Разоблачаем эффект Даннинга-Крюгера — теперь с регрессией
Кратко:
В оригинальном исследовании показано совсем не то, что люди думают.
Оригинальное исследование так криво сделано статистически, что просто не удовлетворяет критерию фальсифицируемости. Простыми словами — генератор случайных чисел демонстрирует такой же результат.
Единственное, что этот эффект демонстрирует — это любовь людей к красивым историям (а математику никто не любит … и вообще есть ложь, большая ложь и статистика).
Существующие статьи на Хабре
Я решил, что не могу не писать после прочтения вот этого поста. Автор почему-то пишет про автокорреляцию, но понимает под этим что-то своё и в целом пост оценен в комментариях критически. Автокорреляция — это термин относящийся к последовательным (чаще всего временным) рядам и к делу отношения не имеет.
Далее я поискал, что ещё писали на Хабре в последнее время. И тут я приуныл.
Просто посты по поводу эффекта Даннинга-Крюгера (далее эффект Д-К):
Как не зависнуть на пике глупости и преодолеть долину отчаяния? Разбираем эффект Даннинга-Крюгера
Эффект Даннинга-Крюгера
Даннинг с Крюгером, Сократ и круги знаний
Попытки критики:
Эффект Даннинга-Крюгера — не то, чем кажется или Почему деление на умных и глупых — само по себе глупость Тут суть претензий психологическая. Людям нравится этот эффект и это тоже пример когнитивного искажения. По сути это тоже поддерживающий пост.
Разоблачаем Эффект Даннинга-Крюгера. Статистический артефакт, пример автокорреляции — тут ад с автокорреляцией и ничего не понятно.
Чем является и чем не является эффект Даннинга-Крюгера — адекватная статья, но слишком краткая и видимо никто ничего не понял.
Я-то думал стюардессу уже закопали… Придется самому.
Расхождение исследования и интерпретации
«Долину отчаяния» по факту выдумали. Самооценка в исследовании строго растёт с результатом тестов. Коэффициент в регрессии сильно ниже единицы и поэтому можно разводить рассуждения об относительной пере- и недо-оценке в сравнении с реальным результатом теста.
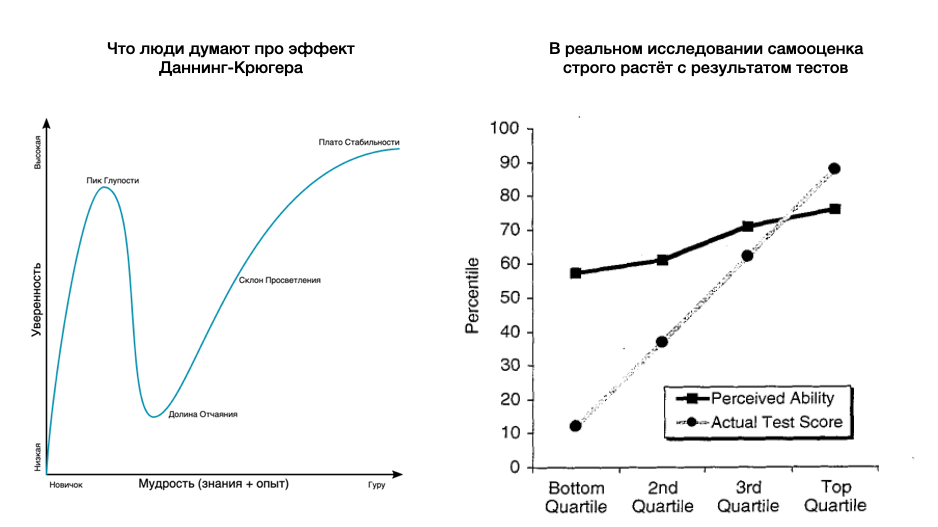
Screenshot 2023–12–01 at 12.12.38 PM.png
Источники для коллажа: Даннинг и Крюгер (1999) и Даннинг с Крюгером, Сократ и круги знаний
Нефальсифицируемость всего исследования
Критиковать оригинальное исследование с точки зрения статистики стали довольно быстро. Первый хороший разбор вышел через три года у Krueger and Mueller (2002). Но кому нужны факты, когда такая тема для графоманства пропадает.
В эксперименте по сути сравниваются два метода измерения неких способностей:
Если оба метода работают нормально и без искажений, но имеют некую погрешность (самую нейтральную — просто нормально распределённый шум), то мы чисто математически должны получить коэффициент регрессии ниже единицы. Это явление называется регрессия к среднему (Regression toward the mean) и известно уже более ста лет.
