Когда метрик и логов недостаточно: как мы реализовали концепцию observability
В 2021 году в Ак Барс Банке мы перешли от концепции мониторинга к observability. Observability помогает нам определить внутреннее состояние системы по ее внешним проявлениям, а в случае инцидента дает быстрые ответы на вопросы: что случилось, кто виноват и как чинить.
Меня зовут Тимур Исхаков, в ИТ с 2009 года: прошел путь от инженера до технического менеджера. В Ак Барс Банке занимался внедрением концепции observability, о которой и расскажу в статье: как искали и выбирали решения, как пытались внедрить observability сами, как находили «нюансы» в коммерческих предложениях, как считали цены решений в премиальных автомобилях и чем все это закончилось.
Дисклеймер. Статья подготовлена на основе доклада с DevOps Conf, где я выступал вместе c Денисом Безкоровайным @bezkod, директором Proto Group. Денис с 2015-го года в мониторинге производительности, участвовал в реализации проекта (о котором пойдет речь) со стороны интегратора-партнера. Выступает как соавтор статьи. Если хотите посмотреть оригинал нашего выступления — вот ссылка на видео.
Сервисы, ответственные и проблемы
Ак Барс Банк — крупный региональный банк в Татарстане. У нас 72 различные бизнес-системы, причем как коробочных (от вендоров), так и с нуля написанных (собственной разработки). На 72 системы у нас 147 ответственных, которые их поддерживают. Когда происходит какой-то инцидент в том или ином бизнес-сценарии, каждая команда вынуждена искать виновного в проблеме. Обычно здесь начинаются чудеса на виражах.
Мы идем к одной команде и уточняем, не случилось ли чего, потому что их система задействована в нашем бизнес-процессе.
— Нет, у нас все хорошо, никаких проблем, последний релиз был 2 недели назад, конфигурацию никто не менял, можем показать Health check«и, у нас все 200-е, никаких алертов.
Мы идем к следующей команде:
— Нет, у нас все хорошо, никаких проблем, последний релиз был 2 недели назад, конфигурацию никто не менял…
Потом к следующей:
— Нет, у нас все хорошо, никаких проблем, последний релиз был 2 недели назад…
Обходим всех, у всех все идеально. Здесь волшебным образом наш бизнес-процесс восстанавливается, хотя никто ничего не трогал, и везде же все идеально. Но никому от этого легче не становилось:
ведь клиент так или иначе страдал;
мы тратили много времени на поиск причины, а на разбор инцидента порой уходило больше часа;
но причины так и не находили;
над этими бизнес-процессами есть другие бизнес-процессы, и глубина вхождения поиска возрастала в разы.
Как следствие, возникали некоторые сложности.
Онбординг. Когда приходят новые ребята, мы занимались тем, что:
объясняли всю эту сложную конструкцию выше о том, как искать причины инцидентов;
знакомили с ответственными (по департаментам/отделам);
твердили, что если ответственные скажут «Нет, проблема не у нас», это не значит «Нет» — надо копать глубже.
Актуальная архитектура. У нас достаточно сложная архитектура, ее нужно поддерживать: тот сервис, что мы задокументировали вчера, уже сегодня будет не актуален. Соответственно, мы вынуждены заниматься актуализацией и тратить на это время, не говоря о том, что с микросервисной архитектурой этим надо заниматься еще чаще.
Микросервисы. Команды активно переходили на микросервисы, их становилось больше, и мы понимали, что проблемы будут только усугубляться.
Стоимость простоя. Банк тоже не стоит на месте, он активно развивается, клиентская база растет, повышается транзакционная активность и растет сумма среднего чека. Стоимость простоев, соответственно, тоже увеличивается, с точки зрения финансовых и имиджевых потерь банка.
Нам это все надоело, мы решили что-то менять и заняться мониторингом бизнес-процессов, но не просто мониторингом, а проактивным. И вот здесь возникает термин «observability».
Что такое observability и чем отличается от мониторинга?
Observability — это то, что способно в случае инцидента дать быстрые ответы на вопросы «Что случилось?», «Кто виноват?» и «Как чинить?».
Какие возможности для этого должна реализовывать observability-система?
Сбор данных. Основные 3 столпа observability — это метрики, трэйсы и логи. При этом observability-система должна обеспечивать сбор и анализ данных, которые находятся за пределами логов, трэйсов и метрик:
событий;
изменений (выкатка, деплой, запуск подов);
метрик, трейсов, логов;
данных пользовательского опыта — каждая транзакция, в конечном счете, начинается на клиенте (мобильное устройство, веб-браузер).
Все это нужно агрегировать и анализировать.
Корреляция и связь всех типов данных. Конечно же, современная система должна выдавать возможность корреляции и связывать все эти события и типы данных в одном контексте. Когда все данные в контексте, мы можем быстро перейти от метрик к трэйсам, от трэйсов к логам, и дальше, и понять, в какой инфраструктуре, в каком контуре эта система работала, когда случился инцидент.
Автодискавери. Если у вас запустилась новая нода в K8S, вы об этом точно узнаете. Но если у вас появился какой-то новый эндпойнт у разработчика, а он его еще не описал, скорее всего, вы про него можете и не узнать. Тем более, на него не будет построено каких-то алертов выявления аномалий в метриках этого эндпойнта.
Соответственно, автодискавери это не только обнаружение компонентов, но и того, что находится внутри приложения.
Автоинструментация — автоматический сбор трэйсов и метрик из приложения. Конечно, разработчики могут все это дело писать, но это время и человеческий фактор — можно просто забыть и вы останетесь со слепым пятном в мониторинге.
