Мониторинг и Kubernetes (обзор и видео доклада)
28 мая на проходившей в рамках фестиваля РИТ++ 2018 конференции RootConf 2018, в секции «Логирование и мониторинг», прозвучал доклад «Мониторинг и Kubernetes». В нём рассказывается об опыте настройки мониторинга с Prometheus, который был получен компанией «Флант» в результате эксплуатации десятков проектов на Kubernetes в production.

По традиции рады представить видео с докладом (около часа, гораздо информативнее статьи) и основную выжимку в текстовом виде. Поехали!
Что такое мониторинг?
Существует множество систем мониторинга:

Казалось бы, взять и установить одну из них — вот и всё, вопрос закрыт. Но практика показывает, что это не так. И вот почему:
- Спидометр показывает скорость. Если измерять скорость раз в минуту по спидометру, то средняя скорость, которую мы посчитаем на основе этих данных, не будет совпадать с данными одометра. И если в случае автомобиля это очевидно, то когда речь заходит о многих-многих показателях для сервера, мы часто об этом забываем.
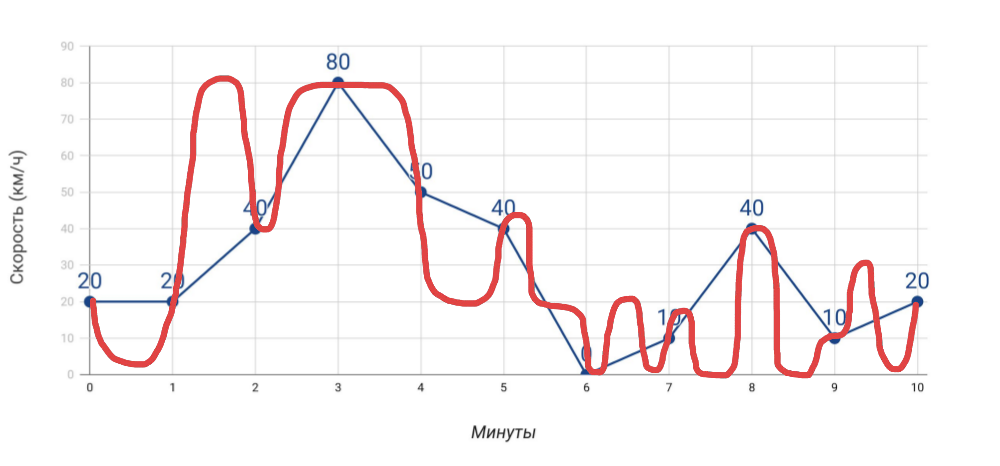
Что мы измеряем и как мы ехали на самом деле - Больше измерений. Чем больше различных показателей мы получаем, тем точнее будет диагностика проблем…, но только при условии, что это действительно полезные показатели, а не просто всё подряд, что удалось собрать.
- Алерты. Нет ничего сложного в том, чтобы отправлять алерты. Однако две типичные проблемы: а) ложные срабатывания происходят так часто, что мы перестаём реагировать на любые алерты, б) алерты приходят в тот момент, когда слишком поздно (всё уже взорвалось). И вот добиться в мониторинге того, чтобы этих проблем не возникало, — подлинное искусство!
Мониторинг — это пирог из трёх слоёв, каждый из которых критичен:
- В первую очередь это система, позволяющая упреждать аварии, уведомлять об авариях (если их не удалось предупредить) и проводить быструю диагностику проблем.
- Что для этого необходимо? Точные данные, полезные графики (смотришь на них и понимаешь, где проблема), актуальные алерты (приходят в нужное время и содержат понятную информацию).
- И чтобы всё это заработало, нужна собственно система мониторинга.
Грамотная настройка системы мониторинга, которая действительно работает, — непростая задача, требующая вдумчивого подхода к реализации даже без Kubernetes. А что же происходит с его появлением?
Специфика мониторинга в Kubernetes
№1. Больше и быстрее
С Kubernetes многое меняется, потому что инфраструктура становится больше и быстрее. Если раньше, с обычными железными серверами, их количество было весьма ограниченным, а процесс добавления — очень долгим (занимал дни или недели), то с виртуальными машинами количество сущностей значительно выросло, а время их введения в бой сократилось до секунд.
С Kubernetes же количество сущностей выросло ещё на порядок, их добавление полностью автоматизировано (управление конфигурациями необходимо, т.к. без описания новый pod просто не может быть создан), вся инфраструктура стала очень динамичной (например, при каждом деплое pod«ы удаляются и создаются снова).
