Машинный поиск аномалий в поведении интернет-магазинов и покупателей
Какое-то время назад мы подключили модуль машинного обучения к системе, которая защищает платежи и переводы в Яндекс.Деньгах от мошенничества. Теперь она понимает, когда происходит нечто подозрительное, даже без явных инструкций в настройках.
В статье я расскажу о методиках и сложностях поиска аномалий в поведении покупателей и магазинов, а также о том, как использовать модели машинного обучения, чтобы все это взлетело.
Зачем платежам еще одна проверка
Вне зависимости от типа авторизации любая платежная операция через Яндекс.Деньги проходит проверку антифрод-системы. Эта процедура позволяет защитить всех участников сделки:
покупателя — от прямых убытков из-за действий мошенников;
продавца и его банк-эквайер — от проведения несанкционированной оплаты, после которой средства придется возвращать;
- Яндекс.Деньги — от штрафов и недовольства пользователей.
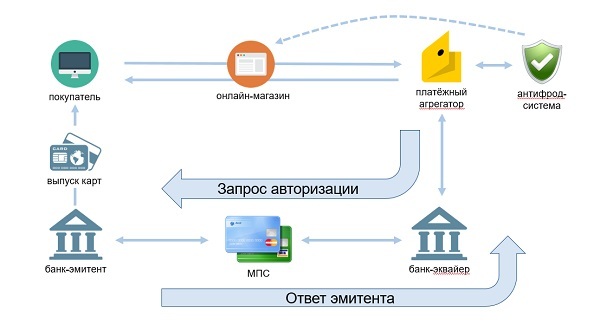
Общая схема процесса оплаты для интернет-магазина.
Антифрод установлен в ядре платежной инфраструктуры Яндекс.Денег, и к нему приходят на проверку любые операции оплаты или переводов. Если есть какие-то подозрения, антифрод может рекомендовать провести дополнительную аутентификацию или обозначить риск как высокий.
Изначально антифрод работал только на основе статичных правил (транзакция с одними параметрами — хорошо, а с другими — плохо), но одни только статичные правила не позволяют поддерживать стабильно низкий уровень ложных срабатываний. В них сложно учитывать, например, внезапные всплески продаж или органические изменения поведения пользователей. Именно поэтому к антифроду подключили модуль машинного обучения, который работает совместно со статичными правилами для более точной оценки рисков.
Как роботы принимают решения
Для работы с методами машинного обучения Яндекс.Деньги используют одну из популярных систем анализа, в которой строятся модели машинного обучения — условно назовем ее ML. Разберем на примере, как все это работает.
Принципиально процесс делится на две фазы:
Обучение. В ходе обучения выявляются параметры модели и значимые признаки;
- Применение результатов, то есть классификация новых операций. В этой фазе определяется класс, к которому относится каждая новая транзакция — рисковая, мошенническая или безопасная.
При отработке статических правил алгоритм антифрода отправляет запрос с определенными атрибутами транзакции модулю машинного обучения для проведения классификации. Модель машинного обучения анализирует их и выдает вердикт с вероятностью того, что операцию проводит мошенник. Здесь самый тонкий момент заключается в выборе и формировании таких атрибутов, но об этом позже.

Так выглядит схема процесса машинного обучения в ML.
Допустим, от имени пользователя Иннокентия проводится операция покупки игровой валюты для World of Tanks в пятницу вечером:
сумма операции — 15 000 рублей;
покупка совершается из Австралии;
пользователь работает с браузером Safari в MacOS;
на часах 15:23;
- еще десяток атрибутов.
По отдельности эти атрибуты не вызывают никаких подозрений, потому что никто не мешает россиянину путешествовать и играть в игры, а также пользоваться системами, отличными от Windows.
Но мы уже раньше встречались с Иннокентием и знаем, что в прошлые месяцы он покупал преимущественно мелкую бытовую технику и одежду в России со средним чеком 7 000 рублей. Только сегодня утром он пополнял проездной в Москве, поэтому принципиальных изменений в его поведении быть не должно.
