Происхождение и эволюция аллокатора памяти в С
Подсистема памяти — это часть т.н. C Runtime или CRT, отвечающая за работу с памятью. Библиотека CRT служит посредником между прикладной программой и ядром операционной системы. Соответственно, её внешним интерфейсом является «стандартная библиотека С», внутренний интерфейс специфичен для конкретной ОС.
А почему нельзя доверить выделение памяти ОС, у неё и аппаратная поддержка есть? Причин несколько
с точки зрения программиста, работа с памятью заключена в системной библиотеке (msvcrt*.dll в Windows, libc.so.* под linux). Возможность подключать разные реализации аллокатора создаёт полезную гибкость в разработке.
делегирование работы с памятью ядру приведёт к тому, что каждый вызов malloc\free станет системным и потребует переключения в защищённый режим с соответствующими издержками (сотни тактов). Кроме того, за доступ к ядру начнут конкурировать все процессы в системе, ведь некоторые действия требуют атомарности на уровне системы, а некоторые просто дороги, ex: редактирование page table, чистка TLB при необходимости.
за блоками меньше размера страницы виртуальной памяти к ОС ходить не стоит, т.е. кто-то их всё равно должен агрегировать и раздавать
ОС не будет собирать для вас статистику и предугадывать поведение.
никакого (в том числе внутри-поточного (TLS)) кэширования
…
Но мы забежали вперёд, давайте начнём с самого начала.
PDP-11, на котором, собственно появились и UNIX и C (строго говоря, началось всё с PDP-7, но это был еще не совсем C), 16-разрядная система, адресное пространство процесса ограничивалось 64 килобайтами. Это пространство разбито на 8 «сегментов», которые отражались в физическую память.
Как минимум один сегмент принадлежал ОС, хотя бы просто для того, чтобы была возможность делать системные вызовы. Остальное адресное пространство выглядело как-то так:
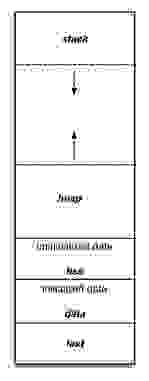 Фиг.1 упрощенное представление о памяти,
используемой программой.
Фиг.1 упрощенное представление о памяти,
используемой программой.
Несколько секций фиксированного размера и две динамические — стек и куча/heap, растущие навстречу друг другу. Такая архитектура позволяет балансировать нагрузку (задействовать ровно столько сегментов, сколько необходимо) на адресное пространство для самых разных программ — и тех, которым требуется много динамической памяти и тех, что работают преимущественно со стеком.
Что касается именно подсистемы памяти в C, к ней давно и прочно прилипло название куча (heap). Название это по-видимому восходит к одноименной структуре данных. Структура эта была представлена в 1964 г. в составе алгоритма heapsort (алгоритм 232). К 1969–1970 гг, которые можно считать началом C, название куча/heap было вполне устоявшимся и распространённым. Хотя, явного использования алгоритма кучи в стандартном аллокаторе нет.
Для расширения доступного пространства данных в C были введены (ныне изрядно устаревшие) системные функции brk & sbrk, которые позволяли программно управлять границей heap-а.
Алгоритмы.
Изначальный алгоритм раздачи памяти в С использовал стратегию first-fit, т.е. «отдаём первый попавшийся пригодный блок».
При таком скромном адресном пространстве во главе всего стоят компактность и простота. Аллокатор реализован как однонаправленный кольцевой список — самое простое и компактное, что только может быть.
Список отсортирован по адресам и включает в себя все блоки — и свободные и занятые.
Поскольку в интерфейсе функции free единственный аргумент — указатель, длина освобождаемого блока должна быть где-то рядом с самим блоком. Хранится она неявно — как разница адресов текущего блока и указателя на следующий, смежный блок. Длина указателя — 2 байта и расположен он непосредственно перед клиентскими данными, указатель на которые возвращает malloc.
