DevOps и Value of User: новая культура взаимодействия бизнеса и инженеров
Это экспериментальная статья про Research&Development, технологии для создания новой ценности для клиента — потому не будет ни слова про техническую часть. Будет немного про историю и культуру DevOps, а также про процессы, культурные особенности, взаимодействие внутри инженерных команд и, конечно, особенности появления R&D внутри них.
Сразу скажу, что это немного идеалистичная картина для нашего российского IT. У нас еще мало компаний, которые действительно используют R&D в качестве основного зарабатывающего бизнес-юнита. В основном лишь частично внедряются практики, взаимодействие и культуру DevOps. Но это не значит, что туда не надо идти. Если у вас это вызовет отторжение: «Такого не бывает, это не работает», то предлагаю превратить это в вопрос: «Такого не бывает? Это не работает?»
Меня зовут Александр Титов, первые DevOps-практики я начал использовать еще до того, как появилось само слово DevOps. Сейчас я управляющий партнер в компании Экспресс 42, которая помогает ставить DevOps в компаниях.

История DevOps началась с твита в 2009 году. В 2000-х огромное количество технологических компаний после бума доткомов в Америке стали развивать айтишные подразделения и столкнулись с тем, что под новые задачи нужны новые походы. У Google на это ушло порядка 6 лет — в 2006 году у них появились Software Reliability Engineering практики, как зачаточная история про DevOps. Впрочем, они об этом не говорили вплоть до 2014 года.
Впервые публично про инженерную культуру и построение собственной инженерной разработки выступил в 2009 году Джон Асплоу из компании Flicr. Через три дня этот доклад появился на YouTube, а еще через день бельгиец Патрик Дебуа (теперь довольно известный товарищ в DevOps-комьюнити) написал твит, что этот доклад — про DevOps. Так появилось имя.
Я рекомендую посмотреть этот доклад — он актуален и понятен даже сейчас. Какие-то вещи были предвосхищены еще тогда. Например, в нем рассказывается про Continuous Delivery, хотя тогда это еще так не называлось. Приведу для примера один из слайдов Джона Асплоу:

Здесь важны все слова. Во-первых, ребята сразу указывают на скорость изменений в компании, которой они достигли — 10 деплоев в день, но вспомните, что это 2009 год! Дальше они говорят про формирование целостного инжиниринга, куда входят и разработчики, и эксплуатация. Там нет разделения на разработку и эксплуатацию. И в третьих, речь идет про инженерную культуру кооперации, то есть объединение вокруг общих целей. Объяснение очень психологично — должны быть, например, доверие, уважение, здоровое отношение к проблемам.
Но вернемся к Research&Development. Начнем с вопроса: в какой момент нужно задуматься о DevOps внутри компании?
Когда нужно задуматься о DevOps
Как известно, процесс создания продукта состоит из 4 больших элементов:
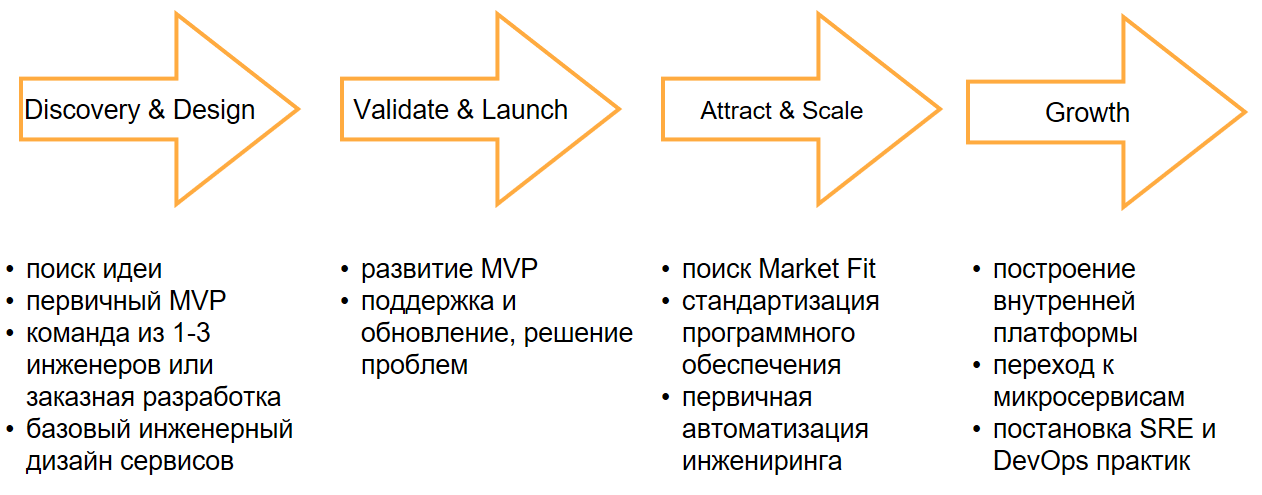
Discovery & Design включает в себя поиск идеи, первичный mvp, затем создается команда из 1–3 инженеров (отдается внешнюю на разработку) и рисуется базовый инженерный дизайн сервисов. Вы просто обкатываете идею и пытаетесь ее воплотить.
