Как я клонировал Томми Версетти, или запускаем GUI/GPU приложения в Kubernetes
Введение

Привет! Меня зовут Сергей Ермейкин, я Junior DevOps engineer в центре разработки IT-компании Lad. В моей первой статье на Хабре я расскажу про сборку своих GUI/GPU образов и покажу, как настроить хостовую и Kubernetes системы на примере игры GTA: VC.
В детстве мне очень нравилось играть в неё: рассекать на PCJ-600, вновь и вновь повторять «миссию с вертолетиком», «летать» на Panzer. Сейчас я выступаю всего лишь в роли зрителя, наблюдая за скоростными прохождениями игры. В один из таких просмотров я задался вопросом: можно ли автоматизировать процесс прохождения и направить искусственный интеллект на игру для выполнения этой задачи? Или как запустить в кластере графическое приложение, которое использует ресурсы видеокарты? Поэтому в данной статье я подготовлю среду для обучения искусственному интеллекту.
Причины появления статьи
Говоря о Kubernetes, мы подразумеваем приложения CLI, активно использующие CPU/RAM/NETWORK. Ниже я рассмотрю противоположный спектр задач, требующий GUI и GPU.
В процессе поиска по запуску GUI/GPU приложений я столкнулся со следующими проблемами:
не было пошагового руководства от А до Я с базовыми примерами;
GUI/GPU приложения редко запускают в Kubernetes — не хватало материала по данной теме.
Надеюсь, что данный материал побудет тебя, мой читатель, изучить ещё одну неизведанную сторону Kubernetes. Спектр применения статьи велик:
запуск графических приложений и отвязка их от хостовой системы;
создание GPU-кластера;
изучение машинного обучения и искусственнного интеллекта;
запуск своих любимых игр;
и многое другого.
Дисклеймер: повторяйте эксперимент на ваш риск.
Основные понятия
X.Org Server — свободная каноническая реализация сервера X Window System с открытым исходным кодом;
GLX — это расширение основного протокола системы X Window, обеспечивающее интерфейс между OpenGL и системой X Window, а также расширения для самого OpenGL;
EGL — это интерфейс между API-интерфейсами рендеринга Khronos (такими как OpenGL, OpenGL ES или OpenVG) и нативной платформой оконных систем;
Direct Rendering Infrastructure (DRI) — это интерфейс и реализация свободного программного обеспечения внутри ядра, используемого системой X Window/Wayland для безопасного предоставления пользовательским приложениям доступа к видеооборудованию без необходимости передачи данных через графический сервер. Его основное назначение — обеспечить аппаратное ускорение для реализации OpenGL в Mesa, которая является ядром драйверов DRI OpenGL;
VirtualGL — свободное программное обеспечение, перенаправляет команды 3D-рендеринга из Unix и Linux OpenGL приложений в аппаратный 3D-ускоритель на выделенный сервер и отображает выходные данные интерактивно с помощью тонкого клиента, расположенного в других местах в сети.
Описание стенда
Стенд — Dell Vostro 5502.
Краткие характеристики:
Операционная система — Ubuntu 22.04.01.
Kubernetes дистрибутив — minikube с установленным driver=none. Причина — необходимость доступа к хостовым устройствам.
Системная информация:
Сборка образов и запуск контейнеров
Проброс X vs Внутренние X
При запуске графический приложений потребуются X, чтобы с минимальными затратами проверить работоспособность приложения. Для этого пробрасываем сокет X11 сервера. Я это делал на свой страх и риск в рамках эксперимента. После базовой проверки установим и настроим X11 сервер, работающий внутри контейнера.
GTA: VC
Для запуска GTA: VC потребуются официальные файлы игры. Их можно достать из системы дистрибуции игр, например, магазина Steam. К сожалению, игра доступна только у тех, кто её купил до момента релиза Grand Theft Auto: The Trilogy — The Definitive Edition.
Стоит сказать, что официально GTA: VC не работает по GNU/Linux. Я буду собирать бинарный файл на основе RE3.
В процессе запусков и тестирования потребовалось собирать билд под два релиза Ubuntu LTS:
Разрешим контейнеру подключаться к X серверу:
xhost +local:Запуск контейнера осуществляется следующей командой:
docker container run \
--gpus all \ # Доступ к GPU устройствам
--rm -ti --entrypoint /bin/bash \
-e DISPLAY=$DISPLAY \ # Проброс адреса дисплея
--device /dev/snd \ # Доступ к звуковым устройствам
-v /dev/dri:/dev/dri \ # Доступ к GPU устройствам
-v /tmp/.X11-unix:/tmp/.X11-unix \ # Проброс сокета X11 сервера
${IMAGE}Читатель может заметить, что проброс осуществляется двумя командами:
--gpus all;-v /dev/dri:/dev/dri.
Это сделано для того, чтобы был получен доступ одновременно к двум видеокартам (Nvidia через --gpus, Intel через --volume).
Также ещё доступны параметры «проброса» устройства через:
После попадания в консоль Docker контейнера запускаем игру:
./reVCПосле окончания работы с приложением/игрой запретим контейнеру подключаться к X серверу:
xhost -local:Дополнительные материалы вы можете найти по данной ссылке.
X11 сервер
Одним из компонентов, требуемых для запуска графических приложений, является X11 сервер. До этого я предоставлял доступ с нашей хостового инстанса, теперь буду запускать его внутри контейнера. Ниже представлены различные варианты решения данной проблемы.
Xvfb
Xvfb (X virtual framebuffer) — виртуальный дисплейный сервер, позволяет выполнять графические операции в памяти без какого-либо вывода на физический дисплей. Является самым частым решением при запуске графических приложений в контейнере. Конфигурацию вы можете найти здесь.
Выглядит оно так
Xdummy
Xdummy — хак для запуска Xorg или XFree86 X-сервера с «фиктивным» видеодрайвером. Повторяет функциональность Xvfb. Конфигурацию вы можете найти здесь.
Удаленный доступ к X11 серверу
X11VNC
VNC (Virtual Network Computing) в представлении не нуждается, т.к. самый частый способ подключения к удаленному рабочему месту. Использовался в образах выше.
X2Go
X2Go — свободное ПО удалённого доступа по протоколу NX. Для ознакомления работы сервера могу посоветовать образы проекта XFCEVDI.
