Как я преподавал курс AI/ML/DL от Samsung
Всем привет. Расскажу вам про свой взгляд на ИИ, так сказать, изнутри процесса. В смысле образовательного и научного процесса.
Так сложилось что в 1998 я поступил аспирантуру в РГАСХМ и темой своей научной работы выбрал AI/ML. Это были суровые времена очередного ледникового периода нейронных сетей. Как раз в это время Ян Лекун опубликовал свою знаменитую работу «Gradient-Based Learning Applied to Document Recognition» о принципах организации сверточных сетей, которая, на мой взгляд, как раз и была началом новой оттепели. Забавно, что тогда я работал над некоторыми похожими элементами, верно ведь говорят, что идея, когда приходит её время, носится в воздухе. Однако не всем дано ее воплотить в жизнь. Свою работу я, к сожалению, так и не довел до защиты, но всегда хотел когда-нибудь закончить ее.
Источник: Hitecher
И вот по прошествии 20 лет, когда я стал работать преподавателем в Южном Федеральном Университете и одновременно преподавать в программе дополнительного образования «IT Школа Samsung», мне представился второй шанс. Компания Samsung предложила ЮФУ первому запустить учебный трек «IT Академии Samsung» по искусственному интеллекту для бакалавров и магистров. У меня были некоторые опасения в том, что удастся реализовать всю учебную программу в полном объеме, но я с энтузиазмом откликнулся на предложение читать курс. Я понял, что круг замкнулся, и мне представился таки второй шанс сделать то, что когда-то не удалось. Здесь нужно отметить, что курс Samsung AI/ML — это один из лучших на сегодня открытых русскоязычных курсов, доступных бесплатно на платформе Stepik (https://stepik.org/org/srr). Однако в случае ВУЗовской программы, помимо теоретико/практического курса, добавлялась проектная часть. То есть годовая учебная программа «IT Академии Samsung» считалась освоенной в случае изучения двух модулей «Нейронные сети и компьютерное зрение», «Нейронные сети и обработка текста» с получением соответствующих сертификатов Stepik, а также выполнения индивидуального проекта. Обучение по курсу завершалось защитой проектов студентов, на которую приглашались эксперты, в т.ч. сотрудники московского Центра искусственного интеллекта Samsung.
И вот с сентября 2019 мы стартовали курс в Институте высоких технологий и пьезотехники ЮФУ. Безусловно, довольно большое количество студентов пришло на хайпе и впоследствии был серьезный отсев. Программа была не то чтобы очень сложная, но объемная — требовались знания:
- линейной алгебры,
- теории вероятности,
- дифференциального исчисления,
- языка программирования Python.
Конечно, все требуемые знания и умения не выходят за рамки учебной программы бакалавриата 3-го курса ВУЗа. Приведу пару примеров, из тех что посложнее:
Честно говоря, кое-что, особенно из современных алгоритмов работы с нейронными сетями, я спешно изучал вместе со студентами. Изначально предполагалось, что студенты будут сами изучать видео-лекции онлайн курса Samsung на Stepik, а в аудитории мы будем делать только практикумы. Однако, я принял решение также читать и теорию. Это решение обусловлено тем, что с преподавателем можно разобрать непонятную тему, обсудить возникшие идеи и т.д. Практические же задачи студенты получали в виде домашних заданий. Подход оказался правильным — на занятиях получалась живая атмосфера, я видел, что студенты в целом достаточно успешно осваивают материал.
Через месяц мы плавно перешли от модели нейрона к первым простым полносвязным архитектурам, от простой регрессии к многоклассовой классификации, от простого вычисления градиента к алгоритмам оптимизации градиентного спуска SGD, ADAM и т. д. Завершали первую половину курса сверточные сети и современные архитектуры глубоких сетей. Финальным заданием первого модуля по Computer Vision было участие в соревновании на Kaggle «Dirty vs Cleaned» с преодолением порога точности в 80%.
Еще один, на мой взгляд, важный фактор: мы не были замкнуты внутри вуза. Организаторы трека проводили для нас вебинары и мастер-классы с приглашенными экспертами из лабораторий Samsung. Такие мероприятия повышали мотивацию студентов, да и мою, честно говоря :). Например, было интересное профориентационное мероприятие — онлайн-мост между аудиториями ЮФУ, МГУ и Samsung, на котором сотрудники московского Центра ИИ Samsung рассказали о современных направлениях развития AI/ML и ответили на вопросы студентов.
