Сайзинг Elasticsearch
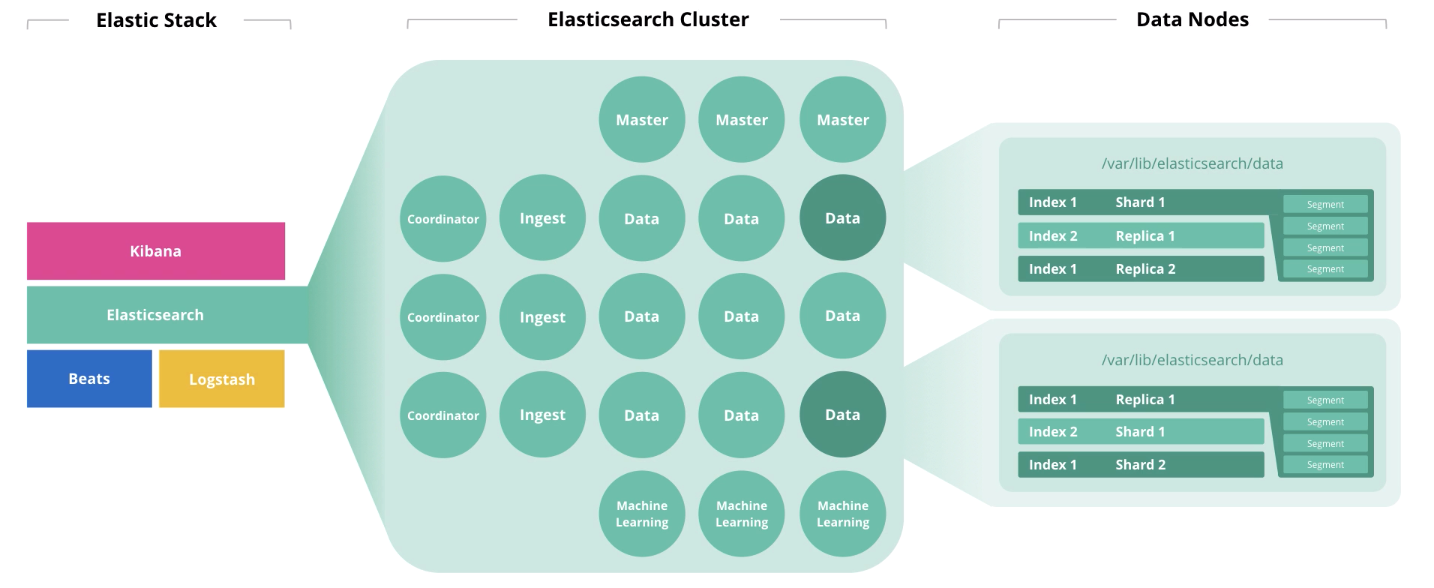
— How big a cluster do I need?
— Well, it depends… (злобное хихиканье)
Elasticsearch — сердце Elastic Stack, в котором происходит вся магия с документами: выдача, приём, обработка и хранение. От правильного количества нод и архитектуры решения зависит его производительность. И цена, кстати, тоже, если ваша подписка Gold или Platinum.
Основные характеристики аппаратного обеспечения — это диск (storage), память (memory), процессоры (compute) и сеть (network). Каждый из этих компонентов в ответе за действие, которое Elasticsearch выполняет над документами, это, соответственно, хранение, чтение, вычисления и приём/передача. Поговорим об общих принципах сайзинга и раскроем то самое «it depends». А в конце статьи ссылки на вебинары и статьи по теме. Поехали!
Эта статья основана на материалах вебинара Дэвида Мура «Sizing and Capacity Planning». Его рассуждения мы дополнили ссылками и комментариями, чтобы было чуть понятнее. В конце статьи бонус-трек — ссылки на материалы Elastic для тех, кто хочет лучше погрузиться в тему. Если у вас хороший опыт работы с Elasticsearch, пожалуйста, поделитесь в комментариях как проектируете кластер. Нам и всем коллегам было бы интересно узнать ваше мнение.
В начале статьи мы говорили про 4 компонента, формирующие аппаратное обеспечение: диск, память, процессоры и сеть. На утилизацию каждого из этих компонентов влияет роль ноды. Одна нода может выполнять сразу несколько ролей, но с ростом кластера, эти роли должны быть распределены по разным нодам.
Master-ноды выполняют контроль за работоспособностью кластера в целом. В работе master-нод должен соблюдаться кворум, т.е. их количество должно быть нечётным (может быть 1, но лучше 3).