Поскольку блоки выровнены как минимум по 2 байта, младший разряд указателя всегда нулевой и его используют для записи флага, свободен блок или нет.
Аллокатор содержит т.н.»блуждающий» (roving) указатель, который глядит на (или за) блок, с которым работали в прошлый раз — освобождали или выделяли.
при старте программы
создаём сегмент данных некоторого стандартного размера
собственно аллокатор содержит — размер, сколько свободно, блуждающий указатель смотрит на на первый свободный блок.
создаём единственный свободный блок размером в сегмент данных
при вызове malloc
стартуем с блуждающего указателя
бежим по списку, пока не найдём свободный блок подходящего размера, возможно, это блок заметно большего размера, откусим от него сколько надо с формированием двух блоков
при движении по списку, сливаем идущие подряд неподходящие (слишком мелкие) свободные блоки.
если не нашли, вызываем sbrk, чтобы расширить сегмент данных, добавляем новый свободный блок, предварительно откусив от него сколько надо
возвращаем результат, сдвинутый на 2 байта вперед, не забыв пометить его как занятый и прописать указатель на следующий блок в эти самые два байта
блуждающий указатель теперь смотрит на блок, следующий за только что выделенным
при вызове free
Обратим внимание, что free не пытается объединять соседние свободные блоки, этим занимается malloc. Что касается левого (от освобождаемого) блока, мы просто не знаем его размер в силу однонаправленности списка блоков, чтобы найти его начало, придётся просмотреть весь (ну, хорошо, его половину) список. Насчет правого тоже переживать не стоит, поскольку блуждающий указатель теперь смотрит на свеже-освобожденный блок, их по возможности сольёт следующий вызов malloc.
Причем здесь «heap»? Можно только догадываться. Не исключено, кстати, что название «куча/heap» прицепилось к аллокатору позже во время многочисленных экспериментов.
Такая незатейливая структура, как ни странно, оказалась довольно живучей. Д.Корн (David Korn) в 1985 на конференции USENIX говорит о ней как о всё еще распространённой. Проблем две — невысокая производительность и внешняя фрагментация. Быстро накапливаются мелкие свободные блоки, при этом при формально большом количестве свободной памяти сколь-нибудь большой кусок выделить невозможно — просто нет такой непрерывной свободной области. Слияние блоков во время malloc недостаточно эффективно.
 Фиг.2 типичная фрагментированная карта памяти, Д.Кнут, И.П., т.1, гл. 2.5
Фиг.2 типичная фрагментированная карта памяти, Д.Кнут, И.П., т.1, гл. 2.5
Согласно Д.Кнуту, возможны два принципиально разных, ортогональных, если угодно, аллокатора, пригодных для стабильной долговременной работы. Стоит отметить, что Д.Кнут работал с более тяжелыми по сравнению с PDP-11 системами и отношение к аллокаторам у него более требовательное. В описанных им аллокаторах слияние свободных блоков происходит непосредственно при освобождении памяти. Проблемы тут две — как узнать что соседний блок (или блоки) свободен и как узнать длину соседнего блока.
Алгоритм двойных меток
Алгоритм двойных меток (метод граничного дескриптора) разработан Д.Кнутом в 1962 при работе над Burroughs 5000 (Д.Кнут, И.П., т.1, гл. 2.6).
На границе между блоками находится т.н. дескриптор. В нём записана информация об обоих смежных блоках — и их длины и их статус (занято/свободно).
В результате при освобождении блока по границам пользовательских данных есть полная информация о соседях, при возможности блоки сливаются.
Еще одно усовершенствование — двунаправленный список свободных страниц, при этом размещаться указатели будут в теле блока на месте бывших пользовательских данных. Это позволит очень быстро удалять блок из списка свободных, не нужно просматривать в среднем половину списка. Но минимальный размер блока теперь — два слова.