Управление сессией выглядит так
Более подробно с запуском можно прочитать здесь. Работа X2Go на Xephyr — X2Go KDrive позволяет задействовать поддержку 3D и RANDR, но ответвление на момент начала 2023 года считается нестабильным.
XRDP
RDP — протокол удалённого рабочего стола от компании Microsoft. Для ознакомления работы сервера могу посоветовать образы проекта container-xrdp.
Управление сессией выглядит так
Xpra
Утилита xpra — инструмент, который запускает программы X11, обычно на удаленном хосте, и направляет их отображение на локальный компьютер без потери состояния. Предоставляет удаленный доступ как отдельным приложениям, так и новым или существующим сеансам рабочего стола.
Поддерживает работу со звуком, принтерами, веб-камерами. В качестве протоколов подключения можно использовать:
Для ознакомления работы сервера можно воспользоваться инструкцией.
Есть возможность работать через web-browser
Видеодрайвера
Intel
За основу можно взять данный образ или построить свой по образу и подобию.
Nvidia
Необходимые настройки включены в образы от nvidia. Можно выбрать образ под требуемые задачи.
VirtualGL
В процессе изучения мы также коснёмся пакета VirtualGL, через которое будем запускать GUI-приложения. Чтобы его установить, можно воспользоваться:
Состав пакета VirtualGL
cpustat;
eglinfo;
glreadtest;
glxinfo;
glxspheres;
glxspheres64;
nettest;
tcbench;
vglclient;
vglconfig;
vglconnect;
vglgenkey;
vgllogin;
vglrun;
vglserver_config.
Утилиты бенчмарка и диагностики
На этапе проверки и тестирования я советую пользоваться следующими утилитами и пакетами:
mesa-utils:
glxgears;
glxinfo;
egl-info;
glmark2;
virtualgl:
vglrun -d egl0 /opt/VirtualGL/bin/glxspheres64;
/opt/VirtualGL/bin/eglinfo -e;
/opt/VirtualGL/bin/glxinfo;
intel-gpu-tools:
nvidia:
nvidia-smi;
nvtop — top для видеокарт;
clinfo;
vainfo --display drm --device /dev/dri/renderD128;
xrandr.
X11docker
Удобной альтернативой по запуску графических контейнеров является утилита x11docker. Подробнее о ней можно почитать здесь.
Настройка хостовой системы, установка плагинов, проверка
Установка драйверов на хостовую систему
Nvidia
На момент написания статьи (январь-февраль 2023 года) установил последние доступные проприетарные драйвера от nvidia — NVIDIA driver metapackage из nvidia-driver-525. Могу только посоветовать, что в процессе настройки не забывать подчищать за собой и перезагружаться. По документации аналогично — ваша по дистрибутиву или документация Arch.
После установки драйверов можно перейти к установке NVIDIA Container Toolkit. Прошу внимание обратить на конфигурационные файлы:
/etc/nvidia-container-runtime/config.toml — содержит настройки nvidia-container-runtime;
/etc/docker/daemon.json — требуется изменить runtime по умолчанию.
Intel
Для своей системы я не помню, чтобы проводил какие-либо манипуляции. По причине того, что видеодрайвера с открытым исходным кодом, то явных проблем быть не должно. Из документации могу посоветовать официальную документацию по вашему дистрибутиву и документацию Arch.
Проверка хостовой системы
Nvidia
Не открою Америку и продублирую тест от nvidia:
sudo docker run --rm -e NVIDIA_VISIBLE_DEVICES=all nvidia/cuda:12.0.0-base-ubuntu22.04 nvidia-smi
Tue Jan 24 17:53:42 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.78.01 Driver Version: 525.78.01 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:2C:00.0 Off | N/A |
| N/A 45C P8 N/A / N/A | 40MiB / 2048MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
+-----------------------------------------------------------------------------+Intel
Запустить в данном образе clinfo и удостовериться, что вывод соответствует действительности.
Kubernetes (minikube)
Чтобы получить прямой доступ к PCI устройству (в нашем случае к видеокарте), Docker требуется запускать:
Я выберу первый способ. Более подробно можно почитать здесь.
Установка плагинов устройств (device plugin)
Nvidia
Важное наблюдение — в процессе поиска информации вы можете найти как nvidia-device-plugin, так и nvidia-operator. Для реализации задачи хватит и nvidia-device-plugin, но если вы хотите заняться своим кластером вплотную, то можете рассмотреть nvidia-operator. И будьте осторожны — команды от оператора не подходят плагину, следите какую документацию читаете.
Чтобы развернуть nvidia-device-plugin, достаточно воспользоваться следующей командой:
helm upgrade --install nvidia-device-plugin nvdp/nvidia-device-plugin --namespace nvidia-device-plugin --create-namespace --waitБудет создан daemonset nvidia-device-plugin, он в свою очередь создаст pods. Логи подов должны быть примерно следующие:
2023/01/21 17:26:52 Starting FS watcher.
2023/01/21 17:26:52 Starting OS watcher.
2023/01/21 17:26:52 Starting Plugins.
2023/01/21 17:26:52 Loading configuration.
2023/01/21 17:26:52 Updating config with default resource matching patterns.
2023/01/21 17:26:52
Running with config:
{
"version": "v1",
"flags": {
"migStrategy": "none",
"failOnInitError": true,
"nvidiaDriverRoot": "/",
"gdsEnabled": false,
"mofedEnabled": false,
"plugin": {
"passDeviceSpecs": false,
"deviceListStrategy": "envvar",
"deviceIDStrategy": "uuid"
}
},
"resources": {
"gpus": [
{
"pattern": "*",
"name": "nvidia.com/gpu"
}
]
},
"sharing": {
"timeSlicing": {}
}
}
2023/01/21 17:26:52 Retreiving plugins.
2023/01/21 17:26:52 Detected NVML platform: found NVML library
2023/01/21 17:26:52 Detected non-Tegra platform: /sys/devices/soc0/family file not found
2023/01/21 17:26:52 Starting GRPC server for 'nvidia.com/gpu'
2023/01/21 17:26:52 Starting to serve 'nvidia.com/gpu' on /var/lib/kubelet/device-plugins/nvidia-gpu.sock
2023/01/21 17:26:52 Registered device plugin for 'nvidia.com/gpu' with Kubelet
Строчка Detected NVML platform: found NVML library говорит о том, что видеокарта была обнаружена. Также нода теперь имеет соответствующие ресурсы:
kubectl describe nodes user-vostro-5502
...
