Что такое MLOps и как мы внедряли каскады моделей
Привет, меня зовут Александр Егоров, я MLOps инженер. В статье расскажу о том, как мы в банке выкатываем огромное количество моделей. Разберем не только пайплайн по выкладке отдельных моделей, но и целые каскады.

Как появляется потребность в MLOps
Постепенно, с ростом темы искусственного интеллекта, все начали поспешно разрабатывать свои модели. Однако, как и с разработкой, например, тех же веб-сайтов, дата саентисты, ML-инженеры, и другие специалисты столкнулись с проблемой скорости воспроизведения всего процесса заново. Более того, процесс не всегда может быть успешен. По статистике, только около 25% моделей действительно доходят до продакшена. Поэтому, скорее всего, придется повторять весь цикл для модели несколько раз, чтобы она действительно начала приносить пользу бизнесу. Но все системы обладают энтропией, и через какое-то время даже ранее полностью рабочую модель нужно переобучать, так как она может потерять свою точность.
Из этого следует простой вывод: как и разработка сайтов, так и разработка моделей машинного обучения должна иметь свои CI/CD процессы. В этом нам может помочь MLOps. MLOps подход подразумевает внедрение принципов DevOps в сферу машинного обучения.
Однако, так или иначе, сфера машинного обучения имеет свои аспекты. В данной ситуации у нас появляется работа с большими данными. Зачастую, сырые данные не готовы, чтобы на них обучали модели и для этого разработчики создали ETL-процессы, которые позволяют получить данные, обработать их и отправить результаты далее, чтобы на них обучать модели. Однако ETL-процесс не подразумевает уже сам training модели и тем более её выкат на стенд.
Подход MLOps же предполагает создание пайплайна, который позволит обучить модель до нужной точности на готовых данных, а также выкатить её в тестовую или продуктовую среду.
Инструментарий MLOps
При переходе от обычного DevOps в MLOps у нас появляются новые инструменты, которые закрывают различные новые проблемы. И поэтому сейчас я кратко представлю инструментарий, который уже используется в нашем пайплайне в Альфа-Банке.

Все эти инструменты, я постарался расположить в порядке их использования по ходу разработки моделей: подготовка данных, обучение моделей и их выкладка.
И первый инструмент из списка это Airflow — средство для разработки, планирования и мониторинга сложных процессов. Для общего понимания: представляет из себя CronTab на стероидах, способный выполнять целые пайплайны, написанные на Python по определённому времени. В большинстве своём, написание ETL-процессов включает в себя использование данной тулзы.
Hadoop — уже достаточно давняя экосистема для хранения больших данных и их обработки. Она включает много разных компонентов, однако, один из самых молодых — это фреймворк Spark, который позволяет реализовывать распределенные вычисления над некоторыми наборами данных.
В рамках кластера Kubernetes на котором стоят все наши инструменты, данное средство разворачивается через SparkOperator. Использование данного фреймворка с AirFlow, а также с сохранением данных в Hadoop кластере даёт большой прирост в скорости их обработки и эффективности хранения.
Далее, после обработки данных, идёт разработка моделей, и в этом может помочь инструмент MLFlow, который позволяет сохранять и воспроизводить модели машинного обучения. Вы создаете MLFlow эксперимент, в рамках него обучаете модель, а все результаты записываются автоматически в MLFlow вместе со всеми нужными метриками, графиками и диаграммами. Проект MLFlow постоянно развивается и имеет огромное комьюнити, что, безусловно, даёт преимущества в части использования его в различных средах и, как раз-таки, в пайплайнах.
Когда у нас есть готовая обученная модель, мы можем перейти к шагу по её выводу. В чем может помочь Seldon Core, представляющий из себя целую платформу для развёртки ML-моделей. Сейчас это одно из самых популярных решений на рынке, которое обернет вашу обученную модель из MLFlow в online-вариант, предоставив API для общения с ней, а также запустит её как сервис. Для ручного тестирования вы получите Swagger UI.
На нашей платформе Seldon Core также как и Spark запущен в виде Kubernetes Operator.
Дополнительный модуль
Обычно все DevOps пайплайны строятся на основе какого-то CI/CD инструмента. Происходит сборка образа и его деплой, например, на кластер Kubernetes. Однако, в контексте ML требуется использование более специфичных инструментов, таких как AirFlow, Spark и Seldon Core.