Определение взаимосвязей между сущностями. Каждый трэйс находится в контексте, он связан с приложением, с инфраструктурой. Главная задача — выявить проблему, понять корневую причину и выявить root cause. Желательно это делать автоматически, чтобы один раз мы внесли в базу знаний наши экспертные знания, и дальше они бы работали на всю масштабируемую инфраструктуру, на весь объем новых данных и новых приложений.
Теперь, отвечая на вопрос в начале главы, уточню, что корневое отличие observability от мониторинга — в активности.
Мониторинг — реактивный: мы строим дашборды и обкладываемся алертами, чтобы найти ответ на вопрос «Что случилось?»
Observability — проактивный: отвечает на вопрос «Почему случилось?», «Где случилось?», «Как чинить?» и «Где корневая причина?», потому что у нас может быть 100 алертов на одну проблему.
В мониторинге у нас есть человек, который следит за всем, а в observability к нему в помощь добавляются алгоритмы, которые анализируют весь массив информации трэйсов, логов, и помогают человеку понимать, что произошло.
Это именно то, что нам было нужно. Тем более, что мы уже использовали различные средства мониторинга вроде Zabbix, SCOM и Grafana, и кажется, что внедрить observability будет проще.
Можно ли внедрить observability самим?
Первым делом, мы встали перед выбором — делать что-то самим или купить готовое решение? Чтобы выбрать правильный вариант решили сравнить.
Если мы делаем решение сами, то у нас:
Минимальная зависимость от какого-то вендора.
В долгосрочной перспективе экономия денег, потому что система будет масштабироваться, а мы используем микросервисы: много сервисов — много лицензий.
Но есть и свои минусы, конечно.
Скорее всего, мы будем делать систему достаточно долго — у нас нет подходящей экспертизы в разработке подобных систем, придется всему учиться.
Этот класс решений достаточно сложный, поэтому есть риски вообще не сделать такой проект.
С другой стороны, если мы возьмем какую-то готовую коробку, то внедрим ее достаточно быстро, и нам в этом поможет сам вендор/интегратор. Но будет ли он помогать, когда стороннее решение мы будем масштабировать? Не обернется ли это затратами, когда на любую доработку мы получим ответ «Подождите полгода, у нас пока другие клиенты»?
Одну из таблеток точно надо выбрать.

Сначала решили пойти по пути собственной разработки. Прикинули, какие этапы нас ждут.
