NewSQL: SQL никуда не уходит
Tренду NoSQL уже почти 10 лет, и можно смело делать какие-то выводы и обобщения. Этим и займемся, поговорим про развитие NoSQL.
Вспомним, как родился NoSQL. Посмотрим, что в нем хорошо, а что плохо, и что выдержало испытание временем. Разберем возможности, которые уже есть в SQL, и которые теперь появляются в NoSQL СУБД. Выделим уникальные ценности NoSQL, и заглянем чуть-чуть вперед в то, что на рынке будет завтра.
А поможет нам в этом Константин Осипов (@kostja) — разработчик и архитектор СУБД Tarantool, который в своем докладе на РИТ++ 2017 говорил про тренды NewSQL, ведь архитектору полагается понимать, что происходит в мире баз данных, чтобы, как минимум, не изобретать велосипед.
О спикере: Сейчас Константин Осипов работает над Tarantool, но ранее участвовал в разработке MySQL, и, когда Константин начинал работу над новой базой данных, его очень смущало, зачем это делать вообще, зачем нужна очередная база данных. В частности, отношение к NoSQL было очень скептическим, как к «недоSQL».
Однако, развитие продолжается, некоторые изначальные принципы отмирают, и, в то же время, NoSQL базы перенимают возможности от классического SQL. На основании результатов этих нескольких лет бурной трансформации вполне можно подвести промежуточные итоги и позволить себе сделать несколько предсказаний на будущее.
План
- Предыстория. Вспомним, как родился NoSQL, что в нем хорошо, а что плохо.
- Посмотрим, что из NoSQL выдержало испытание временем.
- SQL в NoSQL: N1QL и CQL. Разберем возможности, которые уже есть в SQL, и которые теперь появляются в NoSQL СУБД.
- NoSQL уже мёртв, а NewSQL ещё не рождён: чем тёплый, ламповый SQL отличается от SQL в NoSQL.
- Уникальные ценности NoSQL. Мы посмотрим, что хорошего получилось за 10 лет усилий и что будет дальше.
- Multi-Model databases и NewSQL. Заглянем чуть-чуть вперед в то, что на рынке будет завтра.
NoSQL tenets
К термину NoSQL сейчас многие пытаются примазаться, но изначально он получил распространение в 2009 году, когда появился хэштег #nosql. Разработчик из Last.FM изобрел этот тэг для митапа об distributed databases.
После этого тэг стал набирать популярность в Твиттере, а NoSQL стал сливным бачком или воронкой для фрустрации, как я это называю — фрустрации, которая накопилась за многие годы работы с традиционными базами данных.
NoSQL — выход для фрустрации, тэг, который присвоили себе все, кому оказалось недостаточно возможностей SQL.
Эту фрустрацию нужно как-то структурировать и определить, что чаще всего людям не нравилось в традиционных СУБД. Можно выделить 3 крупных блока задач, для решения которых создавался NoSQL:
- горизонтальное масштабирование;
- новые модели данных;
- новые модели консистентности.
Посмотрим, что эти блоки из себя представляют. Возьмем, для примера, Key-value databases. Основная идея модели данных Key-value в том, что база данных простая, но зато она масштабируемая. Огромное количество проблем ложится на плечи разработчика, зато у него есть строгая гарантия, что его база данных будет бесконечно масштабироваться. Но бесконечная масштабируемость — это не магия. Гарантии масштабируемости достигаются за счёт предельно простой семантики поддерживаемых операций: в key-value базе данных любая операция затрагивает строго один узел кластера.
Изначально сообществу было очень сложно отделить модели данных от моделей масштабирования. Если посмотреть на ту же Cassandra, в ранних версиях её модель данных называлась Wide Column Store — широкая колоночная база данных. Если в key-value СУБД индекс один, по ключу, то в wide column store всегда автоматически создавалось два индекса: по ключу и по Column Family.
Причем индекс по ключу шардируемый, а индекс по Column Family — локальный на конкретную data-ноду. За счет этого мы достигли горизонтального масштабирования, но при этом получили возможность выполнять локальные запросы по column family. Старожилы помнят, что похожая возможность была реализована в Oracle, с сохранением реляционной модели, и называлось joined table. Эта возможность позволяла задать двум таблицам физическое размещение в joined-виде. Wide column store в Cassandra — реализует joined table с автоматическим распределением по кластеру.
Слияние модели данных и модели масштабирования, это ровно та проблема, которую решали с помощью реляционной модели. Добро пожаловать в 70е.
Кроме новых моделей данных в NoSQL были реализованы новые модели консистентности. Да-да, опять эта знаменитая CAP-теорема. Меня все время забавляют разговоры про CAP теорему — кому она вообще пригодилась? Как не бывает осетрины второй свежести, так не бывает никаких других ответов на вопрос о консистентности данных кроме одного: база данных должна эту консистентность гарантировать. Поэтому новые модели консистентности — это также, на мой взгляд, отмирающий тренд.
