Как работает Kubernetes пока ты спишь
Эта статья — базовое описание того, из каких компонентов состоит Kubernetes, как он работает «под капотом». Подходит для новичков и любознательных. Это важно так как платформа сложная и:
понимание ее работы влияет на факторы разработки;
становится понятно, что можно и чего нельзя;
помогает объяснить, почему одно не работает;
или почему другое работает не так, как ты рассчитываешь.
Kubernetes (k8s) — это инструмент, который позволяет запустить приложение в нескольких экземплярах на разных узлах. (Все приложения внутри Kubernetes запускаются в контейнерах. Об этом — отдельно)
Цели:
отказоустойчивость;
простота внесения изменений в код;
масштабирование по текущим нуждам.
Если приложение очень объемное — его можно побить на независимые блоки и каждый блок развернуть как отдельный компонент.
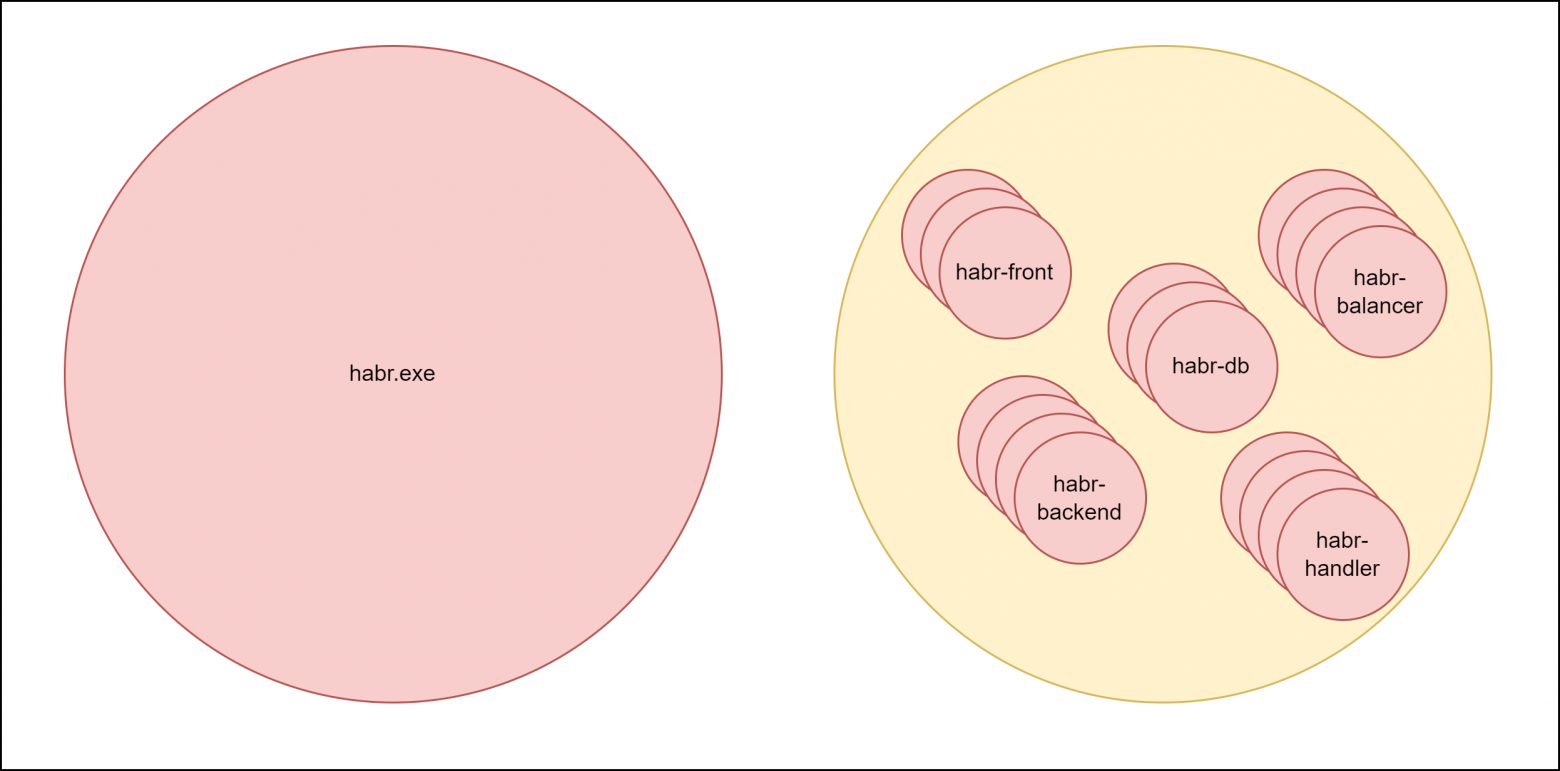
Приложение монолит vs приложение, разбитое на сервисы в Kubernetes
Идея Kubernetes: разработчики пишут код, система сама себя админит. Для этого нужно указать, какие узлы и хранилища памяти использовать и какие типы настроек k8s вы предпочитаете.
