[Перевод] Как обнаружить мертвый узел в распределенной системе
Если AWS предоставляет только сервер на голом металле, вам нужно будет помесячно платить за каждый запрос, выполняемый при помощи службы обнаружения узлов. AWS будет тяжело не предоставлять такую услугу, но и компаниям будет непросто платить за такую функцию и за каждый инстанс. в отдельности. Кажется, что обнаружить мертвый узел не составляет труда, однако на деле это не так уж просто. Часто эта простая функция предоставляется сторонним облачным сервисам, чтобы было проще отслеживать состояние нашего узла.
Для обеспечения отказоустойчивости отказы нужно обнаруживать. Однако в этой статье вы увидите, как сложно обнаружить отказ узла. Мы также в общем виде обсудим архитектуру, позволяющую обнаруживать отказ узла с накоплением Phi.
Разбираемся, как возникают задержки
Медленную работу сети можно сравнить с очередями в Диснейленде. Представьте, что вы стоите в очереди, желая покататься на аттракционе. В начале очереди вы видите, что время ожидания составляет 10 минут. Может показаться, что 10 минут — это не так уж и много. Поэтому вы остаетесь в очереди. Проходит еще несколько минут. Вы видите, что вы почти дошли до кассы, но вдруг понимаете, что перед вами еще несколько человек, и вам нужно подождать лишние 30 секунд. Задержка устроена аналогично.

Когда пакеты отправляются с вашего компьютера на другой, они проходят через сетевой коммутатор, и он ставит их в очередь и передает в целевой сетевой канал один за другим.
Если пакет перейдет по сетевому каналу на компьютер-адресат, а все ядра процессора на этом компьютере в данный момент окажутся заняты, операционная система поставит в очередь запрос, поступивший из сети, и он останется в очереди до тех пор, пока приложение не будет готово его обработать.
TCP выполняет управление потоком (противодавление), и этот механизм ограничивает количество узлов, к которым обращается сеть, чтобы уменьшить нагрузку на узел, который сейчас содержится в сетевом канале. Следовательно, выстраивается еще один уровень очереди пакетов, он находится на уровне сетевого коммутатора.
Почему трудно обнаруживать отказы узлов
Представьте, что вы выполняете одну программу. Программа не вылетает, но подвисает и выдает ошибки. В программе нет трассировки стека, которая указывала бы, какая часть функции или метода не работает. В этой программе будет намного сложнее обнаружить отказы, чем в описанном выше сценарии полного отказа. Такого рода поведение называется частичным отказом.
Если вы запускаете программу, и часть функции не работает, обычно происходит сбой всей программы. К тому времени уже просматривается трассировка стека, которую можно изучить и понять, почему система отказала.
Частичные отказы гораздо сложнее обнаружить, потому что они не сводятся к «работает — не работает». Существует множество причин, по которым у программы ничего не ладится.
Поскольку распределенные системы не имеют разделяемого состояния, частичные отказы случаются постоянно.
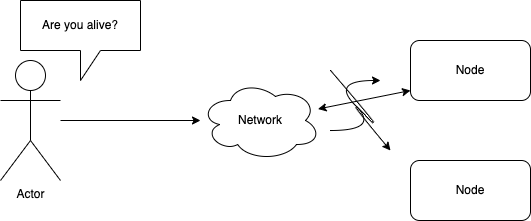
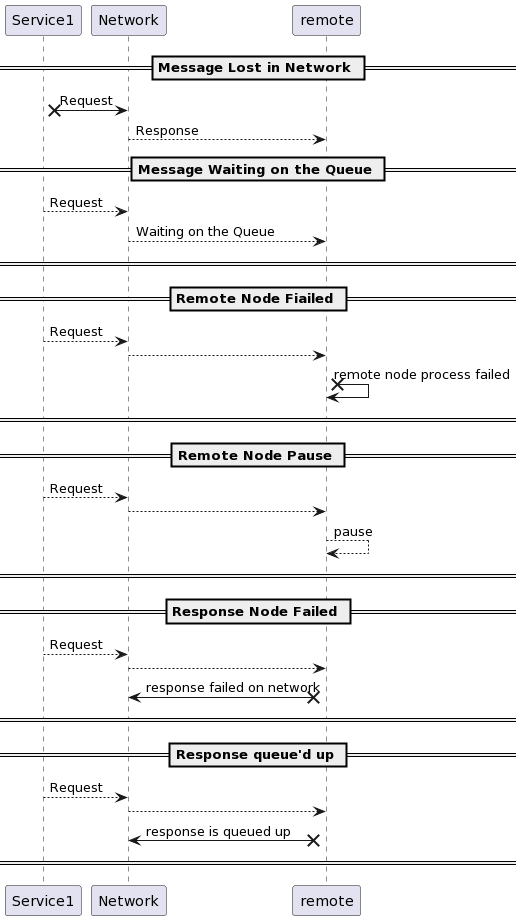
Если вы не получили никакого ответа, это не означает, что узел мертв. Это возможности отказов:
Сообщение было отправлено в сеть, но оказалось потеряно и не получено на другой стороне. Почему это могло произойти:
• Сообщение может ожидать в очереди и будет доставлено позже
• Удаленный узел мог отказать.