Отступление — откуда есть пошло слово регрессия
В 1889 году Френсис Гальтон построил график зависимости роста сыновей от роста отцов. И получил коэффициент регрессии в районе 2/3. То есть сыновья очень низких отцов были выше, а сыновья очень высоких отцов были ниже (ничего не напоминает?). Гальтон использовал термин регрессия (в смысле роста у следующих поколений) и так этот термин вошёл в статистику. Сегодня все знают про регрессию, а вот про «регрессию к среднему» знают единицы.
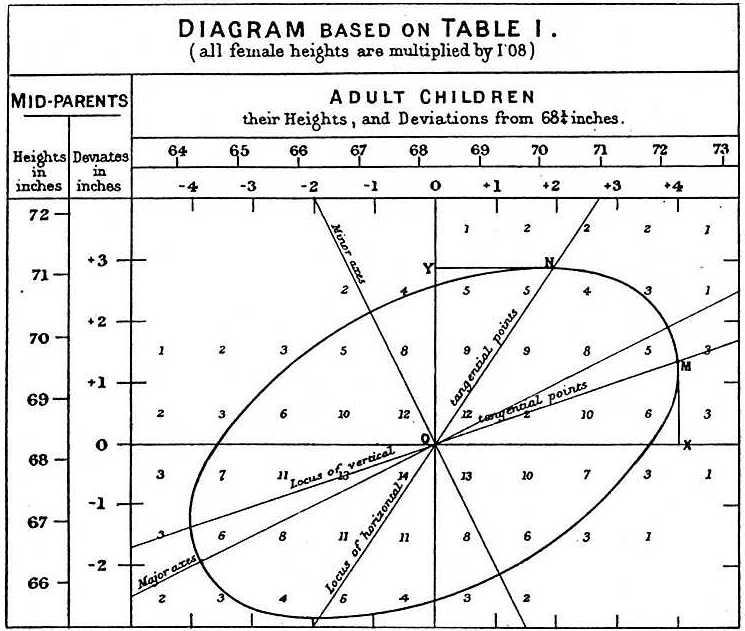
Untitled
Источник: википедия — Regression toward the mean
Назад к нашему эффекту Д-К. Само наличие погрешности в двух измерениях уже гарантирует, что коэффициент будет ниже единицы.
То есть, если бы вместо вопроса про самооценку был просто другого типа тест на ту же способность, то мы бы получили похожий результат — испытуемые хорошо справляющиеся с тестом А относительно хуже справляются с тестом Б и можно начинать писать бестселлер про… психологические причины этой разницы между тестами.
Без формул проще всего объяснить так — лидеры в первом измерении реально сильны + им повезло. А во втором измерении им не повезло и они откатились в середину. И аналогично с худшими результатами.
Никакого нового знания по результатам такого эксперимента мы не получаем. Результат запрограммирован в дизайне -, а значит есть проблема с фальсифицируемостью. Либо нужно демонстрировать, что эти тесты имеют низкий уровень шума — проводить повторные измерения всякие и так далее. Я такого не нашёл по факту.
Демонстрирую «эффект» на генераторе случайных чисел
Я ввожу исходный (верный) уровень способностей (нормальное распределение со средним 50 и стандартным отклонением 5) и два раза его «измеряю» прибавляя нормально распределённый шум (среднее 0 и стандартное отклонение 10). Одно измерение можно назвать «тест», а другое «самооценка». Но это только названия.
