Как в компании развивался Python. Доклад Яндекса
13 лет назад начался эксперимент по использованию Python в больших сервисах Яндекса. Эксперимент получился удачным (кто бы сомневался!) и Python начал свое победное поползновение по сервисам компании. Яндекс.Афиша, Яндекс.Погода — через некоторое время сервисов стало очень много. Вместе с ними начали появляться «лучшие практики» и «устоявшиеся подходы» к решению задач.
В докладе я вспомнил всю эволюцию Python в компании: от первых сервисов, запаковывавшихся в deb-пакеты и раскатывавшихся на голое железо, до непростого монорепозитория с собственной системой сборки и облаком. Еще в рассказе будут Django, Flask, Tornado, Docker, PyCharm, IPv6 и другие штуки, с которыми мы сталкивались на протяжении этих лет.
— Давайте расскажу про себя. Я пришел в Яндекс в 2008 году. Сначала делал контент-сервисы, в частности Яндекс.Афишу. Писал там на Python, мы переписывали сервис с Perl и других веселых технологий.
Потом я перешел во внутренние сервисы. Отдел внутренних сервисов постепенно трансформировался в управление поисковых интерфейсов и сервисов для организаций. Прошло уже много времени, из простого разработчика я дорос до руководителя питонячей разработки нашего подразделения, порядка 30 человек.
Важный момент: компания очень большая, и я не могу говорить за весь Яндекс. Я общаюсь, конечно, с коллегами из других подразделений, знаю, чем они живут. Но в основном могу рассказывать только про наш отдел, про наши продукты. Мой доклад будет сфокусирован на этом. Иногда буду рассказывать, что еще где-то в Яндексе делают так-то. Но это будет не часто.
Python используется много где в компании: любые технологии, любые технологические стеки, любые языки. Все, что приходит на ум, где-нибудь в компании есть, либо в виде эксперимента, либо еще чего-то. И в любом яндексовом сервисе точно будет Python в том или ином компоненте.
Все, что я буду рассказывать, — моя интерпретация событий. Я не претендую на стопроцентную объективность. Все это проходило в том числе и через мои руки, было эмоционально окрашено. Весь мой опыт он такой, личный.

Как будет структурирован доклад? Чтобы вам было проще воспринимать информацию, а мне — рассказывать, я решил разбить всю эволюцию с 2007 года примерно до текущего момента на несколько эпох. Доклад будет строго структурирован этими эпохами. Эпоха означает некое кардинальное изменение инфраструктуры либо подхода к разработке. Если у нас меняется железная инфраструктура и при этом мы меняем то, как мы разрабатываем сервисы, какими инструментами пользуемся, — это эпоха. Понятно, что мне приходилось немножко подгонять. Понятно, что все происходило не синхронно, и между этими изменениями были гэпы, но я всё пытался подогнать под один таймлайн, просто чтобы было компактнее.
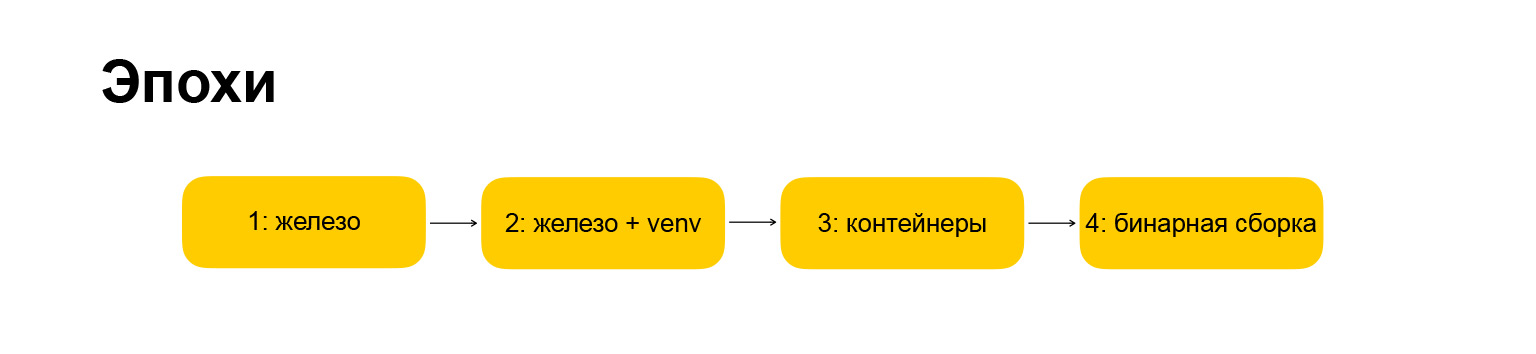
Какие у нас были эпохи? Тут тоже все авторское, все названия мои. Первая эпоха называется «железо», это то, с чего мы начинали, когда я приходил в компанию. Потому все немножко поменялось. Эпоха стала «железо + venv». Дальше я раскрою, что за этими названиями скрыто. Сначала хочу дать вам гайд по тому, что я буду рассказывать.
Следующая эпоха — «контейнеры», тут все более-менее понятно. Эпоха, в которую мы шагаем в данный момент, — «бинарная сборка», про нее тоже расскажу.