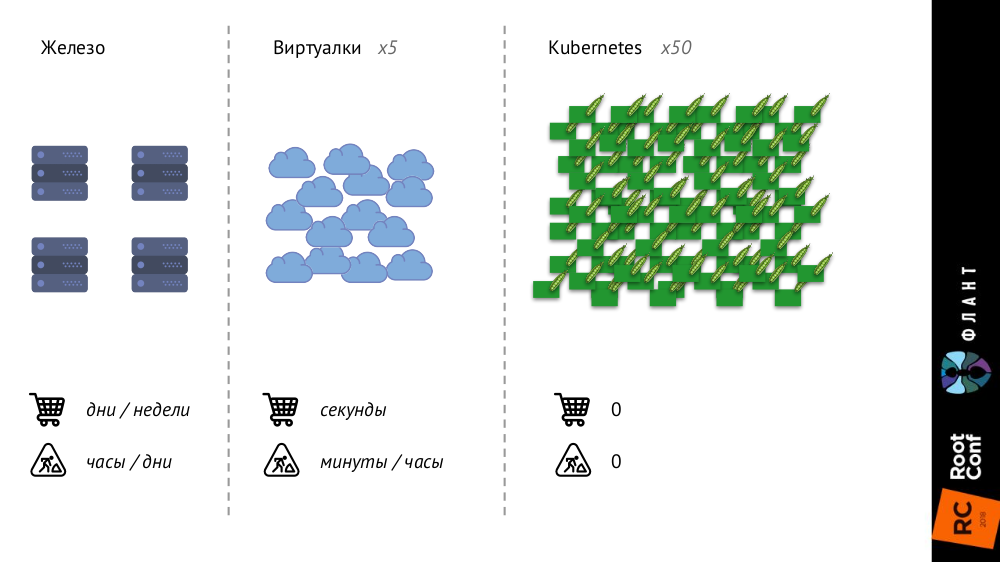
Что это меняет?
- Мы в принципе перестаём смотреть на отдельные pod«ы или контейнеры — теперь нас интересуют только группы объектов.
- Service Discovery становится строго обязательным, потому что «скорости» уже таковы, что мы в принципе не можем заводить/удалять вручную новые сущности, как это было раньше, когда новые серверы покупались.
- Объём данных значительно растёт. Если раньше метрики собирались с серверов или виртуальных машин, то теперь с pod«ов, количество которых сильно больше.
- Самое интересное изменение я назвал »текучкой метаданных» и расскажу о нём подробнее.
Начну с такого сравнения:
- Когда вы отдаёте ребёнка в детский садик, ему выдают личный ящик, который закрепляют за ним на ближайший год (или больше) и на котором указывают его имя.
- Когда вы приходите в бассейн, ваш шкафчик не подписывают и он вам выдаётся на один «сеанс».
Так вот классические системы мониторинга думают, что они детский сад, а не бассейн: они предполагают, что объект для мониторинга к ним пришёл навсегда или надолго, и выдают им шкафчики соответствующим образом. Но реалии в Kubernetes иные: pod пришёл в бассейн (т.е. был создан), поплавал в нём (до нового деплоя) и ушёл (был уничтожен) — всё это происходит быстро и регулярно. Таким образом, система мониторинга должна понимать, что объекты, за которыми она следит, живут короткую жизнь, и должна уметь полностью о нём забывать в нужный момент.
№2. Параллельная реальность существует
Другой важный момент — с появлением Kubernetes у нас одновременно существуют две «реальности»:
- Мир Kubernetes, в котором есть namespaces, deployments, pods, контейнеры. Это мир сложный, но он логичный, структурированный.
- «Физический» мир, состоящий из множества (буквально — кучи) контейнеров на каждом узле.
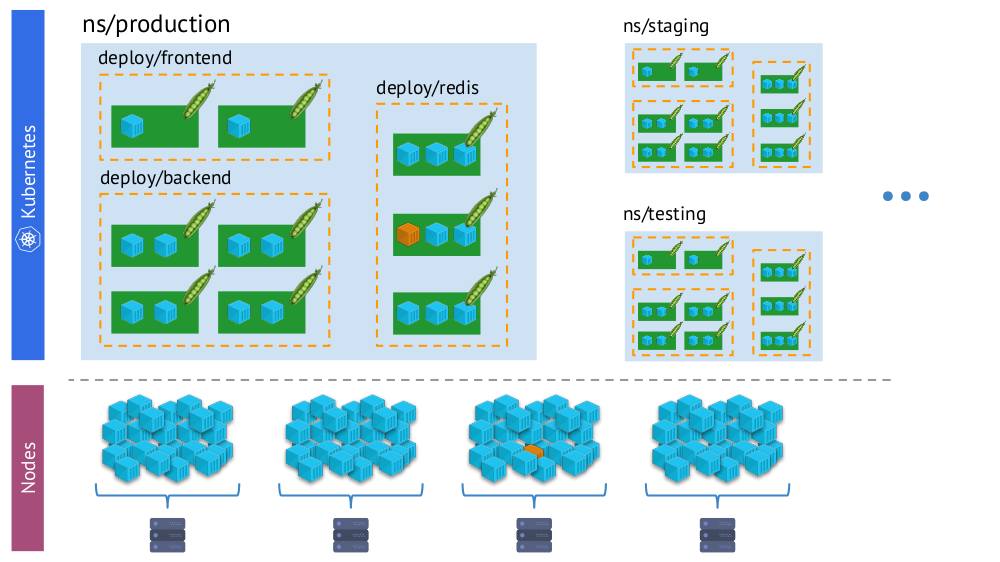
Один и тот же контейнер в «виртуальной реальности» Kubernetes (сверху) и физическом мире узлов (снизу)
И в процессе мониторинга нам необходимо постоянно сопоставлять физический мир контейнеров с реальностью Kubernetes. Например, когда мы смотрим на какое-то пространство имён, мы хотим знать, где находятся все его контейнеры (или контейнеры одного из его подов). Без этого алерты не будут наглядными и удобными в использовании — ведь нам важно понимать, о каких объектах они сообщают.