На втором этапе — Validate & Launch — вы отдаете идею на суд публики в первый раз и тем самым развиваете, обновляете mvp и решаете возникшие с ним проблемы. То есть когда вы запускаетесь, обычно всё летит криво-косо, а люди ничего не понимают. Этап развития mvp может занимать от месяца до 2 лет. Многие компании так и не доходят до момента, когда все начинает расти и работать.
Если предыдущая стадия пройдена успешно, вы попали в сердце целевой аудитории, то вы переходите на этап Attract & Scale. Здесь и начинают появляться первые DevOps-практики в компании, потому что вам нужно масштабироваться. Вы упираетесь в то, что в софте становится слишком много зависимостей, уже не получается 10 деплоев в день, как раньше, потому что очень много компонентов, которые надо увязывать вместе.
Вы стандартизируете программное обеспечение и впервые автоматизируете инжиниринг. Потому что к моменту, когда происходит попадание в рынок, требуется делать реально много изменений. И если вы не успеваете, то люди перестают пользоваться вашим продуктом.
На четвертом этапе Growth, в постоянном развитии и росте, вы выстраиваете свою внутреннюю платформу, переходите к микросервисам и вам уже надо иметь все SRE- и DevOps-практики в своем арсенале. Что и позволит вам построить такую оргструктуру, чтобы продукт непрерывно обновлялся, подстраиваясь к клиенту.
Однако нам также важно помнить про очень важную связку между DevOps-практиками, организацией работы и ценностью, которую мы доносим до клиента. Покажу на примерах.
DevOps и Value of User
Пример Airbnb
Сначала приведу пример связи ценности продукта для конечного пользователя и организацией работы. Все, наверно, знают, что такое Airbnb. Это платформа для очень разных типов путешественников, а не просто людей, которые хотят снять какое-то жилье. Она помогает погрузиться в то окружение, куда люди приезжают. Помогает найти жилье тем, кто путешествует самостоятельно, с детьми или ездит в командировки. Тому, кто параллельно хочет увидеть новое или нереально увлечен историей Рима. У них есть подсказки, при помощи какого жилья можно получить лучший опыт погружения в определенную среду. И, конечно, это платформа для тех, кто сдает недвижимость.
За счет того, что Airbnb закрывает потребности такого довольно широкого круга людей, они и держатся на рынке. Это не просто агрегатор отелей, а платформа, которая дает ценность для разных типов участников. Например, если я ищу жилье для поездки, где мне важно разместить двоих детей, то они специально это подчеркивают в описаниях. А через отзывы можно понять, что это жилье действительно подходит именно мне.
Всё это Airbnb делает через определенные технические системы:
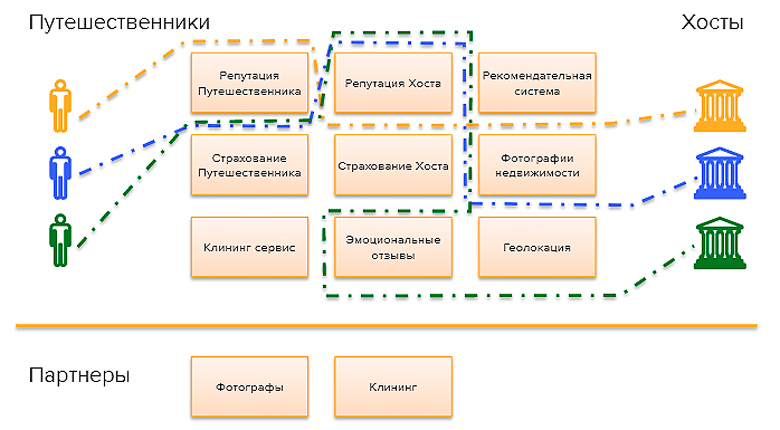
С одной стороны, это те кубики на схеме, которые позволяют доставить ценности от хостов по предоставлению жилья до путешественников. Они подсвечиваются на выходе: через репутацию путешественника и хоста, эмоциональные отзывы, рекомендательную систему и фотографии недвижимости.