import pandas as pd
import numpy as np
from statsmodels.formula.api import ols
import plotly.express as px
import plotly.graph_objects as go
# Model
df = pd.DataFrame(np.random.normal(50, 5, 500), columns=['underlying_ability'])
df['test'] = df['underlying_ability'] + np.random.normal(0, 10, 500)
df['self_estimate'] = df['underlying_ability'] + np.random.normal(0, 10, 500)
# Fit regression
model = ols("self_estimate ~ test", df).fit()
print(f"self_estimate = {model.params['Intercept']:.2f} + {model.params['test']:.2f}*test")
# Plot data and regression
df['regression'] = model.params['Intercept'] + model.params['test']*df['test']
fig1 = px.scatter(x=df['test'], y=df['self_estimate'])
fig2 = px.line(x=df['test'], y=df['regression'])
fig = fig2.update_traces(line_color='red', line_width=2)
fig = fig = go.Figure(data=fig1.data + fig2.data)
fig.update_layout(
autosize=False,
width=600,
height=600,
plot_bgcolor='rgba(0,0,0,0)'
)Получаем график почти неотличимый от оригинального:
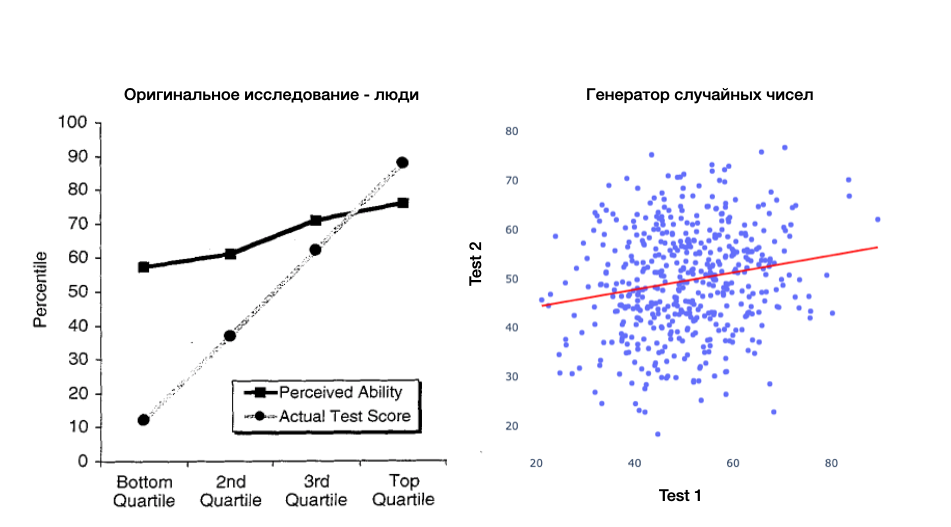
Screenshot 2023–12–01 at 1.18.12 PM.png
Заметки
Можно заметить, что моя линия регрессии чуть ниже оригинальной (в районе 50, а не 65). Одно из объяснений — это общая склонность завышать свою оценку вне зависимости от способностей. Но я сомневаюсь, что тут есть что-то важное. Скорее всё зависит от сеттинга для эксперимента. Студентам в опросе могло быть просто стыдно совсем уж низкие баллы писать и сдавать профессору.
Ещё люди копали в сторону ограничений шкалы измерений. Написавшие на 99 из 100 баллов тест по сути могли в самооценке ошибаться только в сторону ниже. И то же самое с худшими студентами. Но мне думается, что это детали. У меня выше получилось неплохо и с нормальным распределением без границ шкалы.
Моё личное мнение по поводу поведенческой психологии как науки
В последнее время эту дисциплину кто только не пинал.
Лет десять назад были обвинения в нереплицируемости (базовая статья Ioannidis 2005) и в p-hacking (базовая статья Simonsohn U 2014)
В последнее время крупные авторитеты получают обвинения в прямой фабрикации данных — см. Дэн Ариэли (лучше читать hacker news) и Франческа Джино (лучше читать оригинальный разбор). Причём я помню как ещё лет 10 назад над Ариэли в кулуарах другие исследователи прямо ржали. Но про фальшивые данные никто не подозревал.
Уже половину книжки Канемана «Думать быстро и медленно» можно вычёркивать (лучше читать такой разбор).
Что вообще происходит? Далее строго моё мнение.
Неадекватная экстраполяция результатов. Даннинг и Крюгер проводят письменный тест среди студентов-психологов Корнельского университета на знание английской грамматики, понимание юмора и на умение решать логические задачки. А результаты экстраполируются на все виды знаний и способностей без привязки к письменным тестам и на всех людей подряд в любых ситуациях. Главное чтобы было интересно читать.
Неадекватное описание исследований. На поведение человека влияет куча факторов, которые обычно в статье не описаны. Как и каким тоном давались инструкции? Что в это время было в новостях? Это всё, думаете, не влияет на результат?
Я, помню, работал в опросном бизнесе. Там есть некий протокол как отлавливать интервьюеров, которые рисуют анкеты. Он работает. Но даже после него я всегда строил зависимость результатов от идентификатора интервьюера. И всегда были «звёзды», которые несмотря на инструкцию читать строго формулировку вопроса — «поддерживаете ли Вы…» — умудрялись транслировать своё мнение просто через интонацию. Да, я слушал записи, когда были опросы по телефону.
Как это работает в условиях исследований с двойным ослеплением? У меня есть гипотеза, что многие «эффекты» можно просто разворачивать управляя уровнем внимания респондента. Просто задавая некий фрейм «отвечай быстро не думая» или напротив «думай, тут вопрос с заковыркой.» Но проверять я её конечно не буду…
