PostgreSQL Antipatterns: в этом плане кто-то лишний
 Должен остаться только один!
Должен остаться только один!
Сегодня будет рассказ про избыточные группировки и сортировки в SQL-запросах — как они возникают, по каким признакам их можно потом вычислить и как избавиться от них.
Aggregate
Недавно на глаза попался примерно вот такой запрос:
SELECT
k
-- тут несколько выражений по 5-10 строк
, sum(s / q) v
FROM
(
SELECT
CASE
WHEN i % 5 = 0 THEN 5
WHEN i % 3 = 0 THEN 3
WHEN i % 2 = 0 THEN 2
ELSE 1
END k
-- тут десятки полей
, sum(i) s
, count(i) q
FROM
generate_series(1, 1e6) i
GROUP BY
k
) T
GROUP BY
1;Очевидно, что в ходе постепенного усложнения запроса (а я уже рассказывал в «PostgreSQL Antipatterns: сказ об итеративной доработке поиска по названию, или «Оптимизация туда и обратно», что при этом может происходить) вслед за одной группировкой пришла другая, и визуально их не особо многое связывает — в одном случае это ключ k, а в другом… тот же самый ключ, который стоит у нас в позиции номер 1!
Даже если мы посмотрим на план этого упрощенного запроса, то понять, что сортировка на самом-то деле одна и та же — будет затруднительно:
HashAggregate (actual time=1240.398..1240.400 rows=4 loops=1)
Group Key: (CASE WHEN ((i.i % '5'::numeric) = '0'::numeric) THEN 5 WHEN ((i.i % '3'::numeric) = '0'::numeric) THEN 3 WHEN ((i.i % '2'::numeric) = '0'::numeric) THEN 2 ELSE 1 END)
-> HashAggregate (actual time=1240.383..1240.386 rows=4 loops=1)
Group Key: CASE WHEN ((i.i % '5'::numeric) = '0'::numeric) THEN 5 WHEN ((i.i % '3'::numeric) = '0'::numeric) THEN 3 WHEN ((i.i % '2'::numeric) = '0'::numeric) THEN 2 ELSE 1 END
-> Function Scan on generate_series i (actual time=183.734..998.200 rows=1000000 loops=1)
Planning Time: 0.122 ms
Execution Time: 1252.607 msНо для этого у нас есть визуализация этого плана на explain.tensor.ru, который подскажет, что повторная группировка идет по тому же ключу:
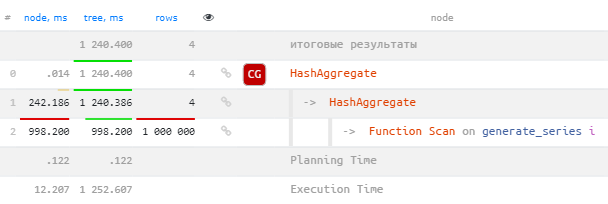 Клонированная группировка
Клонированная группировка
Если результирующих записей не слишком много, то повторная группировка не будет слишком дорогой. Но если вы запускаете какой-то большой аналитический отчет — будет ой…
Исправим, избавившись от повторной сортировки:
SELECT
CASE
WHEN i % 5 = 0 THEN 5
WHEN i % 3 = 0 THEN 3
WHEN i % 2 = 0 THEN 2
ELSE 1
END k
, sum(i) / count(i) v
FROM
generate_series(1, 1e6) i
GROUP BY
k;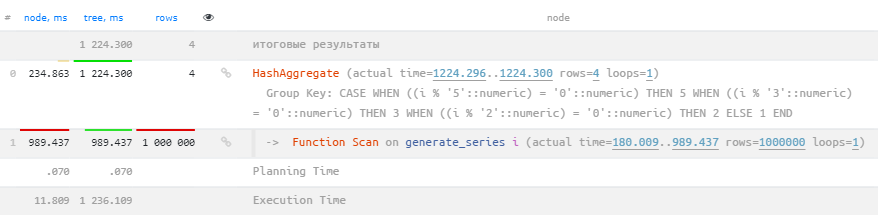 Сэкономлена одна группировка и немного времени
Сэкономлена одна группировка и немного времени
Sort
Судьба повторных сортировок развивается обычно точно так же — отлаживали, да недочистили:
SELECT
i
, 1e6 - i
FROM
(
SELECT
*
FROM
generate_series(1, 1e6) i
WHERE
(i % 2, i % 3, i % 5, i % 7) = (1, 2, 4, 6)
ORDER BY -- осталось от отладки
i DESC
) T
ORDER BY
1;Sort (actual time=765.072..765.245 rows=4761 loops=1)
Sort Key: t.i
Sort Method: quicksort Memory: 416kB
-> Subquery Scan on t (actual time=761.475..763.069 rows=4761 loops=1)
-> Sort (actual time=761.471..761.739 rows=4761 loops=1)
Sort Key: i.i DESC
Sort Method: quicksort Memory: 416kB
-> Function Scan on generate_series i (actual time=187.029..759.222 rows=4761 loops=1)
Filter: (((i % '2'::numeric) = '1'::numeric) AND ((i % '3'::numeric) = '2'::numeric) AND ((i % '5'::numeric) = '4'::numeric) AND ((i % '7'::numeric) = '6'::numeric))"
Rows Removed by Filter: 995239
Planning Time: 0.109 ms
Execution Time: 777.414 msПро разные причины их возникновения и способы избавиться от них я подробно тоже уже рассказывал в статье «PostgreSQL Antipatterns: убираем медленные и ненужные сортировки». К сожалению, не для всех из них можно однозначно рекомендовать какой-то способ исправления, но иногда — можно.
В отличие от группировки, где совпадение Group Key обязательно для наших «подозреваемых», в сортировке Sort Key могут быть разными, но сами Sort-узлы должны идти или сразу друг за другом, или могут быть разделены Subquery Scan, как в этом случае.
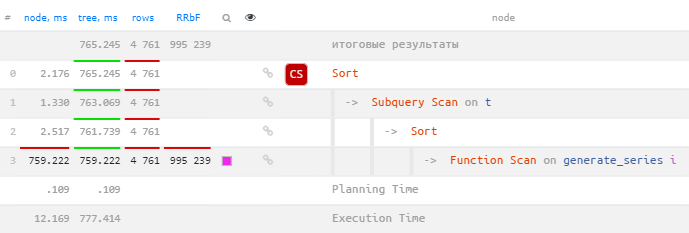 Повторная сортировка
Повторная сортировка
Исправление очевидно — убрать бесполезную внутреннюю сортировку:
SELECT
i
, 1e6 - i
FROM
(
SELECT
*
FROM
generate_series(1, 1e6) i
WHERE
(i % 2, i % 3, i % 5, i % 7) = (1, 2, 4, 6)
) T
ORDER BY
1; Сэкономили сортировку и Subquery Scan
Сэкономили сортировку и Subquery Scan
Группировки и сортировки — не единственные узлы в плане, которые могут бесполезно повторяться — иногда это происходит даже с целыми сегментами плана. Подробнее читайте в «PostgreSQL Antipatterns: «где-то я тебя уже видел…».
Знаете еще какие-то неочевидные «грабли» — расскажите в комментариях.