Первый — обоснование бюджета на разработку. Сюда же входит построение календарно-ресурсного плана.
Второй — поиск и наем соответствующих людей, экспертиза которых будет особенная, потому что мы занимаемся продуктовой разработкой. Здесь же нужно будет искать инженеров с определенным техническим опытом.
Третий — разработка и развитие этой системы.
Сколько это будет стоить? Опять же, прикинули на пальцах.
Над подобной системой у нас будут работать примерно 6 инженеров.
Функционал, который нам нужен, мы будем делать около 12 месяцев, опять же, примерно. Как нас не уверяли наши же инженеры, что за полгода все закончится, по собственному опыту мы все знаем, что надо умножать на 2.
Цена разработки вышла в 1,5 премиальных автомобиля в ценах начала 2022. Если тоже захотите поиграться — оставлю ссылку на калькулятор, который обычно используют наши продакты при построении финансово-экономической модели.

Показав эти расчеты менеджменту, мы услышали:
— У нас бизнес-задачи стоят, а вы тут со своими игрушками. Вот вам деньги, идите ищите что-то готовое.
На этом путь собственной разработки завершился и начался квест из выбора готовых решений.
Магический квадрат и четыре решения на выбор
В качестве источника информации мы взяли магический квадрат Гартнера по APM решениям, для определения лидеров отрасли.
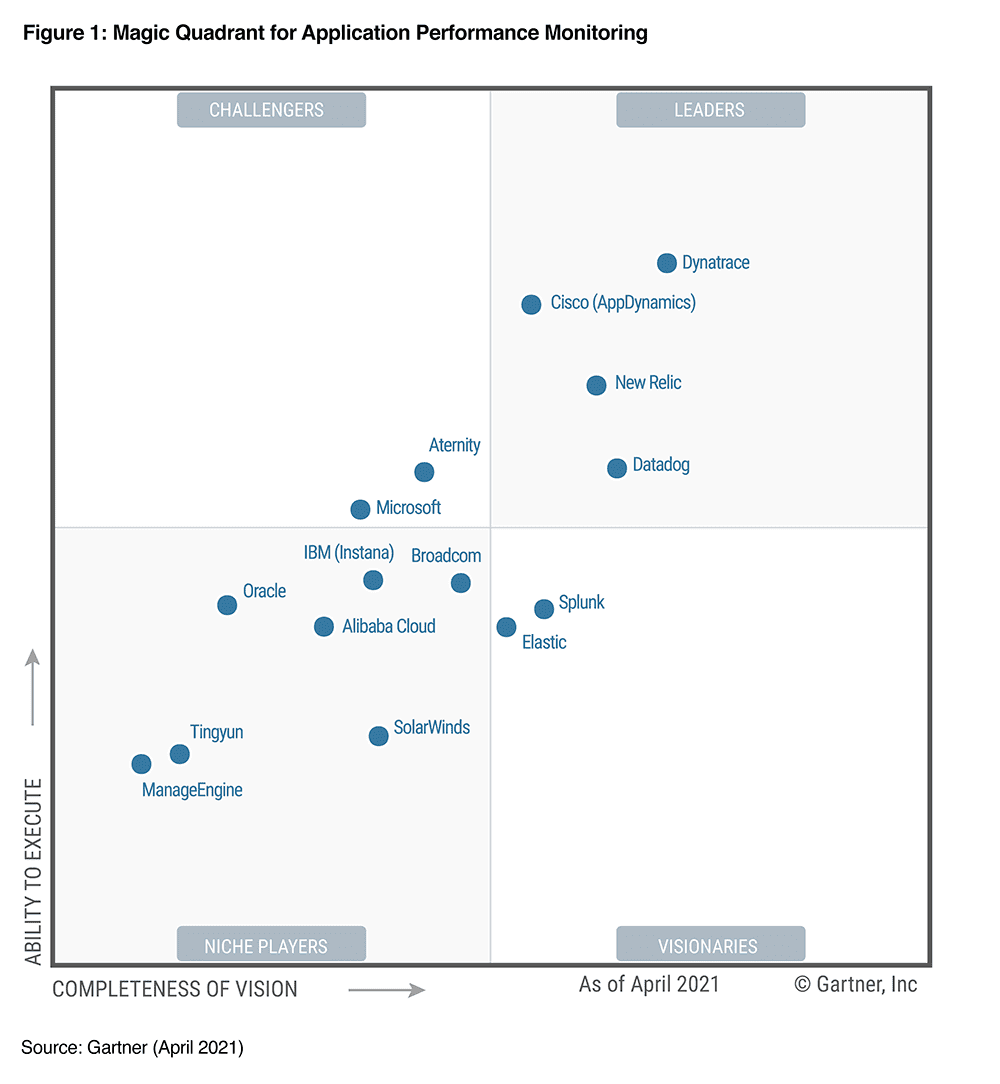
Примечание. На момент написания статьи вышла свежая аналитика за 2022 год, доступна по ссылке.
Требования к готовым решениям всё те же, что описаны чуть выше.
Автоматический поиск наших сервисов, как тех, что существуют, так и тех, что будут выкатываться.
Возможность построения связей между ними, желательно в автоматическом режиме.
Немного искусственного интеллекта, чтобы система могла подсказать где непосредственно возникает тот или иной инцидент.
Есть еще пара требований, специфичных для банков.
Все должно быть в контуре банка, никаких внешних зависимостей. Это настоятельное требование Департамента информационной безопасности.
Поддержка .NET без бубнов, потому что 90% кодовой базы у нас на .NET.
«Приложив» эти требования на решения которые мы нашли, определили четырех финалистов.
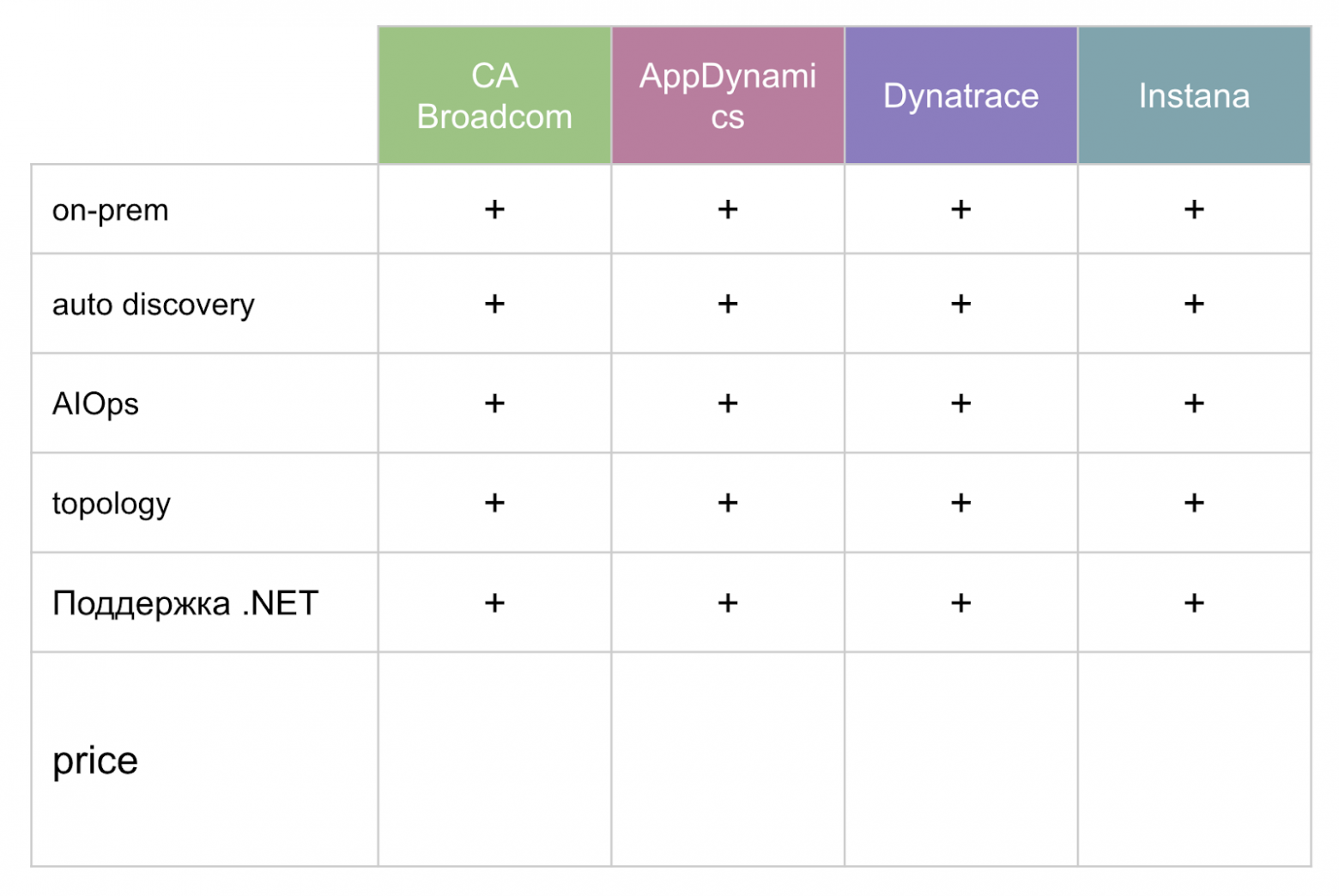
Все решения примерно одинаковы. Но после того, как получили их коммерческие предложения, заметили, что появилась существенная разница.

