Как свести проблемы в инфраструктуре облачного сервиса к нулю?
Как известно, управление сложным космолетом невозможно без нормальной приборной панели. Совсем недавно мы уже рассказывали, об эволюции инфраструктуры нашей облачной help desk системы Okdesk, которой пользуется каждый день более 800 компаний и о том, как она вообще устроена и почему мы выбрали именно такой подход.
В этой статье мы впервые поделимся «внутрянкой» того, как у нас построены процессы мониторинга, которые позволяют не только постоянно держать руку на пульсе, но и оставаться нашему решению одним из самых стабильных и безбажных на рынке.

Как построен мониторинг? Прописные истины
В первой статье мы писали о том, что в части инфраструктуры, да и реализации сервиса в целом, пытаемся идти на шаг впереди — реагировать на возможные проблемы до того, как их заметят клиенты. Задача не в том, чтобы тушить пожары, а в том, чтобы предсказывать их и предотвращать, до того, как клиенты начнут про это писать. Об этом даже в ITIL написано достаточно (кстати, тут мы подробно писали, какая от него польза и есть ли она вообще). Очень простая мысль, но проблема прописных истин в том, что их все знают, но не многие им следуют. Таким образом при построении мониторинга перед нами стояло две цели:
мы должны максимально быстро заметить происходящее, если что-то начинает деградировать;
нам хочется как можно быстрее понять, в чем причина — какой из компонентов инфраструктуры и почему сбоит. В идеале нужно диагностировать и исправить проблему до того, как ее заметит клиент.
Чтобы мониторинг действительно решал эти задачи не на словах, нужно уметь смотреть на сервис в разных плоскостях. Для этого требуется много инструментов и мы действительно внедрили сочетание принципиально разных подходов — и тех, что смотрят внутрь приложения, и тех, что тестируют снаружи по принципу «черного ящика». Постарались обложить все метриками — прямыми и косвенными, нативными и синтетическими, чтобы при любой нештатной ситуации получать уведомление. А кроме того наблюдаем за происходящим в ручном режиме, чтобы не пропустить негативные тенденции, еще не описанные метриками.
Мы понимаем инструментов не должно быть слишком много, иначе в них можно запутаться. И хотя набрали целый пул сервисов, выработали типовые подходы для каждого из возможных случаев. К примеру, срабатывает мониторинг — допустим, запросы выполняются медленно. Ты пробегаешь по основным метрикам. Видишь, что база отвечает нормально и сразу отбрасываешь ее из рассмотрения — дело не в базе. С помощью другого инструмента выделяешь, какой тип запроса тормозит и так далее.
