[Перевод] Управление производительностью с Python 3.12
В Python 3.12 появилась поддержка perf profiling. В этой статье рассмотрим, как это помогает сократить время выполнения Python-скрипта с 36 секунд до 0,8. Мы рассмотрим Linux-инструмент perf, а также графики Flame Graph (добавить пояснение: способ визуализации процессорного времени, потраченного на функции), посмотрим на дизассемблированный код и займемся поиском ошибок. Код из статьи можно посмотреть здесь.
Загляните на соответствующую страницу официальной документации Python и в список изменений. Для этой статьи из документов по ссылкам выше важно следующее:
Профилировщик perf для Linux является мощным инструментом, который позволяет профилировать и получать информацию о производительности приложения. У perf богатая экосистема инструментов, которые помогают с анализом данных, которые он производит.
Основная проблема при использовании профилировщика perf с приложениями Python состоит в том, что perf позволяет получить информацию только о нативных символах, то есть об именах функций и процедур, написанных на C. Это значит, что имена и названия файлов функций Python в вашем коде в выводе perf не появятся.
Начиная с Python 3.12, интерпретатор может работать в специальном режиме, который позволяет функциям Python появляться в выводе профилировщика perf. При включенном режиме интерпретатор вставляет небольшой фрагмент кода, скомпилированный на лету, перед выполнением каждой функции Python и обучает perf взаимосвязи между этим фрагментом кода и связанной с ним функцией Python с помощью файлов perf map.
Написание «плохой» программы
Давайте приступим. Для начала создадим Python-скрипт для профилирования. Я делаю это до установки Python 3.12, поскольку хочу визуализировать и сравнить с помощью Flame Graph то, как этот процесс выглядит в версиях 3.10 и 3.12. Вот скрипт, который выполняет поиск в большом списке:
import time
def run_dummy(numbers):
for findme in range(100000):
if findme in numbers:
print("found", findme)
else:
print("missed", findme)
if __name__ == "__main__":
# создать входные данные большого размера, чтобы продемонстрировать
неэффективность
numbers = [i for i in range(20000000)]
start_time = time.time() # текущее время [начало]
run_dummy(numbers) # запустить наш неэффективный метод
end_time = time.time() # текущее время [конец]
duration = end_time - start_time # вычислить продолжительность
print(f"Duration: {duration} seconds") # вывести продолжительность на экран
Запуск скрипта дает следующий результат:
python3.10 assets/dummy/perf_py_proj/before.py
...
found 99992
found 99993
found 99994
found 99995
found 99996
found 99997
found 99998
found 99999
Duration: 36.06884431838989 seconds36 секунд недостаточно для того, чтобы собрать необходимое количество сэмплов.
Flame Graph
Теперь создадим Flame Graph:
# запись профиля производительности в файл "perf.data" (вывод по умолчанию)
perf record -F 99 -g -- python3.10 assets/dummy/perf_py_proj/before.py
# прочтение perf.data (созданного выше) и отображение вывода трассировки
perf script > out.perf
# сложим стеки в одну линию
# здесь я ссылаюсь на ~/FlameGraph/ - лежит по адресу https://github.com/brendangregg/FlameGraph
~/FlameGraph/stackcollapse-perf.pl out.perf > out.folded
# генерация flamegraph
~/FlameGraph/flamegraph.pl out.folded > ./assets/perf_example_python3.10.svgПолучаем красивый SVG с визуализацией данных:
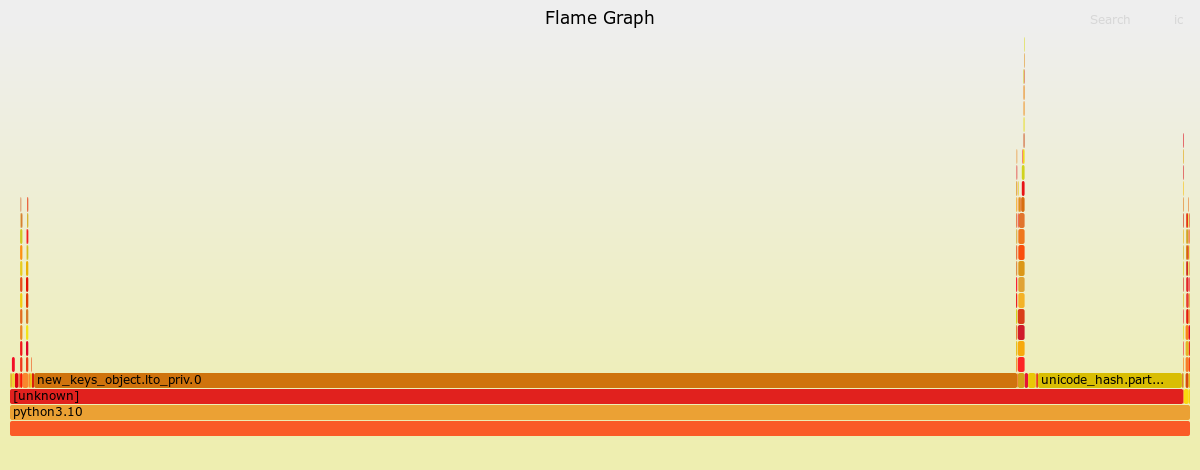
Я вижу, что большая часть времени была потрачена на «new_keys_object.lto_priv. 0», но это не несет смысла в контексте кода.
