Альтернативный вариант к подходу хранения SQL-кода в репозитории и его разработке
Приветствую, current_user ()!
В мире разработки баз данных хранение кодовой базы (далее — КБ) и её обновление на разных инстансах являются задачами, с которыми сталкиваются многие специалисты. Одним из общепринятых подходов к этой проблеме является использование файлов миграций, которые содержат изменения состояний базы данных и переносят её из одной версии в другую. Однако, помимо этого метода, существуют и другие инструменты и методы управления миграциями, которые могут быть более эффективными и удобными в различных сценариях.
В этой статье мы рассмотрим существующие подходы к хранению и обновлению кодовой базы данных, а также представим новый метод, который может быть эффективным альтернативным решением. Мы обсудим основные проблемы и недостатки стандартного подхода к миграциям, а затем представим концепцию, основанную на современных принципах разработки и автоматизации, которая может значительно улучшить процесс управления изменениями в базе данных.
Цель этой статьи — предоставить читателям новые идеи и инструменты для улучшения процесса управления изменениями в базе данных, что позволит им эффективнее и безопаснее развивать свои проекты.
Предисловие
Начало этого пути произошло случайно, когда я просто экспериментировал с новым подходом. Недавно наш интерес (в нашей компании) к этому подходу возрос, и мы решили внедрить его. В настоящее время мы активно работаем над ним, внося множество правок, поскольку столкнулись с немалым количеством подводных камней.
В этой статье мы сосредоточимся исключительно на концепции подхода к хранению и разработке кодовой базы. Здесь мы не будем предлагать готовые инструменты (за исключением, возможно, псевдокода или bash-кода для пояснения происходящего).
Для удобства понимания, вся статья будет разделена на следующие части:
и так начнём.
Пример того, как в данный момент используют файлы миграций
Для различных инструментов и подходов выглядит всё по-разному, я же попытаюсь описать псевдовариант.
Смысл тут очень простой: у нас есть КБ версии прода, мы хотим хотим добавить новую фичу. Для этой фичи надо добавить какие-то колонки, поменять какие-то функции, добавить триггеры.
Все эти манипуляции заносятся в файл миграции с именем $number+1.sql, где number — это номер последней миграции в каталоге миграций.
После этого можно накатывать эту миграцию тем инструментом, которым пользуются в данном проекте.
Пример
Создадим файл миграции:
# путь к папке с миграциями
MIGRATION_PATH="~/git/project/sql/migrations"
# запишем сразу number+1 сюда
NUMBER="101"
# в результате фичи добавляли таблицу users
echo "create table users(id int, name text);" >> $MIGRATION_PATH/$NUMBER.sql
# допустим, ещё был создан индекс по users.name
echo "create index on users(name);" >> $MIGRATION_PATH/$NUMBER.sqlНу и всё, миграция готова, осталось только скормить его вашему ПО для заливки миграций
Инструментов для заливки миграций существует очень большое количество. Вот, например, некоторые из них: flyway, liquibase, pg_mig, db-migrate, pg_codekeeper.
В общем их алгоритм таких инструментов (кроме pg_codekeeper) выглядит следующим образом:
Сбор всех файлов миграций на входе
Проверка, залиты ли эти миграции в БД
Те, которые не залиты — заливаются
Постановка задачи
Этот раздел назван не совсем корректно.
В нём будут описаны признаки подхода к разработке, к которым подойдёт описанная в этой статье концепция.
Задача (критерии):
в проекте бóльшая часть бизнес-логики реализована на уровне БД → почти все изменения кода бэкенда затрагивают хранимые функции в БД
сделать удобное хранение кода в репозитории
чтобы можно было удобно смотреть историю изменений тех или иных
чтобы было удобно проводить ревью кода
бэкендеров/задач много — нужна хорошая устойчивость к конкурентной (параллельной) разработке
имеется в виду, что может быть открыто несколько МР на изменение одной и той-же функции в БД, нужно сделать так, чтобы изменения не затирали друг друга
Описание структуры концепции
Мне категорически не нравилось то, что мы должны создавать для каждой фичи свой файл миграции. При параллельной разработке часто бывало, что вносятся изменения в одну и ту же функцию, по итогу создавались 2 миграции, которые не видели изменения друг друга, из-за чего при заливке миграций в прод мы могли лишиться части функционала
Пример такой ситуации
Допустим, у нас была функция:
-- migration #100
create function myfunc(
p_user_id bigint,
p_amount numeric)
returning bool
as $$
begin
return exists(
select from users
where
id = p_user_id
and amount > p_amount);
end;
$$Нам ставится задача, чтобы мы добавили сюда ещё проверку по status = 'active', и в МР мы создадим файл миграции, в котором будет функция такого вида:
-- migration #101
create function myfunc(
p_user_id bigint,
p_amount numeric)
returning bool
as $$
begin
return exists(
select from users
where
id = p_user_id
and amount > p_amount
and statuss = 'active');
end;
$$Параллельно с этой задачей нам поставили новую задачу, в ней говорится, что проверка на amount должна быть с запасом в 100 у.е., т.е. amount > p_amount + 100, получается, во втором МР мы создадим файл миграции, в котором будет функция:
-- migration #102
create function myfunc(
p_user_id bigint,
p_amount numeric)
returning bool
as $$
begin
return exists(
select from users
where
id = p_user_id
and amount > p_amount + 100);
end;
$$И в чём вся проблема заключается:
когда инструмент для заливки миграций будет отрабатывать, он сначала зальёт первую миграцию, потом вторую. Соответственно, изменения по первой задаче зальются в БД, а потом сотрутся.