Как будет структурирована каждая эпоха? Это тоже важно, потому что мне хотелось сделать ритмичное повествование, чтобы каждый раздел был строго структурирован и его было проще воспринимать. Эпоха описывается инфраструктурой, фреймворками, которые мы используем, тем, как мы работаем с зависимостями, какая у нас среда разработки, и плюсами-минусами того или иного похода.
(Техническая пауза.) Я рассказал вам введение, рассказал, как будет структурирован доклад, давайте перейдем к самому повествованию.
Эпоха 1: железо
Первый сервис, который я стал делать, придя в компанию, назывался «Куда все идут». Это был сателлит Афиши, первый большой сервис на Django.
Гриша Бакунов bobuk может рассказать, почему он в свое время решил перенести Django в Яндекс — в общем, это случилось. Мы стали делать сервисы на Django.
Я пришел, и мне сказали: давай делать «Куда все идут». Тогда уже какая-то была база. Я подключился, и мы это считали неким экспериментом — получится или нет. Эксперимент получился удачным. Все согласились, что на Python и на Django можно делать веб-сервисы в Яндексе. Отлично! Наша инфраструктура к этому готова, люди готовы, мир тоже готов. Погнали, давайте дальше распространять Python и Django дальше по компании. Мы стали это делать. Переписали Яндекс.Афишу, Погоду. Потом — Телепрограмму. Дальше все пошло, как в тумане, стали переписывать все.
К тому моменту яндексовая инфраструктура выглядела так, что весь бэкенд в основном писался на плюсах. Очевидно, что шаг в сторону Python очень сильно ускорил разработку во многих местах, это было хорошо воспринято компанией и руководством. Давайте теперь поговорим про инфраструктуру — где эти сервисы работали, на чем крутились и все такое.

Это были железные машины, отсюда название этой эпохи. Что такое железные машины? Это просто сервера в дата-центре. Серверов много, они все объединены в кластер, скажем, из 15 машин. Потом было 30, потом 50, 100. И все это на Debian или Ubuntu. К тому моменту мы мигрировали с Debian на Ubuntu. Все приложения мы запускали через стандартный init-процесс. Все было стандартно, как в то время делали. Чтобы наши приложения общались в веб-сервере, мы использовали FastCGI-протокол и библиотеку flup. Если вы давно работаете с Python, вы, наверное, про нее слышали. Но теперь, я уверен, не используете, потому что она морально устарела и была очень странной штукой, очень медленно работала.
В тот момент, очевидно, третьего Python не было, мы писали на Python 2.3. Потом мигрировали на 2.4. Дикие времена. Не хочется даже о них вспоминать, потому что язык, сообщества и экосистема выглядели совсем по-другому, хотя тоже прикольно, и многих это тогда привлекало. Лично меня это в мир Python и окунуло — что даже несмотря на особенности и странности, уже тогда было понятно, что Python — перспективная технология, можно вкладывать туда свое время.
Важный момент: тогда мы еще не пользовались nginx, уже не пользовались Apache, а пользовались веб-сервером, который назывался Lighttpd. Если вы давно делаете веб-сервисы, то, наверное, тоже про него слышали. В какой-то момент он был очень популярным.

Из фреймворков мы, собственно, использовали Django. Мы начали делать большие сервисы на Django. Где-то в компании был CherryPy, где-то — Web.py. Возможно, вы тоже про эти фреймворки слышали. Сейчас они не на первых ролях, давно уже оттеснены более молодыми и дерзкими фреймворками. Тогда у них была своя ниша, но в итоге они рано или поздно отмерли, мы на них перестали что-либо делать. Все стали делать на Django.
В этот момент Python стал настолько широко распространен в компании, что выплеснулся за пределы нашего отдела: веб-сервисы на Python и Django стали делать везде в компании.

Давайте пойдем дальше, к работе с зависимостями. И тут такая вещь, с которой вы, скорее всего, тоже сталкивались, если приходили работать в большую компанию: в корпорации уже есть устоявшаяся инфраструктура, нужно под нее подстраиваться. В Яндексе была deb-инфраструктура, внутренние репозитории deb-пакетов. Считалось, что яндексовый разработчик умел собирать этот deb-пакет. Мы были вынуждены встроиться в этот flow, собирали наши проекты в виде полноценных deb-пакетов и потом как deb-пакет ставили все это на сервера, про которые я говорил, а потом и на кластеры раскладывали их тоже в виде deb-пакетов.
Как следствие, все зависимости и библиотечки, ту же Django, мы тоже должны были упаковывать в deb-пакеты. Мы для этого делали собственную инфраструктуру, поднимали внутренний репозиторий, учились, как это делать. Это не очень оригинальное занятие: если вы пробовали собирать RPM или deb-пакет, то вы об этом знаете. RPM чуть попроще, deb посложнее. Но все равно — не получится просто прийти с улицы и по щелчку начать это делать. Нужно немножко покопаться.
Мы долгие годы после этого собирали deb-пакеты. И мне кажется, что не все, кто этим занимался по рабочим нуждам, понимал, что происходит под капотом. Просто брали друг у друга, копировали заготовки, шаблоны, а глубоко не копались. Но те, кто раскапывал, что происходит внутри, становились очень полезными и очень востребованными коллегами: если вдруг чего-то не собиралось, к ним все ходили за советом и спрашивали нюансы и помощь в отладке. Это было забавное время, потому что мне было интересно разобраться, что там внутри. Тем самым заработал дешевую популярность у коллег.

Помимо экосистемы зависимостей, есть еще работа с общим кодом. Уже на старте был взрывоподобный рост числа проектов, и требовалось работать с общим кодом, делать общие библиотеки и прочее. Мы начали делать такой внутренний опенсорс. Сделали общие функциональности авторизации, работы с логами, с другими общими вещами, внутренними API, внутренними хранилищами. Все это мы делали в виде библиотек, выкладывали во внутренний репозиторий. Вначале это были sven-репозитории, потом — внутренний GitHub.
И в конечном итоге паковали все эти зависимости, все эти библиотечки тоже в deb, загружали в единый репозиторий. Из этого формировался такой environment пакетов. Если вы стартовали новый проект, то могли поставить там несколько библиотек, получить базу функциональностей, и сразу запустить проект в яндексовой инфраструктуре. Было очень удобно.