Capacity:
...
nvidia.com/gpu: 1
...Забегая наперед, скажу если один pod с графикой занял видеокарту, то другие pods уже не смогут подключиться. Одним из способов решения данной проблемы является покупка дополнительной видеокарты настройка time slicing.
Для этого применим данный манифест:
kubectl apply -f configmap.yamlи передеплоим хелм чарт:
helm upgrade --install nvidia-device-plugin nvdp/nvidia-device-plugin --namespace nvidia-device-plugin --create-namespace --wait --set config.name=time-slicing-configТеперь посмотрим логи у новосозданного пода (теперь в нём два контейнера: sidecar, ctr), нам нужен контейнер ctr:
2023/01/21 18:16:16 Starting FS watcher.
2023/01/21 18:16:16 Starting OS watcher.
2023/01/21 18:16:16 Starting Plugins.
2023/01/21 18:16:16 Loading configuration.
2023/01/21 18:16:16 Updating config with default resource matching patterns.
2023/01/21 18:16:16
Running with config:
{
"version": "v1",
"flags": {
"migStrategy": "none",
"failOnInitError": true,
"nvidiaDriverRoot": "/",
"gdsEnabled": false,
"mofedEnabled": false,
"plugin": {
"passDeviceSpecs": false,
"deviceListStrategy": "envvar",
"deviceIDStrategy": "uuid"
}
},
"resources": {
"gpus": [
{
"pattern": "*",
"name": "nvidia.com/gpu"
}
]
},
"sharing": {
"timeSlicing": {
"resources": [
{
"name": "nvidia.com/gpu",
"devices": "all",
"replicas": 4
}
]
}
}
}
2023/01/21 18:16:16 Retreiving plugins.
2023/01/21 18:16:16 Detected NVML platform: found NVML library
2023/01/21 18:16:16 Detected non-Tegra platform: /sys/devices/soc0/family file not found
2023/01/21 18:16:16 Starting GRPC server for 'nvidia.com/gpu'
2023/01/21 18:16:16 Starting to serve 'nvidia.com/gpu' on /var/lib/kubelet/device-plugins/nvidia-gpu.sock
2023/01/21 18:16:16 Registered device plugin for 'nvidia.com/gpu' with KubeletДобавленные реплики в в timeSlicing сообщает о том, что мы всё сделали верно.
Нода сможет запустить больше графических приложений:
kubectl describe nodes user-vostro-5502
...
Capacity:
...
nvidia.com/gpu: 4
...Интересный тред как это решали раньше.
Intel
Чтобы развернуть intel-device-plugin, достаточно воспользоваться следующими командами:
kubectl create ns intel-device-plugin
kubens intel-device-plugin
kubectl apply -k 'https://github.com/intel/intel-device-plugins-for-kubernetes/deployments/gpu_plugin?ref=release-0.26'Будет создан daemonset intel-gpu-plugin, он в свою очередь создаст pods.
Мои pods не проронили ни строчки логов, так что о работоспособности я судил по статусу pod:
kubectl get po
NAME READY STATUS RESTARTS AGE
intel-gpu-plugin-lnb2d 1/1 Running 0 10mНода теперь имеет соответствующие ресурсы:
kubectl describe nodes user-vostro-550
...
Capacity:
...
gpu.intel.com/i915: 1
...С множественным доступом к видеочипу история повторяется, что у nvidia. Официальный способ решения. Я же просто изменю параметры запуска у daemonset в рамках статьи:
kubens intel-device-plugin
EDITOR=nano kubectl edit daemonset.apps/intel-gpu-pluginДобавим параметры:
...
image: intel/intel-gpu-plugin:0.26.0
imagePullPolicy: IfNotPresent
args:
- "-shared-dev-num=4"
- "-enable-monitoring"
- "-v=2"
name: intel-gpu-plugin
...Теперь посмотрим логи у новосозданного пода:
I0122 06:29:12.819134 1 gpu_plugin.go:403] GPU device plugin started with none preferred allocation policy
I0122 06:29:12.819253 1 gpu_plugin.go:235] GPU 'i915' resource share count = 4
I0122 06:29:12.819937 1 gpu_plugin.go:248] GPU scan update: 0->4 'i915' resources found
I0122 06:29:12.819944 1 gpu_plugin.go:248] GPU scan update: 0->1 'i915_monitoring' resources found
I0122 06:29:13.820620 1 server.go:268] Start server for i915_monitoring at: /var/lib/kubelet/device-plugins/gpu.intel.com-i915_monitoring.sock
I0122 06:29:13.820672 1 server.go:268] Start server for i915 at: /var/lib/kubelet/device-plugins/gpu.intel.com-i915.sock
I0122 06:29:13.822908 1 server.go:286] Device plugin for i915_monitoring registered
I0122 06:29:13.822950 1 server.go:286] Device plugin for i915 registeredНода сможет запустить больше графических приложений:
kubectl describe nodes user-vostro-5502
...
Capacity:
...
gpu.intel.com/i915: 4
gpu.intel.com/i915_monitoring: 1
...Проверка плагинов устройств (device plugin)
Тесты не признаны проверить все аспекты использования устройства, а только правильность установки и не более. Логи можете найти в соответствующем README.md, лежащим рядом с манифествами.
Nvidia
Базовые тесты на проверку можно найти здесь.
Intel
Базовые тесты на проверку можно найти здесь.
Лирическое отступление про smarter-device-manager
На этом я заканчиваю подготовку кластера Kubernetes и перехожу к запуску полезной нагрузки. В процессе поиска я наткнулся на проект, как smarter-device-manager. Он может предоставить доступ к dev устройству в виде ресурса:
...
Capacity:
cpu: 8
ephemeral-storage: 482095632Ki
gpu.intel.com/i915: 4
gpu.intel.com/i915_monitoring: 1
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 32597084Ki
nvidia.com/gpu: 4
pods: 110
smarter-devices/gpiochip0: 20
smarter-devices/i2c-0: 1
...
smarter-devices/i2c-14: 1
smarter-devices/rtc0: 20
smarter-devices/snd: 20
smarter-devices/ttyS0: 0
...
smarter-devices/ttyS9: 1
smarter-devices/video0: 20
smarter-devices/video1: 20
...