Чтобы этого избежать — приходится много раз всё проверять и писать кучу приблуд для проверок. Или-же не допускать параллельной разработки одного и того-же объекта в БД (в данном случае это функция)
Чтобы избавиться от таких проблем можно попробовать хранить каждый объект БД в своей миграции (как в традиционном программировании). Например: создание таблицы `users` будет храниться в файле `public/table/users.sql`, а функция `myfunc` — в `public/function/myfunc.sql`
Так-же нам нужен инструмент, который сможет такие миграции заливать (т.е. не только когда файл добавляется в в список, но и когда модифицируется). Как раз liquibase умеет такое делать.
К чему мы приходим — можно взять код всех объектов БД, распарсить этот код в отдельные файлы-миграции. В будущем, когда эти файлы-миграции будут изменяться — не будет создаваться копия этих объектов (как в примере выше), а просто модифицироваться уже существующий файл-миграция.
Но этого будет недостаточно.
Если мы добавляли, к примеру, столбец в таблицу — новый скрипт не добавит его.
Тут нам помогут так называемые «добивочные» миграции. Их я опишу чуточку позже.
По итогу, с учётом некоторых доработок наше хранилище миграций превращается в нечто подобное:
migrations/before_scripts/
Скрипты, которые выполняются перед заливкой основной части. Например, это скрипты, которые настраивают сессионные переменные
migrations/migrations_scripts/
Скрипты, которые выполняют миграцию структуры БД для некоторых объектов. Для удобства назовём их «добивочные» миграции
migrations/migrations/
migrations/data_scripts/
Это скрипты, которые содержат в себе не схему БД, а именно данные таблиц (например таблица переводов, таблица с конфигами и т.д.)
migrations/after_scripts/
Скрипты, которые выполнятся после заливки всех миграций. Например, обновление конфигов, пересбор каких-то вьюх, сброс статистики pg_state_statement и другое
Описание концепции разработки
В этом разделе я попробую описать всё, что должно происходить с МР и БД от начала разработки фичи и до её вливания в основную ветку (или деплой в прод).
И так, вся разработка у нас поделена на несколько частей (стейджи):
Теперь рассмотрим, конкретней каждый этап:
Примечание: ниже я буду употреблять некоторые возможно непонятные выражения, поэтому дам тут их пояснения:
master-ветка — ветка в репозитории, в которой хранится тот код, который в данный момент работает в проде
dev-ветка — ветка в репозитории, которая является «основной веткой разработки»
фич-ветка — ветка в репозитории, в которой содержатся изменения, касаемые разработки определённой фичи
прод-БД, dev-БД, фич-БД — базы данных, в которых содержится код из соответствующих им веток
Инициализация разработки фичи
Перед тем, как начать программисту работать с БД — её над создать. Для этого сделаем структурную копию БД из дев-ветки (думаю, переменные, которые тут употребляются, не нуждаются в комментариях):
psql -d postgresql://$DB_USER:$DB_PASS@$DB_HOST:$DB_PORT/$sourceDB -c "create database $targetDB"
pg_dump --format=c --schema-only -d postgresql://$DB_USER:$DB_PASS@$DB_HOST:$DB_PORT/$sourceDB \
| pg_restore --format=c -d postgresql://$DB_USER:$DB_PASS@$DB_HOST:$DB_PORT/$targetDBЧто выполняет этот код?
Создаёт БД $targetDB
Создаём дамп структуры БД $sourceDB (это наша dev-БД)
Восстанавливаем эту структуру в $targetDB
После этого, необходимо будет подключить к этой БД все внешние кроны, сервисы и т.д. Но это уже DevOps и тут мы не будем рассматривать всё это, нас интересует только БД и разработчик.