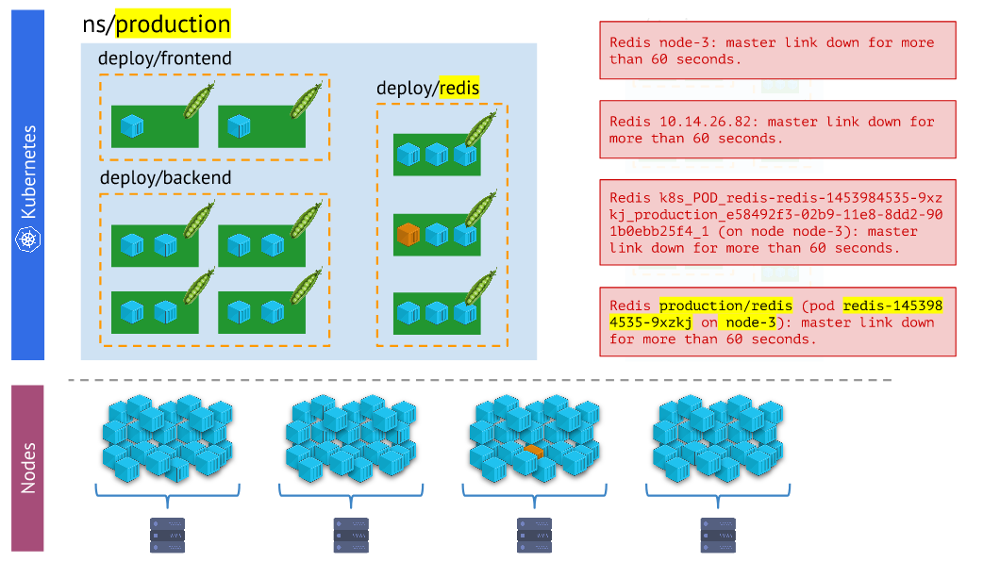
Разные варианты алертов — последний нагляднее и удобнее в работе, чем остальные
Выводы здесь таковы:
- Система мониторинга должна использовать встроенные примитивы Kubernetes.
- Реальностей больше одной: зачастую проблемы случаются не с подом, а каким-то конкретным узлом, и нам нужно постоянно понимать, в какой они «реальности».
- В одном кластере, как правило, несколько окружений (помимо production), а значит — это нужно учитывать (например, не получать ночью алерты о проблемах на dev).
Итак, у нас есть три необходимых условия, чтобы всё вообще могло получиться:
- Мы хорошо понимаем, что такое мониторинг.
- Мы знаем о его особенностях, которые и какие особенности появляются с Kubernetes.
- Мы берём на вооружение Prometheus.
И вот, чтобы действительно получилось, остаётся лишь приложить действительно много усилий! Кстати, почему именно Prometheus?…
Prometheus
На вопрос о выборе Prometheus можно отвечать двумя путями:
- Посмотреть, кто и что вообще использует для мониторинга Kubernetes.
- Рассмотреть его технические преимущества.
Для первого я воспользовался данными опроса от The New Stack (из электронной книги The State of the Kubernetes Ecosystem), согласно которым Prometheus как минимум популярнее других решений (и Open Source, и SaaS), а если разобраться, то и вовсе имеет пятикратное статистическое преимущество.
Теперь посмотрим, как устроен Prometheus, параллельно разбираясь с тем, как его возможности сочетаются с Kubernetes и решают связанные вызовы.
Как устроен Prometheus?