Запуск графических приложений в Kubernetes
Сборка графического образа для Kubernetes
При запуске и тестировании GUI/GPU в кластере я использовал собственный образ, основанный на образе docker-nvidia-egl-desktop. Считаю его самым оптимальным при построении графических образов, можно опираться на его Dockerfile. Также у него есть версия docker-nvidia-glx-desktop, которая уже использует glx подход.
Сборка
Dockerfile файл располагается здесь и задействует одновременно образ ehfd и мой с GTA: VC.
Сборка образа:
cd article_materials/run-gui-app-in-k8s/dockerfile
docker build -t ehfd-egl-gta-vc:22.04 .CPU only
Манифесты располагается здесь. Renderer отображается как llvmipe. Производительность запущеной игры никакая, можно использовать только как рабочее пространство. Стоит также отметить, что если вы по умолчанию используете nvidia-runtime-docker, то внутрь будет пробрасываться nvidia устройства, даже если не указано это в ресурсах. Для отключения этого требуется указывать переменную NVIDIA_VISIBLE_DEVICE = none.
Privileged
Манифесты располагается здесь. Данный метод я не рекомендую к использованию, т.к. предоставляет прямой доступ к /dev/ устройствам, что может повредить системе, но в рамках эксперимента я должен его рассмотреть.
Включается добавлением следующих строчек:
securityContext:
privileged: trueКонтейнер получает прямой доступ к DRI устройству, но требуются дополнительные манипуляции (установка прав, переменных и т.д.), чтобы DRI устройство заработало полноценно. Обычно на себя большинство этих забот берёт device plugin, который будет рассмотрен ниже. Если запускать приложение через vglrun, то производительность находится на должном уровне, близкой к запуску на хостовой системе. Выбор DRI устройства происходит с помощью ключа -d:
Kubernetes Device Plugins
Самый правильный способ предоставления контейнеру GPU ресурсов является установка и настройка Kubernetes Device Plugins.
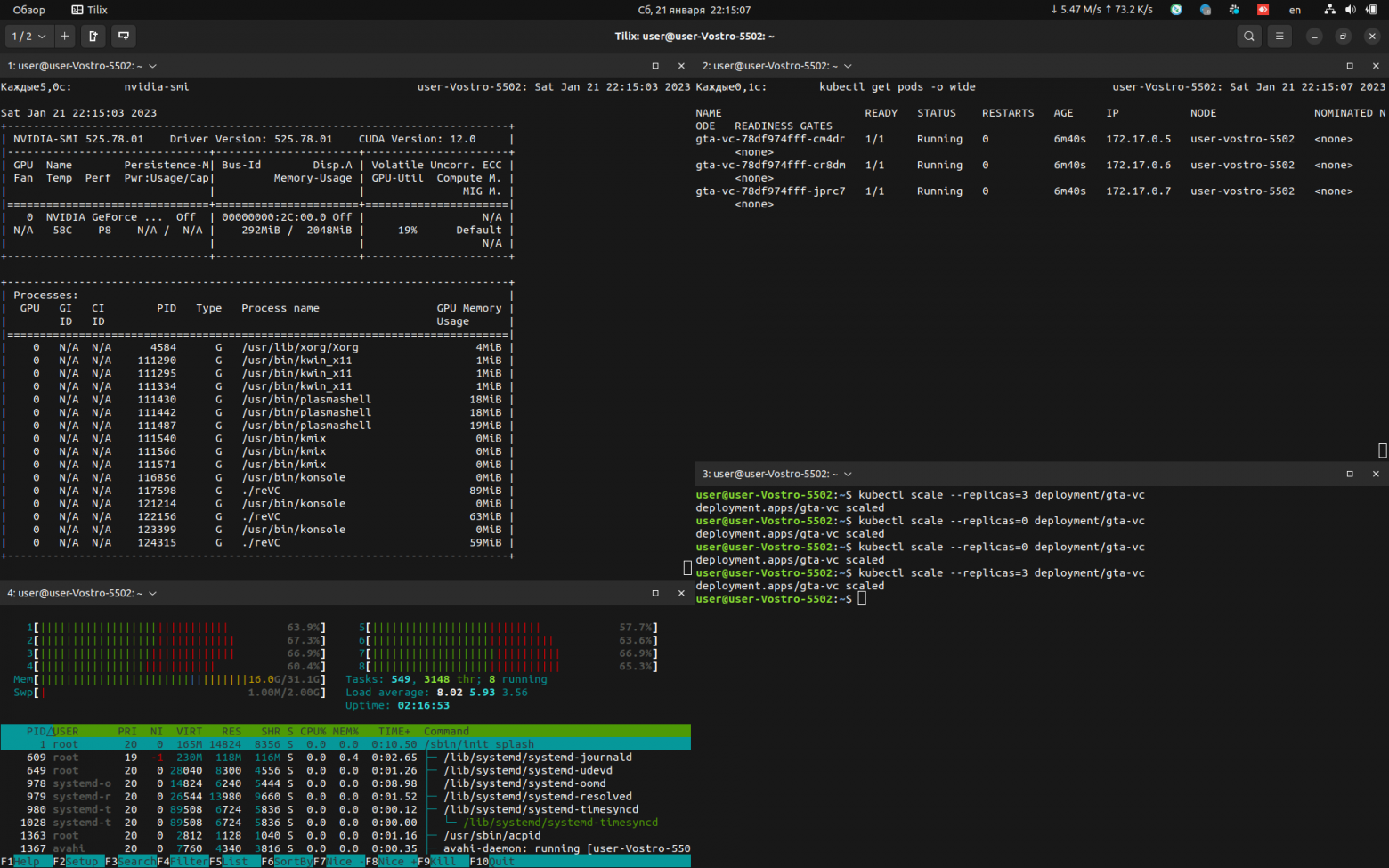
Nvidia-VNC
Манифесты располагаются здесь. Для активации требуется прописать в ресурсах:
nvidia.com/gpu: 1и указать соответствующие NVIDIA-* переменные в контейнере (либо через env, либо в dockerfile).
