Headless eCommerce на Laravel: Погружение в модульную архитектуру
Привет, Habr! Меня зовут Тальгат Хайруллов, я руководитель команды разработки в компании CS-Cart. В статье расскажу, как мы поверх Laravel реализовали фреймворк для быстрой и гибкой разработки API продукта с модульной архитектурой.
Про модульную архитектуру в монолите написано немало информации, этот подход даёт возможность выстроить явные границы кода, уменьшить связанность, позволяет масштабировать разработку. Но что, если вам нужно одновременно иметь чёткую границу и высокую расширяемость? Представьте, что ваша модель данных может быть сформирована набором из нескольких модулей, и всё это должно гармонично взаимодействовать как на уровне бэкенда, так и на уровне публичного API.
Модульность и расширяемость
В наших продуктах модульность — это не просто способ организации кода и разработки, это ещё и инструмент экосистемы продукта, так сторонние разработчики могут разрабатывать свои модули под различные требования бизнеса.
Laravel сам по себе расширяемый фреймворк, с богатым набором инструментов, казалось бы, что ещё нужно? Давайте посмотрим на следующий пример:
validate([
'title' => ['required', 'string', 'max:255'],
'content' => ['required', 'string'],
'category_ids' => ['required', Rule::exists(BlogCategory::class, 'id')]
]);
$post = new BlogPost();
$post->fill($validated);
$post->save();
$post->categories()->sync($validated['category_ids']);Инструментарий в Laravel позволяет подписаться на событие сохранения модели и даже выполнить проверку того, что в модели изменилось. И всё же есть ограничения: вы не сможете понять, как изменились связи модели. В примере выше создаётся пост и прикрепляется к категориям. Как со стороны другого модуля, понять, в какие категории был прикреплён пост? Без костылей никак, разработчик должен самостоятельно заложить эту возможность.
А что делать, если модель подразумевает расширение? Например, модуль «Images gallery» расширяет модель BlogPost модуля «Blog», и теперь при создании поста можно задать картинки, а возможно, в некоторых сценариях картинки и вовсе должны быть обязательными. Как написать код создания поста, чтобы учитывались и другие модули? Что для этого нужно?
Фреймворк
В CS-Cart у нас достаточно опыта работы с модульными системами, в новом продукте мы подошли к этому вопросу основательно. Нам хотелось унифицировать процесс работы с моделями и при этом сохранить гибкость, чтобы простые вещи можно было делать максимально просто, и оставалась возможность делать сложные вещи в рамках того же процесса.
Давайте усложним предыдущий пример создания поста. Представим, что нам необходимо атомарно создать пост с тегами и категорией, если её нет. Вот как этот код мог бы выглядеть:
validate([
'title' => ['required', 'string', 'max:255'],
'content' => ['required', 'string'],
'category' => ['required', 'array'],
'category.title' => ['required', 'string'],
'category.slug' => ['required', 'string'],
'tags' => ['required', 'array'],
'tags.*.title' => ['required', 'string', 'max:255'],
]);
DB::transaction(static function () use ($validated) {
$category = BlogCategory::query()->where('title', $validated['category']['title'])->first();
if ($category === null) {
$category = new BlogCategory();
$category->fill($validated['category']);
$category->save();
}
$post = new BlogPost();
$post->fill($validated);
$post->save();
$post->categories()->attach($category);
foreach ($validated['tags'] as $tagInput) {
$tag = new BlogPostTag();
$tag->fill($tagInput);
$tag->post_id = $post->id;
$tag->save();
}
});При этом категория является самодостаточной моделью, у которой есть свои связи, правила валидации и ограничения, которые должны быть учтены во всех сценариях создания. Очевидно, что с увеличением количества моделей возрастает сложность кода, а вероятность ошибки неуклонно растёт.