Вторая часть курса, посвященная обработке текста, начиналась с общей теории лингвистического анализа. Далее студентам были представлены векторная и TF-IDF модели текста, а потом и дистрибутивная семантика и word2vec. По результатам было проведено несколько интересных практикумов: генерация ембедингов word2wec, генерация имен и лозунгов. Дальше мы перешли к теории и практике по использованию сверточных и рекуррентных сетей для анализа текста.
Пока суть да дело, выпустил статью в ВАКовском журнале и начал готовить следующую, плавно набирая материал на новую диссертацию. Мои студенты тоже не сидели на месте, а стали работать над своими первыми проектами. Студенты выбирали темы самостоятельно, и в итоге получилось 7 выпускных проектов в разных областях применения нейронных сетей:
- «Мониторинг физической активности человека» Благодарный Александр, Крикунов Станислав.
- «Разработка алгоритмов идентификации усталости человека» Соленова Антонина.
- «Распознавание маски на лице» Будаева Екатерина.
- «Распознавание эмоций по фотографии лица» Пандов Вячеслав.
- «Определение эмоций по речи» Тихонов Алексей.
- «Косметологический консультант» Жмайлова Наталья.
- «Цена слова» Ринкон Диас Хаиро Алонсо, Моралес Кастро Хайме Игнасио.

Все проекты прошли защиту, но степень сложности и проработанности была разной, что, вполне справедливо, нашло отражение в оценках за проекты. По результатам защиты четыре проекта были отобраны на ежегодный конкурс «IT Академии Samsung». И с гордостью могу сказать, что жюри присудили двум нашим проектам высшие места. Ниже я приведу краткое описание этих проектов, основанное на материалах, предоставленных моими студентами Благодарным Александром, Крикуновым Станиславом и Пандовым Вячеславом, за что им большое спасибо. Считаю, что продемонстрированные ими решения вполне могут быть оценены как серьезная исследовательская работа.
Проект состоял в том, чтобы создать мобильное приложение, определяющее и количественно подсчитывающее физическую активность на тренировках при помощи сенсоров мобильного телефона. Сейчас существует множество мобильных приложений, которые могут распознавать физическую активность человека: Google Fit, Nike Training Club, MapMyFitness и другие. Однако, эти приложения не могут распознавать отдельные виды физических упражнений и подсчитывать количество повторений.
Один из авторов проекта Благодарный Александр, мой выпускник по программе «IT Школа Samsung» 2015 года, и я не без гордости, радовался, что полученные еще в школе знания по мобильной разработке были применены в таком ключе.
Как распознаётся физическая активность? Начнем с того, как определяются временные границы упражнений. Для детектирования начала и конца упражнений студентами было решено использовать модуль ускорения, вычисляемый как корень из суммы квадратов ускорений по осям. Выбирался некоторый порог, с которым сравнивалось текущее значение ускорения. Если произошло превышение порога (производная ускорения положительная), то считаем, что упражнение началось. Если текущее ускорение стало ниже порога (производная ускорения отрицательная), то считаем, что упражнение закончилось. К сожалению, такой подход не позволяет производить обработку в реальном времени. Возможное улучшение — применение скользящего окна на данные с вычислением результата на каждом шаге сдвига.
Датасет был собран авторами самостоятельно. При выполнении 7 различных упражнений использовались 3 вида смартфонов (Android версии 4.4,9.0, 10.0). Смартфон закреплялся на руке с помощью специального кармана. Суммарно тремя добровольцами было выполнено 1800 повторений. При выполнении могли возникать ошибки в технике по каким-либо причинам, поэтому была проведена процедура очистки выборки. Для этого были построены распределения взаимных корреляций для всех видов упражнений. Затем для каждого упражнения был выбран порог корреляции, ниже которого упражнение считается негодным и исключается из выборки.
Одно и то же упражнение, в зависимости от повторения, имеет различное время выполнения. Для борьбы с этим было решено интерполировать данные фиксированным числом отсчетов вне зависимости от того, сколько поступило с датчиков. Поступило 50 — удваиваем частоту дискретизации, вычисляя промежуточные позиции как среднее арифметическое соседних. Поступило 200 — выбрасываем каждый 2 отсчет. При этом число отсчётов будет постоянным. Аналогично при любых отношениях входного числа отсчётов к желаемому выходному числу.