В блоге Airbnb есть целая история, как они тюнят фотографии, причем и технически, и организационно. Например, в исторические локации они привлекают профессиональных фотографов, чтобы показать, что это действительно отвечает той задаче, которая есть у путешественника.
С другой стороны, это конкретный софт, который требует постоянного изменения. Ведь от того, насколько вы хорошо посчитаете репутацию путешественника или хоста, будет зависеть, воспользуются вашей системой или нет.
В случае если вы хотите добавить определенную целевую аудиторию, ей нужно дать дополнительную ценность. Например, проводится чемпионат мира по футболу, и для болельщиков есть отдельная ценность в местах проживания (недалеко от тусовочных мест фанатов или от стадиона). В Барселоне есть места, где футбол можно смотреть прямо из окна дома, на Сантьяго Бернабеу открывается отличный вид.
Чтобы дать такую дополнительную ценность, вам надо написать софт, быстро его выкатить, оттестировать, предоставить клиенту и посмотреть, как он им пользуется. Этот путь ценности внутри компании обеспечивает DevOps. Заметьте, всё это не для того, чтобы выкатываться быстрее, и даже не для того, чтобы уменьшить Time to Market. Сейчас скажу крамольную мысль: Time to Market — это следствие того, что мы обеспечиваем создание ценности нашим пользователям.
Если у вас в компании true DevOps, у вас обязательно должна быть ориентация на поставку ценности клиенту. Если это не так, то возникают разные косвенные случаи, когда DevOps-практики работают, но только в отдельно взятой истории.
Приведу еще один пример, на это раз связи ценности для пользователя и технологической сложности.
Пример Clubhouse
Наверное, все слышали, что в январе 2021 года взлетела популярность Clubhouse. Но на самом деле здесь важно другое — для приложения, которое организует звуковую коммуникацию, важным становится качество звука. И я долго думал, как же они решили проблему качества звука, потому что это базовая ценность для организации звуковых каналов связи.
Оказалось, что в Clubhouse для работы с аудио используют SaaS сервис Agora:
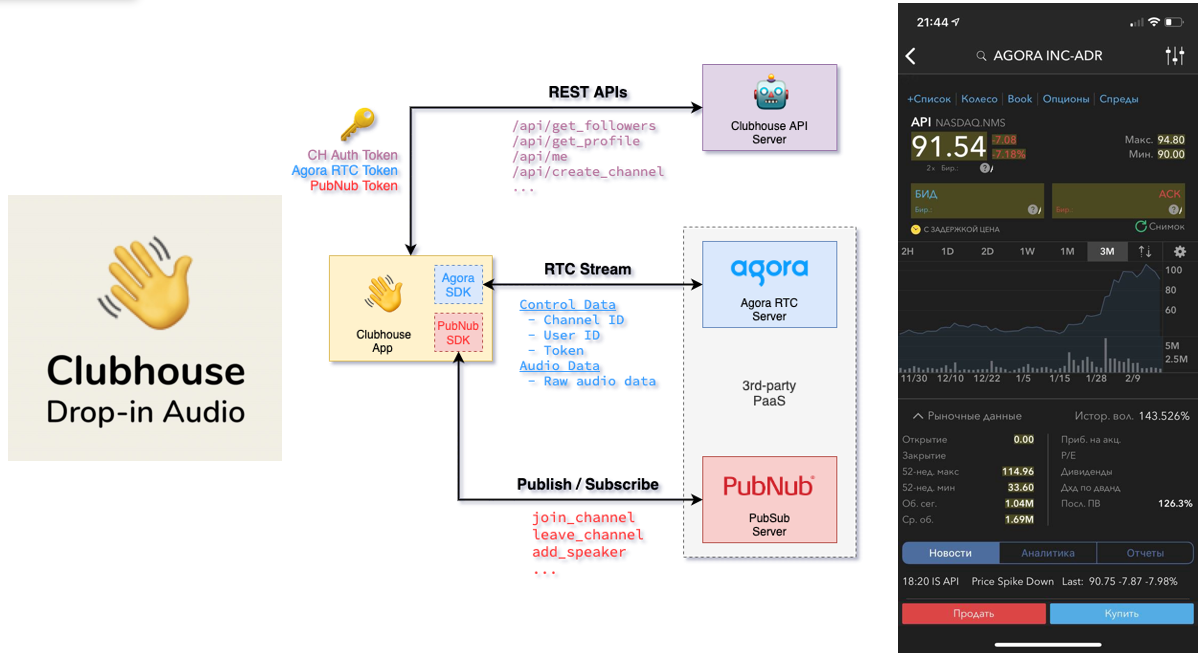
На графике их биржевых котировок видно, что в районе 28 января 2021 года акции Agora взлетели в 2 раза. Так работает связка технологий и бизнеса в реальности. Просто реальный график показывает, что технология аудио — важнейшая история в создании ценности аудио-сервиса. Никаких рассказов про Time to Market.