Конечно, какие-то выводы можно сделать уже на основании простого сравнения атрибутов из двух соседних операций. Вряд ли наш герой изобрел способ добраться из Москвы до Австралии быстрее самолета. Такая существенная разница в географии уже сама по себе привлекает внимание.
Но простое сравнение с соседней транзакцией в случае с суммами уже будет малоэффективно. В принципе, ничто не мешает после покупки проездного приобрести и нечто более крупное. И тут применяется следующий подход. На основании имеющихся данных об истории формируется прогноз для каждого из атрибутов новой транзакции с указанием интервала возможных значений. Если несколько атрибутов вдруг выходят за эти границы — налицо аномалия, которую нужно пристально рассмотреть.
Кроме того, иногда интересны не конкретные значения каких-либо атрибутов, а некие основанные на них качественные характеристики. Поэтому, кроме использования уже имеющихся в транзакции данных, система может сформировать дополнительные атрибуты операции. Например, таким атрибутом может быть признак «Сумма больше N рублей» вместо просто числового значения суммы, или разница между реальным значением какого-то базового атрибута и его прогнозом — чуть позже этот вопрос рассмотрим более подробно.
Результат работы машинного обучения совсем не обязательно будет определяющим — в правилах антифрода есть множество статичных критериев, по которым принимается решение. Тем не менее, результаты этой дополнительной проверки позволяют существенно повысить точность обнаружения мошенника.
Если по многим параметрам реальность слишком отличается от прогноза — это повод для подозрений и, например, дополнительной верификации.
Область поиска аномалий
При покупке в интернет-магазине наибольший риск, как правило, принимает на себя магазин, которому в случае проблем придется работать с опротестованиями и возвратами. Поэтому поиску аномалий в пользовательском поведении в антифрод-системах уделяется наибольшее внимание.
Но аномальным может быть и поведение магазина, который, как и обычные пользователи, тоже может стать объектом атаки мошенников или перейти на сторону зла. Поэтому важно вовремя обнаруживать, когда с магазином происходит что-то не то. Заметить такие изменения можно с помощью все того же изменения характера операций и связанных с ними атрибутов.
Сложности анализа
Из набора известных данных операции составляется набор атрибутов, который бесполезен без понимания, какие значения «хорошие», а какие «плохие». То есть нужно провести черту, при выходе за которую параметры операции станут подозрительными для антифрод-системы — это и будут аномальные значения для каждого атрибута (в некоторых случаях — их комбинации). Здесь-то и кроется одна из самых больших сложностей.
Чтобы построить доверительный интервал для значений добросовестной транзакции, нужно экстраполировать данные из истории операции конкретного пользователя или магазина. Аномалия будет видна, если сравнить текущее значение параметров операции с границами интервала. Иногда сравнивать нужно не абсолютные, а нормированные значения. Решением такого рода вопросов занимаются аналитики Яндекс.Денег в ходе подготовки и обучения моделей.
В процессе обучения применяются следующие методы:
вероятностные — построение всяческих распределений для объектов класса;
метрические — вычисление расстояний между объектами;
- корреляционные — определение количественных взаимосвязей между несколькими параметрами исследуемой системы.
Кроме того, базовых атрибутов вроде товарной группы и суммы заказа бывает недостаточно для поиска закономерностей. Поэтому из имеющихся данных аналитики формируют дополнительные сложносоставные атрибуты.
Любая аномалия — это выбивающееся из общего ряда событие. Может показаться, что достаточно просто выполнить нормирование данных из истории операций (отбросить слишком низкие и слишком высокие значения), чтобы получить приблизительный разброс «хороших» транзакций. Но это не работает, так как существуют дневные всплески продаж, акции, распродажи.
Поэтому в Яндекс.Деньгах используется, например, такой алгоритм выявления аномальных значений атрибутов:
экстраполяция значений временного ряда по каждому из признаков;
вычисление разницы между фактическим значением признака и спрогнозированным машиной;
- если разница слишком велика и такие аномальные события объединяет нечто общее (IP, BIN карты, браузер) — скорее всего, с конкретной транзакцией дело нечисто.
