Архитектура и реактивное программирование
Что такое реактивное программирование? Не Rx. И даже не Excel. Это архитектурный паттерн, позволяющий абсолютно иначе писать код. В статье мы устаканим фундаментальные знания, утвердимся в том, что React.js всё же является реактивным, и подумаем о том, как и когда нужно, а когда не нужно применять паттерны реактивного программирования.
Так уж вышло, что я побывал в большом количестве огромных кодовых баз, где сталкивался с одними и теми же проблемами организации кода. Информация ниже — это результат исследований программирования в общем и реактивного программирования в частности за последние пять лет. Я уже несколько лет пишу свой менеджер состояния Reatom, и это не просто пет-проект, а серьёзный продукт. Я старался сделать его проще для входа и использования, но оставил возможность расти до энтерпрайза и решать соответствующие проблемы. В статье будет не теория из пустых рассуждений, а опыт решения реальных задач.
Вы уже могли видеть связанную статью «Что такое состояние», где я подробно разбираю этот вопрос. А сегодня поговорим о второй стороне управления состоянием и потоками данных.
Проблемы, которые реактивное программирование поможет вам решить:
- связанность кода и его разбиение на модули;
- ленивая подгрузка модулей;
- автоматическая инвалидация кеша.
▍ Определение
Реактивное программирование — парадигма программирования, предполагающая передачу ответственности за инициализацию обработки информации источнику информации.
Это определение — описание того общего, что есть у Rx и MobX — таких разных, но безусловно реактивных библиотек, признанных всей индустрией. Да, они полностью отличаются внешним API, но подкапотные механизмы одни и те же — динамический список подписчиков и какое-то условие (триггер) его обхода. Это очень простая механика, и она встречается постоянно. В этом нет ничего сакрального, многие стандартные API платформы и библиотеки её реализуют. Иногда доступ к подписчикам явный — метод subscribe или effect. Иногда он скрыт — JSX тег разворачивается в React.createElement, который ведёт к подписке на внутренний стейт.
Да, React.js также использует паттерны реактивного программирования, это легко проверить. Есть ли у нас контроль над выполнением функции рендера? Нет, React определяет это. Вы могли бы попросить запланировать обновление, но оно будет запущено, когда React примет решение об этом. Он несёт ответственность за запуск вычислений.
В документации React как-то мелькало утверждение о том, что React не ФРПшный и это так. Он не использует специфичные конструкции функционально-реактивного программирования, но немного использует реактивное программирование в общем.
Паттерны реактивного программирования предполагают разворачивание направления связей в нашем коде, позволяя одним модулям зависеть от других, не меняя их код. Иначе говоря, реактивное программирование позволяет уменьшить связанность кода.
Хорошей практикой при разработке приложений является разделение их на независимые виджеты / модули / компоненты / фичи — все называют их по-разному. Но важно понимать, что эти модули не существуют сами по себе, они имеют какой-то общий смысл, и цельное приложение получается из их связанности. Сложный вопрос — как описывать эти связи и где их хранить.
▍ Пример
Здесь и ниже мы будем находиться в контексте JavaScript, но все идеи относятся к любому ЯП.
У нас есть аватарка пользователя в шапке и на странице профиля, при её обновлении с этой страницы нужно подставить новый урл в двух местах. Классический подход: в handlePictureUpdate мы пишем такой код: document.querySelector('.profile .ava').src = newSrc; document.querySelector('.header .ava').src = newSrc. Важно тут то, что функция handlePictureUpdate находится в коде модуля профайла, но почему-то ходит в модуль шапки — это и есть связанность. Такой кодстайл имеет свойство расти по своей сложности, его чтение может давать не те результаты, на которые рассчитываешь, — код шапки не содержит информации о связи с профайлом. Всё это ведёт к неочевидным багам — мы обновили шапку, поменяв её класс на .app-header, и querySelector в handlePictureUpdate теперь будет падать с ошибкой TypeError: Cannot set properties of undefined (setting 'src'). Причём ошибку после такого изменения скорее всего не выявили бы, потому что она в другом модуле. А в интеграционных тестах профайла не было бы проверки того, что происходит в шапке — классика.
Кто-то скажет, что дело в отсутствии БЭМа и предсказуемых селекторов. Кто-то возмутится неиспользованием общей константы с названием селектора шапки. Кто-то укажет на отсутствие проверки на undefined после querySelector — TypeScript бы подсказал! Такой маленький пример и уже так много проблем. Но это всё вопросы прикладного кода, которые в разных ситуациях будут разными. Возможно ли решить проблему подобного характера с архитектурной точки зрения, принципиально избавившись от необходимости перепроверять один модуль при рефакторинге другого?