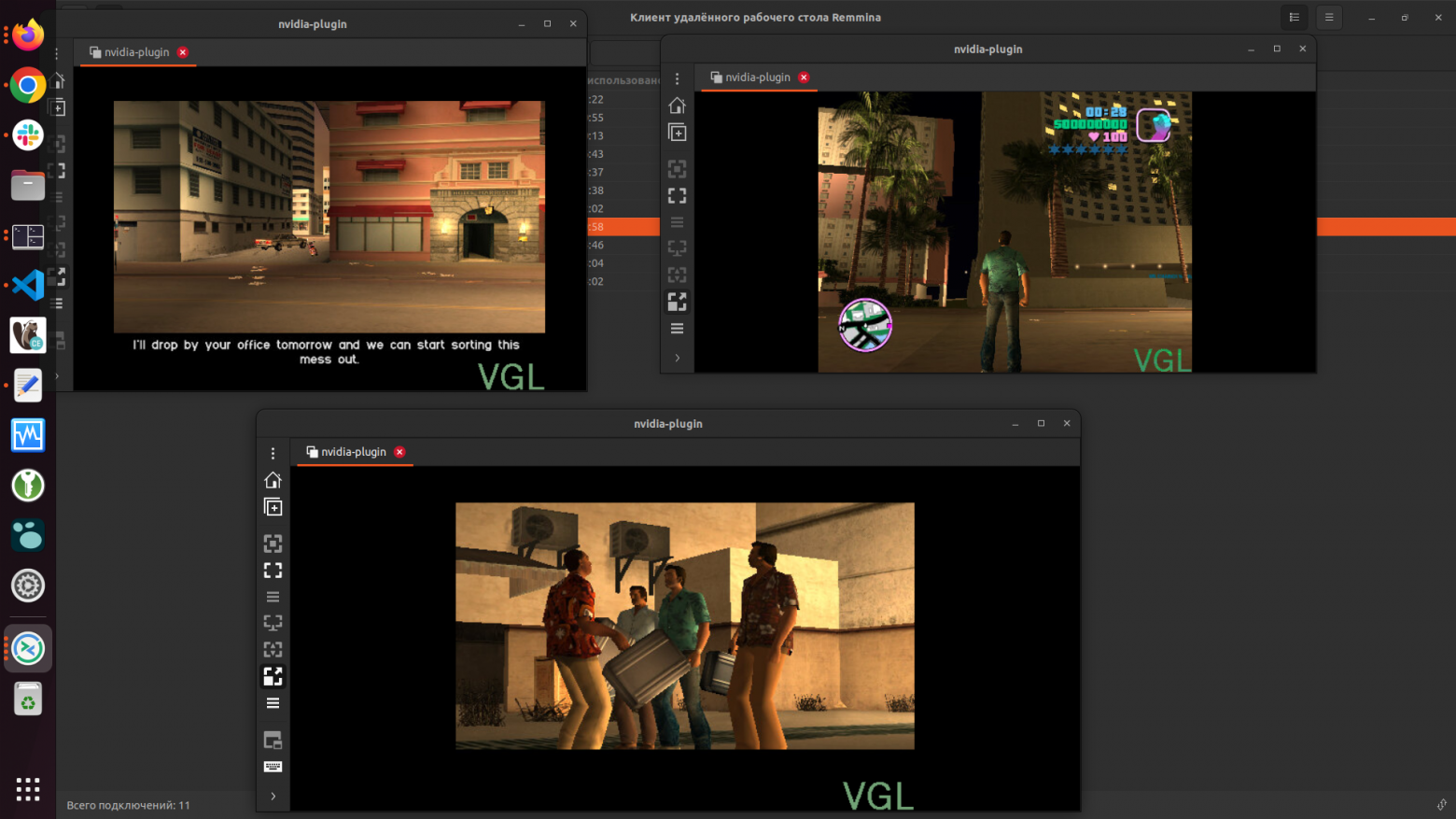
Запуск осуществляется через vglrun, производительность на должном уровне, близкой к запуску на хостовой системе. При настройке (см. раздел выше) есть возможность запустить несколько gpu приложений на одном видеоядре. При игре через VNC отсутствует звук, т.к. протокол не предусматривает его.
Скриншоты самой игры и мониторина представлены ниже
Nvidia-Gstreamer
Манифесты располагаются здесь. Для активации также прописываем ресурсы:
nvidia.com/gpu: 1указываем соответствующие NVIDIA-* переменные в контейнере (либо через env, либо в dockerfile), переключаем режим на Gstreamer (см. configmap).
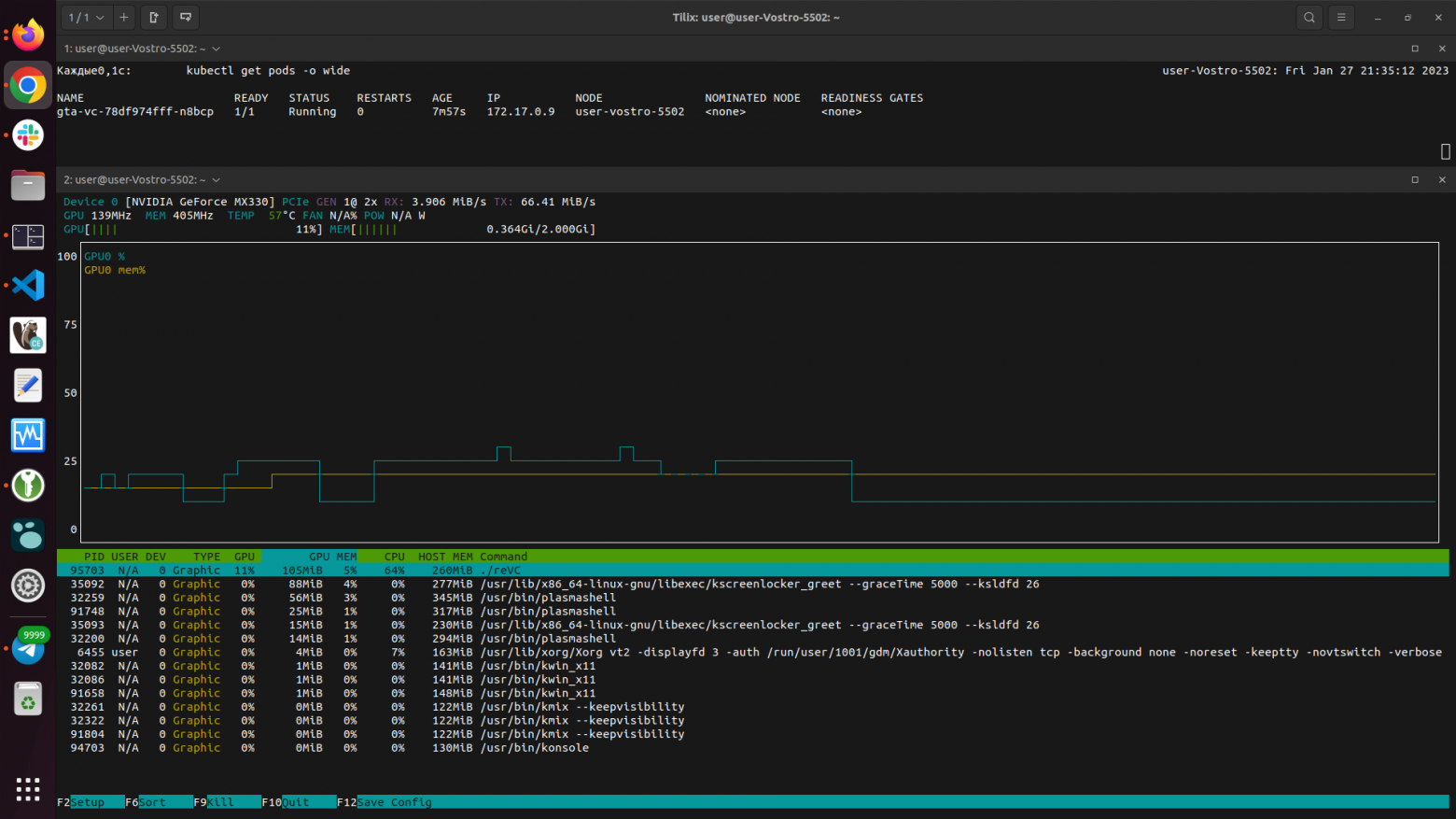
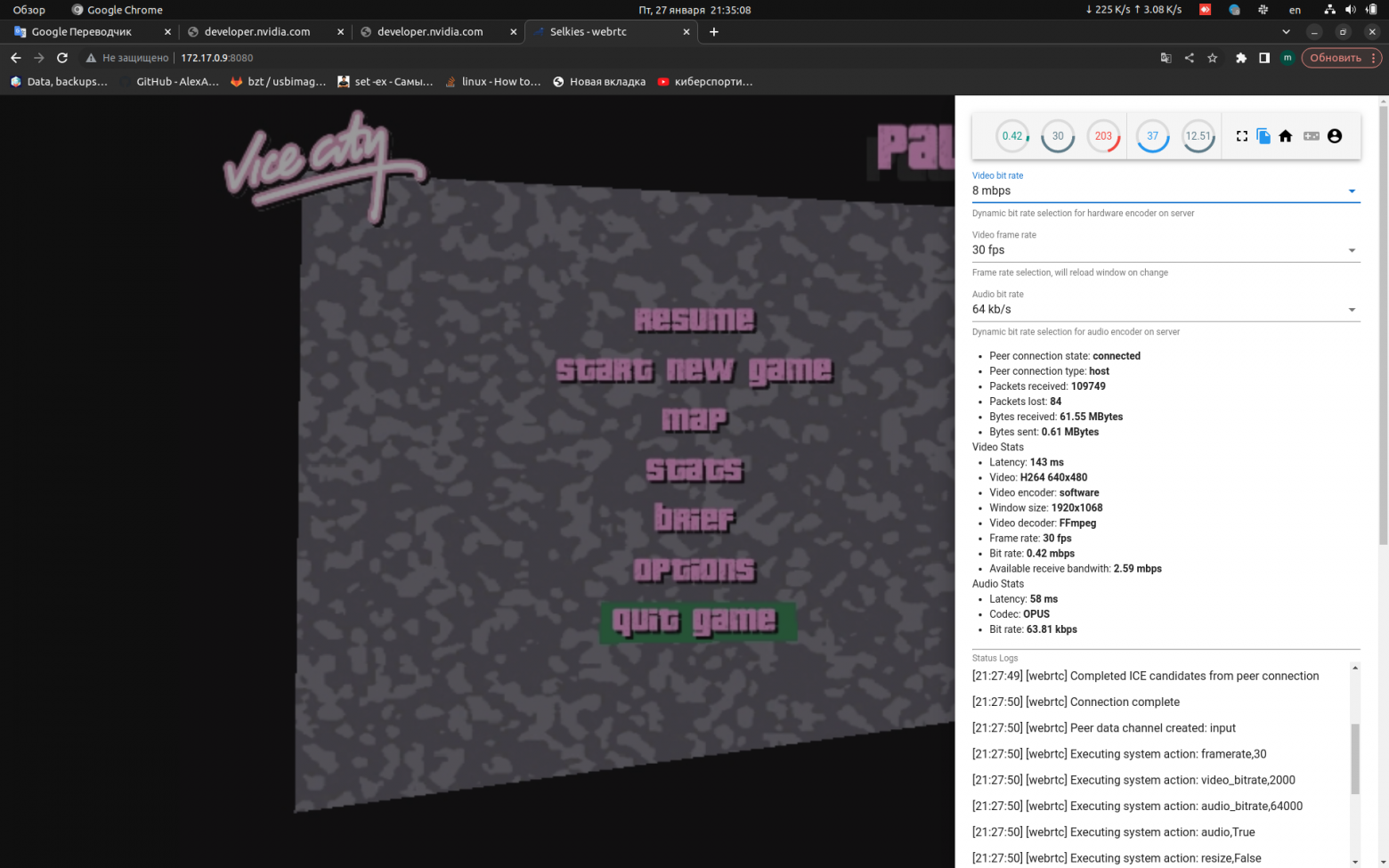
Запуск осуществляется через vglrun, производительность кодирования через мой software кодек низкая (это не означает, что у вас будет также, проверьте свою видеокарту). При настройке (см. раздел выше) есть возможность запустить несколько GPU приложений на одном видеоядре. При игре звук присутствует, но на больших разрешениях он начинает заедаться и картинка «мыльная».
Подключаемся мы напрямую к pod, т.к. если подключаться через nodePort, то требуется настройка TURN сервера. Это конечно требуется учитывать, если есть желание работать через gstreamer.
Скриншоты самой игры и мониторина представлены ниже
Nvidia-XPRA
Манифесты располагаются здесь. Для активации требуется прописать в ресурсах:
nvidia.com/gpu: 1и указать соответствующие NVIDIA-* переменные в контейнере (либо через env, либо в dockerfile). В Docker образ уже встроен XPRA и SSH сервер.