• Удаленный узел может временно перестать отвечать, поскольку занят сборкой мусора
• Удаленный узел мог обработать запрос, но ответ был потерян в сети.
• Удаленный узел может быть занят в каком-либо процессе. Он ответил, но ответ был задержан и будет доставлен позже.
Если на сетевые вызовы не будет ответа, то нам так и не удастся узнать состояние удаленного узла. Тем не менее, в большинстве случаев не следует подолгу ожидать отклика… Что в данном случае должны делать балансировщик нагрузки или служба мониторинга?
Время ожидания
Обычно балансировщики нагрузки постоянно выполняют проверку работоспособности, чтобы уточнить, в порядке ли служба. Когда удаленный узел не отвечает, мы можем только предполагать, что пакеты потеряны где-то в процессе передачи.
В таком случае понадобится либо повторная попытка, либо нужно будет выждать до истечения заданного времени. Вариант с повторной попыткой может быть немного опасным, если операции не являются идемпотентными. Следовательно, ожидание — предпочтительный способ, поскольку при отсутствии ответа выполнение каких-либо дополнительных действий может вызвать нежелательные побочные эффекты, например, повторное снятие средств со счета.
Но если мы хотим использовать подход с ожиданием, то какова должна быть длительность ожидания?
Если задан слишком долгий период ожидания, то клиенту, может не хватить терпения; следовательно, от работы с ресурсом «останется осадок».
Если задать слишком краткий период ожидания, то можно получить ложноположительный результат, пометив совершенно функциональный узел мертвым. Например, если узел активен, у него есть больше времени для обработки определенных действий. Преждевременное объявление узла мертвым и включение других узлов может привести к повторному выполнению операции.
Кроме того, как только узел объявлен мертвым, ему необходимо делегировать все свои задачи другим узлам, увеличивая нагрузку на соседей, что может привести к лавинообразным отказам, если другие узлы уже и так работают под высокой нагрузкой.
Правильный период ожидания зависит от логики приложения и прикладных вариантов его использования.
Сервис может объявить ожидание операции через x промежутков времени, если пользователи могут подождать. Например, платежный сервис может установить период ожидания в 7 минут, если пользователь готов ждать 7 минут. Зачастую период ожидания определяется экспериментально, методом проб и ошибок. В таком сценарии устанавливаемое время ожидания обычно является постоянным. Например, оно может составлять 7 минут или 5 минут и так далее.
Однако более разумный способ обнаруживать, что уже идет ожидание — рассматривать это значение не как постоянную величину, а как распределенную дисперсию. Если мы измерим распределение оборотного времени передачи по сети в течение длительного периода и на многих машинах, то сможем определить ожидаемую изменчивость задержек.
Мы можем собрать все данные о среднем времени отклика и некотором факторе изменчивости (колебания). Система мониторинга может автоматически корректировать время ожидания в соответствии с наблюдаемым распределением времени отклика. Такой алгоритм обнаружения сбоев реализуется с помощью детектора сбоев накопления Phi, который используется в Akka и Cassandra.
Детектор сбоев накопления phi (Phi Accrual Failure Detector), использует фиксированный размер окна выборки для каждого такта при оценке распределения сигнала. Каждый раз, когда он вызывает такт на удаленном узле, он записывает время ответа в фиксированное окно. Алгоритм будет использовать это фиксированное окно для получения среднего значения, дисперсии и стандартного отклонения времени отклика.
Таким образом, в следующем разделе мы кратко обсудим, как в общем виде проектируется система обнаружения отказов узла.
Проектирование обнаружения отказов узла
Мы будем использовать компонент обнаружения отказов узла, состоящий из двух сущностей: интерпретатора и монитора.
Задача интерпретатора состоит в том, чтобы трактовать уровень подозрительности узла. Задача монитора состоит в том, чтобы получать такт каждого узла и сообщать время такта интерпретатору.
Монитор будет постоянно пинговать каждый удаленный узел. Каждый раз, обращаясь к удаленным узлам для проверки работоспособности, он получит ответ в течение определенного времени. Затем он отправит информацию о времени отклика интерпретатору для определения уровня подозрительности узла.