Как работает Kubernetes
Из чего состоит Kubernetes?
Условимся, что составляющие главного узла (master-ноды) мы будем называть компонентами.
Kubernetes настраивается с помощью YAML-ов и сам состоит из нескольких независимых компонентов (поддерживает свою же идею).
Сами компоненты написаны на Go.
Создавая и изменяя объекты, мы управляем архитектурой приложений.
Объект — это запущенный экземпляр ресурса Kubernetes.
Ресурс — описание сущности в Kubernetes.
То есть, ресурсы — стандартные сущности для кубера, а ресурсы, которые мы заполнили своими данными и запустили, стали объектами.
Модуль (Pod) — объект k8s, внутри которого работает приложение в контейнере.
Какие бывают ресурсы?
Deployment — без прерываний процесса обновляет старые экземпляры приложений или запускает новые непрерывно работающие экземпляры приложений.
StatefullSet — ресурс, аналогичный deployment, при этом сохраняет внутреннее состояние приложения (как для базы данных).
ReplicaSet — указывает фиксированное количество непрерывно работающих модулей (включен в deployment).
DaemonSet — отвечает за непрерывную работу единичного экземпляра приложения на каждом узле кластера.
Job, CronJob — выполняет приложение единожды, либо по расписанию, после выполнения процесс завершается.
PersistentVolume — отвечает за настройки хранилища данных.
PersistentVolumeClaim — бронирует часть хранилища данных для конкретного приложения.
Service — обеспечивает доступ через точку входа в приложение, регулирует сетевое взаимодействие компонентов и доступ к ним.
Pod — описывает единичный экземпляр приложения в контейнере, либо в нескольких связанных контейнерах; минимальный объект, которым может управлять Kubernetes, включен в ReplicaSet.
Endpoints — хранит актуальные адреса узлов с работающим приложением.
