Дата-инженеры в бизнесе: кто они и чем занимаются?
Данные — один из активов организации. Поэтому вполне вероятно, что перед вашей командой в какой-то момент могут возникнуть задачи, которые можно будет решить, используя эти данные разными способами, начиная с простых исследований и вплоть до применения алгоритмов машинного обучения.
И хоть построение крутой модели — неотъемлемо важная часть, но все же это не залог успеха в решении подобных задач. Качество модели в большой степени зависит от качества данных, которые собираются для нее. И если Data Science применяется не ради спортивного интереса, а для удовлетворения реальных потребностей компании, то на это качество можно повлиять на этапе сбора и обогащения данных. И за это отвечает скорее не дата-сайентист, а другой специалист — дата-инженер.
В этой статье я хочу рассказать о роли дата-инженера в проектах, связанных с построением моделей машинного обучения, о зоне его ответственности и влиянии на результат. Разбираемся на примере Яндекс.Денег.

Какие роли есть в Data Science-проекте?
Существуют разные подходы к делению сфер ответственности в команде, которая занимается DS-проектами.
К сожалению, не для всех названий ролей есть аналоги в русском языке. Если у вас в компании есть устоявшееся русское название, например, для Data Ingest, то поделитесь им в комментариях.
Например, можно выделить следующие роли:
- Data Scientist — тот человек, который непосредственно делает модели машинного обучения,
- Data Ingest — отвечает за загрузку данных, разрабатывает ETL-пакеты,
- Data Steward — тот, кто следит за качеством этих данных,
- Data DevOps — примерно как девопс, но с упором на процессы, связанные с загрузкой и обработкой данных,
- Специалист в Information Security — отвечает за безопасность исследуемых данных, доступы, и т.д.
- и др.
Задачи, которыми занимается дата-инженеры, примерно относятся к Data DevOps, Steward и Ingest.
Что такое Data Science-проект?
Это ситуация, когда мы пытаемся решить какую-то задачу при помощи данных. То есть во-первых, эта задача должна быть сформулирована. Например, один из наших проектов начался с того, что нам нужно было распознавать аварии в приеме платежей (далее распознавание аварий будет упоминаться как исходная задача).
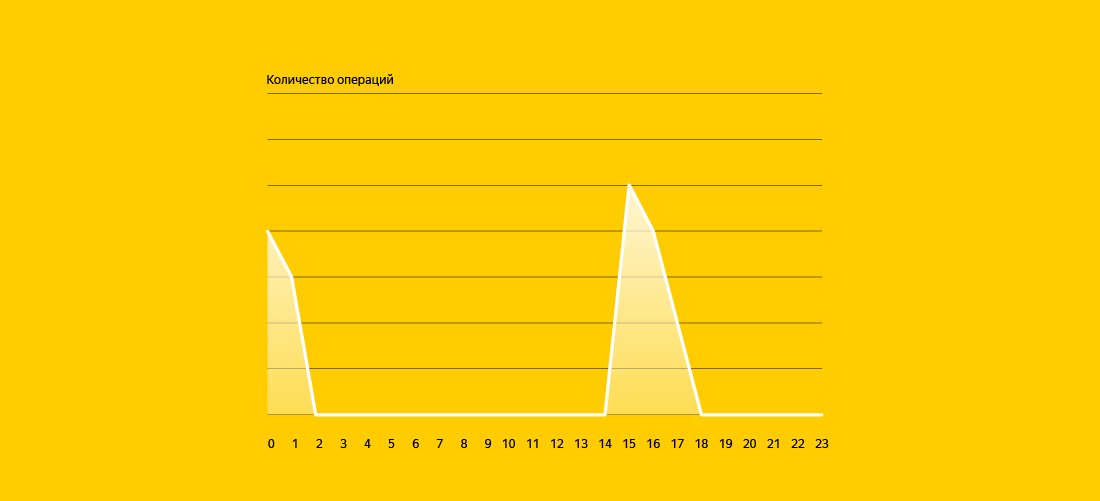
Во-вторых, должен быть набор конкретных данных, датасет, на котором мы будем пытаться ее решать. Например, есть список операций. Из него можно построить график количества операций по каким-нибудь временным периодам, например, часам:

Сам график с количеством не требует дата-сайенса, но уже требует дата-инженерии.
Не будем забывать, что помимо простых показателей, таких как количество, показатели, которые нас интересуют, могут быть достаточно сложными в получении: например, количество уникальных пользователей или факт наличия аварии в магазине-партнере (который достоверно определять силами человеческого мониторинга весьма дорого).