Как выглядел наш типовой сервер? Классически. Есть системные зависимости, есть питонячьи зависимости и приложеньки. Отсюда следует несколько вещей. В первую очередь, все приложения, которые работают на одном сервере и, следовательно, на одном кластере, должны иметь одинаковые зависимости. Потому что если вы ставите пакет-систему, он всегда одной версии, их не может быть несколько, вы должны синхронизироваться.
Когда проектов мало, это еще как-то можно делать. Когда много, все очень сильно усложняется. Их делают разные команды, им сложно договариваться. Каждая команда хочет пораньше обновиться на какую-нибудь библиотеку или хочет обновить фреймворк. И этому должны следовать все остальные. Со временем это создает очень много проблем. Это нас побудило отказаться от такой схемы, перейти в следующую эпоху. Но о ней я расскажу чуть позже.
Поговорим о среде разработки. Но тут такое расширенное понимание среды разработки. Это и то, как вы приходите на работу, как пишете код, как его отлаживаете, как с ним работаете, где проверяете, как запускаете его, где запускаете тесты и все такое.

Когда я пришел в компанию, мы все работали на удаленных dev-серверах. То есть у вас есть какой-то десктоп, на Windows или Linux, неважно. Вы идете на удаленный сервер, где стоит правильный Debian, где подключен правильный репозиторий пакетов. И вы работаете, запускаете vim, Emacs, пишете код, делаете отладку.
Это не очень удобно, но тогда мы особо не знали другой жизни. Тем кому повезло, у кого был десктоп или ноутбук с Linux, могли попытаться это сделать локально. Но тоже не было ни особых инструкций, ничего. Такое, немножко дикое время. Особые люди, которые в тот момент жили на Windows и на Маках и хотели разрабатываться локально, поднимали виртуалку, внутри которой Linux. Они внутри этой виртуалки писали код, запускали его. Точнее, писали код они на хост-системе, внутри виртуалки запускали код и как-то там пробрасывали файловую систему, чтобы все синхронизировалось. Все это работало довольно плохо, но как-то выживало.
Какие плюсы-минусы этой эпохи, этого подхода к разработке? На самом деле — сплошные минусы:
- Как я уже сказал, на общих кластерах было тесно.
- Все проекты на кластере должны были иметь одинаковые зависимости.
- Эти зависимости было сложно обновлять. Например, был момент, когда нам нужно было обновить Django на кластере. Она тогда очень быстро развивалась, довольно часто выпускались релизы. На кластере к тому моменту крутилось порядка 15–20 проектов. Весь процесс обновления занял у нас примерно пять или шесть недель. Сначала мы дождались, когда все проекты обновят свой код, потом — когда они его протестируют. Потом договорились о часе X, когда мы это все начнем катить на кластер. Конечно же, с первого раза ничего не получилось. Кто-то нас подвел, кто-то не совсем правильно обновился, нужно было откатываться. Это повторялось несколько раз и навсегда отучило обновлять эти штуки так глобально. Мы искали, как решить эту проблему, как не тратить столько времени и ресурсов на поддержание в рабочем состоянии кластеров и актуальных библиотек. Мы попытались решить это в следующей эпохе.
- Яндекс был зависим от Debian-инфраструктуры. Мы ее поддерживали, собирали пакеты, поддерживали внутренний репозиторий. И это, конечно, тоже не очень хорошо, не очень удобно, не очень гибко. Ты зависишь от странных вещей, которые делались не для компании. Debian как опенсорсное решение, как дистрибутив Linux, все-таки делался для других задач.
Давайте еще немножко поговорю про Django. Почему мы стали ее использовать? Я сейчас подумал перед докладом, пока сидел на стуле, что, оказывается, 11 лет назад я выступал в Киеве на конференции с такой же темой «Почему надо использовать Django»? Тогда мне самому это понравилось. Я был восхищенным разработчиком, который прочитал документацию, сделал свой первый проект, и ему кажется, что все, теперь этот инструмент универсально подходит для всего и на нем можно, не знаю, даже гвозди забивать.
Но прошло много времени. Я все равно люблю Django, она до сих пор довольно много используется в нашем отделе и вообще в компании. Например, еще до осени 2018 года в бэкенде Алисы была Django. Сейчас ее там уже нет, но чтобы быстро стартовать, коллеги выбрали ее. Потому что часть плюсов справедлива до сих пор — большая экосистема, по-прежнему много специалистов. Есть все нужные батарейки.
И есть достаточная гибкость. Когда вы только начинаете с Django работать, вам кажется, что она вас очень ограничивает, связывает по рукам, требует определенного flow работы с ней. Но если чуть глубже копнуть, многие вещи можно отключить, поменять, настроить. И если этим умело пользоваться, можно получать и все плюшки, которые связаны с самым, наверное, популярным фреймворком на Python. Можно все минусы обходить. Их тоже много, но они так или иначе купируются.
Эпоха 2: железо + venv
Мы закончили рассуждения об этой эпохе. Подошел к концу 2011 год, мы перешли в следующую эпоху, «Железо + venv». Вы уже знаете про железо, теперь надо рассказать, что случилось, откуда название venv. Лирическое отступление: venv возник не потому, что появились «виртуалки». Почему в кавычках? Потому что мы стали пробовать всякие контейнероподобные штуки типа OpenVZ или LXC. Тогда они были очень слабо развиты, не то что сейчас. Они у нас не очень полетели. Мы все равно жили на общих кластерах, нам все равно надо было существовать вместе с другими проектами плечом к плечу на одних машинах. Мы искали путь решения.