NoSQL сегодня
Тезис, который я хочу высказать в первую очередь — это то, что из всего NoSQL движения выжило:
- горизонтальное масштабирование;
- новые модели данных документные и графовые модели данных;
- новые модели консистентности.
Из тезисов про новые модели данных выжило фактически полтора и полностью умер тезис про модели консистентности.
Смерть CAP
Почему какие-то модели консистентности не выжили?
● Eventual consistency: инфляция термина
Кто пользуется базой данных, у которой работающие векторные часы и на это заточена бизнес-логика приложения? — никто. Кто пользуется базами данных, у которых CRDT (conflict-free replicated data types)? Кто пользуется Riak? — никто. Чем пользуется люди? Чаще PostgreSQL, реже другими базами, например, MongoDB.
● MongoDB: atomic сменяется isolated, добавляются транзакции в 3.xx
У этой базы есть асинхронная репликация. Это очень простая в понимании вещь, хотя, на самом деле, есть 4 вида асинхронной репликации. Репликация данных транзакции может происходить после того, как транзакция закоммитилась локально; до того, как транзакция закоммитилась локально.
То есть точка коммита в основную базу может соотносится с точкой коммита в реплику также разными способами.
Запись в локальный журнал уже сделана, но на реплику это еще не улетело. Допустим, ты хочешь дождаться, что она хотя бы улетела на реплику. Улетела — не значит прилетела. Прилетела — это еще не значит, что записалось в локальный журнал на реплике.
Изначально у MongoDB был режим: запрос прилетает на сервер, база данных ответила ОК — он еще даже ни на диск не попал, ни в журнал — никуда вообще, и полетел дальше. За счет этого все работает очень быстро, но потом MongoDB за это стали критиковать, и по умолчанию в более поздних релизах 3+, все-таки сначала стала записывать транзакцию в журнал, и только после этого отправлять клиенту подтверждение.
То есть даже асинхронная репликация — это бездна семантических моделей. Поэтому модели консистентности — это слишком сложная штука для понимания широким кругом разработчиков, и на смену ассортименту экзотических моделей приходят транзакции и синхронная репликация.
На фоне смерти модели консистентности еще есть интересный тренд в развитии на самом деле более строгой консистентности. В Redis есть транзакции, хотя я бы не назвал это транзакциями, но на счет того, что такое настоящая транзакция, и без этого идут споры.
Давайте посмотрим историю появления транзакций в NoSQL. Cначала в MongoDB была реализована атомарность на уровне документа. Потом добавился режим выполнения isolated, чтобы позволить разработчикам, если им ну очень хочется, обновлять несколько документов атомарно.
● Redis transactions
На заре NoSQL разработчику предлагают положить вообще весь бизнес-кейс в одну корзинку-документ. Появляется целое течение под названием domain driven design которое возводит эту перверсию в ранг дизайн-паттерна. Действительно, если всё хранится в одном документе, атомарность достигается просто: вы сделали одну транзакцию, один бизнес-процесс и у вас одно атомарное изменение одного документа.
Но оказывается, это не работает. Данные нужно нормализовать чтобы избежать избыточности хранения. Их нужно нормализовать для аналитических запросов. В конце концов, модель данных эволюционирует — и тот документ, что ещё вчера мог сохранить всю необходимую для бизнес-сценария информацию сегодня нужно расширять и дополнять.
Проблемы атомарности демонстрируют? насколько тесно модели данных связаны с моделями консистентности — появление транзакций и синхронной репликации делает большую часть моделей в NoSQL ненужными.
Модели данных
Теперь поговорим про следующую историю — историю с моделями данных.
Группы моделей данных, которые изобрели после SQL:
- Key Value;
- Документные;
- Wide Column store;
- Data structure server (у Redis);
- Графовые базы данных.
Круто! У нас есть столько моделей данных! А насколько хорошо они масштабируются?
Это некий тезис, связанный, в первую очередь, с так называемой гиперконвергентностью, когда все современные проекты используют дешёвые одноюнитовые сервера, и бизнесы перестают покупать вертикально масштабируемые машины.
Гиперконвергентность вошла в нашу жизнь настолько основательно, что сегодня даже внутри вертикально масштабируемых машин, если они есть, уже сидит горизонтально масштабируемое ПО — посмотрите как устроен PureStorage или, не к ночи будь помянут, Nutanix. Людям продают, конечно, шкафы, но эти шкафы внутри устроены как обычные стойки у хостинг-провайдера.
То есть горизонтальное масштабирование — это тренд, который давит на всех, в том числе на изобретателей новых моделей данных. Так какие модели данных хороши для горизонтального масштабирования, а какие плохи?
SQL — он хорош или плох для горизонтального масштабирования? Ответ, на самом деле, довольно спорный, вернемся к нему позже.
Redis
Когда Redis добавил Redis кластер, выяснилось, что не все операции моделей данных нормально горизонтально масштабируются.

Это цитата из документации, где они пишут, что у них что-то работает на конкретном шарде, а что-то действительно работает как в настоящем кластере.