Наша система мониторинга не стационарна. Каждый новый инцидент дает нам почву для размышлений о том, что можно в ней улучшить, так что мы продолжаем экспериментировать. Но несколько основных инструментов у нас уже прижились окончательно. О них и поговорим.
Мониторинг внутри приложения
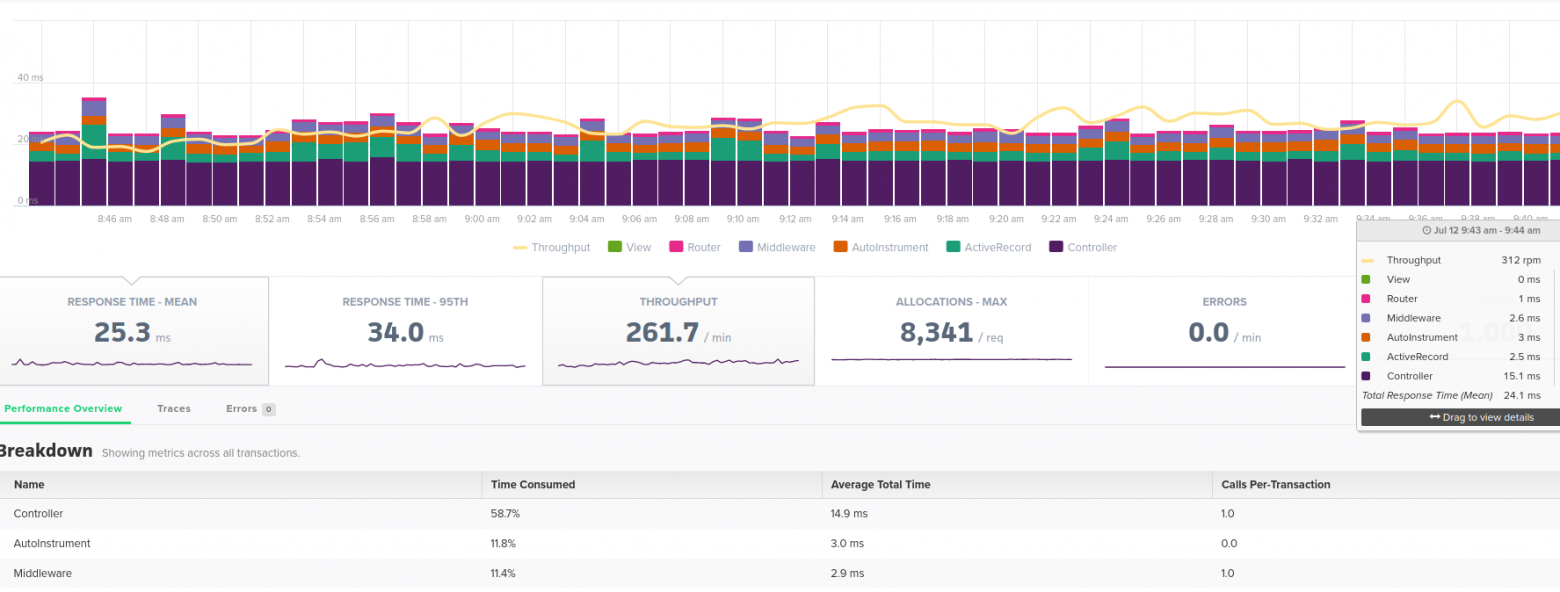
За метриками внутри приложения мы наблюдаем с помощью Scout APM. Инструмент позволяет разобраться, что пошло не так. Без мониторинга такого уровня фактически невозможно решать проблемы производительности, связанные с работой кода приложения.
Scout APM позволяет видеть на графиках, насколько быстро работают те или иные страницы. Можно детализировать: что именно сейчас работает медленно и как это менялось исторически — он в буквальном смысле отображает, сколько времени требуется на загрузку списка заявок (а он в Okdesk невероятно функциональный и удобный), сколько он отрисовывается, сколько уходит на обращение к БД и т.п. Инструмент позволяет в буквальном смысле разложить процесс по строкам кода — сколько каждая из них выполнялась и почему. Так после выкатки очередной версии можно увидеть, что новая фича тормозит, и разобраться почему (после деплоя мы всегда смотрим, нет ли явных отклонений по производительности).
Инструмент помогает увидеть проблему в момент нарастания, а не когда все уже перестало работать. Это позволяет решить проблему до того, как ее заметят клиенты. Например, у нас был случай, когда прервалась связь между основным и резервным дата-центром, что должно было привести к замедлению работы основной БД, но мониторинг вовремя подсказал, что у нас проблемы, и мы успели с ними справиться.
В предыдущей статье мы отмечали, что используем архитектуру мастер — слейв БД, при этом мастер размещен в основном датацентре, а слейв — в резервном. Изменения вносятся в мастер БД и постоянно отправляются на слейв. При обрыве соединения между основным и резервным дата-центрами данные записываются в буфер мастер БД, который через пару часов начинает переполняться и «тормозит» всю мастер БД. Мы заметили это до того, как клиенты почувствовали на себе.
Scout APM — это аналог New Relic, поддерживающий используемый нами в разработке Ruby. Начали строить систему мониторинга мы около 5 лет назад (то есть как раз, когда количество клиентов стало измеряться несколькими десятками), и уже тогда NewRelic был слишком дорог — тысячи долларов в месяц на наших масштабах. Это действительно мощный инструмент, но если можно так выразиться, он несоразмерен нашим задачам. В то же время Ruby поддерживает не так много других систем, так что выбор в целом был небольшой. Scout APM нам понравился. Он также платный и имеет платную техподдержку, однако цена для нашего технологического стека оказалась на порядок меньше.