Для интеграции Spark и Seldon с Kubernetes, мы используем специальные операторы, которые управляют запуском SparkApplication и SeldonDeployment в рамках Pod. В свою очередь AirFlow работает с DAG — ацикличными графами, которые описываются на Python. У каждой из этих технологий есть свои собственные способы запуска: либо отдельные манифесты Kubernetes, либо скрипты на Python.
Так, для обучения и запуска разнообразных моделей с различными параметрами в рамках всех этих инструментов мы разработали специальный модуль на Python, который на основе входной конфигурации от разработчика позволяет ему обучать и выкладывать модели не имея глубоких познаний в инфраструктуре. Этот модуль выполняет роль связующего звена, которое объединяет знания DS о модели с инфраструктурой.
Для начала DS создаёт простой конфигурационный файл в своём репозитории для работы с нашим модулем. В этом файле указывается всевозможная информация для обучения, либо выкладки модели: тип (batch или online), время и интервал запуска DAGов, параметры для Spark сессии, версию Python, на котором модель должна запускаться, её название и всю другую информацию, которую может указать DS о своей модели.
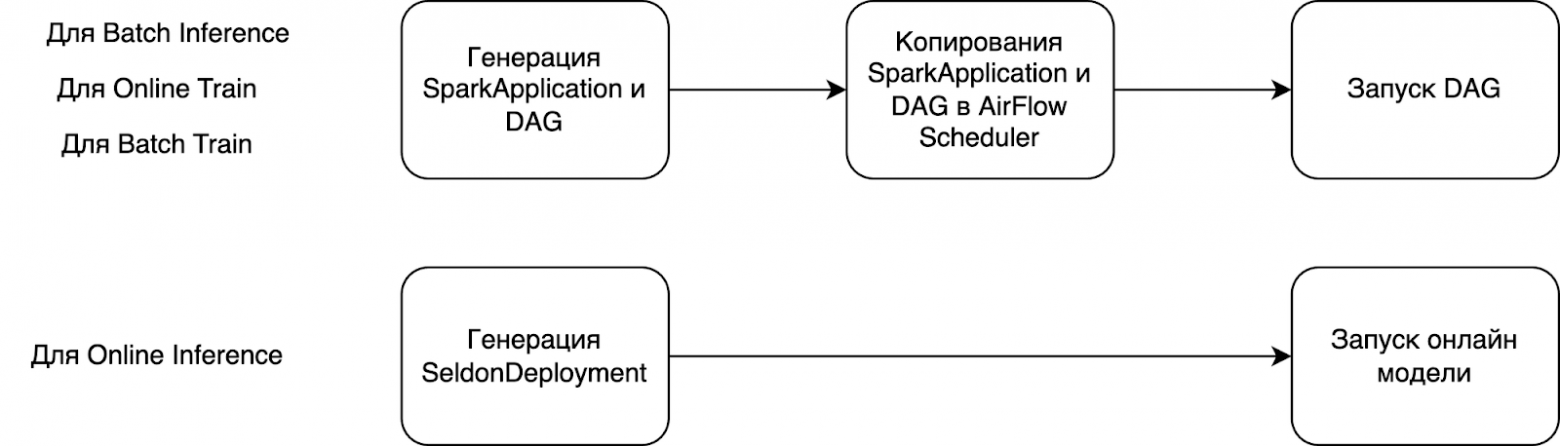
Таким образом, основная задача модуля заключается в том, чтобы взять пользовательскую конфигурацию, на основе неё создать Spark Application, DAG и разместить всё это в AirFlow Scheduler, в том случае, если мы говорим про Batch модели. Если мы говорим про выкладку онлайн-моделей, то модуль создаст SeldonDeployment манифест.