Фундаментальная проблема этого подхода та же самая, что и в MySQL, который мы взяли и пошардили руками. То есть у разработчика появляется две модели данных:
- В одной он мыслит в рамках реляционной алгебры.
- Потом, когда он думает о самостоятельном шардировании, он мыслит в модели данных шардированной реляционной алгебры.
Хорошая модель данных должна быть универсальна. Чем прекрасна реляционная алгебра — результатом проекции является отношение, результатом любого оператора является отношение. И как только мы вручную начинаем шардировать MySQL на кластер, мы это теряем.
Тем не менее, Redis добавляет Redis-кластер, потому что все хотят горизонтально масштабироваться.
Графовые базы данных
Графовые базы данных — хороший пример, который помогает разделить понятия горизонтального масштабирования вычислений и хранения. Информацию всегда можно разделить по какому угодно количеству узлов. Но если база данных по своей природе предназначена обрабатывать те данные, которые она хранит, и эти вычисления горизонтально не масштабируются, то возникает проблема эффективного горизонтального хранения, позволяющего вычислениям работать.
Давайте рассмотрим проблему масштабирования графовых СУБД — SQL СУБД сталкиваются с очень похожими препятствиями при масштабировании.
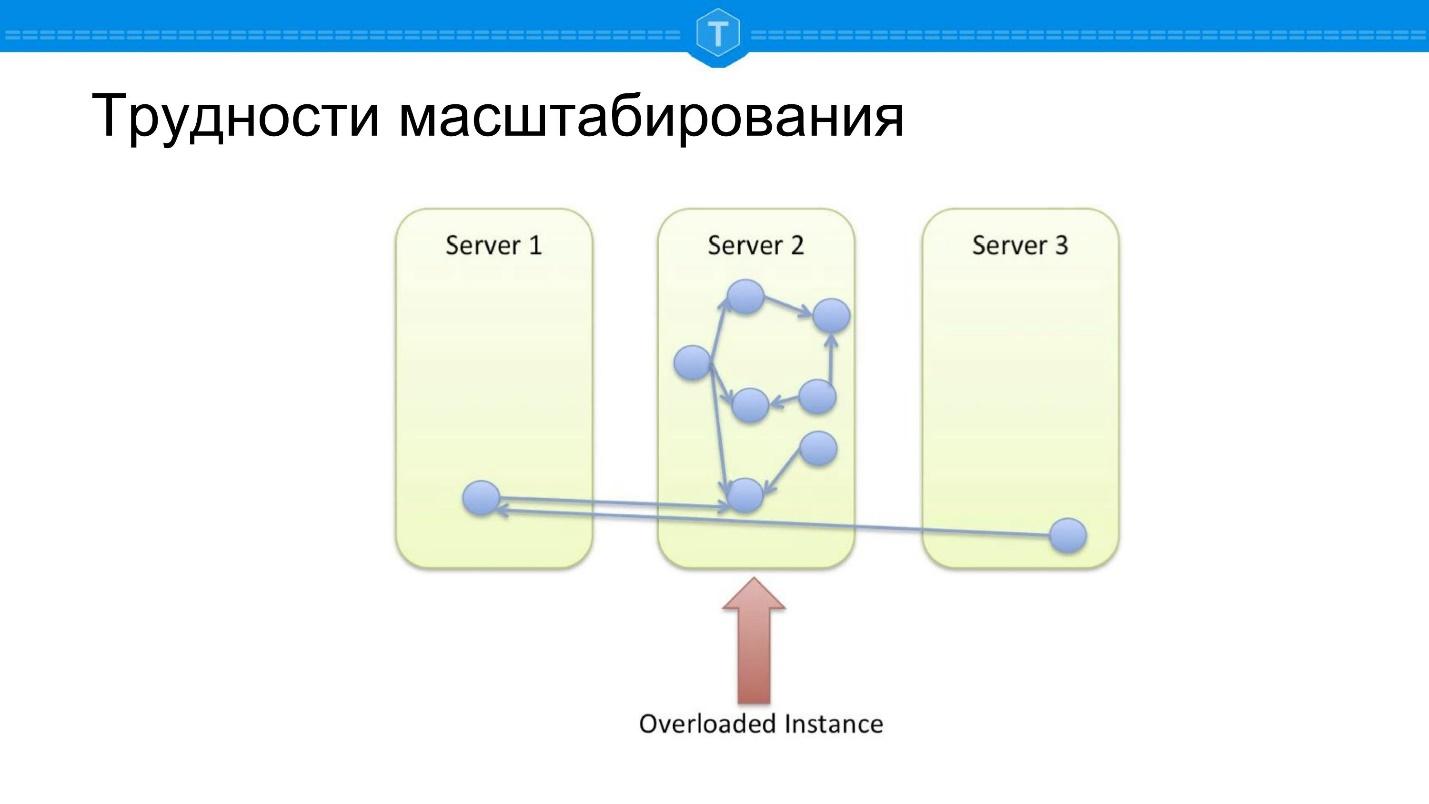
Возьмём локальную базу данных, в которой хранится граф. Рано или поздно один узел заполняется, и мы начинаем использовать другие ноды. Как только мы задействуем больше одного узла, центральная нода становится перегруженной, так как теряется локальность запросов. Какие-то запросы по графу вынуждены ходить по нескольким физическим нодам, то есть появляются сетевые задержки.