Чтобы снять эту нагрузку с разработчика, мы реализовали слой работы с моделями, который призван упростить разработку и обеспечить расширяемость. Верхнеуровнево в коде он выражен следующими компонентами:
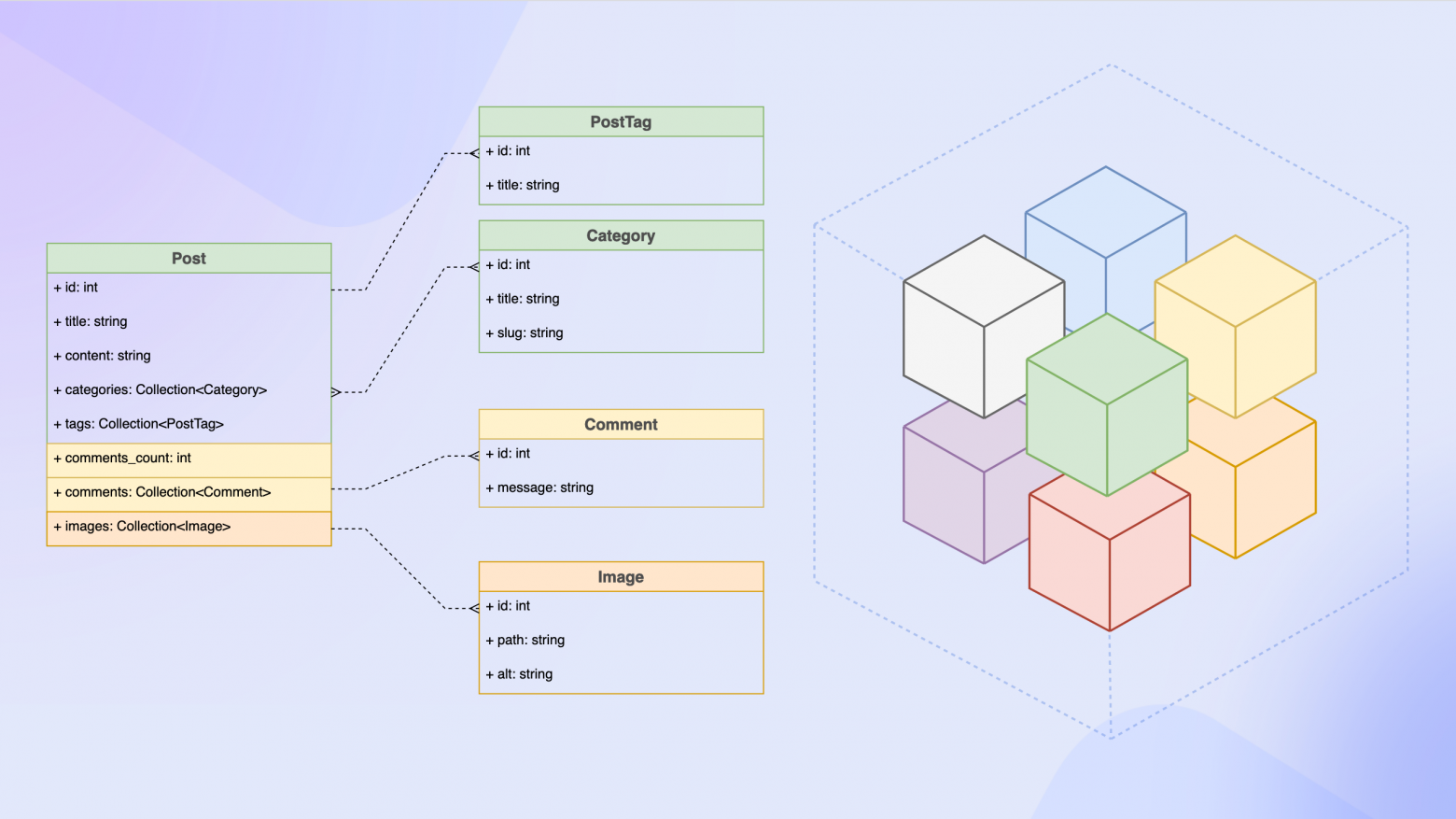
Model — абстрактный базовый класс для всех моделей, реализующий дополнительные инструменты для контроля состояния модели и управления связями.
Input — абстрактный базовый класс для всех объектов, представляющих входные данные, предназначенный для типизации, валидации, санитизации входных данных и реализации хуков процесса обработки данных.
