Как устроена наша PIM-система, и почему мы не используем ни реакт, ни микросервисы
Пара слов обо мне. У меня никогда не было серьезного плана делать свой продукт, открывать под это дело компанию, погружаться в custdev и вот это вот всё. Днем я работал в сеньёр девелопером, по вечерам — делал pet-проекты типа онлайн версии настольной игры или онлайн-редактора пиксель-арта, и все было хорошо.
Но в какой-то момент так совпало, что вопрос с жильем был решен, была накоплена финансовая подушка на пару лет и подвернулся интересный, как мне показалось, проект. Свою лепту также внес мой друг, который вложил в мою голову мысль, что со временем мы стареем, хуже учимся, труднее воспринимаем новую информацию, и чем дальше, тем будет хуже. Так что если я не хочу всю жизнь в найме провести — то вот подходящее время, когда и опыт уже есть, и силы еще есть.
В общем, мы разрабатываем PIM-систему catalog.app, и я оказался ответственным за весь процесс, начиная от общения с клиентами и формирования требований и заканчивая оптимизацией SQL запросов. В этой статье я расскажу, как наша система устроена внутри, и постараюсь обосновать, почему были выбраны именно такие подходы и инструменты, как у нас организован процесс разработки.
У нас нет кубернетеса, кликхауса, реакта, бессерверных вычислений, рэббит эмкью, кафки, кибаны, графаны, дженкинса, ноды, эластика, и много чего ещё нет. Зато есть дотнет последней версии, энтити фреймворк, нгинкс и шваггер. Я постараюсь рассказать, как и почему мы дошли до такой жизни, и жизнь ли это.
Вы не подумайте, все то, что перечислено выше и чего у нас нет, я считаю прекрасными инструментами (кроме ноды, нода ужасна), и со многим когда-то имел дело. Но любая сторонняя зависимость, а особенно инфраструктурная зависимость, имеет свою цену, и я искренне считаю, что на этом этапе развития проекта не все зависимости нам по карману. Возможно, в комментариях будет порция обоснованной критики по выбору технологий, мы постараемся к ней прислушаться.
Для начала два слова о том, что это такое — PIM-система. По своей сути это инструмент для централизованного управления информацией о товарах. Если речь идет о том, как удобно управлять каталогом, и где хранить характеристики, фотографии, видео, описания, маркетинговые материалы, инструкции — это речь про PIM. Здесь же опционально может быть информация про динамику продаж, наличие у поставщиков и на складах, закупочные цены, цены конкурентов и так далее.
Может возникнуть вопрос, а зачем нужна отдельная система, если есть Битрикс или Magento и 1С, и управление всем перечисленным выше можно организовать там? Да, можно, но тут появляются вопросы удобства, доработок, поддержки и обновления всего того, что получилось в итоге. Наверное, не зря PIM выделяются в отдельный класс, и к этому классу Битрикс и 1С не причисляют. На хабре недавно публиковался обзор PIM систем, и я очень рад, что мы в него попали.
Вернемся к нашей истории. Сначала речь не шла о разработке PIM со всеми её возможностями. Была гипотеза, что задача сопоставления товаров сама по себе может стать основой продукта, что компаниям из сферы дистрибуции и продаж нужно решать её, так почему бы не воспользоваться готовым продуктом? Через полгода такой сервис был готов, мы нашли трех платящих клиентов, внедрили наше решение. А дальше как-то все застопорилось. Сложно назвать одну конкретную причину, почему так произошло, думаю, это совокупность факторов:
У меня не было никакого опыта в поиске клиентов, продажах и продвижении. Я всю свою профессиональную жизнь до этого работал с кодом.
Сама по себе задача возникает на том уровне, на котором и решается: условно, в IT отделе компании. Отдавать свою оплачиваемую работу стороннему сервису за деньги есть не так много желающих.
Об этом этапе развития я уже писал на Хабр, там можно найти подробный разбор применяемых подходов и алгоритмов.
Несмотря на это, проект мы решили развивать, и двигаться в сторону полноценной PIM-системы. Это немного исправило положение, полноценную PIM продать проще. Давайте посмотрим, как сейчас она у нас устроена.
Общий обзор архитектуры
В этой статье я не буду рассматривать организацию кода на уровне сборок или классов, речь будет идти про более высокоуровневые вещи: сервисы, веб-приложение, API и так далее.