Volumes — описывает, как примонтирована файловая система в контейнер для хранения временных результатов выполнения приложения.
Secrets — хранит секреты приложения.
ConfigMap — хранит данные в формате «ключ: значение» для приложения (подходит для конфигурационных данных).
CustomResource — позволяет создавать экземпляры кастомных объектов на основе CRD.
CustomResourceDefinition — позволяет создавать кастомные ресурсы k8s (CRD).
И прочие ресурсы.
Состав Kubernetes:
master-нода — узел с административной частью, «голова» кубера;
worker-ноды — узлы, на которых работают приложения и агенты, управляющие этими приложениями.
Конечно, для тестов вообще все (и master и worker) могут работать на одном узле. Для приложений большого масштаба может быть много и master и worker нод. Но базовая идея — множество экземпляров управляются одним обработчиком, как стадо овец — пастухом.
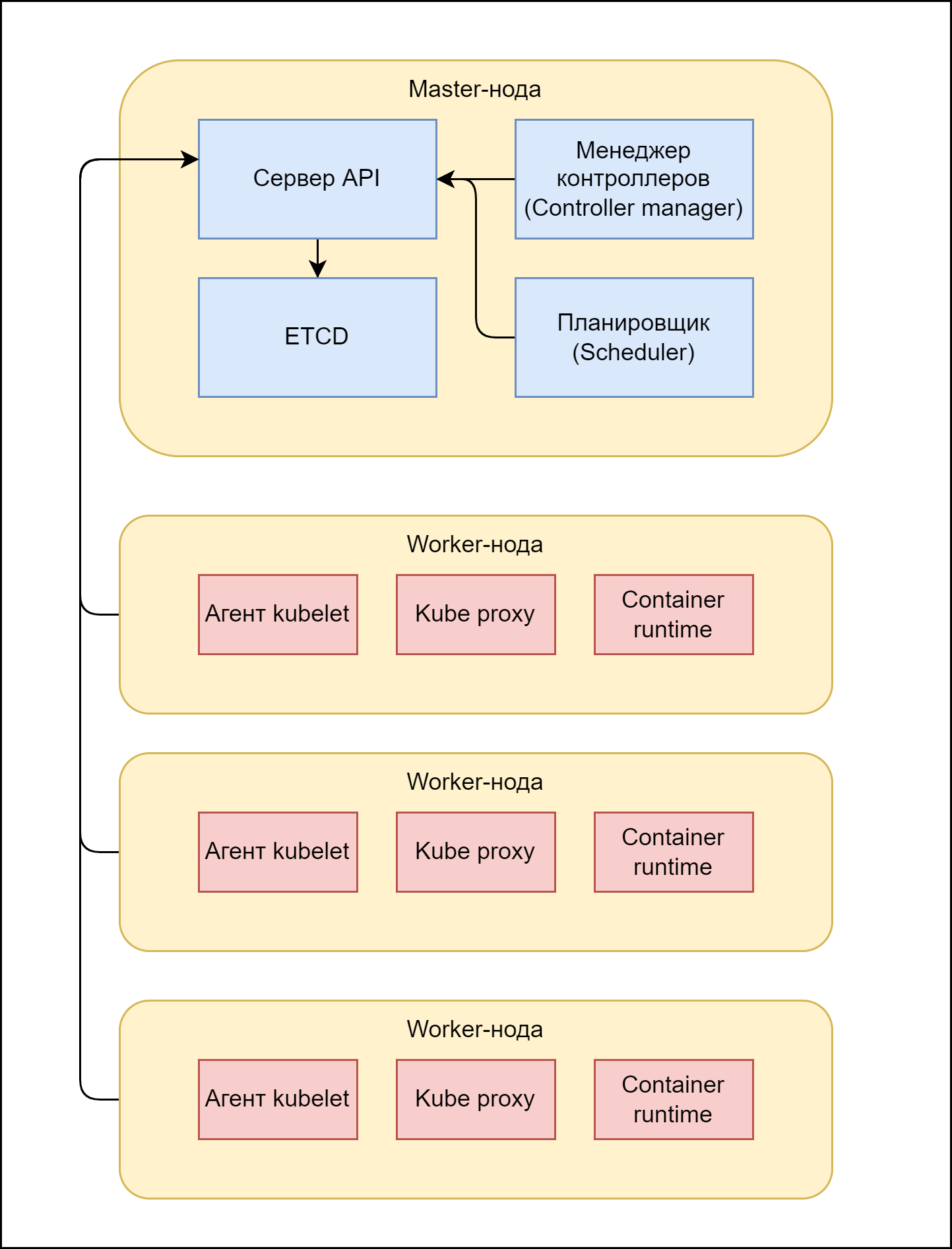
Схема компонентов k8s
Основной принцип работы k8s
Каждый объект Kubernetes знает, какое состояние для него является нормальным исходя из параметров, указанных вами в YAML-ах.
Например: какой образ брать, сколько экземпляров приложения гарантировано должно работать, сколько ресурсов на максимуме должен расходовать один экземпляр, что делать при сбое работы приложения.
Каждый объект k8s не знает, что нужно сделать; он знает, что для него норма, а что нет и запускает механизмы возвращения «в норму». Так происходит за счет асинхронной работы компонентов: каждый выполняет свою задачу и сигнализирует об изменениях и текущем статусе.
Master-node
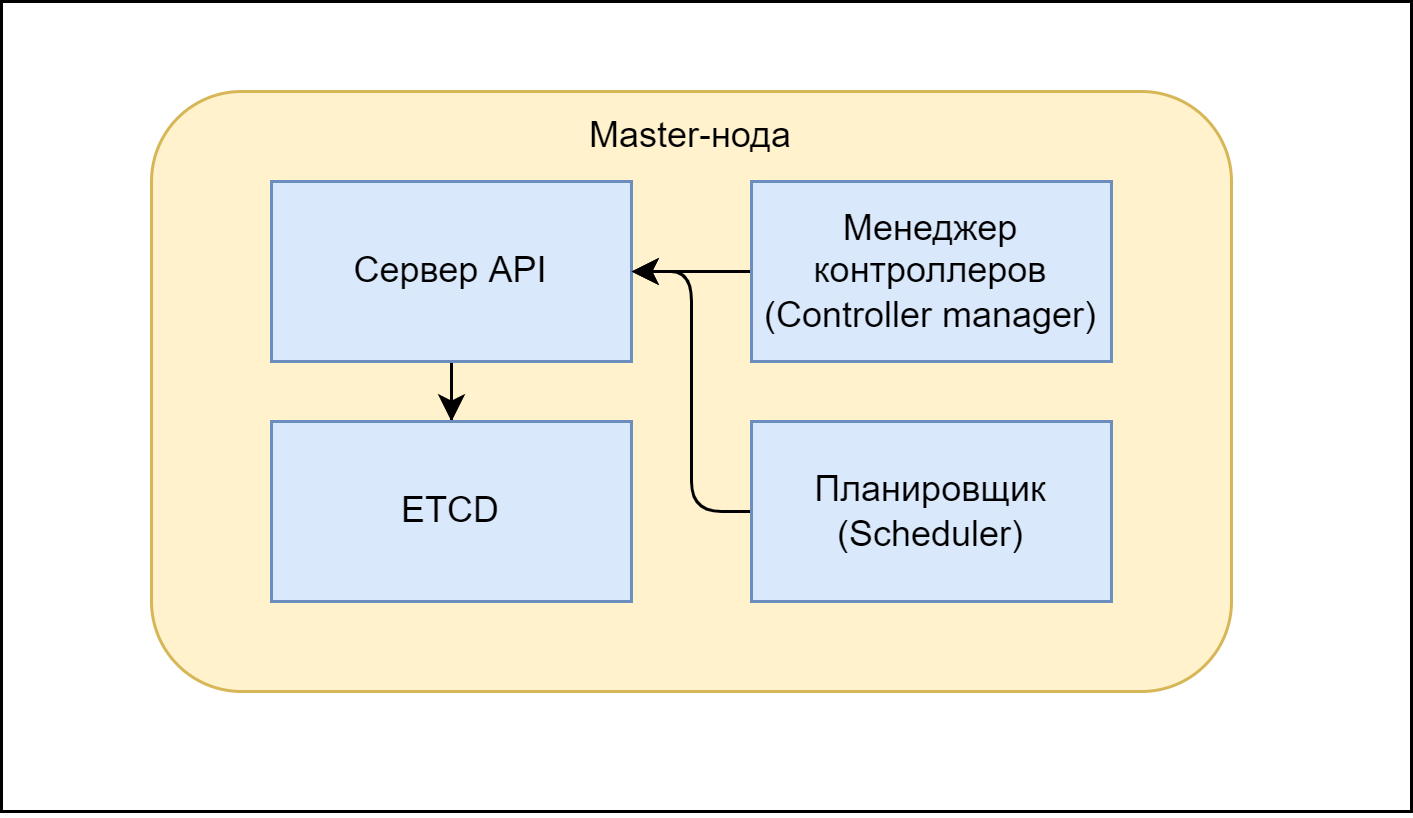
Компоненты master-node
И так разберем внутрянку master-ноды.
Она состоит из:
API-сервера;
планировщика (scheduler);
менеджера контроллеров;
распределенного хранилища etcd (то есть у нас может быть много узлов с хранилищем, не только мастер нода).
