[Перевод] Создание искусственного интеллекта для игр — от проектирования до оптимизации

Сегодня — первое сентября. А значит, многие читатели хабры начинают прохождение нового уровня одной древней известной игры — той самой, в которой требуется прокачать интеллект, и, в итоге, получить магический артефакт — аттестат или диплом, подтверждающий ваше образование. К этому дню мы сделали реферативный перевод статьи про реализацию искусственного интеллекта (ИИ) для игр — от его проектирования до оптимизации производительности. Надеемся, что она будет полезна как начинающим, так и продвинутым разработчикам игр.
Создание искусственного интеллекта для игр
В традиционных исследованиях в области ИИ целью является создание настоящего интеллекта, хотя и искусственными средствами. В таких проектах, как Kismet Массачусетского технологического института (МТИ) делается попытка создать ИИ, способный к обучению и к социальному взаимодействию, к проявлению эмоций. На момент написания этой статьи в МТИ ведется работа над созданием ИИ, располагающего уровнем способностей маленького ребенка, и результаты этой работы весьма перспективны.
С точки зрения игр подлинный ИИ далеко выходит за рамки требований развлекательного программного проекта. В играх такая мощь не нужна. Игровой ИИ не должен быть наделен чувствами и самосознанием (честно говоря, и очень хорошо, что это именно так!), ему нет необходимости обучаться чему-либо за пределами рамок игрового процесса. Подлинная цель ИИ в играх состоит в имитации разумного поведения и в предоставлении игроку убедительной, правдоподобной задачи.
Принятие решений
Основным принципом, лежащим в основе работы ИИ, является принятие решений. Для выбора при принятии решений система должна влиять на объекты с помощью ИИ. При этом такое воздействие может быть организовано в виде «вещания ИИ» или «обращений объектов».
В системах с «вещанием ИИ» система ИИ обычно изолирована в виде отдельного элемента игровой архитектуры. Такая стратегия зачастую принимает форму отдельного потока или нескольких потоков, в которых ИИ вычисляет наилучшее решение для заданных параметров игры. Когда ИИ принимает решение, оно передается всем участвующим объектам. Такой подход лучше всего работает в стратегиях реального времени, где ИИ анализирует общий ход событий во всей игре.
Системы с «обращениями объектов» лучше подходят для игр с простыми объектами. В таких играх объекты обращаются к системе ИИ каждый раз, когда объект «думает» или обновляет себя. Такой подход отлично подходит для систем с большим количеством объектов, которым не нужно «думать» слишком часто, например в шутерах. Такая система также может воспользоваться преимуществами многопоточной архитектуры, но для нее требуется более сложное планирование (подробные сведения см. в статье Ориона Гранатира Многопоточный ИИ).
Базовое восприятие
Чтобы искусственный интеллект мог принимать осмысленные решения, ему необходимо каким-либо образом воспринимать среду, в которой он находится. В простых системах такое восприятие может ограничиваться простой проверкой положения объекта игрока. В более сложных системах требуется определять основные характеристики и свойства игрового мира, например возможные маршруты для передвижения, наличие естественных укрытий на местности, области конфликтов.
При этом разработчикам необходимо придумывать способ выявления и определения основных свойств игрового мира, важных для системы ИИ. Например, укрытия на местности могут быть заранее определены дизайнерами уровней или заранее вычислены при загрузке или компиляции карты уровня. Некоторые элементы необходимо вычислять на лету, например карты конфликтов и ближайшие угрозы.
Системы на основе правил
Простейшей формой искусственного интеллекта является система на основе правил. Такая система дальше всего стоит от настоящего искусственного интеллекта. Набор заранее заданных алгоритмов определяет поведение игровых объектов. С учетом разнообразия действий конечный результат может быть неявной поведенческой системой, хотя такая система на самом деле вовсе не будет «интеллектуальной».
Классическим игровым приложением, где используется такая система, является Pac-Man. Игрока преследуют четыре привидения. Каждое привидение действует, подчиняясь простому набору правил. Одно привидение всегда поворачивает влево, другое всегда поворачивает вправо, третье поворачивает в произвольном направлении, а четвертое всегда поворачивает в сторону игрока. Если бы на экране привидения появлялись по одному, их поведение было бы очень легко определить и игрок смог бы без труда от них спасаться. Но поскольку появляется сразу группа из четырех привидений, их движения кажутся сложным и скоординированным выслеживанием игрока. На самом же деле только последнее из четырех привидений учитывает расположение игрока.