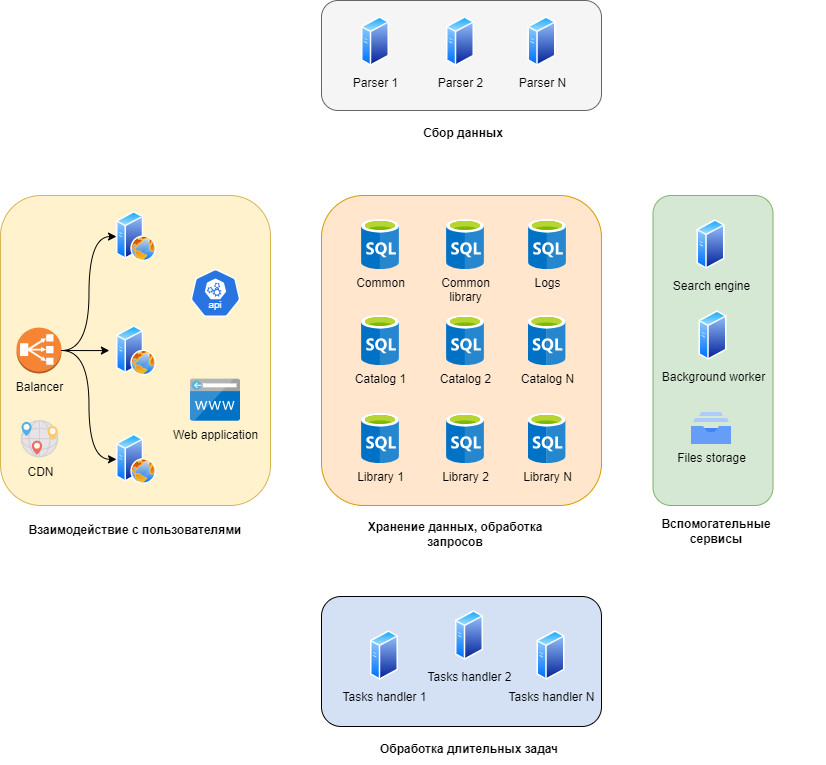
Все это требуется для работы
Я выделил девять основных подсистем с точки зрения выполняемых ими задач, и объединил их в пять групп. Какие-то из них могут почти неограниченно масштабироваться горизонтально, какие-то существуют в одном экземпляре, и параллельно работать не могут, но от них, к счастью, и не требуется (у нас никогда не будет миллиарда пользователей, например). У меня получились такие группы:
Взаимодействие с пользователями и API. Их я объединил, по сути это веб-проект, который и страницы генерирует, и API предоставляет. Сюда же включил CDN.
Сервисы по обработке длительных задач. Например, пользователь загрузил файл с миллионом записей для автоматического сопоставления, его обработка займет 5–10 минут. Эти сервисы отвечают за обработку такого типа задач. Могут масштабироваться горизонтально почти без ограничений.
Сбор данных. PIM предназначена для работы с информацией о товарах. Иногда, если система внедрена у производителя, эта информация уникальна, и по сути создается или приводится к упорядоченному виду в PIM системе. В других случаях — не уникальна, она уже есть где-то в интернете. В таком случае мы можем помочь с характеристиками товаров. Для этого мы сделали систему парсинга, к этому моменту она собрала информацию о 73 миллионах товаров с их изображениями и характеристиками.
Хранение данных. По сути — сервера с базами данных. Каждый каталог клиента хранится в отдельной базе, что позволяет масштабироваться горизонтально почти без ограничений. Единственное ограничение — один каталог не может быть распределен между разными серверами.
Вспомогательные сервисы. Например, сервис по удалению старых загруженных в систему файлов, поисковый индекс, сервис по хранению файлов.
Взаимодействие с пользователями (интерфейс)
Тут дело обстоит довольно стандартно, и в то же время довольно нестандартно. Довольно стандартно — потому что используется .NET 8 (я окончательно запутался в нумерации версий, в общем, это последняя версия веб-фреймворка от Микрософта), это достаточно популярный фреймворк. Нестандартно — потому что вопреки современным тенденциям у нас страницы рендерятся на сервере, а скрипты на клиенте просто улучшают их поведение. Из сторонних зависимостей используется jQuery с несколькими плагинами.

Пример того, как выглялит страница товара
Что нам это даёт? У нас небольшая команда из четырех человек, и каждый может делать всё. Не нужно быть специалистом по реакту, если он не используется на проекте. Поехала верстка — поправить дело условно пяти минут. Нужно добавить данные на страницу — потребуются те же условные пять минут.