И каждый компонент master-ноды также может работать на отдельном узле.
API-Server — принимает состояния от всех компонентов, валидирует их и сохраняет в хранилище (etcd), а также позволяет остальным компонентам k8s следить за состоянием интересующих их объектов. Доступ к состоянию можно получить по REST API. Все компоненты общаются только с сервером API и ничего не знают друг о друге.
ETCD — хранилище, которое содержит состояние всех элементов. Все настройки (описания объектов) — yaml-ы с конфигурационными данными, хранятся тут. Хранилище является распределенным и все данные хранятся в нескольких экземплярах.
Менеджер контроллеров — содержит контроллеры для ресурсов, где каждый отслеживает состояние компонента и при различии текущего и желаемого состояний, приводит его в норму.
Например, контроллер видит, что приложение работает на двух узлах, а в конфигурации объекта количество узлов равно трем, тогда контроллер создает еще одно описание экземпляра приложения, но не назначает ему пока никакой узел.
Scheduler (планировщик) — ищет подходящий узел, чтобы назначить его, когда нужно развернуть еще один экземпляр приложения, затем вписывает его в yaml-манифест ресурса, с помощью которого разворачивается приложения.
Эти компоненты кубера работают со всем кластером и отслеживают состояние всех требуемых им объектов.
Разрешение споров
Можно создать несколько master-нод, тогда планировщик и менеджер контроллера будут выбираться по очереди, чтобы в каждый момент времени был запущен только один экземпляр этих объектов. Почему? Так как эти компоненты изменяют состояние объектов, может случиться так, что два планировщика назначат одному и тому же приложению два разных узла и сформируется ошибка. Этого нельзя допустить.
Для того, чтобы выбрать один экземпляр планировщика и менеджера контроллеров из нескольких используется механизм выбора лидера.