Существует два способа размещения интерпретатора: централизованный и распределенный.
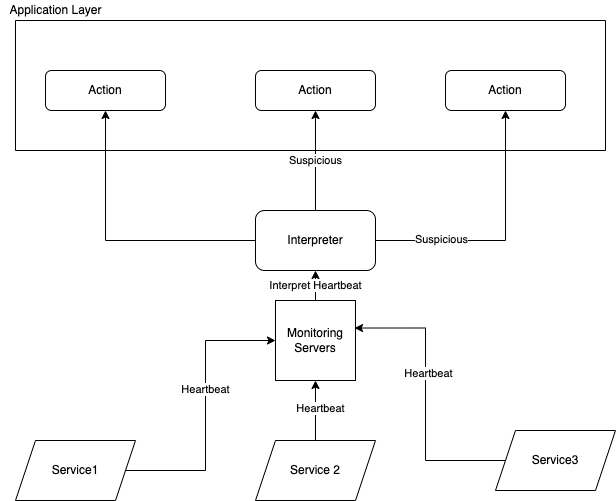
Централизованный способ заключается в размещении интерпретатора и монитора в качестве самостоятельного блока. В таком случае система сама интерпретирует каждый узел и отправляет сигнал другим узлам для дальнейших действий. Результат будет выражен булевым значением, характеризующим, подозрителен узел или нет.
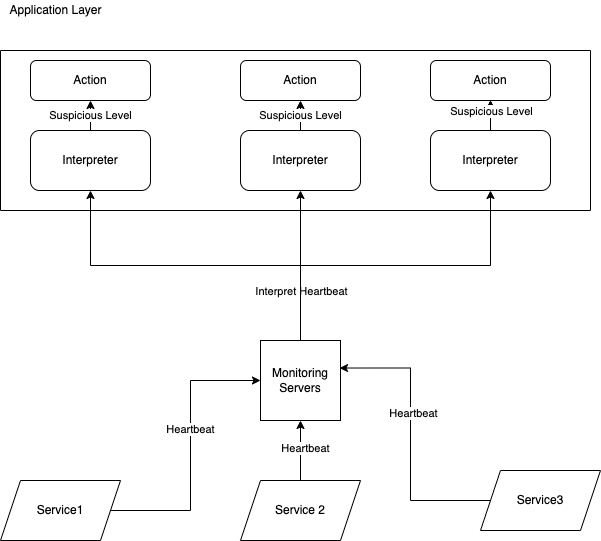
Распределенный способ заключается в размещении интерпретатора на каждом уровне приложения, что позволяет приложению свободно настраивать уровень подозрительности и действия, которые должны выполняться при каждом уровне подозрительности.
Преимущество централизованного способа в том, что он упрощает управление узлами. Распределенный способ позволяет точно настроить или оптимизировать каждый узел, чтобы узлы вели себя по-разному в зависимости от уровня подозрительности.
Мы можем использовать отказ узла с накоплением Phi для интерпретатора, рассмотренного в предыдущем разделе. Мы устанавливаем пороговое значение phi — и, если результат phi выше порогового значения, мы объявляем удаленный узел мертвым. Если результат phi ниже порогового значения, это значит, что удаленный узел доступен.
Пока монитор отправляет запрос на удаленный узел, интерпретатор начинает отсчитывать время ответа. Если требуемое для ответа время превышает пороговое значение, интерпретатор может остановить запрос и объявить данный узел подозрительным.
Выводы
Мы никогда не задумываемся об обнаружении отказов узлов, занимаясь проектированием приложения, потому что эта возможность встроена в функционал любого облачного провайдера. Однако обнаружение такого узла — это не такая уж и простая операция. Одна из причин — модель неразделяемого состояния в распределенных системах. Инженерам приходится проектировать надежную систему в ненадежной сети.
В большинстве случаев, выявляя отказы узлов, приходится действовать методом проб и ошибок. Однако можно не ограничиваться булевыми значениями, выясняя, мертв ли узел, а зайти со стороны изменчивости — воспользоваться распределенной дисперсией, определяя, когда узел выходит из строя. Для этого применяется алгоритм обнаружения сбоев с накоплением Phi и устанавливается пороговая длительность времени ожидания.
Наконец, абстрактная схема для обнаружения отказа узла может в общем виде состоять из монитора и интерпретатора. Монитор будет постоянно пинговать удаленные узлы и сообщать время ответа интерпретатору, чтобы система могла проанализировать, насколько подозрителен данный узел. Если узел достигает определенного порогового уровня подозрительности, интерпретатор возвращает соответствующее булево значение сервису вызова узлов, тем самым сигнализируя, что необходимы дополнительные действия.
