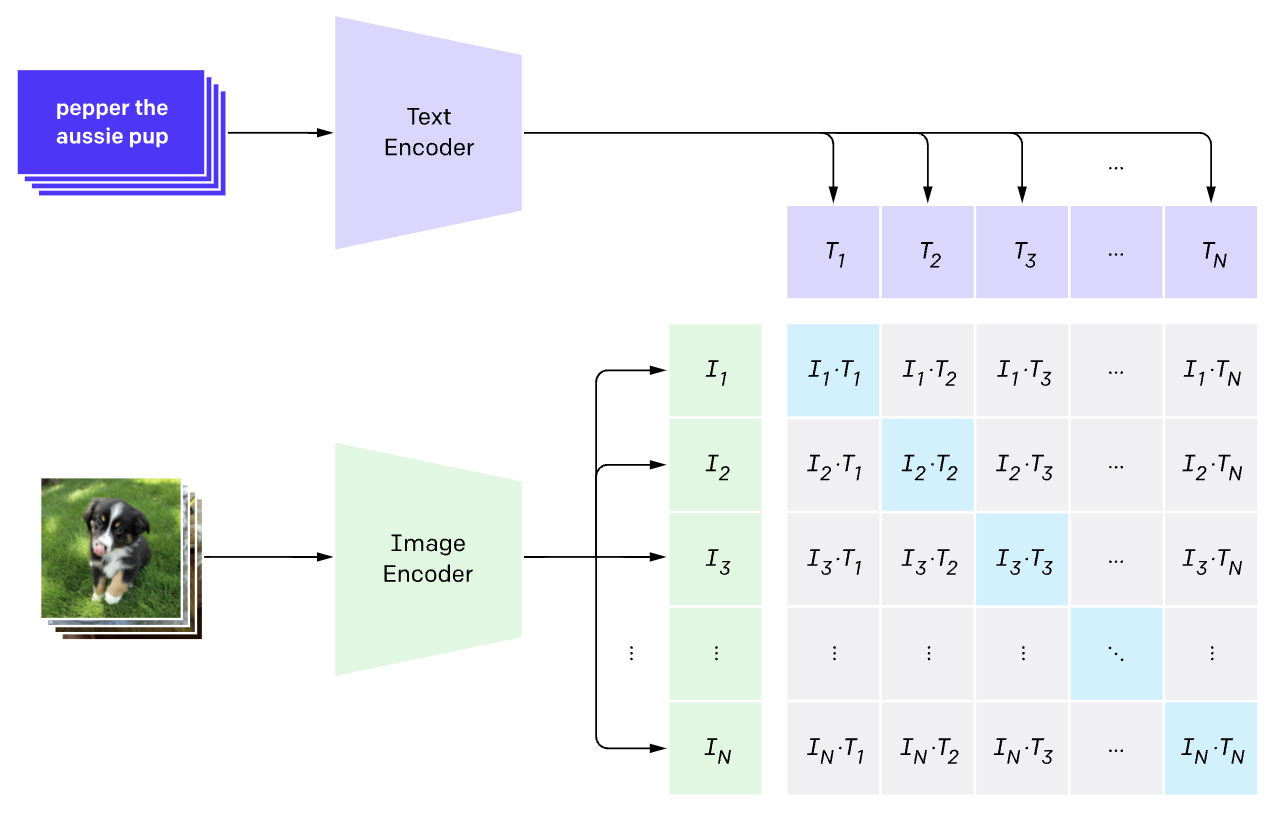 Архитектура CLIP
Архитектура CLIP
Модель состоит из Text Encoder (Transformer) и Image Encoder (ViT).
Сравним картинку, которую подавали на вход VAE в прошлой секции и текстовые описания:
clip_model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
clip_processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
url = 'https://i.ibb.co/qmcCRQJ/ferrari.png'
image = Image.open(requests.get(url, stream=True).raw)
description_candidates = [
'A grey sketch on paper of a Ferrari car, full car, pencil art',
'a car',
'a dinosaur',
]
inputs = clip_processor(text=description_candidates, images=image, return_tensors="pt", padding=True)
outputs = clip_model(**inputs)
logits_per_image = outputs.logits_per_image # this is the image-text similarity score
probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
print(logits_per_image)
> [37.2948, 26.1819, 19.6026]
print(probs)
> [9.9999e-01, 1.4917e-05, 2.0718e-08]Видим, что описание 'A grey sketch on paper of a Ferrari car, full car, pencil art' подходит картинке с вероятностью 0.9999, в то время как описание 'a dinosaur' подходит той же картинке с вероятностью близкой к нулю.
UNet
Рабочая лошадка под капотом Stable Diffusion. Именно эта компонента производит Denoising — итеративное превращение шума в результирующую картинку.