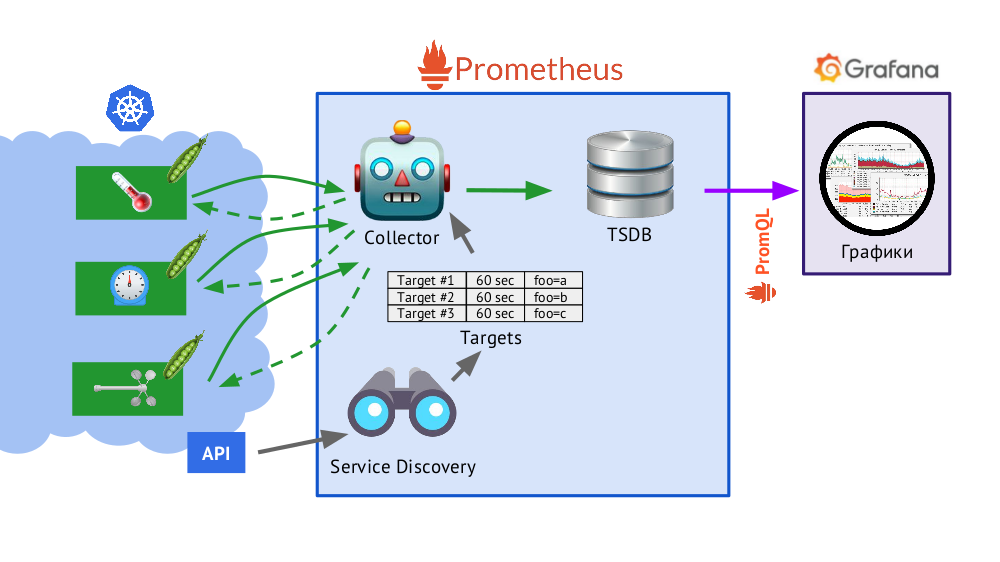
Prometheus написан на языке Go и распространяется как один бинарный файл, в который встроено всё необходимое. Базовый алгоритм его работы следующий:

- Collector читает таблицу целей (targets), т.е. список объектов, которые надо мониторить, и периодичность их опроса (по умолчанию — 60 секунд).
- После этого collector отправляет HTTP-запрос каждому нужному поду и получает ответ с набором из метрик — их может быть сто, тысяча, десять тысяч… У каждой метрики есть название, значение и лейблы.
- Полученный ответ складывается в базу данных TSDB, где к полученным данным о метрике добавляются отметка времени её получения и лейблы объекта, с которого она была взята.Вкратце о TSDB
TSDB — time series database (БД для временных рядов) на Go, которая позволяет хранить данные за указанное количество дней и делает это очень эффективно (по размеру, памяти и вводу/выводу). Данные хранятся только локально, без кластеризации и репликации, что и плюс (просто и гарантированно работает), и минус (нет горизонтального масштабирования хранилища), но в случае с Prometheus хорошо делается шардирование, федерация — подробнее об этом дальше.
- Представленный в схеме Service Discovery — встроенный в Prometheus механизм обнаружения сервисов, который позволяет «из коробки» получать (через Kubernetes API) данные для создания таблицы целей.
Как выглядит эта таблица? Для каждой записи в ней хранятся URL, к которому обращаться для получения метрик, частота обращений и лейблы.
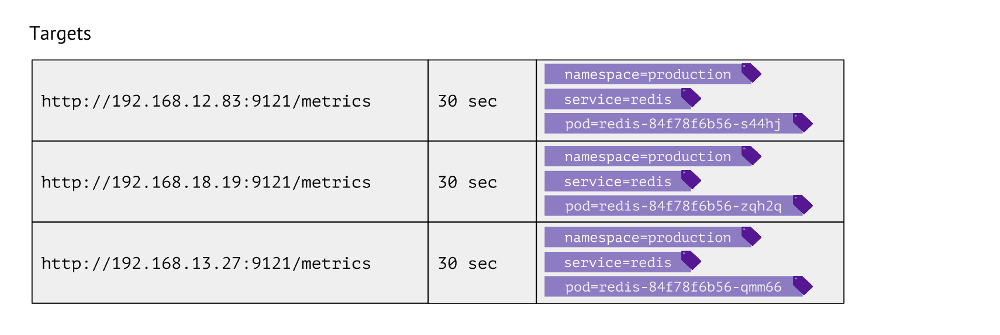
Лейблы используются для того самого сопоставления «миров» Kubernetes и физического. Например, чтобы найти pod с Redis нам необходимо иметь значения namespace, service (используется вместо deployment ввиду технической особенности для конкретного случая) и собственно pod’а. Соответственно, эти 3 лейбла хранятся в записях таблицы целей для метрик Redis.
Эти записи в таблице формируются на основе конфига Prometheus, в котором описаны объекты мониторинга: в секции scrape_configs определяются job'ы, где указывается, по каким лейблам искать объекты для мониторинга, как их фильтровать, какие их лейблы записывать.
Какие данные в Kubernetes собирать?