У департамента закупок есть важное требование — в финальном конкурсе должны участвовать три решения, как минимум. Что ж, три так три.
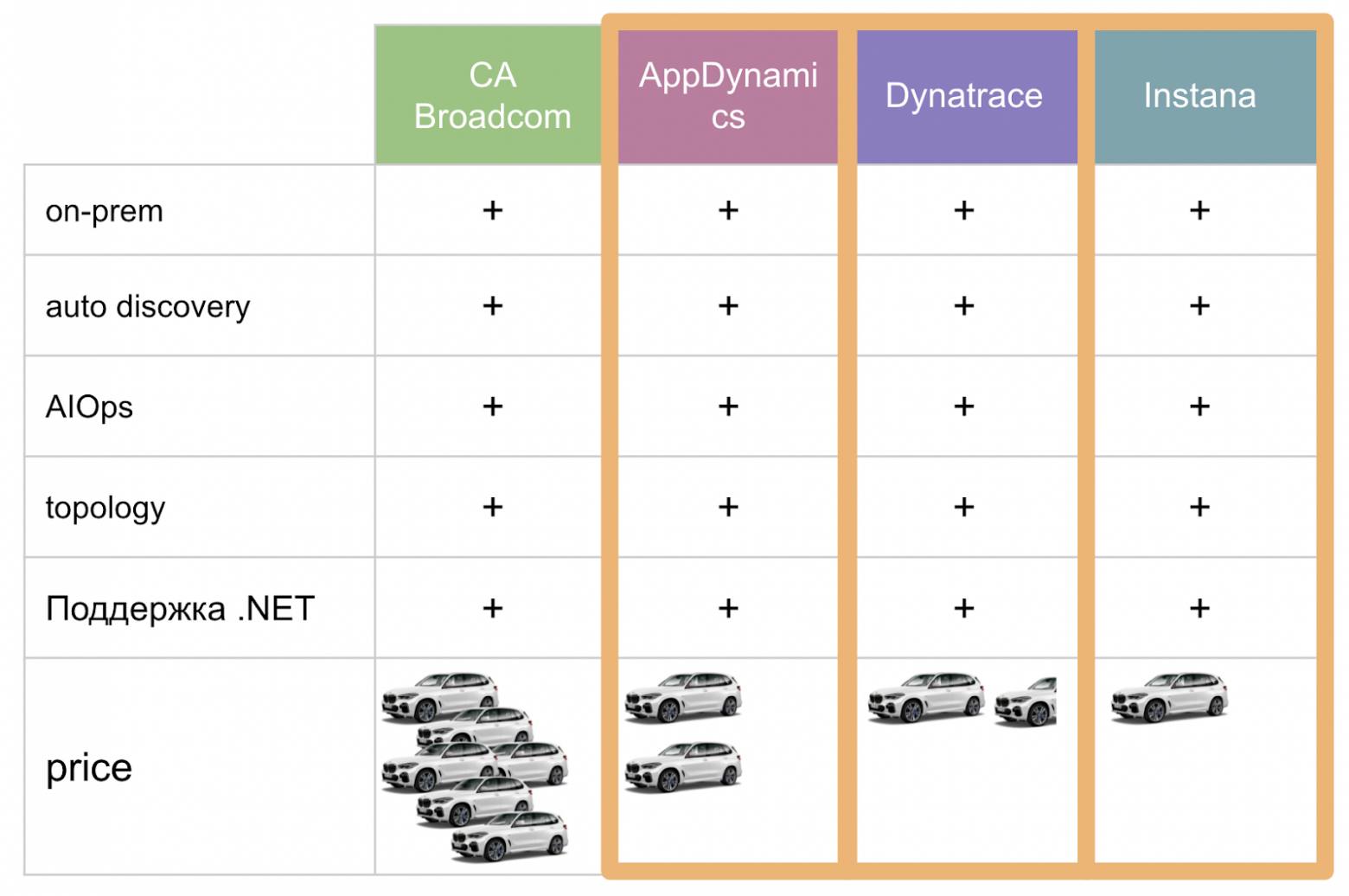
На этих трех решениях мы и запустили пилот.
Пилотирование: ожидание и реальность
Да, от пилотов у нас были некоторые определенные ожидания:
быстро все это прототипируем;
параллельно развернем все три решения;
возьмём в качестве контура наши тестовые Dev-контуры;
выявим в рамках пилотирования понятные кейсы для апробации;
и все это без танцев с бубном — как это любят говорить продавцы: «Ставите «one agent» и все сразу инструментируется».