▍ DDD и SSoT
Принцип Single Source of Truth (SSoT) означает, что в системе существует единственный актуальный и согласованный источник данных определённого типа, а все связанные модели работают с данными и процессами этого типа только через этот источник. Предметно-ориентированное проектирование (domain-driven design, DDD) говорит нам о том, что эти типы данных должны исходить от бизнес-сущностей — доменов: профиль пользователя, сформированный заказ товара. Модель — реализация домена в коде, страница пользователя и форма просмотра и создания, редактирования заказа.
Оперируя бизнес-доменами и не привязываясь к интерфейсу пользователя, нам становится намного проще определять, что к чему относится. Если отвязать профиль от страницы, а заказ от формы — выделить отдельную модель под домен — то станет намного проще принимать решение о том, где хранить и обрабатывать путь к аватарке пользователя.
Пример-предыстория о всё том же адресе аватарки. Когда приложение только начинали делать, выделенной страницы пользователя не было, были только основные формы для реализации бизнеса: список товаров, оформление заказа. Со временем решили повысить UX пользователя, сделать интерфейс дружественным и домашним и решили отображать на нём всегда что-то очень знакомое для пользователя — его аватарку. При клике по квадратной заглушке в правой части шапки можно было выбрать картинку и загрузить её. Логика этой загрузки лежала, соответственно, в шапке. Ещё позже решили сделать страницу редактирования профиля, чтобы адрес можно было заранее сохранить и редактировать, ну и картинку покрупнее посмотреть, заменить и покропить. У программиста встала дилемма — двигать код загрузки из файла с шапкой в файл профайла или из профайла импортировать код из шапки, что странно. В итоге код был передвинут, но это там так и осталось: document.querySelector('.header .ava').src = newSrc.
Теперь у нас в коде страницы профайла есть какое-то знание о коде шапки — не хорошо. В начале статьи разобрали, где это может сломаться. Но даже если мы попытаемся применить DDD и выделим код профайла отдельно от страницы профайла, завязка на интерфейс у нас всё равно останется: document.querySelector('.profile .ava').src = newSrc; document.querySelector('.header .ava').src = newSrc, просто будет лежать в другой папочке. Таким образом, отделяя домен бизнесовый, мы раздробили домен системный — код страницы профайла и код шапки. Шило на мыло.

▍ Проектирование с реактивным программированием
Реактивное программирование прекрасно решает подобные проблемы за счёт простого трюка — связи между модулей переносятся из кода в рантайм. В коде мы лишь описываем, что хотели бы получить, но не описываем как. Это очень важно. Когда мы говорим о высокой связанности как плохом запахе кода, мы имеем в виду переплетение в самом коде, в тексте файлов проекта. Написание кода, чтение и дебаг происходят в подавляющем большинстве при работе с текстом программы, с кодом в самом материальном смысле этого слова. Реактивные паттерны позволяют убрать код, но оставить логическую связь, образовав её в рантайме. Как мы знаем, лучший код тот, что не написан.
Вспоминая пример с обновлением аватарки в шапке, код выглядел бы так для шапки: profile.$picture.subscribe(src => { this.ava.src = src }), в то время как в модели профайла нужно было бы просто экспортировать синглтон profile с picture, обёрнутым в контейнер Observable — $picture. Теперь код профиля ничего не знает о шапке, но она связана с ним наглядно и типобезопасно. Мы легко можем отследить эти связи при необходимости — Find all references в IDE, но сам код профайла остался максимально чистым и ёмким. По сути ничего не меняется, но код становится обслуживать легче. Повторю КДПВ.
▍ Ленивость
Тема небольшая и понятная, но проговорить её стоит. Проектируя модели с реактивными публичными интерфейсами, мы достигаем такого сильного уровня изоляции, что другие не зависимые, а зависящие модели могут легко подключаться и отключаться в любой момент времени, позволяя включать и настраивать dynamic imports максимально легко.
▍ Инвалидация кеша
Ещё одна тема, по которой я пройдусь лишь вскользь, но не потому, что она простая, а потому, что слишком большая и требует отдельной статьи или серии статей. Задача этой статьи — сделать архитектурный обзор, на этом и сфокусируемся.