Рассмотрим шаги пайплайна подробнее
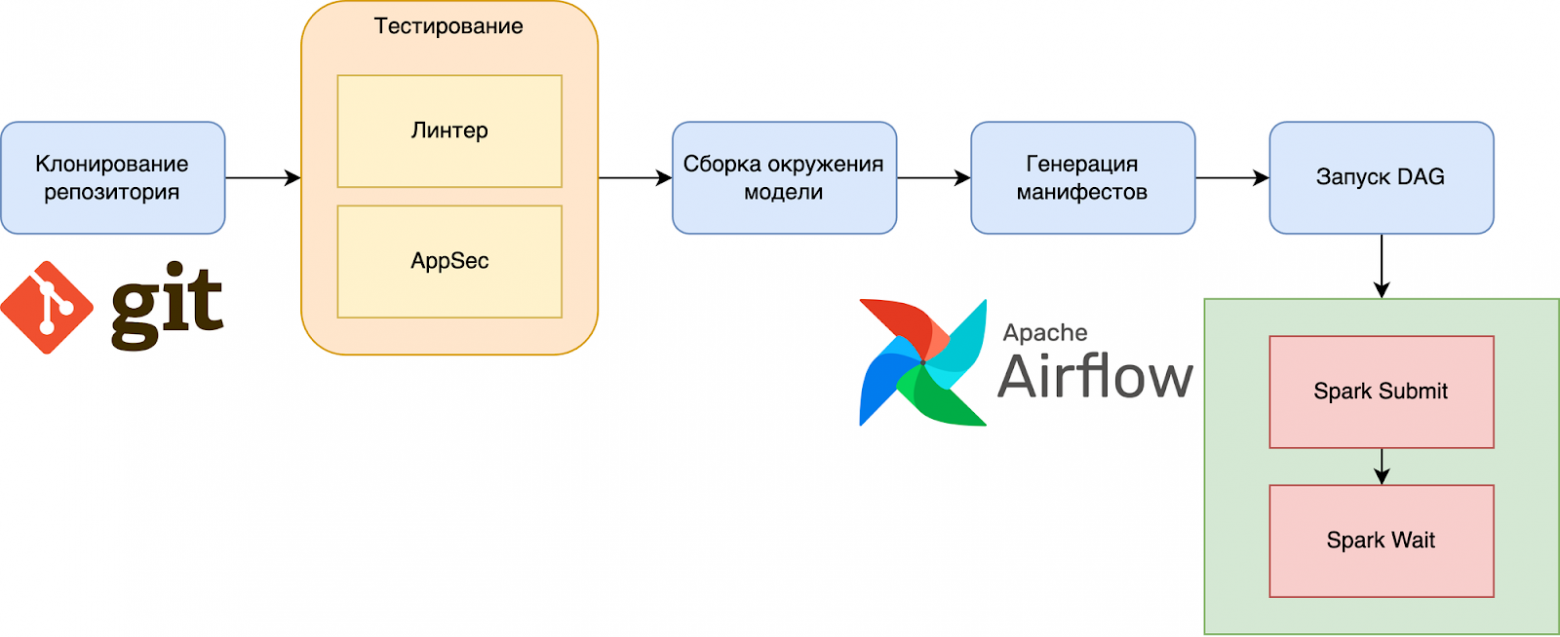
В начале посмотрим пайплайн по обучению.
Процесс начинается со стандартной загрузки кода и его тестирования. После различных проверок кода происходит сборка окружения модели (т.е. установка всех библиотек), и сохранение архива с ним в S3 хранилище. Далее модуль создаёт необходимые манифесты на основе конфигурации и передаёт их в AirFlow Scheduler.
Теперь, когда у нас есть готовое окружение для работы модели, есть DAG для AirFlow и манифест для запуска SparkApplication в кластере, мы можем запустить обучение.
Поскольку все наши модели работают со Spark, в рамках DAG выполняются два основных действия: Spark Submit и Spark Wait.