Сейчас их история развивается. Они наняли самого крутого эксперта в WebRTC, чтобы развивать это уже внутри себя. Потому что они понимают, что если будут завязаны на сервис Agora, то далеко не уйдут.
Value of User и Value Stream
В компаниях, которые создают технологические продукты как ценность для клиента, появляется понятие Value Stream. Но на самом деле есть несколько Value Stream:
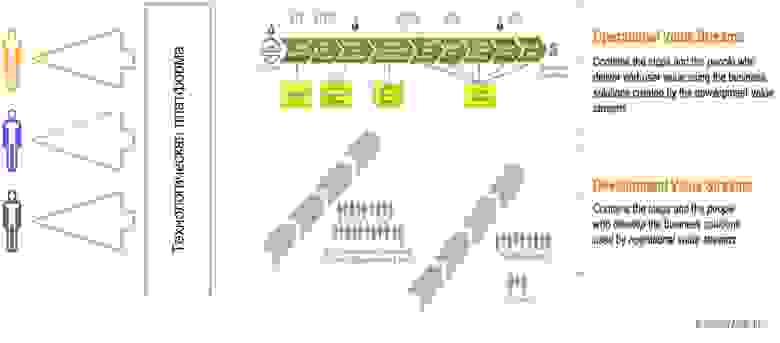
Продуктовый Value Stream (показан желтым) связан с поставкой пользы клиенту. Операционный Value Stream обеспечивает базовые логистические функции внутри компании, чтобы деньги приходили, людей нанимали в нужные места и решались правовые вопросы. А Development Value Stream, я бы его назвал R&D Value Stream — это ребята, которые создают процессы и технологии, позволяющие донести ценности до клиента. Это и есть Stream, в котором реализуются DevOps-практики.
Типичный пример процесса создания ценности в организации:

Кажется, что это классический водопадный процесс, включающий формирование требования, создание функциональности, тестирование, доставку к пользователю, контроль и прочее. Но на самом деле нет.
Если посмотреть на кубики внизу, то видно, что эксплуатационные вещи есть и на первом уровне — например, при изменении связей между приложениями. На втором — это изменение схемы данных, конфигурации и метрики системы. Так же как и на уровне интеграционного тестирования API и доставки к пользователю.
Все процессы, которые раньше относились к эксплуатации и были в самом конце, уходят на первые роли. Чтобы мы могли прямо на первом этапе как можно быстрее понять, что идет не так. Увидеть, насколько наше техническое решение позволяет ценности клиента переместиться из одной точки в другую или из одного представления в другое.