Алгоритм двойников / близнецов
Алгоритм двойников / близнецов (buddy allocator) открыт в 1963 Г.Марковицем (H.Markowitz), открыт заново и опубликован в 1965 (CACM 8, 1965, 623…625) К.Ноултоном (K.Knowlton).
все выделяемые блоки имеют размер в степень двойки, 4, 8, 16, 32, … байт
размер изначального единого свободного блока (при старте программы) тоже равен степени 2
свободные блоки одного размера объединены в двунаправленный список
когда требуется выделить блок размера S
находим минимальную степень 2 больше S
проверяем наличие свободных страниц такого размера, отдаём если есть
если нет, находим минимальный блок большего размера и рекурсивно расщепляем его до нужного размера. Получившиеся «обрезки» пополняют списки свободных блоков.
при освобождении блока
находим размер блока
проверяем, свободен ли второй блок (buddy) и если свободен, объединяем их и рекурсивно проверяем вышестоящий (уже объединённый) блок.
размер и флаг занятости можно хранить в начале блока, как и в вышеописанном алгоритме, возможны и другие варианты
Размер соседнего блока (двойника, buddy) всегда равен размеру освобождаемого. Причем сосед только один (слева или справа, согласно алгоритму выделения), его адрес легко установить из значения указателя текущего блока и его размера.
Алгоритм двойников потребляет в среднем больше памяти (т.н. внутренняя фрагментация за счет округления размера до степени двойки), но мистическим образом не подвержен внешней фрагментации.
По мере «взросления» UNIX/C, развития аппаратных возможностей и клиентских требований возникла потребность в более производительных и устойчивых алгоритмах раздачи памяти. Было разработано и испытано огромное их количество, вот некоторые из упоминавшегося доклада Д.Корра:
first-fit с free-list, BSD 4.1 (1981). Развитие стандартного first-fit, отличается наличием дополнительного отсортированного по адресам однонаправленного циклического списка свободных блоков. Блуждающий указатель ходит только по свободным блокам. Слияние страниц происходит во время освобождения памяти.
недо-buddy аллокатор, BSD 4.2 (1983), написан Крисом Кингсли (Chris Kingsley) из CalTech. Аллокатор состоит из набора двунаправленных списков — на каждую степень двойки размера выделяемых блоков. При выделении памяти размер всегда округляется до ближайшей степени двойки, но не делается попыток сливать блоки. Исключительно быстрый, но потребляющий память вдвое больше конкурентов, по-видимому из-за издержек на маленьких блоках.
first-fit с двунаправленным free-list, SYS V r2 (1984). Список свободных блоков двунаправленный и не сортированный. Двухступенчатая аллокация мелких блоков — выделение происходит пачками, внутри пачки — битовыми масками. При освобождении памяти происходит слияние с правыми соседями, при malloc — всё что найдётся. Для управления пачками мелких блоков хорошо подойдёт куча/heap — как раз востребована операция «дай пачку с минимальным адресом» за константное время.
first-fit со сбалансированным деревом свободных блоков, ключ — адрес. Структуры самого дерева расположены в пользовательском пространстве блока.
better-fit c декартовым деревом свободных блоков. Ключ дерева — адрес, размер (остроумно, не правда ли). Декартово дерево, кстати, ведёт себя и как дерево и как куча/heap.
best-fit со сбалансированным деревом свободных блоков, ключ — размер, поиск в дереве приводит к списку свободных блоков заданного размера
множественные списки свободных блоков, размеры блоков делятся на диапазоны в соответствии с числами Фибоначчи, внутри каждого диапазона алгоритм аналогичен first-fit с двунаправленным free-list. Если не удался поиск, берется следующий диапазон, если диапазоны кончились, sbrk.
