Остроумие и отвага: как мы много раз ошибались, создавая iFunny
Это — не статья, это — фейлбук. То, что вы прочтете под катом, — выжимка наших нелепых техно-промахов за все 5 лет работы над флагманским продуктом — iFunny. Возможно, наша фейловая история поможет вам избежать ошибок, а возможно, вызовет смех. Что тоже хорошо. Смешить людей — призвание FunCorp уже 13 лет.

Несколько вводных о команде и продукте
Костяк команды мы сформировали ещё студентами в далеком 2004 году в Пензе. Много лет делали что-то мобильное и, как правило, смешное. В 2010 году, в череде многих, мы выпускаем АйДаПрикол — iOS-приложение для просмотра веселых картинок. Без особых вложений оно заходит на аудиторию России и СНГ.
«Why not?» — думаем мы и уже в 2011 делаем версию для североамериканского рынка. За первые 12 месяцев iFunny из App Store и Google Play скачают более 3 миллионов человек, а за 5 лет продукт превратится в полноценное развлекательное соцмедиа весьма популярное в США (DAU = 3,5M).
Основной частью аудитории остаются пользователи iOS- и Android-приложений. Весь функционал доступен именно там. Но Web-версия постепенно догоняет app«ы как по аудитории, так и по наполнению. Ежедневно юзеры постят в iFunny около 400К мемов, а просматривают больше 600M.
Часто приходится слышать: «Да что тут сложного, обычная листалка картинок. Неужели после работы этим нельзя заниматься?» Однако помимо реализации хитрой бизнес-логики (в нашем случае entertainment-логики), это ещё и серьёзный технический челлендж под капотом. Вот, например, с чем приходится справляться:
- 15 000 RPS в пике приходят бэкенд-серверам, которые формируют ответ за 60 миллисекунд;
- 3,5 миллиарда событий в день пишется и анализируется в Data Warehouse;
- 5,5 петабайт контента в месяц раздаётся с помощью CDN. В пике это 28 000 запросов в секунду, или 44 Гбит в секунду.
В самом первом варианте эта статья была на 22 страницы: собрали в нее всё, что только вспомнили. Потом решили, что это будет ещё один фейл, только теперь на Хабре, и выбрали самое характерное: про неразбериху с хранилищами, ошибки в подсчетах DAU, БДСМ-игрища с Mongo, специфику аудитории. И небольшая интрига: мы сводили Трампа и Путина вместе, когда это ещё не было мейнстримом.
Highload-проект
До iFunny у нас было много проектов, но ни одного с приставкой highload. Самой впечатляющей считалась ежедневная посещаемость в 100 000 уников. Здесь всё произошло слишком резко. Мы не справлялись с нагрузкой и объемами данных, поэтому регулярно меняли то хостеров, то технологии.
Выглядело это примерно вот так:

Каждый переезд был вызван своими причинами: где-то было дорого, где-то не хватало функционала, а где-то, как в случае с Hetzner, вынуждал бежать сам хостинг. Мы были довольно неблагополучным соседом, которого регулярно ддосят и закидывают обоснованными жалобами на заливаемые пользователями сиськи/письки и прочую расчленёнку.
Как вы успели заметить, особенно у нас получалось бегать от железа к облакам и обратно. Про случай с «обратно» как раз и расскажем.
Побег с препятствиями
На начало 2012 года приложение и база данных находились на AWS, а контент вскоре начнем раздавать через CDN, пройдя тернистый путь от одного 10Гбит сервера до нескольких с rsync.
Но уже к маю наша вертикально-масштабируемая MySQL на AWS упирается в потолок и начинает сбоить под нагрузкой. А поскольку это RDS, то ручек мы почти не можем покрутить. Понимая, что облака — это всё же про горизонтальное масштабирование, а нам влом, решаем переехать на OVH, который оправдал себя ещё при раздаче контента.
Любой нормальный разработчик начал бы думать об изменении архитектуры, шардировании, но мы в очередной раз пошли по пути наименьшего сопротивления, то есть вертикального масштабирования. Первым делом унесли MySQL в OVH. Производительность возросла, потому что это всё-таки железо, а не виртуализация, у которой есть небольшой оверхэд и куча нюансов с дисковым I/O. При этом железо взяли мощное — 8-ми ядерный Xeon, 24 ГБ оперативки и 300 ГБ SSD, а по деньгам вышло дешевле AWS.
Позже вскрылся интересный факт. Когда копались в логах, заметили русский IP, который воровал контент, посылая 50 запросов в секунду. Это создавало большую нагрузку на API-бэкенды, особенно на MySQL. Именно эти запросы стали одной из причин стремительного бегства на OVH. После того как мы всё это дело отфильтровали, базе данных стало ещё легче, только уже раза в три.
Расстроились тогда не сильно, потому что 50 реквестов в секунду могли бы и за пару недель набежать с новыми пользователями. Но отомстить решили, потому что выкачка шла уж очень жёсткими методами и большими страницами. Отдали в ответку вместо картинок 700-мегабайтный дистрибутив Убунты, замаскированный под jpeg. Не жалеем — были очень злы. Это сейчас при пиковых 15000 RPS можно только посмеяться над «проблемными» 50, но тогда это было существенно.
В итоге радовались мощностям OVH недолго. Спустя год после переезда у них возникли проблемы с оперативным предоставлением новых серверов. Задержка доходила до месяца и это просто по велению их основателя. Мы же продолжали расти и от такой политики серьёзно пострадали. Вернулись всем составом на AWS, где уже есть проверенные решения, SaaS продукты, а главное — гибкость. Пусть там суровый enterprise делает capacity planning, а мы пойдём писать код. И теперь всё больше понимаем, что если бы не облака и SSD на первых порах — нас бы вообще не существовало. Как и этой статьи.
Сейчас стараемся по максимуму использовать managed-сервисы AWS: S3, Redshift, ELB, Route 53, CloudFront, ElasticMapReduce, Elastic Beanstalk. Для небольшой команды это выход, работается эффективнее. Но это совсем не означает, что можно с помощью волшебной технологии решить проблему. Тот же Redshift мы уже копнули глубоко: пришлось основательно изучать потроха. Поэтому всё это, как и NoSQL, точно не серебряная пуля. Нужно разбираться в мелочах.
Быстрый рост
ЛжеDAU
Всё тот же 2012 год. В период смуты и шатания в технологиях у нас всё хорошо с ростом: ТОР-3 в App Store и взлёт дневной посещаемости.
Но как известно, любая смута порождает парочку Лжедмитриев. Мы же столкнулись с двумя случаями ЛжеDAU.
Первый скачок.
Неожиданно за 2 дня получаем подозрительные +300 тысяч: 2200K превратились в 2500K.
Причину выяснили быстро. iFunny можно пользоваться анонимно, не регистрируясь. Такие юзеры тоже учитываются. Этим и воспользовался некто, расковырявший наше API. Просто слал запросы, подставляя рандомные идентификаторы, которые мы и посчитали.
Второй скачок.