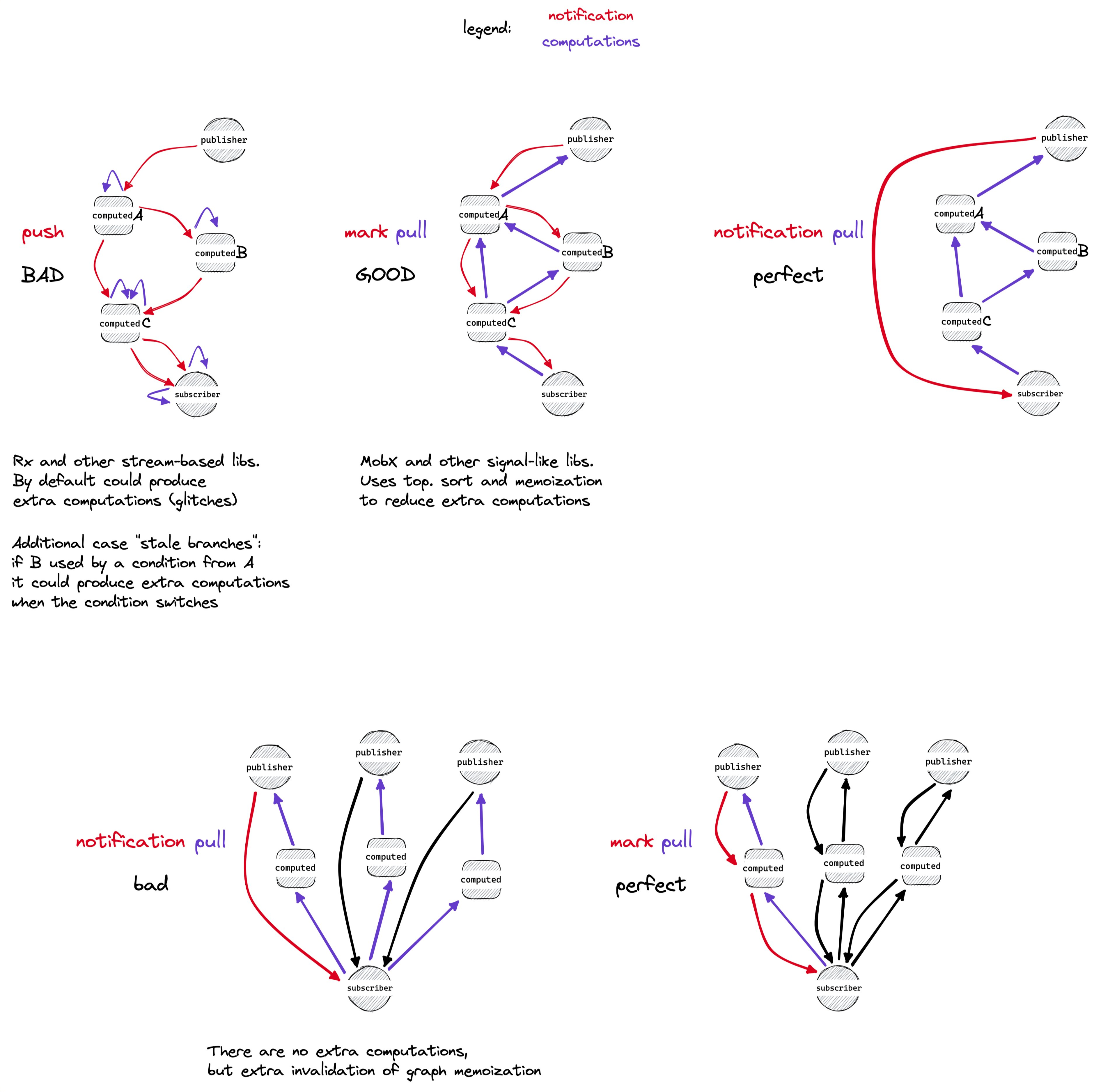
Мы знаем, что связи в нашей системе никуда не делись, но перенеслись из кода в рантайм, и рантаймом этим управляет какой-то утилитарный код. Обычно это интерфейс, который скрывает за собой список подписчиков и логику их обхода при поступлении новой информации, но как ещё это можно использовать? Я долго копаюсь в этой теме и с уверенностью могу сказать, что сложная реактивная система походит на упрощённую реализацию виртуальной машины. Тут и автоматическая очистка мусора (garbage collection), и инлайн кеши (мемоизация), и виртуальная адресация (скоупы / контексты), и ещё небольшая пачка разнообразных фич для метапрограммирования (?). Одна из таких фич лежит на поверхности — зная все места хранения данных и связи между ними, можно легко отслеживать инвалидацию данных и их связей. Главная прелесть такой оптимизации заключается в её автоматическом применении, что делает вопрос производительности всего приложения более предсказуемым.
