Классификация действий на видео (Action Classification)
Всем привет дорогие читатели! Данная статья показывает, как можно решить задачу Action Classification, а именно следить за рабочим процессом на производстве, где необходимо определить работает человек или нет.

Проблематика
Для начала необходимо определить проблематику данной задачи. Она состоит в том, что для стандартной задачи классификации изображения мы используем свёрточную сеть, на которую передаем изображение и получаем предсказание. А теперь вопрос на засыпку: можно ли по одному изображению классифицировать действие человека на снимке ниже?

Рисунок 1 — Первый кадр рандомной гифки из инета
Итак, это практически невозможно, так как мы не можем понять, что конкретно этот человек делает. Поэтому необходимо анализировать ряд изображений, чтобы понять то, чем занимается человек. Именно в этом состоит основная проблематика данной задачи.

Исходная гифка
Пути решения проблемы
На данный момент я нашёл 2 самых наиболее адекватных работоспособных решения:
1) классификация действий по видеоряду изображений;
2) классификация действий по keypoints.
Первый способ подразумевает использовать N изображений видеоряда и классификацию действий по ним. Грубо говоря на вход модели подается массив с размером NxWxHxK, где
N — количество изображений;
W — ширина каждого изображения;
H — высота каждого изображения;
K — количество каналов у изображения.
Но тут может возникнуть проблема. Если на видео предполагается, что людей много, то модель не сможет сделать правильный прогноз. Данная проблема решается «трекингом» каждого человека и составлением массивов изображений для каждого объекта на видеоряде.
Второй способ — это примерно такой же подход, как и у первого способа, но вместо массива изображений размером NxWxHxK в модель передаются массив кейпоинтов размером NxMxK, где
N — количество изображений;
M — количество «кейпоинтов» по оси абсцисс;
K — количество «кейпоинтов» по оси ординат.

Рисунок 2 — Пример keypoint detection
Важный момент! Каждый сам выбирает сколько кадров необходимо за раз обрабатывать, поэтому параметр N в обоих случаях выбирается индивидуально. На практике я обрабатывал 10 кадров на видеопотоке с частотой 2 кадра в секунду и в целом за 5 секунд уже можно классифицировать действие человека.
Как подобрать параметр N для своей задачи? Просто просмотрите видео на которых вы будете обучаться и ответьте на несколько вопросов:
Сколько секунд вам необходимо, чтобы понять, что делает объект на видео?
Нужно ли вам уменьшать скорость видео? Это необходимо, когда например у вас скорость 30 кадров в секунду и вы понимаете, что вам необходимо например 5 секунд, чтобы понять, какое действие проиходит. Соответственно хранить промежуточно 150 кадров для одного объекта это довольно затратно по памяти. Именно поэтому можно ограничит скорость видео например до 2 кадров в секунду.
Подведем промежуточный итог плюсов и минусов каждого подхода
Плюсы для первого способа (классификация действий по видеоряду изображений):
Необходимы только изображения. Даже если придётся производить «crop» людей с помощью другой нейросети, то выделять bbox объектов намного проще и надёжнее чем определять keypoints каждого объекта.
Минусы
Необходимо хранить в буфере изображения для каждого объекта, поэтому этот способ будет занимать больше оперативной памяти.
Нейросеть для классификации действий должна обрабатывать изображения ряд изображений вместо матрицы keypoints. Поэтому такая модель будет иметь больше параметров.
Плюсы для второго способа (классификация действий по видеоряду):
В буфере хранятся keypoints объектов, что значительно эффективнее, чем хранить всё изображение человека
Высокая точность. Так как keypoints объекта содержит только скелет, модель не будет «привязываться» к фону, свету одежды и другим деталям. Поэтому можно быть уверенным в точности определения действия.
Минусы
Необходимы изображения, на которых человека видно полностью и в хорошем качестве, иначе определения ключевых точек может стать для модели «трудной» задачей.
Разметка кейпоинтов является более трудоемкой задачей, чем выделение bbox человека.
В данной статье я опишу только первый способ, так как ключевым фактором для определения точек является хорошая видимость каждого человека на изображении. В задаче, которую решала наша команда, людей было видно не очень хорошо и поэтому модель определения keypoints даже с дообучением выдавала не очень удовлетворительный результат.
Постановка задачи от реального заказчика
Для начала определимся с постановкой задачи от заказчика, который обратился к нам в компанию.
Есть производство, которое занимается разделкой куриного мяса и заказчик хочет определять насколько эффективно работает каждая бригада (их несколько) с помощью компьютерного зрения по камерам в помещении.
Исходя из постановки задачи мы понимаем, что это задача Action Classification, где необходимо определять для каждого работника класс условно «работает» и «не работает». И собирать статистику, чтобы потом её анализировать.
Решение данного кейса
Для начала нам необходимо определять каждого человека на изображении и трекать его. Так как нам необходимо определить время работы каждого сотрудника.