Отладка тоже максимально упрощается. Весь процесс формирования страницы можно отследить в одном окне шаг за шагом.
Еще из плюсов — любая задача может выполняться одним человеком, у разработчиков нет необходимости согласовывать изменения в структуре базы данных, изменения в API и изменения на фронте, как это происходит в случае специализации каждого члена команды на чем-то одном — базе, сервере или фронте.
Минусы у такого подхода тоже есть, но мы до них не доросли ещё. Они нас настигнут, когда у нас будут тысячи клиентов, десятки тысяч пользователей и команда разработки из 30 человек, а до этого еще довольно далеко.
Для разработки API используется тот же фреймворк. Для документации и интерактивной отладки — swagger. Документация генерируется из комментариев в коде. Кстати, очень рекомендую всем, кто им по какой-то причине еще не пользуется.
Но кроме документации API нужна ещё и база знаний для пользователей. Обычно для этого используют Confluence или другой вики-движок, но мы пошли другим путем, и храним всю документацию в виде Markdown файлов в том же репозитории проекта. Из них довольно просто собирается некое подобие вики: markdown преобразуется в html, добавляется навигация, оглавление и так далее.
Такой подход закрывает несколько важных вопросов:
Документация привязана к коду. Обновился функционал на продакшене — синхронно обновилась и документация.
Доступны все функции гита для просмотра истории и контроля версий.
Разработка функций и документации к ним происходит в одной среде, не нужно переключаться на другую систему и выпадать из потока.
Не нужно администрировать стороннюю систему или сервис.
Из кода просто сослаться на документацию, сделать ссылки на нужные страницы документации на страницах сервиса.
Минусы тоже есть, все же поддерживать большую базу знаний с большим количеством перекрестных ссылок и изображений будет трудоемко и неудобно. Но — это потом, мы еще не столкнулись с такой проблемой.
В этот же блок я поместил балансир и CDN, в нашем случае это сторонние сервисы, настроенные для работы с нашей системой.
Сервисы по обработке длительных задач
Для начала немного контекста: наша система может работать с каталогами в несколько миллионов товаров. При этом часто возникают задачи, затрагивающие много товаров сразу, например, сопоставление записей из загруженного пользователем файла каталогу по нечетким признакам. Файл, при этом, тоже может содержать такое же по порядку количество строк. Алгоритм, который делает такое сопоставление, требует формирования в оперативной памяти разных оптимизированных для этой задачи структур данных. Я об этом когда-то подробно рассказывал.
Пример того, что делает алгоритм сопоставления
Тут же обрабатываются задачи по формированию больших файлов, по взаимодействию со сторонними сервисами и так далее. Например, эти сервисы должны проверять настроенные почтовые ящики на предмет новых писем, делать рассылки, обновлять данные из API маркетплейсов.
Так вот, читать все из базы, заново считать статистические характеристики токенов и строить структуры в памяти — слишком долго, чтобы делать это каждый раз, когда они понадобятся. Поэтому мы стараемся не выгружать их из памяти, пока памяти достаточно. А когда свободной памяти становится мало, то выгружаем то, что давно не использовалось. Это просто, когда сервер один.
С другой стороны, мы хотим уметь масштабировать этот сервис горизонтально, причём, процесс этот должен быть максимально простым. А если какой-то из серверов становится недоступен, то его задачи должны взять на себя другие сервера без какого-либо участия человека в этом процессе. В обоих случаях требуется, чтобы после добавления или выбывания сервера память расходовалась рационально, то есть, поисковые структуры были загружены в память в одном экземпляре. Кроме того, будет здорово, если получится обойтись минимальным пересчетом данных в памяти, то есть, чтобы перераспределение задач между серверами максимально оставляло все «как есть».
В этом и заключается задача этих сервисов — обрабатывать длительные задачи и хитро масштабироваться. Для такого масштабирования мы сами придумали и реализовали алгоритм, который всем нашим условиям удовлетворяет. Но это — тема на целую статью.
Думаю, вы уже догадались, что и тут у нас используется .NET в качестве основной технологии. И, если честно, я не вижу альтернатив.
Во-первых, это предсказуемое использование памяти и предсказуемая и управляемая скорость выполнения. Тут я имею в виду, что мы довольно точно можем сказать, что и как располагается в памяти, сколько памяти будет выделено для той или иной структуры или класса. Кроме того, сама по себе виртуальная машина .NET невероятно быстрая.