Тема эта очень большая, на Хабре уже были хорошие статьи. Я лишь могу привести свою последнюю версию обзора возможных алгоритмов инвалидации и реакций. Вникать в это не обязательно.
▍ Что такое хорошо, что такое плохо
Интереснее всего поговорить о том, какую сложность и какие проблемы привносит реактивное программирование. Две первых лежат на поверхности: производительность и дебаг.
Мы привносим больше работы в рантайм — конструируя ещё один уровень абстракции, мы забираем память на его обслуживание (в большей степени) и в некоторых случаях вычислительную производительность (в меньшей степени). К счастью, используя современные техники автоматического кеширования (и автоматической инвалидации), мы можем отыграть потраченные ресурсы на том, что уменьшим количество вычислений в доменном коде.
Большей проблемой является дополнительная ментальная нагрузка и сложность дебага дополнительных структур в рантайме. Данные уже нельзя просто увидеть в переменной, гуляя по коду с отладчиком — нужно запросить их из реактивного контейнера, написав дополнительный код в консоли, в лучшем случае раскрыть свойство-геттер, что может иметь неприятные сайд-эффекты. Дополнительные девтулзы могут помочь в этом вопросе, но всё ещё нет библиотек, где они были бы развиты достаточно хорошо, чтобы можно было в большинстве случаев отказаться от нативного дебагера.
Самой большой проблемой, на моей практике, является непонимание, когда эту реактивность применять, а когда нет. Дело в том, что внедряя реактивные интерфейсы в наш код, мы его красим. Как асинхронные функции заставляют везде писать await, чтобы получить из них данные, так и реактивные примитивы удобно использовать тогда, когда весь код на них опирается. Соответственно, когда все ключевые сущности имеют дополнительный реактивный интерфейс, программисту кажется что именно его и нужно использовать для всех задач. Но это не так.
В своём канале я опубликовал сравнение реализации очень простой задачи на двух разных реактивных библиотеках. Одна пропагандирует описывать вообще все связи реактивно, вторая подразумевает описание локальных процессов модели императивно. Размер кода отличается, но является не самым страшным моментом. Стрелочки на скрине показывают последовательность чтения кода при дебаге — попытке увидеть последовательность его выполнения (самая крайняя левая стрелка — начало операции). На этом примере очевидно, что процессы, описанные через реактивные интерфейсы, требуют больший путь для чтения — приходится больше прыгать глазами по коду.

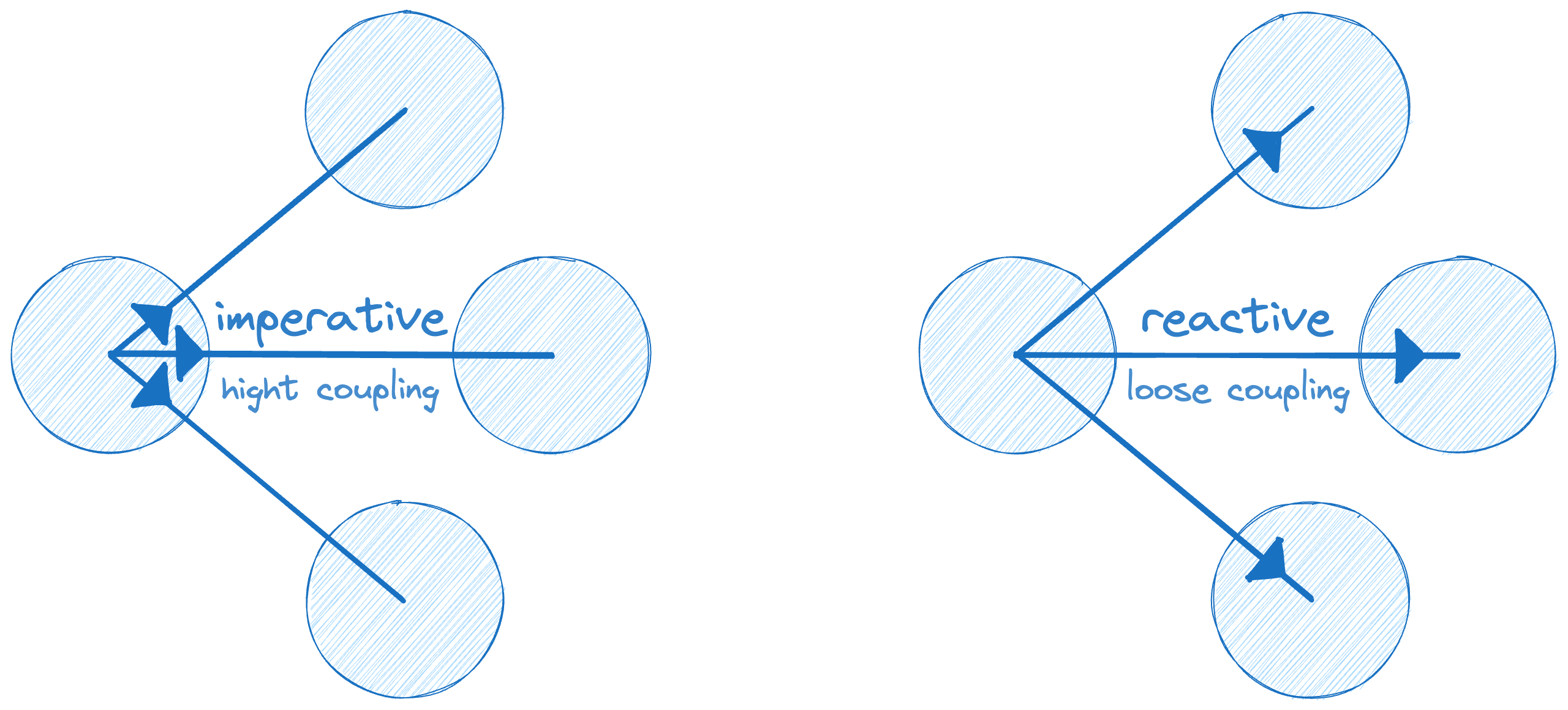