Рисунок 3 — Условная схема расположения людей на камере
В самом начале нашего пайплайна решения мы используем дообученную YOLOv8m от Ultralitics для выделения bbox каждого человека и трекинга. После трекинга модели мы записываем в хэш таблицу для каждого id вырезанный bbox человека, номер кадра и размеры bbox.
Если мы получили для любого id 10 изображений мы создаём numpy array размером 10×160x160×3 и передаем в модель классификации. Моделью классификации действия является модель на TensorFlow.
Архитектура модели — изменённая ResNet50 со слоями TimeDistributed над слоями свёртки и пулинга. После слоёв свертки модель имеет 3 слоя LSTM с 128, 64 и 32 нейронами соответственно. На выходе 1 нейрон с функцией активации «сигмоида».
Также мы для привязки к рабочему месту использовали «Perspective Transformation» от OpenCV для расположения каждого объекта на карте. Благодаря этому мы можем привязать каждый объект к определенной области работы и отслеживать статистику работы. Пример представлен на рисунке 4.
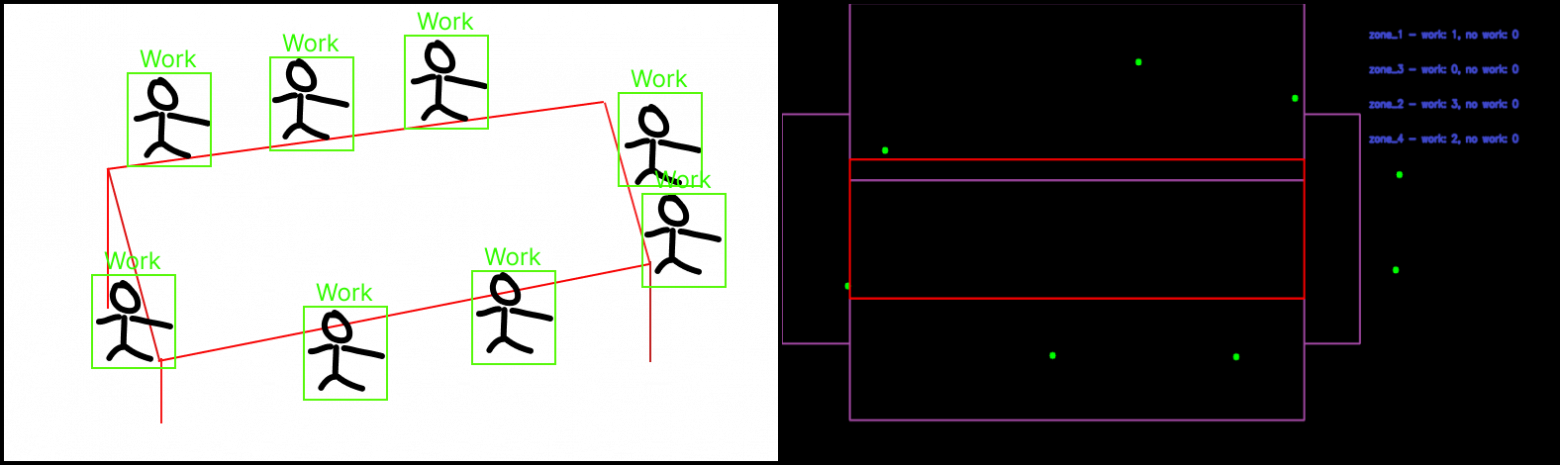
Рисунок 4 — Пример отображения карты
Вывод
В целом пайплайн из данных моделей, может помочь компаниям отследить статистику рабочих процессов по видеокамере. Для этого достаточно выбрать оптимальный для себя способ определения действий (по изображениям объектов или по их кейпоинтам), обучить модель классификации действий и собирать статистику.
Материалы
Научная статья про классификацию действий
Алгоритм классификации видео
Научная статья про определение действий на видео
Научпоп статья про распознавание действий
Статья arXiv
Автор: Ярослав Колташев