При этом данных с самого начала может быть много либо их в какой-то момент внезапно становится много, а в реальной жизни — они еще и продолжают непрерывно копиться даже после того, как мы сформировали для анализа какой-то датасет.
Как наверное для любой проблемы сначала стоит посмотреть, есть ли на рынке готовые решений. И во многих случаях окажется, что они есть. Например, существуют системы, которые умеют детектить простои тем или иным способом. Однако та же Moira не справлялась полностью с нашими проблемами (из коробки она ориентируется на статические правила — которыми задать наши условия достаточно сложно). Поэтому мы решили писать классификатор самостоятельно.
И дальше в статье рассматриваются те случаи, когда нет готового решения, которое полностью бы удовлетворяло возникшим потребностям, или если даже оно есть, то мы не знаем о нем или оно нам недоступно.
В этот момент из инженерной области, где что-то разрабатываем, мы переходим в RnD-область, где пытаемся изобрести алгоритм или механизм, который будет работать на наших данных.
Порядок действий в DS-проекте
Давайте посмотрим, как это выглядит в реальной жизни. Дата-сайентический проект состоит из следующих этапов:
- сбор датасета — в нашем примере это извлечение из источников истории операций,
- формулировка проблемы с позиции Data Science, определить тип задачи — классификации, регрессии или что-то другое,
- выбор модели, ее подготовка, построение и обучение,
- оценка результатов, скоринг модели — нужно выяснить, насколько хорошо она определяет аварийные ситуации, или не определяет вовсе, или только в некоторых случаях,
- обратная связь.
В идеале есть еще один заключительный шаг — выкатка в продакшн, и модель начинает работать. Однако в реальности после того, как мы построили первую модель и результаты получились не очень или вообще ничего не получилось, процесс зацикливается и круг начинается сначала:

В проектах, которыми мы занимались, один такой круг занимал по времени около 1,5–2 недель.
Дата-сайентист точно участвует на этапе построения модели и при оценке результата. Все остальные этапы чаще ложатся на плечи дата-инженера.
Теперь рассмотрим этот процесс подробнее.
Сбор датасета
Как мы сказали, без набора данных бессмысленно начинать любой Data Science. Давайте посмотрим, из каких данных получился график с количеством платежей.
В нашей компании применяется микросервисная архитектура, и в ней для дата-инженера наиболее важный момент, что нужные данные еще нигде не собраны воедино. Каждый микросервис льет свои события в брокер, в нашем случае Kafka, ETL оттуда их забирает, кладет в DWH, откуда их забирают модели.
Каждый микросервис знает только свой кусочек: один компонент знает про авторизацию, другой — про реквизиты и так далее. Задача дата-инженера — эти данные собрать в одном месте и объединить их друг с другом, чтобы получился необходимый датасет.
В реальной жизни микросервисы появились неспроста: такой атомарной операции, как платеж, не существует. У нас даже есть такое внутреннее понятие, как процесс платежа — последовательность операций для его выполнения. Например, в эту последовательность могут входить следующие операции:
- авторизация в личном кабинете,
- сбор реквизитов,
- авторизация карты,
- зачисление денег в систему,
- перевод на счет получателя,
- уведомление получателя,
- клиринг и т.д.
Из такого большого разнообразия типов событий (артефакты по каждому из которых собираются в отдельном месте) следует выбрать наиболее подходящие для наших целей действия и анализировать только их.
Действия могут быть как явно существующими в этом процессе, так и суррогатными (расчетными).
И в нашем примере мы решили, что нам будет достаточно знать два следующих шага:
- сбор реквизитов (когда человек хочет за что-то заплатить, заходит на форму и вводит реквизиты карты/кошелька),
- уведомление получателя о том, что платеж успешно прошел (это значит, что перевод на счет/зачисление денег и авторизация прошли благополучно).
На этом этапе собранные данные уже могут представлять ценность не только для главной задачи. В нашем примере уже здесь без применения ML можно брать количество процессов, прошедших каждый из этих шагов, поделить друг на друга и рассчитывать таким образом success rate.
Но если вернуться к главной задаче, то после того, как мы решили выделить эти два события, следует научиться извлекать данные из этих событий и куда-то их складывать.
На этом этапе важно помнить, что большинство моделей классификаций на входе принимает матрицу признаков (набор m чисел и n столбцов). А события, которые мы получаем, например, из Kafka, — это текст, а не числа, и из этого текста матрицу не составишь. Поэтому изначально текстовые записи нужно преобразовать в числовые значения.