Во-вторых, хорошие и удобные инструменты по профилированию (подписка на DotTrace и DotMemory за примерно 12 долларов в месяц полностью себя окупает).
В-третьих, возможность использовать небезопасный код в узких местах. Например, нам нужно определенным образом обрабатывать изображения. Первую версию делаем на GDI+, когда понимаем, что алгоритм делает то, что нужно, но медленно — переписываем на небезопасный код и получаем ускорение в десятки раз.
В четвертых, язык C# очень приятен в использовании. На мой субъективный взгляд.
И еще, .NET позволяет разрабатывать веб-приложение, API и сервисы одинаково удобно, используя один и тот же язык и среду разработки. Для небольшой команды это важно.
Фоновый сервис
По своей сути очень похож на сервисы из предыдущего пункта, но не масштабируется.
Он занимается поддержанием проекта в рабочем состоянии: удаляет старые файлы, следит за фрагментацией индексов в базах данных и инициирует пересчет в случае чего, создает задачи для сервисов из прошлого раздела в соответствии с настроенным пользователями расписанием и так далее.
Сбор данных
Подробно об этой части я уже рассказывал в статье про то, как мы обходим блокировки Cloudflare и других сервисов по автоматическому отсеиванию роботов. Кратко напомню.
У нас есть сервис, который обходит сайты из нашего списка, для которых мы реализовали парсеры. Загружает страницу за страницей и пытается распарсить нужную нам информацию: наименование товара, его цену, характеристики, картинки. Если что-то на странице подгружается асинхронно, наш сервис тоже подгружает эти данные. Все это происходит без запуска реального браузера, этим занимается наш код с помощью библиотеки AngleSharp (рекомендую).
Но не всем нравится, когда их сайт сканируют роботы. В таком случае для отсева автоматических запросов часто используется проверка по IP и автоматическая капча. Проверка по IP, как правило, блокирует запросы от хостинг-провайдеров и пропускает запросы от интернет-провайдеров. Для её прохождения нужны резидентные (резидентный в данном случае значит, что IP адрес принадлежит подсети интернет-провайдера) прокси-серверы. А для прохождения капчи — реальный браузер, запущенный в графическом режиме, автоматизированный при помощи разработанного нами расширения. Обо всем этом подробно рассказано в упомянутой статье, там же есть ссылка на GIT, код расширения и сервиса мы выложили в открытый доступ, он доступен всем желающим.
Кроме того, нужно скачать, обработать и сохранить картинки. Обработка подразумевает их дедупликацию, подсчет перцептивных хэшей и сопутствующие задачи. Перцептивные хэши нужны для выявления похожих по содержанию изображений.
Непосредственно сбором данных, а также обработкой изображений у нас занимаются дешевые виртуалки по 4 евро за штуку в месяц, прохождением капч — более дорогие виртуальные машины в связке с пулом прокси-серверов.
Эта подсистема хорошо масштабируется горизонтально, стоит просто добавить новый сервер, и он возьмет на себя часть работы. Построено это на крайне простом принципе: каждый из серверов работает независимо, просто регулярно случайным образом берет небольшую порцию работы из очереди. Больше серверов — быстрее движется очередь, и быстрее обновляется информация.
База в этом процессе не является узким местом, работа с ней оптимизирована до простых запросов на вычитку (обычно из одной таблицы за раз с условием по первичному ключу) и batch или bulk операций на обновление и добавление данных.
Хранение данных
Для каждого каталога создается отдельная база данных. Еще по одной — для каждого аккаунта компании, это для хранения данных из приватной библиотеки. Еще одна на весь сервис — это данные общей библиотеки. И еще одна — это информация, которая не входит в контекст каталога: пользователи, сессии, настройки видимости столбцов в таблицах для каждого пользователя и так далее.
За счет такого подхода хранение данных легко масштабируется горизонтально, нам нужно просто запомнить, на каком сервере находится база данных для каждого каталога.
В качестве СУБД тут безальтернативно используется Microsoft SQL Server. Но так было не всегда, вначале вместо него был PostgreSql, но в какой-то момент мы решили сравнить производительность, благо тогда у нас еще не было обилия оптимизированных запросов, и почти все работало через Entity Framework и сгенерированные им запросы. Простое переключение на Microsoft SQL Server ускорило доступ к данным в наших сценариях работы в полтора раза.
Второй аргумент — нам потребовались bulk операции для быстрой вставки большого количества строк за раз. Для .NET был готовый драйвер для MS SQL Server, но не было для PostgreSql. Сделать его самостоятельно — я не уверен, что мы бы осилили. В чем я уверен, так это в том, что потраченное время бы бы никогда не окупили. На самом деле, это самый критичный пункт и переезд мы затеяли именно из-за него.