Запуск осуществляется через vglrun, производительность на должном уровне, близкой к запуску на хостовой системе. При настройке (см. раздел выше) есть возможность запустить несколько gpu приложений на одном видеоядре. При игре через XPRA присутствует звук, игру можно запустить на удаленном клиенте в оконном режиме.
Intel-VNC
Манифесты располагаются здесь. Для активации требуется прописать в ресурсах:
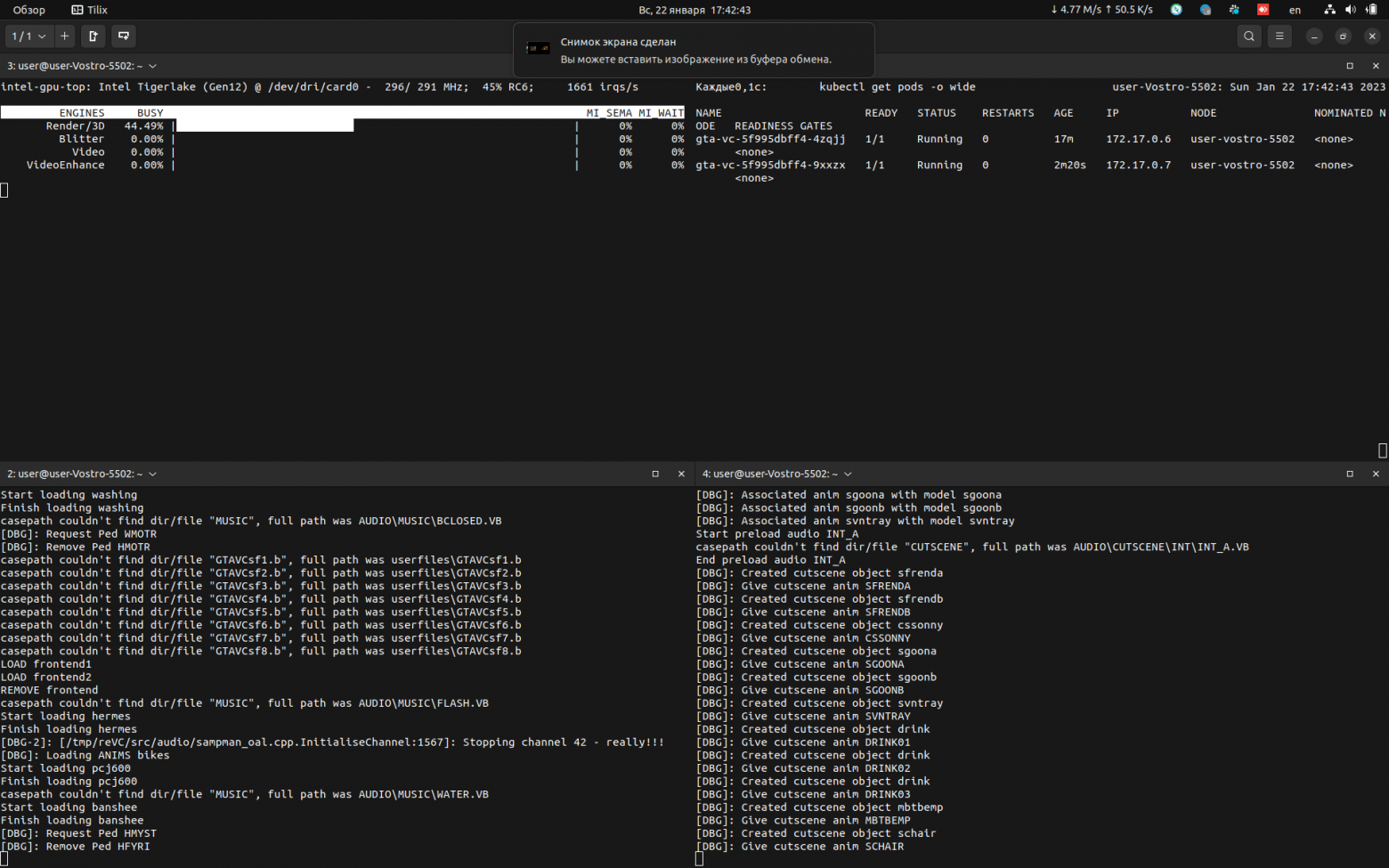
gpu.intel.com/i915: 1Запуск осуществляется через vglrun, производительность на должном уровне, близкой к запуску на хостовой системе. Эксперимент был коротким по времени, т.к. могло что-то отказать из превышений допустимой нагрузки на аппаратную часть. Понадобилось также добавить права пользователю, см. README.md. При настройке (см. раздел выше) есть возможность запустить несколько gpu приложений на одном видеоядре.