В чём же причина, почему в этом примере реактивный подход выглядит так плохо? Давайте вспомним определение, что реактивность — способ разбиения кода. Зачем разбивать код единого процесса? В этом нет никакого смысла. Помимо связанности у нас есть и зацепленность, иногда эти понятия путают, но в английском они строго определены: сoupling и cohesion. На вики есть прекрасная иллюстрация.

Модули системы должны быть отвязаны друг от друга, но внутри, наоборот, они должны быть полностью сцеплены. Мне нравится другая формулировка — процессы должны быть максимально последовательны, линейны, императивны.
Чаще всего, контейнер доменной логики — это не данные, а процессы, которые описывают условия и правила их трансформации и изменения. Это самая сложная и важная часть кода приложения. Она должна описываться максимально просто.
Бывают задачи, когда части процессной логики должны быть реактивными — на них должны как-то реагировать другие модули системы и делать это прозрачно для основного домена. Например, когда нам нужно собирать аналитику с действий пользователя и системы, делать какие-то трассировки. В таких задачах событийная модель, конечно, будет правильным решением. Но по моей практике — такие сценарии встречаются очень редко. Чаще всего достаточно завернуть наши данные в интерфейс подписки, чтобы было проще соблюдать SSoT — это потребность большинства приложений.
▍ Выводы
ФРП и Rx помогают описывать асинхронные цепочки процессов, которые можно переиспользовать, но нужно это откровенно редко. При этом Rx очень плох в управлении состоянием — связанными данными. Команда Angular так и не смогла адаптировать rxjs для оптимального управления состоянием и недавно завезла отдельный примитив для этого — сигналы.
MobX отлично справляется с управлением связанными данными, но у него полностью отсутствуют примитивы для описания реактивных процессов, решающие редкие, но также важные задачи.
Оба имеют специфическое апи и связанные с этим проблемы.
Как вы понимаете, я автор ещё одной реактивной библиотеки (Reatom), рассказывающий вам об этом, как в своей реализации учёл обе эти потребности и сделал внутренние примитивы для описания процессов (экшены) тоже реактивными. Вы можете максимально эффективно описывать состояния, зависимые состояния, императивно описывать процессы и лениво, при необходимости, подписываться на них.
Выбирайте правильный тулинг, а самое главное — делайте это осознанно. Low coupling для модулей через публичные реактивные интерфейсы. Hight cohesion — через простой императивный код для внутренней логики — процессов.
Telegram-канал с розыгрышами призов, новостями IT и постами о ретроиграх
