О дублировании тайлов веб-карт
Для организации работы веб-карт по технологии Slippy Map требуется организовать тайловое хранилище, в котором могут предварительно рендериться (генерироваться) тайлы в заранее заданном контексте карты, либо использоваться набор сервисов для генерации тайлов по запросу, либо некий симбиоз из первых двух подходов.
Первый подход имеет недостаток — требуется слишком большое хранилище для тайлов. Так, по данным OpenstreetMap по состоянию на март 2011 года требовалось 54ТБ места для хранения тайлов. По моим подсчетам для актуальных данных на июнь 2015 года эта цифра уже составляет около 100ТБ (это только оценка, на реальный эксперимент я не решился) для хранения тайлов масштабов 0…17. Такой «прирост» оценок вызван тем, что за прошедшее время данные OpenStreetMap существенно пополнились, детализировались районы, которые в марте 2011 года были пустыми. Нельзя также списывать со счетов неоптимальность сжатия (в моем случае по сравнению с OpenStreetMap) формата PNG (у меня средний размер тайла составляет 4.63КБ против 633 байт OpenStreetMap’а в марте 2011 года), сложность стиля рисования карты mapnik’ом и прочие мои нюансы. В любом случае требуется ОЧЕНЬ много места для тайлового хранилища, что может себе позволить далеко не каждый сервер. Ситуация усугубляется еще и тем, что для блочных файловых систем маленькие по размеру тайлы расходуют целый блок (тайл размером 103 байта может занимать целый блок, например, 4КБ), что приводит к неэффективному расходованию физического пространства жесткого диска. Для большого количества тайлов (для крупных масштабов карт) в рамках одной директории может еще наблюдаться проблема невозможности хранения требуемого количества файлов либо директорий больше, чем позволяет файловая система. Но при всем при этом данный поход обеспечивает комфортное время выполнения запроса на отдачу тайла.
Второй подход хоть и не требователен к емкости тайлового сервера, но требует организовать и поддерживать несколько сервисов (PostgreSQL, Postgis, HStore, mapnik, renderd, mod_tile, apache), которые бы надежно генерировали и отдавали тайл запрашиваему клиентскому сервису. Также требуется периодически подчищать кэш тайлов. Иными словами платой за небольшую емкость жесткого диска тайлового сервера является сложность архитектуры и значительное время выполнения запроса на отдачу каждого конкретного тайла (по моим подсчетам до 500 мс только для 1 клиента, для высоконагруженного сервиса это время может вырасти до неприемлемых величин).
В данной публикации я не касаюсь вопросов архитектуры тайлового сервера. В конечном счете Вам решать как Вы будете строить свой собственный сервис веб-карт, отталкиваясь от «железа» Вашего сервера. В статье я лишь хочу обратить внимание на некоторые особенности тайлового хранилища, зная которые Вы можете оптимально построить свой сервис веб-карт.
К слову, я решил строить свой сервис веб-карт на основе смешанного подхода. Дело в том, что география запросов пользователей моего веб-сервиса достаточно четко определена. Т.е. я заранее знаю контекст карты, который будут запрашивать пользователи, что позволяет мне пререндерить тайлы в данном контексте карты. В моем случае объем необходимых тайлов составил 511ГБ для масштабов 3…17. При этом для масштабов 3…13 я сгенерировал все тайлы, не отталкиваясь от заранее известного мне контекста карты. Привожу статистику по количеству и объемам сгенерированных тайлов по масштабам карты.