Data-ноды выполняют функции хранения. Для повышение производительности кластера, ноды нужно разделить на «горячие» (hot), «тёплые» (warm) и «холодные» (frozen). Первые предназначены для оперативного доступа, вторые для хранения, а третьи для архива. Соответственно, для «горячих» разумно использование локальных SSD-дисков, а для «тёплых» и «холодных» подойдёт массив HDD локально или в SAN.
Для определения объёма памяти нод для хранения, Elastic рекомендует пользоваться следующей логикой: «горячие» → 1:30 (30Гб дискового пространства на каждый гигабайт памяти), «тёплые» → 1:100, «холодные» → 1:500). Под JVM Heap не более 50% общего объёма памяти и не более 30Гб во избежание набега garbage collector. Оставшаяся память будет использована как кэш операционной системы.
На утилизацию ядер процессоров в большей степени влияют такие показатели производительности инстанса Elastisearch как thread pools и thread queues. Первые формируются на основе тех действий, которые выполняет нода: search, analyze, write и другие. Вторые являются очередью из соответствующих запросов различных типов. Количество доступных для использования процессоров Elasticsearch определяет автоматически, но в настройках можно указать это значение вручную (может быть полезно когда у вас на одном хосте запущено 2 и более инстанса Elasticsearch). Максимальное количество thread pools и thread queues каждого типа можно задать в настройках. Показатель thread pools — это основной показатель производительности Elasticsearch.
Ingest-ноды принимают на вход данные от сборщиков (Logstash, Beats и т.д.), выполняют преобразования над ними и записывают в целевой индекс.
Ноды Machine learning предназначены для анализа данных. Как мы писали в статье о машинном обучении в Elastic Stack, механизм написан на С++ и работает за пределами JVM, в которой крутится сам Elasticsearch, поэтому разумно выполнять такую аналитику на отдельной ноде.
Coordinator-ноды принимают поисковый запрос и маршрутизируют его. Наличие такого типа нод ускоряет обработку поисковых запросов.
Если рассматривать нагрузку на ноды в разрезе инфраструктурных мощностей, распределение будет примерно таким:
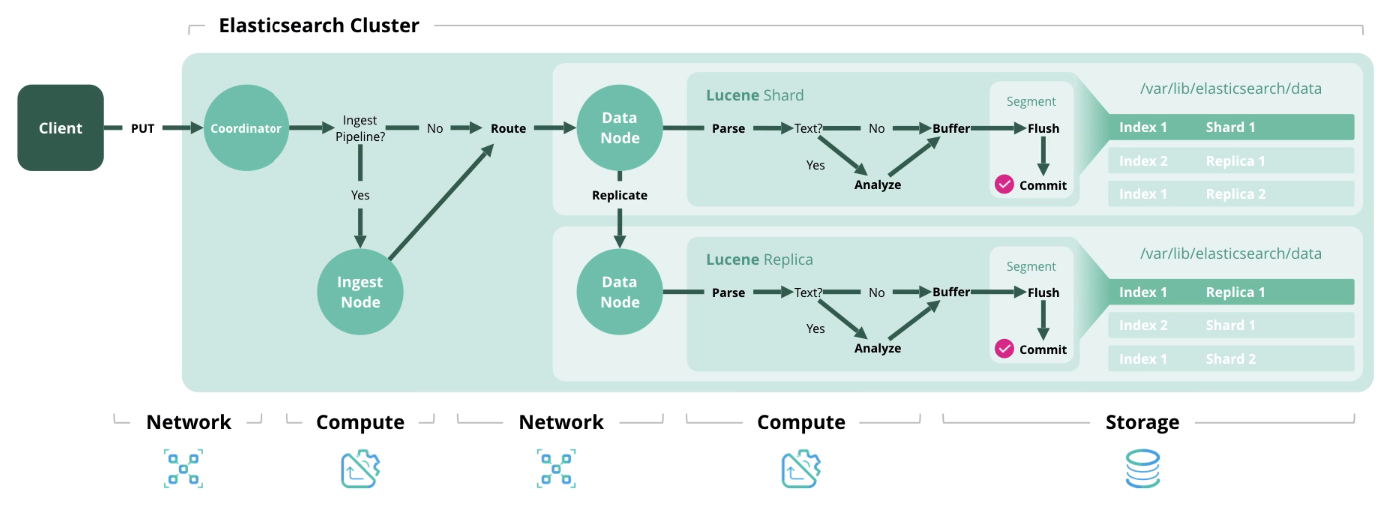
Дальше мы приведём 4 основных типа операций в Elasticsearch, каждая из которых требует определённого типа ресурсов.
Index — обработка и сохранение документа в индексе. На схеме ниже представлены ресурсы, используемые на каждом из этапов.
