Level Up: Геймдев в эпоху искусственного интеллекта

Машинное обучение революционизирует игровую индустрию всё больше. Если играли, то знаете, что в играх теперь не просто бездумно бегают NPC, а ведут битву настоящие стратеги, которые адаптируются к вашему стилю игры и, так уж и быть, позволяют вам красиво выиграть, а себе — также красиво (или не очень) проиграть…
Как так происходит?
С помощью ML, конечно.
Есть обучение с учителем. Это когда персонажи учатся на основе заранее размеченных данных или подсказок, что можно представить как обучение на основе опыта предыдущих игроков или действий разработчиков. В результате получается оптимальное поведение, которое уже имеет определенную «интеллектуальность».
Есть обучение без учителя. Здесь уже боты изучают игровую среду и формируют свои стратегии, не имея прямых указаний от разработчиков или опыта предыдущих игроков. Этот подход позволяет создавать персонажей, которые могут адаптироваться к самым разным игровым ситуациям, даже если они не были предвидены заранее.
И наконец, обучение с подкреплением. Это когда боты принимают решения, основываясь на полученных «наградах» или «штрафах» за свои действия, что в игровом мире может быть аналогично получению очков или бонусов за правильные действия и потере жизней или опыта за ошибочные.
Учим ботов стать лучше: обучение с учителем в геймдеве
От простых NPC до сложных стратегических решений почти на одном уровне с игроком — обучение с учителем в геймдеве открыло перед разработчиками новые горизонты возможностей.
Так как это работает?
Сначала необходимо собрать данные об игровых ситуациях и правильных решениях для различных игровых ситуаций.
Это можно сделать такими способами:
Понаблюдать за тем, как играют профессиональные игроки. Ещё можно использовать алгоритмы, которые эмулируют поведение игроков и записывают их действия в различных игровых ситуациях.
Сгенерировать сценарии. В некоторых случаях сценарии игры могут быть созданы искусственно для получения размеченных данных.
После того, как данные были собраны, их нужно обработать и подготовить для обучения модели.
Это процесс состоит из:
Удаления шума или несущественных факторов из данных.
Преобразования данных в формат, подходящий для обучения модели, например, числовые значения или категориальные признаки.
Разделения данных на обучающую, валидационную и тестовую выборки для оценки качества модели.
После того, как данные подготовлены, нужно выбрать модель машинного обучения, которая будет учиться на этих данных. Это может быть любая модель, которая подходит для решения конкретной задачи в игре. Например, нейронные сети, деревья решений, случайные леса и т.д.
Вот пример простого кода на Python для обработки и подготовки данных для обучения модели в геймдеве:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# Загрузка данных
data = pd.read_csv('game_data.csv')
# Предварительная обработка данных
# Удаление ненужных столбцов или шума
data.drop(['player_id', 'timestamp'], axis=1, inplace=True)
# Преобразование категориальных признаков в числовые
data = pd.get_dummies(data, columns=['action'])
# Разделение данных на обучающую и тестовую выборки
X = data.drop('target', axis=1)
y = data['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Масштабирование признаков
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Дальнейшие шаги: выбор модели и обучениеЭтот код загружает данные из CSV-файла, выполняет предварительную обработку, включая удаление ненужных столбцов и преобразование категориальных признаков в числовые, разделяет данные на обучающую и тестовую выборки, а также масштабирует признаки для улучшения производительности модели. Далее требуется выбрать подходящую модель машинного обучения и обучить её на подготовленных данных.
Сам процесс обучения модели заключается в настройке её параметров на основе обучающих данных. В случае обучения с учителем модель «учится» находить зависимости между входными данными и целевыми значениями, минимизируя ошибку прогнозирования.
Вот как это может выглядеть в коде на Python с использованием библиотеки scikit-learn:
from sklearn.linear_model import LinearRegression
# Создание модели линейной регрессии
model = LinearRegression()
# Обучение модели на обучающих данных
model.fit(X_train_scaled, y_train)
# Предсказание значений на тестовых данных
y_pred = model.predict(X_test_scaled)Этот код создает модель линейной регрессии, обучает её на обучающих данных (X_train_scaled, y_train) и делает предсказания на тестовых данных (X_test_scaled). В этом примере модель «учится» находить зависимости между входными данными (X_train_scaled) и целевыми значениями (y_train), минимизируя ошибку прогнозирования. Конечно, реальные задачи могут быть более сложными, и они требуют более глубокого анализа и настройки параметров, но основной принцип остается тем же.