Schema — объект для описания метаинформации конкретных Model и Input классов.
Context — контекст приложения, предоставляет доступ к текущему пользователю и настройкам приложения.
Repository — сервис для выполнения CRUD операций.
За расширяемость отвечает Schema. Она позволяет описывать структуру Model и Input классов, указывать различные директивы, влияющие на поведение модели в различных ситуациях. Схемы описываются внутри соответствующих классов, объект схемы размещается в сервис-контейнере приложения, что позволяет модулям расширять этот объект без внесения изменений в код файлов класса. Схема участвует во многих процессах, например, генерация mixin, чтобы IDE и статические анализаторы кода (psalm, phpstan) понимали структуру объектов.
Пример схемы для модели BlogPost:
id('id', 'Post ID');
$schema->int('author_id', 'Post author ID');
$schema->string('title', 'Post title');
$schema->string('content', 'Post content');
$schema->datetime('updated_at', 'Post updated at');
$schema->datetime('created_at', 'Post created at');
$schema->nullableDatetime('published_at', 'Post published at');
$schema->models('categories', 'Post categories', BlogCategory::class);
$schema->models('tags', 'Post tags', BlogPostTag::class);
$schema->model('author', 'Post author', User::class);Для полноценной работы у каждой модели должно быть как минимум 2 класса Input:
Входные данные для мутации —
ModelInput.Входные данные для фильтрации —
ModelQueryFilter.
Схемы этих классов по умолчанию выводятся из схемы модели, так, если в модели есть строковый атрибут title, то он будет представлен в схеме ModelInput как необязательный строковый атрибут, а в схеме ModelQueryFilter как структура:
array{
eq?: string, // = ?
in?: array, // IN (?)
ne?: string, // != ?
nin?: array, // NOT IN (?)
like?: string, // LIKE ?
contains?: string // LIKE %?%
} Кроме атрибутов модели, схема ModelInput класса описывает входные данные для управления связями модели. В зависимости от типа связи используются свои структуры, например, для связи BelongsToMany используется следующего вида структура:
array{
ids?: array, // Sync by IDs
sync?: ModelQueryFilter, // Sync by filter
attach?: ModelQueryFilter, // Attach by filter
detach?: ModelQueryFilter, // Detach by filter
create?: Collection, // Create and attach models
update?: Collection<{ // Update attached models
where: ModelQueryFilter,
input: ModelInput
}>
upsert?: Collection<{ // Upsert and attach models
where: ModelQueryFilter,
create: ModelInput,
update?: ModelInput,
}>
} Пример ModelInput класса модели BlogPost:
['required_if_create', 'filled', 'string'],
'content' => ['required_if_create', 'filled', 'string'],
'published_at' => ['nullable', 'date'],
'categories' => ['relation_required']
];
}
}После создания Model и Input классов, разработчик получает интерфейс выполнения CRUD операций над моделью. Пример создания поста с тегами и категорией:
title = 'How to Create GraphQL API';
$input->content = 'In our second blog post…';
$input->tags->create->push(new BlogPostTagInput(['title' => 'GraphQL']));
$input->tags->create->push(new BlogPostTagInput(['title' => 'Laravel']));
$input->categories->upsert->push(new RelationUpsertInput([
'where' => new BlogCategoryQueryFilter(['title' => ['eq' => 'Dev']]),
'create' => new BlogCategoryInput(['title' => 'Dev', 'slug' => 'dev'])
]));
$repository->save($input, $context);При вызове метода save сервис Repository выполняет большую работу:
Разворачивает иерархию
Inputобъектов, определяет модели и операции над ними. В рамках одного вызоваsaveможет быть несколько моделей и несколько разных операций, мы можем обновляя пост, удалить тег, создать новую категорию и прикрепить к ней пост.Запускает проверку прав для всех операций и моделей. По каждой модели нужно проверить наличие разрешения у пользователя, а также вызвать политики для более точечного контроля.
Запускает валидацию для всей иерархии
Inputобъектов. Если возникнет ошибка в каком-нибудьInputобъекте, то она будет выброшена ещё до старта транзакции.Вызывает хуки
ModelInputобъектов, для более точечного контроля над процессом.Запускает транзакцию.