Иерархическая компания с большим количеством функциональных отделов на самом деле создает всего лишь один Value Stream. Когда Value Stream становится много, то и компания кардинально меняется — организационно и технологически. В примере с Airbnb кубики — это те самые отдельные Value Stream Research&Development, которые позволяют доносить до клиента конечную ценность:
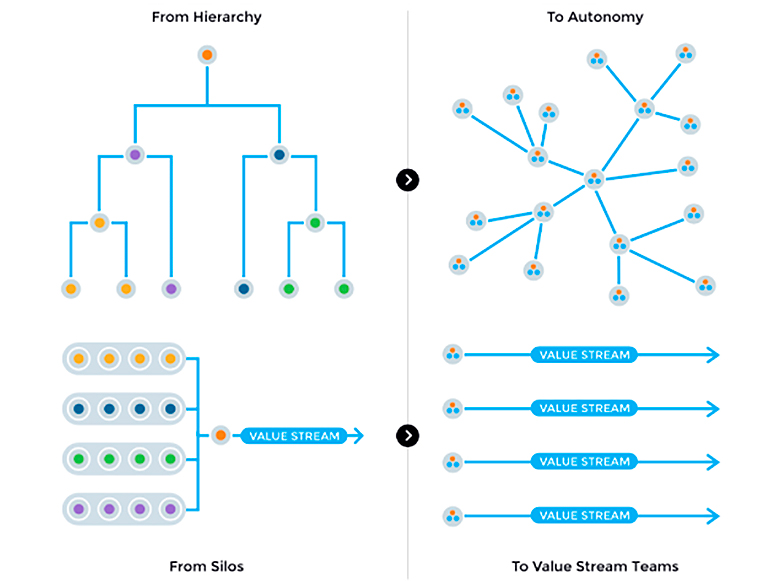
Value Cycle
В цикл создания ценностей входят основные DevOps-практики: это Continuous Integration, Continuous Delivery, анализ и измерение того, что входит в Observability:
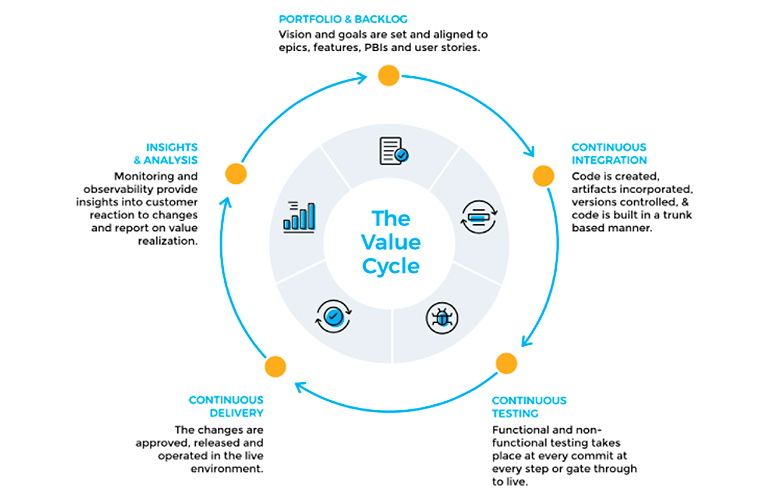
Становится понятно, как примерно меняются акценты. Observability — это больше про понимание, как ценность была технически доставлена клиенту. Раньше мы использовали мониторинг, чтобы понимать, работает сервис или нет. Для нас было важно, насколько работает система — включен ли сервер, проходят ли пинги. Сейчас мы спрашиваем себя: «Насколько то, что мы хотели донести до клиента при помощи определенной технической системы, действительно донесено?» Система метрик и мониторинга, а также показатели качества должны отвечать именно на эти вопросы.
Так появляется отдельная дисциплина Value Stream Management, которая тоже причисляется к DevOps. Она координирует/синхронизирует разные стримы создания ценностей, оптимизирует стримы по скорости разработки и анализирует компетенции команд, а также собирает новые команды под цели и задачи.
Это очень важно, потому что ваши инженеры перестают быть просто инженерами. Одни становятся инженерами, которые разбираются в аудио-разработке. Другие разбираются в видео, классно делают Service Discovery или строят системы сбора логов и управления метриками. Все это разные предметные области, компетенции и разные инженеры.
Против чего я борюсь последние 10 лет — это тот самый мифический DevOps-инженер, которому подводят разные компетенции. На самом деле, когда компания начинает набирать DevOps-инженеров, то в конечном итоге она понимает, что это просто огромное количество вариаций разного типа инженеров. Которые умеют работать внутри новой среды, где создается не просто решение по автоматизации или переводу из пункта А в пункт В, а некоторая среда, чтобы клиент мог получать новый тип ценности.
Этот навык — работать в такой среде — приходит с появлением DevOps в мире, а не с появлением новой профессии DevOps-инженера. Потому что системные администраторы как занимались настройкой инфраструктуры, так ею и занимаются. Конечно, появляются и новые компетенции: например, связанные с мониторингом, с построением CI/CD пайплайнов. Но в конечном счете это тоже инженеры, а не DevOps-инженеры. Это важная штука, которая позволяет посмотреть на мир немного по-другому, а не продолжать по-старому, что DevOps-инженер — это равно сисадмину.
