Как можно применить генерацию изображений в химии для предсказания наноматериалов
Когда я со своими коллегами с направления Химия и ИИ начинал делать этот проект, в мире был в самом разгаре интерес к таким системам генерации изображений как Stable Diffusion, DALL-E и Midjourney. Именно тогда мы решили совместить модели обработки естественного языка (такие как BERT) и системы генерации изображений и применить все это в химическом домене.
В итоге мы создали прототип системы, которая может из методики синтеза какого-либо наноматериала генерировать его изображение, которое обычно получают с помощью сканирующего электронного микроскопа.
Этот кейс будет интересен даже людям никак не связанным с химией, так как я дам всю необходимую вводную информацию. Приятного прочтения!

Для начала я отвечу на несколько важных вопросов, которые могут возникнуть.
Чего мы хотели достигнуть?
Мы хотели создать систему, которая позволяет взять методику синтеза наноматериала, например из какой-нибудь научной публикации и залив текст методики в нашу систему сразу же получить изображение данного наноматериала. На практике можно написать методику и самому, а можно просто менять уже существующую, пока на изображении мы не увидим желаемый результат.
Почему же мы взялись за эту задачу?
На данный момент создание и анализ наноматериалов это долгий процесс, требующий дорогого оборудования. При этом часто возникает необходимость получить наноматериал с какими-то определенными характеристиками, который раньше никто не получал, а какого-то гарантированного способа понять как это сделать не существует.
Как сейчас создают наноматериалы с нужными свойствами?
На данный момент ученые делают десятки экспериментов, многие из которых не приводят к нужным результатам. При этом каждый раз мы должны проанализировать наш наноматериал с помощью сканирующего электронного микроскопа, что само по себе требует немало усилий.
Почему вообще создают наноматериалы с определенными свойствами?
Часто такие параметры как размер и форма наноматериала определяют более глобальные свойства, такие как токсичность, распределение в организме, оптические свойства и другие. Все эти свойства важны, если мы планируем применять наноматериал в медицине, электронике, промышленности и так далее.
Теперь перейдем к тому, чем мы занимались.
Немного о датасете
Для начала, мы решили разработать эту систему используя наш собственный датасет, полученный из более 200 экспериментов по синтезу наночастиц карбоната кальция.
Не буду рассказывать подробно про синтез и анализ с помощью сканирующего электронного микроскопа, но в результате, для каждого эксперимента было получено изображение по которому можно впоследствии увидеть форму и размер наночастиц. Вот несколько подобных изображений.
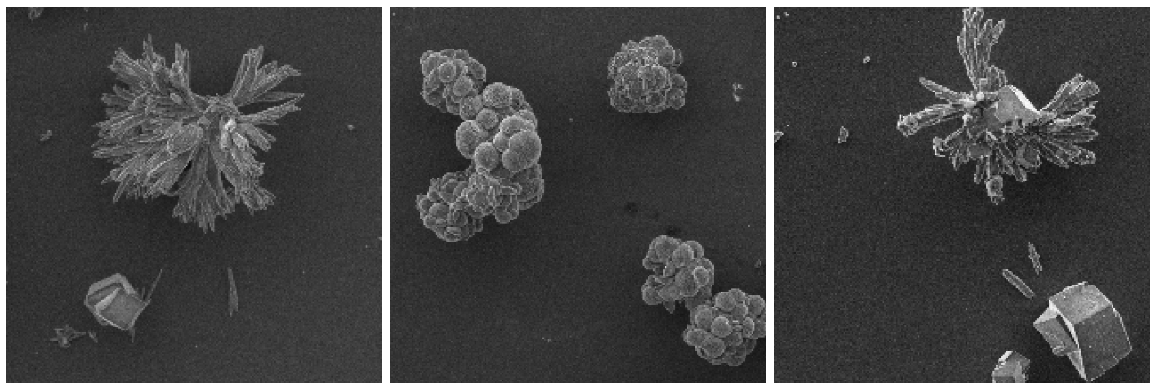 Пример изображений наночастиц из датасета
Пример изображений наночастиц из датасета
Помимо картинок у нас также была структурированная информация о синтезе, которая находилась в специальной таблице. В ней были выписаны такие параметры, как концентрации и названия различных используемых в синтезе веществ, температура, время реакции и так далее.