Здесь заложена вот какая идея. Элемент ряда Фибоначчи равен сумме двух своих предшественников — 1,2,3,5,8,13,21,34,55,89,144… Алгоритм аналогичен методу близнецов, но участок делится не пополам, а так, что длины двух под-интервалов являются предыдущими элементами ряда. Для этого, очевидно, изначальный размер выделенного ОС блока памяти должен входить в ряд Фибоначчи. Как и в случае метода двойников, имея указатель и его сдвиг от начала исходного блока можно вычислить размер освобождаемого блока, а также размеры его соседа (buddy) и слиться с ним по возможности.
Ожидалось, что такое деление приведёт к меньшей внутренней фрагментации по сравнению с методом двойников при аналогичной внешней. Так оно и есть в модели, когда выделяются и освобождаются блоки случайной длины. Увы, в жизни эти размеры далеки от равномерного (или нормального, не столь важно) распределения и данный метод приводит к избыточной внешней фрагментации. Например, если программа массово просит блоки размером 20 байт, алгоритм будет выделять ей куски по 21 байт, но при этом станут накапливаться и участки размером 13 байт у которых нет шансов быть использованными.
…
Освобождение памяти.
Следует различать освобождение памяти программой и аллокатором. Суть аллокатора в получении больших кусков памяти из ОС и «раздаче» всем желающим. Когда программа вызывает free, освобождаемый блок всего-лишь помечается как свободный. Если повезёт, этот блок будет объединён с одним из своих так же свободных соседей. Если очень повезёт, то с обоими.
Возможно, при этом образуется значительный участок свободной памяти (как минимум, несколько страниц), который можно отдать системе т.е. перевести эти страницы из состояния COMMITED в RESERVED. В этом состоянии страницы по крайней мере не будут подвержены подкачке.
Ситуация, когда весь исходный кусок памяти, который аллокатор выпросил у системы оказался свободным и может быть отдан обратно ОС возможна, хотя и не очень вероятна.
В этом случае все страницы области, будут переведены в состояние FREE, т.е. выведены из виртуальной памяти процесса.
Стоит отметить, что сказанное выше в данном разделе касается небольших блоков памяти потому что блоки значительного размера аллокатор зачастую выпрашивает у системы напрямую и так же может их сразу освобождать.
Впрочем, во времена, когда sbrk была настоящей функцией, меняющей размер кучи, а не заглушкой, всё было тоже довольно печально. Чтобы аллокатор мог отдать память в ОС, т.е. вызвать sbrk с отрицательным параметром, свободный блок заметного размера должен был оказаться в самом конце списка блоков памяти, на границе кучи.
Итого
Что же мы имеем на сегодняшний момент. Прежде чем отвечать на этот вопрос, стоит разобраться, а какие изменения произошли за истёкший период, т.к. если условия не изменились, то и новых идей ожидать не стоит, учитывая, какие умы трудились над задачей.
изрядно выросла производительность компьютеров, это позволяет использовать достаточно дорогостоящие алгоритмы.
повсеместно распространённая многопоточность (multithreading), если раньше работа программы шла в единственном потоке (коим был процесс), сейчас их десятки, иногда сотни.
на 4–5 порядков выросли объемы располагаемой памяти, простым циклом её не обойти
виртуальная память стала сначала 32, а затем 64-разрядной. Можно создать сегмент (ы) любого (в пределах разумного) размера, для этого даже не надо сдвигать границу существующего через sbrk.
аппаратная поддержка атомарных операций с памятью, позволяющая в определенных случаев обойтись без жесткой синхронизации. Впрочем, это скорее из разряда оптимизации.
Неоднородная память (NUMA). В такого рода системах процессоры объединены в группы (узлы, ноды), в каждой группе есть своя память, обращения к которой быстры, как в обычном компьютере. Но обращение к памяти из чужой ноды в разы дороже. В результате ОС старается запускать потоки (threads) как минимум в той же ноде, что и перед вытеснением. Соответственно, и память лучше выделять в той же ноде.
Есть и встречное движение со стороны ОС. Вот, например, патч в ядро linux балансировщика памяти NUMA, который время от времени просматривает список затребованных процессом страниц и переносит их физически в ноду поближе.