После того, как обучение завершено, модель необходимо оценить на тестовых данных, чтобы оценить её качество и способность обобщаться на новые данные. Это позволяет проверить, насколько хорошо модель справляется с задачей и насколько её прогнозы точны.
Если предыдущие этапы прошли успешно, то модель может быть интегрирована в игру.
С этим понятно, но почему сам метод называется «обучение с учителем»?
Обучение с учителем получило свое название из-за аналогии с процессом обучения в школе или университете, где преподаватель (учитель) передает знания и опыт ученику.
В контексте ML, «учителем» являются размеченные данные, которые содержат в себе правильные ответы или метки для задачи, которую модель должна научиться решать. Эти данные используются для «обучения» модели, которая по сути является учеником, чтобы она могла извлечь закономерности из данных и научиться делать предсказания на основе новых входных данных.
Обучение без учителя
Давайте теперь поговорим о методе обучения без учителя, который открывает ещё больше возможностей для развития игрового мира. В отличие от обучения с учителем, где у нас есть размеченные данные с правильными ответами, в обучении без учителя модели приходится «учиться» на основе неразмеченных данных.
Да, так можно было.
В первую очередь, нам нужно иметь данные о состояниях игры или о её действиях, но без явно заданных меток или правильных ответов. Мы можем использовать различные методы для сбора таких данных:
Кластеризация данных
Этот метод позволяет группировать данные по их сходству, выявляя скрытые структуры или шаблоны без явного задания меток.
Автоэнкодеры
Это нейронные сети, которые обучаются создавать компактное внутреннее представление данных, что может помочь выявить скрытые закономерности в неразмеченных данных.
Генеративные модели
Эти модели стремятся создать вероятностную модель данных, которая может быть использована для генерации новых, похожих на исходные данные.
Как только мы подготовим данные, то можем перейти к обучению модели. Вместо предоставления правильных ответов, модель сама ищет структуры и закономерности в данных. Это может включать в себя:
Методы кластеризации
Принцип работы методов кластеризации заключается в разбивке данных на группы таким образом, чтобы объекты внутри одного кластера были как можно более похожи между собой, а объекты из разных кластеров — как можно более различны. Для этого используются различные алгоритмы, такие как K-means, иерархическая кластеризация, DBSCAN и многие другие.
В геймдеве методы кластеризации могут применяться разными способами. Например, разработчики могут использовать их для анализа поведения игроков. В WOW (World of Tanks) можно выделить кластеры игроков, предпочитающих сражения на быстрых танках, отличающиеся от кластеров игроков, предпочитающих тяжелые танки.
Это персонализирует игровой опыт для каждой группы игроков и предлагает им соответствующий контент.
Другой пример — это генерация уровней и контента. Методы кластеризации могут быть использованы для анализа архитектуры игровых уровней и группировки их на основе общих элементов или характеристик.
Моб Вервольф из Minecraft
В Minecraft можно использовать кластеризацию для создания разнообразных уровней, каждый из которых представляет собой различные комбинации элементов дизайна уровня. Это может быть расположение мобов (врагов), распределение ресурсов или архитектура ландшафта.
Обучение на основе плотности
Простыми словами, модель пытается понять, как данные распределены в пространстве признаков, то есть как они размещены и какие закономерности или шаблоны могут быть выявлены.
Когда мы говорим о распределении данных, то представляем, что данные находятся в некотором пространстве, где каждая ось представляет собой признак или характеристику. Например, в трехмерном пространстве признаков данные могут быть представлены точками в трехмерном графике, где каждая ось соответствует определенному признаку.
Модель обучения на основе плотности стремится построить математическую модель, которая описывает, как данные распределены в этом пространстве признаков. Это позволяет модели выявлять аномалии или неожиданные шаблоны данных, так как она может определить, какие области пространства признаков более плотно заполнены данными, а какие менее плотно.