Составление корректного датасета состоит из следующих этапов:
- интеграция,
- очистка,
- разметка,
- расчет фич,
- актуализация.
На этапе интеграции следует разобраться с преобразованиями и агрегациями событий. Обычно это не очень сложный процесс, но достаточно трудоемкий:
- Нужно прочитать все данные — топики, в которых содержится то, из чего мы будем составлять датасет. В зависимости от архитектуры приложений одно и то же событие может записываться в брокер событий по-разному: at-least-once, exactly-once (at-most-once не рассматриваем, так как строить аналитику на таких данных не слишком надежно). Так вот в случае at least once залитые в Kafka данные требуется отфильтровать (например, избавиться от дублей одной записи) и оставить только те события, которые реально нужно рассматривать.
- Если разные части нашего будущего датасета пишутся в разные топики, то данные, прочитанные из разных топиков, следует объединить между собой. Часто для этого нужно, чтобы в записях разных топиков были общий идентификатор.
- Из текстовых данных нужно получить числовые значения, которые в последующем мы будем анализировать.
Далее этап очистки датасета от некорректных, ненужных или ошибочных данных.
Например, в поле «дата» появился платеж 1970 года, и такую запись, скорее всего, не следует учитывать (если мы в принципе хотим использовать время как признак).
Это можно делать разными способами. Например, полностью исключить строки с неправильными значениями. Это хорошо работает, но могут потеряться остальные данные из этих строк, хотя они могут быть вполне полезными. Или, другой вариант — сделать что-то с неправильными значениями, не трогая остальные поля в этой строчке. Например, заменить на среднее или мат. ожидание по этому полю или вовсе обнулить. В каждом случае принять решение должен человек (дата-сайентист или дата-инженер).
Следующий шаг — разметка. Это тот момент, когда мы помечаем аварии как «аварии». Очень часто это самый дорогостоящий этап в сборе датасета.

Предполагается, что изначально мы знаем откуда-нибудь про аварии. Например, операции идут, затем их количество резко падает (как на картинке выше), а потом они восстанавливаются снова, и кто-то нам говорит: «Вот там и была авария». А дальше нам хочется автоматически находить идентичные кейсы.
Интереснее ситуация, когда операции прекращаются не полностью, а только частично (количество операций не падает до нуля). В этом суть детектинга — отслеживать изменение структуры исследуемых данных, а не их полное отсутствие.
Возможные неточности разметки приводят к тому, что классификатор будет ошибаться. Почему? Например, у нас есть две аварии, а размечена только одна из них. Соответственно, вторую аварию классификатор будет воспринимать как нормальное поведение и не рассматривать как аварию.
В нашем случае мы специально собираем вручную историю аварий, которую потом мы используем в разметке.
В итоге после серий экспериментов одним из решений задачи поиска простоев получился следующий алгоритм:
- Определяются граничные условия: минимальный размер выборки для расчета срезов, минимальная история, которую принимаем во внимание, коэффициент для расчета критической задержки (λ), а также трешолды для расчета аномальных значений.
- Определяется размер окна: каждый час истории операций берется с временным окном, размер которого увеличивается, пока не наберется достаточное число платежей.
- Накопив данные за нужный период, рассчитываем количество платежей в каждом окне за эту историю, и выполняем фильтрацию аномальных значений в рамках срезов: если значение, полученное в текущем окне, сильно отклоняется от медианы предыдущих значений, то считаем значение аномальным.
- Для каждого ряда рассчитываем критическую задержку — например, как величину окна, деленную на медиану + стандартное отклонение по неаномальным значениям, взятое с коэффициентом (λ).
В итоге получается датасет для дальнейшего анализа — в нашем примере, как неаномальные значения временного ряда для каждого магазина + критическая задержка. Этих данных достаточно, чтобы в реальном времени определять наличие аварий. Во многих случаях этот алгоритм работает, но чуть ниже мы опишем случаи, когда он не работает. И когда алгоритм не работает, требуется обучать классификатор — так мы переходим на следующий этап, расчет фич (feature engineering) — получение той матрицы, на которой мы собираемся строить классификатор.
И не стоит забывать про последний пункт — актуализацию данных. Особенно если проект длинный, готовится несколько недель или месяцев, то датасет может устареть. И важно, когда весь пайплайн готов, обновить информацию — выгрузить данные за новый период. Именно в этот момент становится важна роль дата-инженера как автоматизатора, чтобы все предыдущие шаги можно было дешево повторить на новых данных.