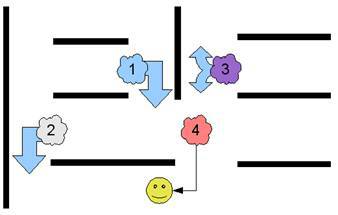
Наглядное представление набора правил, управляющих привидениями в игре Pac-Man, где стрелки представляют принимаемые «решения»
Из этого примера следует, что правила не обязательно должны быть жестко заданными. Они могут основываться на воспринимаемом состоянии (как у последнего привидения) или на редактируемых параметрах объектов. Такие переменные, как уровень агрессии, уровень смелости, дальность обзора и скорость мышления, позволяют получить более разнообразное поведение объектов даже при использовании систем на основе правил.
В более сложных и разумных системах в качестве основы используются последовательности условных правил. В тактических играх правила управляют выбором используемой тактики. В стратегических играх правила управляют последовательностью строящихся объектов и реакцией на конфликты. Системы на основе правил являются фундаментом ИИ.
Конечные автоматы в качестве ИИ
Конечный автомат (машина с конечным числом состояний) является способом моделирования и реализации объекта, обладающего различными состояниями в течение своей жизни. Каждое «состояние» может представлять физические условия, в которых находится объект, или, например, набор эмоций, выражаемых объектом. Здесь эмоциональные состояния не имеют никакого отношения к эмоциям ИИ, они относятся к заранее заданным поведенческим моделям, вписывающимся в контекст игры.
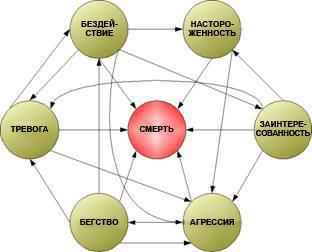
Схема состояний в типичном конечном автомате, стрелки представляют возможные изменения состояния
Существуют как минимум два простых способа реализации конечного автомата с системой объектов. Первый способ: каждое состояние является переменной, которую можно проверить (зачастую это делается с помощью крупных инструкций переключения). Второй способ: использовать указатели функций (на языке С) или виртуальные функции (С++ и другие объектно-ориентированные языки программирования).
Адаптивный ИИ
Если же в игре требуется большее разнообразие, если у игрока должен быть более сильный и динамичный противник, то ИИ должен обладать способностью развиваться, приспосабливаться и адаптироваться.
Адаптивный ИИ часто используется в боевых и стратегических играх со сложной механикой и огромным количеством разнообразных возможностей в игровом процессе.
Предсказание
Способность точно предугадывать следующий ход противника крайне важна для адаптивной системы. Для выбора следующего действия можно использовать различные методы, например распознавание закономерностей прошлых ходов или случайные догадки.
Одним из простейших способов адаптации является отслеживание решений, принятых ранее, и оценка их успешности. Система ИИ регистрирует выбор, сделанный игроком в прошлом. Все принятые в прошлом решения нужно каким-то образом оценивать (например, в боевых играх в качестве меры успешности можно использовать полученное или утраченное преимущество, потерянное здоровье или преимущество по времени). Можно собирать дополнительные сведения о ситуации, чтобы образовать контекст для решений, например относительный уровень здоровья, прежние действия и положение на уровне (люди играют по-другому, когда им уже некуда отступать).
Можно оценивать историю для определения успешности прежних действий и принятия решения о том, нужно ли изменять тактику. До создания списка прежних действий объект может использовать стандартную тактику или действовать произвольно. Эту систему можно увязать с системами на основе правил и с различными состояниями.
В тактической игре история прошлых боев поможет выбрать наилучшую тактику для использования против команды игрока, например ИИ может играть от обороны, выбрать наступательную тактику, атаковать всеми силами невзирая на потери или же избрать сбалансированный подход. В стратегической игре можно для каждого игрока подбирать оптимальный набор различных боевых единиц в армии. В играх, где ИИ управляет персонажами, поддерживающими игрока, адаптивный ИИ сможет лучше приспособиться к естественному стилю игрока, изучая его действия.