Но реальность, ожидаемо, была не такой. Оказалось, что…
Внедрять 3 решения надо последовательно, с полной выпилкой предыдущего. Инструментируя каждое решение параллельно, мы столкнулись с проблемой, что они используют одни и те же механизмы. Между собой решения начали конфликтовать, и достаточно серьезно уходить в конфигурацию тех хостов, где устанавливались агенты, а мы жутко мучались с тем, чтобы выпиливать вот это вот все.
Инструментацию надо проводить в промышленном контуре. Пилотирование в тестовом контуре не дало никаких результатов, потому что метрики, которые синтетикой собираются, обрублены, и не несут никакой информации. Соответственно, мы пошли на то, что пришлось пилотировать каждое решение по отдельности в бою.
Не надо пытаться ловить успешный кейс. Любой кейс, который мы хотели апробировать, вылавливали на продакшене, начинали разбирать в инструменте, и заканчивался он в итоге какой-то интересной историей. Например, начинаем идти по stack trace, который рисует инструмент, доходим до интересного момента и… ничего не видим. Почему? Инженеры со стороны компании-партнера говорят:
— Вы же здесь не установили агента, поэтому у вас ничего нет.
Хорошо, установили. Начинаем разбирать другой кейс, опять доходим до интересного момента, где вроде бы уже должна быть раскатка, а тут…
— Вы конфигурации не включили…
Включили. В третий раз поймали, начинаем разбирать:
— Лицензия закончилась…
В общем, безудержное веселье каждый раз на каждом тестовом кейсе.
Будет много конфигураций и танцев с бубнами. «Никто не ожидал», но заверения продавцов, что «one agent» будет установлен и все махом замониторится, не работают. Начинаешь что-то инструментировать, начинаешь выяснять, что, оказывается, у тебя тут старая версия неподдерживаемой библиотеки на Rabbit, а здесь старый фреймворк — иди поднимай…и т.п.
Какое решение выбрали и почему?
На пилотирование каждого решения уходит примерно квартал, потому что нужно встраиваться в релизные циклы команд и попасть в технологические окна решений. В итоге, через 3 квартала мы все-таки закончили пилот и настало время выбирать победителя. На этот случай у нас было несколько критериев.
Минимальные «накладные расходы». Выбирали решение по тому, насколько оно добавляет оверхеда на конечный сервис. Например, Dynatrace (Ключ-АСТРОМ) на продакшн нам добавлял 20% оверхеда на CPU. Это никуда не годится — Dynatrace, прощай.
Универсальное лицензирование. Мы также изучали все коммерческие приложения на предмет того, как именно лицензируется то или иное решение. Например, на любой чих, грубо говоря, в AppDynamics нужна лицензия: за каждый микросервис плати, хочешь дополнительную аналитику — плати, ставишь агента на хост, где крутится твой сервис и хочешь метрики самой ОС — плати, по умолчанию их нет в базовой версии. Возможно, сейчас что-то изменилось, ситуацию описываю на 2021 год.
Безлимитная аналитика и запросы. Анализ метрик тоже должен быть безлимитным или стоить не так много денег.
Удобная и быстрая инструментация.
Поддержка пилота локальной командой партнера.
В конце остался только один вендор — Instana — и это решение удовлетворяло всем критериям. Был лишь единственный минус на тот момент — по заявлению Instana, у них не было поддержки на территории РФ.
По счастливой случайности, на одном из митапов, где выступали различные представители подобных APM-решений, мы познакомились с Денисом — партнером Instana. Он нам и помог с приобретением и внедрением Instana в банке.
Что такое Instana?
Если коротко — это Application Performance Management (APM) + Observability система.
Ее ценность в том, что:
У Instana есть автоматическая инструментация сервисов и эндпойнтов, как и в любой другой observability-системе.
Для получения трэйсов и метрик нужно минимальное вовлечение разработчиков.
Как правило, внедрение происходит очень быстро (с учетом масштаба систем, конечно).
Автоматический алертинг доступен из коробки — определения состояния здоровья и агрегация множества алертов в один инцидент. Помогает не отвлекаться на множество сигналов, а увидеть root cause проблему: что в него входит, какие проблемы, на каких компонентах, на каких сервисах, как они влияют на пользователя. Конечно, внутри там сложная математика, но на выходе этим удобно пользоваться.
Защита проекта
После пилотирования настал этап защиты — обоснование затрат. Мы сделали красивые презентации…

…провели демо систем трех финалистов, обосновывали ценность инструмента для каждого департамента, например, технической поддержки.
Но от бизнеса слышали «Дорого!»
Бизнес видел в observability-системе игрушку, которую нам просто хочется.
Решили подступиться с другой стороны. Если бизнесу важно понимать совокупные затраты, мы их предоставим. Так мы познакомились с термином ТСО — total cost of ownership. Это все затраты бизнеса на решение в течение 5 лет.