Настало время для Python 3.12
Для начала установим. Шаги установки различаются в зависимости от ОС. Следуйте инструкциям по сборке для вашей среды.
# для ubuntu:22.04
# убедимся, что я установил python3-dbg
sudo apt-get install python3-dbg
# сборка python
export CFLAGS="-fno-omit-frame-pointer -mno-omit-leaf-frame-pointer"
./configure --enable-optimizations
make
make test
sudo make install
unset CFLAGS
# после этого я сбросил символьную ссылку python3 на 3.10, так как 3.12 еще не стабилен
# для тестирования python3.12 я буду называть «python3.12» вместо «python3»
ln -sf /usr/local/bin/python3.10 /usr/local/bin/python3После установки нужно включить поддержку perf. В документации предлагается три возможных варианта: 1) переменная среды, 2) параметр -X или 3) динамическое использование sys. Я выберу подход с переменной среды, поскольку я за то, чтобы все было профилировано с помощью небольшого скрипта:
export PYTHONPERFSUPPORT=1Теперь мы просто повторяем описанный выше процесс, используя вместо этого собранный python3.12:
# записать профиль производительности в файл "perf.data" (вывод по умолчанию)
perf record -F 99 -g -- python3.12 assets/dummy/perf_py_proj/before.py
# прочитать perf.data (созданный выше) и отобразить вывод трассировки
perf script > out.perf
# сложим стеки в одну линию
# здесь я ссылаюсь на ~/FlameGraph/ - который можно найти по адресу https://github.com/brendangregg/FlameGraph
~/FlameGraph/stackcollapse-perf.pl out.perf > out.folded
# генерация flamegraph
~/FlameGraph/flamegraph.pl out.folded > ./assets/perf_example_python3.12.before.svg
Взглянем на отчет с помощью perf report -g -i perf.data.