Восприятие и поиск путей
До сих пор речь шла о простейших способах решений, принимаемых интеллектуальными агентами; так в исследованиях в области искусственного интеллекта называются объекты, использующие ИИ. Далее я предоставляю нашему герою (или чудовищу, или игровому объекту любого другого типа) контекст для принятия решений. Интеллектуальные агенты должны выявлять области интереса в игровом мире, а затем думать о том, как туда добраться.
Здесь мы уже достаточно близко подходим к настоящему искусственному интеллекту. Всем интеллектуальным агентам требуется базовая способность восприятия своей среды и какие-либо средства навигации и перемещения в окружающем их мире (реальном или каком-либо ином). Нашим игровым объектам требуется то же самое, хотя подход сильно отличается. Кроме того, по отношению к игровому миру можно жульничать, и вам придется это делать, чтобы все работало быстро и плавно.
Как ИИ воспринимает окружающий мир
Зрение
Если ваш агент собирается принимать достаточно взвешенные решения, ему необходимо знать, что происходит вокруг. В системах ИИ, применяемых в робототехнике, значительный объем исследований посвящен компьютерному зрению: роботы получают способность воспринимать окружающий мир с помощью объемного трехмерного зрения точно так же, как люди. Но для наших целей такой уровень совершенства, разумеется, избыточен.
Виртуальные миры, в которых происходит действие большинства игр, имеют огромное преимущество над реальным миром с точки зрения ИИ и его восприятия. В отличие от реального мира нам известно количество буквально всего, что есть в виртуальном мире: где-то среди ресурсов игры есть список, где перечисляется все, что существует в игре. Можно выполнить поиск по этому списку, указав нужный запрос, и мгновенно получить информацию, которую ваш агент сможет использовать, чтобы принимать более обоснованные решения. При этом можно либо остановиться на первом же объекте, который будет представлять интерес для вашего агента, либо получить список всех объектов в пределах заданной дальности, чтобы агент смог принять оптимальное решение в отношении окружающего мира.
Такой подход неплохо работает для простых игр, но, когда стиль игры усложняется, ваши агенты должны быть более избирательными в отношении того, что они «видят». Если вы не хотите, чтобы агенты вели себя так, будто у них глаза на затылке, можно провести выборку в списке потенциальных объектов, находящихся в пределах радиуса зрения агента. Это можно сделать довольно быстро с помощью несложной математики.
- Рассчитайте вектор между агентом и нужным объектом путем вычитания положения цели из положения агента.
- Вычислите угол между этим вектором и направлением взгляда агента.
- Если абсолютное значение угла превышает заданный угол поля зрения агента, то ваш агент не видит объект.
В более сложных играх нужно учитывать, что игрок или другие объекты могут находиться за каким-либо укрытием. Для таких игр может потребоваться построить бегущие лучи (так называемый метод ray casting), чтобы узнать, не загорожена ли возможная цель чем-либо. Построение бегущих лучей — это математический способ проверить, пересекается ли луч с какими-либо объектами, начиная с одной точки и двигаясь в заданном направлении. Если хотите узнать, как именно это делается на конкретном примере, ознакомьтесь со статьей Одна голова хорошо, а две лучше.
Описанный выше метод позволяет узнать, загораживает ли что-либо центр цели, но этого может быть недостаточно, чтобы скрыть вашего агента. Ведь может быть и так, что центр агента скрыт, но зато его голова удобнейшим (для противника) образом торчит над укрытием. Использование нескольких бегущих лучей, направленных на определенные точки цели, поможет не только определить, можно ли попасть в цель, но и куда именно можно поразить цель.
Слух
Казалось бы, между слухом и зрением не так много разницы. Если вы можете видеть объект, то, безусловно, вы можете его и слышать. Верно, что, если ваш агент заметил объект, агент может активно обнаруживать все действия объекта до тех пор, пока объект не окажется вне поля зрения. Тем не менее если добавить агентам дополнительный уровень слуха, то и зрение будет работать эффективнее. Отслеживание шума, издаваемого объектами, — это важнейший уровень восприятия для любых игр с подкрадыванием.
Как и в случае со зрением, сначала нужно получить список находящихся рядом объектов. Для этого можно снова просто проверить дистанцию, но выборка нужных объектов из этого списка происходит уже совсем иначе.