Мониторинг снаружи
Работу серверов на более низком уровне мы контролируем с помощью Okmeter. Этот инструмент использует наш инфраструктурный подрядчик Флант. Кстати, в прошлом году Флант купил эту компанию целиком (дополнительный плюс, кроме созвученного с Okdesk названия у этого решения еще в том, что, как и мы, это российская разработка с командой внутри страны, т.е. геополитические риски минимальны).
Okmeter — относительно несложный и очень наглядный. Его можно настроить под себя.
С точки зрения Okmeter метрика — это некоторый критерий (иногда сложный), который нужно отслеживать.
Типовые примеры — потребление памяти или процессора сервером. Менее типовые примеры — имитация открытия пользователям браузера, входа в Окдеск, успешность поочередного открытия всех страниц и т.п. Сами проверки реализованы у нас через ручной скрипт, но Okmeter отображает алерты, если работа скрипта завершилась нештатно.
Мы используем и некоторые специфические метрики, связанные с особенностями нашего сервиса, например по нашим представлениям новая заявка в системе должна появляться каждую минуту. Если этого не происходит, то это косвенно говорит о проблемах в сервисе, т.е. необходимости отправить алерт.
Okmeter шлет уведомление вместе с описанием в корпоративный Slack.

Для отображения результатов мониторинга используется Grafana — ее применяем и мы сами, и Флант. Grafana — мощный инструмент, который позволяет собирать огромное количество метрик с разных уровней инфраструктуры: как с физического (состояние серверов, загрузка сети и так далее), так и с уровня kubernetes. В ней можно настроить собственные панели, чтобы следить за нужным набором метрик на одном экране. Кроме того, это open source проект, который очень активно развивается и отлично интегрируется с различными системами.
Мы стараемся выстроить максимально дублированную систему мониторинга, поэтому дополнительно используем сервис ping-admin.ru. Он не раз нас выручал.
Это достаточно простой инструмент, который умеет делать запросы на заданные пути и сверять возвращенный результат с ожидаемым. Прелесть такого подхода в том, что проверка идет по принципу черного ящика: запрос как-будто выполняет пользователь. Не важно, что там сейчас внутри происходит, ответы на внешние запросы должны быть стабильными. А если ответ не приходит в течение заданного времени, сервис умеет автоматически слать SMS или звонить тимлидам и нашему техническому директору.
По закону подлости, происходит это обычно ночью или в праздничные дни. К примеру, крупный клиент решает протестировать нечто, интегрированное с нашей системой, миллионом запросов в секунду. Или пытается сгенерировать очень объемный отчет (у нас это происходит в асинхронном режиме). И нам приходится разбираться.

Реакция на инциденты
Сообщения о проблемах поступают к нам не только от мониторинга, но также от техподдержки. Иногда нам пишет подрядчик по инфраструктуре — Флант. У них есть свои метрики и свой агрегатор для их сбора с разных инструментов. Они пишут нам в Slack, если видят проблему, которая не имеет отношения непосредственно к инфраструктуре.
Первую реакцию на все эти обращения обеспечивает техподдержка, которая в нашем случае разделена на несколько линий.
Линия L1
Первая линия — это фронт, который принимает обращения клиентов и первым сталкивается с алертами мониторинга. Фактически, у нас работает две первых линии:
L1 Okdesk работает через клиентский портал Okdesk (конечно же, мы сами используем свой замечательный софт) только с клиентами системы — обрабатывает входящие заявки;
L1 подрядчика по инфраструктуре не взаимодействует с клиентами, но видит алерты от мониторинга.
Работа с клиентами
Взаимодействие первой линии с клиентами Okdesk — тема для отдельной статьи и мы не будем подробно рассматривать здесь все практики. В контексте системы мониторинга важно, что мы стараемся дать первой линии больше инструментов, чтобы максимальное количество обращений можно было решить без эскалации.
Каждую неделю у нас есть ретроспектива с техподдержкой, где мы разбираем все задачи, которые уходили на последующие линии. Цель — понять, могли ли мы предоставить какие-то инструменты, чтобы проблема решилась без перевода на следующие линии. В некоторых случаях в интерфейсе техподдержки достаточно добавить какую-нибудь кнопку, которая что-то меняет у пользователя, или дать доступ к определенным данным мониторинга. Благодаря этому первая линия не только фиксирует существование проблем, но может часть из них устранить.