Например, перешли от init к upstart systemd, а чуть позже у нас появилась гибкость в запуске наших приложений. Мы отказались от FastCGI и стали пользоваться либо WSGI-интерфейсом для общения с веб-сервером, либо HTTP. В этот момент мы уже пользовались более-менее современным Python, экосистема уже была очень хорошо развита. Мы перешли на nginx в качестве веб-сервера, в общем-то все было неплохо.

Также мы стали адаптировать под себя новые фреймворки. Например, стали пользоваться Tornado. Конечно, к тому моменту уже появился Flask, после 2012 года Flask был уже очень модный, популярный и грозился Django скинуть с пьедестала популярных фреймворков в Python. И, конечно, стали пользоваться Celery. Потому что когда проекты растут, растет их количество, они становятся более высоконагруженными, решают большее количество задач, обрабатывает большее количество данных, то вам нужен фреймворк для офлайнового выполнения задач на большом вычислительном кластере. Мы, конечно, для этого стали использовать Celery. Но об этом чуть позже.

Что кардинально изменилось, так это работа с зависимостями. Мы стали собирать виртуальное окружение. Примерно в то время питонячье сообщество дошло до того, что можно не ставить питонячьи библиотеки в систему, а сделать виртуальное окружение, поставить туда все нужные вам питонячьи зависимости, и это окружение будет полностью независимым. Таких виртуальных окружений на машине может быть сколько угодно. Это изоляция, очень удобная зависимость. Вы до сих пор этим пользуетесь. И мы тоже это все адаптировали. В итоге что мы стали делать? Мы создавали виртуальное окружение и ставили туда все питонячьи зависимости, запаковывали это в deb-пакет и уже его катили на сервер.
Как следствие, все проекты перестали друг другу мешать, зависеть от общей питонячей зависимости в системе, могли спокойно выбирать, какую версию фреймворка или библиотеки использовать. Это очень удобно. С общим кодом тоже случились изменения. Поскольку мы частично отказались от Debian-инфраструктуры и, в частности, перестали ставить deb-пакетами питонячьи зависимости, нам нужно было что-то, куда мы могли бы весь наш общий код и общие библиотеки выгружать и откуда можно было бы их ставить.

Ссылка со слайда
К тому моменту уже было несколько реализаций PyPI, то есть репозиторий питонячих пакетов, реализации, написанные, в частности, на Django. И мы одну из них выбрали. Называется она Localshop, вот ссылочка. Этот репозиторий до сих пор живет, в нем уже порядка тысячи внутренних пакетов. То есть примерно с 2011–2012 года компания размера Яндекса нагенерила примерно одну тысячу разных библиотек, утилит, написанных на Python, которые, как считается, переиспользуются в других проектах. Можете оценить масштаб.
Все библиотеки публикуются на этом внутреннем репозитории. И потом оттуда либо устанавливаются в Python, либо есть специальная автоматическая инфраструктура, которая их перезаворачивает в Debian. Это все более-менее автоматизировано, удобно. Мы перестали тратить так много ресурсов на поддержание Debian-инфраструктуры. Оно все более-менее работало само.
И это качественный шаг. Вот схема с тем, о чем я говорил.
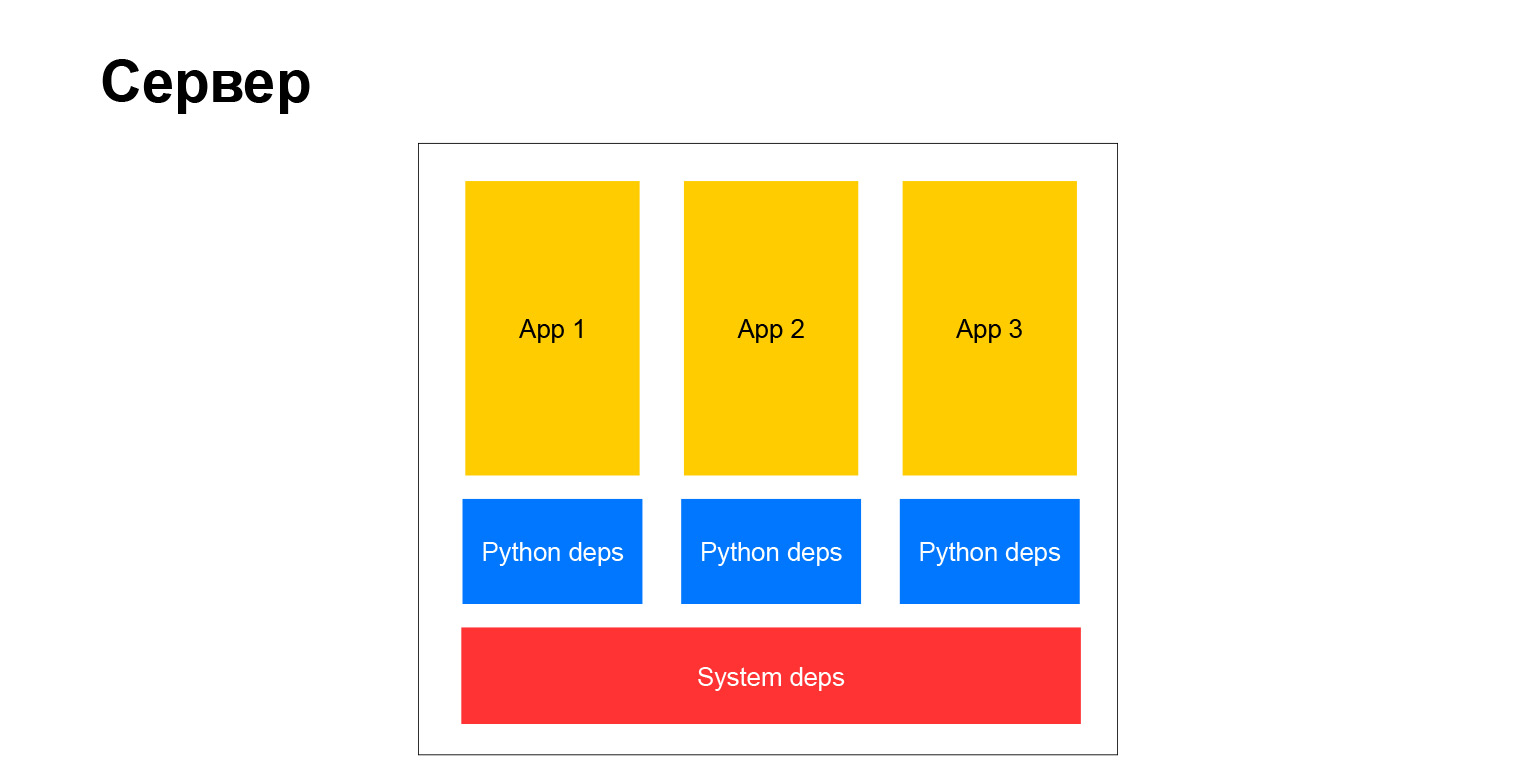
То есть питонячьи зависимости наконец перестали быть одинаковыми для всех. Системные все еще остались, но их не так много. Например, драйвер к базе данных, парсер XML требовал системных бинарных либ. В общем, от этих зависимостей мы на тот момент так и не смогли избавиться.