С каждым действием, которое может выполнить объект, связывается определенный уровень звука. Можно заранее задать уровни звука (для оптимизации игрового баланса) либо рассчитывать их на основе фактической энергии звуковых эффектов, связанных с теми или иными действиями (это позволяет добиться высокого уровня реализма, но вряд ли необходимо). Если производимый звук громче заданного порога, то ваш агент заметит объект, издающий звук.
Если нужно учитывать препятствия, то можно снова сократить список объектов и с помощью бегущих лучей определить, есть ли какие-либо преграды на пути звука. Но лишь немногие материалы полностью звуконепроницаемы, поэтому следует более творчески подойти к сокращению списка.
Базовая функциональность, необходимая для придания вашим агентам зрения и слуха, может использоваться и для имитации других органов чувств. Например, обоняния. (Возможность отслеживания игроков интеллектуальными агентами по запаху существует в современных играх, таких как Call of Duty 4*). Добавление обоняния в игру не вызывает особенных трудностей: достаточно назначить каждому игровому объекту отличительный номер запаха и его интенсивность. Интенсивность запаха определяет два фактора: радиус запаха и силу запаха следа, который остается позади. Активные объекты игроков часто отслеживают свои предыдущие положения по ряду причин. Одной из таких причин может быть использование объектов с запахом. С течением времени сила запаха следа уменьшается, след «остывает». Когда данные агента о запахе изменяются, он должен проверить наличие запаха точно так же, как наличие звука (с учетом радиуса и препятствий). Успешность обоняния вычисляется на основе интенсивности запаха и силы обоняния агента: эти значения сравниваются с объектом и его следом.
Осязание в играх поддерживается изначально, поскольку в любой игре уже есть система автоматической обработки столкновений объектов. Достаточно добиться того, чтобы интеллектуальные агенты реагировали на события столкновений и повреждения.
Способность ощущать окружающий мир — это замечательно, но что именно должны ощущать агенты? Необходимо указывать и идентифицировать доступные для восприятия вещи в настройках агентов. Когда вы распознаете то, что видите, агенты смогут реагировать на это на основе правил, управляющих данным объектом.
Временные объекты
Их иногда называют частицами, спрайтами или спецэффектами. Временные объекты являются визуальными эффектами в игровом мире. Временные объекты схожи с обычными объектами в том, что одна общая структура класса определяет их все. Разница же состоит в том, что временные объекты не думают, не реагируют и не взаимодействуют ни с другими объектами игрового мира, ни друг с другом. Их единственная цель — красиво выглядеть, в течение некоторого времени улучшать детализацию мира, а затем исчезнуть. Временные объекты используются для таких эффектов, как следы от пуль, дым, искры, брызги крови и даже отпечатки подошв на земле.
В силу природы временных объектов для них не требуется значительного объема вычислений и обнаружения столкновений (за исключением очень простых столкновений с окружающим миром). Проблема заключается в том, что некоторые временные объекты предоставляют игроку наглядные подсказки о недавно произошедших событиях. Например, пулевые отверстия и следы обгорания могут указывать, что недавно здесь было сражение; следы в снегу могут привести к потенциальной цели. Почему бы и интеллектуальным агентам не использовать такие подсказки?
Эту задачу можно решить двумя способами. Можно либо расширить систему временных объектов, добавив поддержку бегущих лучей (но при этом будет искажен весь смысл системы временных объектов), либо схитрить: размещать пустой объект недалеко от временных объектов. Этот пустой объект не будет способен думать, с ним не будут связаны никакие графические элементы, но ваши агенты смогут его обнаруживать, а временный объект будет располагать связанной информацией, которую сможет получить ваш агент. Итак, когда вы рисуете на полу временную лужицу крови, можно также разместить там невидимый объект, по которому ваши агенты узнают, что здесь что-то произошло. Что касается отпечатков: этот вопрос уже решается с помощью следа.
Укрытие
Во многих играх со стрельбой было бы здорово, если бы агенты умели прятаться за укрытиями, если они есть поблизости, а не просто стоять под огнем противника на открытом месте. Но эта проблема несколько сложнее всех перечисленных ранее проблем. Каким же образом агенты смогут определять, есть ли рядом какие-нибудь подходящие укрытия?