Допустим, мы сделали несколько иначе — взяли и разбили все хорошей функцией шардирования. Мы вычисляем некий хэш, достаточно случайно размазывающий все данные по нашему кластеру — и получаем другую проблему.

Если в предыдущей схеме хотя бы какие-то запросы работали нормально, то здесь 100% запросов тупят, потому что большинство запросов базы данных связаны с обходом графа. Любой обход от узла куда-то должен попасть, и чаще всего, чтобы вычислить запрос, нужно перейти на другой узел.

Возникает идея шардировать примерно, как показано на схеме выше: находить кластеры и размещать их на своих нодах: сильно связанные подмножества размещаются вместе, слабо связанные подмножества разносятся.
Это некий идеальный вариант, но идеальный вариант существует только в теории. Живые данные не поддаются статическому разбиению. Чтобы реализовать этот подход, мы должны автоматически обнаруживать кластеры на динамично изменяющемся наборе, постоянно перемещать узлы в зависимости от появляющихся и исчезающих связей.
Поэтому Neo4j по большому счету сейчас масштабируются как классические SQL базы. Они уже довольно долго работают над шардингом, пытаясь решить описанные проблемы.
Тезис, который я выдвигаю, заключается в том, что горизонтальное масштабирование давит на всех, и все модели данных рано или поздно будут вынуждены его реализовать. Но какие-то модели при этом с нами останутся, а какие-то нет.
Так, например, если рассматривать Key-Value и Document базы в чистом виде, то мое утверждение, что их не будет. Если посмотреть на графовые базы данных, то они уже сейчас занимают существенный сегмент, но испытывают давление горизонтального масштабирования.
Исчезнут ли при этом графовые базы данных? Более вероятно, что графы так же, как документы, войдут во все продукты. Этот тренд называется multi-model databases, и позже в докладе я приведу пример того, как это может работать на практике. Но пока в качестве ещё одной иллюстрации тренда multi-model databases, давайте посмотрим на JSON.
JSON
Ниже пример того, как работает тренд, который становится всеохватывающим.
Я утверждаю, что любая база данных, которая вообще хоть как-то способна поддерживать JSON, будет поддерживать JSON.
Возможно, какие-то базы данных для матричных вычислений не будут поддерживать JSON. Но скорее всего и там он пригодится. А все остальные точно будут.
| MySQL |
PostgreSQL |
Redis |
Couchbase |
Cassandra |
Neo4J |
|
| Хранение JSON |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes! |
| JSON field ops |
Yes |
Yes |
Yes |
Yes |
No |
No |
| JSON query |
Yes |
Yes |
No |
Yes |
Yes |
No |
| JSON secondary index |
Yes |
Yes |
No |
Yes |
No |
No |
Эта таблица позволяет наглядно увидеть, что происходит с моделями данных. Реляционные базы в своей поддержке JSON находятся даже впереди нереляционных, той же Cassandra. В ней нет secondary-ключей по JSON-полям. И даже графовые базы данных тоже начинают в себя включать JSON, потому что JSON нужен всем.
Таким образом, multi-model databases, и в частности JSON как тип данных, который есть практически во всех продуктах — это то, что останется от NoSQL всерьез и надолго.
Но если все базы данных поддерживают JSON, зачем вообще нужны NoSQL базы данных?
Остается только одна история — горизонтальное масштабирование. Мы хотим горизонтально масштабироваться, и только поэтому используем что-то кроме MySQL или PostgreSQL.

Это keynote Томаса Улина, VP MySQL Engineering в Oracle, который рассказывает про будущее MySQL. То же самое происходит в Postgres-сообществе и других реляционных продуктах. Давление горизонтального масштабирования сказывается на 100% продуктов из-за перехода к гиперконвергентности и облачным вычислениям.
Томас говорит, что их видение — один продукт с высокой доступностью и масштабировании из коробки. Речь идет о высокой доступности в первую очередь именно InnoDB Cluster, это групповая репликация + InnoDB. Такая база данных никогда не умирает, даже если ее бить молотком.
Дальше Томас пишет »scaling features baked in» — «мы запекли все эти возможности». Речь идет о том, что через x релизов (думаю, что x = 2, 3) они получат MySQL Cluster в чистом виде, который будет поддерживать SQL на кластере, JSON- хранение в кластере.
Уже сегодня В MySQL есть протокол X, который очень похож на MongoDB и предназначен для работы с JSON.