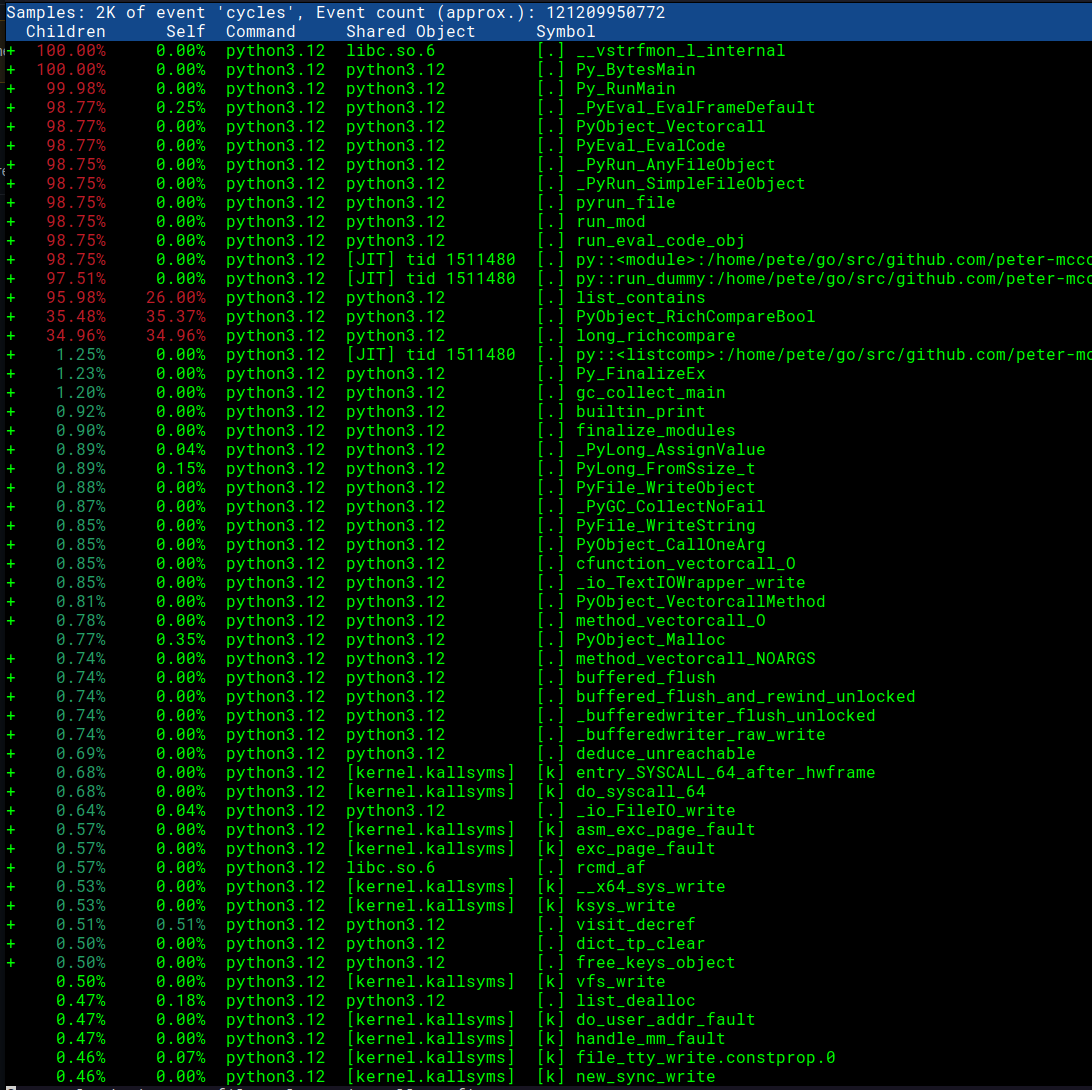
Отлично, мы видим имена функций Python и имена скриптов.
Давайте посмотрим на обновленный SVG, который визуализирует трассировки с Python 3.12:
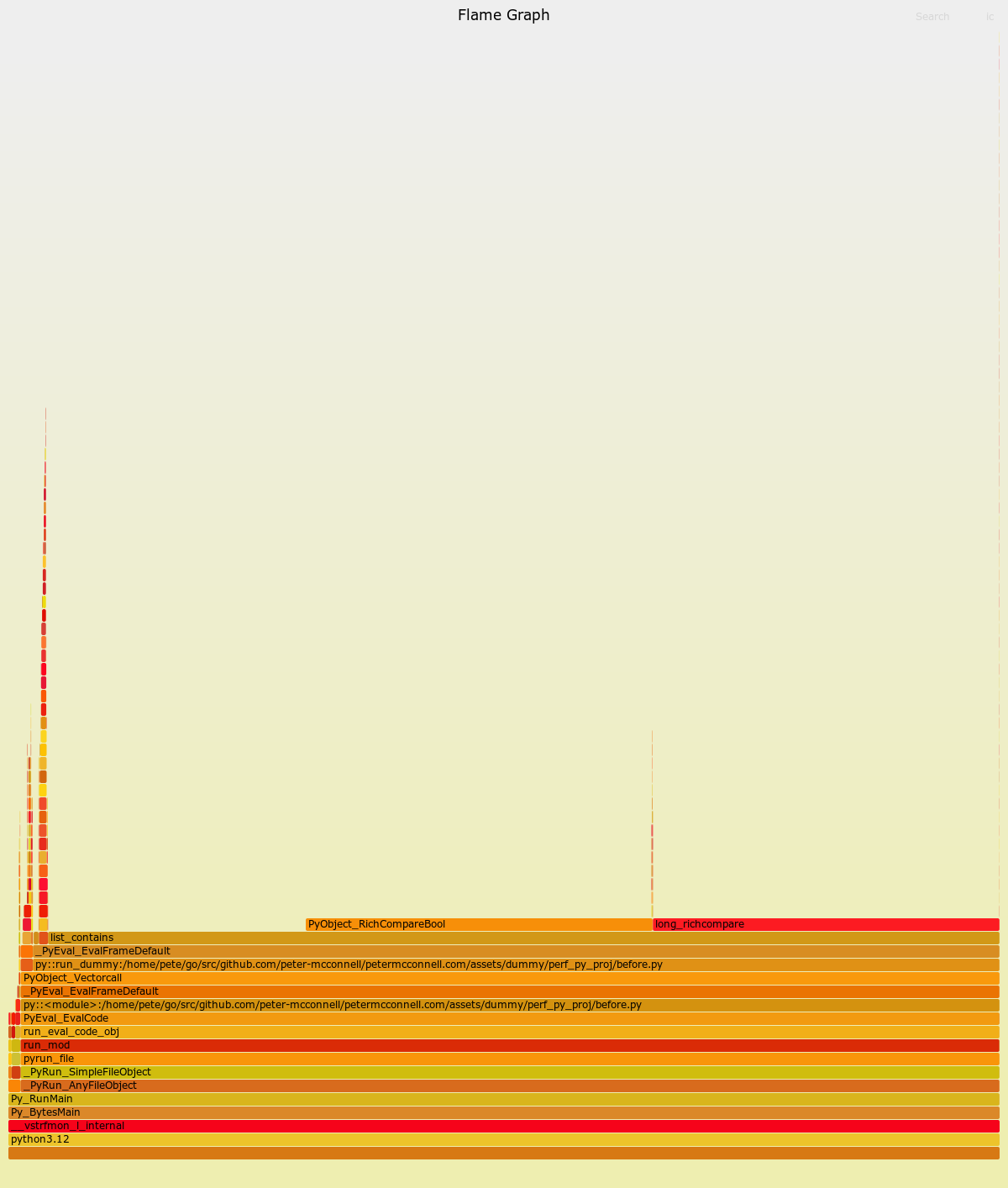
Это уже выглядит гораздо полезнее. Отсюда мы узнали, что большая часть времени уходит на сравнения и на метод list_contains. Также видим конкретный файл before.py и вызывающий его метод run_dummy.
Время расследования / исправление
Теперь, когда мы знаем, где в нашем коде проблема, давайте посмотрим на исходный код на CPython, чтобы понять, почему метод list_contains работает так медленно.
Примечание: если нет доступа к исходному коду, можно просмотреть дизассемблированный код непосредственно в результатах perf. Ближе к концу статьи я добавлю краткое описание того, как это выглядит.