Художники из Penny Arcade* сатирически описывают проблему ИИ противника и укрытий
Эта проблема на самом деле состоит из двух задач: во-первых, нужно правильно распознать укрытия на основе геометрии окружающего мира; во-вторых, нужно правильно распознать укрытия на основе объектов окружающего мира (как показано в приведенном выше комиксе). Чтобы определить, способно ли укрытие защищать от атак, можно просто один раз сравнить размер граничной рамки агента с размерами возможного укрытия. Затем следует проверить, сможет ли ваш объект поместиться за этим укрытием. Для этого нужно провести лучи от различий в положениях вашего стрелка и укрытия. С помощью этого луча можно определить, свободно ли место, находящееся за укрытием (если смотреть со стороны стрелка), а затем пометить это место как следующую цель перемещения агента.
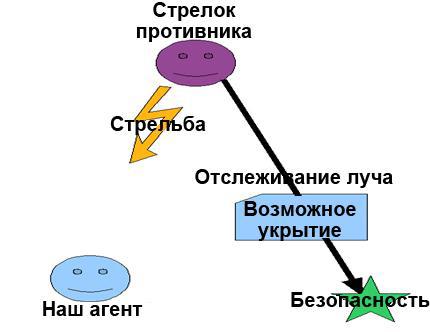
На этой схеме наш агент определил, что в месте, помеченном зеленой звездочкой, можно будет укрыться в безопасности
Навигация ИИ
До сих пор мы говорили о том, каким образом ИИ принимает решения и как ИИ узнает, что происходит в окружающем мире (чтобы принимать более взвешенные решения). Теперь посмотрим, как ИИ выполняет принятые решения. Приняв решение, интеллектуальному агенту нужно понять, как двигаться из точки А в точку Б. Для этого можно использовать разные подходы, выбрав оптимальный в зависимости от характера игры и от нужного уровня производительности.
Алгоритм, условно называемый Столкнуться и повернуть, является одним из простейших способов формирования маршрута движения объекта. Вот как это работает.
- Двигайтесь в направлении цели.
- Если столкнетесь со стеной, повернитесь в направлении, при котором вы окажетесь ближе всего к цели. Если ни один из доступных для выбора вариантов не имеет очевидных преимуществ, выбор делается произвольным образом.
Такой подход неплохо работает для несложных игр. Пожалуй, я не смогу даже сосчитать, в каком огромном количестве игр чудовища применяют этот алгоритм, чтобы выслеживать игрока. Но при использовании алгоритма «Столкнуться и повернуть» объекты, охотящиеся за игроком, оказываются запертыми за вогнутыми стенами или за углами. Поэтому такой алгоритм идеален разве что для игр с зомби или для игр без стен и других препятствий.
Если же агенты в игре должны действовать не столь бестолково, можно расширить простое событие столкновения и снабдить агентов памятью. Если агенты способны запоминать, где они уже побывали, то они смогут принимать более грамотные решения относительно того, куда поворачивать дальше. Если же повороты во всех возможных направлениях не привели к удаче, агенты смогут вернуться назад и выбрать другой маршрут движения. Таким образом, агенты будут производить систематический поиск пути к цели. Вот как это работает.
- Двигайтесь в направлении цели.
- Если путь разветвляется, выберите одно из возможных направлений.
- Если путь приводит в тупик, возвращайтесь к последнему разветвлению и выберите другое направление.
- Если все возможные пути пройдены безрезультатно, отказывайтесь от дальнейшего поиска.
Преимущество этого метода состоит в невысокой нагрузке на вычислительные ресурсы. Это означает, что можно поддерживать большое количество перемещающихся агентов без замедления игры. Этот метод также может использовать преимущества многопоточной архитектуры. Недостатком является расход огромного объема памяти впустую, поскольку каждый агент может отслеживать целую карту возможных путей.
Впрочем, нерационального использования памяти можно избежать, если агенты будут хранить отслеживаемые пути в общей памяти. В этом случае могут возникнуть проблемы в связи с конфликтом потоков, поэтому рекомендуем хранить пути объектов в отдельном модуле, в который все агенты будут отправлять запросы (по мере перемещения) и обновленные данные (при обнаружении новых путей). Модуль карты путей может анализировать полученную информацию, чтобы не допускать конфликтов.
