Оптимизация каналов связи для добычи полезных ископаемых на севере России

Когда мы ехали на монтаж, рядом доставали трактор из оврага
Есть такие суровые русские мужики, которые добывают разные полезные ископаемые, которые подло сгруппировались в труднодоступных местах. Часто просто добраться и вытащить их из-под земли бывает очень и очень дорого. Поэтому развитая инфраструктура на месте добычи — явление редкое. Так вот, на Дальнем Востоке во многих местах оптоволокно — всё ещё раздел научной фантастики, а провод встречается в дикой природе только если принести его с собой в руках.
Связь там сделана через спутник. Соответственно, требования по каналу растут, но расширяться очень больно и дорого — спутниковый ресурс не самый масштабируемый, и гигабайты через него гонять не получится.
Мы решали задачу оптимизации канала за счёт сжатия трафика и приоритезации приложений в каналах, чтобы самое важное всегда ходило первым. Получился целый сетевой детектив.
Вводная
Есть канал на спутнике, и расширять его дорого. Есть решения Riverbed, которые позволяют сжимать трафик, оптимизировать обмен на уровне протокола (чтобы не передавались избыточные данные), плюс кэшировать куски словаря сжатия на себе. Всё это в целом может дать от 20% до 80% выигрыша по полосе в зависимости от того, что за данные и как летают.
Началась задача с того, что нас попросили просчитать возможность приоритезации критичного трафика, чтобы он выделялся из всего обмена, что есть на точках. После выяснилось, что оптимизация тоже очень выгодна, потому что за поднятый спутниковый канал нужно платить постоянно, а за железо — только один раз.
Обследование
Архитектура обмена — несколько «колёс со спицами» с хабами в крупных городах. Например, в Иркутске, Магадане и Москве. На хабы подходит оптика или медь. На удалённых точках на добывающих предприятиях в 90% случаев используется станция спутниковой связи, есть буквально пара радиорелейных линий и ещё на нескольких точках оптикой делятся те, кто так или иначе тащил её мимо ради магистрали.
Поставили систему диагностики, собирающую данные.
Приложений много, а пользователей мало, основной обмен — технический. Вот пример того, что может работать на одном из предприятий где-то далеко-далеко за снегами:
Распознанное приложение |
Интерпретация наблюдаемого трафика |
Microsoft-DS Active Directory |
Обмен файлами средствами операционной системы Windows (SMB Direct). |
Microsoft Terminal Server (RDP) |
Удаленный рабочий стол |
HTTPS |
Outlook Web Access |
SMTP |
Пересылка почты между серверами Exchange |
MS SQL |
Обращения к MS SQL серверу |
netview-aix-2 |
Клиентское подключение 1С |
domain |
Служба доменных имен (DNS) |
webcache |
Доступ в Интернет через прокси-сервер |
Всё это, в целом, хорошо сжимается, за исключением DNS и доступа в Интернет. Ещё есть Lync, VoIP и видеоконференцсвязь, которая в силу особенностей не сжимается, зато требует приоритета №1 — особенно, когда главу объекта вызывают на ВКС-совещание.
По большей части обыденный трафик — это передача файлов, real time трафик, так же есть данные контроля добычи, учёта и сырые данные с датчиков. Многие приложения, которые отправляют информацию, «болтливые», то есть отправляют много пакетов там, где можно было бы обойтись одним. Соответственно, такие вещи решаются Riverbed достаточно просто.
Вот, сравните как работают приложения до и после оптимизации:

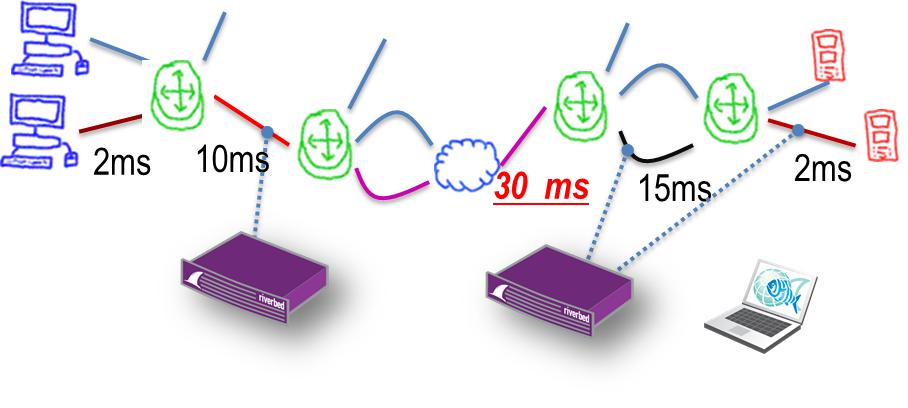
Например известный всем «болтливый» протокол CIFS, который используется для доступа к файлам. Файл размером 20-40 Мбайт в локальной сети будет загружен за считанные секунды. Если же загрузка файла осуществляется из удаленного офиса по WAN каналу связи, как показано на схеме выше, время загрузки может быть увеличено до 5 и более минут.

Чтобы увеличить время загрузки в удаленный офис, нужно свести к минимуму количество проходов в обе стороны.
Для приоритезации трафика нужно было разбирать пакеты — пришлось поднимать аналог DPI и смотреть на 7-м уровне, поскольку просто разбрасывать по используемым портам было явно недостаточно — один и тот же тип трафика мог быть как показаниями важного датчика, так и болтливым обменом чего-то некритичного. Или вот надо было выделять сессии Exchange и отдавать под них полосу ещё на этапе установления соединения.
До этого, конечно, попробовали просто на роутерах, но там очень сложный контроль, плюс всё это сложно поддерживать конфигом. Чтобы было полное понимание — в нашем случае в центральном офисе в Москве нет команды поддержки. Основная сидела на равноудалённом расстоянии от точек добычи и головной организации. Место так выбрано из-за часовых поясов — есть шансы застать рабочий день и там, и там. Есть и промежуточная команда для оперативных задач, но никому из этих людей совершенно не надо было создавать столько проблем для ручных настроек. И без гарантии правильной работы в будущем.
Железо
Тут надо прерваться и сказать, что вся эта история гладко звучит только на бумаге. Сложности, конечно, были — начиная от такой банальной вещи как подключение зеркалирующих устройств анализа трафика. Просто представьте себе добывающее предприятие где-то очень-очень далеко, куда нет дороги. Добраться туда по земле можно только несколько месяцев в году. Соответственно, железо после отправки ещё где-то минимум 1 месяц добирается до точки. Как доберётся — его нужно подключить, причём подключать будет кто-то местный из службы поддержки пользователей.
Подключалось всё это, к счастью, в разрыв на выходе из серверных через байпасс, поэтому работы шли достаточно просто. Единственный момент — нужно было дать все инструкции ДО того, как инженер на точке дёрнет кабель, потому что та же телефония была завязана именно на него.