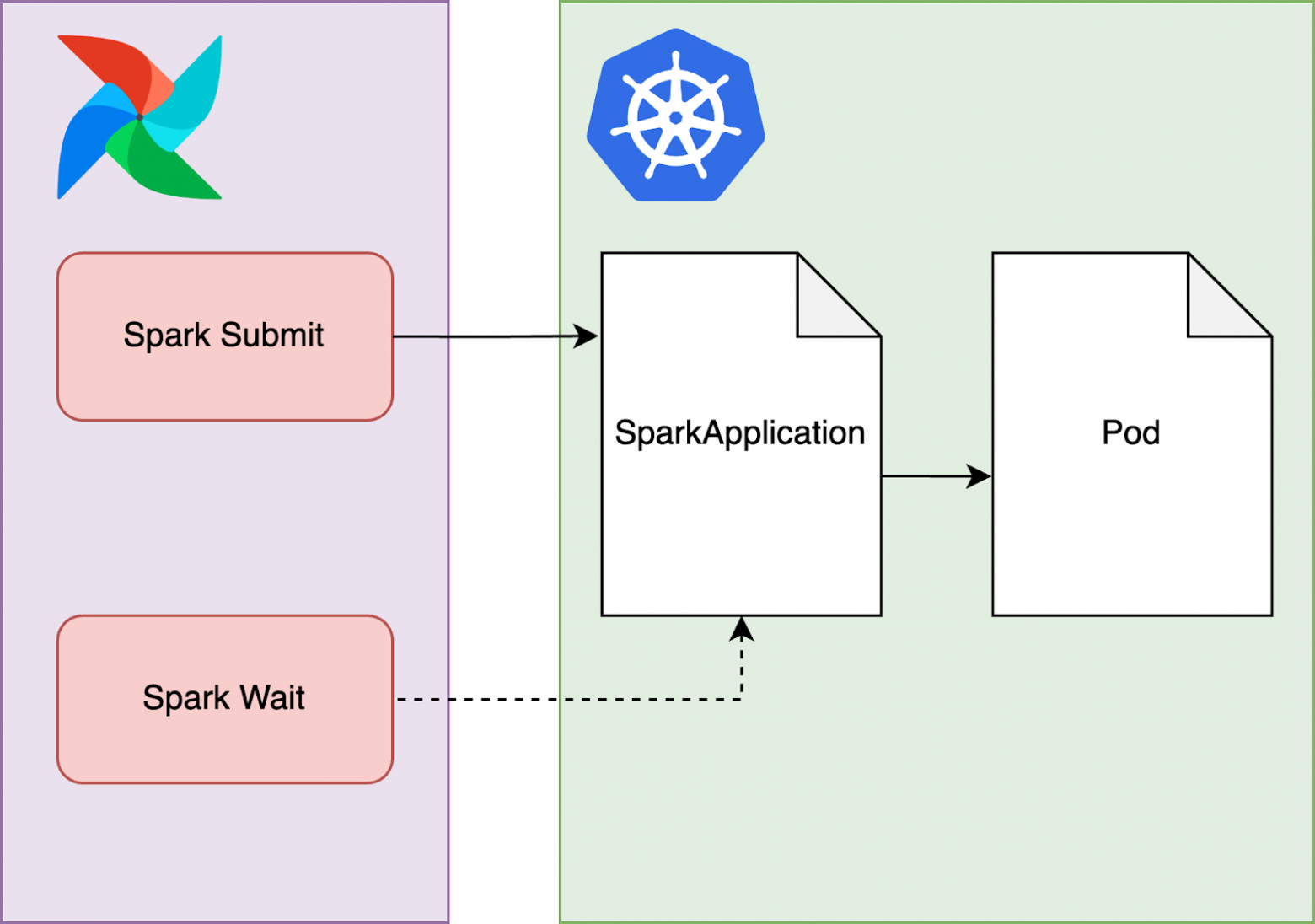
Первая таска запускает сессию Spark: на стороне Kubernetes создаётся сущность под названием Spark Application, манифест для которого уже был передан в Scheduler на предыдущем этапе. Далее этот Spark Application создает Pod, в котором как раз и начинается обучение модели.
Вторая таска Spark Wait просто отслеживает состояние Spark Application после его создания.
Как только обучение завершено, Pod Spark Application завершает свою работу. DAG в Airflow отмечается как успешно выполненный, завершая таким образом весь пайплайн в Jenkins.