Сохраняет модели и их связи.
Запускает события жизненного цикла моделей. Модули смогут подписаться на изменение модели, отследить какие именно были изменения, как изменились связи.
Кроме мутации моделей, в зоне ответственности сервиса Repository ещё и поиск моделей. Пример поиска постов:
title = StringFilter::contains('API');
$query = BlogPost::createModelQuery($filter, ['categories', 'tags']);
$query->limit = ModelQueryLimit::take(10);
$repository->find($query, $context);При вызове find сервис Repository выполняет следующую работу:
Выполняет валидацию
Inputобъектов.Применяет политики чтения. В некоторых случаях поиск моделей может отличаться от контекста выполнения, например, в публичном API мы не должны показывать неопубликованные посты, а в API админа должны отображаться все.
Находит класс
ModelFinder, отвечающий за поиск модели и запускает поиск.
Отдельно стоит проговорить про ModelFinder. Иерархия Input объектов формирует некий язык запроса модели, который достаточно абстрагирован, чтобы использовать различные стратегии поиска модели. По умолчанию поиск выполняется стандартным для Laravel способом, через QueryBuilder, каждый применённый фильтр в Input объектах накладывает свои ограничения. Но в некоторых случаях реляционная БД неспособна дать достаточную производительность, в таких случаях есть возможность выполнить поиски через специализированные поисковые движки, например, ElasticSearch. Так в нашем продукте реализован поиск товарных предложений на витрине, если все условия фильтра могут быть удовлетворены, используя индекс ElasticSearch, то поиск выполняется через ElasticSearch, в противном случае выполняется поиск по реляционной БД.
GraphQL
В headless решениях API занимается важную часть, от того, насколько хорошо API спроектирован и документирован будет зависеть популярность решения. Для реализации API мы используем GraphQL, о его плюсах и минусах написано немало, не буду касаться этого, расскажу только как это реализовано у нас в продукте.
Есть несколько готовых пакетов для Laravel, упрощающих разработку GraphQL API:
Оба пакета под капотом используют webonyx/graphql-php и реализуют разные подходы.
Мы используем rebing/graphql-laravel, но не в чистом виде. Фреймворк умеет выводить GraphQL типы из схем Input и Model классов, таким образом, мы мапим структуры API на структуры в бэкенде, что уменьшает дублирование метаинформации. Для обеспечения безопасности у разработчика есть инструменты контроля, например, если какие-то атрибуты или связи модели не должны быть доступны в API, разработчик сможет это сделать за счёт специальных директив, которые применяются к схеме.
Для демонстрации возможностей фреймворка мы реализовали модуль «Blog» и выложили его на github: incrize/cscart-blog. Тут вы сможете оценить кол-во ручной работы для того, чтобы реализовать вот такое API: https://graphdoc.io/doc/dBpJfwe5fd636xGv/
Пример мутации на создание поста:
mutation {
blogPostCreate(
input: {
title: "How to Create GraphQL API"
content: "In our second blog post…"
categories: { sync: { id: { in: [1, 2, 3] } } }
tags: { create: [{ title: "GraphQL" }, { title: "Laravel" }] }
}
) {
data {
id
}
}
}Заключение
Мы находимся в стадии активной разработки продукта и продолжаем усовершенствовать инструменты. Однако уже сейчас можно сказать, что описанный подход значительно упростил разработку. Он позволяет сосредоточиться на реализации бизнес-правил и сократить время, затрачиваемое на выполнение рутинных задач. Согласованный и стандартизированный процесс работы с моделями упрощает жизнь как бэкенд-разработчиков, так и фронтенд-разработчиков.
Бонус
eCommerce — достаточно популярная область, существует множество продуктов, которые, в определённой степени, можно считать конкурентами нашего продукта. Мы выбрали два open source решения и решили проверить, насколько удобно разрабатывать под них. Выбор был сделан на основе рейтинга в github. Lunar и Bagisto — оба модульные, оба на Laravel и headless. Для каждого из них мы реализовали такой же модуль «Blog». Результаты можно посмотреть тут и тут.