Один из примеров игр, в которых можно использовать метод обучения на основе плотности для обучения ботов противников, это стратегическая игра в реальном времени (RTS) StarCraft II. Она высоко стратегическая, поэтому игрокам часто приходится принимать сложные решения, основанные на текущей ситуации и действиях противника.
В StarCraft II можно использовать метод обучения на основе плотности для обучения ботов противников, чтобы они адаптировали свои стратегии в зависимости от поведения игрока и ситуации на карте. Например, модель может анализировать игровые данные, такие как расположение войск, состав армии, ресурсы и т. д., и определять, какие стратегии наиболее эффективны в различных игровых ситуациях.
Вот здесь будет уместно вспомнить про нейросеть AlphaStar. Особенно про то, как она обыгрывала профессиональных игроков в StarCraft II. Разработанная компанией DeepMind, AlphaStar была представлена в начале 2019 года и сразу же вызвала огромный интерес игрового сообщества.

AlphaStar обыгрывает профессиональных игроков в StarCraft II
Почему?
Основные технологии, использованные в AlphaStar — это глубокое обучение (deep learning) и обучение с подкреплением (reinforcement learning).
В начале процесса обучения AlphaStar была предоставлена огромная база данных матчей, сыгранных обычными игроками. Эти данные использовались для обучения нейронной сети, чтобы она могла адаптироваться к различным игровым ситуациям и принимать лучшие решения.
Затем AlphaStar прошла через процесс обучения с подкреплением, который позволил ей соревноваться со своими собственными версиями в ускоренном режиме. Этот метод обучения позволил AlphaStar значительно улучшить свои навыки и стратегии игры. За время обучения каждой из версий AlphaStar было сыграно огромное количество матчей, эквивалентное 200 годам игрового времени.
И да, именно так AlphaStar научилась обыгрывать лучших игроков в StarCraft II в 95% случаев.
Генерация данных
Такой метод используется для создания новых данных на основе имеющихся.
Для создания новых данных методы генерации могут использовать различные подходы: случайная генерация, аугментация данных и генеративные модели, такие как генеративные состязательные сети (GAN) или вариационные автокодировщики (VAE). Эти методы позволяют создавать данные, которые сохраняют основные характеристики и структуру исходных данных, но при этом добавляют разнообразие и новизну.
В игре No Man’s Sky разработчики использовали методы генерации процедурных миров для создания бесконечного и уникального игрового мира.

No Man’s Sky
Здесь весь игровой мир —- планеты, флора, фауна и атмосфера — генерировался случайным образом на основе набора математических алгоритмов и правил. Благодаря этому каждый игрок может исследовать уникальные локации и встречать разнообразных существ в этом бесконечном мире. Возможно, именно поэтому No Man’s Sky обрела просто бешеный успех.
Выживаем и побеждаем: обучение с подкреплением
Обучение с подкреплением — это как игра, где вы учитесь, делая разные ходы и получая «награды» или «штрафы» в зависимости от того, насколько хорошо вы играете. Этот метод машинного обучения использует концепцию проб и ошибок для улучшения результатов.
Давайте представим, что вы играете в игру, где ваша цель — добраться до конечной точки, избегая препятствий. Вы начинаете с первого уровня и пробуете разные действия: идти вперед, поворачивать влево или вправо, прыгать, бегать… За каждое успешное действие вы получаете очки, а за неудачные — штрафы. С течением времени вы узнаете, какие действия приводят к наилучшим результатам, и начинаете использовать их, чтобы пройти уровень быстрее и с большим количеством очков.
Точно так же работает обучение с подкреплением. Модель, называемая агентом, принимает решения в определенной среде и получает положительные или отрицательные вознаграждения за свои действия. С течением времени агент учится выбирать наилучшие действия для достижения цели, максимизируя получаемые награды.
Технически обучение с подкреплением включает в себя несколько ключевых компонентов:
Агент
Это модель или алгоритм, который принимает решения в среде, чтобы достичь определенной цели. В контексте игр это может быть персонаж или бот, который действует в игровом мире.