При выборе лидера компоненты не обмениваются информацией друг с другом напрямую. Все экземпляры компонента пытаются создать ресурс под названием kube-<имя компонента>. В поле holderIdentity аннотации ресурса вносится имя текущего лидера. Первый экземпляр, которому удается проставить там свое имя, становится лидером. Экземпляры соревнуются друг с другом, но победитель всегда только один. И каждый экземпляр знает, является ли он лидером, или нет. Как только он становится лидером, он должен периодически обновлять ресурс, чтобы другие экземпляры знали, что он жив.
Кстати, хранилища и сервер работают в полностью параллельном режиме. С сервером проблем не возникает, а вот к хранилищу есть вопросы. Если в один экземпляр хранилища внесли новые данные, а в другой — нет, как узнать, какое хранилище является актуальным?
Чтобы состояние etcd оставалось согласованным, используется консенсусный алгоритм RAFT, где состояние определено на наибольшем количестве узлов. Для достижения кворума требуется нечетное количество узлов.
Кроме того, при одновременной записи в один и тот же YAML применяется метод оптимистического управления параллелизмом: при внесении данных добавляется номер версии. При обновлении данных одним объектом проверяется, увеличился ли номер версии во время обновления другим объектом, и, если да, обновление отклоняется, данные нужно обновлять снова. Все ресурсы Kubernetes содержат поле metadata.resourceVersion. Если версия в этом поле не совпадает с версией в etcd, сервер API отклоняет обновление.
Worker-node
Теперь посмотрим на worker-ноду.
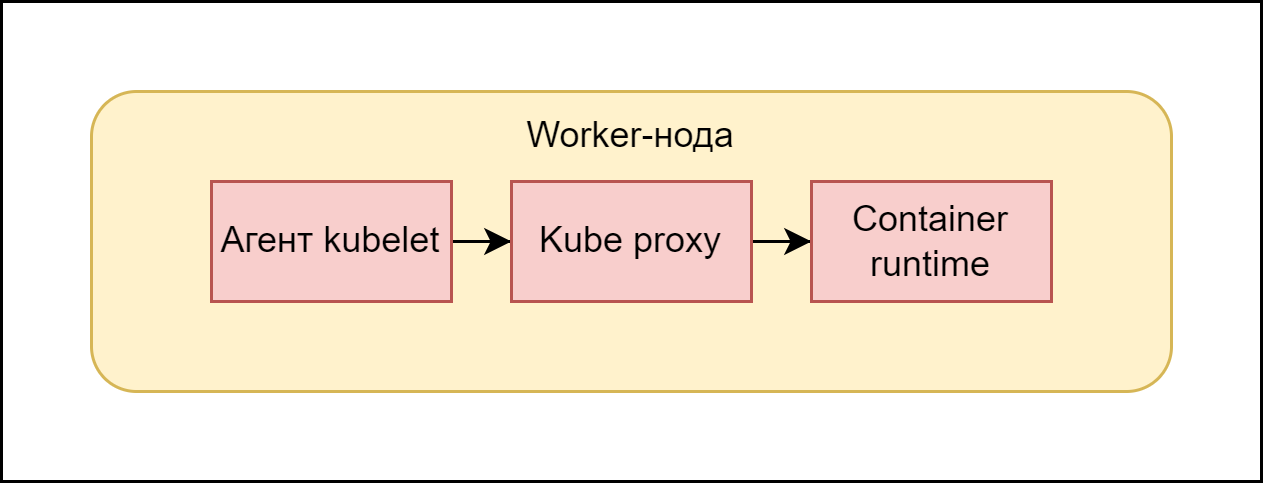
Компоненты worker-node
На каждом узле с приложением присутствует агент, который его регулирует — Kubelet
Что делает агент:
регистрирует узел;
дает команду запуска контейнера с приложением среде выполнения контейнеров (например, Docker);
регулирует состояние контейнера на узле;
при необходимости перезапускает контейнер.
Иными словами, когда описание модуля (содержащего контейнер) становится готовым на master-ноде, kubelet по этому описанию создает и запускает реальный рабочий модуль.
Также на каждом рабочем узле присутствует kube-proxy. Этот компонент:
гарантирует, что IP-подключение попадет в модуль конкретно этого приложения;
выполняет балансировку нагрузки;
kube-proxy на каждом узле работает посредством правил в iptables и не предоставляет функции проксирования запросов.
Алгоритм взаимодействия всех компонентов
Теперь давайте рассмотрим, как работает механизм Kubernetes на примере. Представим, что вам нужно обновить приложение (наиболее распространенная задача). Для этого вы создаете ресурс Deployment, который развернет для вас несколько экземпляров приложения на нескольких узлах и будет поддерживать их фиксированное количество даже в случае, если один экземпляр завершит работу (тогда Deployment развернет новый экземпляр).
