Поиск аномалий при запусках процессов Windows с помощью рекомендательных систем
В SIEM-системах есть множество написанных экспертами правил, которые помогут отследить подозрительное поведение. Однако существует много сценариев атак, которые нельзя описать строгими правилами, а значит, эффективно отслеживать.
Учитывая объем данных, обрабатываемый SIEM-системой ежедневно, а также специфические задачи анализа этих данных (целью которого является поиск действий злоумышленников), применять машинное обучение сегодня необходимо и чрезвычайно эффективно.
Описание задачи
В конкретном случае мы решали следующую задачу: после получения злоумышленниками доступа к IT-инфраструктуре они используют различные тактики и техники, чтобы укрепиться и продвинуться дальше, вся их деятельность так или иначе будет оставлять следы, которые впоследствии попадут в SIEM-систему.
Применение большинства тактик будет фиксироваться в событиях журналов Windows, которые касаются запуска процессов (Sysmon EventID 1 и Windows Seсurity EventID 4688). Отбросив ненужную информацию, наши исходные данные можно представить в виде следующей таблицы:
User name | Process name |
Ivanov Ivan | cmd.exe |
Petrov Petr | outlook.exe |
Sidorov Nikolay | whoami.exe |
Мы видим список всех процессов, запущенных в инфраструктуре, и пользователей, под чьими учетными записями это произошло. Нам важно научить SIEM-систему определять, какие процессы нормальны для конкретного пользователя, а какие нетипичны — аномальны. Причем, как можно догадаться, аномальные процессы для одного пользователя могут быть совершенно нормальными для другого.
Имея в своем распоряжении такую функциональность (возможность определять аномальные процессы для пользователей), мы сможем замечать множество попыток атак на ранней стадии. Например, представим две ситуации: бухгалтер запускает у себя на рабочей станции служебные утилиты, чтобы посмотреть информацию об Active Directory Domain Services, и секретарь, который раньше работал только с офисными программами, вдруг запускает бухгалтерские программы. Возможно, ничего страшного, и за компьютер бухгалтера просто сел системный администратор для диагностики сетевой проблемы, а секретарю добавили обязанностей и установили »1С: Предприятие». Но ведь может быть и другое объяснение — над учетной записью получили контроль злоумышленники и проводят разведку с целью дальнейшего продвижения. Или секретарь на самом деле является инсайдером и пытается украсть из компании базу данных.
Такие случаи, безусловно, требуют внимания со стороны оператора SIEM-системы и проработки, когда рассматриваются контекст ситуации и сторонние события, не относящиеся к запуску конкретных событий.
Базовые подходы к решению задачи
Какие могут быть подходы к решению этой задачи? Первое, что приходит на ум, — нужно контролировать все процессы, которые запускает конкретный пользователь, и проверять их допустимость для этого пользователя.

Алгоритм проверки допустимости запуска процесса для конкретного пользователя
На первый взгляд, такой простой алгоритм решит проблему. Но при тестировании мы получим следующие ситуации.
Представьте, что у нас есть программист в организации, который любит писать код в своей любимой IDE — Visual Studio Code. В один прекрасный день друг ему посоветовал попробовать другой инструмент — PyCharm, и он воспользовался советом. С точки зрения нашего алгоритма произошла аномалия, нетипичное поведение. Наш пользователь никогда не работал в этой программе. Но с точки зрения оператора SIEM-системы, не произошло ничего, что требовало бы внимания. Это false positive — ложное срабатывание. И таких ситуаций будет очень много, что сведет пользу от нашего алгоритма к нулю.
Как решить эту проблему? Сразу приходит мысль:, а давайте мы будем оперировать не конкретными приложениями, а их функциональным назначением. Классифицируем все приложения и объединим их в группы. Например, PyCharm и Visual Studio Code будут находиться в одной группе, которую назовем «Инструменты для разработки», Microsoft Word и Microsoft Excel — в группе «Офисные программы».
Так же можно поступить и с учетными данными пользователей. Наша система будет видеть пользователя не как Васю, Петю, Таню, а как набор их функциональных обязанностей. Например, Вася — разработчик и по совместительству системный администратор, а Таня — бухгалтер. И система обучится тому, что для разработчиков нормально использовать инструменты для разработки, а для бухгалтеров — бухгалтерские программы. И для них всех нормально использовать офисные программы.