| Масштаб | Всего сгенерировано тайлов | Всего тайлов для масштаба (4^zoom) | Доля в % от общего количества тайлов | Объем сгенерированных тайлов | Общий объем тайлов для масштаба | Доля в % от общего объема тайлов |
|---|---|---|---|---|---|---|
| 3 | 64 | 64 | 100 | 1.3М | 1.3М | 100 |
| 4 | 256 | 256 | 100 | 4.3М | 4.3М | 100 |
| 5 | 1 024 | 1 024 | 100 | 15М | 15М | 100 |
| 6 | 4 096 | 4 096 | 100 | 50М | 50М | 100 |
| 7 | 16 384 | 16 384 | 100 | 176М | 176М | 100 |
| 8 | 65 536 | 65 536 | 100 | 651М | 651М | 100 |
| 9 | 262 144 | 262 144 | 100 | 1.7Г | 1.7Г | 100 |
| 10 | 1 048 576 | 1 048 576 | 100 | 6.1Г | 6.1Г | 100 |
| 11 | 4 194 304 | 4 194 304 | 100 | 18Г | 18Г | 100 |
| 12 | 16 777 216 | 16 777 216 | 100 | 69Г | 69Г | 100 |
| 13 | 67 108 864 | 67 108 864 | 100 | 272Г | 272Г | 100 |
| 14 | 279 938 | 268 435 456 | 0.10 | 3.2Г | 1.1Т | 0.29 |
| 15 | 1 897 562 | 1 073 741 824 | 0.18 | 15Г | 4.35Т | 0.34 |
| 16 | 5 574 938 | 4 294 967 296 | 0.13 | 34Г | 17.4Т | 0.19 |
| 17 | 18 605 785 | 17 179 869 184 | 0.11 | 94Г | 69.6Т | 0.13 |
| Всего | 115 842 662 | 366 503 875 925 | 0.51 | 511Г | 92.8Т | 0.51 |
Самое первое, на что я обратил внимание при разработке веб-карт (помимо непомерных емкостей) — это то, что очень часто картинка повторяется. Например в океане два соседних тайла выглядят одинаково голубыми. Но визуально одинаковые и бинарно одинаковые тайлы — это разные вещи.
Проверяя свою гипотезу, я сравнил контрольные суммы MD5 двух соседних тайлов и они оказались одинаковыми.
root@map:~# md5sum 10/0/0.png
a99c2d4593978bea709f6161a8e95c03 10/0/0.png
root@map:~# md5sum 10/0/1.png
a99c2d4593978bea709f6161a8e95c03 10/0/1.png
Значит ли это, что все тайлы уникальны по контрольной сумме MD5? Нет, конечно! 
Есть такое понятие, как коллизии. Т.е. два визуально (в т.ч. бинарно) отличающихся тайла могут иметь одинаковую контрольную сумму. Риск такой есть, хоть он и невелик для файлов произвольного размера. Поскольку веб-карты — это ресурс, как правило, не требующий абсолютной точности (в отличие, например, от банковских транзакций или котировок Forex), то примем, что низкая вероятность коллизий тайлов — допустимый риск, оправдывающий…
А ради чего нам, собственно, важно знать, что есть одинаковые по некоторой хэш-функции тайлы? Вероятно, Вы уже догадались. Зачем хранить несколько одинаковых тайлов, занимать ими жесткий диск, если можно хранить только один файл и некий маппинг к нему всех дубликатов (например, с помощью банального symlink)?
Итак, низкая вероятность коллизий тайлов — допустимый риск, оправдывающий снижение требований к емкости тайлового хранилища. Но насколько мы выиграем от удаления всех дубликатов? По моим подсчетам, до 70% тайлов дублируются. Причем, чем крупнее масштаб, тем больше эта цифра.
Следует отметить, что я не первый догадался исключить дублирование тайлов по хэш-функции. Так, команда Спутника использовала данный нюанс для оптимальной организации тайлового кэша. Печально, что никто об этой особенности вслух не говорит (не пишет и пр.). Очевидно, это одна из фич подобных сервисов, за счет которых они являются лидерами на рынке.
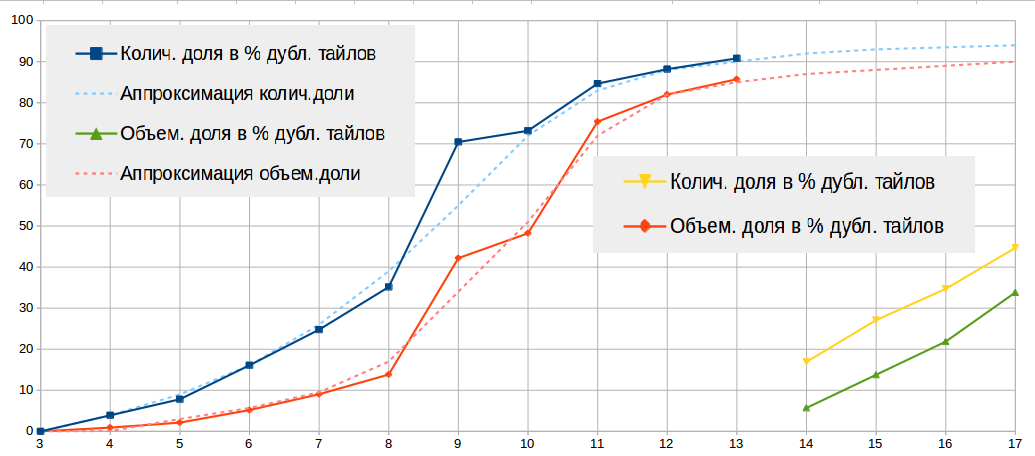
Ниже в таблице и на рисунке привожу статистику по найденным дубликатам (по MD5) тайлов.