Очень удобно это всё делать на одном кластере с dev-веткой. Потому что у вас будут уже подключены все shared_library и созданы все роли (так-же настроен общий hba).
Разработка
Вот в это разделе разработчик будет радоваться как никто другой.
Поскольку в таком подходе разработчику не надо нигде фиксировать свой код (я имею в виду в файликах миграций, комментариях к МР, чатах и пр). Всё что делает разработчик — делает свою работу непосредственно в фич-БД (да, есть нюансы, но их очень мало).
Когда разработчику необходимо слить результат своей работы в репозиторий и отправить на ревью — он выполняет следующие действия:
Создаёт дамп структуры тестовой БД
Парсит этот дамп и раскладывает по нужным папкам/файлам в репозитории.
Коммитит и пушит
Да, некоторые программы умеют это делать за один раз, но всё же доверия к pg_dump больше:)
Небольшой пример
Попробую тут описать маленький пример того, как это выглядит.
# первым делом сделаем дамп схемы
pg_dump --file "dump_schema.sql" --format=p --schema-only -d postgresql://$1:$2@$3:$4/$5
Слияние фич-ветки в дев-ветку
# запустим скрипт ( в данном случае на python ), который распарсит все объекты и упакует всё в нужный файл
./pg_schema_split.py dump_schema.sql $project_path/sql/migrationsИ так, дамп мы получили, теперь бы его распарсить.
Очень удобным будет вариант парсинга DDL/DCL через их идентификацию какой-нибудь библиотекой парсинга SQL-скриптов, постепенно складывая их по нужным папкам/файлам. Пример такой билиотеки: pg_query_go
В начале для тестов я писал вариант «нативного» парсера на python.
Всё дело в том, что pg_dump на выходе выдаёт скрипты в виде:
--
-- Name: users; Type: TABLE; Schema: public; Owner: postgres
--
CREATE TABLE public.users (
id integer NOT NULL,
name text
);
ALTER TABLE public.users OWNER TO postgres;т.е. выводит шапку (хедер) блока кода, а потом в теле этого блока пишется сам скрипт. Если правильно всё распарсить — можно быстро понимать, где и к чему какой блок кода относится.
После распарсинга ещё надо переделать скрипты на множественный запуск (например create table изменить на create table if not exists).
Замечу, что не все объекты поддерживают if not exists / replace, для некоторых приходится писать подобную оболочку:
DO $$
BEGIN
IF NOT EXISTS ( <проверка того или иного объекта> ) THEN
<скрипт создания объекта>
END IF;
END
$$;Примеры того, что на выходе — будут ниже (в примере ниже показаны старые скриншоты, их я делал ещё со скриптом на python).
Если в результате ревью/тестов обнаружились проблемы — можно спокойно править всё прямо в базе (как при разработке) и скриптом сливать в фич-ветку.
После того, как разработчик всё сделал, прошли тесты, ревьюер всё проверил — можно перейти к подготовке для вливания в дев-ветку.
Слияние фич-ветки в дев-ветку
Как раз на этом этапе создадутся те самые непонятные «добивочные» миграции.
Пример, зачем такие миграции нужны:
Была таблица:
create table if not exists users(
id int,
name text
);В результате разработки фичи мы добавили в эту таблицу поле age int, наш скрипт миграции для этой таблицы стал следующим:
create table if not exists users(
id int,
name text,
age int
);Как все мы прекрасно понимаем, выполнение этого кода заново не создаст новой колонки в проде.
Нам нужен запрос, который создаст колонку отдельно:
alter table if exists users add column if not exists age int;Такие скрипты легко генерировать через различные sql-diff-утилиты.
Последовательность будет следующая:
Создадим новую БД от дев-ветки (скрипт мы и так знаем, не буду дублировать)
Накатим туда те основные миграции, которые у нас получились в результате работы прошлого этапа.
Сравним новую БД и фич-БД какой-нибудь sql=diff-утилитой, а результата запишем в файл «добивочной» миграции
Вот пример использования pg_codekeeper-а:
$run_pgcodekeeper $newDB_url $targetDB_url >> $migrationsPath/migration_scripts/$continueMigrationName.sqlКогда создастся «добивочная» миграция, всё что надо будет сделать — ещё раз её проверить (автоматика- это круто, но прод уронить тоже не хочется). После чего — закрыть МР.

В итоге блок-схема работы будет выглядеть как-то так
Пример использования
Я буду тут прикреплять скриншоты, чтобы было немного понятно, что где и как.