Такой подход может сработать, но, к сожалению, только в тех компаниях, где список сотрудников и их обязанности поддерживаются в актуальном состоянии IT-подразделением. Кроме того, придется отслеживать и поддерживать в актуальном состоянии список ПО, что также будет непростой задачей, если учитывать, что многие организации используют специфическое или самостоятельно разработанное ПО.
Подход с использование машинного обучения
И вот, когда становится понятно, что стандартные строгие алгоритмы требуют слишком больших усилий, приходит время использовать «магию» машинного обучения. Нам нужно применить такой алгоритм, который фактически самостоятельно «поймет» функциональные обязанности каждого пользователя и предназначение каждой конкретной программы.
Выглядит сложно. Но, оказывается, нашим потребностям полностью соответствует класс алгоритмов, который называется «Рекомендательные системы».
Рекомендательные системы — это класс алгоритмов машинного обучения, призванных рекомендовать пользователям товары или контент.
Как можно догадаться, рекомендательные системы широко распространены в нашей жизни. Алгоритм может использоваться везде, где требуется удержать внимание пользователя новым для него контентом или рекомендовать к покупке новый товар.
Есть два подхода к построению рекомендательных систем:
content-based;
collaborative filtering.
Content-based-технологии требуют для своей работы дополнительной информации. В таком случае необходимо описать каждый товар или пользователя набором признаков. Например, в случае с подбором фильма для пользователя это могут быть жанр, актеры главных ролей, год выпуска, страна производства. Как можно понять, этот тип рекомендательных систем не удовлетворяет нашим требованиям в конкретной задаче.
А вот технология collaborative filtering использует только информацию о том, насколько пользователю понравился тот или иной товар. Нам не нужно собирать данные по каждому отдельному признаку.
Остановимся подробнее на том, как работает collaborative filtering. Представим некий премиальный товар, который приобрела часть пользователей, покупающих другие премиальные товары. Логично порекомендовать этот продукт и остальной части таких пользователей.
Очевидно, что люди, которые ставят примерно одинаковые оценки одним и тем же товарам, обладают похожими вкусами и предпочтениями. И обратная ситуация: если контент нравится определенной группе пользователей, это многое говорит о его характеристиках. На этих простых принципах и основан collaborative filtering.
Наша задача при обучении модели — получить для каждого пользователя и товара такие векторы, при перемножении которых друг на друга мы получим оценку товара, которую ему бы поставил пользователь, если бы приобрел его.
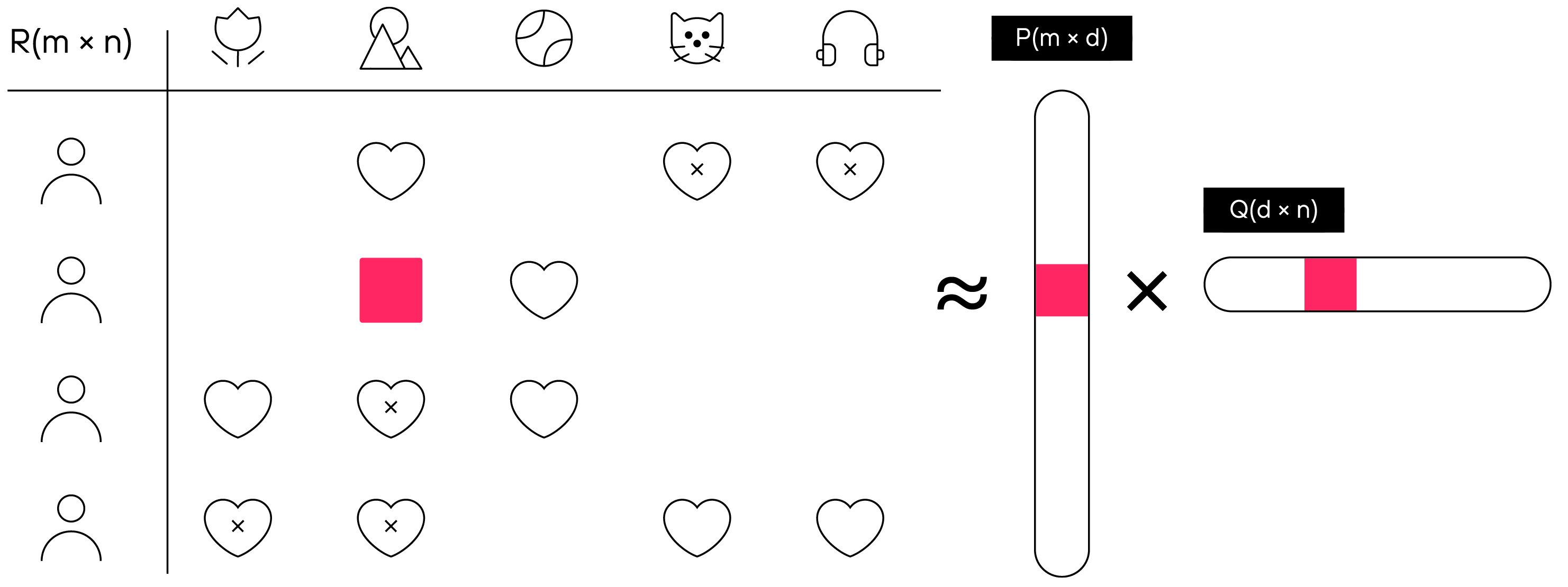
Принцип работы технологии collaborative filtering, где P — матрица векторов пользователей размерности m×d, а Q — матрица векторов товаров размерности d×n
Главный вопрос — как сделать такие векторы, если у нас нет никакой информации ни про пользователей, ни про контент? Но это только на первый взгляд. У нас ведь есть история их оценок, и этого нам достаточно.