Среда разработки тоже поменялась. Поскольку venv, виртуальное окружение стали доступны и работали на тот момент везде, мы могли собрать наш проект в общем-то на любой локальной платформе. Это существенно упрощало жизнь. Уже не нужно было возиться с Debian, не нужно было делать никакие виртуалки. Можно было просто взять любую ОС, сказать virtual venv, потом pip install чего-нибудь. И это работало.
Какие плюсы этой схемы? Поскольку мы довольно долго — может быть, чуть больше трех лет — прожили при такой конфигурации параметрии, то стало проще жить на кластерах-общежитиях. Это действительно удобно. То есть мы перестали зависеть от этих глобальных обновлений какой-нибудь Django во всей компании. Могли более точечно подбирать подходящие нам версии, чаще обновлять критические зависимости, если в них исправляют уязвимости или еще что-то. И был очень правильный путь, нам он нравился и сэкономил нам много всего.
Но были и минусы. Системные зависимости все еще оставались общими. Иногда это выстреливало, иногда мешало. Я вновь немножко выйду за скоуп нашего отдела и расскажу про компанию. Поскольку компания большая, не все шли в ногу с этими эпохами вместе с нами. На тот момент в компании все еще продолжали пользоваться deb-пакетами для работы с питонячими зависимостями. Давайте чуть подробнее расскажу, почему мы стали использовать те или иные фреймворки. В частности, Tornado.

Нам нужен был асинхронный фреймворк, у нас появились под него задачи. Третьего Python и его asyncio еще не существовало, либо они были в начальном состоянии, использовать их было еще не очень надежно. Поэтому мы пытались выбрать, какой же нам асинхронный фреймворк использовать. Было несколько вариантов: Gevent и Twisted. Скорее всего, их было больше, но мы выбирали среди них. Twisted уже использовался в компании — например, бэкенд Яндекс.Такси был написан на Twisted. Но мы посмотрели на них и решили, что Twisted выглядит не по-питонячьи, даже PEP-8 не соответствует. А Gevent — там внутри какой-то хак с питонячим стеком. Давайте использовать Tornado.
Мы не пожалели. У нас в некоторых сервисах до сих пор используется Tornado — в тех, которые мы еще не переписали на третий Python. Фреймворк доказал за эти годы, что он компактный, надежный и на него можно полагаться.
И конечно, Celery. Я уже частично про это рассказал. Нам нужен был фреймворк для распределенного выполнения отложенных задач. Мы его получили.

Было очень удобно, что в Celery есть поддержка разных брокеров. Мы этим активно пользовались b для разных задач пытались подобрать тот или иной правильный брокер. Где-то это был Mongo, где-то SQS, где-то Redis. Но мы старались выбрать по потребности, и у нас получалось.
Несмотря на то, что к Celery, к тому, как оно написано внутри, как его отлаживать, какое там логирование, есть много претензий, оно скорее работает. Celery до сих пор активно используется практически в каждом проекте в нашем отделе, и, насколько мне известно, за пределами нашего проекта. Celery — must-have. Если вам нужно отложенное выполнение задач, то все берут Celery. Или сначала не берут, пытаются что-то другое взять, но потом все равно приходят к Celery.
Идем в следующую эпоху. Уже приближаемся к нынешнему времени, более современному. Тут название эпохи говорит само за себя.
Эпоха 3: контейнеры

Мы внутри компании получили облако, совместимое с docker. Внутри не docker runtime, а внутренняя разработка. Но при этом туда можно деплоить докерные образы. Нам это очень помогло, потому что мы смогли использовать всю docker-экосистему для разработки и тестирования. Мы могли всяким плюшками пользоваться, а потом, просто получив оттестированный image, загружать в это облако. Оно там запускалось и работало как надо.
К тому моменту мы уже были независимы от того, какая ОС внутри контейнера. Можно было выбрать любую. Мы, конечно, пользовались не обычными демонами, а, например, супервизором. Впоследствии все перешли на uWSGI — оказалось, uWSGI не просто умеет запускать ваши веб-приложения и предоставлять интерфейс для веб-сервера в них. Это еще и просто хорошая дженерик-штука для запуска процессов.
Там, правда, немножко странная конфигурация, но, в общем, это удобно. Мы избавились от лишней сущности и все стали делать через uWSGI. Его же используем для связи с веб-сервером. Особенности нашего облака таковы, что с балансировщиком, который глобально, как компонент, представлен в облаке, мы общаемся по HTTP, uWSGI-протокол использовать не можем. Но это не страшно. Внутри uWSGI довольно хорошо реализован HTTP-сервер, это работает быстро и надежно.