Для нейросети было решено применять данные в частотной области. Поскольку масса тела человека достаточно велика, можно ожидать, что на большинстве стандартных упражнений характерные частоты сигнала будут лежать в низкочастотной области спектра. При этом высокие частоты можно считать либо дрожью при выполнении, либо шумами датчиков. Что это значит? Это значит, что мы можем найти спектр сигнала при помощи быстрого преобразования Фурье и использовать только 10–20% данных для анализа. Почему так мало? Так как 1) спектр симметричен, можно сразу отсечь половину составляющих 2) основная информация — лишь 20–40% информативной части спектра. Такие предположения особенно хорошо описывают медленные силовые упражнения.
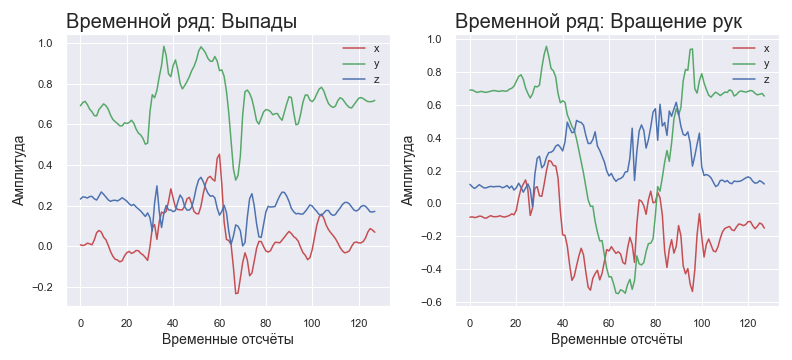
Нормированный временной ряд для разных упражнений
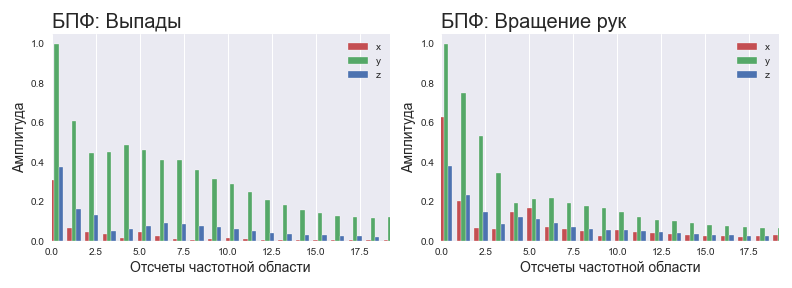
Нормированный спектр для разных упражнений
Перед обработкой нейросетью происходит нормировка спектра данных на максимальное значение среди трёх осей, чтобы уложить все образцы упражнений в диапазон 0–1 по амплитуде. При этом пропорции между осями сохраняются.
Нейросеть выполняет задачу классификации упражнений. Это значит, что она выдает вектор вероятностей всех упражнений из списка, по которым она была обучена. Индекс максимального элемента в этом векторе — номер выполненного упражнения. При этом, если уверенность в выполненном упражнении менее 85%, то считается, что ни одно из упражнений не было выполнено. Сеть состоит из 3 слоев: 4 свёрточных, 3 полносвязных, количество выходных нейронов равно количеству упражнений, которые мы хотим распознавать. В архитектуре для экономии вычислительных ресурсов используются только свёртки с размером ядра 3×3. Сравнительно простая архитектура сети оправдана ограниченными вычислительными ресурсами смартфонов, в нашей задаче необходимо распознавание с минимальной задержкой.

Описание архитектуры нейросети
Стратегия обучения нейросети — обучение по эпохам с применением батч-нормализации к обучающим данным до момента, пока лосс-функция на тренировочной выборке не достигнет минимального значения.
Результаты: при более-менее качественном выполнении упражнений уверенность сети составляет 95–99%. На валидационной выборке точность составила 99.8%.
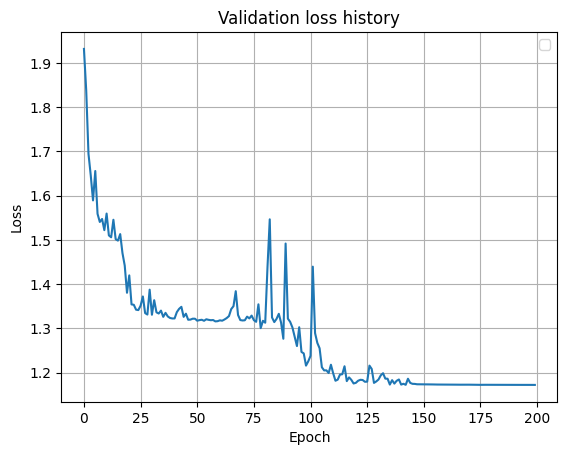
Ошибка при обучении на валидационной выборке

Матрица ошибок для нейросети
Нейросеть была встроена в мобильное приложение и показала аналогичные результаты, как и при обучении.