Сделать это можно, например, с помощью алгоритма alternating least squares (ALS). Не вдаваясь глубоко в математику, можно объяснить его работу следующим образом: мы фиксируем матрицу с векторами пользователей, оптимизируем и меняем матрицу контента. Используем для этого производную от функции потерь (градиент) и движемся в сторону, обратную градиенту, — в нужную нам сторону, где лежит «истина» и где мы не будем ошибаться в предсказаниях. Затем мы фиксируем уже матрицу контента и проделываем то же самое с матрицей пользователей. Повторяем это много раз, шаг за шагом приближаясь к нужным значениям, «обучая» нашу модель.
Таким образом мы получим нужные нам векторы. Безусловно, если мы возьмем конкретный вектор и посмотрим на него с точки зрения человека, мы ничего не поймем. Для нас это будет просто набор чисел. Но каждое число в этом векторе и расположение этих чисел относительно друг друга будут иметь смысл и отражать реальное положение дел.
Возникает закономерный вопрос: как можно использовать рекомендательные системы для поиска аномалий?
Логично предположить, что если пользователь запускает тот или иной процесс, то он ему нравится. У этого процесса будет высокая оценка (score), если мы говорим в терминах рекомендательных систем.
И обратная ситуация: если процесс аномальный, если конкретный пользователь и похожие на него никогда не запускали этот и похожие процессы, то рекомендательная система выдаст низкую оценку — скажет, что нашему пользователю этот процесс не понравится. И вот то, что он запустил, ему понравилось, хотя не должно было (по версии рекомендательной системы), — это и есть аномалия.
Этот подход хорошо показал себя в процессе тестирования. Оказалось, что вектор пользователя хорошо описывает функциональные обязанности пользователей, а вектор приложения, соответственно, справляется с описанием набора функций приложения. То, что вектор пользователя хорошо отражает реальность, видно на следующем примере.
Возьмем все векторы пользователей и отразим их в двумерном пространстве. Мы получим примерно такую картинку.

Отображение в двумерном пространстве учетных записей пользователей
Одна точка — это один конкретный пользователь, цвет точки — его функциональные обязанности, которые взяты из штатного расписания. Мы можем видеть, что пользователи из одного отдела группируются рядом, то есть наша модель хорошо обучилась, и ее внутреннее состояние отражает реальность. Безусловно, в такой ситуации будут исключения, но они связаны с особенностями поведения конкретных людей.
Еще одна важная перспективная особенность, на которую можно обратить внимание, — это движение точек (пользователей) на этом графике. Если пользователь занимается примерно одной и той же деятельностью, то он будет на одном месте в пространстве. Однако если под его учетной записью начали выполнять нетипичные действия, то мы увидим резкий «прыжок» точки. Если сделать удобный инструмент для обнаружения и анализа таких «прыжков», это может быть полезно операторам систем защиты.
Теперь посмотрим, как может выглядеть на практике традиционное использование модели.