Только после этого дата-инженер передает эстафету (вместе с датасетом) дата-сайентисту.
А дальше…
Что же делает дата-сайентист?
Предполагаем, что проблема у нас сформулирована, дальше дата-сайентисту ее нужно решить.
В этой статье я не буду детально затрагивать вопрос выбора модели. Но для тех, кто только начинает работать с ML, отмечу, что есть множество подходов к выбору модели.
- Применить экспертные знания — это тот случай, когда вы знаете, какая модель в каком случае работает. Например, если у вас антифрод, то скорее всего вам нужна какая-то из моделей классификации. А если рекомендательная система, то применить коллаборативную фильтрацию. Если таких знаний нет, то можно пойти куда-нибудь, где эти модели перечислены (см. следующий пункт).
- Например, на machinelearing.ru есть целый список моделей с описанием того, что они делают и какие данные им нужны на вход. Описания в разной степени сложности (где-то можно почитать и понять с первого раза, а где-то с пятого). Помимо общего описания модели важно извлечь из такой документации, как исходные данные должны выглядеть и в каком виде модель дает ответ. Если вы, например, строите регрессию и вам нужно на выходе число, то понятно, что бинарная классификация вряд ли поможет.
- Если таким способом построить гипотезу не удалось — стоит прочитать про опыт других компаний, кто что недавно в этой области делал (например, в статьях или на конференциях/митапах).
- Ну, а если все предыдущие шаги не сработали — можно думать про разработку собственного алгоритма.
Если путем настройки гиперпараметров дата-сайентисту не удалось добиться хорошего качества работы выбранной модели, то нужно выбрать другую модель либо обогатить датасет новыми фичами — значит, требуется пойти на следующий круг и вернуться на этап расчета фич или еще раньше — на этап сбора данных. Угадайте, кто это будет делать?
Предположим, что модель выбрана, отскорена, дата-инженеры оценивают результат и получают обратную связь. Заканчивается ли на этом их работа? Конечно, нет. Приведем примеры.
Сначала немного лирического отступления. Когда я учился в школе, учительница любила спрашивать:
— А если все спрыгнут с крыши, ты тоже спрыгнешь?
Спустя какое-то время я узнал, что для этой фразы есть стандартный ответ:
— Ну… вам же никто не мешает говорить фразу, которую все говорят.Однако после изобретения машинного обучения ответ может стать более предсказуемым:
— А если все спрыгнут с крыши, ты тоже спрыгнешь?
[изобретено машинное обучение]
— Да!Такая проблема возникает, когда модель ловит не ту зависимость, которая существует в реальной жизни, а ту, которая характерна только для собранных данных.
Причина, по которой модель ловит не те зависимости, которые есть в реальной жизни, могут быть связаны с переобучением либо со смещением в анализируемых данных.
И если с переобучением дата-сайентист может побороться самостоятельно, то задача дата-инженера в том, чтобы найти и подготовить данные без смещения.
Но кроме смещения и переобучения могут возникнуть и другие проблемы.
Например, когда после сбора данных мы пытаемся на них обучиться, а потом выясняется, что один из магазинов (где проходят платежи), выглядит вот так:
Вот такие у него операции, и все другие наши размышления про падения количества операций, как признака аварии, просто бессмысленны, так как в данном примере есть периоды, где платежей нет совсем. И это нормальный период, тут нет ничего страшного. Что это для нас означает? Это как раз и есть тот случай, когда указанный выше алгоритм не работает.
На практике это частенько означает, что следует перейти к другой проблеме — не той, что мы изначально пытались решать. Например, что-то сделать до того момента, как мы начинаем искать аварии. В рассматриваемой задаче пришлось сначала привести кластеризацию магазинов по профилю: часто платящие, редко платящие, редко платящие со специфическим профилем и другие, но это уже другая история. Но важно, что это, в первую очередь, тоже задача для дата-инженера.
В итоге
Основной вывод, который можно сделать из рассказанного выше, что в реальных ML-проектах дата-инженер играет одну из важных ролей, а возможностей по решению бизнес-задач у него зачастую даже больше, чем у дата-сайентиста.
Если сейчас вы разработчик и хотите развиваться в направлении машинного обучения, то не сосредотачивайтесь исключительно на дата-сайенсе и обратите внимание на дата-инженерию.