И третий момент: работать в SQL Management Studio и SQL Profiler было намного приятнее, чем в аналогичных утилитах для PostgreSQL.
В общем, мы взяли и довольно быстро поменяли СУБД, спасибо ORM за это. Кто тут говорил, что так никто не делает, и это сомнительный плюс ORM? Хотя, если честно, тогда мы могли себе это позволить, сейчас — уже нет, слишком много специфичных возможностей используется.
Я не говорю, что PostgreSql плох, возможно, мы не умеем как следует с ним работать.
Файловое хранилище
Операции с файлами спрятаны за интерфейсом, и нам все равно, что будет использоваться для хранения файлов. Сейчас готовы реализации для работы с локальной файловой системой, протоколами WebDAV и SMB/CIFS. В принципе, можно и проприетаренное API интегрировать.
В общем, что в app.config указано, то и будет использоваться. При разработке на локальном компьютере обычно используется локальная файловая система, на продакшене — арендуем файловое хранилище как сервис, работаем с ним по WebDAV и SMB/CIFS. Почему с двумя сразу — не буду вдаваться в делали, но в двух словах, у нас бывают разные сценарии работы с файлами, и где-то лучше справляется один, где-то другой протокол.
Поисковый движок
И про него я уже подробно писал. Его мы разработали сами и оптимизировали именно для наших задач. Сейчас, спустя два года, могу сказать, что подход полностью оправдался, нечеткий поиск по 73 миллионам товаров работает почти мгновенно (десятки миллисекунд), а у сервера аптайм уже, похоже, больше года.
Посмотреть в работе можно без регистрации: мягкая игрушка гусь 160 см
Реализация при этом заняла один день, потом было сделано только несколько небольших изменений, на это еще один-два дня в сумме потребовалось.
Интеграции
Это — самая большая боль и проблема. PIM системе крайне необходимы интеграции с другими системами, и среди них — Ozon и Wildberries. Эти двое отняли от трети до половины всего времени, потраченного на разработку всей системы. Именно благодаря им я научился строить сложносочиненные и сложноподчиненные предложения без единого цензурного слова.
Логирование
Систему логирования я выбирал еще тогда, когда работал над проектом один. У меня в голове было несколько требований к ней:
Автоматическое объединение логов, связанных одним контекстом. В нашем случае это может быть обработка http запроса, работа над длительной задачей, одна итерация работы фонового сервиса.
Доступ через веб-интерфейс с возможностями поиска, фильтрации и так далее.
Скорость работы. Логирование не должно тратить много ресурсов. Сбои в логировании не должны приводить к ухудшению отзывчивости основной системы.
Желательно — библиотека, а не отдельный сервис.
В общем, систему логирования я написал сам. С тех пор нам всего пару раз пришлось там что-то незначительно менять.
Заключение
Я не затронул тему организации процесса разработки и взаимодействия в команде, а также вопросы обновления версий и организации бекапов, об этом расскажу в другой раз.
Труднее всего — понять, что делать и как это продавать. На нашем этапе развития самое важное заключается в том, что технологии должны позволять быстро «пилить фичи» и подстраиваться под рынок. К этому можно подступиться по-разному, у нас в команде мы выработали подход, при котором каждый может сделать любую задачу.
Для этого нам пришлось максимально упростить процесс разворачивания и отладки проекта. Почти каждый сценарий можно повторить и пройти по шагам, не покидая окно Visual Studio. Поэтому мы не используем микросервисы, брокеры сообщений, шины данных и прочие инфраструктурные зависимости: они мешают отладке, они выбивают из потока, всем нужно держать в голове известные особенности их работы, и разбираться, столкнувшись с неизвестными.
Чтобы начать работать над проектом с нуля на новом компьютере, достаточно поставить SQL Server, забрать из гита последнюю версию кода, собрать проект, зайти в админку и нажать на кнопку для создания нужных проекту баз данных.
Другое, не менее важное, следствие заключается в том, что можно быстро и просто развернуть коробочную версию, и сделать это можно почти на любом оборудовании, и при этом без зависимостей от сторонних сервисов.
Пока нам такой подход не мешает развивать проект. А когда начнет мешать — я буду очень рад, правда. Это будет означать, что более важные вопросы — вопросы продвижения, продаж и финансовой модели так или иначе решены.
