pgvector или как хранить и обрабатывать фичи в базе данных
На Хабре было много упоминаний pgvector в обзорах Postgresso. И каждый раз новость была про место которое где-то за границей и далеко. Многие коммерческие решения для хранения и поиска векторов в базе данных нынче не доступны, а pgvector доступен любому, тем более в самой популярной базе в России.
В этой статье покажу на практическом примере как хранить, можно кластеризрвать вектора.
Прежде всего надо установить pgvector в PostgreSQL, он доступен в виде расширения. Поскольку я работаю с базой данных из Docker, то могу просто добавить в Dockerfile строчки и пересобрать образ:
RUN git clone --branch v0.5.1 https://github.com/pgvector/pgvector.git
RUN cd pgvector && make && make installА в самой базе данных, нужно загрузить расширение:
osmworld=# CREATE EXTENSION vector;
CREATE EXTENSION
Time: 32,606 msДанные для векторов можно получить, например, из модели машинного обучения в python скрипте или ML модели в spark и вставить в таблицу с колонкой типа vector. А можно создать в SQL как гистограмму определенных категорий. В этом случае можно значения в массивах float[], integer[] или double precision[], numeric[] привести к типу :: vector
Данными для примера послужат гистограммы числа объектов детской инфраструктуры в окрестностях жилых домов в Москве. Про то как рассчитать эти данные я рассказывал здесь раньше, но в этой публикации я просто возьму готовые данные и создам из них таблицу с колонкой типа одинадцатимерный vector:
create table infrastructure_for_children_features2 as
select (row_number() over ())::integer id, null::integer cluster,
district, street, housenumber,
ARRAY[kindergarten::integer, school::integer,college::integer, university::integer, language_school::integer, music_school::integer,training::integer,sports_centre::integer,community_centre::integer,playground::integer,clinic::integer]
::vector(11) feature
from infrastructure_for_children;Так в базе создал таблицу на 30237 записей со структурой:
osmworld=# \d infrastructure_for_children_features2
Table "public.infrastructure_for_children_features2"
Column | Type |
-------------+------------|
id | integer |
cluster | integer |
district | text |
street | text |
housenumber | text |
feature | vector(11) |Теперь хотелось бы объединить их в группы по близости векторов. Опять же можно использовать нейросети, а можно использовать классические алгоритмы кластеризации — метод k-средних (k-means) или основанную на плотности пространственную кластеризацию для приложений с шумами (DBSCAN). Для метрики близости использую Евклидово расстояние. Поскольку число кластеров мне не известно, то я выберу DBSCAN и прогоню этот крошечный набор данных через него чтобы посмотреть зависимость от epsilon числа групп и число элементов не попавших в группы:
eps|clusters|not_in_cluster
0.0 75 29667
0.5 75 29667
1.0 202 28648
1.5 475 26904
2.0 928 22630
2.5 1227 17620
3.0 1173 11778
3.5 856 7605
4.0 601 4562
4.5 364 2760
5.0 232 1574
5.5 138 972
6.0 77 604
6.5 51 377
7.0 29 265
7.5 14 168
8.0 10 96
8.5 4 54
9.0 4 37
