Немного про периодограммы временных рядов
Привет, Хабр!
Сегодня хочу рассказать о периодограмме и одном из ее возможных применений в области анализа временных рядов. С ее помощью можно определять, насколько хорошо выделилась постоянная, сезонная и случайная составляющая, а также делать общие выводы о структуре временного ряда. В статье предлагаю посмотреть, как строится периодограмма и разобрать модельные и реальные примеры. Всем заинтересованным — добро пожаловать под кат.
Немного теории
Временной ряд — это последовательно измеренные через некоторые, чаще всего равные, промежутки времени данные. В классическом случае предполагается, что временной ряд состоит из трех составляющих: тренда (T_n), сезонной (S_n) и случайной (E_n). Классические модели временных рядов: 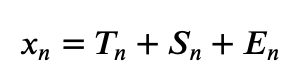
в аддитивном случае и
в мультипликативном.
Какая бы цель не была при исследовании временных рядов, часто в самом начале желательно попробовать отделить и проанализировать каждую компоненту. Объясню на нескольких примерах, зачем это может быть нужно. Зная тренд или тенденцию ряда, можно делать предсказания на несколько точек вперед и говорить о характере протекающего процесса в сколько-нибудь долгосрочной перспективе. Зная характер сезонной составляющей, можно формулировать различные гипотезы, а также корректировать прогноз в зависимости от характера сезонности. Случайную величину можно исследовать, чтобы понять, насколько исследуемый процесс подвержен случайным влияниям, и постараться исключить эту случайную часть при построении аппроксимации или прогноза. Для выделения и анализа каждой из частей используются специальные статистические техники и методики.
С помощью анализа периодограммы ряда можно установить присутствие или отсутствие той или иной составляющей, а также ее характер и относительную величину. Сама периодограмма — это функция от частоты, которая показывает оценку спектральной плотности сигнала.
Разберемся с этим подробнее. Вещественную функцию f можно представить в виде суммы синусов и косинусов разных частот через разложение Фурье.
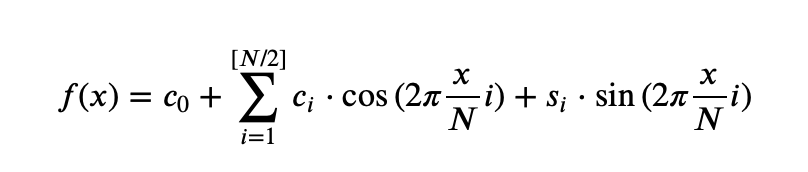
В случае, если вместо функции мы рассмотрим ряд, сумма квадратов коэффициентов перед синусом и косинусом конкретной частоты будет показывать влияние конкретных частот на значения ряда. Формально периодограмма записывается так:
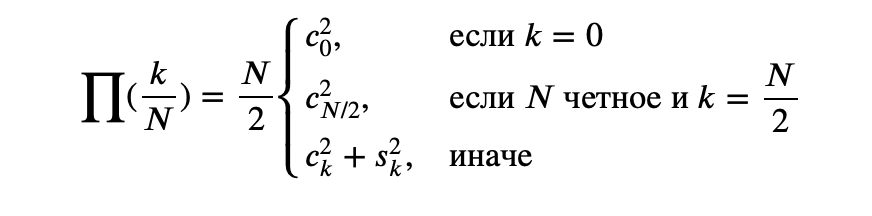
Перейдем к практике и посмотрим, как это все можно использовать.
Примеры
Рассмотрим примеры для нескольких модельных рядов и реальных данных.
Для начала рассмотрим простейший ряд, состоящий из нормально распределенной случайной величины с нулевым математическим ожиданием и единичной дисперсией. Такой ряд называется гауссовским белым шумом.