Research&Development мы строим на основе данных и тех метрик, которые получаем. И мы сами принимаем решение о каких-то изменениях. Нам не надо это согласовывать с бизнесом, потому что бизнес нам уже поставил цель, через которую понятно, какие изменения нужно вносить.
В итоге у нас появляются три домена технологической компании по созданию ценностей для пользователя. Хотя сейчас модно говорить, что есть энтерпрайз, а есть технологические компании, но постепенно границы размываются. Эти три больших домена такие:
Research&Development (Engineering) — технологии для создания новой ценности для клиента.
Management обеспечивает операционное протекание информации и взаимодействие. Это не product-менеджер, а новая компетенция engineering-менеджера, который реализует не управление проектами, а лидерство в коммуникации разных R&D команд.
Product Development — создание продуктов. Отсюда мы получаем изменения в культуре взаимодействия, о которой ребята из Flicr говорили 12 лет назад
Неочевидные вещи
Обратный манёвр Конвея
Мелвин Конвей еще в 1968 году сформулировал свой прямой закон: Любая внутренняя система копирует коммуникационную структуру тех людей, которые ее создали.
Его обратный манёвр: Проектируйте команды и коммуникационную структуру в соответствии с архитектурой вашей системы или разрабатываемого приложения.
То есть вначале нужно понять, что вам делать, а потом делать оргдизайн, а не наоборот — это у нас отдел разработки, это отдел эксплуатации, это отдел тестирования, а само тестирование нарезать на функциональное, модульное и еще какое-нибудь. Такой подход в очередной раз приведет к тому, что вы получите не то.
Проектирование системы всегда начинается, с одной стороны — с проектирования технологий, а с другой — с проектирования процесса R&D, который эту систему создаст. Это хоть и кажется очевидным, но когда пытаешься это сделать внутри компании — далеко не всегда так:

На схеме базово показано, что переход к микросервисной архитектуре — это переход к новому способу организационного дизайна. Если мы на микросервисную архитектуру смотрим технологически, то для отдельных технологических областей создадим отдельные команды. А после этго задумаемся, что нам надо как-то организовать их взаимодействие. Что будет возможно, если каждая команда будет писать исключительно свой отдельный софт.
На самом деле микросервисная архитектура — это про то, как мы организуем команды R&D. Вначале надо организовать команды, а потом уже смотреть, как организовываются отдельные микросервисы. Абсолютно неочевидная вещь, но это именно так и работает.
Это видно на примере с Airbnb. Они сначала разделили, как технологически это должно работать. После этого определили, как производится часть внутреннего R&D. Под это дело создали команды, которые сделали микросервисы. Дальше они договорились о том, как они будут друг с другом взаимодействовать. Так появляются автономные отдельные команды, которые взаимодействуют друг с другом и создают Value Stream«ы. Но не наоборот: договориться, как распилить микросервисы, а потом сделать команды. Нет, так это не работает.
Компания
Следующий неочевидный момент — это сама команда. Она отличается от рабочей группы и просто от ребят, которые собрались чаю попить. Потому что команда собирается вокруг цели или целей, а не вокруг списка задач, которые нужно выполнять. Команда должна быть самоходной, то есть самостоятельно декомпозировать задачи и планировать их выполнение. Плюс для создания нового софта команда ее границы должны быть открытыми как для приема людей и знаний, так и для отдачи знаний и помощи.
Здесь прекрасно работает практика Objectives and Key Results (OKR). Но не только она.
OKR, KPI и мониторинг
С точки зрения описания OCR — это простая практика, но работает она только в структуре, где компания реально ставит и декомпозирует цели. Если компания этого не делает, то вы, конечно, можете ее у себя пробовать, но работать она будет не очень.
В OKR есть свои неочевидные вещи, например, основной прием — думать из будущего в настоящее. Мы все привыкли планировать наоборот: думать из прошлого в настоящее. Это базовый паттерн: «Я сегодня не поеду на такси, потому что в Москве в 9 утра пробки». А для проектного подхода сначала вы придумываете конструкцию, с которой хотите работать, а потом ставите цели и обозначаете ключевые результаты для продвижения к ней. Поэтому в подходе OKR выполнение 80% ключевых результатов — уже грандиозный результат.
Главный вопрос, который вы задаете при этом: куда мы хотим прийти и что мы хотим достичь в будущем? Не на основе нашего предыдущего опыта, а на основе того, что мы действительно хотим создать новое, потому что создание ценности для клиента — это всегда создание нового. Ответ дает именно цель. А ключевые результаты отвечают на вопрос: какие шаги мне надо сделать, чтобы увидеть, добираюсь ли я туда?