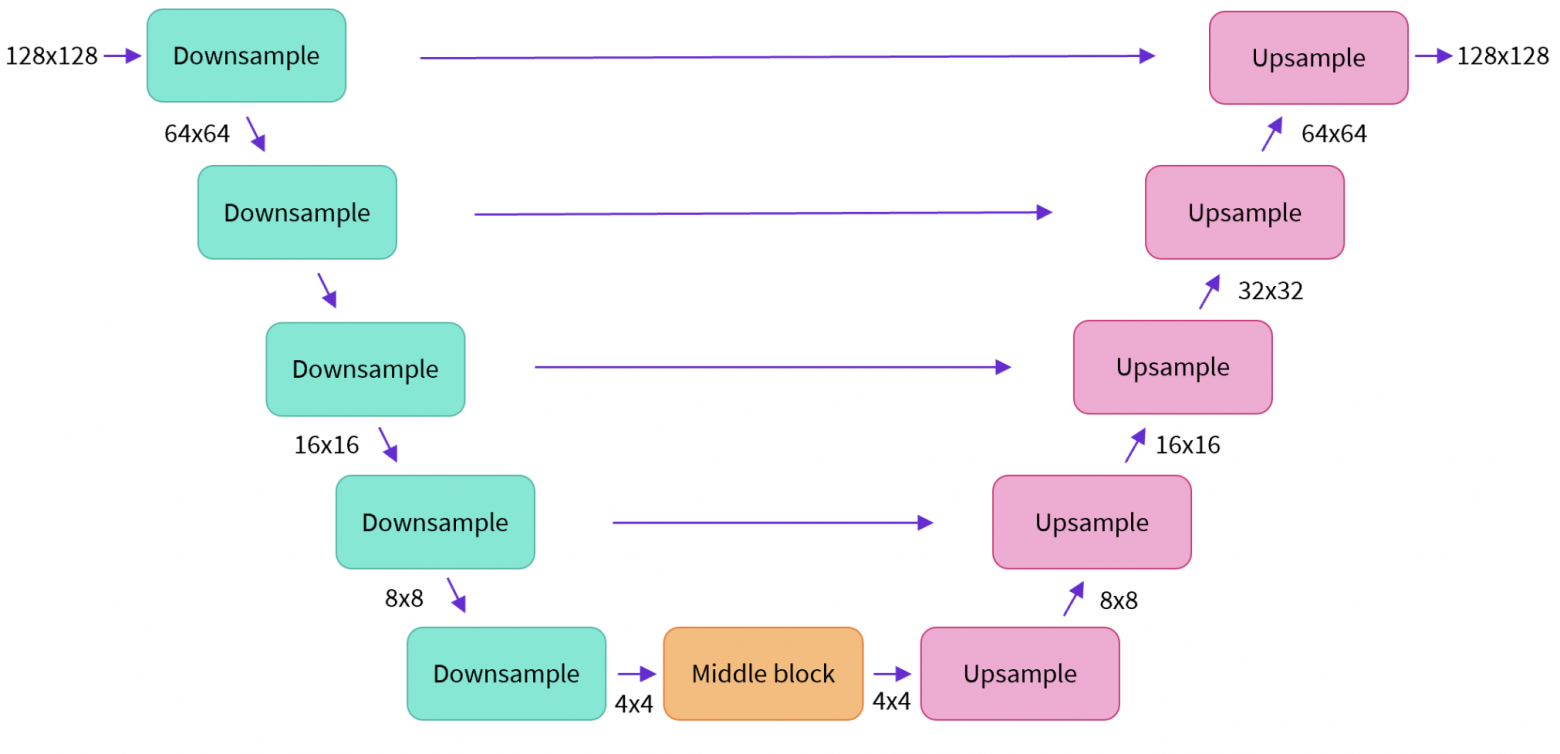 Архитектура UNet
Архитектура UNet
Раньше диффузионные модели умели только восстанавливать картинки из шума, но не учитывали текстовое описание. Тогда они состояли из ResNet блоков — сверточных слоев + skip connections.
В Stable Diffusion все то же самое, но дополнительно используются CrossAttention блоки. Они позволяют смотреть в CLIP Text Encoder, чтобы результат генерации соответствовал текстовому описанию.
unet = UNet2DConditionModel.from_pretrained(
'CompVis/stable-diffusion-v1-4', subfolder='unet', use_auth_token=True
)
unet = unet.to(device)
unet.config
> {
'sample_size': 64,
'in_channels': 4,
'out_channels': 4,
'center_input_sample': False,
'flip_sin_to_cos': True,
'freq_shift': 0,
'down_block_types': ['CrossAttnDownBlock2D',
'CrossAttnDownBlock2D',
'CrossAttnDownBlock2D',
'DownBlock2D'],
'up_block_types': ['UpBlock2D',
'CrossAttnUpBlock2D',
'CrossAttnUpBlock2D',
'CrossAttnUpBlock2D'],
'block_out_channels': [320, 640, 1280, 1280],
'layers_per_block': 2,
'downsample_padding': 1,
'mid_block_scale_factor': 1,
'act_fn': 'silu',
'norm_num_groups': 32,
'norm_eps': 1e-05,
'cross_attention_dim': 768,
'attention_head_dim': 8,
'_class_name': 'UNet2DConditionModel',
'_diffusers_version': '0.3.0',
'_name_or_path': 'CompVis/stable-diffusion-v1-4'
}В конце статьи я приложу ссылку на Colab от создателей Diffusers, где вы можете экспериментировать с UNet и разными Scheduler’ами.