Чтобы понять принцип работы, следует учесть, что ресурс Deployment включает в себя данные ресурса ReplicaSet. А ресурс ReplicaSet включает в себя данные ресурса Pod (модуль). Поэтому создание ресурса Deployment предполагает автоматическое создание двух этих ресурсов.
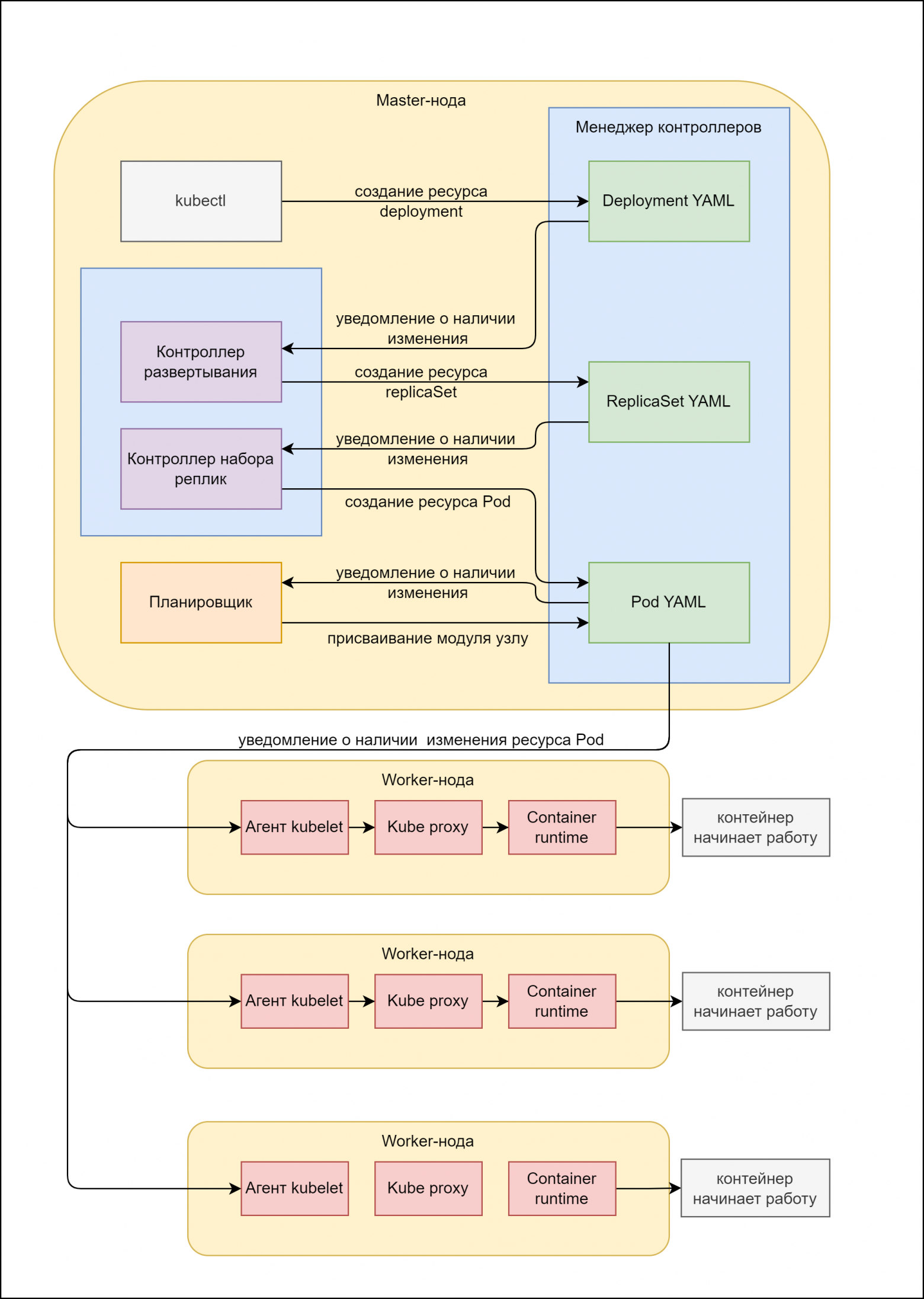
Алгоритм работы объекта Deployment
Вначале мы отправляем Deployment-манифест (YAML файл определенной структуры) с описанием нашего приложения на сервер API.
Сервер API проводит валидацию и, если YAML оказывается корректным, сохраняет его в хранилище etcd.
Контроллер Deployment (один из контроллеров, управляемых менеджером контроллеров) следит за наличием изменений для развертываний (deployment), периодически синхронизируясь с сервером API. При этом и сам сервер API уведомляет контроллер об изменениях.