- Во-первых, мастер в Kubernetes достаточно сложно устроен — и состояние его работы критично мониторить (kube-apiserver, kube-controller-manager, kube-scheduler, kube-etcd3…), причём с привязкой к узлу кластера.
- Во-вторых, важно знать, что происходит внутри Kubernetes.Для этого мы получаем данные от:
- kubelet — этот компонент Kubernetes запущен на каждом узле кластера (и подключается к мастеру K8s); в него встроен cAdvisor (все метрики по контейнерам), а также в нём хранятся сведения о подключенных Persistent Volumes;
- kube-state-metrics — по сути это Prometheus Exporter для Kubernetes API (он позволяет получить информацию об объектах, которые хранятся в Kubernetes: pod«ы, service«ы, deployment«ы и т.п; например, без него мы не узнаем статус контейнера или пода);
- node-exporter — выдаёт информацию о самом узле, базовые метрики по Linux-системе (cpu, diskstats, meminfo и так далее).
- Далее — компоненты Kubernetes, такие как kube-dns, kube-prometheus-operator и kube-prometheus, ingress-nginx-controller и т.п.
- Следующая категория объектов для мониторинга — собственно софт, запускаемый в Kubernetes. Это типовые серверные службы вроде nginx, php-fpm, Redis, MongoDB, RabbitMQ… Сами мы делаем так, что при добавлении определённых лейблов в service у него автоматически начинают собираться нужные данные, по которым создаётся актуальный dashboard в Grafana.
- Наконец, категория для всего остального — это custom. Средства Prometheus позволяют автоматизировать сбор произвольных метрик (например, количества заказов) простым добавлением одного лейбла
prometheus-custom-targetв описание service.

Графики
Полученные данные (описаны выше) используются для отправки алертов и создания графиков. Графики мы рисуем с помощью Grafana. И важной «деталью» здесь является PromQL — язык запросов в Prometheus, который отлично интегрируется с Grafana.
Он достаточно прост и удобен для большинства задач (но, например, делать join’ы в нём уже неудобно, а всё равно придётся). PromQL позволяет решать все необходимые задачи: быстро выбирать нужные метрики, сравнивать значения, выполнять над ними арифметические действия, группировать, работать с временными интервалами и многое другое. Например:

Кроме того, у Prometheus есть исполнитель запросов (Evaluator), который с помощью такого же PromQL может обращаться к TSDB с указанной периодичностью. Зачем это? Пример: начинать отправлять алерты в тех случаях, если у нас есть, согласно имеющимся метрикам, 500 ошибка на веб-сервере на протяжении последних 5 минут. В данные для алертов помимо лейблов, которые были в запросе, Evaluator добавляет дополнительные (как мы настроим), после чего они отправляются в формате JSON в другой компонент Prometheus — Alertmanager.
Prometheus периодически (раз в 30 секунд) отправляет алерты в Alertmanager, который дедуплицирует их (получив первый алерт, он его отправит, а последующие такие же отправлять повторно не будет).
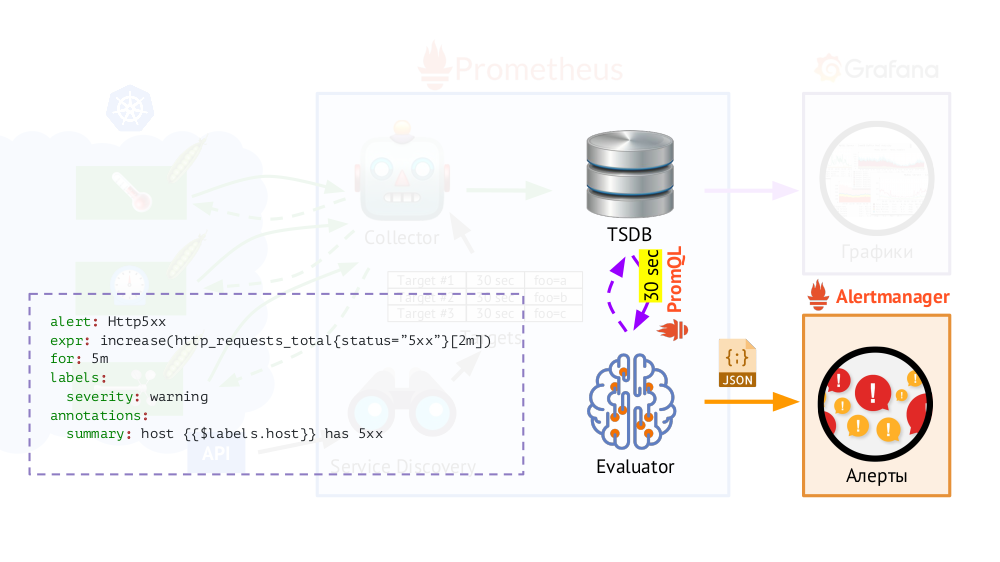
Примечание: Мы у себя не используем Alertmanager, а отправляем данные из Prometheus напрямую в свою систему, с которой работают наши дежурные, но принципиального значения в общей схеме это не имеет.