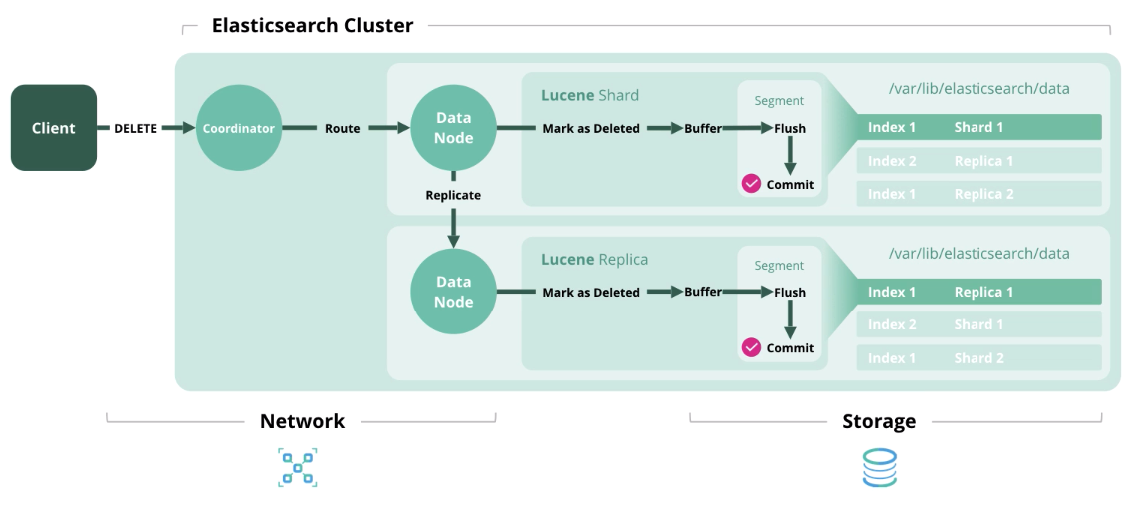
Delete — удаление документа из индекса.
Update — работает как Index и Delete, потому что документы в Elasticsearch неизменны.
Search — получение одного или более документов или их агрегация из одного или более индексов.
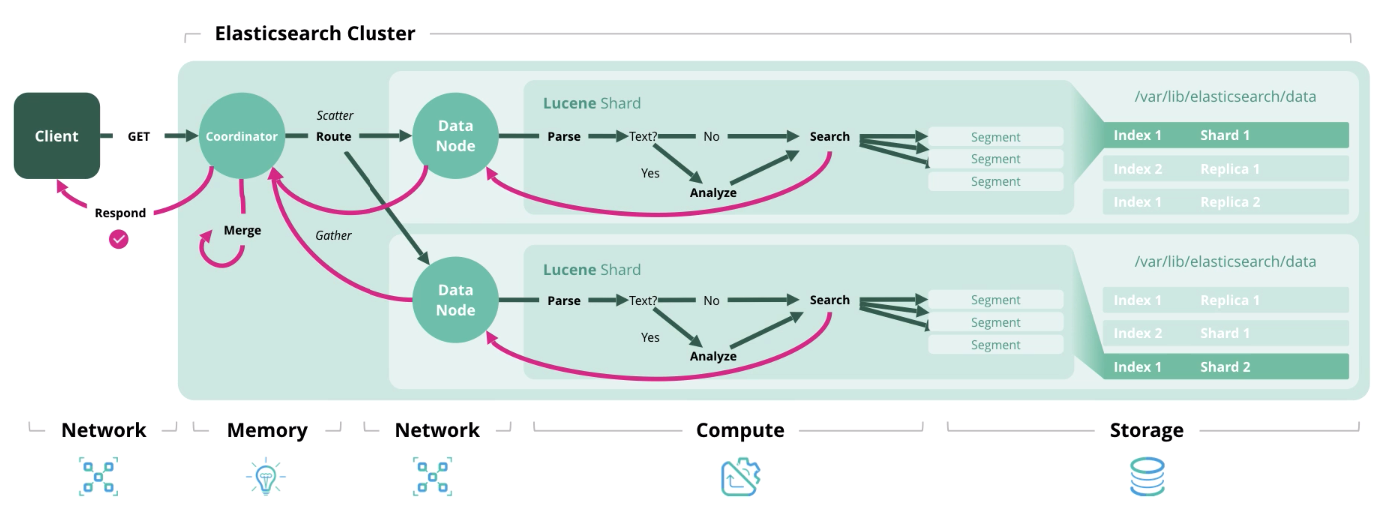
С архитектурой и типами нагрузки разобрались, теперь перейдём к формированию модели сайзинга.
Elastic рекомендует использовать две стратегии сайзинга: ориентированную на объём хранения и на пропускную способность. В первом случае первостепенное значение приобретают дисковые ресурсы и память, а во втором память, процессорная мощность и сеть.