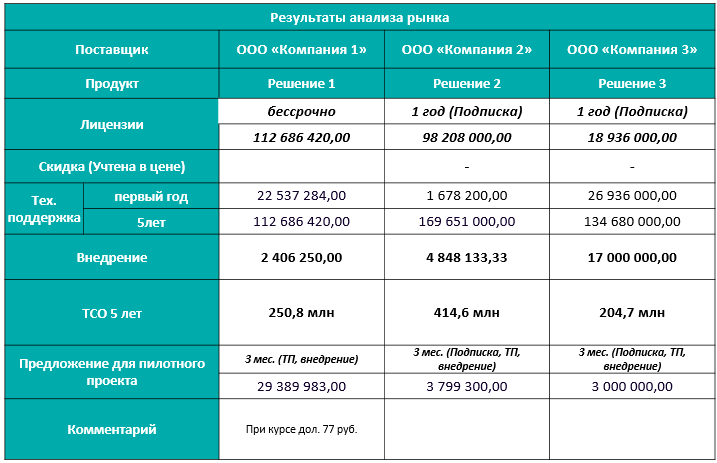 Пример TCO из нашей презентации
Пример TCO из нашей презентации
Здесь уже диалог стал интереснее и нас начали слушать. Ключевой поворот на дороге к одобрению мы прошли, когда один из участников комиссии привел такое сравнение:
— Пацаны, вот вы приходите ко мне и говорите, что сейчас вы ездите на развалюхе, которая вас от точки А до точки Б довозит. А теперь вы хотите премиальной авто. Зачем, если он вас также возить от точки А до точки Б?

Логично. Но есть нюанс и ответ был такой:
— Перед нами стоит цель догнать конкурентов. Мы хотим попасть в десятку* банков. Но на «Жиге» в десятку не попасть. На развалюхе от точки А до точки Б мы может и доедем. Но последними. Если мы хотим догнать конкурентов, то надо что-то помощнее и понадежнее. Решение стоит дорого, но мы получаем комфорт, безопасность и, главное, скорость.
*на тот момент.
Через 5 минут неудобного молчания нас попросили покинуть помещение. Через некоторое весьма волнительное время нам написал наш директор: «Не знаю, что вы сделали, но деньги вам выделили».
Если решите повторить, то вот пара советов.
«Просто внедрить», чтобы нарастить команду, прокачать экспертизу в управлении и написать в резюме, как управлял командой мониторинга из 20 человек, это не цель.
Конечная цель — это «снижение стоимости простоев и инцидентов, и повышение заработка за счет повышения доступности системы. В итоге мы больше заработаем, потому что меньше потеряем на простоях и инцидентах»
Если цель верна, то достаточно просто подсчитывается экономика всего этого процесса, в том числе стоимость разработчиков, эксплуатации, инфраструктуры, стоимость хранения данных и прочее.
А если декомпозировать все это на метрики для обоснования экономической составляющей (покупать или нет, грубо говоря), то для большинства проектов они будут такими:
Стоимость простоя: как правило, бизнес очень хорошо ее знает, например, сколько транзакций не прошло из простоя.
Количество инцидентов за период.
Mean time to detect (MTTD).
Mean time to resolve (MTTR).
SLA, SLO, SLI.
Количество вовлеченных инженеров и разработчиков для решения инцидента.
Другими словами, мы считаем, как часто возникают инциденты, как быстро мы их обнаруживаем, как быстро их разрешаем и какими ресурсами, в том числе человеческими, и сколько это стоит.
Внедрение
Итак, бюджет есть, решение выбрано. Теперь не менее важный этап — внедрение.
У нас сотни микросервисов, 60 продуктовых команд. С чего начать?
Начать надо с плана внедрения.
Сделать опытную зону.
Провести обучение как для разработчиков, так и для команд эксплуатации.
Допилить: какие-то процессы встраивания и изменения пайплайна все равно будут.
Растиражировать на следующие команды и проекты.
План выглядит хорошо. А что на деле? К чему мы пришли?
Инфраструктура микросервисов выглядит так.
 Она живая и постоянно изменяется — все это нужно отслеживать, контролировать.
Она живая и постоянно изменяется — все это нужно отслеживать, контролировать.
Даже с автоматической инструментацией, как правило, нужно доставить агента. В проекте было большое количество сервисов внутри OpenShift и Kubernetes, и интегратор доставлял агентов с помощью Kubernetes Admission Controller Mutating Webhooks. Таким образом, быстро покрыли 60% всех сервисов в банке.
Дальше сервисы сгруппировали по командам, выстроили алертинги, а мы уже сами доработали интеграцию с Telegram, чтобы каждая команда получала нужные алерты по своим сервисам.
Следующий шаг — встраивание в CI/CD-пайплайны — добавление автоматической инструментации приложений для K8S/OS-сервисов. При этом сам CI/CD — источник события для системы: «Вот у нас инцидент, возник потому, что у нас был релиз и деплой, будем откатываться»
Метрики: инциденты, расследования, реакции
У любого проекта есть цели, которые мы отслеживаем метриками. Для проекта мы выбрали метрики по инцидентам (количество). Благо в банке существует отдельная команда, которая занимается их регистрацией и анализом. Не составило труда запросить эти метрики и получать их на периодической основе.
Соотнеся метрики с конкретными системами, которые мы инструментируем, и отсчитывая от даты инструментации, видно, что количество инцидентов сократилось.

Одна из причин — это то, что команды по завершению релиза получали в рамках CI/CD-пайплайна метку в самом продукте о том, что здесь был релиз. Так они могли в реалтайме отслеживать, что происходит с конечной системой и вовремя среагировать.
Сократилось время расследования инцидентов.