Оптимизатор — самый низ
В итоге была отработана такая схема:
- Мы получали железо на свой склад в Москве
- Делали диагностику и преднастройку, чтобы можно было сразу после подключения управлять устройством.
- Отправляли по филиалам
- Дальше играли в «Аватара», помогая специалистам на месте делать непонятные для них движения с кабелем. Иногда всё это наблюдали по видеопотоку с большим лагом. Смешно никому не было.
- Позже, через год, пришла вторая часть квеста — с некоторых точек измерительное оборудование надо было снять и поставить на другие.
Опять же, романтика Севера — один ЦОД доехал до места на салазках, хорошо хоть не собаками. ЦОД на салазках, да-да.
Продолжение
Итак, мы увидели какой трафик ходит и в каких объемах. С какими задержками, что бизнес-критично, что нет. Что для компании важно разметили, что можно «зарезать» — «зарезали», если в полосе был важный трафик. Выделили 4 класса обслуживания для разных типов информации, согласовали их с операторами связи. Собственно, мы этот трафик «раскрашивали» — а у оператора связи на месте делался шейпинг. Была ещё особенность в том, что на каждом объекте свой оператор связи: где-то нужно было заплатить дополнительно за услугу, где-то просто не было технической возможности шейпить правильно, приходилось укладываться в меньшее количество классов обслуживания и придумывать разные хаки.
Правили проблемы сетей. Наши зеркалирующие сенсоры стали идеальным средством отладки. Сенсоры ставились по всем регионам, имели копию трафика — можно было взять копию трафика с нескольких точек из филиала и из центра и сравнить. Получалось, что у нас была возможность зафиксировать каждый пакет здесь и там. В результате мы могли оценить что происходит у оператора связи с каждым из них реально. Вот пример:
Пример проведения диагностики у заказчика:
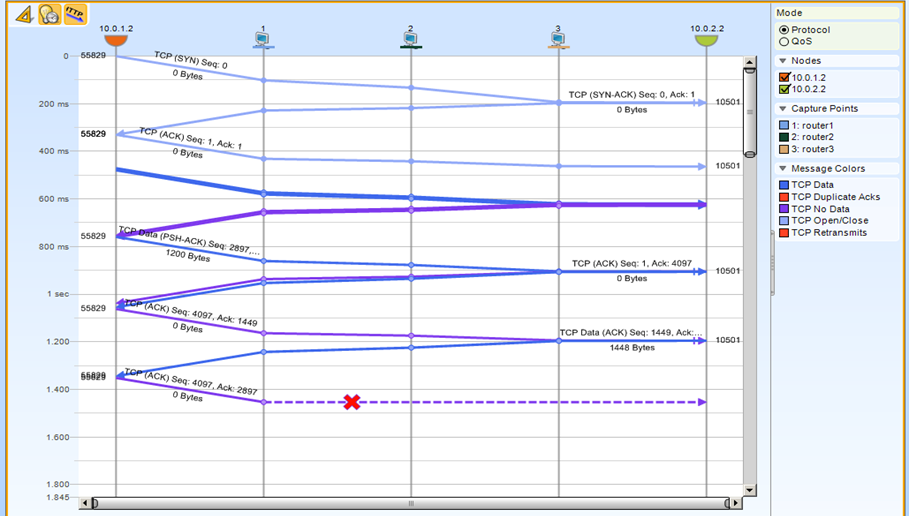
Видим на каком хопе потерялся пакет на пути от сервера к клиенту
Был случай — приехал большой босс в филиал и говорит, мол, что-то у вас тут один терминал специфический отваливается. «Прихожу с утра на включенную машину — а он отвалился». Инженер на месте просто подключился к сенсору и забрал последние пакеты сеанса, чтобы посмотреть, почему завершилось соединение. За полчаса в пакетах нашлось, что клиент сам обрывает соединение по таймауту. В пакете написана причина — и он забил её код в Google — и сразу увидел настройку, чтобы не разрывалось.
Какое железо?

Устанавливались разные модели оптимизаторов начиная от младших, заканчивая старшими — в зависимости от ширины канала связи и количества пользователей и информационных ресурсов на площадке. Подробнее про решения Riverbed я писал здесь и вот здесь в теории.
Какая итоговая экономия трафика?
Вот пример с одной из точек:
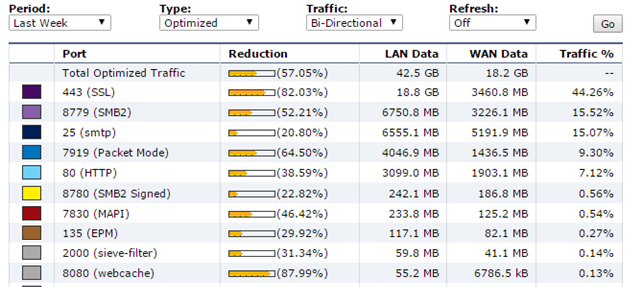
Total optimization здесь равен 57,05 за неделю для оптимизированного трафика на одном из крупных узлов.
Собственно, вот такая история. Если интересны детали конкретно по вашему проекту — могу примерно посчитать по почте AVrublevsky@croc.ru. Ну и готов ответить на любые вопросы здесь или в почте.