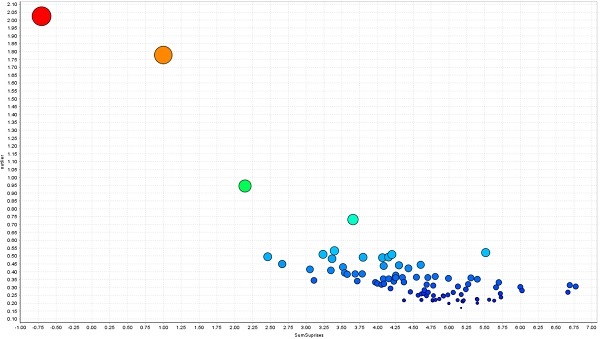
На графике видна зависимость аномальности события от линейной комбинации признаков. Аномальность определяется расстоянием между событиями.
Чтобы не блокировать большинство нормальных платежей, нужно правильно выбрать порог срабатывания для нового признака аномалии, то есть отклонение от нормальной картины, которое мы будем считать существенным и при котором будем готовы принять меры. Тут нет универсального совета по выбору конкретного значения, потому что этот порог можно считать ценой ошибки для бизнеса. Для кого-то вполне нормальной ценой будет отклонение десяти хороших транзакций в день, а кто-то не готов потерять даже одну.
Хорошая новость в том, что для каждой модели машинного обучения можно выставить свой порог.
Во всех этих технологиях и сложной математике важно помнить о пользователе
Пользователи склонны с пониманием относиться к неудобствам, когда речь идет о дополнительной безопасности их денег. Например, устаревшие ныне разовые коды на скретч-карте сложно назвать удобными, но многие пользователи спокойно относятся к этому маленькому злу в обмен на защиту от зла большого — мошеннических операций от своего имени. Здесь важно соблюдать баланс удобства/скорости и надежности, не допуская перегибов.
При любых модификациях в «мозгах» Яндекс.Денег мы особенно внимательно следим за изменением времени обработки каждой операции. Даже идеальная защита не найдет понимания у пользователя, если ему придется ждать подтверждения по несколько минут. Сейчас транзакции выполняются практически мгновенно, если учесть работу антифрода в реальном времени.
Антифрод-система всегда влияла на проведение платежа в режиме онлайн, оценивая каждую транзакцию по статическим правилам. Для нас крайне важно, чтобы добавление оценки риска с помощью машинного обучения не увеличивало время обработки данных. Именно с этой целью был разработан механизм, который позволял проводить классификацию методами ML одновременно со статическими правилами.
Но тут мы столкнулись с новой сложностью — иногда статические правила и машинное обучение могут дать разные ответы, и из них нужно будет выбрать наиболее подходящий в конкретной ситуации. Для этих целей был разработан специальный модуль, который принимает окончательное решение.
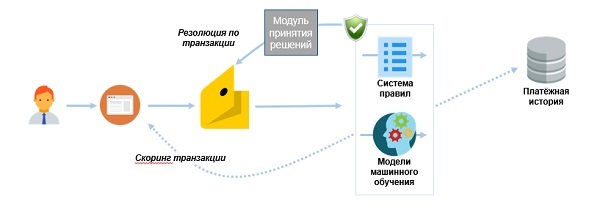
Схема подключения антифрода, при которой проверка выполняется в реальном времени для всех операций.
Результатами каждой проверки по новой схеме являются:
синхронный ответ платежной компоненте от системы правил и моделей машинного обучения;
- отправка скорингового балла и данных о транзакции в базу исторической информации для использования в проверке будущих операций.
Теперь у антифрод-системы появилась возможность дополнительно оценивать опасность транзакции на основе статистики, а не нажимать «красную кнопку» лишь при совпадении со статическими правилами. Для пользователя это означает дополнительный уровень защиты и более гибкую реакцию системы даже в тех случаях, когда покупка выбивается своими атрибутами из общей массы.
Технологии машинного обучения предполагают работу с огромными массивами данных для построения верных прогнозов, поэтому их точечное внедрение нельзя назвать простой задачей. В нашем случае был идеальный кандидат — антифрод, для которого дополнительный уровень интеллекта критически важен, а объем проходящих данных открывает широкие возможности для анализа.