9.5 2 30На свой субъективный взгляд выберу eps=5.5 и запущу Java программу, которая заполнит колонку cluster значениями алгоритма DBSCAN для minPoints=3 и eps=5.5:
package com.github.isuhorukov;
import com.pgvector.PGvector;
import org.apache.commons.math3.ml.clustering.Cluster;
import org.apache.commons.math3.ml.clustering.Clusterable;
import org.apache.commons.math3.ml.clustering.DBSCANClusterer;
import org.apache.commons.math3.ml.distance.EuclideanDistance;
import java.sql.*;
import java.util.ArrayList;
import java.util.List;
public class Main {
public static void main(String[] args) throws Exception {
try (Connection connection = DriverManager.getConnection(
System.getenv("jdbc_url"), System.getenv("user"), System.getenv("password"))) {
connection.setAutoCommit(false);
PGvector.addVectorType(connection);
float eps = Float.parseFloat(System.getenv("eps"));
int minPoints = Integer.parseInt(System.getenv("minPoints"));
DBSCANClusterer dbscanClusterer = new DBSCANClusterer<>(eps,minPoints,new EuclideanDistance());
List features = fetchFeatures(connection,
"select id,feature from infrastructure_for_children_features");
List> cluster = dbscanClusterer.cluster(features);
saveClusters(connection, cluster);
}
}
private static void saveClusters(Connection connection, List> cluster) throws SQLException {
try (PreparedStatement clusterPs = connection.prepareStatement(
"update infrastructure_for_children_features set cluster = ? where id = ?")){
for (int idx = 0; idx < cluster.size(); idx++) {
List featureCluster = cluster.get(idx).getPoints();
for (Feature feature : featureCluster) {
clusterPs.setInt(1, idx);
clusterPs.setInt(2, feature.id);
clusterPs.addBatch();
}
clusterPs.executeBatch();
}
connection.commit();
} catch (Exception e) {
connection.rollback();
throw new RuntimeException(e);
}
}
private static List fetchFeatures(Connection connection, String query) {
List features = new ArrayList<>();
try (Statement statement = connection.createStatement();
ResultSet resultSet = statement.executeQuery(query))
{
while (resultSet.next()) {
int id = resultSet.getInt(1);
float[] feature = ((PGvector) resultSet.getObject(2)).toArray();
features.add(new Feature(id, feature));
}
} catch (Exception e) {
throw new RuntimeException(e);
}
return features;
}
static class Feature implements Clusterable {
public int id;
public double[] feature;
public Feature(int id, float[] feature) {
this.id = id;
this.feature = new double[feature.length];
for (int i = 0; i < feature.length; i++) {
this.feature[i] = feature[i];
}
}
@Override
public double[] getPoint() {
return feature;
}
}
} Для компиляции которого нужен pom.xml для maven:
4.0.0
com.github.igor-suhorukov
vectors
1.0-SNAPSHOT
11
11
UTF-8
org.apache.commons
commons-math3
3.6.1
com.pgvector
pgvector
0.1.3
org.postgresql
postgresql
42.6.0
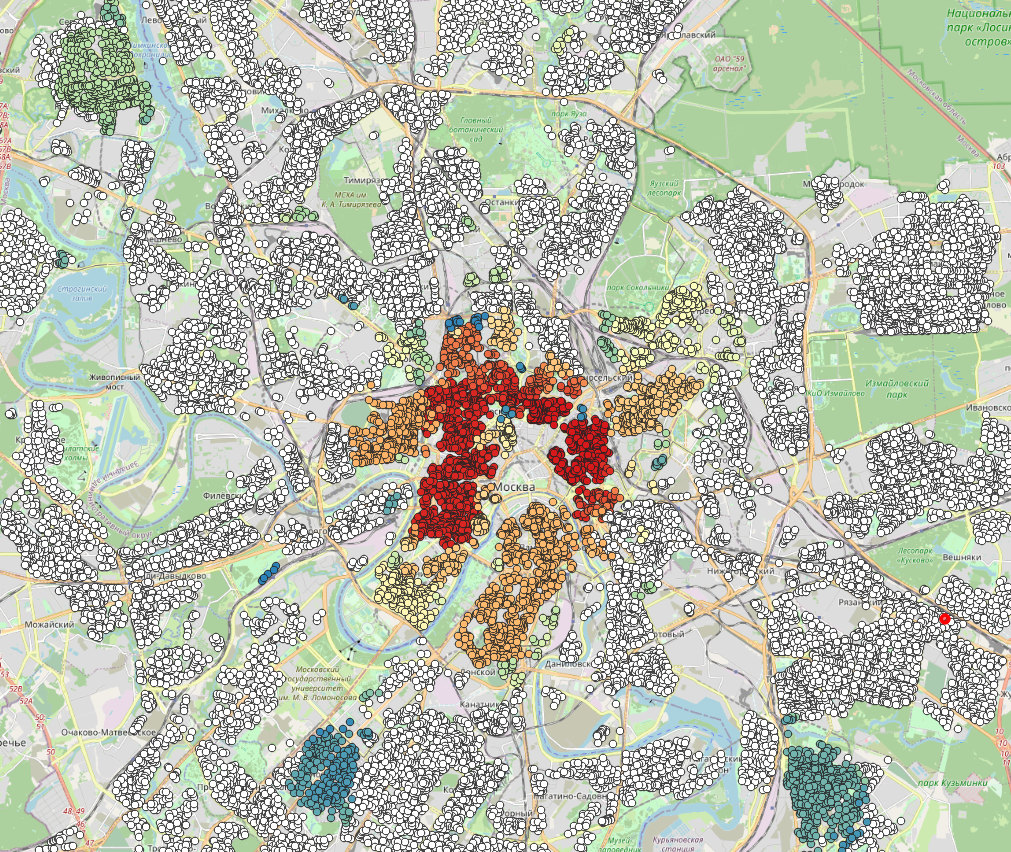
Чем же похожи эти районы, еще стоит выяснить или попробовать другие epsilon

Вывод
C расширение pgvector PostgreSQL оказалось простым в использовании и с ним можно работать не только алгоритмами машинного обучения, но и классическими алгоритмами кластеризации из Java программы.