SQL в NoSQL
Теперь давайте посмотрим на движение с другой стороны. Для того, чтобы констатировать смерть, нужно смотреть не только на то, как SQL перенимает принципы NoSQL, но и наоборот.
| MongoDB |
Couchbase |
Cassandra |
Redis |
|
| Cхема данных |
Yes* |
No |
Yes |
No |
| NULLs/Absent values |
Yes* |
Yes |
Yes |
No |
| JOINs |
Yes |
Yes |
No |
No |
| Secondary keys |
Yes* |
Yes |
Yes, but… |
No |
| GROUP BY |
Yes* |
Yes |
No |
No |
| JDBC/ODBC |
No |
Yes |
No |
No |
Здесь на самом деле тоже есть интересные инсайты. Я взял, на мой взгляд, лидеров. Я согласен, что здесь есть не все, например, Elastic — тоже лидер NoSQL. Но Elastic это всё же в первую очередь решение для полнотекстового поиска, поэтому я его не включил в таблицу.
Times Series Databases как тренд я вообще не затрагиваю. Есть тезис среди times series движения, что это отдельная ниша, аналогично графовым базам, но, если копать глубже, там оказывается под капотом сидит Postgres.
Couchbase
Самый, на мой взгляд, широкий объём возможностей из мира SQL есть у Couchbase. Все знают, что Couchbase — это Memcached. У Дормандо (Alan Kasindorf), одного из разработчиков Memcached было совершенно другое продуктовое видение, которое не предполагало горизонтального масштабирования. Поэтому Memcache форкнули для того, чтобы он горизонтально масштабировался. Пошло хорошо и вокруг этого стали делать бизнес, потом слились с CouchDB и так далее, и так далее.
Couchbase изначально про себя говорит, что они schemaless database. Memcache изначально — это очень простая Key-value. А сейчас посмотрим, как эта самоидентификация меняется со временем.
Например, в Couchbase есть Secondary keys, а Secondary keys — это уже на самом деле начало схемы. Если ты говоришь, что у тебя есть какие-то поля, по которым ты строишь индекс, значит, ты уже что-то говоришь о схеме данных документов, которые ты хранишь.
Более того, как у Couchbase постепенно сегодня выпиливается из документации вся история про Memcache прошлое, так же у них завтра будет выпиливаться история про eventual consistency, хотя сегодня там еще очень много историй про отсутствие согласованности чтений — secondary keys are eventually consistent.
Но прикол в том, что у Couchbase есть JDBC/ODBC. Это драйвера, с помощью которых можно теоретически подключить Tableau или ClickView — теоретически, потому что синтаксис CQL не совместим с SQL. Но эти драйвера уже сами по себе — это часть стандарта SQL.
Забегая вперед, давайте посмотрим на синтаксис.

С синтаксисом они крупно облажались, потому что почему-то решили, что поскольку у них хранятся документы, а схемы нет, то им нужны какие-то особенные операторы — и изобрели полные аналоги того, что уже есть в SQL.
Например, у них есть IS MISSING — зачем это нужно, если в стандарте есть IS NULL?
Почему наличие JDBC, ODBC и специальный синтаксис для стандартных возможностей SQL это уже смерть больного? Потому что 30–40 лет назад, когда SQL-стандарт не был доминирующим в мире SQL баз данных, как сегодня, все вели себя ровно таким же образом: все пытались делать вендор look-in, все думали, что для клиентов будет достаточной ценностью изобретение собственного жаргона и т.д.
Мы знаем, чем это кончилось. Один лидер, условно говоря, держит индустрию в кулаке.
Поэтому то, что Couchbase добавляет JDBC/ODBC — это в принципе Франкенштейн. Но хочется поговорить еще про другое, а именно — про вторичные ключи.
Secondary keys
Я говорил, что основной завет NoSQL — это горизонтальная масштабируемость, исключение — только графовая база, у которой отдельная ниша. Но опять же есть OrientDB, который, как мы выяснили, неплохо горизонтально масштабируется.
SQL-базы данных принципиально ничем не отличаются, помимо работы со схемой (более строгой типизацией, более строгими схемами данных), от NoSQL, кроме горизонтального масштабирования.
Теперь в NoSQL-базах данных появляется secondary keys. Как горизонтально масштабируются secondary keys?
Есть два мажорных способа реализации вторичных ключей в кластере (все остальное — это варианты либо эзотерика):
- Либо по каждому подмножеству, которое находится на конкретном узле, строится локальный вторичный ключ. Но тогда этот локальный вторичный ключ может быть использован только для запросов по этому подмножеству, в первую очередь range-запросов, а SQL это в основном именно такие запросы. При таком подходе range-запрос для которого нет возможности определить конкретный узел кластера для выполнения вынужден запускать map/reduce на весь кластер.
- Либо вторичные ключи выносятся во вне. То есть есть отдельный index notes, который хранит вторичные ключи. Тогда все работает гораздо лучше с точки зрения аналитики именно range-запросов и т.п., но сразу теряется локальность апдейтов.