// Я нашел это, зайдя на https://github.com/python/cpython/ и выполнив поиск "list_contains"
static int
list_contains(PyListObject *a, PyObject *el)
{
PyObject *item;
Py_ssize_t i;
int cmp;
for (i = 0, cmp = 0 ; cmp == 0 && i < Py_SIZE(a); ++i) {
item = PyList_GET_ITEM(a, i);
Py_INCREF(item);
cmp = PyObject_RichCompareBool(item, el, Py_EQ);
Py_DECREF(item);
}
return cmp;
}
Отвратительно… Каждый раз при вызове этого кода выполняется итерация по массиву и сравнение с каждым элементом. Это не лучший вариант для нашей ситуации, поэтому давайте вернемся к написанному коду на Python. Flame Graph показывает, что проблема кроется в методе run_dummy:
def run_dummy(numbers):
for findme in range(100000):
if findme in numbers: # <- это запускает list_contains
print("found", findme)
else:
print("missed", findme)Эту строку мы изменить не можем, так как она делает то, что нам нужно — определяет, является ли integer числом. Возможно, мы можем изменить тип данных чисел на более подходящий для поиска. В нашем коде есть:
numbers = [i for i in range(20000000)]
start_time = time.time() # получить текущее время [начало]
run_dummy(numbers) # запустить наш неэффективный методЗдесь мы использовали тип данных LIST для наших «чисел», которые под капотом (в CPython) реализованы в виде массивов с динамическим размером и, как таковые, далеко не так эффективны (O (N)), как Hashtable для поиска вверх по элементу (это O (1)). С другой стороны, SET (другой тип данных Python) реализован как Hashtable и даст нам быстрый поиск, который как раз нам и нужен. Давайте изменим тип данных в коде на Python и посмотрим, на что это повлияет:
# мы просто изменим эту строку, приведя числа к набору перед запуском run_dummy
run_dummy(set(numbers)) # передача set() для быстрого поискаТеперь мы можем повторить шаги, описанные выше, чтобы сгенерировать новый Flame Graph:
# запись профиля производительности в файл "perf.data" (вывод по умолчанию)
perf record -F 99 -g -- python3.12 assets/dummy/perf_py_proj/after.py