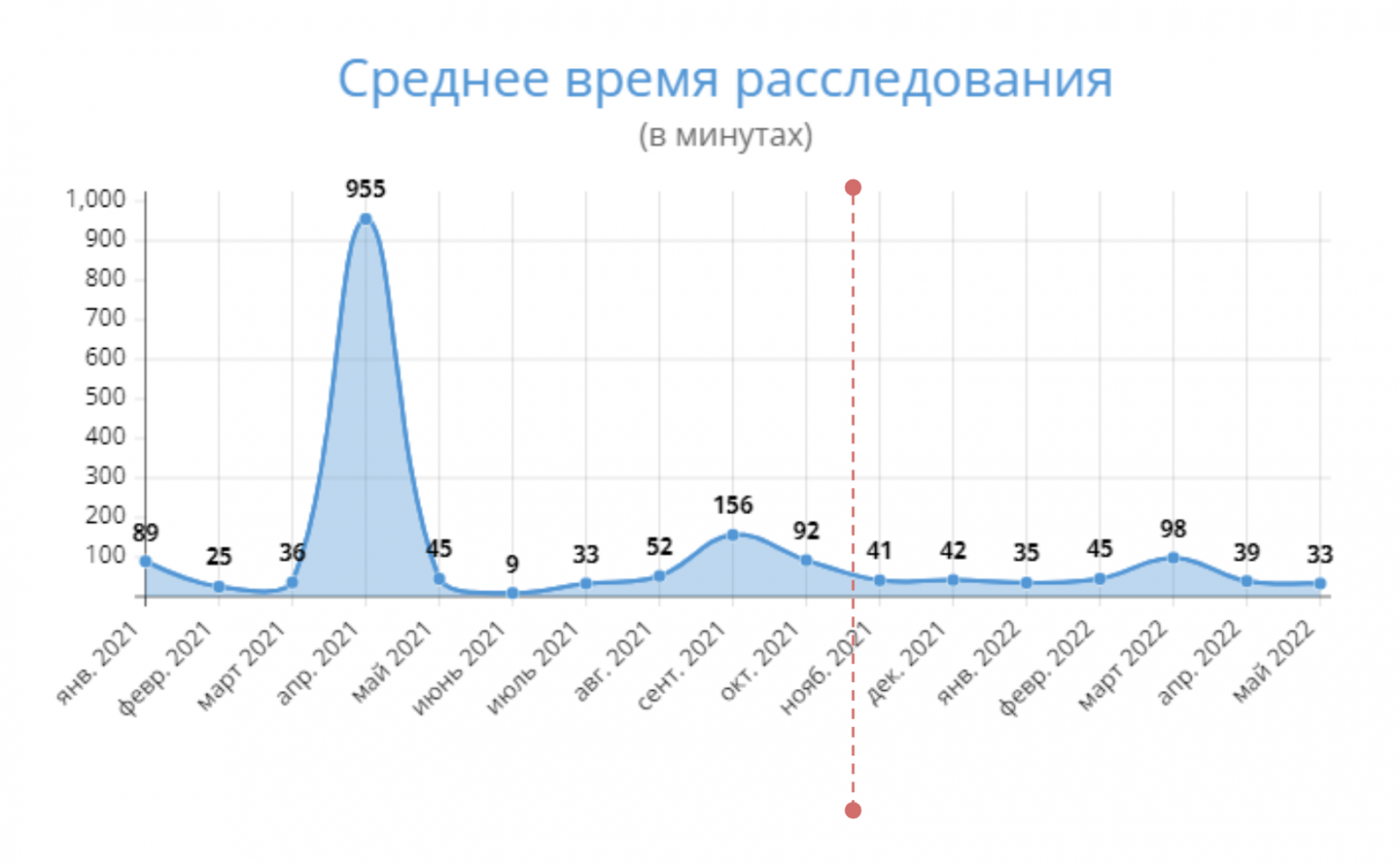
Здесь все достаточно просто: у нас есть дата начала инцидента и дата окончания, а наша задача — сократить это время. Задача решалась за счет того, что команды начали ориентироваться на подсказки Instana, которые система давала в рамках того же AIOPS (Artificial Intelligence for IT Operations), который в них встроен.
К тому же, ребята итак обменивались ссылками из Instana, чтобы быстрее обнаружить ту или иную проблему. Поэтому больше не могло произойти историй из начала статьи — «Извините, проблема не у нас». Теперь сразу видно корневую причину и команду, которая конфигурацию своего сервиса подменила, например. Поэтому мы быстрее локализовывали проблемы.
Сократилось время реакции: еще есть к чему стремиться, но каких-то пиковых моментов не возникало.

Мы плотно интегрировались с командой инцидент-менеджмента. В случае регистрации инцидентов в банке, бизнес сразу получал уведомление о том, что существует определенная проблема и ей уже занимается команда разработки. Все стало прозрачнее и уже нет необходимости поднимать панику.
Команды стали строить дашборды в самой Instana.
При этом они брали не только технические, но и немного бизнес-метрик.
Итого
Что мы получили в банке?
Ускорили time to market. Команды стали уверенней ставить релизы, потому что сразу видели как релиз влияет на бизнес-процесс — система стала предсказуема.
Улучшили интеграцию с командой инцидент-менеджмента (алерты в Телеграмме).
Сократили время на поиск корневой причины: система подсказывает местоположение проблем, так или иначе.
Стали находить проблемы до ее эскалации — стало меньше инцидентов, о которых нам сообщали клиенты.
Сложности. Если решите повторить, то вас ждут:
Стресс от выбора решения в ограниченные сроки. Хотя в текущей ситуации выбора особо не будет, потому что когда проект начинался несколько лет назад у нас было так.