Итого, контроллер Deployment замечает новый манифест развертывания, который мы отправили, и в соответствии с ним создает новые манифесты, которые хранят информацию о том, сколько экземпляров приложений нужно создать (объект ReplicaSet).
Создание этого объекта замечает контроллер ReplicaSet и создает манифесты для каждого экземпляра приложения (модуля). То есть, в соответствии с описанием создает более мелкие объекты.
Тут планировщик видит, что появились новые модули, которым не назначен ни один узел для их выполнения. Он проводит поиск подходящего узла в соответствии со своим алгоритмом и распределяет модули по узлам, внося ip-адреса узлов в манифесты модулей.
Работа на мастер-ноде закончена.Подключается агент kubelet. Он видит, что его узлу назначен новый модуль. Агент берет инструкцию к этому модулю и начинает по ней запускать модуль на узле и уведомлять об изменениях сервер API.
Далее агент отправляет изменения в работе модуля на сервер API и управляет контейнером с приложением, при необходимости, перезапуская его.
Когда модуль удаляется с сервера API, kubelet завершает работу контейнеров внутри модуля.
Подробное описание компонентов master-node
Сервер API
Это центральный компонент, который:
Предоставляет интерфейс CRUD через API RESTfull.
Хранит состояние в etcd.
Проводит валидацию объектов.
Управляет аутентификацией и авторизацией пользователей и служб. Сервер API вызывает плагины аутентификации до тех пор, пока один из них не определит отправителя путём инспектирования HTTP — запроса (сертификат, заголовок HTTP, имя или id пользователя/группы пользователей. Авторизация определяет, может ли пользователь выполнять запрошенные действия над ресурсом.
Пример действий при запросе к серверу API:
kubectl —> HTTP POST запрос к серверу API —> аутентификация —> авторизация —> валидация ресурса —> ETCD
Плагины валидации проводят следующие действия:
создание полей;
переопределение полей;
изменение родственных ресурсов;
отклонение запроса.
При чтении ресурса валидации не требуется.
Существуют также плагины контроля допуска, которые включают поля:
AlwaysPullImages — говорит всегда создавать и сохранять новый образ контейнера.
ServiceAccount — учетная запись применяется явно для всех модулей.
Namespace Lifecycle — в удаленном или несуществующем пространстве имен (namespace) образы не создаются.
ResourceQuota — контролирует, чтобы cpu, memory не выходили за обозначенные лимиты.
Сервер API единственный взаимодействует с хранилищем etcd. Остальные компоненты модифицируют состояние кластера через сервер API. Несколько запущенных серверов API могут выполнять свои задачи параллельно.
Так как данные в хранилище etcd записываются через сервер API, это приносит следующие преимущества:
более устойчивая система оптимистическое блокировки;
валидация данных;
возможность замены хранилища как отдельного компонент.
Сервер API позволяет компонентам наблюдать за изменениями в развёрнутых ресурсах. Клиенты следят за изменениями, открывая соединение HTTP с сервером API для получения потока изменений. При каждом обновлении объекта сервер отправляет новую версию всем наблюдателям объекта.
ETCD
ETCD — единственное место, где Kubernetes хранит состояние master-ноды и метаданные объектов.
Для ручного просмотра хранилища можно использовать утилиту etcdctl версии 3.
В etcd v. 3 нет каталогов, но форма ключа включает »/», что напоминает форму каталогов. Данные в etcd начинаются со значения /registry. Для просмотра содержимого нельзя использовать команду ls, но можно вывести список всех ключей, которые начинаются с префикса /registry.
$etcdctl get /registry -- prefix=trueБлагодаря механизму оптимистической блокировки, реализованному на сервере API, существует минимальный шанс на ошибку. Сервер API гарантирует, что данные в хранилище всегда действительны, изменения выполняются только авторизованными клиентами.
Планировщик (Scheduler)
Планировщик определяет, на каком узле будет работать модуль. Он обновляет определение модуля через сервер, но не предписывает запускать модуль — kubelet создает и запускает контейнера модуля.
Как планировщик выбирает узел?
Сначала происходит фильтрация для получения приемлемых узлов, где проверяются некоторые значения:
Есть ли ресурсы?
Не будет ли дефицита ресурсов в ближайшем будущем?
Соответствует ли прямому назначению по имени?
Совпадает ли селектор меток?
Есть ли порт для привязки?
Может ли быть смонтирован конкретный тип тома?
Существует ли допуск ограничения узла?
Указаны ли правила сходства или анти-сходства для узла или модуля?