Поиск путей
Карты, на которых пути прокладываются с помощью алгоритма «Столкнуться и повернуть», позволяют приспособиться к изменяющимся картам. Но в стратегических играх игроки не могут ждать, пока их войска разберутся с прокладыванием маршрутов. Кроме того, карты путей могут быть очень большими, и на выбор правильного пути на таких картах будет расходоваться очень много ресурсов. В таких ситуациях на помощь приходит алгоритм поиска путей.
Поиск путей можно считать уже давно и успешно решенной проблемой в разработке игр. Даже в таких старых играх, как первая версия легендарной игры Starcraft* (Blizzard Entertainment*), огромные количества игровых объектов могли определять пути движения по крупным и сложным картам.
Для определения путей движения используется алгоритм под названием A* (произносится э-стар). С его помощью можно находить оптимальный путь между двумя любыми точками в графе (в данном случае — на карте). Простой поиск в Интернете выдает чистый алгоритм, использующий крайне «понятные» описательные термины, такие как F, G и H. Сейчас я попробую описать этот алгоритм более удобопонятным образом.
Сначала нужно создать два списка: список узлов, которые еще не проверены (Unchecked), и список уже проверенных узлов (Checked). Каждый список включает узел расположения, предполагаемое расстояние до цели и ссылку на родительский объект (узел, который поместил данный узел в список). Изначально списки пусты.
Теперь добавим начальное расположение в список непроверенных, не указывая ничего в качестве родительского объекта. Затем вводим алгоритм.
- Выбираем в списке наиболее подходящий узел.
- Если этот узел является целью, то все готово.
- Если этот узел не является целью, добавляем его в список проверенных.
- Для каждого узла, соседнего с данным узлом.
- Если этот узел непроходим, игнорируем его.
- Если этот узел уже есть в любом из списков (проверенных или непроверенных), игнорируем его.
- В противном случае добавляем его в список непроверенных, указываем текущий узел в качестве родительского и рассчитываем длину пути до цели (достаточно просто вычислить расстояние).
Когда объект достигает поля цели, можно построить путь, отследив родительские узлы вплоть до узла, у которого нет родительского элемента (это начальный узел). При этом мы получаем оптимальный путь, по которому может перемещаться объект.
Этот процесс работает, только когда агент получает приказ или самостоятельно принимает решение о движении, поэтому здесь можно с большой выгодой использовать многопоточность. Агент может отправить запрос в поток поиска пути, чтобы получить обнаруженный путь, не влияя на производительность ИИ. В большинстве случаев система может быстро получить результаты. При загрузке большого количества запросов путей агент может либо подождать, либо, не дожидаясь выдачи путей, просто начать двигаться в нужном направлении (например, по алгоритму «Столкнуться и повернуть»). На очень больших картах можно разделить систему на области и заранее вычислить все возможные пути между областями (или точки маршрута).
В этом случае модуль поиска путей просто находит наилучший путь и немедленно возвращает результаты. Поток карты путей может просто отслеживать изменения на карте (например, когда игрок строит стену), а затем снова запускает проверку путей по мере необходимости. Поскольку этот алгоритм работает в собственном потоке, он может адаптироваться, не влияя на производительность остальной игры.
Многопоточность может повысить производительность даже внутри подсистемы поиска путей. Этот подход широко применяется во всех стратегиях в реальном времени (RTS) и в системах с большим количеством объектов, каждый из которых пытается обнаружить потенциально уникальный путь. В разных потоках можно одновременно находить множество путей. Разумеется, система должна отслеживать, какие пути обнаруживаются. Каждый путь достаточно обнаружить только один раз.
Пример кода
Вот пример алгоритма А*, реализованного на языке С. Ради упрощения я убрал из этого примера поддерживающие функции.
Этот пример основывается на игровой карте в виде прямоугольной координатной сетки, каждое поле которой может быть проходимым либо непроходимым. Приведенный алгоритм поддерживает только перемещение на соседнее поле, но с незначительными изменениями его можно будет использовать и для перемещения по диагонали, и даже в играх, где карты уровней состоят из шестиугольных полей.