С другой стороны, во многих компаниях используется KPI (Key Performance Indicator), но понимается не совсем одинаково, хотя эти подходы часто сравнивают. На примере видно, чем отличается OKR от KPI:

На самом деле это все вместе собирается. OKR — вы ставите цель в будущее и у вас есть несколько вариантов ее достижения. То есть вы выбираете тот путь, по которому пойдете, как в навигаторе вводите, куда поехать. KPI — это разные показатели системы, которая работает (скорость, количество оборотов двигателя в секунду, сколько до следующего поворота осталось ехать и т.д.)
В этом ключевое отличие observability от мониторинга: нам нужно собрать метрики (показатели работы нашей технической системы), чтобы понять, мы туда идем? Правильно движемся? Мы вообще идём или не идём? Для каждой отдельной ценности это будет отдельный продукт и отдельная история, которую нужно создать внутри компании.
Например, вы построили маршрут, а спидометр показывает 0 км/час — что-то не едет. Или 30 км/час и желтые фонарики горят — что-то не то. Примерно то же самое должно работать в observability.
Главные DevOps метрики — про то, как работает ваш цифровой конвейер поставки ценностей:

Эти метрики ничего не говорят про продукт, который вы делаете — то есть они универсальны. Но каждой компании также нужно создать метрики, которые подсвечивают: идете ли вы к цели, продвигаетесь ли в создание новой ценности, о которой мечтаете.
Есть классный подход Team Topologies. Про него есть выступление Мэтью Скелтон (Matthew Skelton) и Мануэль Пайс (Manuel Pais), авторов книги «Team Topologies: Organizing Business and Technology Teams for Fast Flow». Подход позволяет поделить Research&Development внутри компании на команды и построить систему взаимодействия команд так, чтобы действительно создавать новое.
Заключение
Возвращаясь к тому, что говорили ребята из Flicr. С точки зрения культуры взаимодействия есть важные вещи, и они не про уважение и доверие. Уважение и доверие — это ценности, а культура взаимодействия — это баланс между личной выгодой, правилами и ценностями. Если ваше R&D-подразделение создает новую ценность для клиентов, то вам нужно найти этот баланс. Это такой неочевидный момент, который я понял совсем недавно на следующем примере.
Если вы едете на машине в супермаркет, чтобы купить себе еды, то у вас есть определенная личная выгода. На светофоре вы останавливаетесь на красный свет, потому что есть правила дорожного движения, а потом останавливаетесь, чтобы помочь человеку, который пробил колесо. Тем самым вы оттягиваете достижение личной выгоды на основе правил и ваших ценностей.
Так работает баланс между ценностями, правилами и личной выгодой. Он должен быть простроен внутри компании, задан как норма, руководство к действию менеджмента, потому что иначе очень сложно в этой истории действовать. Для этого должна быть построена безопасная среда, и здесь очень классно работает ненасильственное общение.
Другая неочевидная вещь — обучение и синхронизация через контекст. В этом смысле, например, практика «инфраструктура как код» — не про автоматизацию, а про общий контекст. Это один из способов его задания внутри ваших технологий. Есть еще модная практика DocOps — это тоже про это. С ней дешевле принимать решения за счет того, что знания и подходы уже представлены в вашей среде. Поэтому, например, писать write-only скрипты, которые можно только написать, а прочитать невозможно — это плохая практика. Писать код надо так, чтобы другие люди могли разобраться в нем.
Технологии должны быть для человека, а не человек для технологий. Это обрубает все пути к подходу автоматизации чего-либо. Мы не автоматизируем, а создаем новое. А для того, чтобы создавать новое, нам надо технологию делать для людей. В том числе, для разработчиков. Например, CI/CD пайплайн позволяет им проще и дешевле создавать новое ПО.
Основная литература, которую я рекомендую: раз, два и три.

В нашем отчете прошлого года есть интересные инсайты, которые позволяют понять, что в России происходит с DevOps.
Видео моего выступления на DevOps Conf 2021:
Объединенная конференция DevOpsConf 2022 и TechLead Conf 2022 пройдет в Москве 13 и 14 июня на самой инновационной и технологичной площадке — в кампусе Сколково. Программа полностью сформирована. Билеты можно купить здесь.