Среда
Это окружение, в котором действует агент. В играх это игровой мир с его правилами, объектами и возможностями. Среда предоставляет агенту информацию о его текущем состоянии и реагирует на его действия.
Действия
Это возможные действия, которые может совершать агент в среде. Например, в игре это может быть движение, атака и т. д.
Награды
Это положительные или отрицательные сигналы, которые агент получает от среды в ответ на его действия. Награды мотивируют агента выбирать оптимальные действия для достижения цели.
Если всё понятно, можете переходить к следующему разделу, если не очень — объясняем.
Представьте, что вы играете в шутер от первого лица. Как и всегда, вы управляете персонажем и стремитесь выполнить различные задачи.
В процессе игры игровой движок постоянно анализирует ваше поведение и результаты в игре. Например, если вы убиваете противника, то получаете положительную награду (новое оружие, если противник был вооружен, опыт, открытый путь к цели и т. д.), а если вас убивают, то получаете отрицательную награду (ранение, потерю жизней других персонажей из своей команды, понижение рейтинга и т. д.).
Как это работает в контексте обучения с подкрепления?
Теперь представьте, что ваш персонаж контролируется не вами, а нейросетью или алгоритмом. Этот алгоритм принимает решения, основываясь на том, какие действия приводят к получению наибольшей положительной награды и минимизации отрицательной награды. В начале обучения этот алгоритм просто пробует разные действия и наблюдает, какие из них приводят к положительным результатам.
Таким образом, по мере того, как алгоритм получает опыт в игре и анализирует свои действия, он «учится» выбирать наилучшие действия для достижения цели, которую ему поставили (например, победа над противниками). Этот процесс обучения с подкреплением подразумевает постепенное улучшение стратегии агента на основе накопленного опыта и обратной связи от среды.
Примером применения обучения с подкреплением в играх является AlphaStar в StarCraft 2, о которой мы говорили ранее. AlphaStar использовала этот метод, чтобы соревноваться со своими собственными версиями в игре и учиться играть на уровне, который превосходит 99,8% игроков. Она получала награды за успешные ходы и штрафы за неудачные, что позволило ей постепенно совершенствовать свои навыки и стратегии игры.
Чтобы было ещё понятнее с тем, как работает обучение с подкреплением, давайте вспомним нулевой эпизод Bandersnatch 5 сезона сериала «Черное зеркало». Здесь зритель сам становится частью сюжета, поскольку Netflix подогнал эту серию под формат интерактивного кино. Впервые за всю историю индустрии, кстати.
В этом эпизоде главный герой, Стефан (он программист, создает игру Bandersnatch) сталкивается с рядом выборов, которые определяют развитие сюжета. Каждое решение, принятое зрителем за Стефана, влияет на последующие события и исход истории.

«Черное зеркало» (5 сезон, серия 0)
Это напоминает процесс обучения с подкреплением, где агент, подобно главному герою, принимает решения, а среда, включая реакции зрителей, предоставляет обратную связь. Постепенно агент «учится» выбирать действия, которые приводят к желаемому исходу, на основе накопленного опыта и обратной связи. Таким образом, зритель выступает в роли обучающей среды, влияя на ход событий и формируя исход истории в соответствии с принятыми решениями.
Reinforcement Learning: лучшие примеры
Ещё примеров хотите?
Пожалуйста, Left 4 Dead. Здесь боты зомби были разработаны с использованием методов обучения с подкреплением для достижения более реалистичного поведения. Эти боты обладали способностью адаптироваться к действиям игроков и изменять свои тактики в зависимости от текущей игровой ситуации.

Left 4 Dead
Одним из ключевых аспектов использования обучения с подкреплением в этой игре была способность ботов зомби сотрудничать друг с другом. Они могли формировать группы и координировать свои действия, чтобы создавать более сложные и опасные ситуации для игроков. Например, могли атаковать одновременно с разных направлений или использовать различные виды зомби для создания давления на игроков.
Такой подход позволил создателям игры достичь более реалистичного и захватывающего геймплея, где боты зомби представляли собой значительную угрозу для игроков, адаптируясь к их действиям и создавая динамичные и напряженные бои.