| Масштаб | Всего сген. тайлов | Всего дубл. тайлов | Колич. доля в % дубл. тайлов | Объем сген. тайлов | Объем тайлов после создания symlink’ов | Объем. доля в % дубл. тайлов |
|---|---|---|---|---|---|---|
| 3 | 64 | 0 | 0 | 1.3М | 1.3М | 0 |
| 4 | 256 | 10 | 3.91 | 4.3М | 4.2М | 0.92 |
| 5 | 1 024 | 80 | 7.81 | 14.6М | 14.3М | 2.13 |
| 6 | 4 096 | 659 | 16.09 | 49.7М | 47.1M | 5.18 |
| 7 | 16 384 | 4 058 | 24.77 | 175.4М | 159.6М | 9.04 |
| 8 | 65 536 | 23 031 | 35.14 | 650.3М | 560.3М | 13.83 |
| 9 | 262 144 | 184 668 | 70.45 | 1710М | 989M | 42.18 |
| 10 | 1 048 576 | 767 431 | 73.19 | 6.1Г | 3.1Г | 48.22 |
| 11 | 4 194 304 | 3 553 100 | 84.67 | 18Г | 4,4Г | 75.41 |
| 12 | 16 777 216 | 14 797 680 | 88.18 | 69Г | 12.4Г | 82.01 |
| 13 | 67 108 864 | 60 945 750 | 90.82 | 271.1Г | 38.7Г | 85.74 |
| 14 | 279 938 | 47 307 | 16.9 | 3.2Г | 185M | 5.71 |
| 15 | 1 897 537 | 514 005 | 27.09 | 14.2Г | 12.3Г | 13.78 |
| 16 | 5 574 938 | 1 934 553 | 34.70 | 33.8Г | 26.4Г | 21.86 |
| 17 | 18 605 785 | 8 312 466 | 44.68 | 93.8Г | 62Г | 33.82 |
| Всего edit | 115 842 662 | 91 084 800 | 78.63 | 511Г | 164Г | 32.07 |
Следует иметь в виду, что:
- я генерировал тайлы в контексте крупных городов, что само по себе ухудшает показатель дублированности тайлов, т.к. в крупных городах меньше шансов встретить два одинаковых тайла нежели в море. Поэтому данные масштабов 3…12 показывают степень дублированности тайлов за весь земной шар, а данные масштабов 13…17 показывают дублированность только в контексте крупных городов.
- тайлы масштабов 3…10 я генерировал с одним файлом стилей mapnik’а, а тайлы 11…17 с другим файлом стилей. Более того, на разных масштабах срабатывают разные правила рисования стилей, что обусловливает неоднородность рисования тайлов на разных масштабах. Это обстоятельство вносит определенный шум в статистику.
- как правило дублируются так называемые Empty Tiles, имеющие размер всего 103 байта. Поэтому существенного уменьшения размера тайлового хранилища не следует ожидать, что и показывают данные масштабов 9…12. В среднем при показателе дублированности тайлов 70% удается уменьшить размер директории масштаба всего до 50%.
- в виду случайности выбора оригинального тайла статистика по масштабам зашумлена, т.е. если одинаковый тайл встречается на 10-ом и на 12-ом масштабе, то приняв за оригинальный тайл масштаба 10, дубликатом будет считаться тайл масштаба 12, и наоборот. В зависимости от того, как был проклассифицирован тайл, это внесет шум в статистику соответствующего масштаба. В связи с этим есть некоторый элемент случайности в таблице по строкам масштабов. Абсолютное доверие заслуживает лишь строка «Всего».
Рано или поздно перед Вами встанет вопрос выбора файловой системы. Поначалу Вы будете использовать ту файловую систему, которая уже стоит в Вашей системе. Но когда Вы столкнетесь с большими объемами данных, столкнетесь с избыточным дублированием тайлов, столкнетесь с проблемами долгих ответов файловой системы при параллельных запросах, и рисками выхода из строя этих дисков, то Вы наверняка задумаетесь КАК размещать тайловый кэш.