...
found 99998
found 99999
Duration: 0.8350753784179688 seconds
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.039 MB perf.data (134 samples) ]
Ситуация значительно улучшилась. Если раньше выполнение скрипта занимало 36 секунд, то теперь всего 0,8 секунды. Давайте создадим Flame Graph для нового улучшенного кода:
# читать perf.data (создан выше) и отображать вывод трассировки
perf script > out.perf
# сложим стеки в одну линию
# здесь я ссылаюсь на ~/FlameGraph/ - который можно найти по адресу https://github.com/brendangregg/FlameGraph
~/FlameGraph/stackcollapse-perf.pl out.perf > out.folded
# генерация flamegraph
~/FlameGraph/flamegraph.pl out.folded > ./assets/perf_example_python3.12.after.svg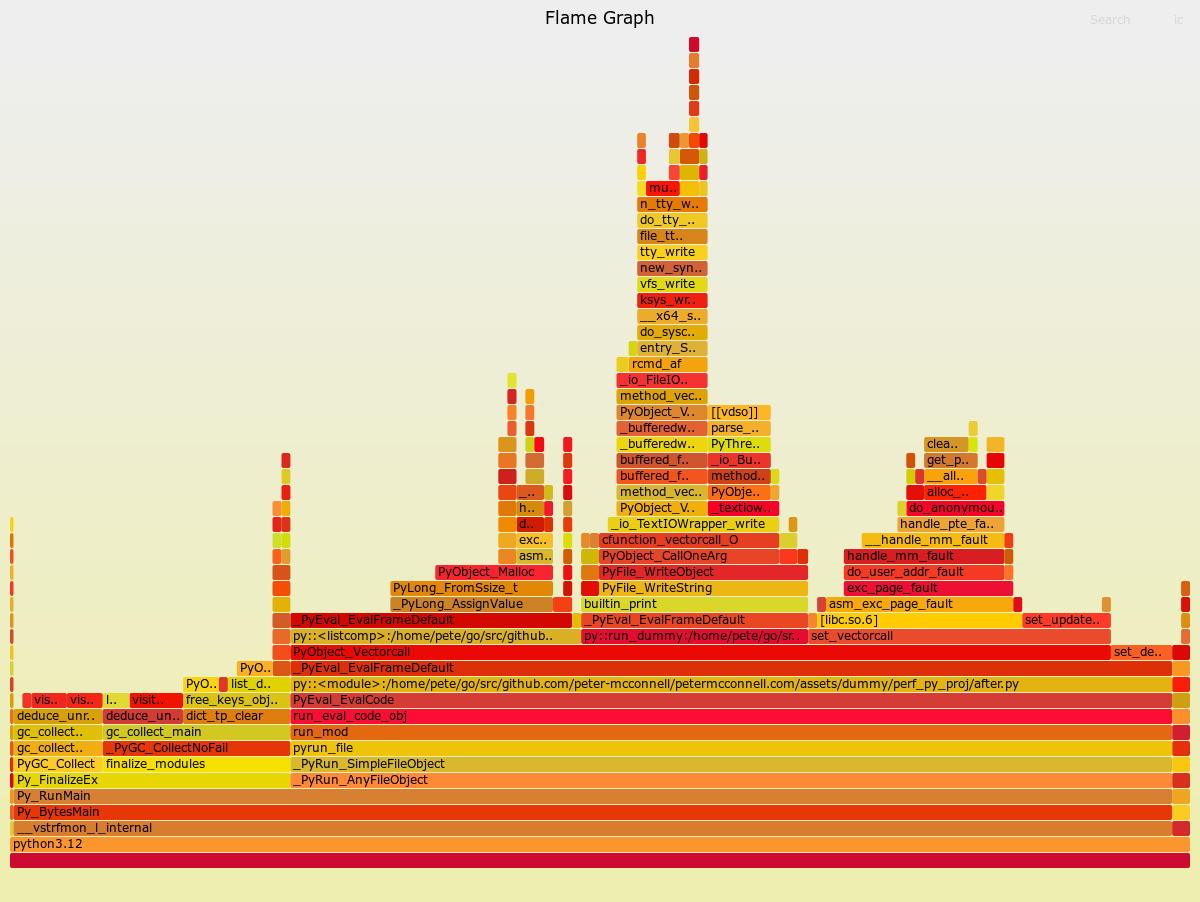
Вот это гораздо более здоровый вид Flame Graph, и в результате приложение теперь работает намного быстрее. Поддержка профилирования производительности в Python 3.12 представляет собой чрезвычайно полезный инструмент для разработчиков программного обеспечения, которые хотят создавать быстрые программы.
Бонусный раунд: что делать, если у вас нет доступа к исходному коду?
Иногда к базовому коду может не быть доступа, что затрудняет понимание происходящего. К счастью, perf report позволяет просматривать дизассемблированный код, что помогает обрисовать картину того, что на самом деле делает машина. Я предпочитаю исходный код, если его можно заполучить, поскольку он позволяет мне просмотреть связанные коммиты и пул-реквесты. Для просмотра нужно сделать следующее:
Открываем отчет о производительности и выбираем интересующую нас строку:
# это предполагает, что мы уже запустили «запись производительности» для создания perf.data...
perf report -g -i perf.data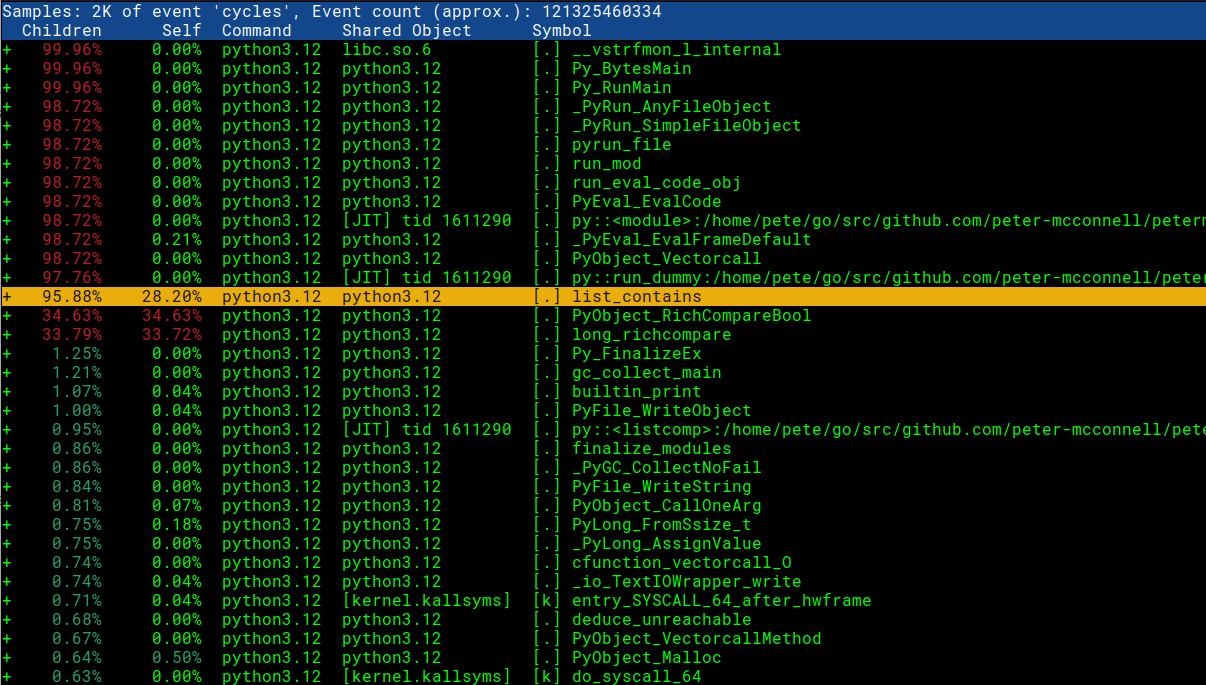
Нажмите Enter и выберите вариант аннотации:

Здесь мы можем видеть как код на C, так и машинные инструкции. Супер удобно! Можно сравнить скриншот ниже с интересующим нас фрагментом кода.