Prometheus в Kubernetes: картина в целом
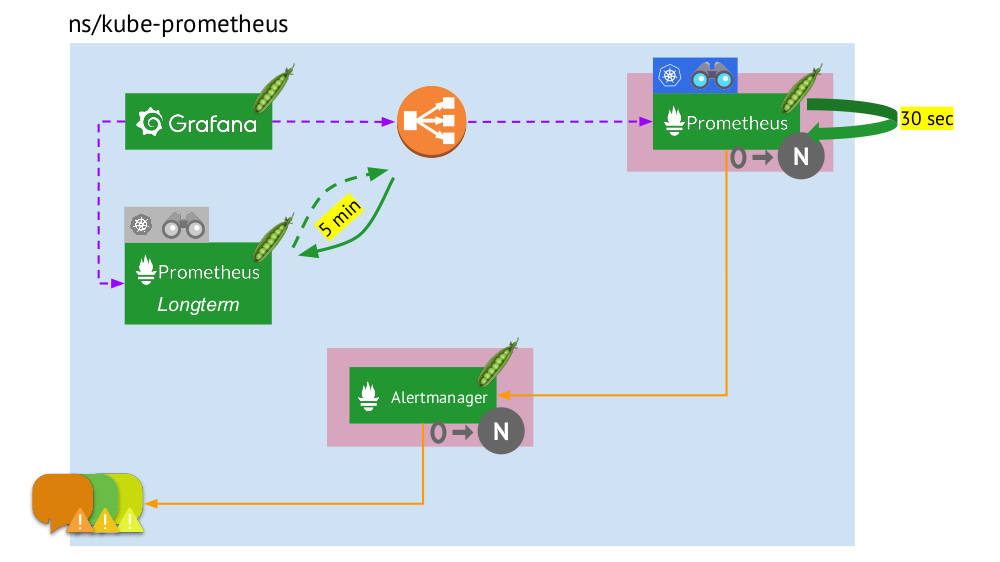
Давайте теперь посмотрим, как работает вся эта связка Prometheus в рамках Kubernetes:
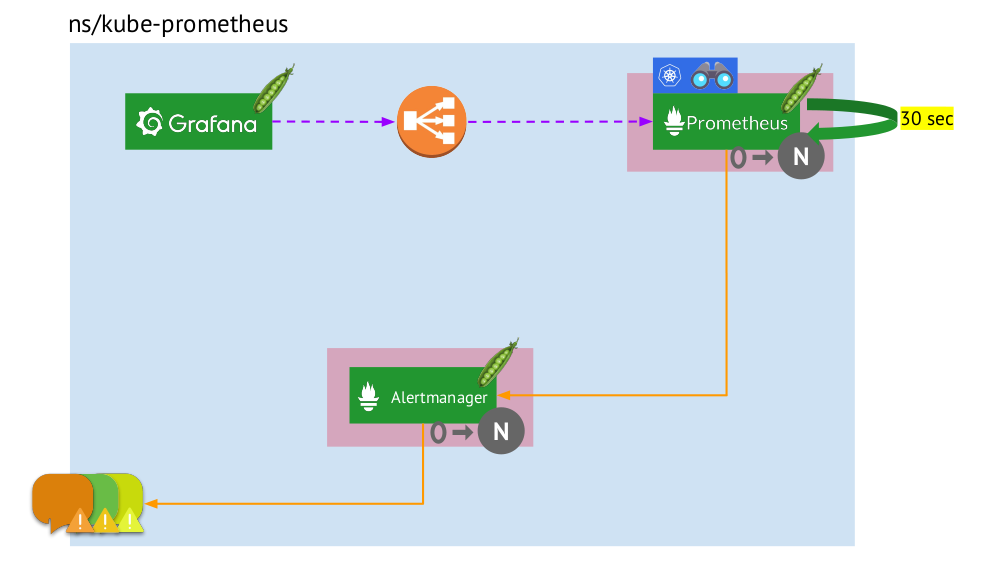
- В Kubernetes есть свой namespace для Prometheus (у нас и на иллюстрации это
kube-prometheus). - В этом namespace размещается pod с инсталляцией Prometheus, которая каждые 30 секунд собирает метрики со всех целей, полученных по Service Discovery, в кластере.
- Также здесь размещается pod с Alertmanager, который получает данные от Prometheus и отправляет алерты (в почту, Slack, PagerDuty, WeChat, стороннюю интеграцию и так далее).