Что по поводу фреймворков? Появился фреймворк Falcon, и ту же Алису с Django мы переписали именно на Falcon, потому что там было какое-то количество апишек — нужно было, чтобы они заработали быстро, но при этом были не очень сложными.
Django в какой-то момент стал немножко избыточным, и чтобы повысить скорость и избавиться от такой большой зависимости, большой библиотеки, мы решили переписать на Falcon.
И, конечно, asyncio. Мы стали писать новые сервисы на третьем Python, а старые — переписывать на третий Python. Только в нашем отделе сейчас около 30 сервисов, которые написаны на Python. Это 30 полноценных продуктов, с бэкендом, фронтендом, своей инфраструктурой. То, что обрабатывает данные, предоставляет услуги и внутренним, и внешним потребителям.
Но в компании, как вы понимаете, тысячи сервисов на Python, и они разные. Они на разных фреймворках, на разных Python, более старых и новых. Сейчас в компании используются почти все современные фреймворки, которые вы знаете. Django, Flask, Falcon, еще что-то, асинхронные — Tornado, Twisted, asyncio. Все используется и приносит пользу.
Давайте вернемся к структуре эпохи — как мы стали работать с зависимостями.

Тут все просто. Мы теперь можем не пользоваться виртуальным окружением. Нам не нужны deb-пакеты. Мы просто в момент сборки образа ставим с помощью pip все, что нам нужно. Это полностью изолировано. Мы никому не мешаем. И очень удобно. Любые системные зависимости, можно выбрать любой базовый образ Debian, Ubuntu, чего угодно. Нам нравится. Полная свобода.
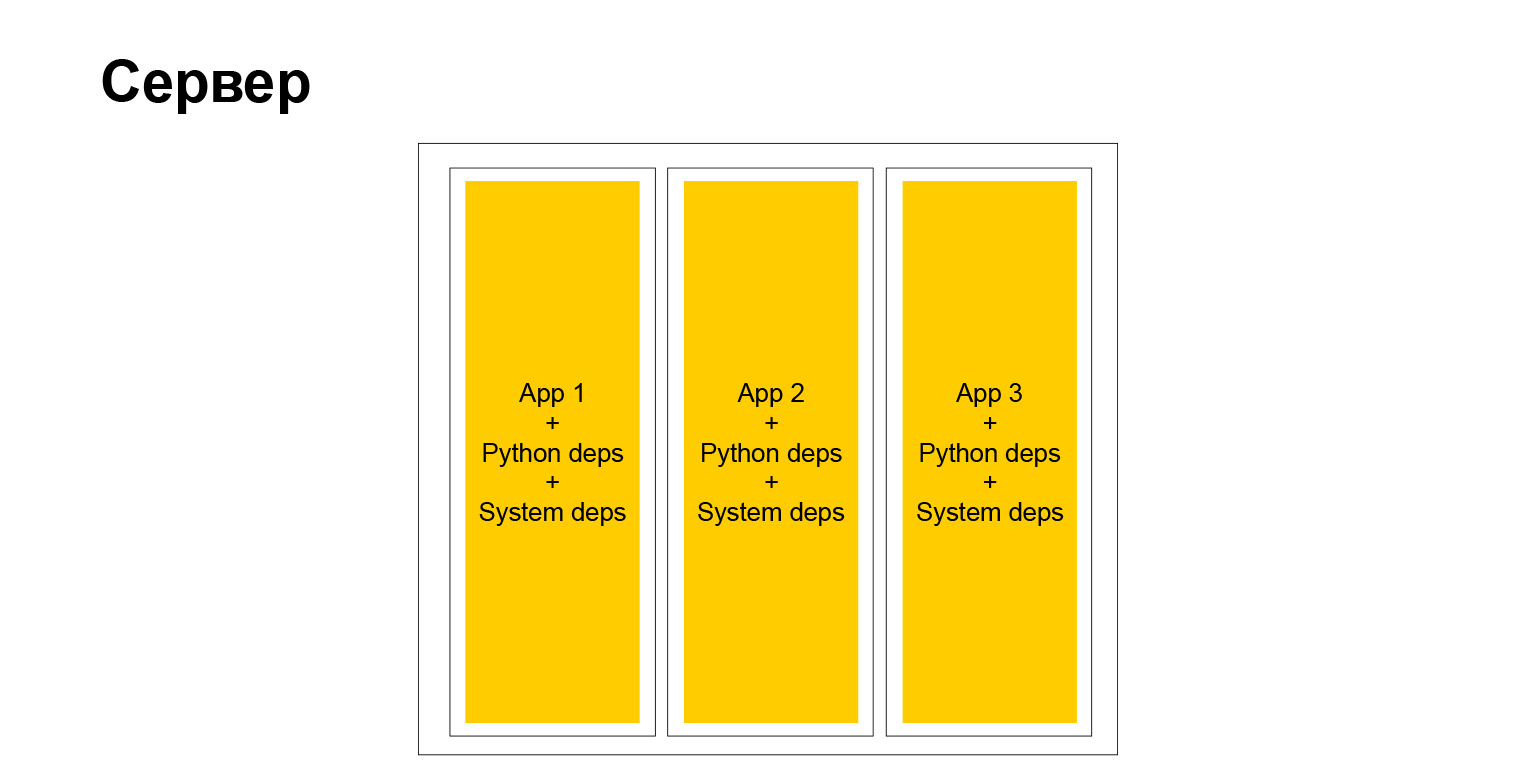
Но на самом деле у полной свободы, как вы понимаете, есть вторая сторона. Когда у вас большая компания и тем более когда вы хотите продвигать единые способы и методы разработки, способы тестирования, подходы к документированию — в этот момент вы сталкиваетесь с тем, что этот зоопарк, с одной стороны, где-то помогает. А с другой, наоборот, усложняет. Он не может легко, например, внедрить какую-то библиотеку во все сервисы, потому что у сервисы разные. У них разные версии Python, Django или какого-либо другого фреймворка. Это всё усложняет. Но в итоге типичный сервер стал выглядеть так.
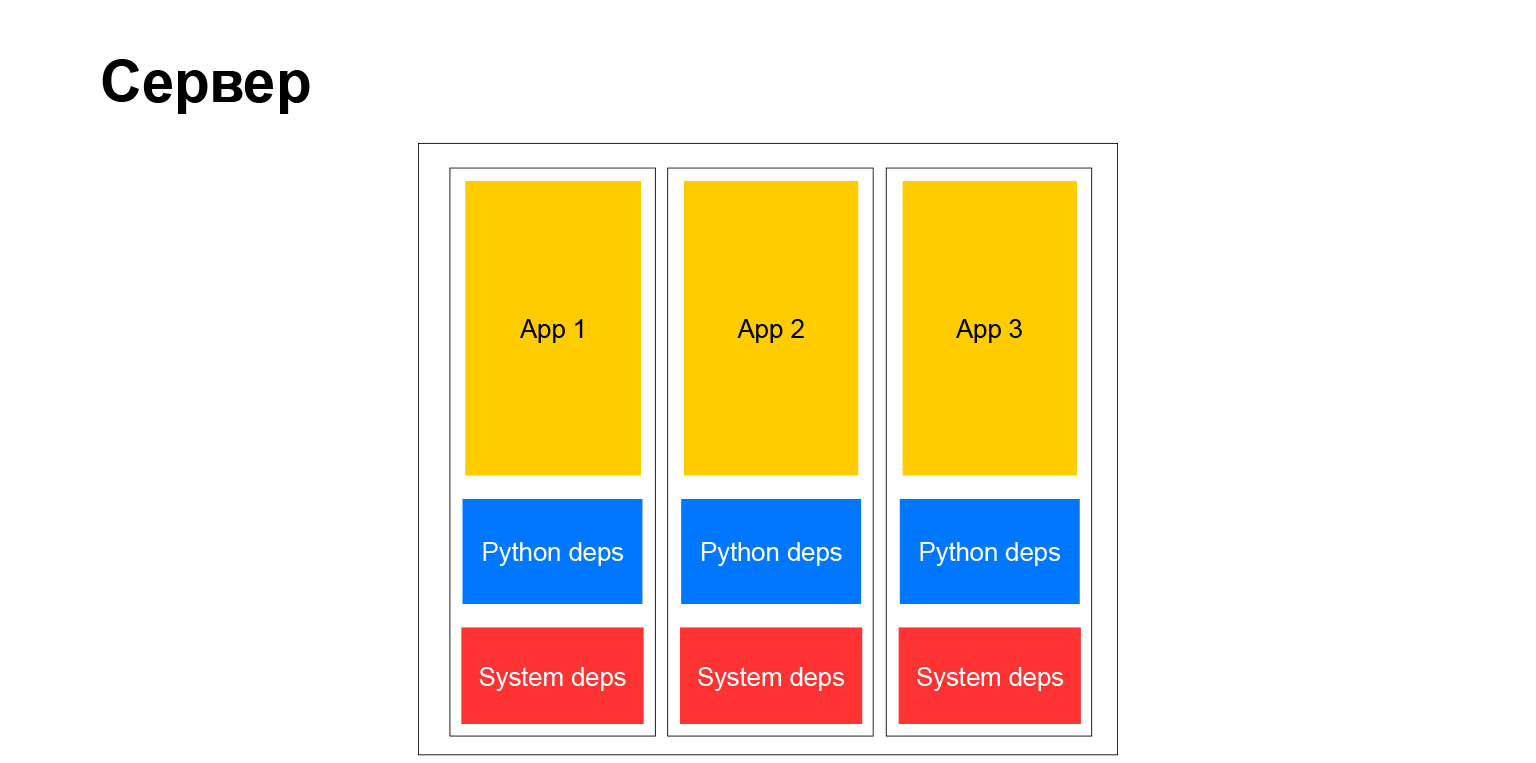
Да, это сервер. У нас есть полностью независимые контейнеры. В каждом из них своя системная среда, и крутятся наши приложения. Очень удобно. Но, как я уже сказал, есть недостатки.
Вернемся ненадолго к docker. Мы стали пользоваться для разработки docker, это нам очень помогло.