/*Get Path will return -1 on failure or a number on distance to path
if a path is found, the array pointed to by path will be set with the path in Points*/
int GetPath(int sx,int sy,int gx,int gy,int team,Point *path,int pathlen)
{
int u,i,p;
memset(&Checked,0,sizeof(Checked));
memset(&Unchecked,0,sizeof(Unchecked));
Unchecked[0].s.x = sx;
Unchecked[0].s.y = sy;
Unchecked[0].d = abs(sx - gx) + abs(sy - gy);
Unchecked[0].p.x = -1;
Unchecked[0].p.y = -1;
Unchecked[0].used = 1;
Unchecked[0].steps = 0;
В приведенном выше фрагменте кода обрабатывается инициализация списка проверенных и непроверенных узлов, а начальный узел помещается в список непроверенных. После этого остаток алгоритма запускается в виде цикла.
do
{
u = GetBestUnchecked();
/*add */
AddtoList(Checked,Unchecked[u]);
if((Unchecked[u].s.x == gx)&&(Unchecked[u].s.y == gy))
{
break;
}
Приведенный выше фрагмент кода анализирует узел из списка непроверенных, ближайший к цели. Функция GetBestUnchecked () проверяет расчетное расстояние каждого узла до цели. Если данное поле является целью, цикл разрывается, процесс завершен.
Ниже видно, как вычисляется расстояние: берем предполагаемые значения расстояния до цели в направлениях X и Y и складываем их. При этом может возникнуть желание использовать теорему Пифагора (сумма квадратов катетов равна квадрату гипотенузы), но это излишне. Нам нужно получить лишь относительное значение расстояния, а не его точную величину. Процессоры обрабатывают сложение и вычитание во много раз быстрее, чем умножение, которое, в свою очередь, работает гораздо быстрее, чем деление. Этот фрагмент кода запускается по много раз в каждом кадре, поэтому во главу угла ставим оптимизацию.
/*tile to the left*/
if((Unchecked[u].s.x - 1) >= 0)/*first, make sure we're on the map*/
{
if((IsInList(Unchecked,Unchecked[u].s.x - 1,Unchecked[u].s.y,NULL) == 0)&&(IsInList(Checked,Unchecked[u].s.x - 1,Unchecked[u].s.y,NULL) == 0))
/*make sure we don't repeat a search*/
{
if(TileValid(Unchecked[u].s.x - 1,Unchecked[u].s.y,team))
NewtoList(Unchecked,Unchecked[u].s.x - 1,Unchecked[u].s.y, Unchecked[u].s.x, Unchecked[u].s.y, abs((Unchecked[u].s.x - 1) - gx) + abs(Unchecked[u].s.y - gy), Unchecked[u].steps + 1);
}
}
В приведенном выше разделе функция анализирует поле слева от текущего узла. Если это поле пока отсутствует в списках «Проверенные» или «Непроверенные», функция попытается добавить его в список. TileValid () — еще одна функция, которую нужно приспособить для игры. Если она передает проверку TileValid (), то она вызовет NewToList () и новое расположение будет добавлено в список непроверенных. В следующих фрагментах кода повторяется этот же процесс, но в других направлениях: справа, сверху и снизу.
/*tile to the right*/
if((Unchecked[u].s.x + 1) < WIDTH)/*first, make sure we're on the map*/
{
if((IsInList(Unchecked,Unchecked[u].s.x + 1,Unchecked[u].s.y,NULL) == 0)&&(IsInList(Checked,Unchecked[u].s.x + 1,Unchecked[u].s.y,NULL) == 0))
/*make sure we don't repeat a search*/
{
if(TileValid(Unchecked[u].s.x + 1,Unchecked[u].s.y,team))
NewtoList(Unchecked,Unchecked[u].s.x + 1,Unchecked[u].s.y, Unchecked[u].s.x, Unchecked[u].s.y, abs((Unchecked[u].s.x + 1) - gx) + abs(Unchecked[u].s.y - gy), Unchecked[u].steps + 1);
}
}
/*tile below*/
if((Unchecked[u].s.y + 1) < HEIGHT)/*first, make sure we're on the map*/
{
if((IsInList(Unchecked,Unchecked[u].s.x ,Unchecked[u].s.y + 1,NULL) == 0)&&(IsInList(Checked,Unchecked[u].s.x,Unchecked[u].s.y + 1,NULL) == 0))
/*make sure we don't repeat a search*/
{
if(TileValid(Unchecked[u].s.x,Unchecked[u].s.y + 1,team))
NewtoList(Unchecked,Unchecked[u].s.x,Unchecked[u].s.y + 1, Unchecked[u].s.x, Unchecked[u].s.y, abs(Unchecked[u].s.x - gx) + abs((Unchecked[u].s.y + 1) - gy), Unchecked[u].steps + 1);
}
}
/*tile above*/
if((Unchecked[u].s.y - 1) >= 0)/*first, make sure we're on the map*/
{
if((IsInList(Unchecked,Unchecked[u].s.x ,Unchecked[u].s.y - 1,NULL) == 0)&&(IsInList(Checked,Unchecked[u].s.x,Unchecked[u].s.y - 1,NULL) == 0))
/*make sure we don't repeat a search*/
{
if(TileValid(Unchecked[u].s.x,Unchecked[u].s.y - 1,team))
NewtoList(Unchecked,Unchecked[u].s.x,Unchecked[u].s.y - 1, Unchecked[u].s.x, Unchecked[u].s.y, abs(Unchecked[u].s.x - gx) + abs((Unchecked[u].s.y - 1) - gy), Unchecked[u].steps + 1);
}
}
memset(&Unchecked[u],0,sizeof(PNode));
Последнее, что осталось сделать в этой итерации, — удалить текущий узел из списка непроверенных. Нет необходимости еще раз анализировать это поле.