Сайзинг архитектуры Elasticsearch в зависимости от объема хранения
Перед проведением расчётов получим исходные данные. Нужно:
- Объём сырых данных в день;
- Период хранения данных в днях;
- Фактор трансформации данных (json factor + indexing factor + compression factor);
- Количество шард репликации;
- Объём памяти дата-ноды;
- Соотношение памяти к данным (1:30, 1: 100 и т.д.).
К сожалению, фактор изменения данных вычисляется только опытным путём и зависит от разных вещеё: формата сырых данных, количества полей в документах и т.д. Чтобы это выяснить, нужно загрузить в индекс порцию тестовых данных. На тему таких тестов есть интересное видео с конференции и дискуссия в коммьюнити Elastic. В общем случае можно оставлять его равным 1.
По умолчанию, Elasticsearch сжимает данные по алгоритму LZ4, но есть и DEFLATE, который жмёт на 15% сильнее. В общем можно добиться сжатия 20–30%, но это тоже вычисляется опытным путём. При переключении на алгоритм DEFLATE возрастает нагрузка на вычислительные мощности.
Ещё есть дополнительные рекомендации:
- Заложить 15%, чтобы был запас по дисковому пространству;
- Заложить 5% на дополнительные нужды;
- Заложить 1 эквивалент ноды с данными для обеспечения быстрой миграции.
А теперь переходим к формулам. Ничего сложного тут нет, и, думаем, вам будет интересно проверить ваш кластер на соответствие этим рекомендациям.
Общее количество данных (Гб) = Сырые данные в день * Количество дней хранения * фактор увеличения данных * (количество реплик — 1)
Общее хранилище данных (Гб) = Общее количество данных (Гб) *(1 + 0,15 запаса + 0,05 дополнительные нужды)
Общее количество нод = ОКРВВЕРХ (Общее хранилище данных (Гб) / Объём памяти на ноду / соотношение памяти к данных + 1 эквивалент ноды данных)
Сайзинг архитектуры Elasticsearch для определения количества шард и нод данных в зависимости от объёма хранения
Перед проведением расчётов получим исходные данные. Нужно:
- Количество index patterns вы создадите;
- Количество основных шард и реплик;
- Через сколько дней будет выполняться ротация индексов, если вообще будет;
- Количество дней хранения индексов;
- Объём памяти на каждую ноду.
Ещё есть дополнительные рекомендации:
- Не превышайте 20 шард на 1 Гб JVM Heap на каждой ноде;
- Не превышайте объема дискового пространства шарды в 40 Гб.
Формулы выглядят следующим образов:
Количество шард = Количество index patterns * Количество основных шард * (Количество реплицированных шард + 1)* количество дней хранения
Количество нод данных = ОКРВВЕРХ (Количество шард / (20 * Память на каждую ноду))
Сайзинг архитектуры Elasticsearch в зависимости от пропускной способности
Самый частый случай, когда нужна высокая пропускная способность —это частые и в большом количестве поисковые запросы.
Необходимые исходные данные для расчёта:
- Пиковое количество поисковых запросов в секунду;
- Среднее допустимое время ответа в миллисекундах;
- Количество ядер и threads на процессорное ядро на нодах с данными.
Пиковое значение тредов = ОКРВВЕРХ (пиковое количество поисковых запросов в секунду * среднее количество время ответа на поисковый запрос в миллисекундах / 1000 миллисекунд)
Объём thread pool = ОКРВВЕРХ ((количество физических ядер на ноду * количество threads на ядро * 3 / 2) +1)
Количество нод данных = ОКРВВЕРХ (Пиковое значение тредов / Объём thread pool)
Возможно, не все исходные данные будут у вас на руках при проектировании архитектуры, но посмотрев вебинар или прочитав эту статью появится понимание, что в принципе влияет на количество аппаратных ресурсов.
Обращаем ваше внимание, что не обязательно придерживаться приведённой архитектуры (например, создавать ноды-координаторы и ноды-обработчики). Достаточно знать, что такая эталонная архитектура существует и она может дать прирост производительности, которого вы не могли добиться другими средствами.
В одной из следующих статей мы опубликуем полный список вопросов, на которые нужно получить ответы для определения размера кластера.
Для связи с нами можно использовать личные сообщения на Хабре или форму обратной связи на сайте.
Дололнительные материалы
Вебинар «Elasticsearch sizing and capacity planning»
Вебинар о планировании мощностей Elasticsearch
Выступление на ElasticON с темой «Quantitative Cluster Sizing»
Вебинар про утилиту Rally для определения показателей производительности кластера
Статья о сайзинге Elasticsearch
Вебинар об архитектуре Elastic stack