Скриншоты самой игры и мониторина представлены ниже
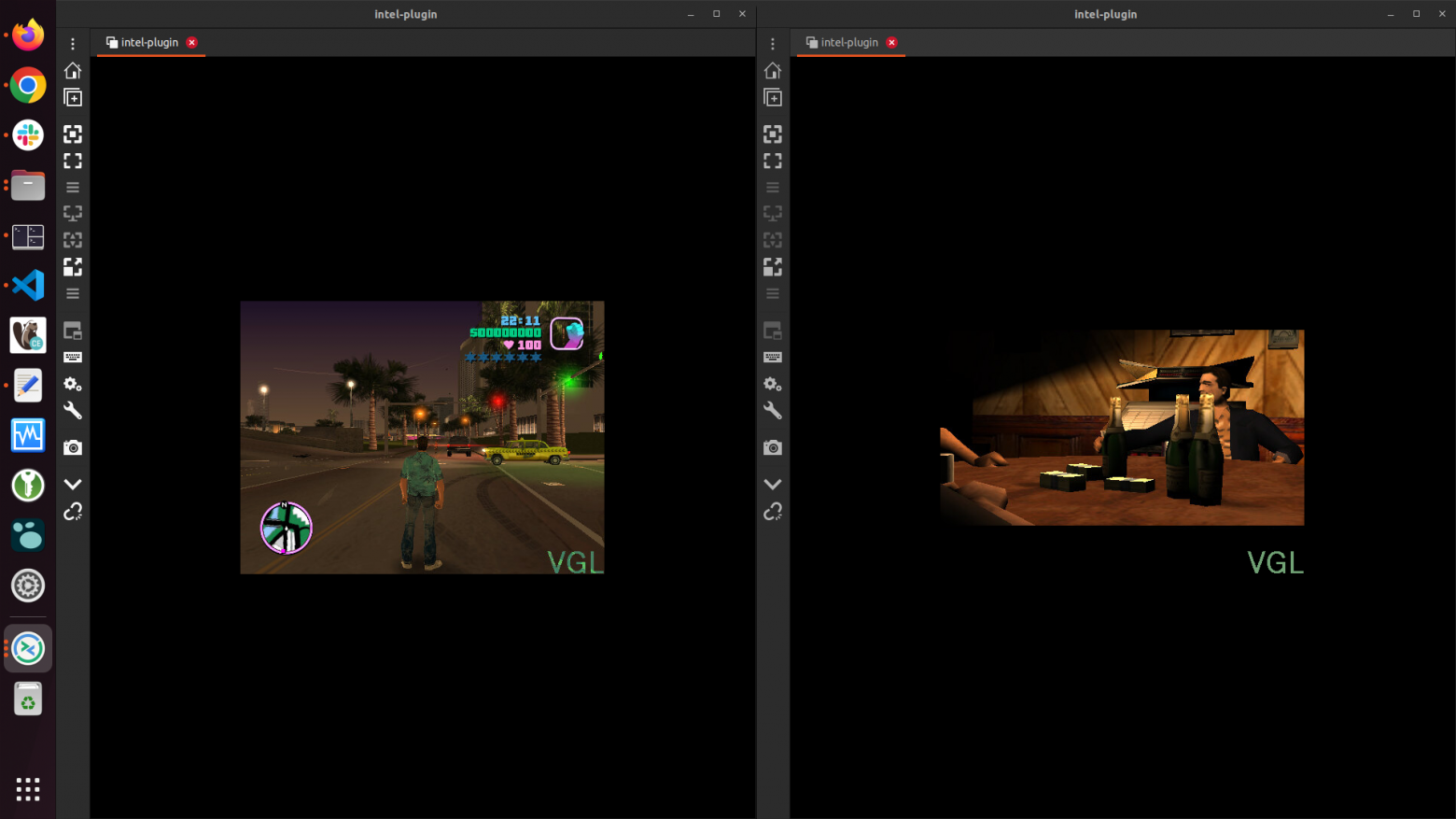
VirtualGL
Т.к. до этого мы использовали во всех экспериментах VirtualGL, то я не мог обойти его мимо. Чтобы использовать его в контейнере, кроме установки, требуется доступ к видеокарте. Я рассмотрел варианты, когда она проброшена в контейнер, но можно также воспользоваться решением, когда virtualgl расположен вне кубера и доступ туда есть по ssh.
Краткая инструкция и манифесты приложены здесь. В качестве опытного образца я создал два deployments:
gta-vc-server — имеет nvidia видеокарту;
gta-vc-client — не имеет видеокарту, но на нём требуется запустить приложения.
Я использовал схему подключения через ssh.
Ограничения по использованию данного метода:
у сервера обязательно должен быть доступ к GPU любым способом;
запускаемое приложение должно быть установлено на сервере с видеоустройством;
часто невозможен запуск нескольких копий из-за архитектуры приложения. GTA: VC не запускалась, поскольку она не подразумевает запуск нескольких копий одновременно — копии получали softlock;
учитывайте скорость соединения.
Также я подготовил видео, где vglconnect происходил с хостового инстанса, а подключался и запускал саму GTA: VC в контейнере в Kubernetes. К сожалению, OBS Studio вносил существенный input lag, по этой причине разрешение было понижено до 1366×768 и уменьшено качество выдаваемой картинки (VGL_QUALITY).
Распространённые проблемы и способы их решения
Strace
В процессе решения проблемы не забываем об утилите strace.
Пример команды:
strace -e openat programFailed to initialize NVML: Insufficient Permissions
Причина: отсутствует доступ к /dev/nvidiactl.
Решение на выбор:
запуск от sudo;
изменить доступ через
chown;добавить пользователя в группу, имеющая доступ к
/dev/nvidiactl;проверьте настройки в файле
/etc/nvidia-container-runtime/config.toml.
Также заметил, что при конфигурировании VirtualGL на хостовом инстансе изменяются права через udev: это справедливо, поскольку ему требуется доступ к nvidia-устройствам. Об этом говорит наличие файла /etc/udev/rules.d/99-virtualgl-dri.rules. Чтобы убрать VirtualGL из системы, требуется:
cd /opt/VirtualGL/bin
sudo vglserver_config
2 пункт - 2) Unconfigure server for use with VirtualGL (GLX + EGL back ends)
exit
rebootПосле проверить права на доступ к видеоустройствам.
Программа запущена верно, но отсутствует GPU ускорение
Краткий алгоритм:
проверить доступ к /dev/nvidia* и /dev/dri/*;
запустить через vglrun с указанием устройства;
воспользоваться утилитами для диагностики и посмотреть рендер;
включить VGL_LOGO=1 для проверки работоспособности vglrun;
запустить на хосте и проверить скорость работы.
Полезные решения
Проброс GUI приложения через hostPath
При пробросе игры можно пробросить директорию через hostPath. Только требуется не забывать о правах пользователя, который запускает данное приложение. В целом это достаточно быстрый способ, когда не хочется собирать контейнер.
Проброс X в deployment
Запускаем игру по аналогии с Docker-средой, только переписываем манифесты под Kubernetes. Потребуется:
privileged доступ;
проброшенный /tmp/.X11-unix;
установленная переменная DISPLAY;
разрешенный доступ со стороны хостового X.
Требуется запустить только приложение в EHFD образе
Достаточно заменить любым удобным способом запуск KDE на своё приложение, начиная с этого места. Сразу не деплоим: отладьте и поработайте со своим приложением, запустив его из графической среды.
Заключение
Напомним кратко что мы сделали:
изучили требуемый софт для формирования docker образов;
собрали и запускали docker образы, взаимодействовали с графикой;
настроили систему и Kubernetes для работы с GPU;
запустили приложения с GPU в Kubernetes;
поиграли в GTA: VC;
рассмотрели возможные проблемы.
Удачи!