}
while(1)
;
Заключительный фрагмент кода выстраивает путь из списка проверенных путем возвращения к исходному положению. Путь к исходному расположению всегда можно найти, поскольку каждый узел на пути отслеживает свой родительский узел. Затем возвращается итоговый путь (с помощью ссылки). Функция возвращает длину нового пути.
IsInList(Checked,Unchecked[u].s.x,Unchecked[u].s.y,&u);
p = Checked[u].steps;
if(path != NULL)
{
for(i = (p - 1);i >= 0;i--)
{
path[i].x = Checked[u].s.x;
path[i].y = Checked[u].s.y;
IsInList(Checked,Checked[u].p.x,Checked[u].p.y,&u);
}
}
return p;
}
Тактический и стратегический ИИ
Теперь пора поговорить о том, как отдавать агентам более сложные приказы. Агенты должны научиться справляться с ситуацией, в которой они оказались. То есть, перейдем к искусственному интеллекту, способному работать с более широкими целями и воспринимать обстановку более масштабно.
Тактический ИИ
Роль тактического ИИ состоит в координации усилий групп агентов в игре. Группы более эффективны, поскольку члены группы могут поддерживать друг друга, могут действовать как единое подразделение, обмениваться информацией и распределять действия по получению информации.
Принцип тактического ИИ построен вокруг динамики группы. Игра должна отслеживать различные группы объектов. Каждую группу необходимо обновлять отдельно от индивидуальных объектов. Для этого можно использовать выделенный модуль обновления, отслеживающий различные группы, их цели и их состав. Недостаток этого метода состоит в том, что требуется разработка отдельной системы для игрового движка. Поэтому я предпочитаю использовать метод командира группы.
Одному юниту в составе группы можно назначить роль командира группы. Все остальные члены группы связаны со своим командиром, их поведение определяется информацией, полученной из приказов командира. Командир группы обрабатывает все вычисления тактического ИИ для всей группы.
Движение группы: поиск путей
Движение объектов можно улучшить с помощью динамики группы. Когда несколько агентов действуют как единое подразделение, их движение можно сделать более эффективным и реалистичным.
Поиск пути может занимать немало времени даже при ускорении с помощью заранее вычисленных карт путей и многопоточного ИИ. Динамика групп позволяет существенно снизить нагрузку, образуемую системой поиска путей.
Когда группе юнитов отдается приказ на перемещение (игроком или искусственным интеллектом), ближайший к цели юнит назначается командиром группы, а все остальные члены группы следуют за командиром. При обновлении командира группы он запрашивает систему путей. При наличии пути командир группы начинает движение к цели. Всем остальным юнитам в группе достаточно просто следовать за своим командиром.
Для более упорядоченного передвижения применяется строй. При использовании строя группа передвигается упорядоченно, например построившись фалангой или треугольником.

В игре Overlord рядовые (красного цвета) действуют как одна команда и передвигаются строем по команде игрока (воин в броне)
Управлять строем очень просто, для этого достаточно несколько расширить сферу действий командира группы. Каждый юнит в строю выполняет определенную роль. При построении каждому члену группы назначается место в строю точно так же, как одному из юнитов назначается роль командира группы. Цель каждог