То есть любое изменение потенциально должно зайти на узел с данными, положить туда новое значение, посмотреть, какие данные изменились, сходить на узлы с индексами, обновить их. Если много вторичных ключей, то и много обновлений индексных узлов.
Предательство происходит на наших глазах. С одной стороны, NoSQL-базы данных подсовывают нам диалекты вместо SQL, с другой стороны, предают цель бесконечного горизонтального масштабирования, потому что добавляют вторичные ключи.
В этой связи у меня вопрос: смотрели ли вы с интересом на CockroachDB? Идея в следующем: если мы все равно собираемся изобретать велосипед, давайте изобретем его хотя бы с нуля. Понятно, почему MySQL так медленно и уверенно ползет к шардированному кластеру — потому что у него очень много legacy. Это миллионы строк кода, миллионы приложений, сложный процесс развития и т.д.
В итоге мы получаем, что NoSQL-движение сейчас обременено тем же самым legacy за 10 лет своего существования. Да, его там меньше, но его все равно много. Проще взять и написать SQL-базу данных с нуля, чем допилить PostgreSQL, условно говоря, с MySQL или с Couchbase для того, чтобы он был True NewSQL.
Здесь есть еще интересная история, помимо secondary keys. У MongoDB нет никакого SQL, у них свой язык запросов. Кстати, на самом деле у них есть JOINs, в табличке ошибка, или проверка на внимательность.
У Redis везде No, потому что он заложник своей модели данных. Если Redis реализует всю эту функциональность, то потеряет свою главную ценность — перестанет быть простым. Мы видим продукты, которые стали заложниками своей изначальной простоты, и они будут отваливаться, потихонечку уходить в небытие.
Я не говорю, что Redis уйдет в небытие — возможно, что там ребята что-то придумают. Сейчас они придумали модули, и уже есть Redis-модули, реализующие SQL. Но насколько я понял, он просто прикручивает к Redis SQLite, но это не прикольно — storage там другой — не Redis«овский, не in memory.
Если NoSQL в целом мёртв, то что хорошего он принёс в историю развития СУБД, что останется с нами надолго?
Схемы данных
Давайте посмотрим на то, как NoSQL решения поддерживают управление схемой данных. На мой взгляд, это очень важно, и это ровно то, почему еще SQL базы данные плохо горизонтально масштабируются. Это очень большой кусок проблемы с SQL базой данных.
Принцип schemaless вообще появился, потому что была фрустрация, связанная с тем, что мы ушли от waterfall в проектировании программного обеспечения: у нас постоянный agile, мы постоянно вносим изменения в требования и из-за этого постоянно меняется схема данных. Это просто невозможно делать, когда у тебя база данных рассчитана на то, что ты сделал CREATE TABLE, и это на века.
Даже есть функциональность, которая называется online alter table. А в Oracle есть версионирование схемы данных, когда каждое приложение может работать со своей версией схемы данных.
Но в общем подход SQL к версионированию схемы данных достаточно заскорузлый, на мой взгляд. В этом смысле документная модель и подход MongoDB — подход трендовый, и это с нами останется.
Изначально MongoDB тоже была заявлена, как schemaless. Но потом у них появилась возможность валидации данных. Можно определить валидатор, основная фишка которого в том, что он не обязан быть strict. Настраиваются validation level и validation action. Validation level позволяет принять решение, что делать с существующими документами и что делать с новыми документами.
Можно настроить валидатор таким образом, чтобы он эти существующие документы не отклонял, и операции с ними по-прежнему проходили. Но новые документы уже обязаны проходить и соответствовать этой валидации, этой схеме данных, которую вы вносите. Соответственно validation action тоже может быть либо reject, либо warn: вы получаете warning, что данные не проходят validation action.
Таким образом вы можете развивать свою схему данных параллельно развитию приложений. К сожалению, кроме MongoDB (еще это есть у нас в Tarantool), этого ни у кого нет.
В Cassandra есть поддержка схемы данных и можно разместить JSON, но версионирования и настройки этого нет. Они пошли по другому пути — если схема данных определена, она должна быть строгой. Это тоже, на мой взгляд, тренд из NoSQL, который с нами останется.
Консистентность
Давайте посмотрим все-таки, почему NoSQL базы данных вообще добавляют SQL в том или ином виде.

Модель eventually consistent аналитики такова, что вы получаете отчет, который не соответствует ни одной точке во времени, потому что это бегущий отчет. Пока он сканирует данные, он не держит никакие локи — данные мутируют параллельно сканированию. Это грубая аналитика.
Почему тем не менее такая необходимость возникает?
Потому что есть мир аналитики, который сейчас очень перегрет, решения стоят миллионы долларов. Если исключить BigQuery и посмотреть на решения для аналитики, например, Vertica, то они стоят миллионы долларов.
Для NoSQL это реальная возможность немножко подзаработать. Но оказывается, что результаты любого запроса SELECT нельзя использовать в LTP, то есть у LTP по-прежнему должен быть Key-value.