Итак, что мы увидим, если заглянем «под капот» более менее современным malloc-у от glibc и/или mi-malloc-у от Microsoft?
Адаптивность. Аллокатор собирает статистику работы с памятью по каждому потоку и исходя из нее предсказывает поведение в будущем.
Расщепление (sharding). Поскольку потоков (threads) теперь несколько, работа с кучей требует синхронизации. Когда потоков много, возникает узкое место, где они «толкаются локтями». В современных аллокаторах куч несколько и разные потоки (по возможности) работают с разными кучами.
По-поточное кэширование. Основываясь на собранной статистике, аллокатор предполагает сколько блоков какого размера следует держать под рукой для каждого потока. Для обращения к такому кэшу не нужна синхронизация (TLS).
Крупные блоки (> 128K glibc) аллокаторы предпочитают брать не из кучи, а выпрашивать отдельно у операционной системы (mmap, MapViewOfFile). Это помогает бороться с фрагментацией, ведь если такой блок выделить из кучи, то при освобождении он очень быстро будет разобран на маленькие блоки и когда еще раз потребуется блок такого размера, его придётся выделять заново. В результате занятое процессом адресное пространство растёт, а его утилизация (КПД) снижается. Это выгодно еще и потому, что некоторые архитектуры допускают физические размеры разного размера, например, x86–64: 4 килобайта и 2 мегабайта (+1 гигабайт). Может оказаться полезным выделять большие объемы большими страницами.
Конструкция собственно кучи принципиально не отличается от описанных выше
двухуровневое выделение памяти — мелкие блоки берутся из агрегирующих блоков, сами эти блоки и просто блоки побольше — из кучи
свободные блоки «популярных» размеров имеют выделенные списки
списки свободных блоков для других размеров имеют древовидную структуру
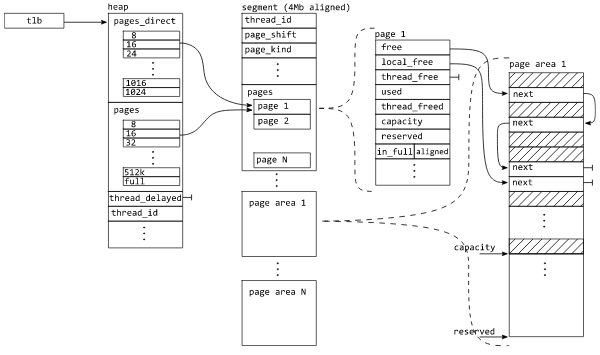 Фиг.3 общее устройство кучи в mi-malloc
Фиг.3 общее устройство кучи в mi-malloc
Чем же приходится платить за все эти нововведения?
Отметим, что в массе своей они имеют эвристическую природу. Эвристика подразумевает сценарии, в которых она ошибается. В этих случаях эвристика играет против программы. Как это происходит на практике?
Кэширование блоков популярных размеров обычно даёт неплохой эффект. Но с другой стороны, блоки, которые «зависли» в локальном кэше увеличивают тенденцию к фрагментации памяти.
Вы освободили всю память, которую ранее выделили, но она не вернулась в ОС? Придётся подождать, пока CRT адаптируется к новой ситуации.
Программа занимается однотипной работой, освобождает всю память, которую выделяет, но использованная виртуальная память растёт и не имеет чёткой тенденции к насыщению? Надо немного потерпеть, вдруг всё обойдётся.
Справедливости ради, современные раздатчики памяти демонстрируют значительный прогресс. Но если вы хотите контролировать поведение вашей программы, хорошо бы отдавать себе отчет как, для чего и каким образом выделяется память. Впрочем, это уже совсем другая история.
PS Титульная картинка взята отсюда.
PPS Спасибо @Dmitriaза помощь в подготовке, не поленитесь отсыпать ему кармы.