В игре Alien: Isolation студии Creative Assembly применялись продвинутые методы искусственного интеллекта, включая элементы обучения с подкреплением, чтобы создать уникальное и напряженное взаимодействие между игроком и враждебным персонажем, ксеноморфом.

Alien: Isolation
В игре ксеноморф обладает высоким уровнем интеллекта и может адаптироваться к действиям игрока в реальном времени. Например, если игрок часто прячется в одном месте или использует одну и ту же стратегию избегания опасности, ксеноморф начинает анализировать такие действия и изменять свое поведение соответственно. Он может начать активнее патрулировать в этих зонах, становиться более осторожным или даже использовать уловки, чтобы привлечь игрока.
В результате ИИ-ксеноморфа становится не просто программой, следующей за скриптами, а настоящим оппонентом, способным адаптироваться к уникальному стилю игры каждого игрока.
Всё это, конечно, создает непрерывное напряжение и атмосферу ужаса, когда вы играете и даже не представляете, когда и где может появиться опасность… Приходится постоянно быть на чеку.
И напоследок. Слово «nemesise» вам о чём-нибудь говорит?
Если не можете вспомнить, то подскажем.
Middle-Earth: Shadow of Mordor, выпущенная в 2014 году, принесла свежий взгляд на игры по мотивам вселенной Властелина Колец. Но самым уникальным аспектом этой игры стала система Nemesis.
Nemesis стала своего рода революцией в индустрии видеоигр. Вместо стандартного подхода, где противники были предопределены и не менялись в зависимости от ваших действий, в Shadow of Mordor каждый враг был индивидуальным: имел свою уникальную личность, страхи, историю и внешность.

Middle-Earth: Shadow of Mordor
Ключевым элементом системы было то, что враги могли помнить вас и реагировать на ваши действия. Если враг выжил после встречи с вами, он мог вернуться, чтобы отомстить. Иногда враги даже продвигались по службе, становясь более могущественными и опасными, если им удавалось убить игрока. Таким образом, игрок чувствовал, что его действия имеют последствия и влияют на игровой мир.
Именно благодаря системе Nemesis игра стала непредсказуемой и захватывающей. Игроки впервые столкнулись с ощущением, будто они ведут настоящую войну, где каждый противник имеет свою собственную судьбу и мотивацию. Это создало по-настоящему захватывающие игровые моменты, которые игроки запоминали надолго.
Технически система Nemesis была реализована с использованием алгоритмов машинного обучения и обучения с подкреплением. Враги в игре наблюдали за действиями игрока и на основе этого принимали решения о своем поведении и стратегии. Их эволюция происходила в реальном времени, что создавало ощущение живого и динамичного мира.
Вот так система Nemesis в Middle-Earth: Shadow of Mordor стала важным шагом в развитии ИИ в видеоиграх, демонстрируя потенциал обучения с подкреплением для создания уникального и захватывающего игрового опыта.
На что сейчас способен ИИ в геймдеве?
Существует ли возможность создать систему, которая может эффективно взаимодействовать с трехмерным окружением любой игры без продолжительной предварительной подготовки? Корпорация Google уверена, что это возможно. Команда разработчиков из Google DeepMind даже доказала это, создав агента, способного к этому.
Какие перспективы открывает эта новая разработка?
На данный момент проект находится на стадии proof of concept и нельзя считать его завершенным. Однако результаты обнадёживают и позволяют предположить, что в будущем можно будет довести новый продукт до уровня обычного геймера. Цель «догнать и перегнать» человека не стоит, скорее, исследователи хотят предоставить основу для создания платформ искусственного интеллекта разного уровня. Люди смогут взаимодействовать с ними в различных сферах, а не только игровой.
Авторы этого исследования говорят, что трехмерные игры — это как раз та штука, которая может научить компьютеры кое-чему интересному. Они взяли девять игр, где можно было взаимодействовать с миром, но без лишнего насилия, и начали обучать своего агента SIMA. Разработчики, с которыми они сотрудничали, включали такие компании, как Hello Games, Embracer, Tuxedo Labs и другие. Они использовали игры типа No Man’s Sky, Teardown, Valheim и Goat Simulator 3, чтобы потренировать своего агента.