В ходе исследования также были опробованы другие модели машинного обучения, используемые в наши дни для решения задач классификации: логистическая регрессия, Random forests, XG Boost. Для этих архитектур были использованы регуляризация Тихонова (L2), перекрёстная проверка и gridsearch для поиска оптимальных параметров. Показатели точности в результате оказались следующими:
- Логистическая регрессия: 99.4%
- Random forests: 99.1%
- XG Boost: 97.5%
Знания, полученные в ходе обучения в «IT Академии Samsung», помогли авторам проекта расширить горизонты интересов и оказали неоценимый вклад при поступлении в магистратуру Сколковского института науки и технологий. На данный момент мои студенты занимаются там исследованиями в области машинного обучения для систем связи.
Код на GitHub
Работа модели хорошо описана на этом слайде:

Все начинается с фотографии. В представленной реализации оно приходит от Telegram-бота. По нему Dlib frontal_face_detector находит все лица на изображении. Затем с помощью Dlib shape_predictor_68_face_landmarks детектируются 68 ключевых 2D точек каждого лица. Каждый набор нормализуется следующим образом: центрируется (вычитая среднее по X и Y) и масштабируется (деля на абсолютный максимум по X и Y). Каждая координата нормализованной точки принадлежит интервалу [-1, +1].
Затем в дело вступает нейросеть, которая предсказывает глубину каждой ключевой точки лица — координату Z, используя нормализованные координаты (X, Y). Данная модель обучалась на датасете AFLW2000.
Далее эти точки соединяются между собой, образуя сеточную маску. Её ещё можно назвать биометрией лица. Длины отрезков такой маски используются как один из способов определения эмоций. Идея в том, что каждый отрезок имеет своё место в векторе отрезков и некоторые из них в зависимости от эмоции. И каждая эмоция, теоретически, имеет ограниченное количество таких векторов. Эта гипотеза подтвердилась в процессе экспериментов. Для обучения такой модели использовались датасеты: Cohn-Kanade+, JAFFE, RAF-DB.
Параллельно ещё одна сеть учится классифицировать эмоции по самому изображению. По найденным с помощью Dlib прямоугольникам вырезаются изображения лиц. Переводятся в одноканальные черно-белые и сжимаются до размеров 48×48. Для обучения этой модели использовались те же датасеты, что и для модели с биометрией. Однако дополнительно использовался датасет FER2013.
В заключение, в работу вступает третья нейросеть, архитектура которой объединяет обучаемым слоем две предыдущие замороженные и предобученные сети. У этих сетей также переопределяются последние полносвязные слои. Вместо ожидаемого «вектора вероятностей», по которому можно определить целевой класс, теперь возвращаются более «низокоуровневые признаки». А объединяющий слой обучается интерпретировать эту информацию в целевые класс.
Среди «аналогичных решений» можно выделить следующие: EmoPy, DLP-CNN (RAF-DB), FER2013, EmotioNet. Однако сложно делать сравнения, т.к. обучались они на разных данных.
Код на GitHub
В заключение хочется сказать, что пилотный курс показал свою состоятельность, и в этом 2020/21 учебном году программа уже преподается в 23х ВУЗах партнерах «IT Академии Samsung» в России и Казахстане. Полный список можно увидеть здесь. В это году у нас уже учится группа магистров и бакалавров (в группе есть даже один целый к.э.н.!) и пока в основной массе успешно грызет гранит науки. Идеи на индивидуальный проект пока еще только предстоит найти, но студенты полны оптимизма. Конечно в следующем конкурсе индивидуальных проектов конкуренция возрастет десятикратно, но мы надеемся и в дальнейшем получать высокие оценки достижений наших учеников. И самое главное, я уверен, что полученные знания и опыт будут очень серьезным подспорьем для наших выпускников в их дальнейшем развитии в сфере IT.
2020 г. Ростов-на-Дону. ЮФУ, IT Академия Samsung.

Дмитрий Яценко
Старший преподаватель кафедры информационных и измерительных технологий, факультет высоких технологий, Южного Федерального Университета,
Преподаватель IT Школы Samsung,
Преподаватель трека AI IT Академии Samsung.