Как только мы перенесли базу на OVH и она перестала тормозить, у нас подскочило DAU. Мы на радостях подумали, что UX — это вам не шутки. Приложение стало работать быстрее и всё сразу начали им пользоваться. Поэтому мы с ещё большим энтузиазмом стали готовиться к первоапрельскому корпоративу — рекорд же. Но увы, это был не рекорд, а период затянувшегося на пару недель переезда приложения с AWS на OVH. Там оно должно было встретиться с базой данных и зажить вместе с ней долго и счастливо. Эта нестыковка выявила некорректный подсчёт DAU в MySQL. Умные парни считали бы по access-логам, а мы зачем-то делали неатомарные запросы вида «если в этот день юзер ещё не заходил, то сделай +1 к счетчику» на каждое действие пользователя. В итоге чем дольше длились эти запросы к базе, тем больше становилось DAU из-за параллельных запросов. : facepalm:
Перенесли регистрацию и подсчёт DAU в Redis в обычный Sorted Set — проблему это решило. Нам понравился такой паттерн, но за три года мы превратили код в лапшу из подсчёта метрик в Redis. В 2016 внедрили сбор серверных и клиентских событий посредством fluentd + S3 + Redshift. Это избавило нас от спагетти в коде. О том, как это происходило, нужно писать отдельный пост. И даже не один.
Redis-Господин
Со временем стал подводить Redis, с которым раньше проблем не было. Пик проблем приходился на ночь. Он просто становился недоступен из PHP, и всё сразу ложилось, поскольку почти на каждый HTTP-реквест нам надо было ходить к нему.
Начинаем разбираться: смотрим на Redis-процесс, расчехляем strace, а там «Too many open files». Оказывается, у нас лимит в 1024 соединения, на который не влияет параметр maxclients. Запускаем с ulimit -n 60000 — максимальное кол-во соединений поднимается только до 10240 и не больше. Тут раскопали удивительную вещь: в Redis 2.4 и старше стоял hard limit на 10240 соединений. Через пару дней поставили Redis версии 2.6 RC5, включили persistent соединения к нему и вздохнули с облегчением, зная, что теперь-то нам точно хватит дескрипторов.
Mongo-БДСМ
Командный рост у нас начнётся только в 2013–14 годах. Помимо QA, сформируется команда DevOps, укомплектуется бэкенд и фронтенд. В мобильной разработке по трое девелоперов на iOS и Android. Но на самых ранних этапах так и оставалось полтора человека. Отсюда нехватка ресурсов, недосыпы из-за разницы во времени и банальная невнимательность. А делать приходилось многое. Например, несколько раз переделывать API или полностью переписывать код на бэкенде под работу с MongoDB. Хотя многие её за нормальную базу данных и не считают.

Кто где черпает вдохновение, а мы у YouPorn. На известном в узких кругах Highscalability вычитали, что в качестве основного хранилища данных они используют Redis. Конечно, страшно держать всё в оперативной памяти, потребуются непростые архитектурные решения. Но если YouPorn сидит аж на Redis, мы разве с MongoDB не справимся?
Да, иногда с ней было приятно, но чаще она делала атата плетью и вставляла кляп. Этот роман продолжается по сей день, но тогда мы, в статусе первого парня, испытывали многие истерики и косяки на себе.
Оправданием всему был шардинг из коробки и, конечно, хайп. В нашем случае это было удобно, потому что мы ленивые и не хотели утруждать себя написанием дополнительного кода и заниматься вопросами балансировки данных. Ещё в MongoDB нас привлекли in-place updates, schema-less & embedded documents. Она заставила нас задуматься о подходе к проектированию структуры данных в высоконагруженных сервисах. Так началось переписывание и миграция с MySQL. Это примерно середина 2012-го и мы начали пользоваться MongoDB 2.0.
Плохой знак, который предвосхитил все наши будущие мытарства, был уже в самом начале. Ошибку допустили в процессе переписывания. Дело в том, что любой мем, который заливается в iFunny, может быть забанен: для этого необходимо определенное количество жалоб. Мы выставили пороговые значения в MongoDB, а когда запустили в эксплуатацию, они продолжали читаться из MySQL. Там они были почти нулевые и буквально одной-двух жалоб хватало, чтобы забанить работу. А с учетом наших троллей… 4000 отборных мемов пропали из Featured. Починилось всё за день, но сложилась ситуация полная драматизма по нашей банальной невнимательности.
Миграция
Спустя 5 месяцев переписывания кода, в свободное от тушения пожаров время, наступил день великой миграции, которая сразу провалилась: MongoDB не выдержала нагрузки. Потому что забыли много индексов накинуть. Потому что кучу багов создали. Усугублял положение сырой MongoDB-PHP драйвер с утечками памяти и проблемами с «форкнутыми» скриптами. Кто тут сказал про тестирование? Не было никакого тестирования на тот момент, нам же некогда — мы пилим новые фичи и сразу в продакшн.
В тот день наши пользователи в надежде посмеяться хоть где-то нахлынули на ресурсы 9GAG и благополучно его положили. Хоть одна радость.
Разница во времени тоже подкидывала проблем: когда в США самая активность — у нас ночь. И вот как мы выглядели на следующее утро, когда надо было ложиться спать:

Две недели кропотливого труда и мы решились на вторую попытку. Всё прошло гладко, почти идеально. Появилось понимание, что без реплик и шард далеко не уедем, а с MongoDB это было легко провернуть.
Всё было хорошо, пока не вышли на пиковую нагрузку. База не выдерживала ночной наплыв пользователей, и мы опять прилегали. При этом были непонятны причины тормозов — CPU или IO, приборы ни о чём толком не говорили. После очередных бессонных ночей, с помощью доброго самаритянина, находится источник проблем: стандартный аллокатор памяти в MongoDB плохо работает под нашей нагрузкой. В итоге подменили аллокатор на tcmalloc и стали ждать ночи. Вуаля, нагрузка упала в 3 раза и мы стали иногда спать по ночам. Тогда поняли ещё кое-что важное: базы данных тоже пишут люди. В следующей версии разработчики MongoDB 2.6 стали включать tcmalloc в поставку по умолчанию.
Всё это время наш саппорт разгребал кучу писем с жалобами на работу приложения:

Видимо, тогда у нас сложилась уникальная ситуация. В очередной раз подтверждалось, что с такой высокой нагрузкой мало кто сталкивается. Или перефразируя иначе: мы единственные раздолбаи, кто на такой нагрузке использует подобные технологии и в принципе допускает, что она может идти на одну ноду.
Если вернуться в прошлое и снова решать, мигрировать ли на MongoDB, то ответ был бы однозначный: в качестве primary storage — не надо. Сейчас работа над ошибками выглядела бы так: для начала избавиться от джойнов, сделать шардинг с виртуальными шардами, унести счётчики куда-нибудь и считать их асинхронно, а для schema-less использовать что-то наподобие jsonb из PostgreSQL. Кто знает, может мигрируем опять. Мы не зарекаемся.
Аудитория
У аудитории юмористического приложения есть один огромный плюс — над всем можно посмеяться. Например, над тем, как у нас падают сервера:

Также никто не мешает устроить голосование на звание «Best on toilet app»:

Часто нам падают письма с благодарностями за то, что приложение помогает справиться с депрессией. Юмор лечит:

Всё это прямо влияет на нас.
Первое время после запуска iFunny технического брака было так много, что юзеры прозвали команду разработки обезьянами. Мы не отрицаем. Взгляните хотя бы на логотип FunCorp.