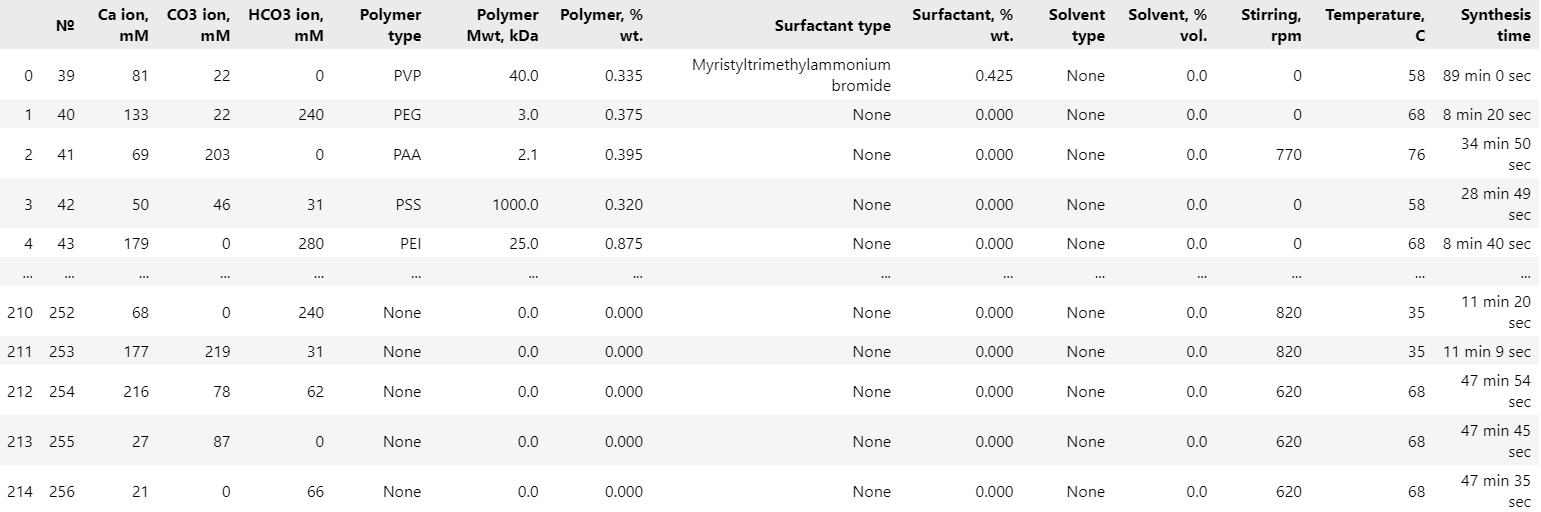 Таблица с данными синтезов
Таблица с данными синтезов
Предобработка данных
Далее, полученные нами экспериментальные данные необходимо было обработать.
Предобработка изображений
У нас было всего 215 картинок с микроскопа и этого явно недостаточно для обучения любой системы генерации изображений. Однако самих наночастиц на данных картинках значительно больше, остается только сегментировать изображения (то есть разделить каждое изображение на составные части, а именно наночастицы) и получить из них индивидуальные изображения наночастиц.
Для этого было решено использовать программу ImageJ, в которой как раз оказалась функция, позволяющая сегментировать частицы.
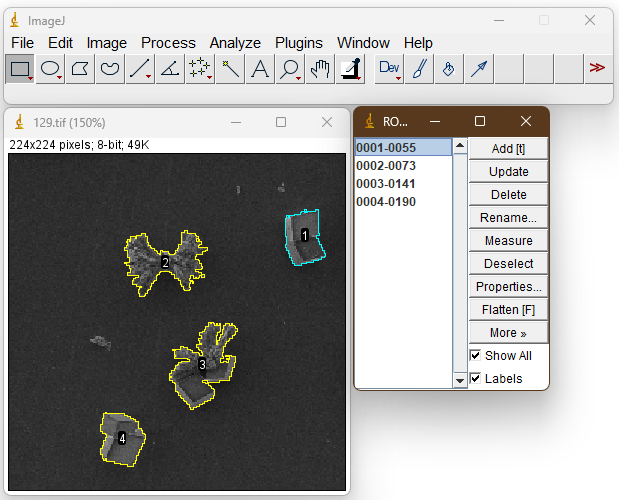 Интерфейс программы ImageJ
Интерфейс программы ImageJ
После написания небольшого скрипта в ImageJ удалось получить изображения более 1000 наночастиц, каждая из которых находилась на черном фоне.
 Пример изображений сегментированных наночастиц
Пример изображений сегментированных наночастиц
После сегментации было получено чуть больше 1000 изображений индивидуальных наночастиц, однако для систем генерации изображений такой датасет будет не очень большим, к тому же чаще всего фотографии со сканирующего электронного микроскопа отличаются друг от друга по яркости, контрасту, резкости и другим характеристикам.