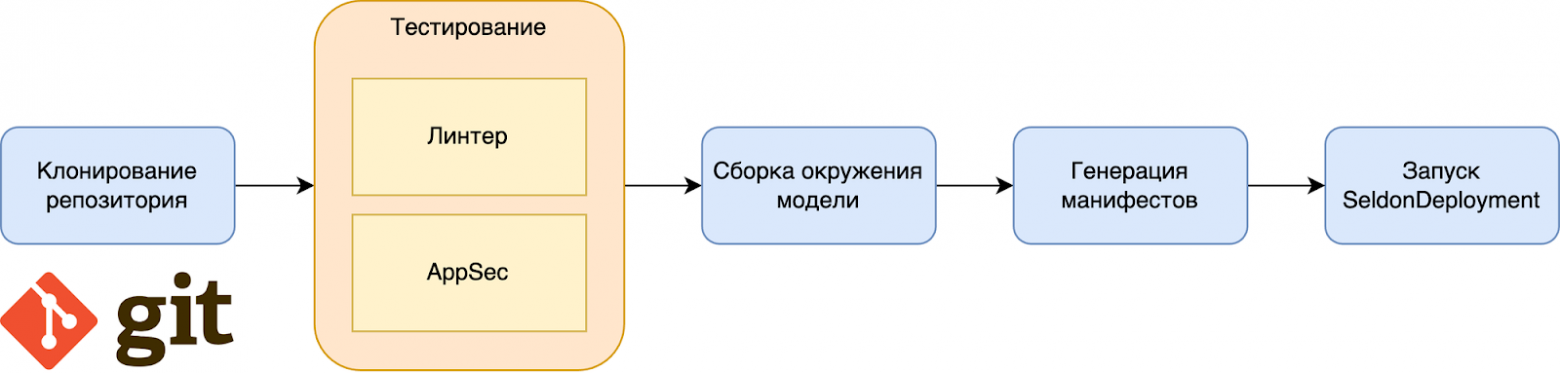
Для инференса батч модели пайплайн имеет аналогичную структуру, но вместо обучения в Spark сессии происходит скачивание готовой модели с MLFlow и её развертка, если это batch модель.
Если модель у нас online, то в модуле вместо DAG и Spark Application, создаётся манифест SeldonDeployment.
Теперь, когда у нас появился полноценный пайплайн для обучения и последующей выкладки, существенно сократилось и время вывода моделей в прод.
Ранее цикл по запуску модели мог производиться и целыми месяцами, что являлось очень затяжным процессом. Теперь же, для аналогичной модели, процесс обучения и последующая выкладка на продакшн с проведением всевозможных тестов занимает около пары дней.
Максимальное время по регламенту не может превышать 5 дней для Batch моделей и 10 дней для Online. Само же время работы inference пайплайна в среде разработки может колебаться от 7 минут до 25. Всё это сильно завязано на типе моделей.
Если в её окружении используются достаточно легкие библиотеки по типу SkLearn, то это нижний порог в 5 минут.
Если модель использует GPU, строится на основе TensorFlow, то это верхний предел, так как только само окружение может достигать порядка 15 Гб.
Каскады: зачем нужны и как работают
Итак, скорость работы увеличилась, следовательно увеличилось и количество созданных моделей. И с этим пришла новая проблема, а именно — как их всех запустить.
Первый кейс, который у нас случился, это появилось порядка 100 моделей. И их нужно было все запустить. Однако, имея текущую реализацию пайплайна на тот момент, этот процесс занял бы огромное количество времени. Нам пришлось бы банально вызывать пайплайн с нужными моделями 100 раз.
В другом кейсе у нас появилась модель, которая использует данные из ответов нескольких других. По сути, нам нужно было развернуть в начале несколько одних моделей и потом сделать запуск другой, таким образом создав ансамбль.
Исходя из этих кейсов, необходимо было придумать некоторый механизм, который должен был помочь нам решить такие кейсы. Так мы пришли к идее создания каскадов моделей.
Каскад моделей означает запуск нескольких обученных Batch моделей в рамках одного DAGа.
Его настройка также выполняется в конфиг-файле дата-сайентистом с помощью некоторых блоков. Каждый блок содержит в себе параллельно запускаемые модели, в то время как сами блоки выполняются последовательно.