Собираем свой пайплайн
Воспользуемся знаниями про VAE, CLIP, UNet и соберем пайплайн похожий на тот, что мы вызывали через StableDiffusionPipeline во втором разделе статьи.
Создадим scheduler.
scheduler = LMSDiscreteScheduler(
beta_start=0.00085,
beta_end=0.012,
beta_schedule='scaled_linear',
num_train_timesteps=1000
)Напишем функцию для получения текстовых эмбедингов для описания'A grey sketch on paper of a Ferrari car, full car, pencil art'.
def get_text_embeds(prompt):
text_input = tokenizer(
prompt, padding='max_length', max_length=tokenizer.model_max_length,
truncation=True, return_tensors='pt'
)
with torch.no_grad():
text_embeddings = text_encoder(text_input.input_ids.to(device))[0]
uncond_input = tokenizer(
[''] * len(prompt), padding='max_length', max_length=tokenizer.model_max_length,
truncation=True, return_tensors='pt'
)
with torch.no_grad():
uncond_embeddings = text_encoder(uncond_input.input_ids.to(device))[0]
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
return text_embeddings
prompt = 'A grey sketch on paper of a Ferrari car, full car, pencil art'
test_embeds = get_text_embeds([prompt])
print(test_embeds)
print(test_embeds.shape)
> tensor([[[-0.3884, 0.0229, -0.0522, ..., -0.4899, -0.3066, 0.0675],
[-0.3711, -1.4497, -0.3401, ..., 0.9489, 0.1867, -1.1034],
[-0.5107, -1.4629, -0.2926, ..., 1.0419, 0.0701, -1.0284],
...,
[ 0.5668, 1.1076, -2.3770, ..., -1.4189, -0.6171, 0.4183],
[ 0.5545, 1.1131, -2.3889, ..., -1.4055, -0.6261, 0.4250],
[ 0.5227, 1.1315, -2.3088, ..., -1.4146, -0.6122, 0.3927]]],
device='cuda:0')
> torch.Size([2, 77, 768])Напишем функцию, которая создает случайный вектор в latent space и производит Denoising с помощью UNet и Scheduler, учитывая test_embeds с предыдущего шага.
def generate_latents(
text_embeddings,
height=512,
width=512,
num_inference_steps=50,
guidance_scale=7.5,
latents=None
):
if latents is None:
latents = torch.randn((
text_embeddings.shape[0] // 2,
unet.in_channels,
height // 8,
width // 8
))
latents = latents.to(device)
scheduler.set_timesteps(num_inference_steps)
latents = latents * scheduler.sigmas[0]
with autocast('cuda'):
for i, t in tqdm(enumerate(scheduler.timesteps)):
latent_model_input = torch.cat([latents] * 2)
sigma = scheduler.sigmas[i]
latent_model_input = latent_model_input / ((sigma ** 2 + 1) ** 0.5)
with torch.no_grad():
noise_pred = unet(latent_model_input, t, encoder_hidden_states=text_embeddings)['sample']
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
latents = scheduler.step(noise_pred, i, latents)['prev_sample']
return latents
test_latents = generate_latents(test_embeds)
print(test_latents)
print(test_latents.shape)
> tensor([[[[ 0.2196, 0.3412, 0.2564, ..., 0.5965, 0.2621, 0.9491],
[ 0.5094, 0.6396, 0.7730, ..., 0.7261, 0.9269, 0.8177],
[ 0.3972, 0.0753, 0.5931, ..., 0.6357, 1.2942, 0.9378],
...,
[ 0.0101, 0.1279, -0.3112, ..., -0.5879, -0.3295, -0.4144],
[-0.1014, 0.6407, 0.3716, ..., -0.3444, -0.6487, -0.4429],
[-0.1337, -0.0826, -0.1991, ..., -0.4089, -0.5995, -0.4405]]]],
device='cuda:0')
> torch.Size([1, 4, 64, 64])Подадим полученный тензор на вход декодеру VAE.
def decode_latents(latents):
latents = 1 / 0.18215 * latents
with torch.no_grad():
images = vae.decode(latents)['sample']
images = (images / 2 + 0.5).clamp(0, 1)
images = images.detach().cpu().permute(0, 2, 3, 1).numpy()
images = (images * 255).round().astype('uint8')
pil_images = [Image.fromarray(image) for image in images]
return pil_images
images = decode_latents(test_latents)
images[0]