Сгенерируем тысячу наблюдений гауссовского белого шума
set.seed(1)
par(mfrow=c(2,1))
data <- rnorm(1000, 0, 1)
plot.ts(data, type="l")
spectrum(data, log='no')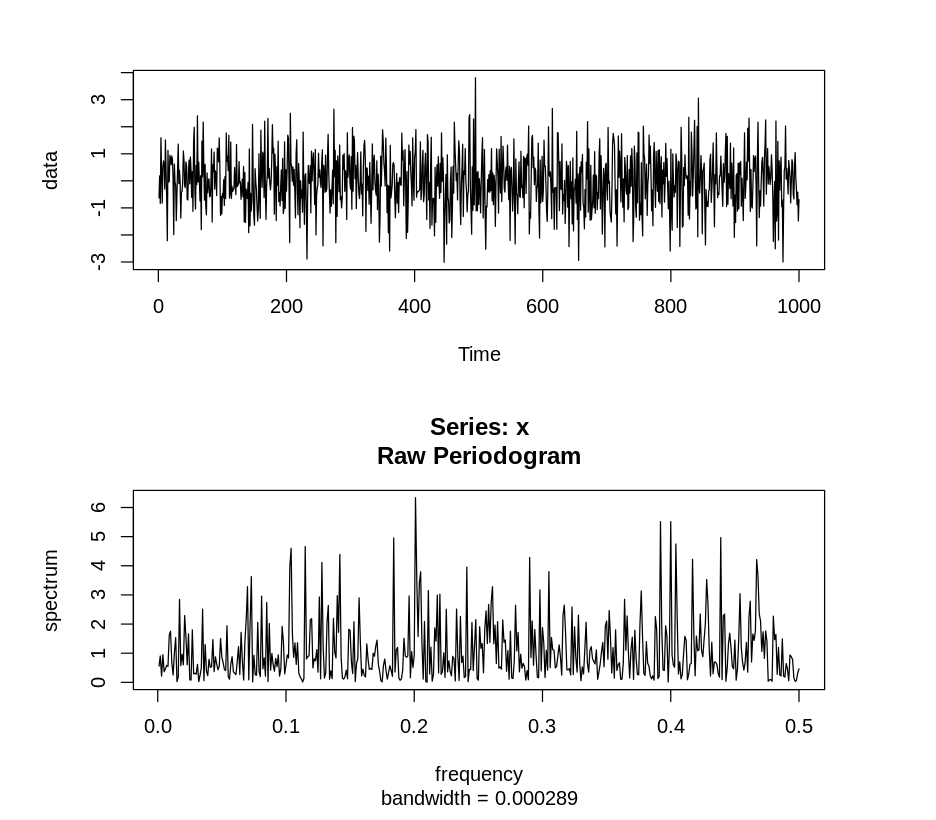
Так как для шума вообще нет детерминирующих частот, мы видим из периодограммы, что каждая частота входит примерно с одинаковой силой. С увеличением количества наблюдений будет увеличиваться значение каждой частоты на сетке. Отсюда и название белый шум — все частоты намешаны в равных пропорциях. Мы не видим идеально равного вложения всех частот, так как это все-таки случайная величина, и конкретные отклонения зависят от реализации. Если у вас при выделении случайной компоненты получается что-то подобное, то можно предположить, что шум выделился правильно.
Отличие красного шума от белого в том, что предыдущие значения влияют на следующие, т.е. имеют ненулевую корреляцию, в отличие от белого шума. Мы знаем, как считается корреляция, соответственно, можем выразить красный шум через белый с наперед заданным значением корреляции следующим образом
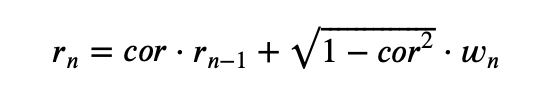
Подробности можно посмотреть, например, тут.