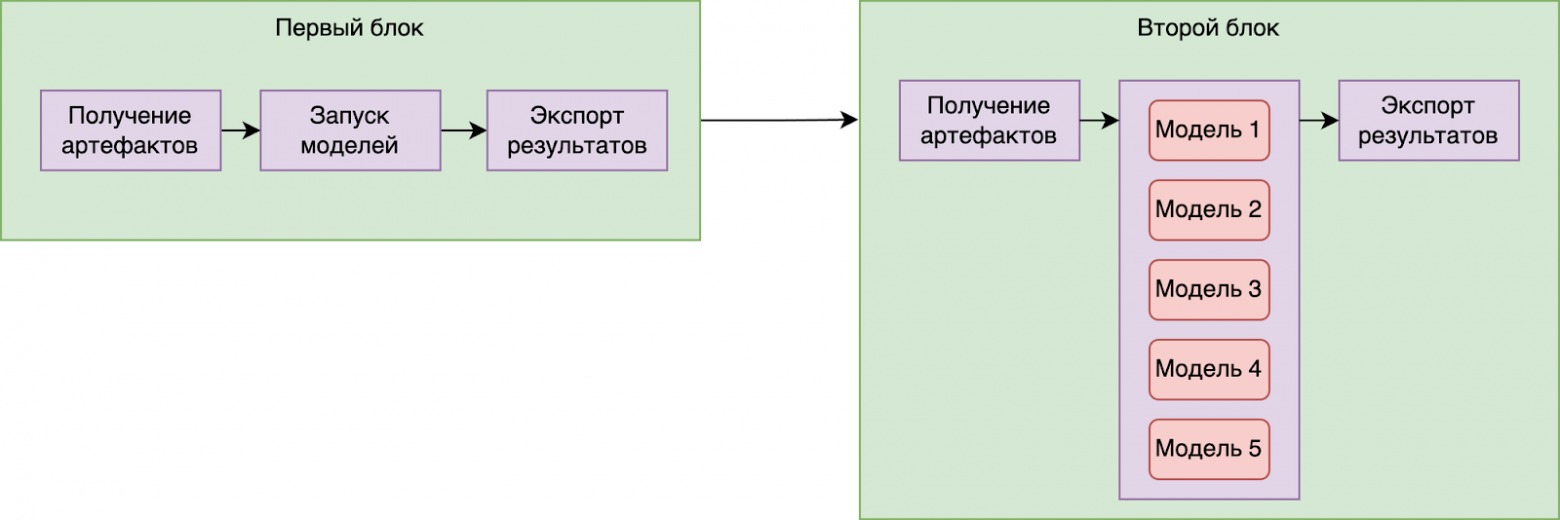
Теперь разберём более подробно что вообще происходит внутри них.
Каждый блок выполняется в три этапа.
В начале идёт скачивание артефактов для всех моделей. Это датасеты, которые далее будут им скармливаться.
После завершения этого шага производится непосредственно запуск всех моделей, которые были указаны в блоке. Они запускаются, принимают данные из прошлого шага и выдают свой ответ.
Далее заключительный шаг — это экспорт предсказаний в Hadoop-кластер.
После прохождения всех шагов блок помечается завершенным, и аналогичный процесс производится с остальными блоками.
Однако, укажу интересную особенность.
Основная цель пайплайна и модуля в целом — создать DAG. А уже либо сам AirFlow, либо пользователь пользователь будут заниматься его запуском. То есть DAG либо выполняется по расписанию, либо тригерится DS в дальнейшем.
И на этом этапе пользователь может также указать каким моделям или целым блокам нужно отработать, а каким нет. Это производится через параметризированный запуск DAG«а.
Сам механизм пропуска тех или иных моделей выполняется за счет технических тасок. Дело в том, что загрузка артефактов, поднятие модели и выгрузка результатов представляют из себя не просто отдельные таски, а группы тасок. Каждая из них содержит 3 технических задания. С двумя последними вы уже знакомы — это Spark Submit и Spark Wait, которые соответственно запускают Spark сессию и ожидают её завершения.
Здесь же уже перед ними стоит ещё одна таска под названием Select, которая и отвечает за логику сравнения входных параметров DAGа c его исходным представлением в конфиг-файле от DS, на основе которого создавался DAG.
Если какая-то модель или какой-то целый блок отсутствуют в параметрах, то соответственно запуска сессии не происходит. Это сокращает время прогона во время тестов, экономит ресурсы кластера и, в целом, делает процесс работы с каскадами более гибким.
Итоги
Итак, теперь использование каскадов позволило нам запускать множество моделей как параллельно, так и последовательно. Во время запусков DAG«а мы можем выбирать, что нам нужно выполнять, а что нет. Это сильно упрощает тестирование отдельных моделей после из выкладки.
И, обобщая, сами каскады моделей освобождают пользователей от рутинных запусков множества пайплайнов, давая им новую возможность выстраивать целые ансамбли из моделей, описывая их в очень простой форме в конфиге в своем репозитории.