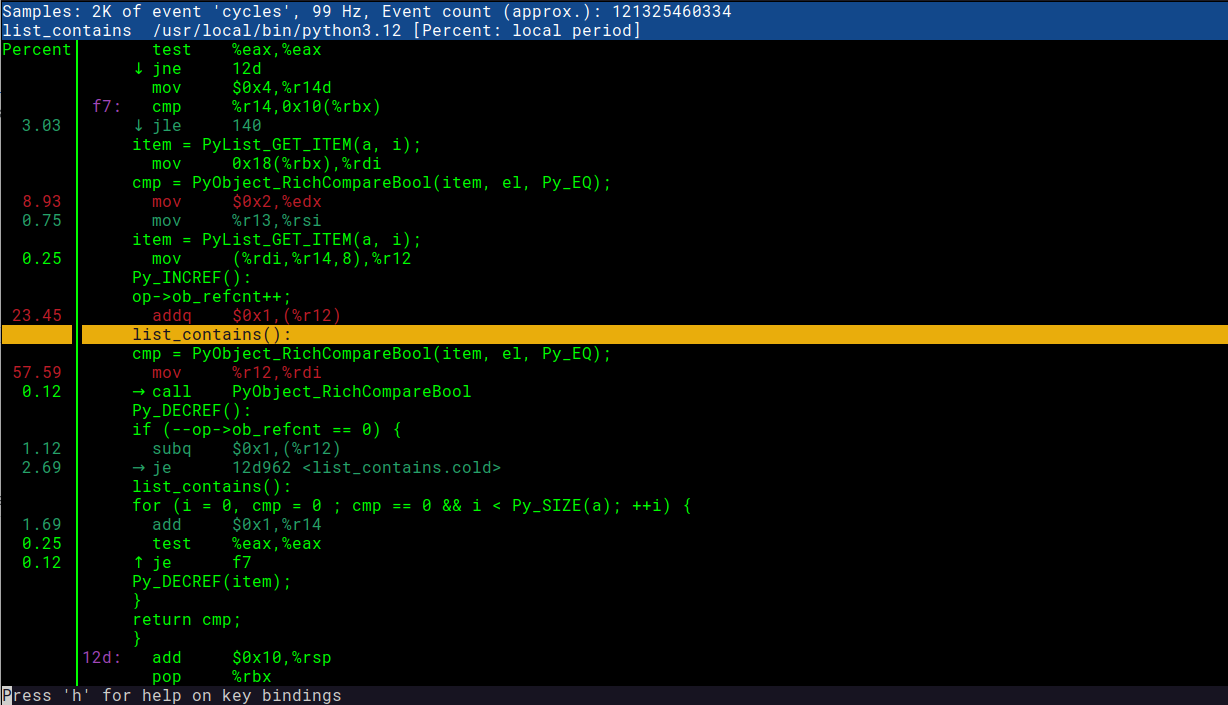
Надеюсь, эта статья дала представление об управлении производительностью, для дальнейшего же изучения темы я могу порекомендовать вот эту книгу о производительности систем.
Приглашаем всех желающих на открытый урок, на котором познакомимся с Декораторами в Python, узнаем, как они работают, а также научимся создавать их самостоятельно. Записаться можно здесь.