Именно поэтому я утверждаю, что в будущем NoSQL-системы будут затягивать гайки и реализовывать строгую консистентность для своих запросов.
Сейчас запросы SELECT и JOIN реализованы исключительно для аналитики, но потом они поймут, что надо двигаться дальше, и будут реализовывать строгую модель консистентности — реализовывать транзакции и т.д.
NoSQL: ищем ценности
Итак, я уже упомянул документы, которые войдут во все продукты, мы поговорили про альтернативы к управлению схемой. Еще хотелось бы упомянуть domain-specific languages.
NoSQL движение породило целую плеяду DSL. Самый примечательный из них — это RethinkDB ReQL. Он был самый передовой, его разработчики сказали — давайте встраивать язык работы с данными в каждый domen specific language. Он нативно встроен в Python, в JavaScript и т.д. — не приходится работать с двумя языками. Это очень радикально отличается от SQL в целом, когда есть реляционная алгебра и можно работать только с ее результатами.
Но у нас есть не только ReQL, как таковой. ReQL демонстрирует, что этого недостаточно для того, чтобы организовать свою нишу — это недостаточная ценность сама по себе. Можно спорить про RethinkDB, но, на мой взгляд, это была основная интересная штука, на которую ребята потратили много времени, но ее недостаточно.
При этом есть много других языков:
- Elasticsearch Query Language:
- MIN/MAX/AVG;
- derivative/percentiles/histogram/cumulative sum/serial diff;
- JSONIQ;
- GraphQL;
- SparQL;
- Pregel.
Смысл в том, что, хотя и можно все сделать на SQL, это не продуктивно. Сообщество по-прежнему недовольно SQL!
Если посмотреть на историю SQL — сначала появляется простой OLTP язык, потом GROUP BY, Window Functions, возможности работать с иерархическими базами данным (recursive). SQL последовательно усложняется для того, чтобы добавить все новые виды вычислений. Но это же не конец! У нас есть разные модели данных в аналитике, есть статистические запросы, которые мы хотим вычислять.
Это, на мой взгляд, очень сильный тренд. То, что мы делаем с данными, постоянно усовершенствуется и усложняется, и, для этого должны будут появиться новые языки.
Взять, допустим, Pregel — это распределенные вычисления на графе. Его идея заключается в следующем: есть цикл вычислений, на каждой итерации которого можно изменить состояние каждой вершины графа и отослать исходящее сообщение / принять входящее сообщение. Пока какие-то вершины участвуют в итерациях, вычисления проходят. Это простая модель, которая может работать как на локальном, так и на распределенном графе.
Чтобы как-то реализовать это на SQL, нужно создать временные таблицы, в которые складывать все промежуточные результаты, потому что потом они не будут нужны.
На мой взгляд, очень важно, что новые языки предлагают другую модель, не реляционную, а часто итеративную или с временными результатами. Поэтому это останется.
Мульти-модельные базы данных
Я утверждаю, что не будет такого понятия, как графовые СУБД. Графовые возможности будут во всех СУБД.

Это кейс от ArangoDB, в котором рассказывается про ценность мульти-модельных баз данных для управления парком самолетов: есть парк самолетов, любой самолет можно представить, как граф (или дерево), который состоит из частей и блоков, тоже состоящих из частей.

Разного рода запросы, допустим, на техническое обслуживание обращаются к этой базе данных по расписанию. Раз в год или полгода необходимо во всех блоках заменить все запчасти с определенной маркировкой. Это классический реляционный запрос: найди данные, у которых сейчас окно обслуживания.