Тут будут показаны программы pgAdmin и sublime-merge
У нас есть функция и таблица в БД:
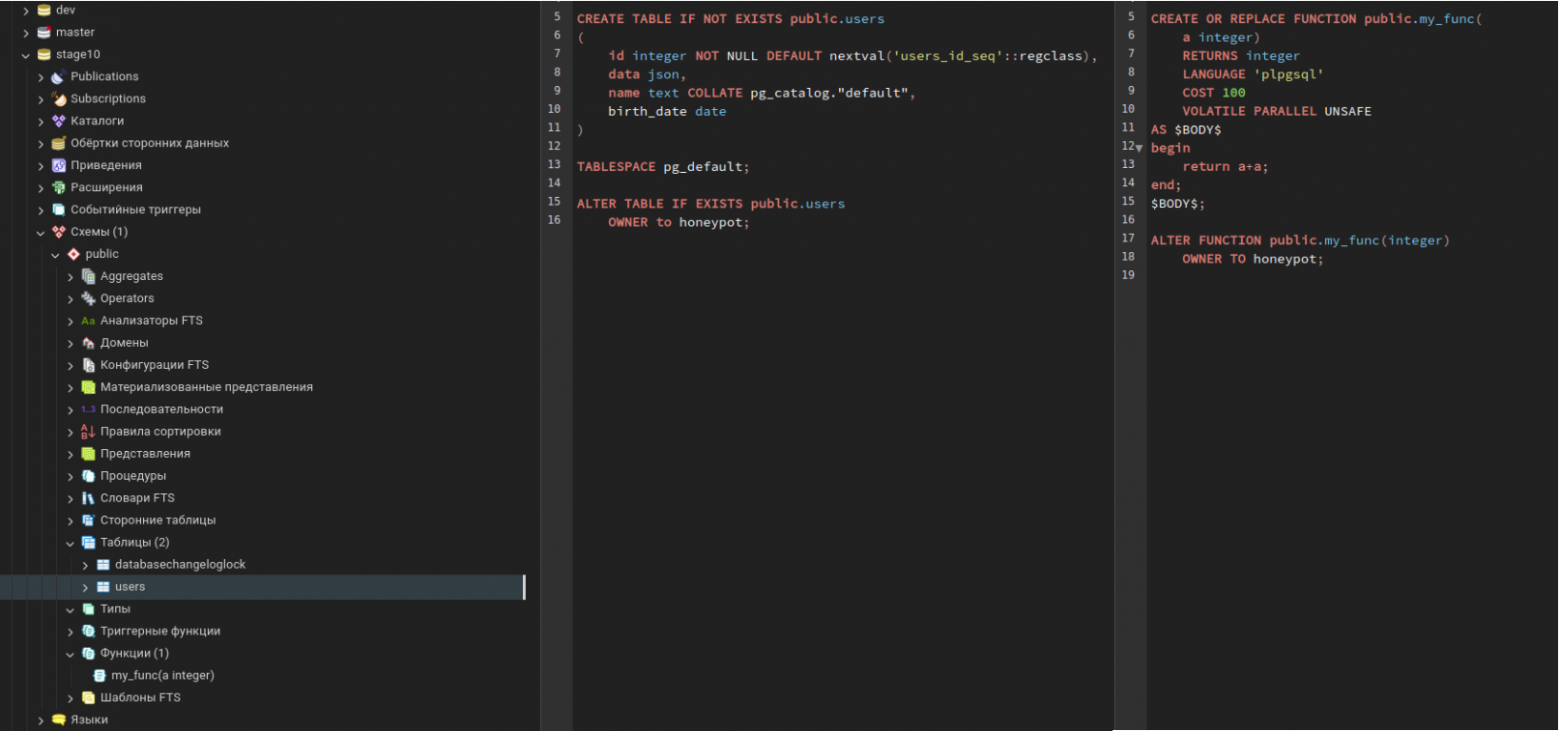
Нам ставят вот такую задачу:
Создать новую таблицу
user_cardsДобавить в
usersновое полеcount_cardsСоздать новую функцию
get_user_count_cards($user_id), которая будет выводить количество карт у пользователяВ существующей функции
my_funcпеределать ответ сa+aнаa*a
Создать новую таблицу user_cards:
Ну тут всё просто:
create table user_cards(
id serial not null primary key,
user_id int not null, -- тут бы стоило добавить FK, но я уже прикрепляю старые скрины и не хочу там ничего править :)
card_number text,
other_data jsonb
);Добавить в users новое поле count_cards:
Думаю, тут даже запрос писать не надо, всё понятно (да можно хоть ручками в pgAdmin-е создать колонку)
Создать новую функцию get_user_count_cards($user_id), которая будет выводить количество карт у пользователя:
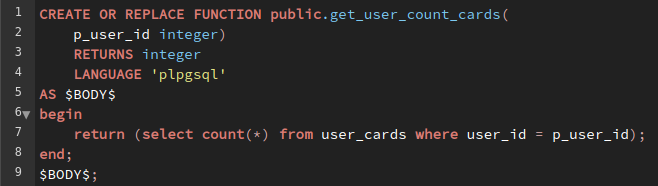
В существующей функции my_func переделать ответ с a+a на a*a:

И так, задача сделана, теперь мы хотим слить схему БД в виде файлов-миграций для каждого объекта. Запустим pg_dump + скрипт для парсинга sql-код по файлам.