Docker есть для всех платформ. Можно тестировать, пользоваться docker-compose, делать docker swarm и на маленьких кластерах пытаться эмулировать ваше продакшен-окружение, чтобы что-то проверить. Может быть, провести нагрузочное тестирование. Мы стали этим активно пользоваться.
Docker также очень хорошо интегрирован со всякими средами разработки. Например, я разрабатываюсь в PyCharm, и большинство моих коллег тоже. Там есть встроенная поддержка docker, со своими плюсами и минусами, но в общем-то все работает.
Стало очень удобно, мы сделали качественный шаг, и именно в этой стадии сейчас находимся. Разрабатываться с использованием docker удобно, даже несмотря на то, что наше целевое облако, куда мы деплоим наши приложения, не является полноценным Docker Runtime, имеет некие ограничения. Но это нам все равно не мешает пользоваться Docker Engine локально и в смежных задачах.
Давайте подведем итоги этой эпохи. Плюсы — полная изоляция, удобный toolchain для разработки и, как я уже сказал, поддержка IDE.
Есть и минусы. Docker есть везде, но если это не Linux, он работает немножко странно. Разработчики Яндекса, у которых MacBook, ставят docker for Mac. И там есть особенности, например, IPv6 работает странно, либо нужно как-то хитро настраивать. А у нас в компании IPv6 очень сильно распространен. Нам уже давно не хватает IPv4 адресов, поэтому вся внутренняя инфраструктура во многом завязана на IPv6. И когда у вас на ноутбуке или внутри docker, который на ноутбуке, не работает IPv6, вы страдаете и не можете толком ничего сделать, то нам приходится это обходить.

Несмотря на это, docker мы очень любим. Он эффективен, на нем хорошая экосистема. Люди приходят к нам с улицы, мы говорим — умеешь docker? Они — да, умею. Все, отлично. Человек приходит и буквально сразу начинает приносить пользу, потому что ему не надо долго вникать в то, как запустить и как собрать проект, как запустить тесты, как посмотреть compose, какой-нибудь отладочный вывод. Человек все уже знает. Это де-факто стандарт во внешнем мире, это повышает нашу эффективность, мы можем быстрее доставлять фичи для пользователей, а не тратиться на инфраструктуру.
Эпоха 4: бинарная сборка
Но мы уже подходим к последней эпохе, в которую мы только вступаем. И тут я вернусь к началу своего доклада, когда я сказал: вы приходите в большую корпорацию со своими инфраструктурными подходами. С Яндексом тоже так. Если раньше это была Debian-инфраструктура, то сейчас другое. В компании уже довольно давно существует единый монолитный репозиторий, где постепенно собирается весь код. Вокруг него сделан механизм сборки, механизм распределенного тестирования, куча инструментов и всего, чем мы пока не пользуемся, но начинаем пользоваться. То есть наши питонячьи проекты тоже заезжают в этот репозиторий. Мы стараемся собираться этими же инструментами. Но поскольку эти инструменты единого репозитория, заточены в первую очередь на C++, Java и Go, там есть своя особенность.
Особенность вот какая. Если сейчас итогом сборки нашего проекта является Docker Engine, где просто лежит наш исходный код со всеми зависимостями, то мы приходим к тому, что итогом сборки нашего проекта будет просто бинарь. Просто бинарь, в котором есть питонячий интерпретатор, код и наши питонячьи и все остальные необходимые зависимости, они статически слинкованы.
Считается, что можно прийти, кинуть этот бинарь на любой Linux-сервис с совместимой архитектурой и он заработает. И это правда.
Кажется, немножко ненативно. Так не делают большинство людей в питонячем сообществе и, я уверен, не делаете вы. В этом есть свои плюсы и минусы. Плюсы:
- Это единый принцип сборки приложений во всей компании. Если раньше мы пользовались опенсорсными наработками, тем, что делают во всем мире, и получали от этого профит, не тратя ресурсы, то сейчас компания уже достаточно большая и может иметь свою внутреннюю команду для разработки подобных инструментов. Мы переключаем свой фокус с внешнего мира на внутренний и пользуемся наработками, которые делают наши коллеги. Это для нас выгодно, потому что все эти инструменты заточены под нашу инфраструктуру, наши требования безопасности и т. д.
- Мы потихонечку начинаем во всей компании, во всех стеках, технологиях, на всех языках единообразно работать с зависимостями. Все зависимости, даже внешние, лежат в нашем монорепозитории. Мы их кладем, адаптируем. Считается, что у вас есть локальный checkout этого репозитория, вам вообще не нужен интернет, чтобы собрать проект. Это правда работает.
- Как я уже сказал, удобство дистрибуции.
И, конечно, есть минус: закрытая экосистема. Человека со стороны нужно погружать в то, как это все устроено, рассказывать, как это работает. Он должен попробовать и только после этого становится эффективным. Мы только в начале этого пути. Возможно, если я приду на эту конференцию через год или два, то смогу вам рассказать, как мы эту трансформацию прошли. Но сейчас мы оптимистично смотрим в будущее и подчиняемся неким внутренним корпоративным правилам, и нам это скорее нравится, чем нет, потому что мы получим очень много именно внутренних плюшек.
Выводы
Они более философские. Сам доклад не столько технический, сколько философский.
- Эволюция неизбежна. Если вы делаете сервис и он живет долго, то вы будете его эволюционировать, эволюционировать его инфраструктуру, то, как вы его разрабатываете.
- Не бойтесь изменений. Мир меняется, вы можете смотреть, что происходит в мире, следить за внешними трендами и адаптировать их для себя.
- Не отказывайтесь от проверенных решений. Например, если десять лет назад мы выбрали Django, то до сих пор ее используем. У нас большая экосистема внутренних наработок, много экспертизы. Несмотря на то, что, может быть, Django где-то морально устарела, мы все равно продолжаем ей пользоваться. Она нам нравится, приносит пользу и все еще эффективна на наших задачах.
- Развивайте внутреннюю Python-экосистему. Если у вас команда или целая компания, которая делает несколько продуктов, не стоит копипастить код туда-сюда. Сделайте такую внутреннюю инфраструктуру, которая позволит вам эффективно обмениваться кодом, эффективно шарить знания и не делать одну и ту же работу в разных проектах. В это тоже имеет смысл вкладываться, поддерживать эту экосистему и культуру разработки, чтобы люди, понимая, что они сделали нечто полезное, сразу думали:, а давайте вынесем это в библиотеку, правильно это