Как правило, тайлы имеют небольшой размер, что приводит к неэффективному расходованию дискового пространства на блочных файловых системах, а большое количество тайлов вполне вероятно может израсходовать все свободное количество i-node’ов. Если Вы уменьшите размер блока до каких-либо небольших размеров, то это повлияет на максимальную емкость хранилища, т.к. любая файловая система, как правило, ограничена максимальным количеством узлов i-node. Даже заменяя дублирующиеся тайлы на symlink’и, у Вас не получится значительно сократить требуемую емкость тайлового хранилища. Отчасти проблему незаполнения блоков можно решить с помощью механизмов метатайлинга — несколько тайлов (как правило, 8×8 или 16×16) хранятся в одном файле, имеющем специальный заголовок, разобрав который можно понять с какого байта по какой находится требуемый тайл. Но метатайлы, к сожалению, сводят усилия по дедупликации тайлов на нет, т.к. вероятность встретить два одинаковых метатайла существенно снижается. Но тем не менее, на сегодняшний день использование метатайлинга позволяет «предсказать» запрос на соседние тайлы, а значит уменьшить время ответа тайлового сервера.
В любом случае, для тайлового хранилища требуется выполнить ряд условий:
- обеспечить эффективное расходование дискового пространства, которое можно достичь уменьшением размера блока блочной файловой системы,
- обеспечить поддержку большого количества файлов и директорий
- обеспечить максимально быструю отдачу тайлов по запросу
- исключить дублирование тайлов
Файловая система, максимально удовлетворяющая перечисленным требованиям, является ZFS. Данная файловая система не имеет фиксированного размера блока, позволяет исключить дублирование файлов на блочном уровне, реализует кэш в оперативной памяти часто используемых файлов. В то же время не имеет встроенную поддержку операционных систем Linux (из-за несовместимости лицензий GPL и CDDL) и создает повышенную нагрузку на процессор и оперативку (в сравнении с традициоными ExtFS, XFS и пр.), что является следствием её полного контроля над физическими и логическими носителями.
Файловая система BtrFS более дружелюбна к Linux, поддерживает дедупликацию (оффлайн), но еще очень сырая для production-систем.
Существуют и другие решения, позволяющие исключить дублирование тайлов и максимально эффективно использующие дисковое пространство. Практически все они сводятся к созданию виртуальной файловой системы и подключением к ней специальных сервисов, позволяющих обращаться к данной виртуальной файловой системе, дедуплицировать «на лету» файлы, помещать и отдавать их в/из кэша.
Например, UKSM, LessFS, NetApp и многие другие реализует на сервисном уровне дедупликацию данных. Но на продакшине нагромождение сервисов чревато большими проблемами, особенно, на high-load веб-сервисах. Поэтому выбор архитектуры тайлового кэша для продакшина должен быть сверх-отказоустойчивым и легок в администрировании.
Известный Спутник (да пусть простят меня упомянутые разработчики — этот проект для меня стал неким положительным примером, на основе которого я строю свой сервис веб-карт) реализует собственный алгоритм дедупликации, в котором также используется некая хэш-функция, позволяющая дедуплицировать тайлы, а сами тайлы хранятся в гибкой CouchBase.
Я тоже попробовал что-то подобное соорудить из средств, к которым у меня в продакшине сложилось доверие. В данном случае мой выбор пал на Redis. Мой опыт показал, что при размещении в памяти Redis’а тайлов, то удается достичь 30% снижения объема занимаемой памяти по сравнениею с размещением в файловой системе. Вы подумаете, зачем использовать Redis? Ведь он живет в оперативке?
Причин такому моему выбору несколько. Прежде всего, надежность. За год на production’е Redis зарекомендовал себя очень надежным и быстрым инструментом. Во-вторых, теоретически ответ из памяти быстрее ответа с файловой системы. В третьих, стоимость оперативки для серверов стала относительно невысокой, а надежность жестких дисков не слишком то, улучшилась за последние годы. Т.е. интенсивная работа сервера с жестким диском (как это происходит при отдаче тайлов) сильно увеличивает риск его выхода из строя. К тому же у моей организации порядка 100 серверов по 515ГБ ОЗУ на каждом (но с небольшими жесткими дисками), что позволяет эффективно размещать в памяти тайлы (при правильном проксировании zxy --> конкретный сервер). Так или иначе, но мой выбор пал на Redis. Я его не навязываю уважаемому читателю. Вы же можете самостоятельно определиться с архитектурой собственного web map service.
У данной статьи была всего одна цель — рассказать о некоторых недокументированных нюансах сервисов веб-карт. Экономьте свое время и деньги за счет моего, надеюсь, не бесполезного исследовательского труда!