- Перед Prometheus стоит балансировщик нагрузки — обычный Service в Kubernetes — и Grafana обращается к Prometheus через него. Для обеспечения отказоустойчивости Prometheus используется несколько pod’ов с инсталляциями Prometheus, каждый из которых собирает все данные и сохраняет в свою TSDB. Через балансировщик Grafana попадает на один из них.
- Количество pod’ов с Prometheus управляется настройкой StatefulSet — мы обычно делаем не более двух pod’ов, но можно и увеличить это число. Аналогично через StatefulSet развёрнут и Alertmanager, для отказоустойчивости которого требуется уже как минимум 3 pod’а (т.к. для принятия решений об отправке алертов нужен кворум).
Чего же здесь не хватает?…
Федерация для Prometheus
При сборе данных каждые 30 (или 60) секунд очень быстро заканчивается место для их хранения, а ещё хуже, что для этого требуется много вычислительных ресурсов (при получении и обработке такого большого количества точек из TSDB). Но мы ведь хотим хранить и иметь возможность загружать информацию за большие временные интервалы. Как этого достигнуть?
Достаточно добавить в общую схему ещё одну инсталляцию Prometheus (мы называем её longterm), в которой Service Discovery отключён, а в таблице целей — единственная статическая запись, ведущая к основному Prometheus (main). Это возможно благодаря федерации: Prometheus позволяет возвращать последние значения всех метрик одним запросом. Таким образом, первая инсталляция Prometheus работает по-прежнему (обращается каждые 60 или, например, 30 секунд) ко всем целям в кластере Kubernetes, а вторая — раз в 5 минут получает данные с первой и хранит их для возможности смотреть данные за большой период (но без глубокой детализации).
Второй инсталляции Prometheus не нужен Service Discovery, а таблица целей будет состоять из одной строки
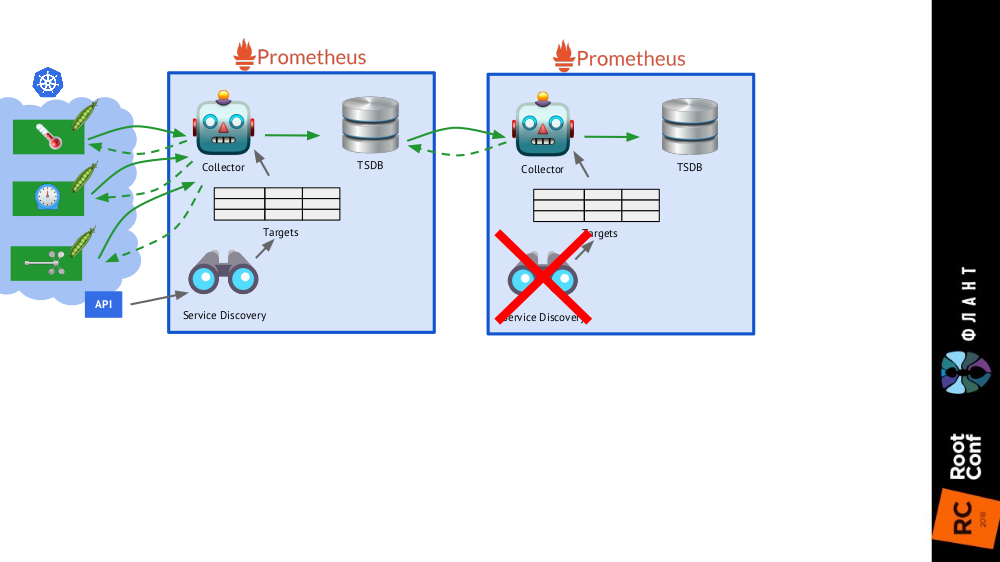
Картина в целом с инсталляциями Prometheus двух видов: main (сверху) и longterm
Финальный штрих — подключение Grafana к обеим инсталляциям Prometheus и создание dashboards специальным образом, чтобы появилась возможность переключаться между источниками данных (main или longterm). Для этого требуется с помощью механизма шаблонов подставить переменную $prometheus вместо data source во всех панелях.