Если все условия совпадают, проводится приоритизация и выбор лучшего узла (а если все хороши — первого в списке).
Можно указать кастомный планировщик для модуля в поле schedulerName (по умолчанию — default-scheduler)
Менеджер контроллеров
Менеджер контроллеров включает контроллеры:
Как видите, контроллеры совпадают с ресурсами Kubernetes. Контроллеры проверяют, что фактическое состояние системы соответствует желаемому, и выполняют операции по приведению в соответствие: создания, удаления, изменения ресурса.
Контроллеры имеют два объекта в своем составе:
Объект-информатор Informer, он прослушивает изменения в ресурсе определённого типа.
Объект Worker выполняет действия по приведению ресурса в соответствие требованиям.
Контроллеры выполняют цикл согласования фактического состояния с требуемым и записывают новое фактическое состояние в поле status в описании ресурса.
Чтобы получать уведомления об изменениях, контроллеры используют механизмы наблюдения. Чтобы не пропустить события, они дополнительно периодически выполняют запрос списка объектов для проверки к серверу API. Каждый контроллер не знает о другом контроллере, он знает только о существовании сервера API.
Примеры контроллеров:
Контроллер репликации. Операция контроллера репликации может рассматриваться как бесконечный цикл, где в каждой итерации контроллер находит нужные модули и сравнивает их количество с требуемым. Контроллер не опрашивает модули, а уведомляется механизмом наблюдения. При нехватке модулей контроллер создает новый манифест, отправляет его на сервер API и поручает планировщику и агенту kubelet назначить узел и запустить модуль.
Контроллер StatefullSet управляет модулями и PVC.
Контроллер узла синхронизирует список машин, отслеживает их работоспособность, удаляет модули с недоступных узлов.
Контроллер службы бронирует и освобождает подсистему балансировки нагрузки.
Контроллер конечных точек является активным компонентом, он обновляет список конечных точек IP-адресами и портами модулей, соответствующих заданному фильтру. Ресурс конечных точек Endpoints — автономный объект, и контроллер создает его по мере необходимости, или удаляет его при удалении службы.
Контроллер PersistentVolume выполняет поиск подходящего PersistentVolume и привязывает его к PersistentVolumeClaim, а после высвобождения либо оставляет как есть, либо удаляет, либо очищает данные ресурса.
Дополнительные компоненты Kubernetes
DNS-сервер
Модули внутри кластера k8s по умолчанию настроены на использование внутреннего DNS-сервера кластера. Это позволяет модулям легко отыскивать службы по имени или IP-адресам.
Модуль DNS-сервера предоставляется через службу kube-dns. IP-адрес службы указан в качестве nameserver в файле /etc/resolv.conf внутри каждого контейнера. Модуль kube-dns использует механизм отслеживания сервера API для наблюдения за изменениями служб и конечных точек и обновляет свои записи DNS с каждым изменением.
Контроллер Ingress
Ingress обеспечивает доступ к модулю через внешний IP-адрес и позволяет балансировать нагрузку трафика.
Контроллер Ingress запускает обратный прокси-сервер (например, Nginx) и держит его сконфигурированным в соответствии с ресурсами Ingress, Service и Endpoints. Этот контроллер должен наблюдать за данными ресурсами и изменять конфигурацию прокси-сервера каждый раз, когда один из них изменяется.
Контроллер Ingress перенаправляет трафик в модуль службы напрямую, а не через IP-адрес службы. Это влияет на сохранность клиентских IP-адресов, когда внешние клиенты подключаются через контроллер Ingress.
DNS, Ingress не только наблюдают и изменяют ресурсы, но и принимают клиентские подключения.
Заключение
Все вместе эти компоненты обеспечивают непрерывную и стабильную работу приложений, обеспечивая возможности:
простого подключения к приложению;
легкого изменения приложения «на лету»;
обеспечения любого количества экземпляров приложения;
добавления нужных данных в приложение посредством Kubernetes;
предотвращения конфликтов записи и проблемы гонки в параллелизме;
легкое администрирование системы;
и другой богатый функционал, делающий процесс разработки менее болезненным и незаметным для внешних клиентов.
Эта статья содержит и базовое описание работы Kubernetes и более неочевидные механизмы регулирования процессов внутри системы. Возможно, базовые вещи будет полезно почерпнуть из нее на начальных этапах знакомства с этим фреймворком, а детали сэкономят массу времени при более глубоком изучении платформы.
Статья является результатом личного опыта взаимодействия с платформой и анализом нескольких книг, описывающих работу Kubernetes. Спасибо за прочтение!