Но есть и другая сторона.
Во-первых, пользователей очень много. Малейшая ошибка — и саппорт перегружен.
Во-вторых, им хочется самоутверждаться. В порядке вещей устроить рейд на контент и минусовать всё подряд.
У вас тут API не работает
Перестали работать наши API-методы. Посыпались жалобы. Гипотез было много, думали даже о блокировке сотовыми сетями. Но когда набралось достаточное количество пользовательских жалоб, мы смогли найти закономерность. Это были айфоны с jailbreak. Тогда было модно снимать защиту и внедрять свои твики с собственными шрифтами и другими рюшечками. Многих, особенно подростков, это забавляло и помогало выделиться. На один из таких твиков у нас случилась аллергия: он перехватывал исходящие HTTP-запросы и удалял некоторые заголовки из них перед отправкой на сервер. Стали предупреждать пользователей о проблемах с конкретными твиками, на этом и разошлись.
О таких нюансах мы даже не думали, но большая аудитория делает своё дело. Сейчас не вспомним сколько таких было, 10 или 50 тысяч. Относительно всего приложения — это мизер, но для саппорта… вы уже видели как это выглядит.
Вывод: репутация страдает, даже если криворукий не ты. За весь долгий опыт разработки мы натыкались на баги и крэши у всех, начиная с Flurry и AWS, заканчивая Apple и Google. Это било как по нашей репутации перед пользователями, так и по DAU.
Невнимательность
Напоследок о невнимательности. Из-за человеческого фактора случается много ошибок. И мы не исключение.
146% может организовать не только Чуров
В iFunny появился веб-апп для голосований. Так сошлись звёзды, что за неимением времени у бекэндеров и за имением желания у фронтендеров написать бекэндный код, голосование получилось неатомарным. Обновление количества голосов шло через обычный инкремент поля в коде, а для базы это типичный read-before-write без локов. Вышло расхождение в лучших традициях российских выборов. Пользователи, конечно, нас потроллили. Возможно, они даже подумали, что это было сделано специально. Но только на Хабре мы расскажем всю правду.
Свидетельство позора не сохранилось, но сохранились красноречивые комментарии:
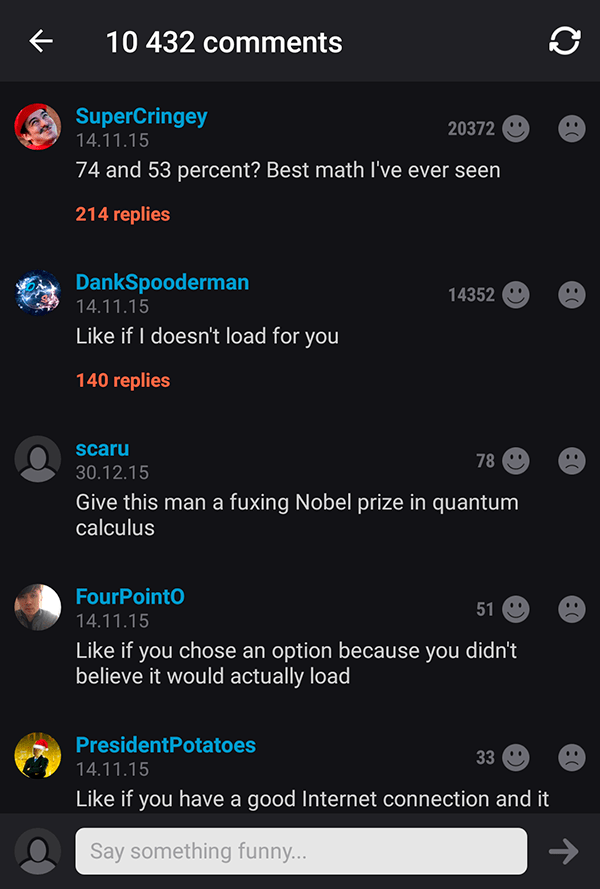
В следующем голосовании всё уже было правильно, но если ещё раз посчитать в нашем стиле, то можно прийти к выводу, что Трамп, получивший 48% голосов, проиграл бы Путину почти в 2,5 раза.

Банальное разгильдяйство
Собираешь, собираешь пользователей, вовлекаешь их, веселишь нещадно, а потом забываешь о какой-то мелочи, и всё. Нет их. Собственноручный отстрел аудитории мы устроили 2 года назад.
Сделали поддержку бейджиков для Android-приложения. В 2015 они появились только у Samsung. Нотификация была классная и не раздражающая. Через некоторое время бейджики сломались и никто этого не заметил. Спустя ещё несколько месяцев это заметил один из продактов. Мы всё починили и прибавили в DAU 120К.
Оказывается, внимательнее нужно быть всем: и QA, и продактам, и разработчикам. И тебе. Да-да — тебе. Вот читаешь сейчас этот лонгрид, а тем временем где-то что-то ломается. Не будь как мы, пойди проверь.
А мы возобновляем блог на Хабре, где будем делиться новыми-старыми историями.
В 2013 нас хватило только на один пост про оптимизацию анимации To Gif or not to Gif. За прошедшие годы накопилось много интересного, о чём хотелось бы рассказать: AWS, NoSQL, iOS, Android, математика в лентах, Big Data, премодерация контента, спам. Иногда это даже не фейлы, а удачные решения и на каждое найдётся целая гора мемов. Поэтому больше юмора в жизнь, ведь Fun Happens:)
Комментарии (2)
9 февраля 2017 в 18:17
0↑
↓
Хотел посмотреть, зашёл на ваш сайт, ничего смешного не нашёл, перечитал пост:Но Web-версия постепенно догоняет app«ы как по аудитории, так и по наполнению.
iFunny можно пользоваться анонимно, не регистрируясь.
Что я сделал не так? rbatoon89
rbatoon89
9 февраля 2017 в 18:25
0↑
↓
Ну вот вроде бы смешно