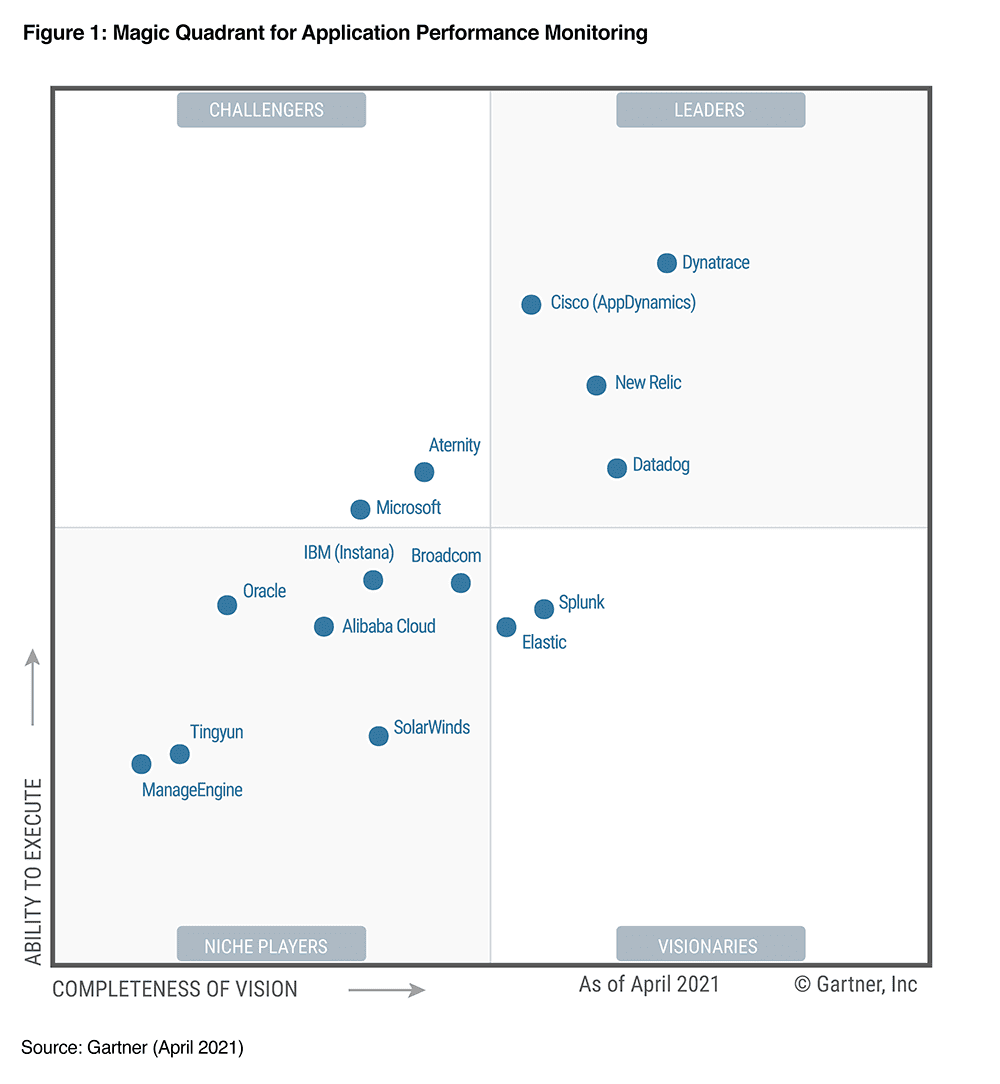
А теперь так.
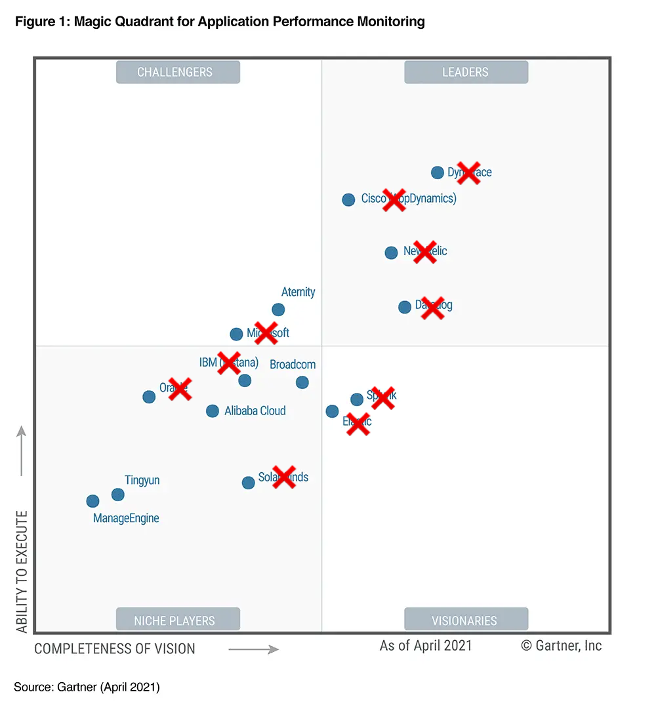
Теперь вы не найдете на рынке РФ подавляющую часть вендоров по теме observability.
Обоснование затрат — защита проекта и множество питчей.
Стресс от инструментации легаси, когда начинаете «двигать» старые сервисы, а они «вросли в землю».
Стресс от инструментации вендорских решений.
Советы.
Действуй быстро! Чем дальше, тем больше увеличивается сложность.
Пилотирование дает эффект в промышленном контуре.
Не сдаваться — добиваться своего до конца (особенно на защите).
Собственное решение для зрелой команды и молодой инфраструктуры.
Не надо бояться экспериментировать.
Куда движемся дальше?
Потратив кучу денег и времени Получив бесценный опыт готового коробочного решения, мы не расстраиваемся. Сейчас мы на базе OpenSource собираем свое решение — опыт очень помогает. Плюс у банка есть много чего неинструментированного, важно покрыть все.