Реакция на алерты мониторинга
Наш инфраструктурный подрядчик Флант предоставляет дежурных 24/7 (работают посменно), которые следят за появлением алертов. Для них каждый алерт имеет свои метки срочности и своего рода «протокол реагирования» (сколько ждать, кому звонить). Например, если проблема помечена как критическая, касается приложения, а не инфраструктуры, и не может быть решена сразу, дежурный зовет инженера из Фланта и оповещает нас.
Линия L2 / L3
Проблемы с уровня L1 эскалируются в L2/L3. Эти линии поддержки на связи 24/7, но не обязаны все это время присутствовать онлайн.
Как и в случае с L1, часть проблем решает наша команда разработки, а часть — команда подрядчика. Это зависит от характера проблемы: в инфраструктуре или в программное коде. Иногда мы объединяемся, если проблема на стыке работы приложения и инфраструктуры.
На этом уровне находятся квалифицированные инженеры, которые обладают знаниями, чтобы оперативно диагностировать или решить большинство проблем.
Дежурные
Некоторое время назад мы ввели у себя практику дежурных инженеров. Возможно, мы подсмотрели ее у нашего подрядчика — Фланта, хотя идея на самом деле витает в воздухе.
Дежурный инженер — это специалист, который условно в течение суток разбирает все запросы от L1. Это сделано затем, чтобы снять нагрузку с других членов команды. Таким образом только один человек в течение дня постоянно переключает контекст, другие могут сосредоточиться на плановых задачах.
До явного выделения этого статуса роль дежурного инженера всегда была у одного человека — технического директора. Но с ростом количества запросов его стало не хватать на основные задачи, поэтому нагрузку решили распределить. В итоге каждый дежурит один день на неделе и планирует свою деятельность соответственно.
Когда мы только вводили идею дежурных, от L1 сваливалось порядка 20 — 25 обращений в неделю. И хотя количество пользователей Okdesk продолжает расти, за 1.5 года мы свели это количество в среднем к 5 обращениям в неделю (а иногда и меньшему количеству) — ретроспектива с поддержкой приносит осязаемые плоды. Т.е. дежурному приходится оторваться в среднем один раз в день.
Помимо ответов на вопросы, дежурный в целом следит за ситуацией У него постоянно открыты основные вкладки мониторинга. Периодически туда надо заглядывать, чтобы проконтролировать, все ли в порядке. Это ручная работа, но иногда автоматические алерты срабатывают не совсем корректно. Заглядывать на эти вкладки достаточно раз в полчаса.
Линия L4
Наиболее сложные проблемы эскалируются на L4. Здесь их решают узкие специалисты, например отдельная команда по PostgreSQL или команда разработки Deckhouse (часть Фланта), к которым мы обращаемся за консультациями в случае нерешаемых на нашей стороне проблем. Эти инженеры, как правило, знакомы с исходным кодом продуктов и могут разобраться с самой сутью проблемы.
Обычно для таких проблем нет быстрого решения. Требуется исследование / разработка / доработка программных продуктов. В этом случае решения проходят полный цикл: разработка, ревью, тестирование.
В целом система мониторинга дает нам полную картину происходящего. По примеру других компаний мы рассматривали возможность повесить в офисе экран с основными показателями, но отказались от этой идеи. Даже самые красочные картинки, к сожалению, могут примелькаться. Потребуется что-то совсем из ряда вон выходящее, чтобы через месяц — другой сотрудники обратили внимание на экран. Вероятно, это часть наблюдения за системой, которую лучше не автоматизировать.
По мере роста клиентской базы мы корректируем старые метрики и вводим новые.
Пишите в комментариях, если вам интересно узнать о том, за какими именно параметрами мы наблюдаем.
p.s. если вам интересно в режиме online посмотреть за тем, как сотни компаний работают в Okdesk, а может быть даже по некоторым метрикам сравнить работу вашей техподдержки, то специально для этого мы совсем недавно запустили спец.проект на основании нашей big data — «Сервисный пульс».