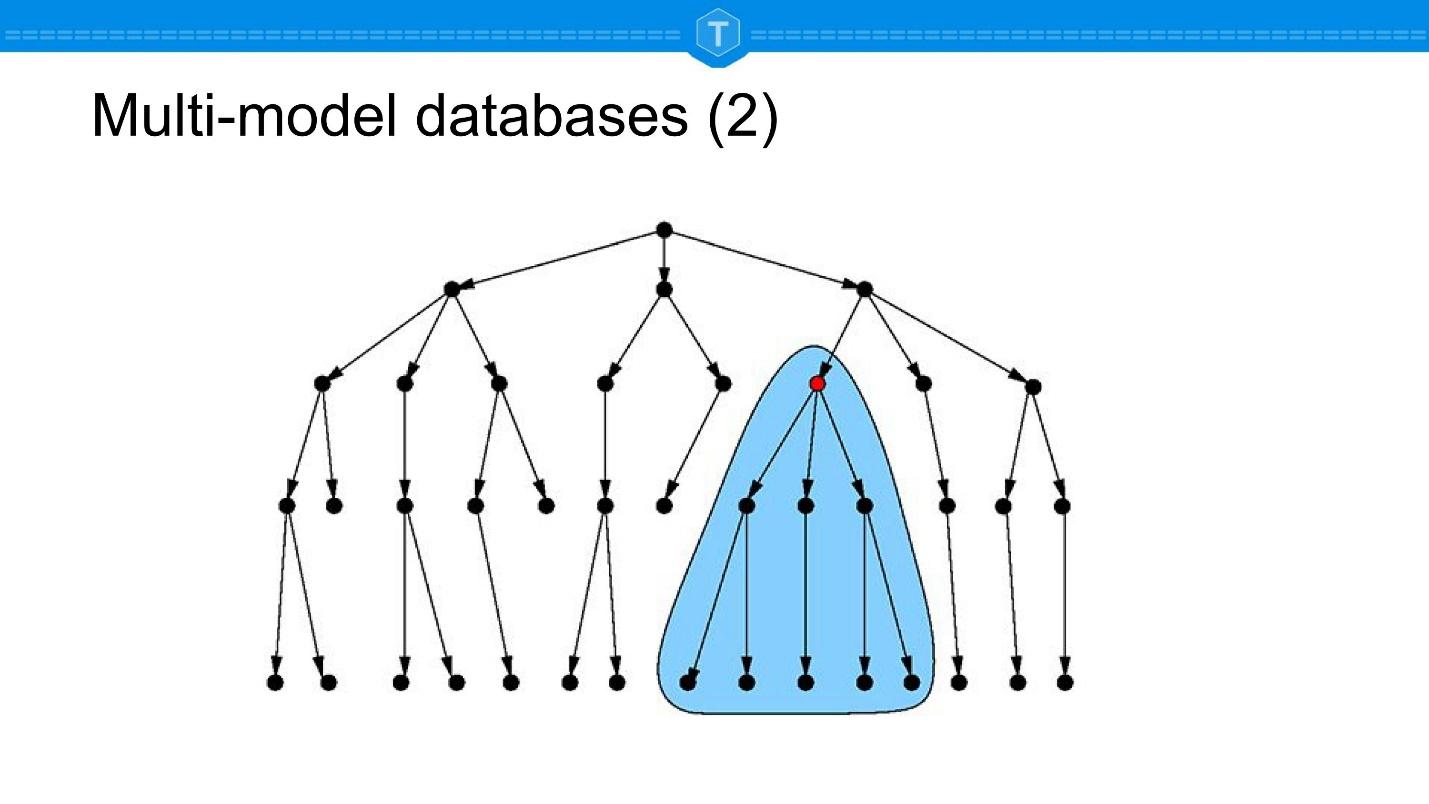
В то же время, есть и типично графовые запросы, как на иллюстрации выше. Допустим, сломалась деталь, но она меняется только в сборе, поэтому требуется найти модуль, который нужно купить и заменить. Это типичный запрос по графу.
Разработчикам нужно дать разные способы работы с одними и теми же данными. В одной и той же базе данных должны быть как графы, так и коллекции, так и relations. Условно говоря, можно в relation включить отсылку на объект, который присутствует в коллекции, в графе можно использовать данные из relations и т.д.
UPSERT: зачем это
Это не совсем про NoSQL, но это тренд, который мне кажется очень важным — это write optimized storage — то, что, на мой взгляд, останется с нами всерьез и надолго.
Ни в SQL, ни в NoSQL сегодня нет операторов, которые были бы write only по своей природе. Даже absert, который есть в MongoDB, в целом ряде случаев тоже читает данные. Insert тоже читающая операция, потому что, если ID уже задан в документе, то нужно проверить, что такого ID больше нет.
Вы скажете — если есть индексы, то мы обязаны читать. Но даже если есть индексы, то читать не всегда обязательно. Идея такая — вы не хотите читать ни в коем случае, вам не надо этого делать, вам не важен результат чтения. Вы хотите добавить данные в базу данных, если они там еще не существуют. Если они существуют, допустим, вы заменяете их старую вервию новой или выполняете какую-то команду слияния. То есть вы должны изобрести новую семантику для того, чтобы не читать.
На мой взгляд, сейчас ни одна база данных этого не предоставляет, но привлекательность write optimized алгоритмов настолько велика, что очень хочется, чтобы такая возможность была. Потому что благодаря write optimized storage у LSM деревьев (RocksDB, LevelDB и иже с ними) производительность записи без чтения на 2 порядка выше, чем производительность записи с чтением. Вместо 10 тысяч запросов в секунду, может быть миллион на одном узле.
Именно поэтому сейчас Time Series Database и выигрывают, потому что в них отсутствует это семантический разрыв. Прилетающий поток данных в них четко определяются как временной ряд и очень быстро и компактно записывается в базу, в частности. потому что не нужно проверять уникальность. Это на порядок быстрее просто потому, что в традиционных базах данных нет такой семантической операции, которая была бы write only.
Думаю, что это появится.

Куда же это все движется дальше? Если посмотреть совсем далеко, инновация не останавливается на NoSQL и NewSQL. Наше представление об информации постоянно развивается.
Один из важнейших трендов будущего, на мой взгляд, в том, что мы все меньше будем удалять информацию.
© Habrahabr.ru