Также частицы могут находиться во всех возможных ориентациях на фотографиях и это тоже стоит учесть. Поэтому было решено увеличить наш датасет за счет аугментации (то есть создания новых данных из уже имеющихся). Был написан скрипт, который поворачивает исходное изображение на углы, кратные 45°, пример изображений представлен ниже.
 Все возможные варианты поворота изображений в нашем датасете
Все возможные варианты поворота изображений в нашем датасете
Далее были применены другие модификации ко всем изображениям, а именно два уровня шума, размытие и увеличение резкости. Примеры представлены ниже в том же порядке.
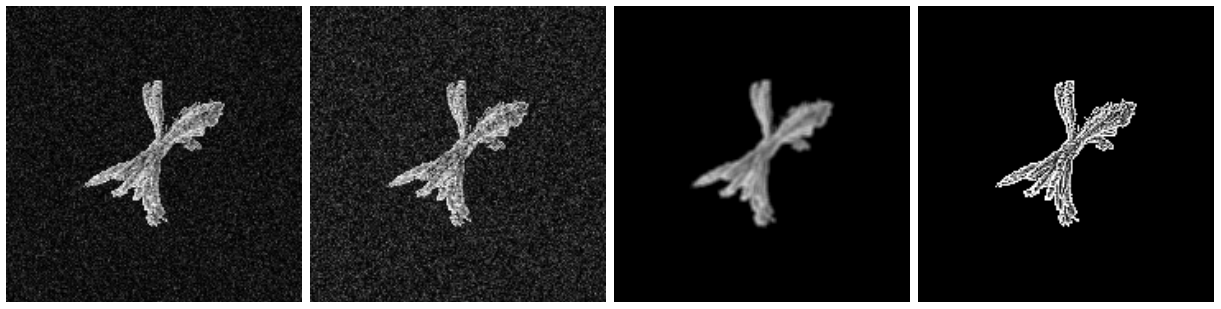 Различные аугментации наших изображений
Различные аугментации наших изображений
После всех преобразований был получен датасет, состоящий из 40000 изображений. Для начала этого достаточно. Теперь перейдем к предобработке текста.
Предобработка текста
Как уже говорилось ранее, для каждого эксперимента у нас были значения в виде таблицы для концентраций всех реагентов, их названий, температуры и других параметров, однако в рамках нашей концепции на вход модели должен подаваться текст синтеза наноматериала, так как текст понятен любому, легко изменяем и часто такие тексты встречаются в литературе.
Решением данной проблемы, на котором мы остановились, было использование семантических шаблонов, то есть текстов, описывающих синтез наноматериала, которые имеют пропуски в тех местах, куда мы будем заносить наши табличные значения.
Выглядели наши шаблоны примерно следующим образом.
All the materials were synthesized by the co-precipitation technique. First, {ca_conc} mkl of 1 M CaCl2 was mixed with {pol_vol} mkl of {pol_conc} % wt. {polymer} polymer with molecular weight of {pol_mass} kDa. Then, {solvent_volume} mkl of {solvent} was added, following adjustment with distilled water up to 500 mkl. Then, {co3_conc} mkl of 0.1 M Na2CO3 was mixed with {hco3_conc} mkl of 0.1 M of NaHCO3 and {surf_vol} mkl of {surf_conc} % wt. {surfactant} as surfactant. Then, {solvent_volume} mkl of {solvent} was added, following adjustment with distilled water up to 500 mkl. Two resulting solutions, heated up to {r_temp} C before the reaction, were mixed under the stirring with {stir_ratio} rpm, while the temperature kept unchanged. Reaction proceeded for {r_time} min following centrifugation.
Таких шаблонов у нас было не так много, но они достаточно сильно друг от друга отличались, при этом сохраняя все детали синтеза. После этого мы заполняли каждый значениями из таблицы. В результате получалась полноценная методика синтеза, которые часто именно в такой форме и встречаются в публикациях.
All the materials were synthesized by the co-precipitation technique. First, 320.2 mkl of 1 M CaCl2 was mixed with 84.0 mkl of 2.2% wt. PAA polymer with molecular weight of 16455 kDa. Then, 165.6 mkl of tert-butanol was added, following adjustment with distilled water up to 500 mkl. Then, 21.5 mkl of 0.1 M Na2CO3 was mixed with 32.4 mkl of 0.1 M of NaHCO3 and 16.9 mkl of 26.0% wt. hexadecyltrimethylammonium bromide as surfactant. Then, 165.6 mkl of tert-butanol was added, following adjustment with distilled water up to 500 mkl. Two resulting solutions, heated up to 37 C before the reaction, were mixed under the stirring with 494 rpm, while the temperature kept unchanged. Reaction proceeded for 44 min following centrifugation.