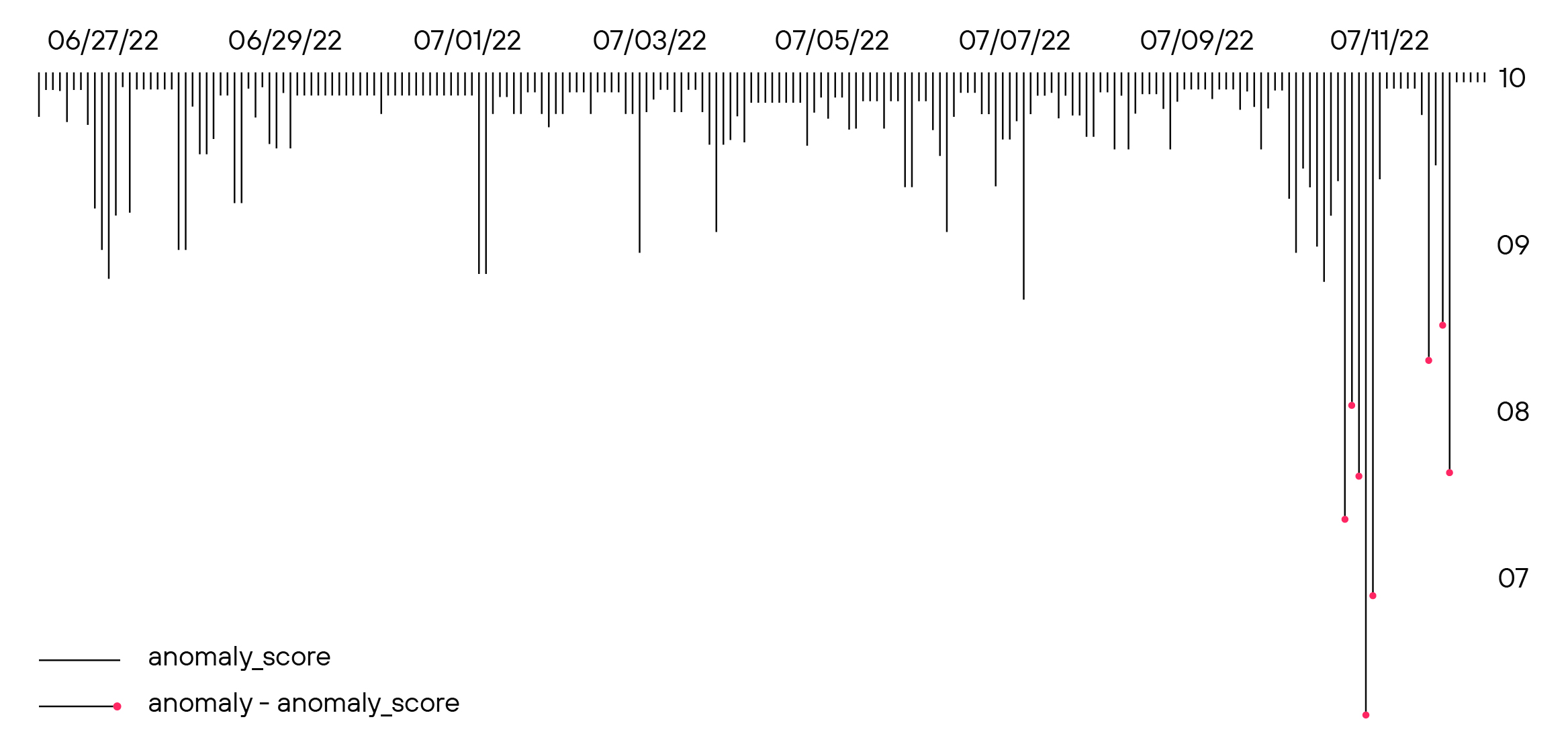
Временной ряд предсказаний модели на одном пользователе
На этот график нанесены показания модели по одному конкретному пользователю. Чем ниже значения по оси y, тем менее «нормальными» становятся действия пользователя. До 7 июля ничего необычного в поведении пользователя не было — значения аномальности не опускались ниже 0,9. Однако 11 июля учетной записью завладел злоумышленник — модель начала выдавать низкие показатели.
Заключение
В этом эксперименте были использованы утилиты для проведения разведки в инфраструктуре. Для пользователя такое поведение, безусловно, типичным не являлось. Мы применяли простые, базовые рекомендательные системы. В целях дальнейшего развития идеи можно пойти в сторону использования совместного подхода content-based и collaborative filtering для создания рекомендательных систем, а также внедрять системы глубокого изучения (deep learning). В качестве основного вывода из проведенных экспериментов можно отметить, что использование рекомендательных систем для поиска аномалий обладает большим потенциалом и может помочь решить большой круг задач в сфере кибербезопасности.
 Игорь Пестрецов
Игорь ПестрецовСтарший специалист отдела перспективных технологий Positive Technologies