set.seed(42)
wnoise <- rnorm(1000, 0, 1)
w0 <- wnoise[1]
wnoise <- wnoise[2:1000]
cor <- 0.8
rnoise = Reduce(function(prev_v, next_v) cor * prev_v + next_v * sqrt(1 - cor^2), wnoise, w0, accumulate = T)
par(mfrow=c(2,1))
plot.ts(rnoise, type="l")
spectrum(rnoise, log='no')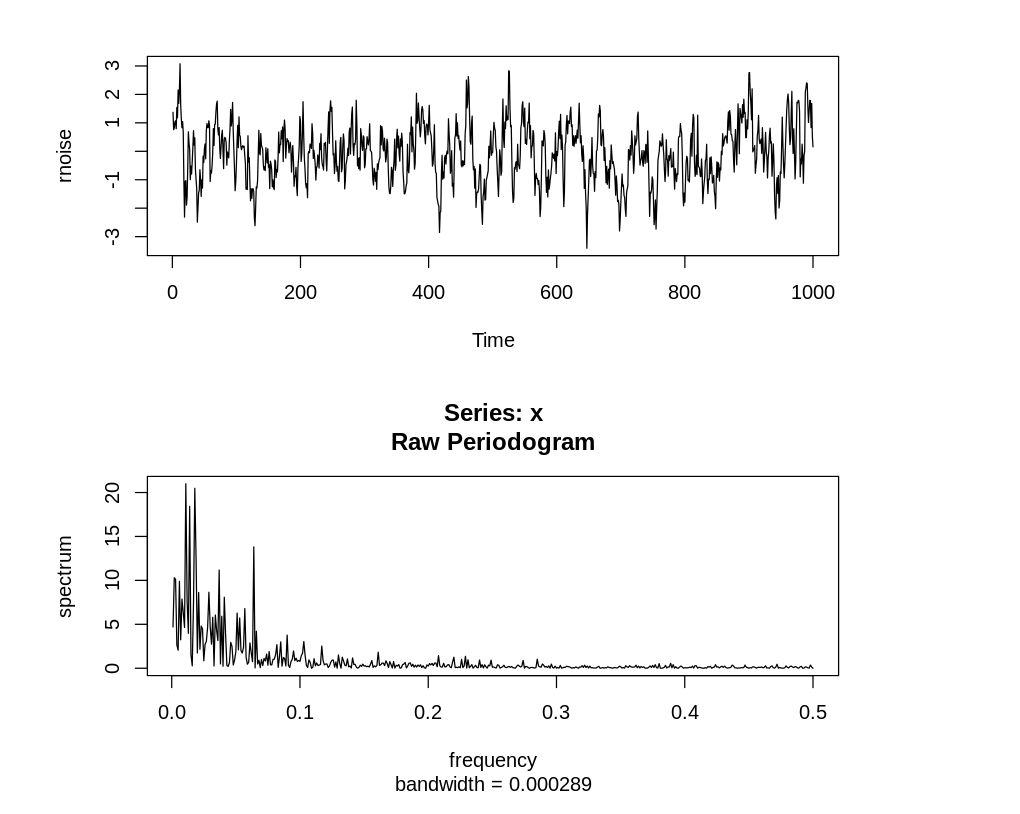
Как и ожидалось, у красного шума присутствуют в основном низкие частоты. Если задать корреляцию ближе к нулю, то получим белый шум, а если единицу, то константу, а именно первое значение ряда белого шума.
Теперь предлагаю посмотреть на возможность применения с реальными временными рядами. Возьмем для примера ряд продаж по пиву, вину, ликерам в миллионах долларов.
data <- read.table('./shared/MRTSSM4453USN.csv', sep=',', header=T, row.names = 1, )
data <- ts(data, start = c(1992, 1), frequency = 12)
plot(data)
Очевидно, присутствует сезонность, посмотрим на периодограмму.
spectrum(data, log='no')
Из графика сразу видно, что по значению наибольшие пики находятся в сетке сезонности. Самый большой пик в точке 2, т.е. в периоде 2/12, что говорит о наличии полугодовой сезонности. Остальные можно проинтерпретировать аналогично. Также видим значения в области низких частот, это медленно меняющаяся компонента ряда — тренд. Таким образом, помимо того, что мы видим, какие частоты преобладают в ряде и какая у ряда есть периодичность, по периодограмме также можно оценить, насколько хорошо мы сгладили ряд.
Сгладить ряд и выделить тренд можно множеством способов, и какой лучше, нужно решать в зависимости от характера данных. Для демонстрации будем использовать метод Classical Decomposition Model, содержащийся в стандартном пакете stats языка R.
decomposeTs <- stats::decompose(log(data))
plot(decomposeTs)
Посмотрим периодограмму тренда, сезонности и шума
spectrum(decomposeTs$trend, log='no', na.action = na.omit)
spectrum(decomposeTs$seasonal, log='no', na.action = na.omit)
spectrum(decomposeTs$random, log='no', na.action = na.omit)


В периодограмме тренда присутствуют в основном низкие частоты, это хорошо. Сезонность слишком идеальная, это связано с методом выделения, который всегда выделяет чистую сезонность, так как оперирует усреднениями. Шум похож на случайную величину, присутствуют пики возле 4 и 5, которые обманчиво кажутся большими, но, если смотреть по значению, видно, что они не особо выделяются из шума. С другой стороны, их можно включить в ближайший период в сезонность, тогда шум будет еще ближе к случайному. Для данного примера стоит попробовать и другие методы, результаты которых также можно проанализировать с помощью периодограммы.