Таким образом заполняя шаблоны значениями из таблицы можно было получить текстовое описание для каждого изображения. На схеме ниже описан весь процесс создания нашего датасета.
 Схема создания датасета
Схема создания датасета
Создание генеративной модели
Итак, когда в нашем распоряжении были 40000 пар текстов синтезов и изображений наночастиц, мы приступили к разработке самой модели. Этот процесс состоял из двух основных частей, а именно обработка текстов и генерация изображений.
В данной статье основной фокус направлен на данные, так как пока что это была основная часть нашей работы. Поэтому я не буду сильно углубляться в сами системы, по крайней мере в этой статье.
Для начала мы решили использовать легкие в использовании предобученные модели обработки естественного языка, например BERT. Подобные модели можно скачать с помощью библиотеки Hugging Face Transformers. Их можно применять для различных задач, таких как классификация, предсказание следующего предложения и так далее.
Для того, чтобы применять BERT, необходимо провести токенизацию текста, это процесс, который переводит слова в вашем тексте в специальные токены, с которыми работает BERT.
После того, как текст проходит через BERT каждый токен превращается в вектор длины 768. При этом в начале каждого текста на этапе токенизации также добавляется специальный токен [CLS]. Из этого токена также получается вектор и именно он содержит общую информацию о предложении для задач классификации.
Для начала мы решили использовать именно этот вектор и после того, как все наши тексты прошли через BERT наш датасет превратился в набор векторов и картинок.
На последнем этапе мы обучили генеративно-состязательную сеть для того, чтобы она создавала изображения основываясь на векторе, который мы получили на предыдущем этапе. Пока что эта система генерирует изображения вот такого вида:
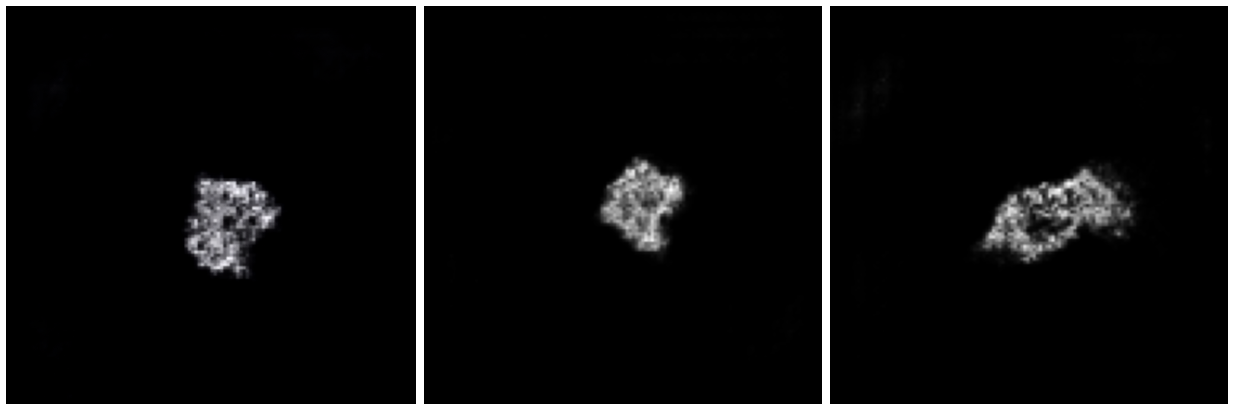 Изображения, сгенерированные нашей системой
Изображения, сгенерированные нашей системой
Заключение
На данный момент у нас есть все основные системы, которые планировалось создать в данном проекте для того, чтобы доказать, что что-то подобное вообще осуществимо, однако нам предстоит сделать более продвинутую систему генерации изображений, создать метрики для ее проверки и объединить все эти системы для удобство в одну большую модель. Уже сейчас можно создать вектор, соответствующий реальному тексту и преобразовать его затем в картинку, по которой можно различить форму и размер наночастицы, однако планируется сделать так, чтобы картинки стали более красивыми и точность генерации была подтверждена как с помощью различных метрик, так и экспериментально. В следующих статьях я планирую рассказать более подробно про алгоритмы обработки естественного языка и системы генерации, над которыми мы сейчас работаем.
Спасибо за внимание!