Ну что, проверим, что изменилось в репозитории?

Изменения в файле public/function/my_func.sql

Изменения в файле с таблицей users

Новый файл с функцией get_user_count_cards

Созданы миграции для таблицы user_cards:
Поскольку там serial — необходимо создать sequence, потом подключить её, поэтому всё в несколько файлов.
Ревьюер нас проверяет, задача сделана, создадим «добивочную» миграцию, поскольку в таблице users добавлялось поле count_cards .
Запустим скрипты, которые выполнят работу по созданию такой миграции (описано было выше). Но выходе получаем файл:

«Добивочная» миграция
Если после этого к нам «резко» прилетело исправление ТЗ (ну бывает же), то всё что нам надо сделать — удалить из ветки «добивочную» миграцию, разработать, и опять отдать на ревью с последующим созданием «добивочной» миграции.
В случае, если «добивочная» миграция не нужна — её можно и не создавать.
«Добивочные» миграции, которые залиты в на все существующие БД (я имею в виду ревью-БД и прод-БД) можно удалять, они нам уже не понадобятся (грязь надо чистить).
Вывод, примечания и прочее:
Такой подход позволяет хранить sql-код объектов БД в различных файлах и не допускать повтора скриптов.
Всё это достигается тем, что инструмент для заливки миграций будет перезаливать миграции, которые были модифицированны.
Так-же создаются » добивочные» миграции специально для тех миграций, которые не могут довести структуру БД до нужной версии (пример с добавлением колонки был выше).
Всё это позволяет поддерживать конкурентную разработку одних и тех-же объектов, не дублировать код, удобное ревью и удобный workflow у разработчика и ревьюера.
Правда, за это придётся заплатить нервами на настройку, а так-же отказаться от откатов миграций (в стандартном подходе создаётся как миграция на новую версию БД, так и миграция на откат версии, а такие откаты в данный архитектуре не поддерживаются).
Я хочу ещё раз подчеркнуть, что такая система хорошо подходит именно для проектов, где БД является бэкендом по большей части, и где в основном разработка бекенда — это модификация функций.
Есть закономерный вопрос: Почему бы не использовать pg-codekeeper, ведь он уже умеет хранить структурно файлы с объектами, а так-же создавать миграции ?
Тут ответов несколько:
Во-первых, если генерировать одну большую миграцию на выходе, сохранять её в файлах миграций или заливать на прод — появляются проблемы с конкурентной разработкой (то что в начале пример был).
Если хранить в репозитории код объектов, а миграцию генерировать именно в момент заливки — придётся много ревьюить, что будет достаточно неудобно.
Во-вторых, его функционал немного скромный, в нём можно управлять разве-что параметрами include/exclude .
Подход, описанный тут, позволяет сверху сделать достаточное количество доработок. Например: разделение кода по частям (модули), подмену некоторых параметров (например переопределение дефолтного владельца), сохранение и перенос данных таблиц, управление через контексты (на примере liquibase) и т.д. Пока-что прям все плюшки сказать не могу, поскольку мы далеко не всё смогли из неё выжать. Но, то что сейчас поддерживается — меня уже начинает радовать.
Повторюсь ещё раз. Я просто хотел описать подход к хранению миграций, который будет удобен разработчикам и ревьюерам.
И ещё раз повторюсь, что всё находится на этапе тестирования, допиливания фичей и устранения подводных камней.
Зачем я написал эту статью?
Для того, чтобы показать, как можно реализовать разработку.
Возможно, в комментариях кто-нибудь задаст пару вопросов, которые дадут пищу для размышлений и мы сможем на нынешнем этапе это устранить. А может кто-то захочет подобное внедрить к себе, и, прочитав эту статью с комментариями, будет знать, заработает это или нет.
Спасибо за внимание, всем добра !