SIMA не знал внутренних хитростей игры или программного интерфейса (API). Вместо этого он просто смотрел на экран и управлялся так же, как и любой другой игрок, — с помощью клавиатуры и мыши. Интересно, что агент мог это делать в реальном времени, без многих часов обучения, как это обычно бывает.
Чтобы его обучить, они использовали видеозаписи игр, где люди показывали, как играть, а потом добавили к этому еще немного обучения с помощью предварительно обученных моделей. Такой подход позволил минимизировать время, необходимое для понимания всего этого языка и визуальных данных.
Испытав его на 1500 различных задачах в девяти разных областях, они оценили его успех исходя из точки зрения компьютера и обычного человека. SIMA мог находить общие черты в разных играх и успешно справляться с базовыми задачами. Хотя его успех в тестировании варьировался в зависимости от конкретной задачи, он все же превзошел других агентов во всех девяти играх.
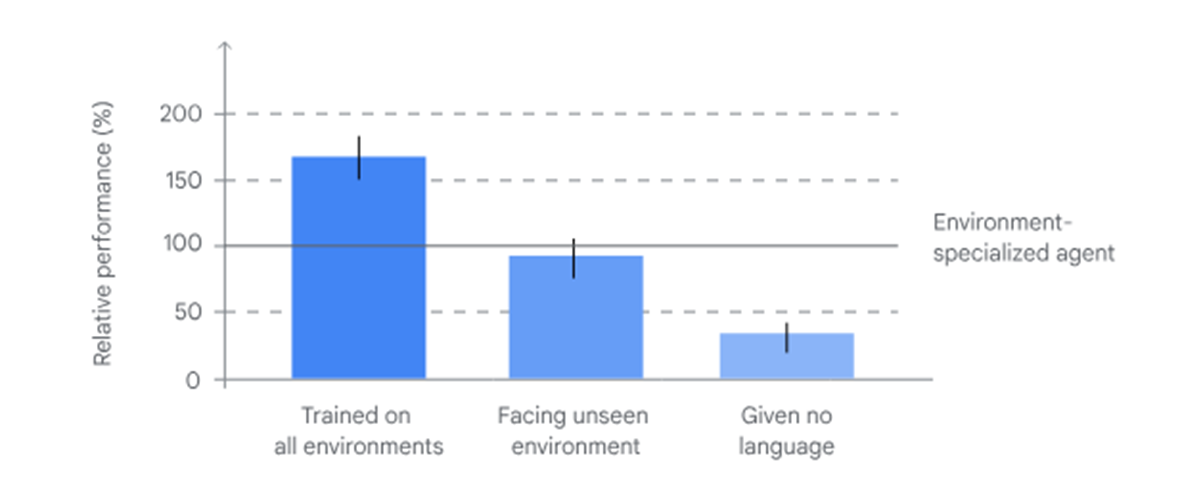
Но не торопитесь делать выводы, что SIMA уже может выиграть любую игру, как профессиональный киберспортсмен. Пока что SIMA справляется только с некоторыми вещами. Например, в No Man’s Sky он успешен лишь в трети задач, а у человека результат вдвое лучше. Но это ведь не так уж и плохо, учитывая, что задания были не из легких, верно?
Основная проблема в том, что иногда агент не понимает, как добиться успеха. Да, он знает, что такое «срубить дерево», но как выбрать нужное дерево, о котором говорит игрок, пока загадка. Или вот еще пример: агент умеет стрелять по врагам, но как только цель скрывается, он тут же забывает о ней. В то время как настоящий игрок знает, что нужно преследовать врага до самого конца. Так что здесь еще есть над чем поработать.
Команда Google DeepMind сейчас старается сделать так, чтобы будущие версии SIMA могли справляться с широким спектром задач, включая не только рубку деревьев, но и поиск ресурсов или даже строительство лагеря, где требуется планирование. И, конечно же, конечный шаг — использовать агентов, обученных в играх, для решения реальных задач в реальном мире.
Впрочем, это уже совсем другая история.