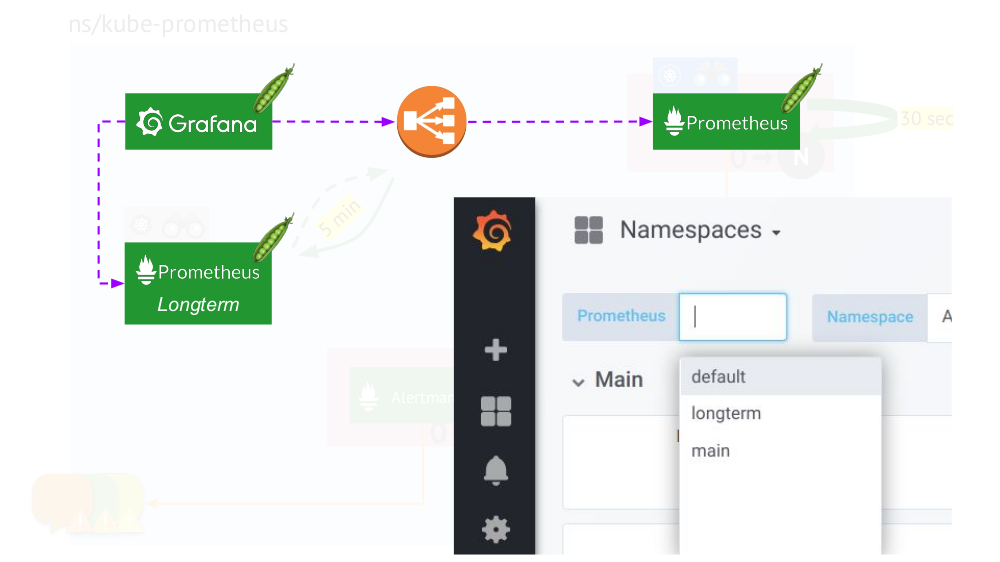
Что ещё важно в графиках?
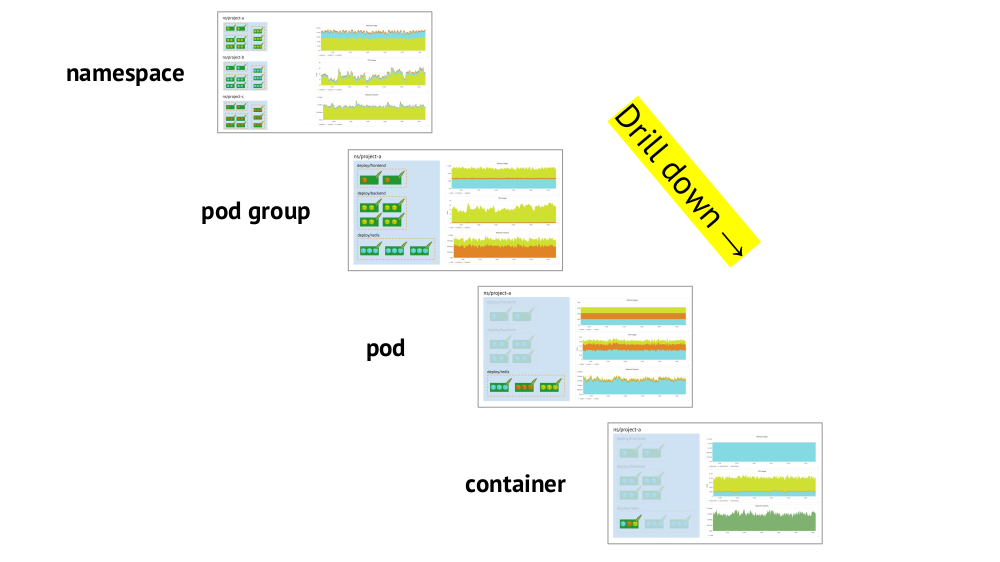
Два ключевых момента, которые стоит учитывать при организации графиков, — это поддержка примитивов Kubernetes и возможность быстрого drill down от общей картины (или более «низкого» представления) к специфической службе и наоборот.
Про поддержку примитивов (пространства имён, поды и т.п.) уже говорилось — это необходимое в принципе условие для комфортной работы в реалиях Kubernetes. А вот пример про drill down:
- Смотрим на графики потребления ресурсов тремя проектами (т.е. трёх namespaces) — видим, что основная часть CPU (или памяти, или сети, …) приходится на проект A.
- Смотрим на такие же графики, но уже для сервисов проекта A: кто из них потребляет больше всего CPU?
- Переходим к графикам нужного сервиса: какой pod «виноват»?
- Переходим к графикам нужного pod’а: какой контейнер «виноват»? Это и есть искомая цель!
Резюме
- Точно сформулируйте для себя, что такое мониторинг. (Пусть «трёхслойный пирог» служит напоминанием об этом… равно как и о том, что грамотно выпекать его непросто даже без Kubernetes!)
- Помните, что Kubernetes добавляет обязательную специфику: группировка целей, service discovery, большой объём данных, текучка метаданных. Причём:
- да, часть из них волшебным образом («из коробки») решается в Prometheus;
- однако остаётся и другая часть, за которой необходимо самостоятельно и вдумчиво следить.
И помните, что содержимое важнее системы, т.е. первичны правильные графики и алерты, а не Prometheus (или любой другой аналогичный софт) как таковой.

Видео и слайды
Видео с выступления (около часа):
Презентация доклада:
P.S.
Другие доклады в нашем блоге:
Вероятно, вас также заинтересуют следующие публикации:
